RISC-V AI处理器设计实战
RISC-V AI处理器设计实战
景芯团队专家老师1v1辅导学员,让您快速超越同龄人!景芯训练营主打文档+服务器实战,我们不卖视频,只提供免费导学视频!我们选取景芯HD6850项目中的RISC-V AI处理器进行实战。希望您成为公司的中流砥柱后,给景芯团队介绍design servie业务(有提成),共同进步!
02
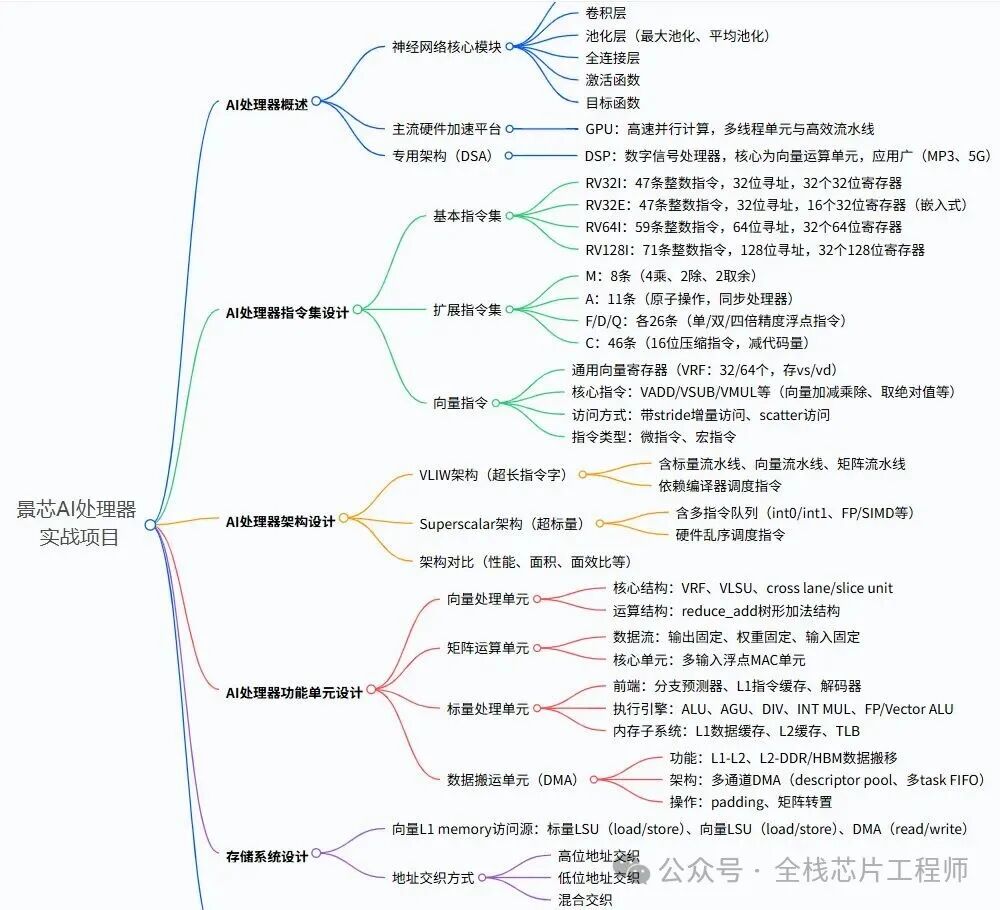
RISC-V AI处理器介绍
第一部分:AI处理器架构
1.1 AI计算芯片发展历程
-
从通用CPU到专用AI芯片的演进
-
不同AI工作负载对芯片架构的需求
-
云端与边缘AI处理器的差异
1.2 主流AI处理器架构对比
1.2.1 专用AI加速器(ASIC)
-
Google TPU架构深度解析
-
脉动阵列计算模式优势与局限
-
固定功能单元与可编程性平衡
1.2.2 可重构AI处理器(FPGA)
-
硬件可编程性在AI中的应用
-
动态重配置适应算法演进
-
能效与灵活性的折中设计
1.2.3 神经处理单元(NPU)
-
移动端AI加速器设计理念
-
功耗约束下的架构优化
-
端侧模型压缩与硬件协同
1.2.4 图形处理器(GPU)
-
从向量处理器到现代GPGPU的架构发展
-
GPU和GPGPU架构对比
-
GPGPU在AI和高性能计算中的应用场景
-
GPU同其他AI架构的对比及优势
1.2.5 图形处理器(GPU)架构选择
-
为什么选择GPGPU作为AI处理器基础
-
通用并行计算与AI工作负载的契合度
-
软件生态与开发生态优势
第二部分:GPGPU架构作为AI处理器的优势
2.1 AI工作负载特性与GPGPU架构匹配度
-
矩阵运算的并行化本质
-
神经网络层间的数据流并行性
-
训练与推理的差异化架构需求
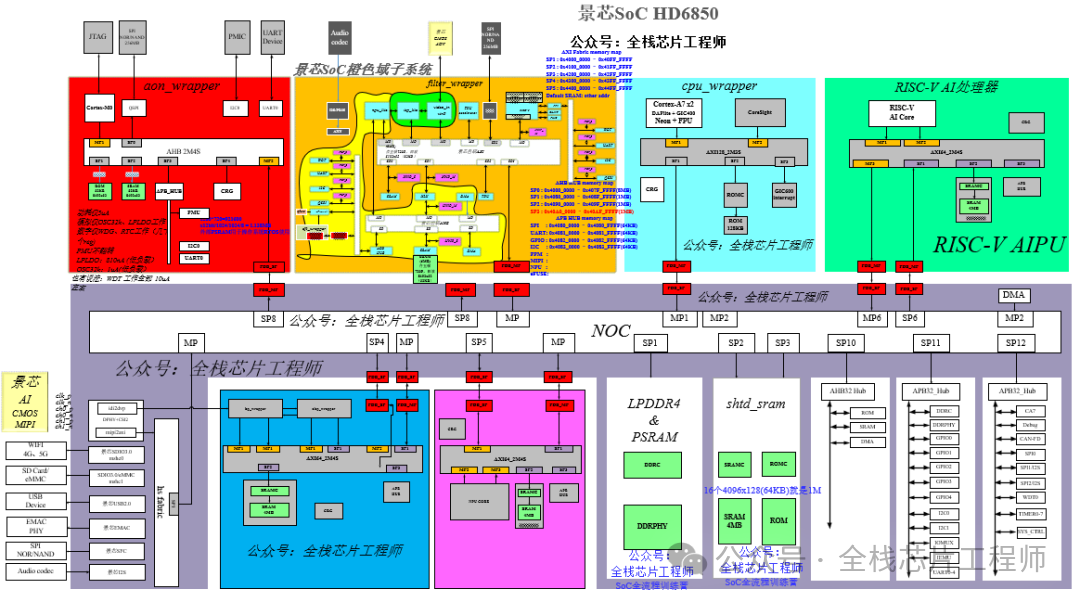
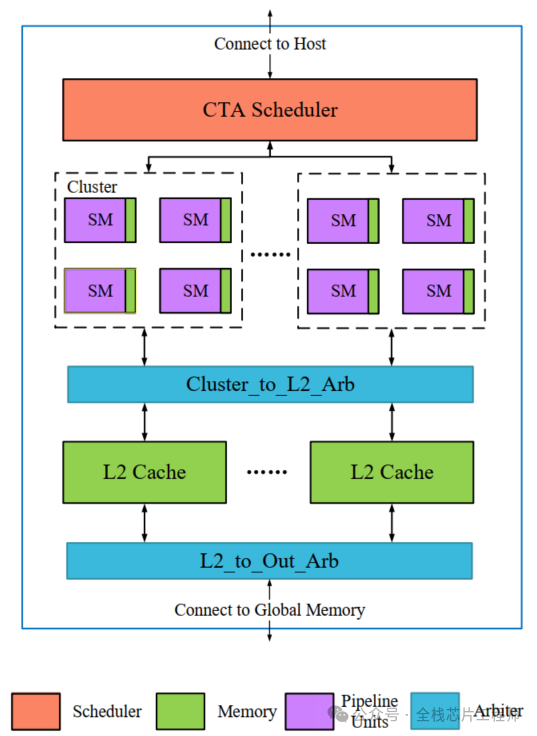
2.2 景芯定制化GPGPU核心架构解析
-
整体硬件架构框图与组件交互
-
流多处理器(SM)集群组织方式
-
多层次存储体系结构深度分析
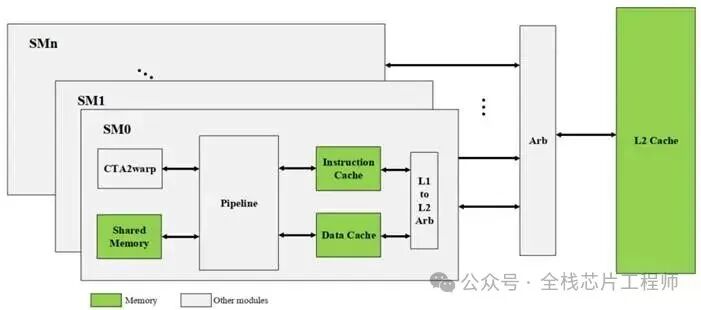
2.3 景芯定制化GPGPU特性
-
灵活的架构switch机制,可配置为NPU
-
混合精度计算硬件支持
-
张量核心专用运算单元
-
稀疏计算加速机制
第三部分:AI处理器微架构深度设计
3.1 并行计算架构优化
3.1.1 多层次并行度利用
-
数据并行与模型并行协同
-
指令级并行(ILP)优化技术
-
线程级并行(TLP)调度策略
3.1.2 AI专用执行单元设计
-
矩阵乘法单元优化实现
-
卷积计算专用数据通路
-
激活函数硬件加速
3.2 存储子系统AI优化
3.2.1 数据流优化架构
-
权重数据重用模式优化
-
特征图数据局部性利用
-
梯度计算存储访问模式
3.2.2 片上存储层次定制
-
共享内存AI工作负载优化
-
缓存替换算法AI特性适配
-
模型参数片上缓存策略
第四部分:AI专用指令集与编程模型
4.1 AI专用指令集扩展
-
张量运算指令设计
-
稀疏计算指令支持
-
量化运算指令实现
第五部分:芯片实现与验证
5.1 AI处理器RTL实现深度解析
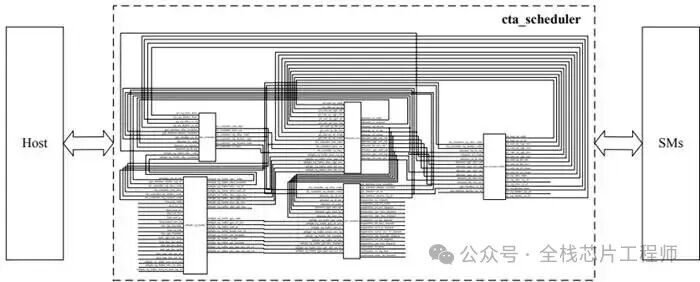
5.1.1 AI处理器RTL架构介绍
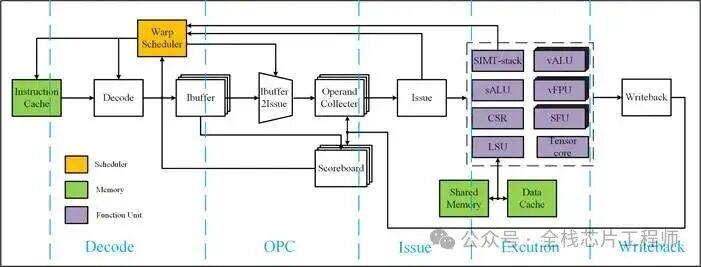
AI处理器RTL pipeline架构框图
5.1.2 关键AI计算模块1
-
Scheduler 模块
-
warp调度
-
寄存器堆
-
取指
-
译码
-
指令缓冲
-
发送、记分板
-
写回
-
L1 Cache
-
L2 Cache
5.1.2 关键AI计算模块2
-
ALU
-
vALU
-
vFPU
-
MUL
-
LSU
-
CSR
-
SFU
-
warp控制
-
Tensors core
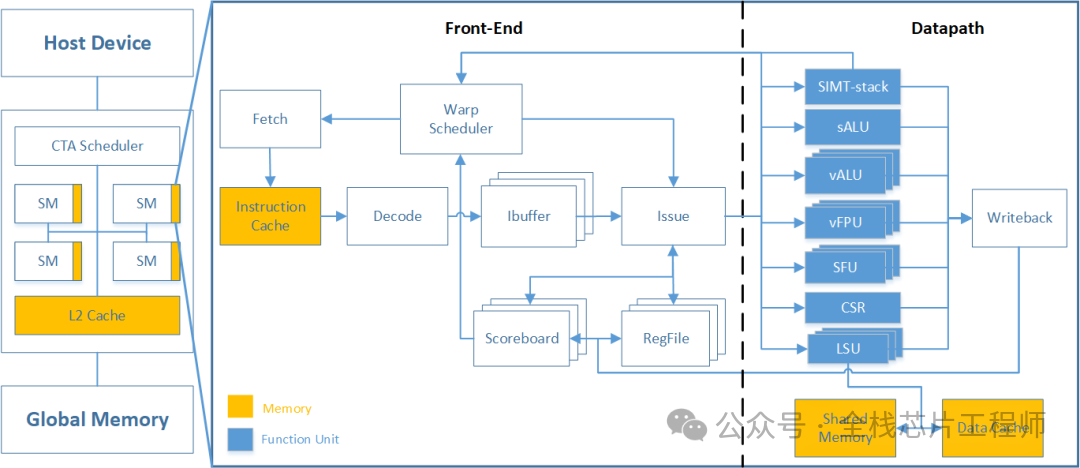
5.2 AI处理器专用验证方法
5.2.1 Simulation 仿真验证
-
仿真验证环境搭建
-
AI testcase开发
-
AI 性能精度体系验证
5.2.2 FPGA原型验证
-
FPGA选型
-
AI处理器RTL Porting
-
FPGA 仿真验证
-
性能功耗 profiling
Part.03
课程报名微信,扫描咨询我们吧

景芯SoC芯片全流程实战附属【知识星球】,一个包括设计、验证、DFT、后端全流程技术的交流平台,也是景芯学员的答疑平台!若您和我一样渴求技术,那欢迎扫下面二维码加入星球,共同进步!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)