高创新!MSD-BiGRUAttention:基于多尺度分解与GlobalAttention优化BiGRU的创新预测模型

往期精彩内容:
VMD + CEEMDAN 二次分解,BiLSTM-Attention预测模型-CSDN博客
基于麻雀优化算法SSA的预测模型——代码全家桶-CSDN博客
高创新 | CEEMDAN + SSA-TCN-BiLSTM-Attention预测模型-CSDN博客
独家原创 | 基于TCN-SENet +BiGRU-GlobalAttention并行预测模型-CSDN博客
独家原创 | BiTCN-BiGRU-CrossAttention融合时空特征的高创新预测模型-CSDN博客
CEEMDAN +组合预测模型(CNN-Transfromer + XGBoost)-CSDN博客
时空特征融合的BiTCN-Transformer并行预测模型-CSDN博客
独家首发 | 基于多级注意力机制的并行预测模型-CSDN博客
独家原创 | CEEMDAN-CNN-GRU-GlobalAttention + XGBoost组合预测-CSDN博客
暴力涨点! | 基于 Informer+BiGRU-GlobalAttention的并行预测模型-CSDN博客
重大更新!锂电池剩余寿命预测新增 CALCE 数据集_calce数据集-CSDN博客
基于 VMD滚动分解+Transformer-GRU并行的锂电池剩余寿命预测模型
快速傅里叶变换暴力涨点!基于时频特征融合的高创新时间序列分类模型-CSDN博客
基于CNN-BiLSTM-Attention的回归预测模型!-CSDN博客
独家原创 | CEEMDAN-Transformer-BiLSTM并行 + XGBoost组合预测-CSDN博客
涨点创新 | 基于 Informer-LSTM的并行预测模型-CSDN博客
一区直接写!CEEMDAN分解 + Informer-LSTM +XGBoost组合预测模型
基于Informer-SENet的光伏电站发电功率预测对比合集!6组对比预测模型,毕业论文、小论文直接写!
独家创新!基于ICEEMDAN+SHAP可解释性分析的锂电池剩余寿命预测高创新模型!
独家创新!基于Informer-BiGRUGATT-CrossAttention的预测模型
高创新!基于ICEEMDAN+MSCNN-BiGRU-Attention并行预测模型
独家首发!基于VMD滚动分解+Transformer-LSTM的并行预测模型
独家原创!基于特征—时间双图注意力与BiGRU全局注意力并行融合的高创新预测模型-CSDN博客
前言
本期提出一种面向风电功率预测的高创新模型:MSD-BiGRUAttention,即:基于多尺度分解与BiGRU全局注意力机制的风电功率预测模型。该模型以多变量风电时间序列为输入,首先通过多尺度分解模块将原始序列划分为不同时间粒度的 temporal patterns;随后,为每个尺度构建独立的 BiGRU-GlobalAttention 分支,用于提取不同尺度下的双向时序动态特征;最后,通过尺度注意力融合模块自适应分配不同尺度分支的贡献权重,并输出未来风电功率预测结果。
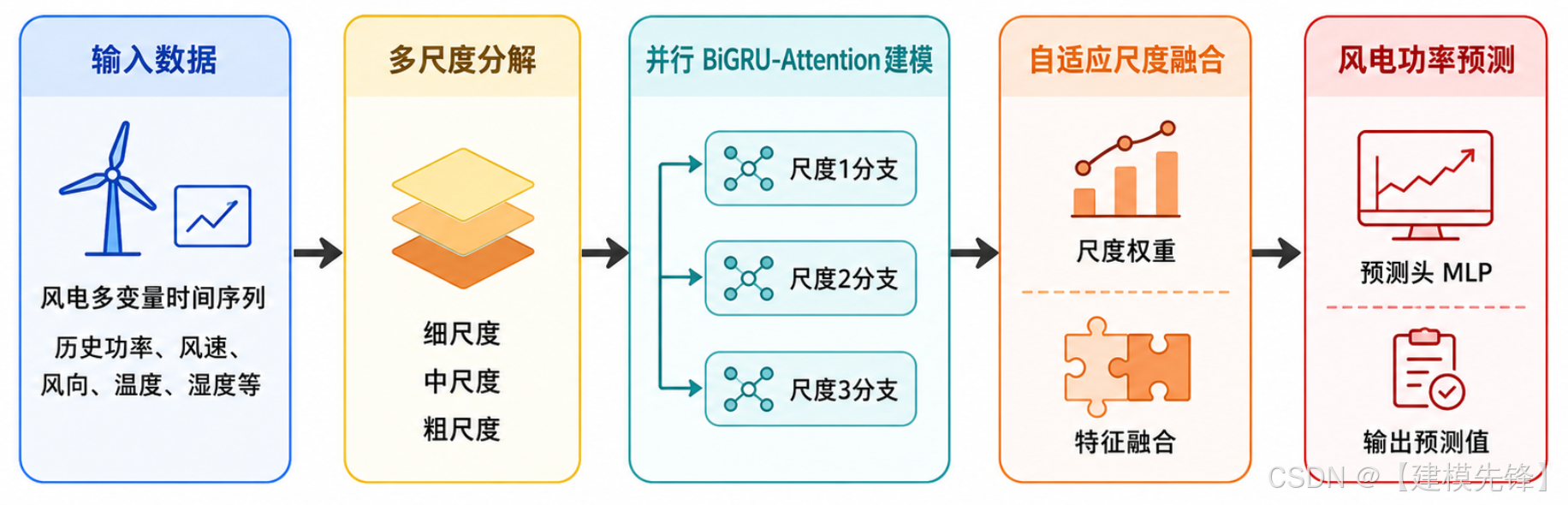
模型核心思想可以概括为:
多尺度分解 → 并行BiGRU-Attention建模 → 自适应尺度融合 → 风电功率预测
该模型不仅能够捕获风电功率序列中的短期波动、中期变化和长期趋势,还能够通过 GlobalAttention 机制突出关键历史时间步,从而提升模型对多特征序列时域特征的感知能力。(创新点还未发表!)
我们同时提供详细的资料、解说文档和视频讲解,包括如何替换自己的数据集、参数调整教程等,代码逐行注释,参数介绍详细:
● 数据集:某风电场风电功率数据集、电力数据集、风速数据集等
● 环境框架:python 3.11 pytorch 2.1 及其以上版本均可运行
● 模型分数:测试集 0.98
● 使用对象:论文需求、毕业设计需求者
● 代码保证:代码注释详细、即拿即可跑通。
1 创新模型介绍
1.1 模型整体流程
MSD-BiGRUAttention 的整体流程如下:
(1)输入多变量时间序列:
X ∈ R^{B×L×C}
其中:
-
B 表示 batch size
-
L 表示历史窗口长度
-
C 表示输入特征变量数
(2)模型首先进行多尺度分解:
-
Scale 1:原始细尺度序列
-
Scale 2:中尺度下采样序列
-
Scale 3:粗尺度下采样序列
随后,每个尺度分别进入独立的 BiGRU-GlobalAttention 分支:
-
Scale 1 → BiGRU-Attention
-
Scale 2 → BiGRU-Attention
-
Scale 3 → BiGRU-Attention
(3)每个分支输出一个尺度级特征表示,然后通过 ScaleAttentionFusion 计算不同尺度的重要性权重,并进行自适应融合。最终,融合特征输入线性预测头,输出未来风电功率。
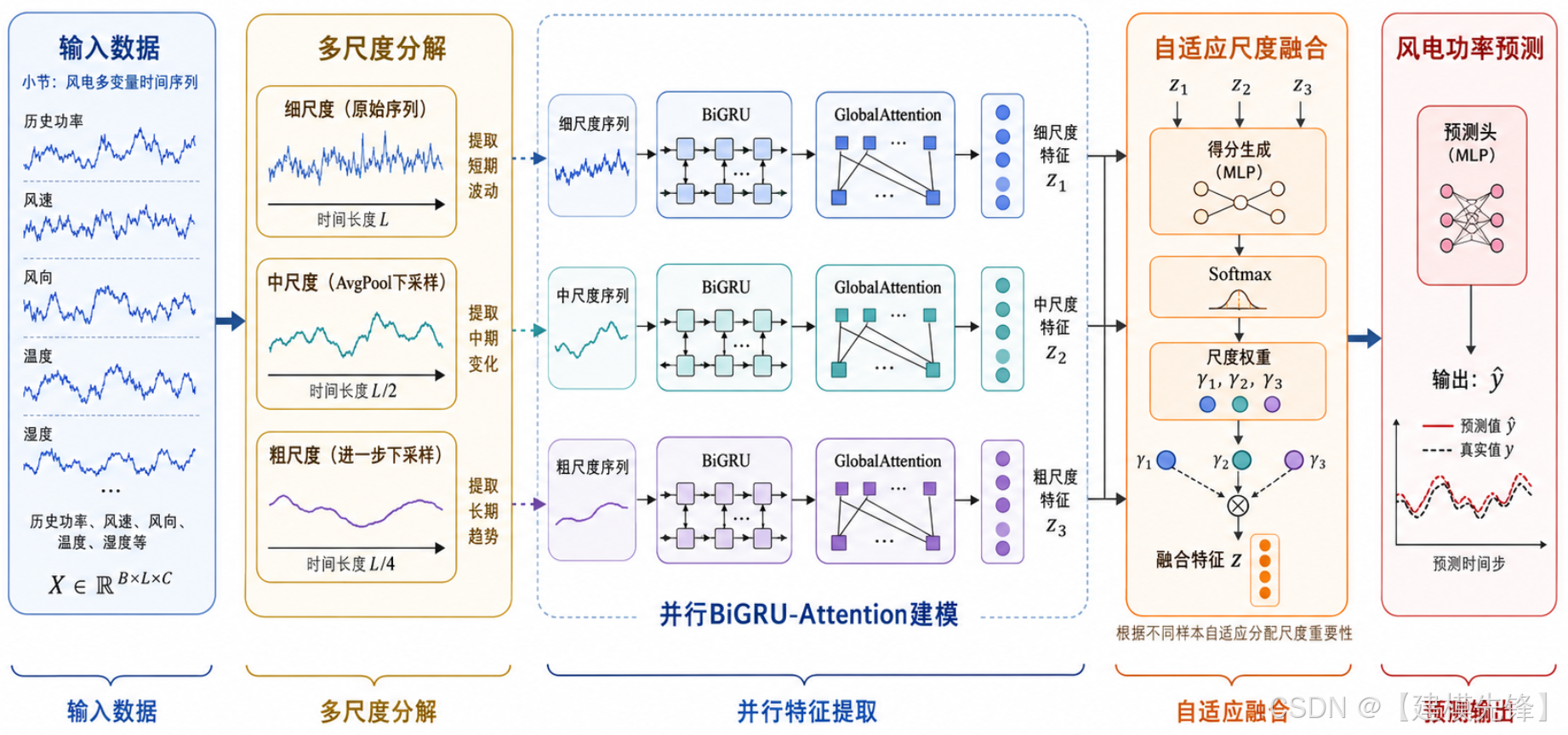
1.2 核心模块一:MultiScaleDecomposition 多尺度分解模块
MultiScaleDecomposition 是模型的第一步,主要用于将原始多变量时间序列划分为不同时间尺度的表示。该模块沿时间维度对输入序列进行平均池化下采样,得到不同时间粒度的 temporal patterns。例如,输入序列长度为 24,设置 3 个尺度、下采样率为 2,则得到:
-
Scale 1:[B, 24, C]
-
Scale 2:[B, 12, C]
-
Scale 3:[B, 6, C]
也就是说,模型同时保留原始细粒度序列、中等尺度序列和粗粒度趋势序列。
1.3核心模块二:多尺度并行 BiGRU-GlobalAttention 分支
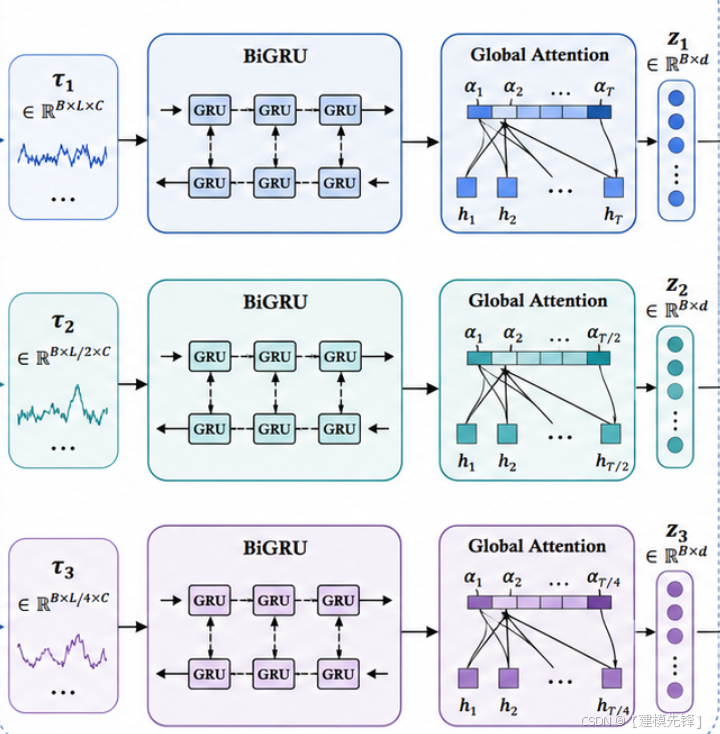
不同尺度的序列长度和变化特征不同。细尺度序列保留更多局部细节,适合捕获短期波动;粗尺度序列经过下采样后更平滑,适合捕获长期趋势。如果将所有尺度过早融合,可能会造成尺度信息混杂。因此,本模型为每个尺度建立独立 BiGRU 分支,使每个分支专门学习该尺度下的时序动态。GlobalAttention是一种用于加强模型对输入序列不同部分的关注程度的机制。在 BiGRU 模型中,全局注意力机制可以帮助模型更好地聚焦于输入序列中最相关的部分,从而提高模型的性能和泛化能力。在每个时间步,全局注意力机制计算一个权重向量,表示模型对输入序列各个部分的关注程度,然后将这些权重应用于 BiGRU 输出的特征表示,通过对所有位置的特征进行加权,使模型能够更有针对性地关注重要的时域特征, 提高了模型对多特征序列时域特征的感知能力。
1.4核心模块三:ScaleAttentionFusion 尺度自适应融合
ScaleAttentionFusion 会为每个尺度分支计算一个重要性权重:
γ1, γ2, γ3
然后对各尺度表示进行加权融合:
z = γ1z1 + γ2z2 + γ3z3
其中:
γ1 + γ2 + γ3 = 1
该机制使模型能够根据当前样本状态,自适应判断不同尺度的重要性。也就是说,这里的“自适应”主要体现在两个层面:
-
第一,GlobalAttention 在每个尺度内部自适应选择关键时间步;
-
第二,ScaleAttentionFusion 在尺度之间自适应选择更重要的时间粒度。
这使模型能够同时具备尺度内注意力和尺度间注意力。
2 电力变压器数据集介绍
2.1 导入数据
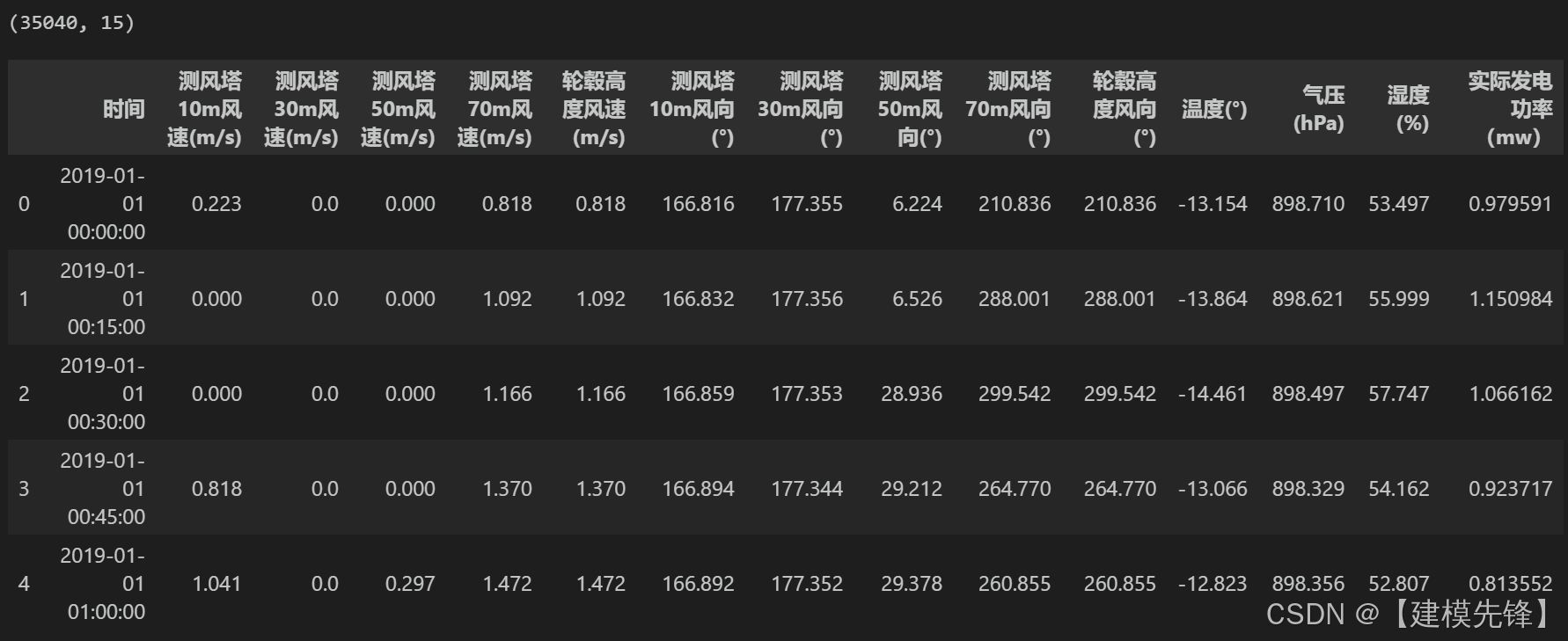
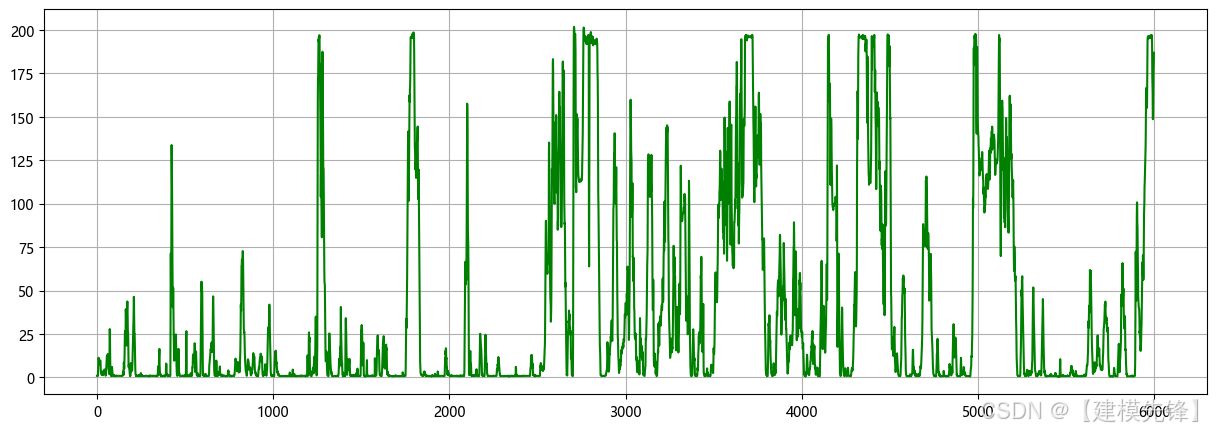
风电功率数据集一共35040个样本,15个特征,取前6000条数据进行可视化:
2.2 数据集制作与预处理
详细介绍见提供的文档!
3 基于MSD-BiGRUAttention的高创新预测模型
3.1 定义MSD-BiGRUAttention预测网络模型
3.2 设置参数,训练模型
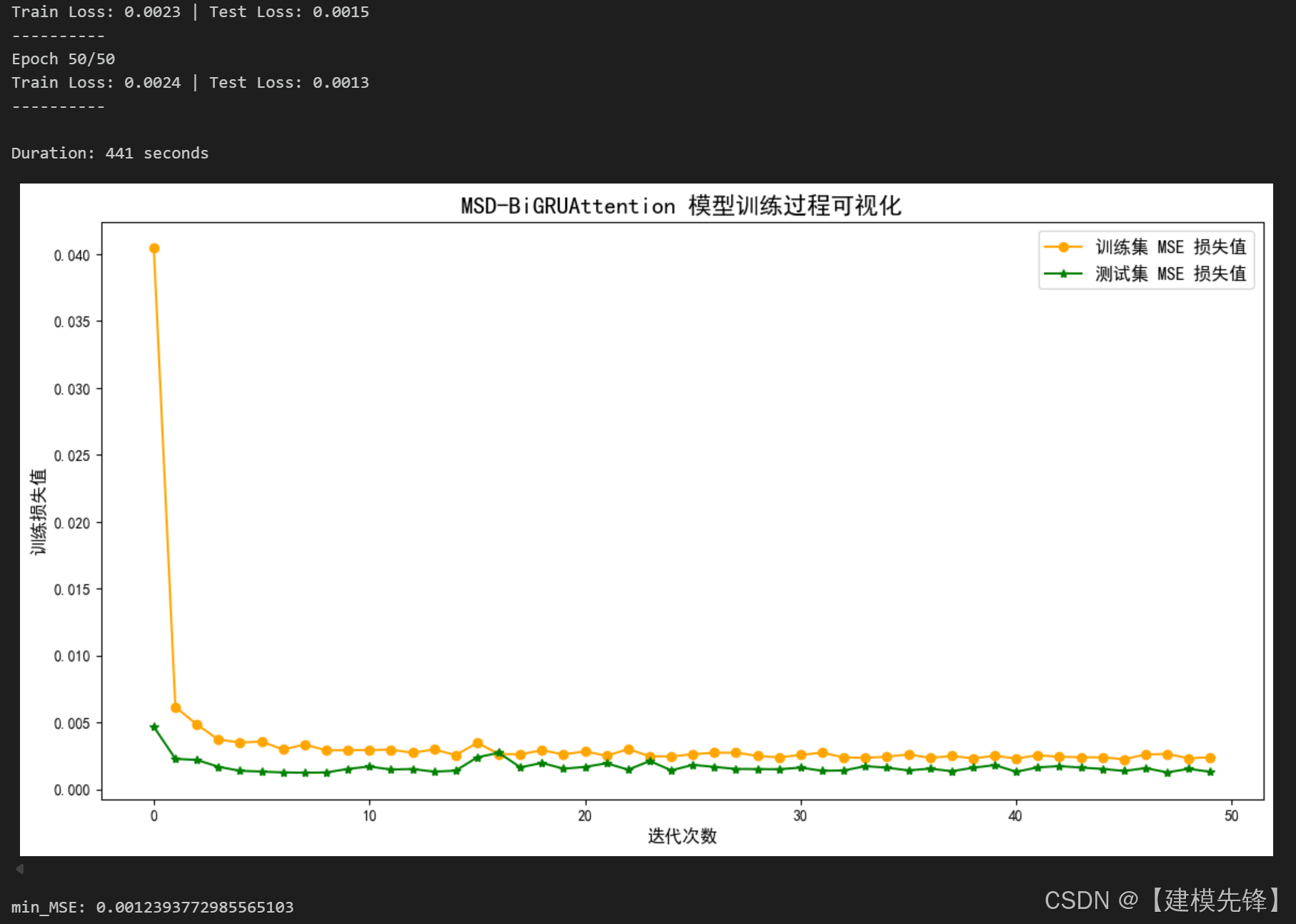
50个epoch,MSE 为0.001239,MSD-BiGRUAttention预测效果显著,该模型通过 MultiScaleDecomposition 提取不同时间尺度的多变量 temporal patterns,通过 BiGRU 捕获每个尺度下的双向时序动态,通过 GlobalAttention 强化关键历史时间步的贡献,并通过 ScaleAttentionFusion 自适应融合不同尺度信息。整体来看,该模型具有以下优势:
● 能够捕获短期扰动、中期变化和长期趋势
● 能够增强多特征序列的时域特征感知能力
● 能够自适应判断不同尺度的重要性
● 结构清晰,参数可控,容易训练
● 注意力权重可视化,解释性较强
4 结果可视化和模型评估
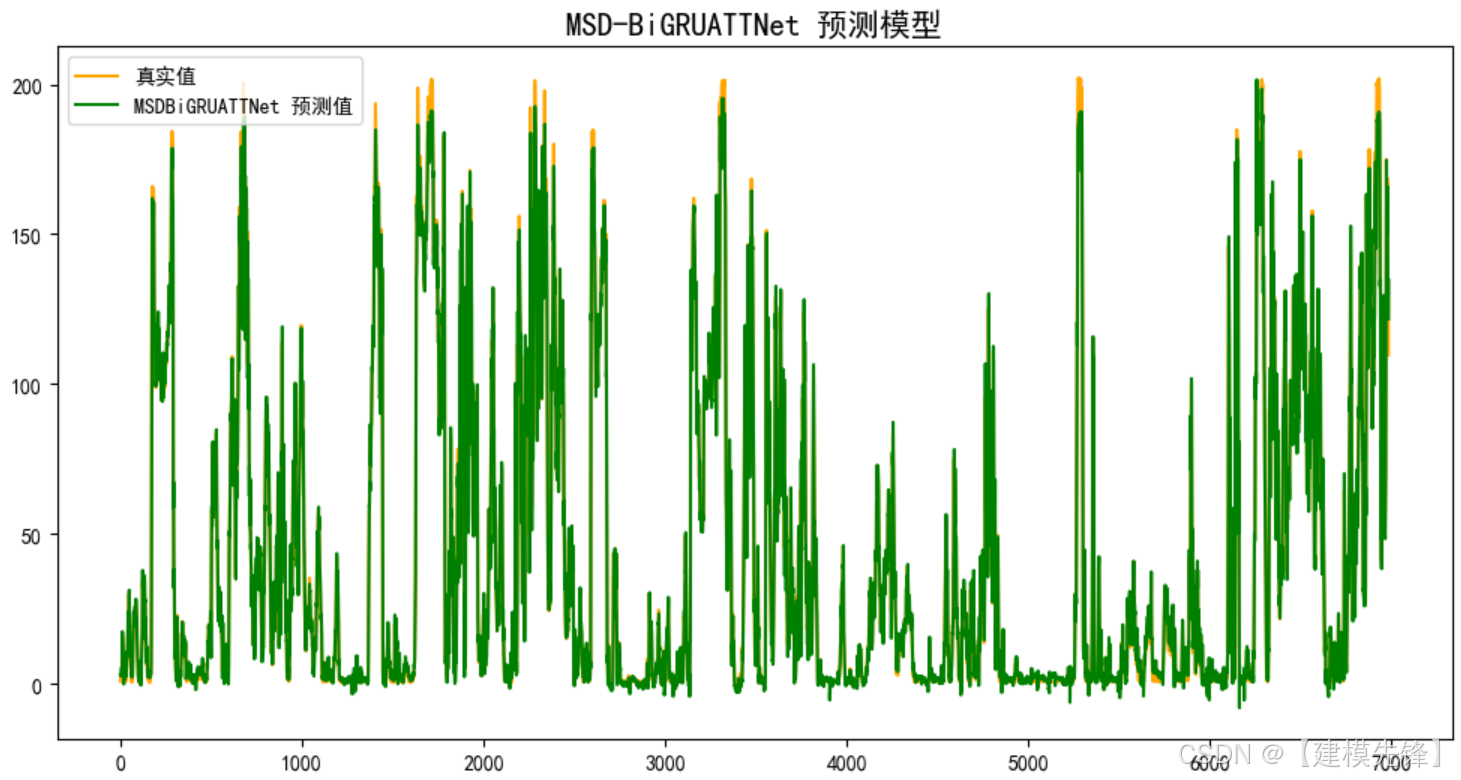
4.1 预测结果可视化
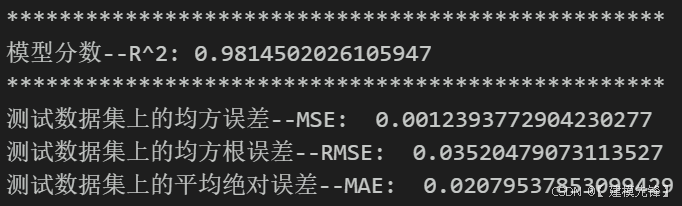
4.2 模型评估
MSD-BiGRUAttention 不仅适用于风电功率预测,也可推广到光伏功率预测、电力负荷预测、设备状态预测、变压器油温预测等多变量时间序列预测任务。
5 代码、数据整理如下:
点击下方卡片获取代码!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)