SkillOpt:做Agent,当然不能只靠Prompt和微调啦
在当前的大模型应用开发中,构建一个能够稳定执行特定任务的Agent,始终面临着工程路径上的两难选择。
第一条路是重度依赖人工编写Prompt。这种方式虽然起步直观,但极度依赖开发者的个人经验。随着业务场景复杂度的上升,手动调试Prompt很容易出现这种问题:你在这里加了一句指令修补了漏洞,可能又会在另一个意想不到的地方引发模型的幻觉。
第二条路则是走向模型微调。做过大模型调优的开发者对此应该有这样的共感,当你在尝试让百亿参数级别的模型理解特定任务时,立刻就会面临严苛的显存瓶颈以及高额的算力成本,即便使用了 LoRA 等参数高效微调技术,底层的工程复杂度和数据准备成本依然很高。但是更加难以解决的问题是迭代过程,一旦基础模型发生跨代际的版本迭代,原本费尽心血跑出来的微调权重往往难以直接迁移,只能将整个工程推倒重来。
面对这种算力与人工的拉扯,近期微软研究院提出的 SkillOpt(Executive Strategy for Self-Evolving Agent Skills)框架,为打破这一僵局提供了一种全新的工程视角。
这篇文章的核心思想并不复杂:它放弃了对底层神经网络权重的直接修改,转而将 AI 智能体执行任务的skill.md视为深度学习中的“可训练参数”。通过构建一套自动化的文本反馈与更新机制,SkillOpt 实现了智能体能力的自我进化,且在整个优化过程中保持目标大模型处于完全 Frozen状态。
要真正理解 SkillOpt 的运作机制以及它带来的技术冲击,我们可以将其与经典的机器学习训练流程进行一次深度的思想实验类比。这也是整个框架最能让人产生启发的地方:它本质上,是在纯文本的语义空间中,复刻了深度学习寻找“梯度”的优化过程。
在传统的梯度下降中,模型通过前向传播产生预测结果,一旦发现错误,系统就会计算损失函数,并通过反向传播计算梯度。这个“梯度”就像一根精确的指针,告诉每一个抽象的数字参数该往哪个方向微调才能降低错误率。SkillOpt 让人拍案叫绝的创新,就是将这一套极其底层的数学逻辑,完整而优雅地映射到了自然语言的语义空间中。
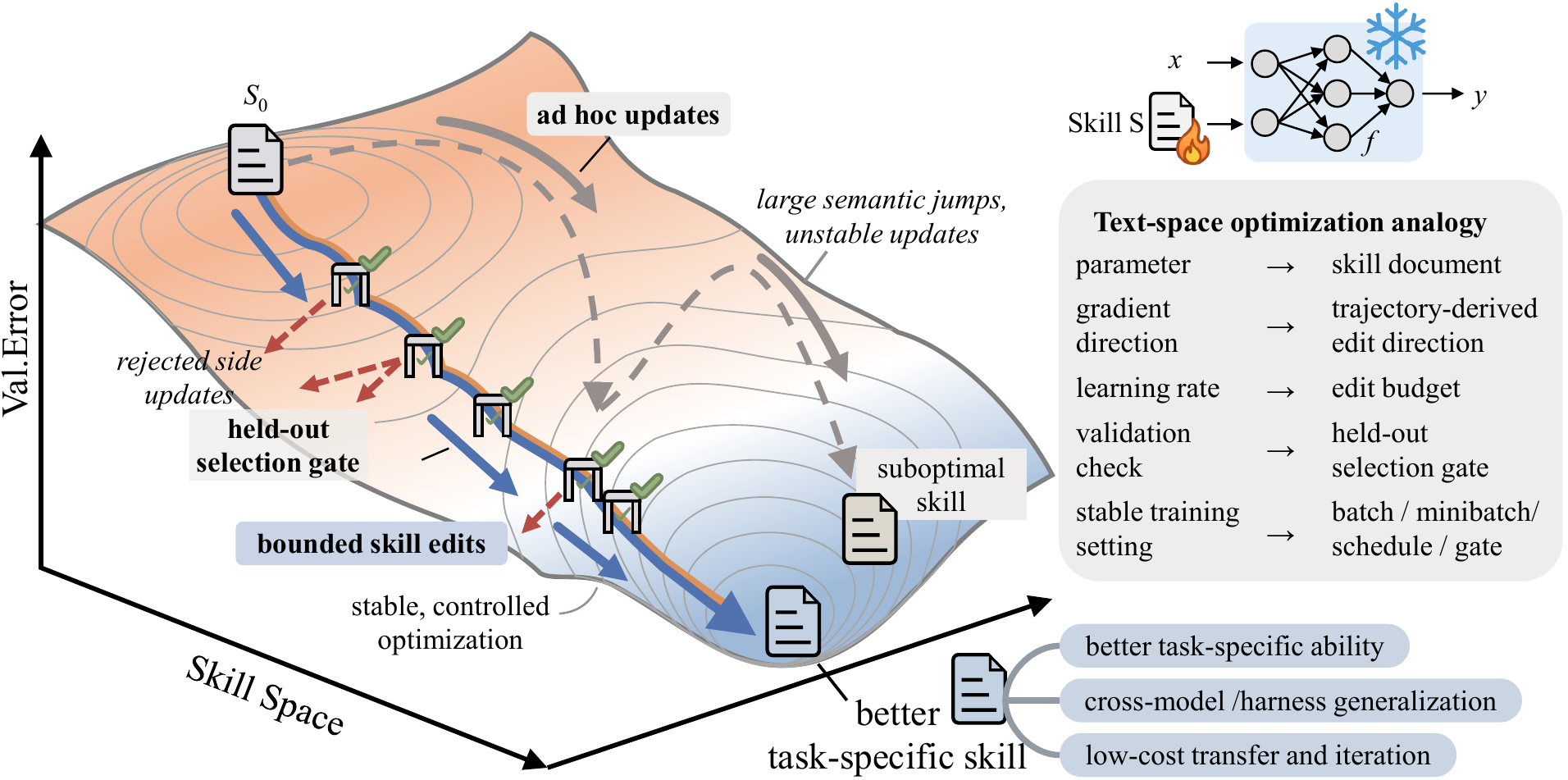
Figure 1:SkillOpt 文本空间优化类比图。右侧展示了从传统的参数优化到“文本技能优化”的完美映射。左侧的蓝线代表通过“有界编辑”和“验证门控”实现的稳定优化路径,有效避免了虚线所示的语义跳跃和系统崩溃。(图源:微软 SkillOpt 官方项目页)
在这个语义优化周期中,系统首先会分配一个大型语言模型作为“执行者”。它拿着初始的skill.md去处理一批真实的复杂任务,这个过程在框架中被称为Rollout,等同于数学模型里的前向传播。执行者在尝试解决问题时留下的所有交互记录、成功经验以及失败教训,都会被完整留存下来,形成类似神经网络训练中的“经验回放”数据。
随后,真正体现这种“语义空间寻优”的环节到来了。系统会引入另一个不直接干活、而是专门承担“优化器”角色的大语言模型。它的任务就像人类资深架构师在做 Code Review,去仔细审视刚才生成的执行轨迹。当优化器发现执行者在某个环节产生幻觉时,它并非简单地判定任务失败,而是去分析执行者出现误判的原因——是因为skill.md中的某条规则定义模糊,还是缺少了处理特定边缘情况的指令。
这段极其精准的自然语言诊断,就是 SkillOpt 提取出来的“文本梯度(Textual Gradient)”。
它不再是包含正负号和浮点数的张量矩阵,而是一句话。但这句自然语言和数学梯度一样,极其精准地指向了 skill.md中那个需要被修改的段落,指明了降低系统错误率的唯一方向。基于这种“文本级”的梯度反馈,优化器会对当前的skill.md提出修改建议,从而完成了一次从“错误反馈”到“策略更新”的完整闭环。
然而,我们必须承认,自然语言的修改存在着极大的不确定性。如果允许优化器顺着文本梯度的方向无限制地重写skill.md,极容易引发语义空间的逻辑崩塌,导致原本运行正常的指令结构失效,引发灾难性的能力衰退。为了驯服这种危险,SkillOpt 引入了两个至关重要的防守机制。
首先是“Bounded Edits”机制,即有边界限制的编辑。理解了这个概念,你就能明白系统是如何控制文本演进的。这相当于让大模型在深度学习过程中控制 Learning Rate。框架极其严格地限制了每次优化时允许修正的文本行数。这种被严格裁剪的编辑预算,迫使模型只能通过小步迭代的方式进行局部优化,绝不允许全面重构,从而确保了核心技能文档演进的绝对稳定性。
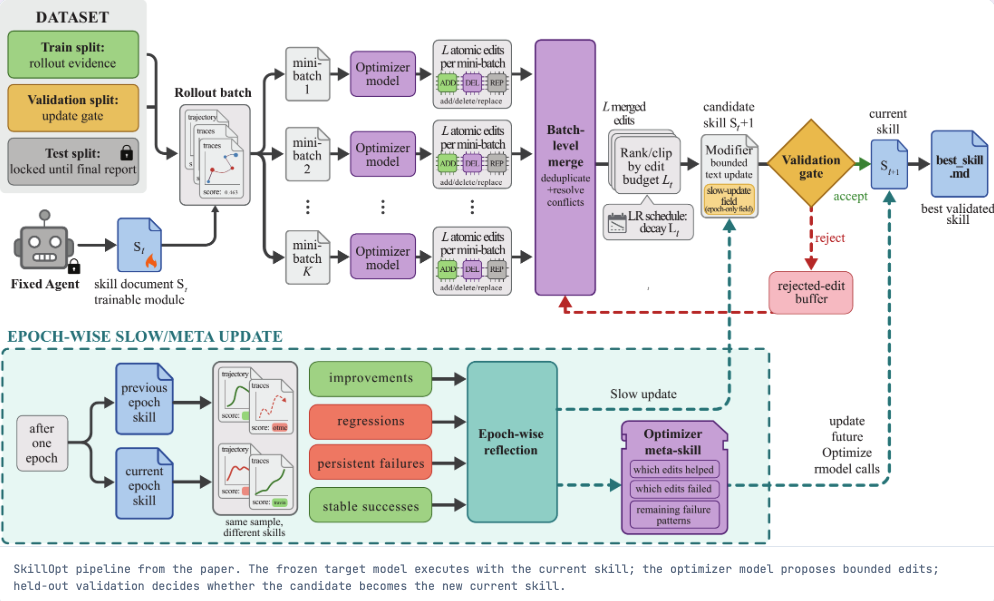
Figure 2:Bounded Edits的批处理流程。优化器通过生成“ADD、DEL、REP”的原子级编辑指令,并在合并后严格按照Edit Budget进行裁剪,确保单次修改不会导致能力崩塌。(图源:微软 SkillOpt 官方项目页)
其次,为了彻底杜绝任何形式的“负优化”,SkillOpt 还在流程的末端设计了极其严谨的 Validation Gate机制。任何经过有界编辑产生的新版skill.md,都不能直接上线,而是必须被送入一个独立于训练数据的保留测试集中进行验证。只有当新文档的实际运行得分严格超越了历史旧版本时,这次修改才会被正式合并到主分支中。这种类似于贪心算法的严密策略,从根本上保证了智能体系统能力的单调递增,绝不回退。
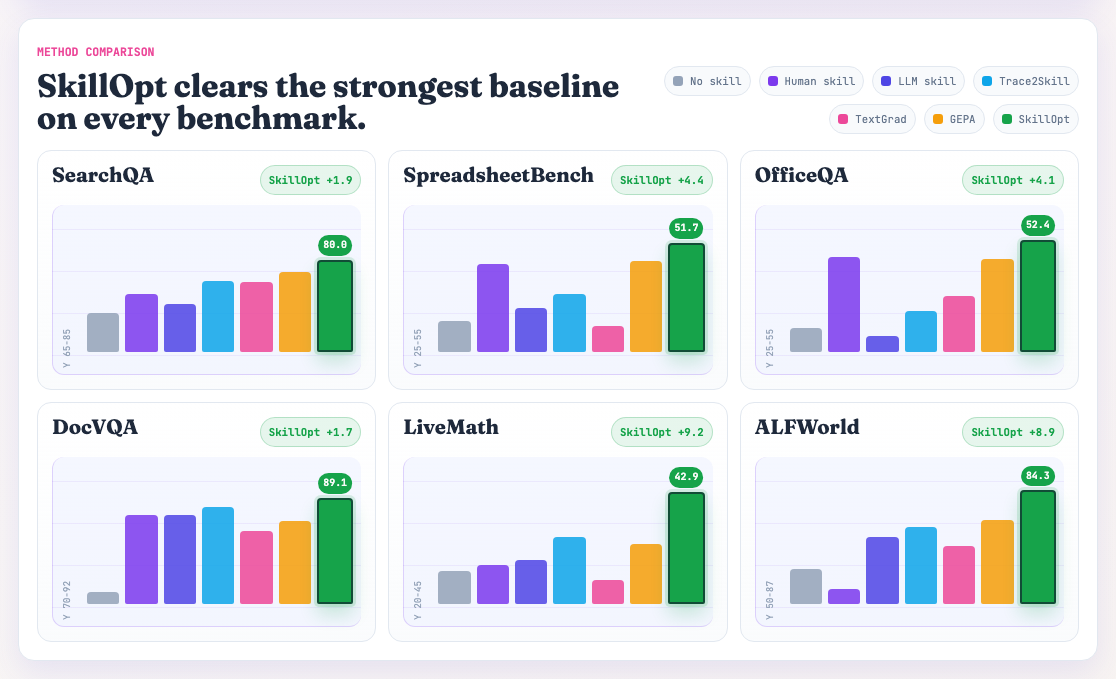
Figure 3:SkillOpt 在六大基准测试中的表现。在完全不修改底层模型权重的前提下,纯文本演进出的技能文档在各项复杂任务(如搜索、电子表格、数学推理等)中,均全面超越了目前最强的人工编写技能和其他基线算法。(图源:微软 SkillOpt 官方项目页)
当我们将视线从精妙的机制拉回工程落地的现实,SkillOpt 带来的最显著优势在于实现了“零推理期成本”。在开发和优化阶段,你虽然调度了模型去推导文本梯度、反思并修改文档,但一旦训练收敛,开发者最终拿到的产物仅仅是一份经过千锤百炼的纯文本文件。在实际部署生产环境时,这份skill.md只需要作为 System Prompt 输入给基座模型即可,完全不需要额外部署微调后的庞大权重体系。
更为深远的是,这种将核心业务逻辑沉淀为纯文本的方案,赋予了这些数字资产极强的跨代际迁移能力。无论底层的基座大模型在未来如何快速更迭,这些通过纯文本梯度优化系统化打磨出来的skill.md依然能够被直接复用,甚至在更强大的模型加持下发挥出更大的效能。SkillOpt 的出现不仅是对现有 Agent 优化范式的一次有效补充,更是在大模型时代,重新定义人类与 AI 协作边界的一次重要探索。
Reference:
SkillOpt: Executive Strategy for Self-Evolving Agent Skills (Microsoft Research)
项目主页:SkillOpt | Executive Strategy for Self-Evolving Agent Skills

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)