具身智能-VLA综述
原论文:《A Survey on Vision-Language-Action Models for Embodied AI》
一 概述
具身智能不同于我们使用的对话AI或者生成式AI,如对话问答、生成图片等,这些AI应用是在抽象空间中进行的,而具身智能需要在现实物理环境中进行交互,控制现实世界中的智能载体去完成指定的任务,常见的载体包括汽车(自动驾驶)、机器人等,具身智能目前被视为通往通用人工智能(AGI)的基础,在具身智能的所有载体中,近几年备受瞩目的是机器人。

强化学习的主要目标就是找到最优的策略π:

强化学习方法可以分为两大类:

以往的机器人控制算法一般是通过强化学习得到,这种方式面临以下问题:

为了解决这些问题,提出了“模仿学习”:

近几年随着大语言模型、多模态模型的发展,提出了一种新的模型方法:VLA模型,这类模型能够直接根据输入的视觉信息(V)、语言指令(L),生成机器人接下来需要执行的动作(A)。VLA这个概念最早由谷歌在RT-2模型中提出,相比于以往每个任务都需要通过强化学习学习最优控制策略的方式,VLA具有更高的泛化性,能够适应不同类型的复杂任务,是目前具身智能领域主流的研究方向,也是通往通用任务机器人的关键技术,基于VLA的机器人控制方式如下:

VLA模型的通用结构如下图所示:
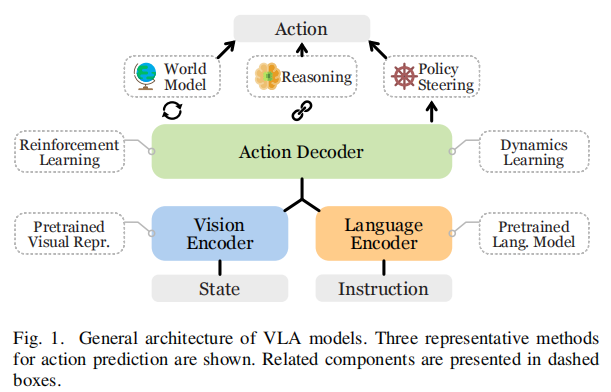
-
Vision Encoder:视觉编码器,负责对当前机器人感知到的视觉信息如通过机器人摄像头采集到的当前客厅图像,进行编码,
-
Language Encoder:语言编码器,负责对当前机器人接收到的命令,如“打开冰箱门”,进行编码
-
Action Decoder/Action:融合视觉编码器和语言编码器的结果,进行动作解码,生成机器人接下来应该执行的动作Action,如“机械臂从坐标(100,100,100)逆时针旋转90度移动到坐标(100,200,300),并且打开机械臂”
一般使用7元组(x,y,z,roll,pitch,yaw,gripper)表示接下来要进行的动作,这个7元组也称为末端执行器位姿:

具体每个末端位姿指令应该怎么执行,是通过机器人中的逆运动学求解器进行求解的,然后机器人根据求解得到的结果,控制电机等部件执行,这些就是偏向于机器人底层的机械控制了,与高层VLA算法无关。
目前VLA的研究主要集中于以下三个方面:
1)基础组件研究:研究如何进一步提升VLA基础组件,如视觉编码器、语言编码器的准确性
2)VLA模型研究:研究如何更好的结合视觉编码器和语言编码器这些基础组件的输出,产生更加准确的机器人执行动作指令
3)任务规划研究:研究如何将人类输入的复杂任务进行拆分,变成更适合机器人执行的具体子任务,提高任务执行的准确性,比如人类输入“帮我打扫房间”这个简单指令,看似简单,但其实包含目前房间怎么样、接下来应该怎么打扫房间、每个房间具体应该怎么打扫、打扫到什么程度算打扫完成等隐含内容,任务规划需要从人类输入的指令中,准确解析、分解出这些子任务
接下来分别介绍这三方面的相关工作,每节最会都会给出所介绍方法的对应原论文,感兴趣的可以自行查阅、下载。
二 基础组件
2.1 相关介绍
强化学习是具身智能方法的基础,并且VLA也可以通过强化学习进一步提升自己,强化学习中的“轨迹”天然具有时序特性,非常适合使用Transformer架构进行处理,这方面的工作包括Decision Transformer、Trajectory Transforme、Gato、π-0.6。
得益于语言大模型领域强化学习方法的应用,比如RLHF方法(RLHF利用强化学习对齐大模型的输出到人类的偏好,让大模型的输出更符合人类语言的习惯),VLA领域也在借鉴这些方法的思想提升自身。SEED利用RLHF方法解决机器人强化学习过程中的稀疏奖励问题,并通过人类验证来提升机器人操作的安全性。Reflexion提出了一种语言强化学习框架,该框架用语言反馈替代强化学习中的模型权重更新,使其适用于规划同样以语言形式进行的具身智能决策任务,Eureka表明,大语言模型能够为具身智能体设计奖励函数,其表现优于人类专家设计的奖励函数。
VLA模型中的视觉编码器会直接影响VLA模型的最终效果,因为它负责提供当前机器人感知状态的关键信息,如物体类别、位置等,有大量研究工作聚焦于提升视觉模型的有效性。
CLIP模型在VLA中被广泛使用,CLIP的训练目标是区分出输入的<图像,文本描述>batch中,真正匹配的<图像,文本描述>,CLIP在4亿规模的<图像,文本描述>数据集WIT上进行了训练,大规模数据的预训练使CLIP具有较强的图文关系理解能力,详细介绍可以看:多模态-2 CLIP。
R3M针对输入视频提出了两个预训练学习目标:时间对比学习(CL)和视频-语言对齐,时间对比学习的目标是最小化时间上邻近视频帧之间的距离,最大化时间上相距较远视频帧之间的距离,该目标旨在创建能够捕捉视频序列时间关系的特征提取,视频-语言对齐旨在学习视频是否与输入的语言指令相匹配,该目标增强了视频编码的语义相关性。
MVP将计算机视觉中的掩码自编码器(MAE)方法应用于机器人学习,MAE对输入到ViT模型的一部分patch进行mask处理,并训练模型以重建这些mask的patch,详细介绍可以看:计算机视觉Transformer-3 自监督模型。这种方法与BERT中使用的掩码语言建模技术非常相似,属于自监督训练范畴。
RPT的预训练策略不仅侧重重建视觉输入,还侧重机器人动作和本体感受状态之间的关联。
Voltron将语言引导生成融入MAE学习目标中,该模型采用Transformer结构,在语言条件引导下的掩码图像重建和从掩码图像生成对应语言描述两个训练任务之间交替进行训练,这种训练方式增强了模型对于语言与视觉模态之间的对齐能力。
DINOv2采用自蒸馏框架,提出了一种新的自监督训练范式,其性能超越了MAE。DINOv2中教师网络和学生网络接收同一输入图像的不同视图,并匹配其编码后的特征表示,学生网络通过梯度下降进行更新,而教师网络则作为学生网络的指数移动平均值来维护,详细介绍可以看:计算机视觉Transformer-3 自监督模型。
I-JEPA来源于LeCu提出的联合嵌入预测架构,它通过比较图像块patch的嵌入向量来构建一个“原始”的内部世界模型,与使用裁剪图像的DINO不同,I-JEPA采用掩码图像块,此外,它与MAE也不同,因为它是一种非生成式的方法。
Theia提出将各种视觉基础模型蒸馏到单一模型中,通过融合分割、深度、语义等多种视觉信息,在训练数据更少、模型规模更小的情况下,性能优于以往的视觉编码模型。
视频可以看作是一个图像序列,可以通过拼接每一帧图像的编码表示来对视频进行整体编码表示,也可以引入视频的时序等信息进行整体编码表示,NeRF是这类方法的代表,近期出现的3D Gaussian Splatting(3D-GS)在视觉质量和渲染速度上均超越了NeRF。此外,许多视频还包含音频,可为机器人策略选择提供额外的重要线索。
动力学学习(Dynamics Learning)是机器人学习的基础,它让机器人从“只会看”世界,变成“理解世界怎么运动”,结合之前所说的强化学习、模仿学习和语言条件化策略,就构成了现代机器人学习的完整技术栈。

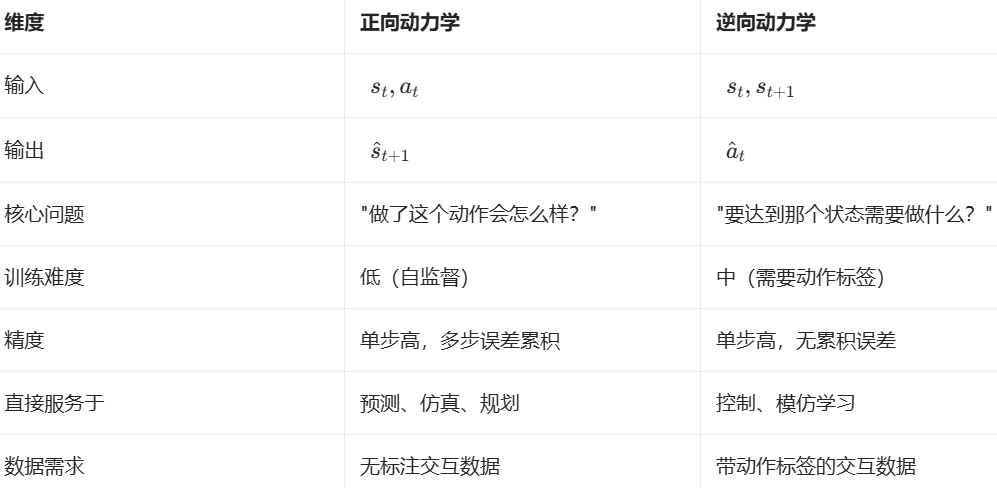
动力学分为正向动力学(Forward Dynamics)和逆向动力学(Inverse Dynamics):


Vi-PRoM动力学方法提出了三种不同的预训练目标:
1)对比自监督学习:让模型区分不同的输入视频
2)时间动态学习:让模型恢复打乱的视频帧
3)伪标签图像分类
通过与先前的预训练方法进行全面比较,Vi-PRoM证明了其在行为克隆(BC)和强化学习PPO方法上的有效性。
MIDAS在其预训练过程中引入了一个逆动力学预测任务,其目标是训练模型从观测中预测动作,该任务被构建为一个运动跟随任务,这种方法增强了模型对环境转换动力学的理解。
SMART提出了一种预训练方案,涵盖三个不同的目标:前向动力学预测、逆向动力学预测以及随机掩码后见控制。前向动力学预测任务涉及预测下一个潜在状态,而逆向动力学预测任务则需要预测前一个动作。在后见控制中,整个控制序列被作为输入,其中部分动作被掩码,模型被训练以恢复这些被掩码的动作。前两个动力学预测任务的引入有助于捕捉局部和短期的动态,而第三个任务旨在捕捉全局和长期的时间依赖关系。
MaskDP使用掩码决策预测任务进行训练,其中状态和动作均被掩码以进行重建,旨在使模型能够理解正向和逆向动力学,与先前诸如BERT或MAE之类的掩码建模方法不同,MaskDP可以直接以零样本方式应用于下游任务。
PACT引入了一种建模状态-动作转换的预训练目标,它以状态和动作序列作为输入,并以自回归方式预测每个接下来的状态和动作,利用这个预训练模型充当动力学模型,随后可针对各种下游任务进行微调,例如定位、建图和导航。
VPT提出了一种视频预训练方法,该方法利用无标注的互联网数据,为《我的世界》游戏预训练一个基础模型,该方法首先使用少量有标注数据训练一个逆动力学模型,然后利用该模型为互联网视频打上标签。随后,这些新生成的标注数据被用于通过行为克隆(BC)训练基础模型。这种方法遵循半监督模仿学习的方式,通过这一过程,该模型在众多任务中展现出了人类级别的性能。
世界模型(World Models)是目前具身智能领域最具革命性的方法,不同于以往的强化学习方式,世界模型让机器人能够像人类一样,在行动之前先在脑子里"想一想",预测不同动作会产生的后果,然后选择最优的方案执行。

世界模型可以和强化学习进行结合:


正向动力学是"知道做了这个动作会怎么样",而世界模型是"不仅知道会怎么样,还能在脑子里把整个过程都演一遍,然后决定怎么做"。
世界模型Dreamer采用三个主要模块来构建潜在动力学模型:
1)表征模型,负责将图像编码为潜在状态
2)转移模型,用于捕捉潜在状态之间的转移
3)奖励模型,用于预测与给定状态相关的奖励
在演员-评论家强化学习框架下,Dreamer利用动作模型和价值模型,通过在所学动力学中传播解析梯度,借助想象来学习机器人行为。在此基础上,DreamerV2引入离散潜在状态空间以及改进的目标函数进行优化。DreamerV3将其关注点扩展到具有固定超参数的更广泛领域世界模型,DayDreamer将此方法应用于执行现实世界任务的物理机器人中。
IRIS采用类似GPT的自回归Transformer作为其世界模型的基础,并使用VQ-VAE作为视觉编码器,利用由世界模型从真实观测中展开生成的想象轨迹序列来进行策略训练。
大语言模型(LLMs)通过大规模预训练数据学习,蕴含丰富的关于物理世界的常识性知识,这促使许多方法尝试利用这些知识来改进VLA模型。
DECKARD通过提示词,让大语言模型生成以有向无环图表示的抽象世界模型,这些模型专门为《我的世界》中的物品合成任务量身定制。DECKARD会在两个阶段之间迭代:在梦境阶段,它根据抽象世界模型的引导,采样一个任务子目标;在清醒阶段,DECKARD执行该子目标并通过与游戏的交互来更新抽象世界模型,这种引导式方法使得DECKARD在《我的世界》物品合成上的速度比缺乏此类引导的基线方法更快。
RAP将大语言模型既充当预测动作的智能体,又充当提供状态转移分布的世界模型,与以往的思维链(CoT)提示方法不同,RAP结合蒙特卡洛树搜索(MCTS)以实现结构化规划,允许大语言模型逐步构建推理树。这种推理策略帮助 RAP 找到一条平衡探索与利用的高回报路径。
与大语言模型提示,产生的文本形式世界模型不同,视觉世界模型能够生成未来状态的图像、视频或3D场景,与物理世界的契合度更高。这些模型还可进一步用于生成新的状态-动作轨迹,自Open AI的Sora展现出世界模拟能力以来,视觉世界模型已获得越来越多的关注。Genie引入了一种新的生成模型,称为生成式交互环境,它由三个主要组件构成:
1)时空视频分词器
2)自回归动力学模型
3)潜在动作模型
通过在无标注视频上进行无监督训练之后,Genie允许用户以逐帧的方式与生成环境进行交互。
3D-VLA提出了一个能够生成目标的3D世界模型,除了二维图像,它还能够处理3D视觉输入,如深度图和点云,然后通过扩散模型根据用户查询,生成一个目标状态(可以是图像或3D点云),生成的目标状态随后可用于引导机器人控制。
UniSim基于真实世界的交互视频构建了一个生成模型,它能够模拟高层级和低层级动作的视觉结果,这些结果随后可以被用作训练具身智能体的新数据经验。
“推理”是大语言模型的一项关键涌现能力,这一点在思维链(CoT)方法中得到了充分体现。在具身智能领域,研究人员正在探索如何利用思维链推理来优化机器人的决策过程。
ThinkBot利用思维链弥补稀疏人类指令中缺失的动作描述,从而增强指令的连贯性,提高机器人在困难任务中的行动成功率。
RAT将思维链与检索增强生成(RAG)相结合,减轻幻觉问题,从而改进行动规划。
OpenVLA在预测动作之前,会对计划、子任务、运动和视觉特征进行思维链推理。通过这种多步推理,而非VLA模型学习得到的“肌肉记忆”,它能够在不额外增加训练数据的情况下,提高在不同泛化任务上的成功率。
CoT-VLA为视觉-语言-动作模型(VLAs)引入了视觉思维链推理。
2.2 方法名(原论文名)
Decision Transformer(Decision transformer: Reinforcement learning via sequence modeling)
Trajectory Transformer(Offline reinforcement learning as one big sequence modeling problem)
Gato(A generalist agent)
π-0.6(π*0.6: a VLA that learns, from experience)
SEED(Primitive skill-based robot learning from human evaluative feedback)
Reflexion(Reflexion: language agents with verbal reinforcement learning)
Eureka(Eureka: Human-level reward design via coding large language models)
R3M(R3M: A universal visual representation for robot manipulation)
VIP(VIP: towards universal visual reward and representation via value-implicit pre-training)
MVP(Real-world robot learning with masked visual pre-training)
RPT(Robot learning with sensorimotor pre-training)
Voltron(Language-driven representation learning for robotics)
I-JEPA(Self-supervised learning from images with a joint-embedding predictive architecture)
Theia(Theia: Distilling diverse vision foundation models for robot learning)
Vi-PRoM(Exploring visual pre-training for robot manipulation: Datasets, models and methods)
MIDAS(Mastering robot manipulation with multimodal prompts through pretraining and multi-task fine-tuning)
PACT(PACT: perception-action causal transformer for autore-
gressive robotics pre-training)
PACT(PACT: perception-action causal transformer for auto regressive robotics pre-training)
VPT(Video pretraining:learning to act by watching unlabeled online videos)
Dreamer(Dream to control: Learning behaviors by latent imagination)
DreamerV2(Mastering atari with discrete world models)
DreamerV3(Mastering diverse domains through world models)
DayDreamer(Daydreamer: World models for physical robot learning)
IRIS(Tansformers are sample efficient world models)
DECKARD(Do embodied agents dream of pixelated sheep: Embodied decision making using language guided world modelling)
RAP(Reasoning with language model is planning with world model)
Genie(Genie: Generative interactive environments)
3D-VLA(3d-vla: A 3d vision-language-action generative world model)
UniSim(Learning interactive real-world simulators)
ThinkBot(Tinkbot: Embodied instruction following with thought chain reasoning)
RAT(RAT: retrieval augmented thoughts elicit context-aware reasoning in long-horizon generation)
OpenVLA(Openvla: An open-source vision-language-action model)
CoT-VLA(Cot-vla:Visual chain-of-thought reasoning for vision-language-action models)
三 VLA模型
VLA模型要解决的问题是:在给定了视觉感知信息、用户指令信息、过往状态和动作信息的前提下,如何得到当前的最优策略,产生接下来要执行的动作。在VLA出现之前,机器人是一个任务一个模型:抓取有抓取的模型,开门有开门的模型,导航有导航的模型,而VLA是第一个真正通用的机器人控制范式,同一个模型可以通过不同的语言指令,执行成百上千个不同任务。
VLA模型的数学形式化定义如下:


目前大部分VLA模型是预测“末端执行器位姿”,而不是真实直接控制机器人的关节,这有以下几方面原因:

这种方式:

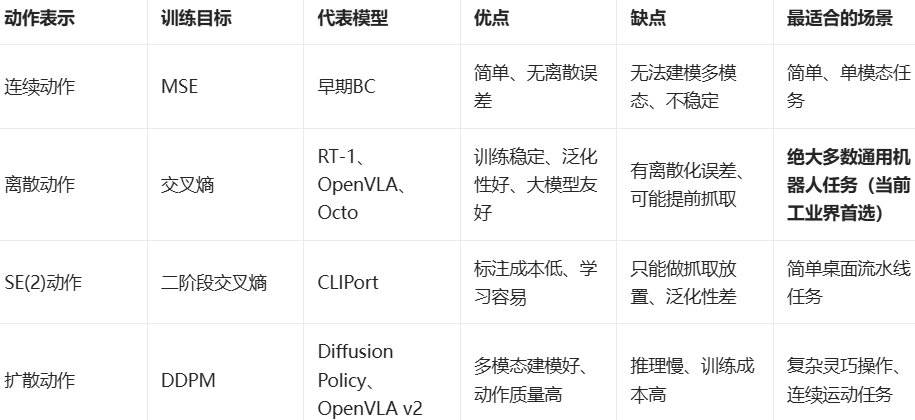
目前VLA常用的是以下4种训练方式:




3.1 相关介绍
Gato提出了一种模型,该模型可以玩雅达利(Atari)游戏、为图像添加描述以及堆叠积木,且所有这些都仅使用同一套模型参数。这一成就得益于一种统一的标记化方案,该方案协调了不同任务和领域之间的输入与输出,因此Gato能够同时训练不同的任务。
RoboCat提出了一种自我改进流程,旨在使智能体能够仅通过少至 100 次演示就快速适应新任务。这一自我改进流程迭代地对模型进行微调,并利用微调后的模型自我生成新数据。RoboCat 建立在 Gato 模型之上,整合了 VQ-GAN 图像编码器。在训练期间,RoboCat 不仅预测下一个动作,还预测未来的观测结果。通过在多任务和多具身(multiembodiment)设置下的模拟环境和真实环境中进行的全面实验,证明了该自我改进流程的有效性。
RT-1由BC-Z模型相同团队开发,与BC-Z有相似之处,但也引入了一些关键区别,RT-1采用了基于更高效的EfficientNet视觉编码器,这与BC-Z使用的ResNet不同。RT-1将BC-Z中的MLP动作解码器替换为 Transformer 解码器,从而生成离散化的动作,这一改进使 RT-1能够关注过去的图像,从而相比BC-Z提升了性能。
Q-Transformer通过引入自回归Q函数来扩展 RT-1。与通过模仿学习来学习专家轨迹的RT-1不同,Q-Transformer 采用了Q-learing方法。除了Q-learning的TD误差目标外,还引入了一个正则化器,以确保最大价值动作保持在分布范围内,这种方法使得 Q-Transformer 不仅能利用成功的演示,还能利用失败的轨迹进行学习。
ACT利用动作分块(action chunking)构建了一个条件变分自编码器(VAE)策略,要求策略预测一系列连续动作而非单个动作。在推理过程中,使用一种称为时间集成(temporal ensembling)的方法对动作序列进行平均。RoboAgent通过 MT-ACT 扩展了 ACT,证明了动作分块能改善时间一致性。它还引入了一种基于修复(inpainting)的语义增强方法。
RoboFlamingo通过一个基于LSTM的策略头,将OpenFlamingo视觉语言模型(VLM)适配为机器人策略,这证明了预训练的视觉语言模型可以有效地迁移到语言条件下的机器人操作任务中。
与纯文本提示相比,VIMA结合多模态提示,引入了六个主要多模态任务:物体操作、视觉目标导航、物体定位、视频模仿、视觉约束满足以及视觉推理,从而构建更具体、更复杂的机器人学习任务,这些任务通常极具挑战性,甚至无法仅通过语言提示来表达,相关任务评测基准已开放,用于评估VLA模型的四个泛化层级:摆放、新组合、新物体以及新任务。
MOO扩展了RT-1,以使模型能够处理多模态提示。它利用RT-1的骨干网络,结合OWL-ViT来定位提示中指定的目标物体。通过用新物体和额外的提示图像扩展RT-1数据集,MOO增强了RT-1的泛化能力。这种扩展还促进了指定目标物体跟踪的新方法,例如可以通过手指指向和点击图形用户界面,让机器人跟踪指定物体。
LVLA以大模型最为自己的基础组件,比如语言大模型LLama、视觉大模型Qwen-VL,借助大模型在大规模预训练数据集上获得的通用知识、能力,提高VLA模型的整体准确性。
RT-2利用大型多模态模型的能力来处理机器人任务,其构建了基于 PaLI-X和PaLM-E大模型的架构,RT-2引入了一种协同微调策略,在互联网规模的VQA数据和机器人数据上联合训练模型,这种训练方式增强了模型的泛化能力,并使其涌现出来额外的能力。
RT-X建立在RT-1和RT-2模型之上,模型使用大规模机器人训练数据集Open X-Embodiment (OXE) 进行了重新训练,该数据集的规模远远超出以往的机器人训练数据集,验证了VLA模型的Scaling Law,证明即使是相同的架构,只要通过扩大训练数据集,同样能获得较好的性能,由此产生的模型 RT-1-X 和 RT-2-X均优于其原始版本。
OpenVLA是RT-2-X模型的开源对应版本,它还探索了高效的微调方法,包括LoRA和QLoRA微调,OpenVLA-OFT提出了优化微调(OFT)方案,以提高OpenVLA的效率和性能。
TraceVLA对OpenVLA进行了进一步微调,以实现视觉轨迹提示,增强模型的时空感知能力。
π-0提出了一种流匹配架构,用于将普通的多模态模型转换为VLA模型,通过混合专家框架引入额外的动作专家,有效地继承了基础多模态模型的互联网规模知识,同时扩展了其处理机器人任务的能力。
RoboMamba用具有线性推理复杂度的Mamba状态空间模型替代计算昂贵的Transformer架构,从而实现了高效的机器人推理和行动。
LAPA设计了首个基于潜在动作的VLA无监督预训练方法。该方法采用三阶段流程从互联网规模的无标签视频中进行学习。首先,预训练一个VQ-VAE,以提取图像帧之间的量化潜在动作,然后,预训练一个VLA模型来预测这些潜在动作,最后,仅使用少量机器人数据集对模型进行微调,将潜在动作映射到实际的机器人动作。
NORA-1.5通过奖励引导的后训练,将VLA与世界模型进行了统一。
Genie Envisioner在单一视频生成框架内集成了世界模型和 VLA,基于量化视觉token的视觉自回归建模,在图像生成中展现出优于扩散模型的性能,表明VLA的三种模态可以在自回归范式下实现统一。
WorldVLA和UniVLA将多模态数据量化为离散token,形成共享的量化多模态token词表,所有模态都可以进行自回归建模,不仅能生成动作和文本,还能生成图像,从而构成一个世界模型。
3.2 方法名(原论文名)
Gato(A generalist agent)
RoboCat(Robocat: A self-improving foundation agent for robotic manipulation)
Q-Transformer(Q-transformer: Scalable offline reinforcement learning via autoregressive q-functions)
ACT(Learning fine-grained bimanual manipulation with low-cost hardware)
RoboAgent(Roboagent:Generalization and efficiency in robot manipulation via semantic augmentations and action chunking)
RoboFlamingo(Vsion-language foundation models as effective robot imitators)
VIMA(VIMA: general robot manipulation with multimodal prompts)
MOO(Open-world object manipulation using pre-trained vision-language models)
RT-2(RT-2: vision-language-action models transfer web knowledge to robotic control)
RT-X(Open x-embodiment: Robotic learning datasets and RT-X models)
OpenVLA(Openvla: An open-source vision-language-action model)
OpenVLA-OFT(Fine-tuning vision-language-action models: Optimizing speed and success)
TraceVLA(Tracevla: Visual trace prompting enhances spatial-temporal awareness for generalist robotic policies)
π-0(π0: A vision-language-action flow model for general robot control)
RoboMamba(Robomamba: Efficient vision-language-action model for robotic reasoning and manipulation)
LAPA(Latent action pretraining from videos)
NORA-1.5(NORA-1.5: A vision-language-action model trained using world model-, and action-based preference rewards)
Genie Envisioner(Genie envisioner: A unified world foundation platform for robotic,manipulation)
WorldVLA(Worldvla: Towards auto regressive action world model)
UniVLA(Unified vision-language-action model)
四 任务规划
任务规划的目的是分解人类输入指令的具体意图,形成机器人可以更高效执行的子任务,提升机器人任务执行整体的准确性。
4.1 相关介绍
大语言模型或多模态大语言模型通常可以在具身智能数据集上进行微调来生成机器人的任务规划,将这些模型称为单体模型。与大型视觉语言助手类似,任务规划器也可以实现为端到端的多模态大语言模型,利用其互联网级别的通用知识进行任务规划。
PaLM-E整合ViT和PaLM,创建了一个具身多模态大语言模型,能够执行高级具身推理任务。基于感知到的图像和语言指令,PaLM-E生成一个文本计划,作为低级机器人执行策略的规划,生成的计划进一步使用SayCan,映射为可执行的低级指令。随着低级策略执行,PaLM-E还可以根据具体的执行情况、环境变化重新进行任务规划,借助PaLM主干网络,PaLM-E可以处理标准的视觉问答(VQA)任务以及具身视觉问答任务。
EmbodiedGPT引入具身构建器(embodied-former),通过结合视觉编码器嵌入和大语言模型提供的规划信息,它能输出与任务相关的实例级别特征,这些实例特征被用于告知低级策略接下来要采取的行动。
SayCan是一个旨在将大语言模型规划器与低层控制策略适配的框架。在该框架中,LLM规划器接收用户输入的高层指令,“说出”最可能的下一个低层技能,这一动作被称为task-grounding,低层策略提供价值函数作为大语言模型可选执行函数,确定策略“能够”完成该技能的概率,这被称为world-grounding,通过同时考虑LLM的规划和策略可实现性,SayCan为当前状态选择最优的执行技能。
Translated采用两步流程将高层人类指令转化为低层机器人可执行的动作。首先,利用预训练的LLM进行动作规划生成,将高层指令分解为下一个动作,以自由形式的语言短语表达,然后,由于该短语可能无法直接映射到具体的可执行动作,使用预训练的掩码 LLM进行动作翻译,此步骤涉及计算生成的动作短语与允许的可执行动作之间的相似度,翻译后的动作被附加到规划中,更新后的规划被反馈给LLM以生成下一个动作短语,重复执行这个过程,直到形成完整的动作规划。
(SL)3是一种在“分割、标记和参数更新”三个步骤之间交替执行的学习算法:
1)在分割步骤中,高层子任务与低层动作进行对齐
2)在标记步骤中推断出子任务具体描述
3)更新网络参数
这种方法使得分层策略能够利用稀疏的自然语言标注发现可重用的技能。
基于代码的任务规划器利用大语言模型的编码能力,以可执行程序的形式生成任务规划。
ProgPrompt提出了一种新颖的任务规划方法,通过向大语言模型提供类似程序格式的规范(详细说明可用的动作和对象)来进行提示,这使得大语言模型能够以少样本的方式为任务生成高层规划,环境反馈可以通过类似程序内的断言方式来整合。
ChatGPT for robotics利用ChatGPT的编程能力,实现了“Human in The Loop”的控制方式,该过程包括以下几个步骤:
1)首先,定义一组 API,例如物体检测 API、抓取 API 和移动 API
2)其次,构建一个针对ChatGPT的提示,明确说明当前机器人所处的环境、API 的功能以及任务目标
3)反复提示 ChatGPT,让其利用所定义的 API 编写代码以执行任务,同时提供环境状态和用户反馈,用于评估代码的质量和安全性
4)最后,机器人执行ChatGPT生成的代码
在此过程中,ChatGPT 充当高层任务规划器,机器人要执行的动作通过调用相应的低层API函数来生成。
CaP同样利用了大语言模型的代码编写能力,它采用GPT-3或Codex生成策略代码,该代码进而调用感知模块和机器人底层控制API,CaP在空间几何推理、对新指令的泛化以及低级控制原语的参数化方面表现出色。
利用GPT-4V自身的多模态能力,COME-robot去除了CaP对感知API的依赖,这为闭环框架内的开放式推理和自适应规划开辟了可能性,实现了故障恢复和自由形式指令遵循等能力。
DEPS代表“描述、解释、规划与选择”,该方法采用LLM生成计划,并基于从环境中收集的反馈描述来解释执行失败的原因,这一过程被称为“自我解释”,有助于LLM重新规划。此外,DEPS引入了一个可训练的目标选择器,根据子目标的易实现程度在候选子目标集合中进行并行选择,这是其他高层任务规划器经常忽视的方面。
ConceptGraphs将观测状态序列转换为开放词汇3D场景图,利用2D分割模型从观测的图像中提取物体,采用多模态模型为物体添加语言描述,并建立物体间的关系,从而构建出当前的3D场景图。随后,该场景图转换为Json格式的文本描述,为LLM提供实体间丰富的语义和空间关系,以用于进行任务规划。
4.2 方法名(原论文名)
PaLM-E(Palm-e: An embodied multimodal language model)
SayCan(Do as I can, not as I say: Grounding language in robotic affordances)
EmbodiedGPT(Embodiedgpt: Vision-language pre-training via embodied chain of thought)
Translated(Language models as zero-shot planners: Extracting actionable knowledge for embodied agents)
(SL)3(Skill induction and planning with latent language)
ProgPrompt(Progprompt: Generating situated robot task plans using large language models)
ChatGPT for robotics(Chatgpt for robotics: Design principles and model abilities)
CaP(Code as policies: Language model programs for embodied control)
COME-robot(Closed-loop open-vocabulary mobile manipulation with GPT-4V)
DEPS(Describe, explain, plan and select: Interactive planning with large language models enables open-world multi-task agents)
ConceptGraphs(Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)