Meta-Harness:模型运行框架端到端优化
Meta-Harness:模型运行框架端到端优化
作者:Yoonho Lee、Roshen Nair、张启正、Kangwook Lee、Omar Khattab、Chelsea Finn
单位:斯坦福大学、麻省理工学院、KRAFTON公司
arXiv预印本:2603.28052v1 [cs.AI],2026年3月30日
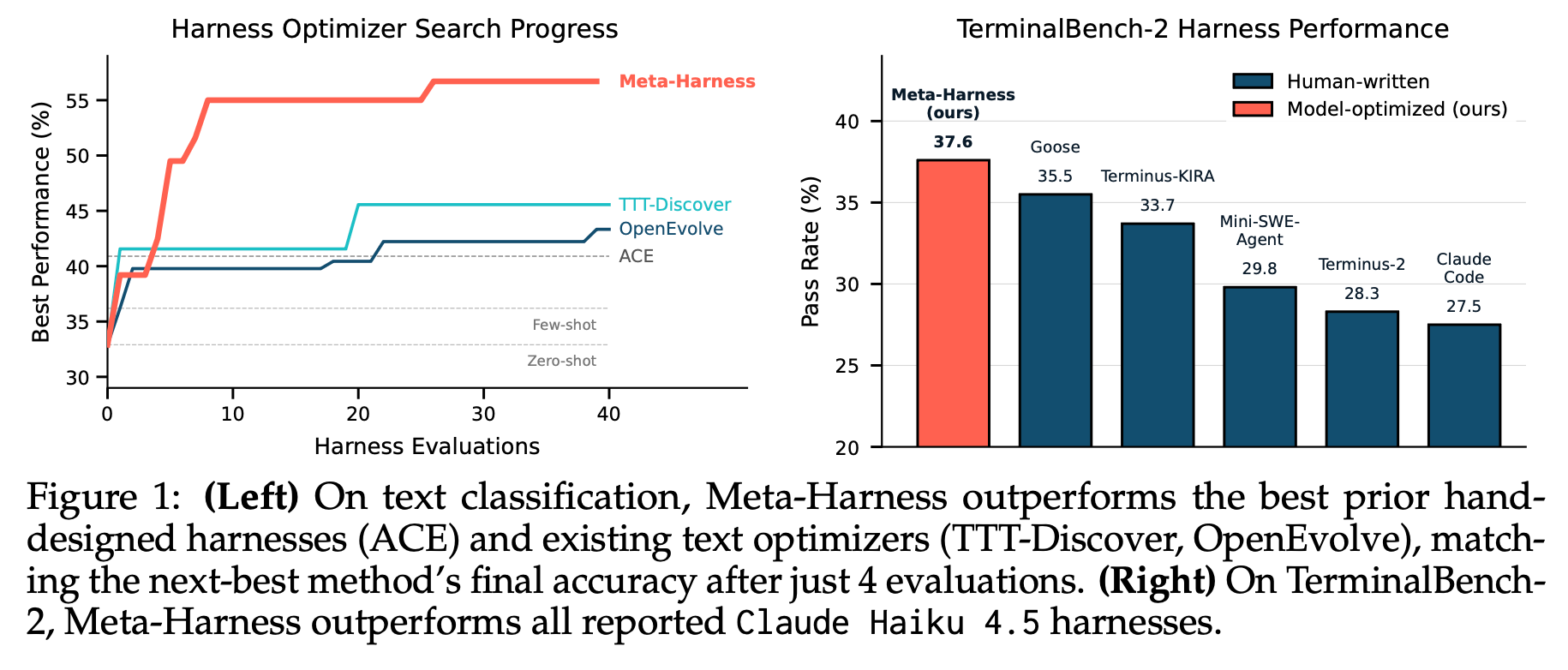
图1:左图:文本分类任务上,Meta-Harness性能优于最优人工设计框架ACE与现有文本优化器TTT-Discover、OpenEvolve,仅4次评估即可达到次优方法的最终准确率;右图:TerminalBench-2基准测试中,Meta-Harness性能超越所有基于Claude Haiku 4.5的已有运行框架。
横轴:框架评估次数;纵轴左:最优性能(%);纵轴右:通过率(%)
对标算法:Meta-Harness(本文)、人工优化框架、Goose(35.5%)、Terminus-KIRA、OpenEvolve、TTT-Discover、Mini-SWE-Agent、Claude Code、ACE、Terminus-2(29.8%)
摘要
大语言模型(LLM)系统的性能不只由模型权重决定,还取决于运行框架(Harness):该代码负责管控模型存储、调取信息以及输入内容。但现阶段运行框架基本依靠人工设计,现存文本优化算法难以适配该场景——这类算法过度压缩反馈信息:无历史记忆、仅依托标量分数做条件约束、或是将反馈限定在简短模板与摘要中。本文提出Meta-Harness,一套外层循环优化系统,面向大模型应用自动搜索最优运行框架代码。系统采用智能提案代理,依托文件系统读取全部历史候选方案的源代码、评测分数与运行日志。
在线文本分类任务中,Meta-Harness相较业内顶尖上下文管理系统准确率提升7.7个百分点,同时上下文token用量缩减至原先1/4;检索增强数学推理场景下,单次搜索得到的运行框架,在200道国际奥林匹克(IMO)难度试题上,跨5个未参与训练的测试模型平均提升准确率4.7个百分点;智能代码代理任务中,自研框架在TerminalBench-2基准上全面超越最优人工工程基线。以上结果证明:充分利用全量历史经验,能够实现运行框架工程的自动化构建。
1 引言
在固定大模型不变的前提下,更换配套运行框架能让同一基准任务性能产生6倍差距。运行框架作为控制数据存储、信息检索、模型输入内容的程序代码,其重要程度堪比模型本身。这一性能波动促使业内兴起运行框架工程:通过迭代优化模型外围配套代码提升整套系统效果。但尽管价值突出,框架设计仍高度依赖人工:研发人员人工排查错误、调整启发式规则、反复迭代少量方案。本文聚焦问题:能否自动化整套框架迭代优化流程?
现有文本优化研究是实现自动化的可行切入点,框架迭代同样依托历史试错反馈不断优化文本与代码组件。但这类算法无法适配框架优化需求:多数方案仅使用短期、经过重度压缩的反馈数据,部分算法只参考当前候选方案、部分仅依靠单一数值打分、还有部分把反馈压缩为固定短模板或大模型生成摘要。该设计是出于工程落地的扩展性取舍,并非长跨度历史信息没有优化价值。
运行框架具备长时序依赖特性:某一处存储/检索/内容呈现的设计选择,会在多轮推理步骤后才体现效果;压缩后的反馈会丢失关键关联信息,无法把后续模型出错回溯到早期框架设计缺陷。如表1所示,主流文本优化算法单次优化可用上下文仅100~30000token,远达不到框架调试所需的全量诊断信息。此外,检索与记忆增强大模型相关研究表明:有效上下文应当按需动态调取,而非一次性全部塞入提示词。
针对上述缺陷,本文提出Meta-Harness,依托端到端搜索实现运行框架自优化的智能系统(图2)。方案中的提案模块为代码智能体(基于大模型、可调用开发工具并修改源码)。选用代码智能体而非原生大模型的原因:历史迭代数据总量远超上下文窗口上限,智能体需要自主筛选信息、通过代码交互验证修改方案。
核心设计:借助文件系统留存全量历史记录,智能体按需筛选读取原始代码与运行日志,而非使用压缩后的方案摘要。文件系统存储每版候选框架的源码、评测得分、执行轨迹,智能体通过grep、cat等终端指令按需读取,而非一次性载入全部内容。实测中,高难度实验环境下智能体平均每轮读取82个文件、单次迭代参考20份以上历史候选方案(附录A)。单次框架评估可生成最高1000万token的诊断数据,相比过往文本优化方案,信息规模高出三个数量级(表1)。
本文在在线文本分类、数学推理、智能代码代理三大场景验证Meta-Harness效果:
在线文本分类:仅4次评估就达到竞品优化器最终性能,最终准确率高出10个百分点,对比ACE基线提升7.7%,上下文token消耗降至原1/4;
检索增强奥数推理:优化得到的检索框架跨5个陌生模型平均提分4.7%;
TerminalBench-2代码代理:基于Haiku 4.5模型实现37.6%通过率,位列同模型全部方案第一名。
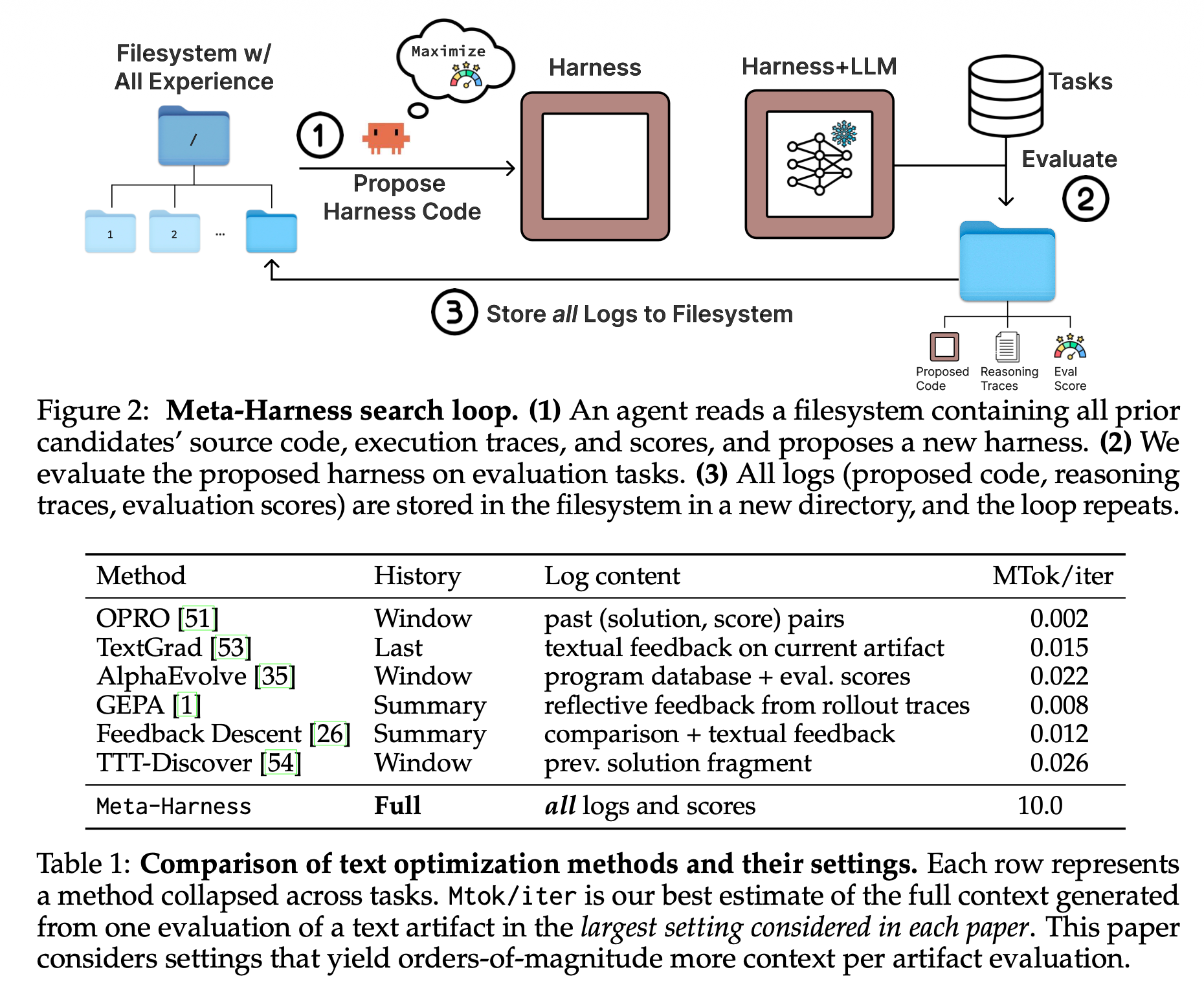
图2 Meta-Harness搜索循环
- 智能代理读取存储全部历史候选源码、运行轨迹、评测分数的文件系统,生成新版运行框架代码;
- 在目标任务上评测新生成框架;
- 将源码、推理日志、评测分数存入文件系统新目录,进入下一轮循环。
表1 各类文本优化算法配置对比
| 算法 | 历史存储范围 | 日志内容 | 单次迭代生成百万token |
|---|---|---|---|
| OPRO | 滑动窗口 | 历史(方案,分数)二元组 | 0.002 |
| TextGrad | 仅上一轮 | 当前方案文本反馈 | 0.015 |
| AlphaEvolve | 滑动窗口 | 程序库+评测分数 | 0.022 |
| GEPA | 摘要精简 | 推演轨迹反思反馈 | 0.008 |
| Feedback Descent | 摘要精简 | 方案对比+文本反馈 | 0.012 |
| TTT-Discover | 滑动窗口 | 历史方案片段 | 0.026 |
| Meta-Harness | 完整全量 | 全量日志+全量分数 | 10.0 |
| 注:Mtok/iter为单轮评测生成上下文token量级,本文优化场景单轮信息体量远超过往所有文本优化工作。 |
2 相关工作
Meta-Harness融合信用分配与元学习思想,区别于传统微调模型权重,本方法在框架层级分配优化贡献:依托过往运行记录定位造成错误的模块与步骤,直接重写控制模型行为的外围代码。研究横跨三大技术方向:外部上下文自适应读取、可执行代码搜索、文本优化。
2.1 外部记忆与自适应访问
已有研究将海量知识库、超长输入作为外部资源,由大模型按需分次读取而非一次性全量输入,代表技术:检索增强生成、推理穿插检索、记忆智能体、递归大模型。Meta-Harness沿用按需读取设计,但落地在框架优化场景:提案智能体按需查阅海量历史代码、打分、运行轨迹,迭代优化上下文管理逻辑。
2.2 可执行代码搜索
现有代码演化算法依托大模型做变异/交叉算子、在固定代码骨架内迭代函数、用元智能体编写新代理、搜索智能体工作流图、优化持续学习智能体的记忆结构。
区别于上述工作:Meta-Harness面向各类领域专属运行框架(提示词构建、检索策略、状态更新,任务间状态重置)做全量代码搜索;外层循环极简,无预设代码骨架、无固定存档规则、无内置持久化记忆机制,智能体拥有文件系统全量访问权限,自主选择查阅内容,实现完整框架源码搜索而非局限于预定义优化空间。
2.3 文本优化算法
ProTeGi、TextGrad、OPRO、GEPA、AlphaEvolve、Feedback Descent等迭代优化提示词的文本优化算法与本文高度相关。但上述方案面向提示词短句优化,难以适配框架工程:优化目标是完整可执行程序,反馈分散在源码、分数、运行日志中,无法提前压缩总结。Meta-Harness不依赖聚合分数或摘要,智能体基于错误样例与运行轨迹定向修改代码。表1、图1、图4对比本方案与GEPA、OpenEvolve、TTT-Discover性能差异。
3 Meta-Harness:面向框架优化的运行框架系统
本节介绍Meta-Harness外层迭代流程:依托文件系统按需读取历史方案、迭代生成、评测、归档新框架。Meta-Harness本身也属于广义运行框架(命名由来),负责管控提案智能体在优化过程中可见的数据范围;正文其余“运行框架”特指待优化的任务配套程序。
优化目标
运行框架是封装大模型的有状态程序,决定模型每一步接收的上下文内容。优化目标:在固定大模型M、任务分布X\mathcal{X}X下,寻找最优框架H∗H^*H∗最大化任务期望奖励:
H∗=argmaxHEx∼X,τ∼pM(H,x)r(τ,x)H^{*}=\underset{H}{arg max } \mathbb{E}_{x \sim \mathcal{X}, \tau \sim p_{M}(H, x)} r(\tau, x)H∗=HargmaxEx∼X,τ∼pM(H,x)r(τ,x)
τ\tauτ为框架HHH+模型MMM处理样本xxx生成的推演轨迹,r(τ,x)r(\tau,x)r(τ,x)为任务打分函数。
多目标优化(准确率+上下文开销)采用帕累托占优筛选,生成最优解集;传统模式由人工反复调试提示词、上下文规则、工具调用逻辑实现优化。
Meta-Harness迭代搜索流程
优化流程仅使用单个代码智能体作为提案器,配套持续扩容的文件系统D充当全量反馈库。代码智能体依托大模型、可调用开发工具、修改源码;区别于传统固定规则优化循环,本方案把错误诊断、修改决策全权交由智能体:自主选定历史方案查阅对象、定位错误诱因、选择局部微调或全量重构代码。提案器不是受固定提示词约束的原生大模型,具备信息检索、源码浏览、代码改写能力。
每轮评测后的框架单独新建文件夹,存放源码、得分、全量运行记录(提示词、工具调用、模型输出、状态变更);因文件系统远超模型上下文上限,智能体通过终端指令筛选内容,而非一次性加载全部数据。
系统维护候选框架集合与帕累托最优解集,但无强制父代筛选规则:智能体可任意调取历史框架与日志生成新版本。优化执行固定轮次,最终在帕累托解集上做测试集评估。
设计思路:优化决策交由智能体而非硬编码搜索规则,伴随代码智能体能力提升,系统优化效果可同步自然升级。提案智能体全程不可访问测试集数据,优化反馈仅来自搜索集评测日志。
代码空间搜索优势
框架优化在程序代码空间开展:检索、记忆、提示词逻辑的微小改动会在多轮推理后显现效果,传统局部搜索启发式规则适用性差。依托运行日志,智能体能够定位错误的根源设计,而非仅获知最终结果出错。附录A案例显示:智能体通读历史代码与日志,定位冲突修改项、隔离有效改动,在多次性能倒退后切换更稳妥的优化方向。
智能体可从检索/记忆/提示词全链路算法层面改写,既可局部微调也能完整重写程序,不受固定模板、预设变异算子限制;优化常从优质基线框架起步,但该行为是智能体自主选择而非系统强制。
尽管代码搜索空间庞大,编程语言天然提供正则约束:代码模型倾向生成逻辑连贯、可复用的上下文管理算法,减少劣质硬编码方案;该优化动作与前沿代码助手训练范式高度契合。
工程落地细节
实验中所有待优化框架均为单文件Python代码,管控任务专属提示、检索、记忆、调度逻辑;提案智能体选用Claude Code(Opus-4.6),配套极简领域技能说明:标注源码存放路径、历史日志查阅方法、文件修改权限;底层大模型M随任务更换,全程冻结权重,详细配置见第4章。常规实验迭代20轮,每轮生成2个候选方案,全流程评测约60个不同框架;新领域落地实操技巧见附录D。
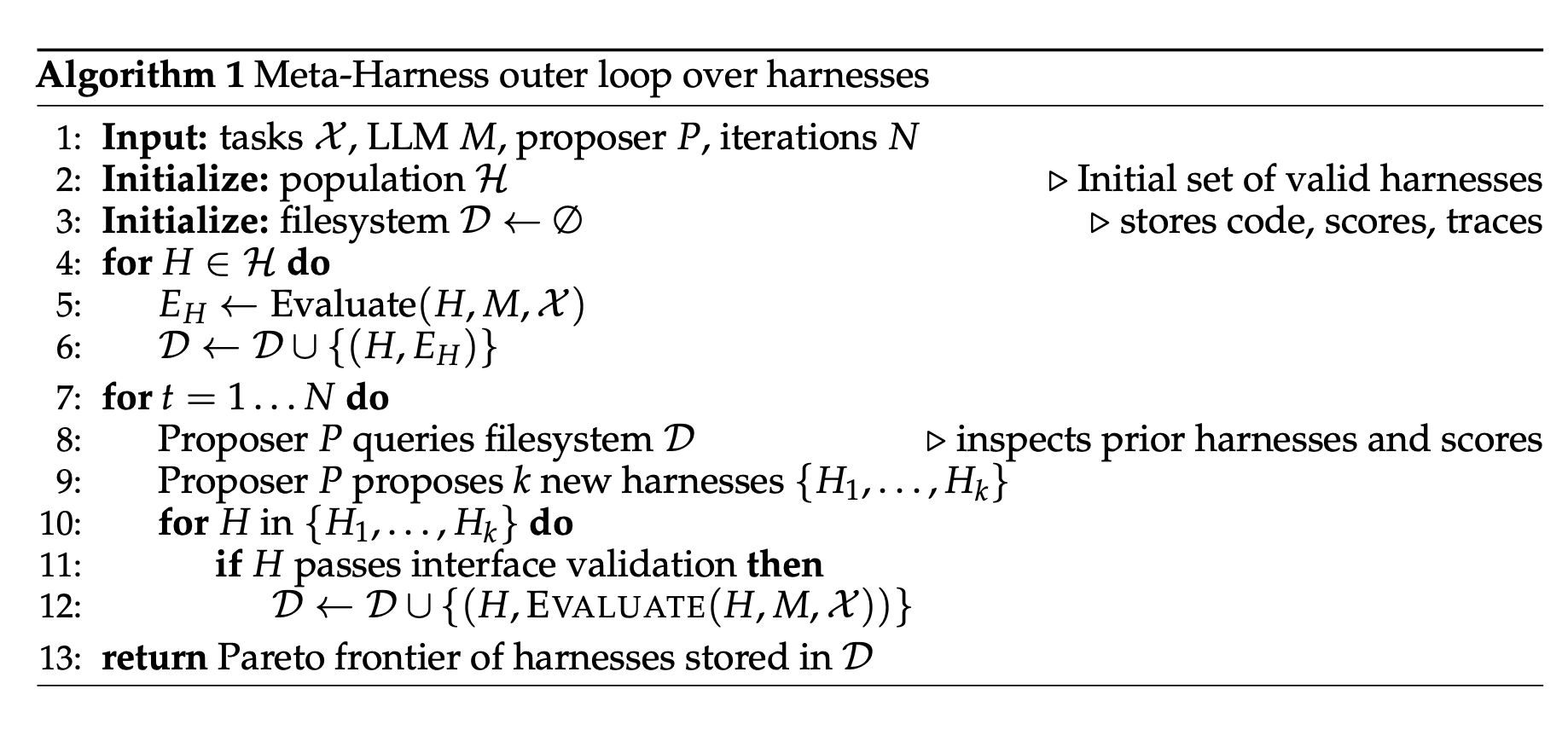
算法1 Meta-Harness外层优化算法
- 输入:任务集X\mathcal{X}X、固定大模型M、提案智能体P、迭代总轮数N
- 初始化候选框架集合HHH(初始有效框架基线)
- 初始化空文件系统DDD(存储源码、分数、运行轨迹)
- 遍历初始集合全部框架H∈HH\in HH∈H:
4.1 评测框架EH=Evaluate(H,M,X)E_H=\text{Evaluate}(H,M,\mathcal{X})EH=Evaluate(H,M,X)
4.2 评测结果存入文件系统D=D∪{(H,EH)}D=D\cup\{(H,E_H)\}D=D∪{(H,EH)} - 循环t=1⋯Nt=1\cdots Nt=1⋯N:
5.1 提案智能体P查询文件系统D,读取历史框架与得分
5.2 智能体生成k个新候选框架{H1,…,Hk}\{H_1,\dots,H_k\}{H1,…,Hk}
5.3 逐个校验候选框架接口合法性,合法则完成评测并归档至D - 最终返回文件系统D中所有框架构成的帕累托最优解集
4 实验
三大评测场景:在线文本分类、检索增强数学推理、智能代码代理;对照组分为人工手工优化框架(领域SOTA上下文策略)、程序自动搜索算法(小场景优化基线)两类。
4.1 在线文本分类
沿用ACE论文实验设定:大模型逐个接收单条标注样本、更新内部记忆,在测试集完成分类;基础大模型选用GPT-OSS-120B,三个跨领域评测数据集:
- LawBench(法律):根据案件描述预测罪名,215分类
- Symptom2Disease(医疗):症状→疾病,22分类
- USPTO-50k(化学专利):产物→合成原料,180分类
初始候选基线:零样本、8/32/全量少样本、MCE、ACE;优化迭代20轮,每轮2个候选,合计40套框架。
对标文本优化算法
统一配置提案器(Opus-4.6满配推理)、同等评测资源,仅依托搜索集筛选方案,测试集仅用于最终指标统计:
- Best-of-N:基线随机采样,无优化迭代,验证搜索有效性
- OpenEvolve:大模型变异驱动程序进化
- TTT-Discover:仅使用原文文本优化模块、PUCT复用筛选规则
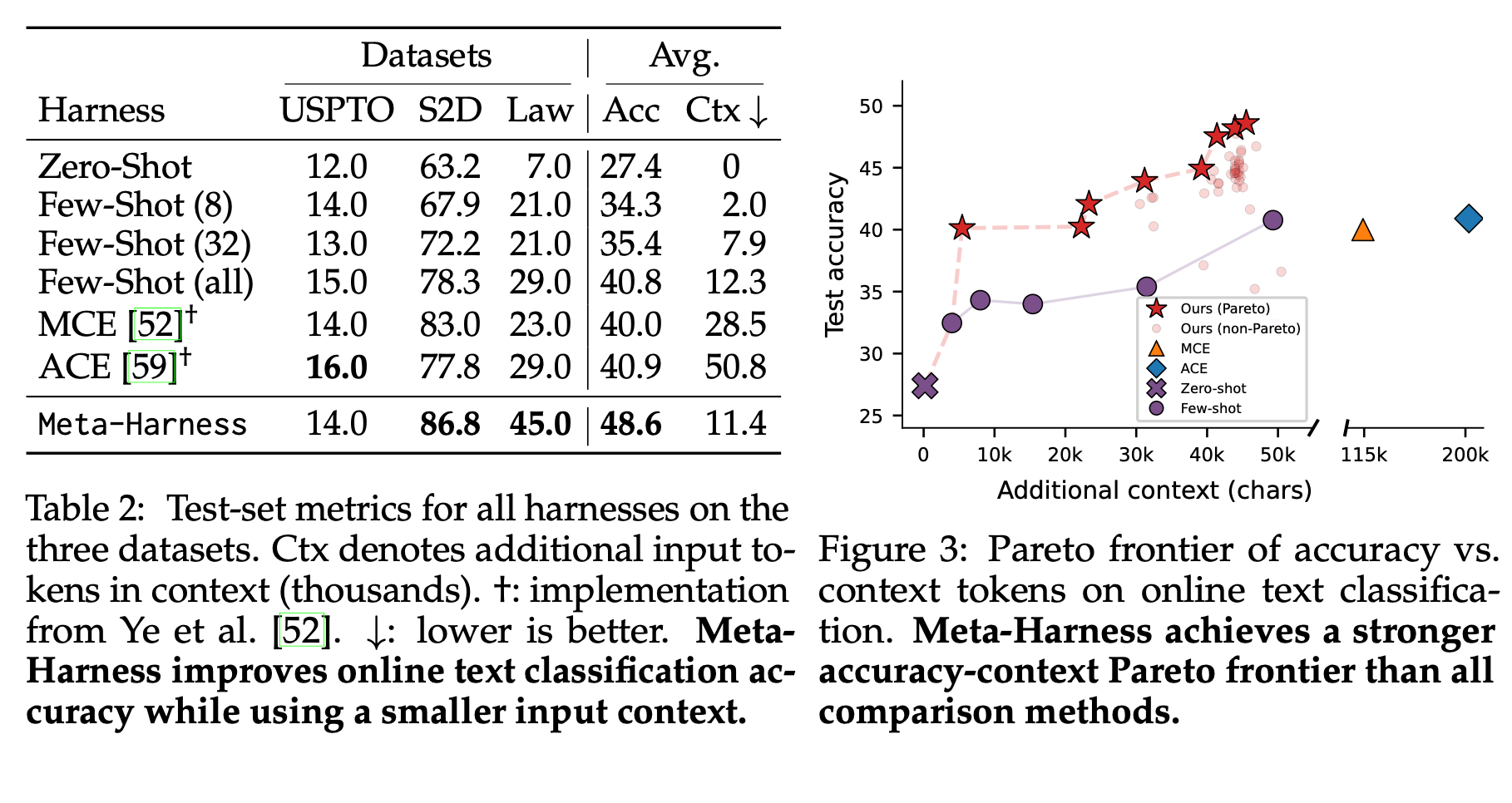
表2 三类数据集测试指标(Ctx:额外上下文字符,单位千,数值越低开销越小;Avg:平均准确率)
| 框架方案 | USPTO | S2D | LawBench | 平均准确率 | 额外上下文 |
|---|---|---|---|---|---|
| 零样本 | 12.0 | 63.2 | 7.0 | 27.4 | 0 |
| 少样本(8例) | 14.0 | 67.9 | 21.0 | 34.3 | 2.0 |
| 少样本(32例) | 13.0 | 72.2 | 21.0 | 35.4 | 7.9 |
| 全量少样本 | 15.0 | 78.3 | 29.0 | 40.8 | 12.3 |
| MCE | 14.0 | 83.0 | 23.0 | 40.0 | 28.5 |
| ACE | 16.0 | 77.8 | 29.0 | 40.9 | 50.8 |
| Meta-Harness | 14.0 | 86.8 | 45.0 | 48.6 | 11.4 |
Meta-Harness平均准确率48.6%,较ACE+7.7%、MCE+8.6%;上下文开销仅11.4k字符,远低于ACE(50.8k)、MCE(28.5k)。
图3 准确率-上下文开销帕累托曲线
横轴:额外上下文字符;纵轴:测试准确率
Meta-Harness帕累托前沿全面优于零样本、各类少样本、MCE、ACE,在更低上下文开销下取得更高精度。
消融实验(表3)
三组变量:仅得分、得分+LLM摘要、完整Meta-Harness(原始全量运行日志)
仅得分:中位数34.6、最优41.3
得分+摘要:中位数34.9、最优38.7
完整方案:中位数50.0、最优56.7
结论:原始运行日志全量访问是核心增益来源,摘要压缩会丢失关键优化信息。
表4 各优化算法搜索集最优准确率
| 算法 | 中位数准确率 | 最优准确率 |
|---|---|---|
| GEPA | 32.6 | 40.2 |
| Best-of-N | 34.0 | 44.2 |
| OpenEvolve | 39.1 | 43.3 |
| TTT-Discover | 34.1 | 45.6 |
| Meta-Harness | 50.0 | 56.7 |
域外泛化测试(9个全新数据集,表5)
Meta-Harness平均准确率73.1%,ACE70.2%;9项任务中6项取得最优,少样本扩充至32例后7/9任务性能下降,证明自研框架学到通用分类策略,无过拟合。
表5 9个域外数据集平均指标
| 方案 | 平均准确率 | 额外上下文(千字符) |
|---|---|---|
| 零样本 | 67.0 | - |
| 少样本8例 | 68.9 | 2.2 |
| 少样本32例 | 69.6 | 5.2 |
| 全量少样本 | 68.2 | 7.4 |
| ACE | 70.2 | 11.7 |
| Meta-Harness | 73.1 | 7.3 |
4.2 检索增强数学推理
数据集:50万+去重奥数题库(8套开源数据集,严格去污染、剔除和测试集重合题目);搜索集:250道奥赛难题(OlympiadBench+Omni-MATH难题),迭代40轮,生成109套检索框架;初始化基线:零样本、少样本、ACE。
测试集:200道IMO级别试题(IMO-AnswerBench/ProofBench/ArXivMath);验证泛化:优化仅基于GPT-OSS-20B,落地5个陌生模型(GPT5.4nano/mini、Gemini3.1FL/Gem3F、GPT-20B)。
表6 200道IMO题目各模型准确率(括号:相对无检索基线提升百分点)
| 方案 | GPT5.4n | GPT5.4m | Gem3.1FL | Gem3F | GPT20B | 平均提升 |
|---|---|---|---|---|---|---|
| 无检索基线 | 23.0 | 28.8 | 28.6 | 42.6 | 47.6 | 34.1(基准) |
| 稠密检索k=1 | 27.1(+4.1) | 24.5(-4.3) | 31.3(+2.7) | 42.3(-0.3) | 46.9(-0.7) | 34.4(+0.3) |
| 稠密检索k=5 | 31.1(+8.1) | 28.3(-0.5) | 37.1(+8.5) | 47.2(+4.6) | 46.7(-0.9) | 38.1(+4.0) |
| 随机少样本 | 23.1(+0.1) | 24.5(-4.3) | 31.0(+2.4) | 40.4(-2.2) | 41.8(-5.8) | 32.2(-1.9) |
| BM25原生检索 | 30.2(+7.2) | 29.2(+0.4) | 32.8(+4.2) | 46.6(+4.0) | 48.9(+1.3) | 37.5(+3.4) |
| Meta-Harness | 31.7(+8.7) | 30.4(+1.6) | 34.9(+6.3) | 46.3(+3.7) | 50.6(+3.0) | 38.8(+4.7) |
| 结论:自研检索框架依托原生BM25,无新增稠密编码器,全模型平均提升4.7%,整体优于稠密检索、原生BM25、少样本基线。 |
4.3 TerminalBench-2智能代码评测(89项高难度长时序终端任务)
优化基线:Terminus2、Terminus-KIRA;分两组基座模型评测:Claude Opus4.6、Claude Haiku4.5。
表7 TerminalBench2通过率(%,Auto:自动优化/人工编写)
Opus4.6
| 方案 | 人工编写 | 通过率 |
|---|---|---|
| Claude Code | 是 | 58.0 |
| Terminus2 | 是 | 62.9 |
| Mux | 是 | 66.5 |
| Droid | 是 | 69.9 |
| TongAgents | 是 | 71.9 |
| MAYA-V2 | 是 | 72.1 |
| Terminus-KIRA | 是 | 74.7 |
| Capy | 是 | 75.3 |
| ForgeCode | 是 | 81.8 |
| Meta-Harness | 自动 | 76.4 |
| 排名全榜第2,仅低于无法复现的ForgeCode |
Haiku4.5
| 方案 | 人工编写 | 通过率 |
|---|---|---|
| OpenHands | 是 | 13.9 |
| Claude Code | 是 | 27.5 |
| Terminus2 | 是 | 28.3 |
| Mini-SWE-Agent | 是 | 29.8 |
| Terminus-KIRA | 是 | 33.7 |
| Goose | 是 | 35.5 |
| Meta-Harness | 自动 | 37.6 |
| 全榜第一,领先次优Goose2.1个百分点 |
优化过程定性分析
迭代前期:智能体同步修改代码结构+提示词,两次迭代全部性能倒退;第3轮通过全量日志定位:性能下滑源于提示词改动、结构修复本身有效;隔离变量验证猜想;后续发现提示词、任务闭环逻辑改动风险极高;第7轮改用环境快照前置注入(不改动原有闭环代码),诞生最优方案;后续组合多个有效改动进一步提升性能,还能跨迭代复用历史优化经验。该行为依托全量原始日志实现,压缩反馈优化算法无法达成因果推理。
5 讨论
除基准性能领先外,Meta-Harness具备多项实用优势:优化出的框架可跨数据集、跨底层模型泛化;单次搜索数小时即可产出可读、可迁移优化逻辑;代码层面过拟合易于人工审查(硬编码规则可直接从源码识别,区别于模型权重隐式过拟合)。
核心优势不在于代码空间搜索,而在于全量历史诊断数据按需读取:智能体跳出单一数值打分、固定摘要的限制,查阅完整源码与故障日志,形成优化假设并迭代验证。
未来方向:框架与模型权重协同联合优化;在更多类型提案智能体上做横向对比实验。
致谢
感谢KRAFTON AI提供API算力支持;项目受OpenAI、KFAS、Schmidt Sciences AI2050项目资助;感谢科研人员提供修改建议。
参考文献(原文保留文献标号,内容不赘述)
附录
附录A 提案智能体行为定性分析(TerminalBench2实验)
A.1 文件读取统计
单轮迭代中位数读取82个文件(区间69~99):源码41%、运行轨迹40%、得分摘要6%、其他文件13%;智能体大范围查阅全量历史,非仅参考最近一轮方案。
A.2 迭代优化完整逻辑
1~2轮:同步修复结构漏洞+改写提示词,两次优化均性能下跌;
3轮:通过两份失败日志定位共性改动为提示词,剥离提示词变更仅验证结构修复,性能小幅回落但远优于前两轮;
4~6轮:持续优化任务闭环逻辑,但只要修改提示/流程就大概率退化;
7轮:放弃修改原有闭环,新增前置环境快照采集,成为最优解;
8轮:组合快照+早期有效结构修复,叠加收益;
10轮:复用其他优化轮次历史有效经验继续迭代。
附录B 优化产出框架源码逻辑说明
B.1 文本分类两类帕累托最优框架
- 草稿-校验双阶段框架(低上下文开销)
- 第一步:召回5条近邻样本生成初步预测;
- 第二步:基于初步预测定向召回同标签佐证样本、异标签反例,二次校验修正结果;
- 冷启动:样本不足5条时回落至标准少样本。
- 标签前置查询框架(高精度,正文选用)
三段式提示词构建:①标签全集枚举;②每类标签各1条代表性样本;③同特征不同标签对比样本;依托TF-IDF查询配对,精准划定分类边界。
表9 文本分类帕累托全解集
| 方案 | USPTO | S2D | LawBench | 平均精度 | 上下文(千字符) |
|---|---|---|---|---|---|
| 草稿校验版 | 18.0 | 85.4 | 17.0 | 40.1 | 5.4 |
| 错误标注版 | 9.0 | 87.7 | 24.0 | 40.2 | 22.3 |
| CoT回放版 | 13.0 | 88.2 | 25.0 | 42.1 | 23.3 |
| 聚类覆盖版 | 12.0 | 86.8 | 33.0 | 43.9 | 31.2 |
| 级联检索版 | 12.0 | 86.8 | 36.0 | 44.9 | 39.2 |
| RRF对比版 | 18.0 | 89.6 | 35.0 | 47.5 | 41.4 |
| 相关度对比版 | 18.0 | 90.6 | 36.0 | 48.2 | 43.9 |
| 标签前置(正文) | 14.0 | 86.8 | 45.0 | 48.6 | 45.5 |
B.2 数学检索四分支路由框架
通过题目关键词+正则自动划分子类,各分支独立BM25检索规则:
- 组合数学:20候选→去重至8→难度重排→取top3;
- 几何:固定1道高难度真题+2条原生BM25结果,无重排序;
- 数论:12候选→加权(关键词+证明前置加分)重排取top3;
- 代数/其他:10候选,根据得分集中度自适应选取样本数量。
B.3 TerminalBench2落地框架
在Terminus-KIRA基础上新增80行代码:任务启动前置执行环境快照采集,shell一次性采集路径、已装编程语言、包管理器、目录文件、内存信息,15s超时静默失败;消除代理前期2~4轮环境探测空耗,在依赖密集型任务(生物编译、密码工具)显著提分。
附录C 数据集明细
C.1 9个域外分类数据集
SciCite(科学引文三分类)、FiNER(金融细粒度实体识别)、亚马逊评论星级、金融情感短语库、GoEmotion细粒度情感、Banking77银行业77分类、AG新闻四分类、SciTail科学文本蕴含、TweetEval仇恨言论二分类。
C.2 奥数检索源数据集(合计53.5万题)
OpenMathReasoning(281743)、DeepMath-103K(103021)、NuminaMath1.5(129520)、PolyMath、Omni-MATH、FineProofs-SFT、AIME历年、Putnam-AXIOM;全库做去重、去污染、答案长度截断处理。
C.3 IMO测试集拆分(合计200题)
IMO-AnswerBench(100)、IMO-ProofBench(60)、ArXivMath25.12(17)、ArXivMath26.01(23)。
附录D 新领域落地实操指南
- 编写专用技能描述:划定文件权限、目录结构、可执行指令,约束禁止操作,不限制智能体诊断思路,小批量迭代调试技能文案;
- 选用弱效果基线+高难度搜索集:基线效果饱和则无优化空间,搜索集控制在50~100样本保证评测效率;
- 标准化日志存储:分层目录+规范命名,适配正则、grep检索;
- 可选配套简易CLI工具:一键查看帕累托解集、代码diff、得分对比,降低智能体文件检索开销;
- 上线前置轻量代码校验:快速过滤无法运行的无效候选,节省评测算力;
- 评测逻辑与提案模块解耦:单独程序完成打分归档,优化逻辑由智能体全权负责。
附录E 扩展相关工作对比
细化AlphaEvolve/OpenEvolve、GEPA、LangChain/DSPy等框架区别:前者固定变异规则、短片段反馈;后者人工设计编排逻辑;Meta-Harness全源码自由搜索、全历史原始日志自适应读取。
[文件名称]: Meta-Harness- End-to-End Optimization of Model Harnesses.pdf
[文件内容开始]
===== 第 1 页 =====
Meta-Harness:模型套件的端到端优化
Yoonho Lee 斯坦福大学
Roshen Nair 斯坦福大学
Qizheng Zhang 斯坦福大学
Kangwook Lee KRAFTON
Omar Khattab MIT
Chelsea Finn 斯坦福大学
项目页面含交互式演示:https://yoonholee.com/meta-harness/ 优化后的套件:https://github.com/stanford-iris-lab/meta-harness-bench2-artifact
摘要
大语言模型(LLM)系统的性能不仅取决于模型权重,还取决于其套件(harness):即决定存储、检索和呈现给模型哪些信息的代码。然而,套件仍然主要依靠手工设计,现有的文本优化器并不适合这一场景,因为它们过于激进地压缩了反馈信息:它们是无状态的、仅依赖标量分数,或者将反馈限制在短模板或摘要中。我们提出了 Meta-Harness,一个用于搜索 LLM 应用套件代码的外部循环系统。它使用一个代理型(agentic)提议者,通过文件系统访问所有历史候选方案的源代码、分数和执行轨迹。在在线文本分类任务上,Meta-Harness 比最先进的上下文管理系统提高了 7.7 个点,同时使用的上下文令牌数减少了 (4 \times)。在检索增强的数学推理任务上,单个发现的套件在 200 个 IMO 水平的问题上,平均提高了 4.7 个点的准确率,这一结果在五个未见的模型上一致成立。在代理编码任务上,发现的套件在 TerminalBench-2 上超越了最佳的手工设计基线。这些结果共同表明,更丰富地访问历史经验可以实现套件工程的自动化。
1 引言
改变围绕固定大语言模型(LLM)的套件可能会在同一个基准测试上产生 (6 \times) 的性能差距 [47]。套件——决定存储、检索和向模型展示哪些信息的代码——通常与模型本身一样重要。这种敏感性导致人们对套件工程(harness engineering)的兴趣日益增长,即精炼围绕 LLM 的代码以提高整个系统性能的实践 [36; 21; 10; 9]。但是,尽管其重要性很高,套件工程仍然主要是手动的:实践者检查失败、
===== 第 2 页 =====
调整启发式规则,并在少量设计上迭代。在本文中,我们提出这样一个问题:这个过程本身能否被自动化?
一个自然的起点是最近关于文本优化的工作,因为套件工程也涉及利用先前尝试的反馈来迭代改进文本和代码工件 [38; 39; 35; 26; 1]。然而,这些方法并不适合套件工程,因为它们通常采用短视或高度压缩的反馈:有些只依赖当前候选方案 [31; 51; 53],有些主要依赖标量分数 [35; 12],还有些将反馈限制在短模板或 LLM 生成的摘要中 [1; 26]。这是一个务实的可扩展性选择,而非证据表明长程依赖关系信息量不大。套件在长时程上运行:关于存储什么、何时检索它或如何呈现它的单个选择可能会影响许多推理步骤之后的行为。压缩后的反馈通常会移除诊断下游失败与早期套件决策所需的信息。在一些代表性文本优化器研究的任务中,每个优化步骤可用的上下文范围仅为 100 到 30,000 个令牌(表 1),远低于套件搜索的诊断信息量。更广泛地说,关于检索和记忆增强语言模型的工作表明,有用的上下文通常应该自适应地访问,而不是单一地塞入单个提示中 [28; 48; 37; 56]。
我们通过 Meta-Harness 解决了这一局限性,这是一个用于通过端到端搜索优化套件的代理型套件(图 2)。它的提议者是一个编码代理,即一个可以调用开发者工具和修改代码的基于语言模型的系统。选择编码代理(而非原始 LLM)很重要,因为经验积累的速度很快会超过上下文限制,所以提议者必须决定检查什么,并通过与代码库的直接交互来验证修改。其关键设计选择是通过文件系统暴露完整的历史记录,从而能够选择性地诊断原始的先前代码和执行轨迹,而不是从压缩的每个候选摘要中进行优化。对于每一个先前的候选套件,文件系统都存储其源代码、评估分数和执行轨迹,提议者通过标准操作(如 grep 和 cat)而非将它们作为一个单一的提示来摄取这些信息。在实践中,在我们要求最高的设置中,提议者每次迭代读取中位数 82 个文件,引用超过 20 个先前的候选方案(附录 A)。在我们研究的设置中,
表 1:文本优化方法及其设置的比较。每行代表跨任务汇总的一种方法。Mtok/iter 是我们对每篇论文中考虑的最大设置下,单次评估一个文本工件所产生的完整上下文的最佳估计。本论文考虑的设置中,每次工件评估产生的上下文比之前的方法大几个数量级。
| 方法 | 历史 | 日志内容 | Mtok/iter |
|---|---|---|---|
| OPRO [51] | 窗口 | 过去的(解决方案,分数)对 | 0.002 |
| TextGrad [53] | 最后 | 对当前工件的文本反馈 | 0.015 |
| AlphaEvolve [35] | 窗口 | 程序数据库 + 评估分数 | 0.022 |
| GEPA [1] | 摘要 | 来自执行轨迹的反思性反馈 | 0.008 |
| Feedback Descent [26] | 摘要 | 比较 + 文本反馈 | 0.012 |
| TTT-Discover [54] | 窗口 | 之前的解决方案片段 | 0.026 |
| Meta-Harness | 完整 | 所有日志和分数 | 10.0 |
===== 第 3 页 =====
一次评估可以产生高达 10,000,000 个令牌的诊断信息,大约比先前文本优化设置中使用的最大反馈预算大三个数量级(表 1)。
我们在在线文本分类、数学推理和代理编码上评估了 Meta-Harness。在在线文本分类上,Meta-Harness 发现的套件比 Agentic Context Engineering (ACE, Zhang et al. [59]) 提高了 7.7 个点,同时使用的上下文令牌数减少了 (4 \times),并且仅用 4 次提议就达到了次优文本优化器 60 次提议后的最终性能(图 1)。在检索增强的数学推理上,单个发现的套件在 200 个 IMO 水平的问题上,平均准确率提高了 4.7 个点,这一结果在五个未见的模型上成立。在 TerminalBench-2 上,发现的套件超越了 Terminus-KIRA,并在所有 Haiku 4.5 代理中排名第一。
2 相关工作
在高层次上,Meta-Harness 将更广泛的信用分配和元学习文献中的思想 [40; 46; 3; 17; 44; 2] 带入了由编码代理最新进展所实现的新场景中。该系统不是更新模型权重,而是在套件层面分配信用:它利用过去执行的经验来仔细推理哪些步骤和组件导致了失败,然后重写控制未来行为的外部代码。更具体地说,该方法位于几个近期研究方向的交叉点;它与自适应访问外部上下文、可执行代码搜索和文本优化的工作关系最密切。
外部记忆和自适应访问。 几项先前的工作指出,将大型知识源或长输入视为语言模型自适应访问的外部资源(而非一次性消费它们)是有益的。具体来说,检索增强生成 [28]、检索与推理交错 [48]、基于记忆的代理 [37] 或递归语言模型 [56] 是自适应访问外部上下文的机制。Meta-Harness 使用了类似的访问模式,但在更具挑战性的套件工程环境中,提议者有选择地检查代码、分数和执行轨迹的大型外部历史记录,以改进上下文管理过程本身。
可执行代码搜索。 近期的方法搜索函数、工作流或代理设计的可执行代码。早期工作提出使用大型模型作为进化程序搜索中的变异和交叉算子 [27]。后来的方法在固定程序框架内进化指定函数 [39],使用元代理从先前的发现中编程新的代理 [20],或搜索代理系统的工作流图 [58]。另一项工作搜索持续学习代理的记忆设计,其中记忆跨任务流持续存在 [57; 50]。相比之下,Meta-Harness 搜索特定领域的套件,包括提示构建、检索和在任务间重置的状态更新策略。它的外部循环有意保持最小化:它不依赖于固定框架、先前发现的存档或持久记忆机制,而是让提议者无限制地访问文件系统中的先前经验。这让代理决定检查哪些信息,并能够搜索完整的套件实现,而不是预定义的上下文管理过程空间。
文本优化方法。 Meta-Harness 也与 ProTeGi、TextGrad、OPRO、GEPA、AlphaEvolve/OpenEvolve 和 Feedback Descent 等方法密切相关,这些方法利用先前尝试的反馈迭代改进提示或其他文本工件 [38; 31; 53; 51; 1; 35; 43; 26]。然而,这些方法不太适合套件工程,因为优化目标是完整的可执行过程,而相关的环境反馈分布在代码、分数和执行轨迹中,这些信息很难事先总结。与仅对标量分数或摘要做出反应不同,Meta-Harness 中的提议者可以推理失败的示例及其执行轨迹,以提出有针对性的编辑。有关这些论文和我们论文中考虑的问题规模的比较,请参见表 1;有关在我们问题设置中与 OpenEvolve、GEPA 和 TTT-Discover 的直接比较,请参见图 1 和图 4。
===== 第 4 页 =====
3 Meta-Harness:用于优化套件的套件
本节介绍 Meta-Harness,我们的用于搜索特定任务套件的外部循环过程。Meta-Harness 建立在这样一个思想之上:套件优化受益于允许提议者通过文件系统有选择地检查先前的代码和执行轨迹,而不是从有损摘要或额外的手工设计搜索结构中进行优化。在高层次上,它重复地提出、评估和记录新的套件。
Meta-Harness 本身就是一个广义上的套件(因此得名),因为它决定了提议者在搜索过程中看到哪些信息。除非另有说明,我们使用术语“套件”来指代正在优化的特定任务程序。
目标。 套件是一个有状态程序,它包装了一个语言模型,并决定了模型在每个步骤中看到哪些上下文。目标很简单:找到能使底层模型在目标任务分布上表现最佳的套件。形式上,令 (M) 表示一个固定的语言模型,(\mathcal{X}) 表示一个任务分布。对于一个套件 (H) 和一个任务实例 (x\sim \mathcal{X}),我们执行一个执行轨迹 (\tau \sim p_{M}(H,x))。套件为 (M) 构建提示,模型响应,并且套件在每次交互后更新其状态。特定任务的奖励函数 (r(\tau ,x)) 对轨迹进行评分。套件优化的目标是找到最大化期望最终奖励的套件:
[H^{*} = \underset {H}{\arg \max}\mathbb{E}{x\sim \mathcal{X},\tau \sim p{M}(H,x)}r(\tau ,x),]
当多个目标相关时(例如,准确率和上下文成本),我们根据帕累托支配关系评估候选方案,并报告最终的前沿。在实践中,这种搜索传统上由人类工程师和研究人员执行,他们手动迭代地精炼提示、上下文管理规则和工具使用逻辑。
Meta-Harness 搜索循环。 Meta-Harness 使用一个单一的编码代理提议者,该提议者可以访问一个不断增长的文件系统 (\mathcal{D}),该文件系统作为其反馈通道1。在这里,编码代理是一个可以调用开发者工具和修改代码的基于语言模型的系统。与将改进逻辑外部化到手工设计搜索循环中的先前系统不同,Meta-Harness 将诊断和提议委托给编码代理本身:它决定检查哪些先前的工件,解决哪些失败模式,以及是进行局部编辑还是更重大的重写。等价地,提议者不是在外层循环组装好的固定提示上操作的原始下一个令牌模型;它是一个检索信息、导航先前的工件并在搜索过程中编辑代码的代理。每个被评估的套件都会贡献一个包含其源代码、分数和执行轨迹(例如提示、工具调用、模型输出和状态更新)的目录。文件系统通常远大于提议者的上下文窗口,因此提议者通过 grep 和 cat 等终端工具查询它,而不是将其作为单个提示来摄取。在每次迭代中,提议者首先检查先前的代码、分数和执行轨迹,然后在生成新套件之前推理可能的失败模式。
Meta-Harness 维护一个种群 (\mathcal{H}) 和评估过的套件上的帕累托前沿,但不施加父代选择规则:提议者可以自由检查任何先前的套件及其执行轨迹来提出新的套件。我们运行固定次数的进化迭代,并在帕累托前沿上进行最终的测试集评估。这种简单性是经过深思熟虑的:通过将诊断和编辑决策留给提议者而不是硬编码搜索启发式规则,Meta-Harness 可以随着编码代理变得更强大而自动改进。提议者永远不会看到测试集结果;它唯一的反馈来自搜索集(用于评估候选套件并生成改进反馈信号的任务实例子集)以及在那些搜索运行期间记录的执行轨迹。
代码空间搜索的优势。 套件优化发生在代码空间中,其中对检索、记忆或提示构建逻辑的小改动可能会影响很多步骤之后的行为,这使得局部搜索启发式规则不太适合这个问题。通过检查执行
===== 第 5 页 =====
轨迹,提议者通常可以推断出套件失败的原因以及哪些早期设计选择可能导致失败,而不仅仅是知道它失败了,如附录 A 和 A.2 中的搜索轨迹所示。在那里,我们看到提议者广泛地阅读先前的代码和日志,然后使用这些轨迹来识别混杂的编辑、隔离可能的因果变化,并在反复出现回归后转向更安全的修改。因此,提议者可以在算法结构层面上修改套件,从更改检索、记忆或提示构建逻辑到完整的程序重写,而不是填充模板或应用预定义的变异算子。在实践中,它通常从一个强大的先验套件开始,但这是一个涌现的策略,而不是硬编码的规则。尽管搜索空间很大,但将套件表示为程序提供了一种自然的正则化偏差:编码模型倾向于提出连贯的算法而不是脆弱的、硬编码的解决方案,这使搜索偏向于可重用的上下文管理过程。这个动作空间与前沿编码助手所训练的可读-可写-可执行工作流密切相关。
实际实现。 在我们的实验中,每个套件都是一个单文件的 Python 程序,它修改特定任务的提示、检索、记忆和编排逻辑。在我们的实验中,提议者 (P) 是带有 Opus-4.6 的 Claude Code [4]。提议者由一个最小的领域特定技能(skill)引导,该技能描述了在哪里编写新套件、如何检查以前的套件及其执行轨迹,以及它可以和不可以修改哪些文件。基础模型 (M) 因领域而异,并且始终保持冻结;详见第 4 节。在我们的实验中,一次典型运行评估大约 60 个套件,迭代 20 次。我们在附录 D 中提供了在新领域实现 Meta-Harness 的额外技巧。
4 实验
我们在三个任务领域评估了 Meta-Harness:在线文本分类、数学推理和代理编码。在每个领域中,我们将搜索发现的套件与使用标准评估指标的领域适当基线进行比较。请参考每个小节了解精确的实验设置。
我们比较了两大类方法。(1) 人工设计策略:这些是针对此问题领域的手工制作的套件,代表了上下文构建的当前最先进水平。我们在相应的小节中描述这些基线。(2) 程序搜索方法:这些方法使用反馈和奖励信号搜索候选套件,但设计用于比套件工程规模更小的场景。
4.1 在线文本分类
我们遵循 Zhang et al. [59]; Ye et al. [52] 的在线文本分类设置:一个 LLM 一次接收一个带标签的示例,更新其记忆,并在留出的测试集上进行评估。我们使用 GPT-OSS-120B 作为 LLM 文本分类器,并考虑设计用于文本分类的套件的问题。我们使用了三个数据集,选择它们是因为其难度和领域多样性:LawBench (Law) [16] 从案例描述预测刑事指控(215 个类别);Symptom2Disease (S2D) [19] 从症状描述预测疾病(22 个类别);USPTO-50k [41] 从产品分子预测前体反应物(180 个类别)。我们从该设置中的主要基线套件初始化搜索种群 (\mathcal{H}):零样本、少样本、ACE 和 MCE。我们运行了 20 次进化迭代,每次迭代两个候选方案,产生了 40 个候选套件。
与文本优化器的比较。 我们将 Meta-Harness 与代表性的文本优化方法进行了比较。为了公平比较,我们使用相同的提议者配置(Opus-4.6,最大推理),仅基于搜索集性能选择候选方案,并保持测试集直到最终评估。由于评估是主要的计算瓶颈,我们给予每种方法相同数量的提议套件评估预算。我们考虑以下比较点:
- Best-of-N:从种子中独立采样,没有搜索结构;一个计算匹配的对照,用以检验搜索是否重要。
- OpenEvolve [43]:使用 LLM 变异对程序进行进化搜索。
- TTT-Discover [55]:我们只使用其方法的文本优化组件,即通过 PUCT 复用规则进行提议选择。
在这个设置中,Meta-Harness 以 (0.1\times) 的评估次数就达到了先前最佳文本优化器(OpenEvolve, TTT-Discover)的最终性能,并且其最终准确率超过它们 10 多个点(图 1 和表 4)。我们将这种加速归因于在第 3 节中描述的有意设计选择,这些选择对外部循环施加了最小的必要结构。特别是,Meta-Harness 使用文件系统保留了完整的经验历史,并允许提议者检查任何必要的东西,而 OpenEvolve 和 TTT-Discover 都使用更具结构化和更有限制的提议者输入(而非完全的文件系统访问)。我们注意到在线文本分类是我们研究的最小上下文设置(表 1),因此如果结构繁重的文本优化器在此处已经落后,它们的局限性在更困难的场景中可能只会扩大。
Meta-Harness 速度提高 10 倍并收敛到更好的套件
在此设置中,Meta-Harness 以少 10 倍的全评估次数达到先前最佳文本优化器(OpenEvolve, TTT-Discover)的最终性能,其最终准确率超过它们 10 多个点。
为了隔离提议者接口的哪些部分最重要,我们在在线文本分类中比较了三种条件:仅分数条件、提议者接收 LLM 生成的摘要但无原始轨迹的分数加摘要条件,以及具有执行轨迹访问权限的完整 Meta-Harness 接口(表 3)。结果显示完整接口有巨大优势:仅分数达到中位数 34.6 和最佳 41.3 的准确率,而分数加摘要达到中位数 34.9 和最佳 38.7。相比之下,Meta-Harness
===== 第 6 页 =====
表 2:三个数据集上所有套件的测试集指标。Ctx 表示上下文中额外的千个令牌。(\dagger):来自 Ye et al. [52] 的实现。(\downarrow):越低越好。Meta-Harness 提高了在线文本分类的准确率,同时使用了更小的输入上下文。
达到中位数 50.0 和最佳 56.7 的准确率,其甚至中位数候选方案也优于在任一消融条件下找到的最佳候选方案。我们将此解释为证据,表明对完整执行轨迹的访问是接口最重要的组成部分:摘要不能恢复缺失的信号,甚至可能因压缩掉诊断上有用的细节而有害。
表 3:在线文本分类中提议者可用信息的消融研究。(>) ZS:准确率超过零样本基线的运行次数。完整的 Meta-Harness 接口显著优于仅分数和分数加摘要的消融版本。访问原始执行轨迹是实现套件搜索的关键要素。
| 条件 | 中位数准确率 | 最佳准确率 | > ZS |
|---|---|---|---|
| 仅分数 | 34.6 | 41.3 | 1/4 |
| 分数+摘要 | 34.9 | 38.7 | 1/4 |
| Meta-Harness (完整) | 50.0 | 56.7 | 4/4 |
与最先进的套件比较。 我们的主要比较点是针对此问题领域的手工设计套件:Agentic Context Engineering (ACE, Zhang et al. [59]),它使用反思性记忆管理来随时间构建上下文,以及 Meta Context Engineering (MCE, Ye et al. [52]),它维护并演化一个用于上下文构建的自然语言技能库。作为额外的基线,我们评估了零样本提示和具有 (N \in {4,8,16,32, \text{all}}) 个示例的少样本提示。表 2 中的结果表明,Meta-Harness 相比先前的手工设计套件有显著改进。选定的 Meta-Harness (^{2}) 达到了 48.6% 的准确率,比 ACE 高出 7.7 个点,比 MCE 高出 8.6 个点。这些增益并非来自使用更多的上下文:Meta-Harness 仅使用 11.4K 上下文令牌,而 ACE 为 50.8K,MCE 为 28.5K。
表 4:不同文本优化器提出的套件在文本分类上的准确率(搜索集)。Meta-Harness 在套件优化方面明显更有效。
| 方法 | 中位数 | 最佳 |
|---|---|---|
| GEPA [1] | 32.6 | 40.2 |
| Best-of-N | 34.0 | 44.2 |
| OpenEvolve [43] | 39.1 | 43.3 |
| TTT-Discover [55] | 34.1 | 45.6 |
| Meta-Harness | 50.0 | 56.7 |
准确率-上下文权衡。 由于 Meta-Harness 对套件代码执行自由形式的优化,我们可以表达对准确率和上下文成本的联合偏好,而不是预先承诺单一的标量目标。仅给定当前指标和所需的权衡,提议者能够发现跨越前沿广泛范围的套件,在图 3 中产生平滑的准确率-上下文帕累托曲线。这使我们能够以受控方式用额外的上下文换取更高的测试准确率,而不是承诺单一的手工设计操作点。
分布外(OOD)任务评估。 我们评估发现的套件是否能泛化到搜索期间未见过的全新数据集。我们考虑了九个不同的数据集,并在附录 C.1 中详细描述了它们。选定的 Meta-Harness 系统实现了最佳平均准确率(73.1%),优于 ACE(70.2%)和所有少样本基线(表 5)。值得注意的是,我们观察到在 7/9 的任务中,天真地添加超过 32 个少样本示例会损害性能。Meta-Harness 在 6/9 的数据集上显示出最高性能,这表明发现的套件捕捉到了文本分类的通用有效策略,而不是过度拟合到搜索中使用的特定数据集。
| 套件 | SciCite | FiNER | Amz5 | FPB | GoEmo | Bank77 | News | SciTail | TwHate | 平均准确率 | Ctx↓ |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Zero-shot | 32.7 | 56.0 | 52.7 | 90.0 | 42.0 | 80.7 | 84.7 | 89.3 | 75.3 | 67.0 | - |
| Few-shot (8) | 34.0 | 63.0 | 54.0 | 90.0 | 44.0 | 82.7 | 84.7 | 91.3 | 76.7 | 68.9 | 2.2 |
| Few-shot (32) | 38.7 | 62.0 | 53.3 | 90.7 | 43.3 | 86.0 | 85.3 | 90.7 | 76.7 | 69.6 | 5.2 |
| Few-shot (all) | 35.3 | 61.0 | 50.0 | 93.3 | 42.7 | 80.7 | 84.0 | 90.0 | 76.7 | 68.2 | 7.4 |
| ACE [59] | 40.7 | 74.0 | 48.0 | 96.7 | 44.0 | 83.3 | 86.0 | 90.7 | 68.7 | 70.2 | 11.7 |
| Meta-Harness | 53.3 | 67.0 | 60.0 | 94.0 | 46.0 | 82.7 | 86.7 | 91.3 | 77.3 | 73.1 | 7.3 |
===== 第 7 页 =====
4.2 用于检索增强推理的套件
我们研究了一个在奥赛数学求解方面有些非标准的设置:增强模型从大型语料库中检索示例的能力。原则上,有充分理由期望检索能帮助数学推理,因为解决方案经常共享可重用的证明模式,所以先前的推理轨迹包含模型可能能够利用的信息。然而,检索尚未成为此设置中的标准组成部分,先前的研究表明,在推理密集的数学基准测试上,检索的成功率远低于事实密集的领域 [42; 49; 6]。困难在于,天真的检索很少能以正确的形式呈现正确的轨迹。这表明成功较少依赖于增加检索本身,而更多依赖于发现正确的检索策略。我们没有手工设计该策略,而是给 Meta-Harness 一组硬性的奥赛问题,并允许检索行为本身从搜索中涌现。
检索语料库包含来自八个开源数据集的 (\geq 500,000) 个已解决问题。我们仔细地进行了去重和去污染,针对评估基准和搜索集进行了处理,确认在我们基于字符串的过滤器下,留出问题没有精确的前缀匹配,并手动检查了留出示例的顶部 BM25 检索结果(附录 C.2)。我们使用 Meta-Harness 优化一个套件,在 250 个奥赛难度数学问题(OlympiadBench + Omni-MATH hard)的搜索集上进行了 40 次迭代,产生了 109 个候选检索套件。我们从此设置中的主要基线套件初始化搜索种群 (\mathcal{H}):零样本、少样本和 ACE。我们基于使用 GPT-OSS-20B 的搜索集性能选择一个套件(附录 B.2)。我们在 200 个来自 IMO-AnswerBench、IMO-ProofBench 和 ArXivMath [30; 6] 的先前未见过的 IMO 水平问题上评估此套件。除了 GPT-OSS-20B,我们还在四个搜索期间未见过的模型上评估了相同的检索套件:GPT-5.4-nano、GPT-5.4-mini、Gemini-3.1-Flash-Lite 和 Gemini-3-Flash。我们遵循先前工作的标准评估协议 [30],并报告每个问题三个样本的平均准确率。
结果。 表 6 比较了发现的套件与无检索、使用单独嵌入模型 text-embedding-3-small 的密集检索、随机少样本提示和 BM25 检索。相比之下,Meta-Harness 完全在代码空间中操作,在相同的基于 BM25 的词法检索栈之上运行,作为稀疏基线。发现的检索套件在所有五个未见的模型上都优于无检索基线,平均增益为 4.7 个点。它在平均水平上达到或超过了最强的固定基线,整体上优于 BM25 检索 1.3 个点,同时避免了在几个模型上观察到的密集检索和随机少样本提示带来的性能退化。
Meta-Harness 改进 IMO 水平数学问题的推理
在检索增强的数学推理中,单个发现的检索套件可迁移到五个未见的模型,平均准确率比无检索提高 4.7 个点,并且在比较的方法中取得了最强的整体平均水平。
表 6:在 200 个 IMO 水平数学问题上的检索增强数学问题求解。我们显示了三个样本 per 问题的 pass@1 平均值,括号内为相对于基线的绝对改进。发现的 Meta-Harness 检索策略在所有五个未见的模型上改进了这些 IMO 水平问题的推理,相对于无检索器平均提高了 4.7 个点。
| 方法 | GPT-5.4n | GPT-5.4m | Gem-3.1FL | Gem-3F | GPT-20B | 平均 |
|---|---|---|---|---|---|---|
| 无检索器 | 23.0 | 28.8 | 28.6 | 42.6 | 47.6 | 34.1 |
| 密集检索 (k=1) | 27.1 (+4.1) | 24.5 (+4.3) | 31.3 (+2.7) | 42.3 (+0.3) | 46.9 (+0.7) | 34.4 (+0.3) |
| 密集检索 (k=5) | 31.1 (+8.1) | 28.3 (+0.5) | 37.1 (+8.5) | 47.2 (+4.6) | 46.7 (+0.9) | 38.1 (+4.0) |
| 随机少样本 | 23.1 (+0.1) | 24.5 (+4.3) | 31.0 (+2.4) | 40.4 (+2.2) | 41.8 (+5.8) | 32.2 (+1.9) |
| BM25 检索 | 30.2 (+7.2) | 29.2 (+0.4) | 32.8 (+4.2) | 46.6 (+4.0) | 48.9 (+1.3) | 37.5 (+3.4) |
| Meta-Harness | 31.7 (+8.7) | 30.4 (+1.6) | 34.9 (+6.3) | 46.3 (+3.7) | 50.6 (+3.0) | 38.8 (+4.7) |
===== 第 8 页 =====
4.3 在 TerminalBench-2 上评估代理编码套件
TerminalBench-2 [33] 在 89 个具有挑战性的任务上评估 LLM 代理,这些任务需要在复杂的依赖关系下进行长时程、完全自主的执行,并且需要大量的领域知识。先前的工作已经表明,代理套件的选择对此基准测试的性能有很大影响。我们从两个强大的开放基线 Terminus 2 [33] 和 Terminus-KIRA [25] 初始化搜索。对于此实验,我们在相同的 89 任务基准测试上进行搜索和最终评估。我们将此基准测试作为一个发现问题 [54],目标是发现一个能提高在公开竞争激烈的基准测试上性能的套件配置。这是标准做法:公开的文档已经描述了在 TerminalBench 本身上重复进行的特定基准测试套件迭代 [18; 34; 25],并且该基准测试规模小且成本高,引入单独的数据分割会实质性地削弱搜索信号。我们另外通过手动检查和基于正则表达式的审计来检查过度拟合,以防止任务特定的字符串泄漏到进化的套件中。我们注意到,尽管最终得到的套件专门针对 TerminalBench-2 环境,但从单一指令自主完成困难的长期任务是核心能力,并且该基准测试包含许多前沿模型和高度工程化的套件都难以应对的任务。
结果。 我们在表 7 中报告了完整基准测试的结果,在两个基础模型上进行了评估:Claude Opus 4.6 和 Claude Haiku 4.5。在 Opus 4.6 上,Meta-Harness 发现了一个达到 (76.4%) 通过率的套件,超越了手工设计的 Terminus-KIRA ((74.7%)),并在 TerminalBench-2 排行榜上的所有 Opus 4.6 代理中排名第二。唯一得分更高的 Opus 4.6 代理是 ForgeCode ((81.8%));然而,我们无法仅从公开可用的代码中复现他们报告的结果,这表明他们的排行榜分数依赖于已发布仓库之外的组件。在较弱的 Haiku 4.5 模型上,改进更大:Meta-Harness 达到了 (37.6%),比次优报告代理(Goose,(35.5%))高出 2.1 个点。TerminalBench-2 是一个活跃竞争的基准测试,多个团队直接为其进行优化,因此一个自动化搜索方法能够在这个前沿领域取得收益,这对于长期文本优化循环来说是令人鼓舞的。
提议者的定性行为。 套件搜索轨迹有助于解释为什么 Meta-Harness 能取得这些增益;我们在附录 A 中提供了详细的总结。在早期迭代中,提议者将看似合理的结构修复与提示模板编辑结合起来,并观察到两个候选方案都出现了退化。然后它明确假设退化是由共享的提示干预所混淆,将结构更改与提示重写隔离开,并最终转向一个更安全的附加修改,该修改成为运行中最好的候选方案。这提供了定性证据,表明文件系统访问使提议者能够足够详细地检查先前的经验,以形成因果假设并相应地修改套件。
| 套件 | 自动通过率 (%) |
|---|---|
| Claude Opus 4.6 | |
| Claude Code | × 58.0 |
| Terminus 2 | × 62.9 |
| Mux | × 66.5 |
| Droid | × 69.9 |
| TongAgents | × 71.9 |
| MAYA-V2 | × 72.1 |
| Terminus-KIRA | × 74.7 |
| Capy | × 75.3 |
| ForgeCode | × 81.8 |
| Meta-Harness | ✓ 76.4 |
| Claude Haiku 4.5 | |
| OpenHands | × 13.9 |
| Claude Code | × 27.5 |
| Terminus 2 | × 28.3 |
| Mini-SWE-Agent | × 29.8 |
| Terminus-KIRA | × 33.7 |
| Goose | × 35.5 |
| Meta-Harness | ✓ 37.6 |
表 7:TerminalBench2 上的通过率。其他结果来自官方排行榜。Meta-Harness 在所有 Opus-4.6 代理中排名第二,在所有 Haiku-4.5 代理中排名第一。
认为退化是由共享的提示干预所混淆,将结构更改与提示重写隔离开,并最终转向一个更安全的附加修改,该修改成为运行中最好的候选方案。这提供了定性证据,表明文件系统访问使提议者能够足够详细地检查先前的经验,以形成因果假设并相应地修改套件。
Meta-Harness 在 TerminalBench-2 上超越手工设计的代理
在 TerminalBench-2 上,Meta-Harness 自动发现的套件在 Opus 4.6 上超越了 Terminus-KIRA,并在所有 Haiku 4.5 代理中排名第一。
===== 第 9 页 =====
5 讨论
除了优于现有的套件之外,Meta-Harness 还有几个实际优势。发现的套件可以泛化到分布外的分类数据集(表 5)以及数学设置中未见的基础模型(表 6)。一次搜索运行只需几小时的挂钟时间,却能产生可读的、可迁移的策略,这些策略可以跨模型重用,包括未来更强的模型。代码空间中的过拟合也更容易检查:脆弱的 if 链或硬编码的类别映射在检查时是可见的,而权重空间中的过拟合则不然。更广泛地说,我们的结果表明,Meta-Harness 的主要优势不仅仅在于代码搜索,而在于带有选择性访问历史诊断经验的搜索。提议者不限于标量奖励或固定摘要;它可以检查原始代码、执行轨迹和先前的失败,然后利用这些信息来形成和测试关于更改内容的假设。附录 A.2 中的定性搜索轨迹直接展示了这种行为。
我们的发现反映了机器学习中一个反复出现的模式 [45]:一旦搜索空间变得可访问,更强的通用代理就能胜过手工设计的解决方案。未来工作一个自然的下一步是共同进化套件和模型权重,让策略塑造模型学习的内容,反之亦然。虽然我们在三个不同的领域进行了评估,但我们的实验证明套件搜索可以在一个特别强大的编码代理提议者(Claude Code)上工作;关于效果如何随提议者代理变化而变化的更广泛研究仍有待未来工作。
===== 第 10 页 =====
致谢
我们感谢 KRAFTON AI 提供的 API 积分支持。这项工作得到了 OpenAI、KFAS 和 Schmidt Sciences AI2050 的支持。我们感谢 Anikait Singh 和 Jubayer Ibn Hamid 提供的宝贵反馈和建议,并感谢 Sienna J. Lee 在这项工作早期耐心地倾听 YL 不成熟的想法。
参考文献
[1] Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl- Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning. arXiv preprint arXiv:2507.19457, 2025.
[2] Ekin Akyurek, Dale Schuurmans, Jacob Andreas, Tengyu Ma, and Denny Zhou. What learning algorithm is in- context learning? investigations with linear models, 2023. URL https://arxiv.org/abs/2211.15661.
[3] Marcin Andrychowicz, Misha Denil, Sergio Gomez, Matthew W Hoffman, David Pfau, Tom Schaul, Brendan Shillingford, and Nando De Freitas. Learning to learn by gradient descent by gradient descent. Advances in neural information processing systems, 29, 2016.
[4] Anthropic. Claude code: An agentic coding tool. https://www.anthropic.com/claude - code, 2025.
[5] Anthropic and community contributors. agentskills/agentskills. GitHub repository https://github.com/agentskills/agentskills. Specification and documentation for Agent Skills, accessed March 27, 2026.
[6] Mislav Balunovic, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovic, and Martin Vechev. Matharena: Evaluating llms on uncontaminated math competitions, February 2025. URL https://matharena.ai/.
[7] Francesco Barbieri, Jose Camacho- Collados, Leonardo Neves, and Luis Espinosa- Anke. Tweeteval: Unified benchmark and comparative evaluation for tweet classification, 2020. URL https://arxiv.org/abs/2010.12421.
[8] Luca Beurer- Kellner, Marc Fischer, and Martin Vechev. Prompting is programming: A query language for large language models. Proceedings of the ACM on Programming Languages, 7(PLDI):1946- 1969, June 2023. ISSN 2475- 1421. doi: 10.1145/3591300. URL http://dx.doi.org/10.1145/3591300.
[9] Birgitta Böckeler. Harness engineering. https://martinfowler.com/articles/exploring- gen- ai/harness- engineering.html, March 2026. martinfowler.com.
[10] Can Bölük. I improved 15 LLMs at coding in one afternoon. only the harness changed. https://blog.can.ac/2026/02/12/the- harness- problem/, February 2026.
[11] Inigo Casanueva, Tadas Teminas, Daniela Gerz, Matthew Henderson, and Ivan Vulić. Efficient intent detection with dual sentence encoders, 2020. URL https://arxiv.org/abs/2003.04807.
[12] Mert Cemri, Shubham Agrawal, Akshat Gupta, Shu Liu, Audrey Cheng, Qiuyang Mang, Ashwin Naren, Lutfi Eren Erdogan, Koushik Sen, Matei Zaharia, et al. Ada- volve: Adaptive llm driven zeroth- order optimization. arXiv preprint arXiv:2602.20133, 2026.
[13] Harrison Chase. Langchain, October 2022. URL https://github.com/langchain- ai/langchain. Software, released 2022- 10- 17.
[14] Arman Cohan, Waleed Ammar, Madeleine van Zuylen, and Field Cady. Structural scaffolds for citation intent classification in scientific publications, 2019. URL https://arxiv.org/abs/1904.01608.
===== 第 11 页 =====
[15] Dorottya Demszky, Dana Movshovitz- Attias, Jeongwoo Ko, Alan Cowen, Gaurav Nemade, and Sujith Ravi. Goemotions: A dataset of fine- grained emotions, 2020. URL https://arxiv.org/abs/2005.00547.
[16] Zhiwei Fei, Xiaoyu Shen, Dawei Zhu, Fengzhe Zhou, Zhuo Han, Alan Huang, Songyang Zhang, Kai Chen, Zhixin Yin, Zongwen Shen, et al. Lawbench: Benchmarking legal knowledge of large language models. In Proceedings of the 2024 conference on empirical methods in natural language processing, pp. 7933- 7962, 2024.
[17] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model- agnostic meta- learning for fast adaptation of deep networks. In International Conference on Machine Learning, 2017.
[18] ForgeCode. Benchmarks don’t matter, 2025. URL https://forgecode.dev/blog/benchmarks- dont- matter/.
[19] Gretel AI. Symptom to diagnosis dataset. https://huggingface.co/datasets/gretelai/symptom_to_diagnosis, 2023. Accessed: 2026- 01- 22.
[20] Shengran Hu, Cong Lu, and Jeff Clune. Automated design of agentic systems. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=t9U3LW7JvX.
[21] Anthropic Justin Young. Effective harnesses for long- running agents. https://anthro pic.com/engineering/effective- harnesses- for- long- running- agents, November 2025. Anthropic Engineering Blog.
[22] Phillip Keung, Yichao Lu, György Szarvas, and Noah A. Smith. The multilingual amazon reviews corpus, 2020. URL https://arxiv.org/abs/2010.02573.
[23] Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. Dspy: Compiling declarative language model calls into self- improving pipelines, 2023. URL https://arxiv.org/abs/2310.03714.
[24] Tushar Khot, Ashish Sabharwal, and Peter Clark. Scitail: A textual entailment dataset from science question answering. Proceedings of the AAAI Conference on Artificial Intelligence, 32(1), Apr. 2018. doi: 10.1609/aaai.v32i1.12022. URL https://ojs.aaai.org/index.php/AAAI/article/view/12022.
[25] KRAFTON AI and Ludo Robotics. Terminus- kira: Boosting frontier model performance on terminal- bench with minimal harness, 2026. URL https://github.com/krafton- a/kira.
[26] Yoonho Lee, Joseph Boen, and Chelsea Finn. Feedback descent: Open- ended text optimization via pairwise comparison. In arXiv preprint arXiv:2511.07919, 2025.
[27] Joel Lehman, Jonathan Gordon, Shawn Jain, Kamal Ndousse, Cathy Yeh, and Kenneth O. Stanley. Evolution through large models, 2022. URL https://arxiv.org/abs/2206.08896.
[28] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Kuttler, Mike Lewis, Wen- tau Yih, Tim Rocktäschel, et al. Retrieval- augmented generation for knowledge- intensive nlp tasks. Advances in neural information processing systems, 33:9459- 9474, 2020.
[29] Lefteris Loukas, Manos Fergadiotis, Ilias Chalkidis, Eirini Spyropoulou, Prodromos Malakasiotis, Ion Androutsopoulos, and Georgios Paliouras. Finer: Financial numeric entity recognition for xbrl tagging. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 4419- 4431. Association for Computational Linguistics, 2022. doi: 10.18653/v1/2022. acl- long.303. URL http://dx.doi.org/10.18653/v1/2022. acl- long.303.
===== 第 12 页 =====
[30] Thang Luong, Dawson Hwang, Hoang H. Nguyen, Golnaz Ghiasi, Yuri Chervoniy, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Clara Huiyi Hu, Henryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu H. Trinh, Quoc V. Le, and Junehyuk Jung. Towards robust mathematical reasoning. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, 2025. URL https://aclanthology.org/2025.emnlp- main.1794/.
[31] Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self- refine: Iterative refinement with self- feedback. Advances in neural information processing systems, 36:46534- 46594, 2023.
[32] Pekka Malo, Ankur Sinha, Pyry Takala, Pekka Korhonen, and Jyrki Wallenius. Good debt or bad debt: Detecting semantic orientations in economic texts, 2013. URL https://arxiv.org/abs/1307.5336.
[33] Mike A Merrill, Alexander G Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E Kelly Buchanan, et al. Terminalbench: Benchmarking agents on hard, realistic tasks in command line interfaces. arXiv preprint arXiv:2601.11868, 2026.
[34] Jack Nichols. How we scored #1 on terminal- bench (52%), Jun 2025. URL https://www.warp.dev/blog/terminal- bench.
[35] Alexander Novikov, Ngân Vũ, Marvin Eisenberger, Emilien Dupont, Po- Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco JR Ruiz, Abbas Mehrabian, et al. Alphaevolve: A coding agent for scientific and algorithmic discovery. arXiv preprint arXiv:2506.13131, 2025.
[36] OpenAI. Harness engineering: leveraging Codex in an agent- first world. https://openai.com/index/harness- engineering/, February 2026. OpenAI Blog.
[37] Charles Packer, Vivian Fang, Shishir G Patil, Kevin Lin, Sarah Wooders, and Joseph E Gonzalez. Memgpt: Towards llms as operating systems. 2023.
[38] Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with “gradient descent” and beam search. arXiv preprint arXiv:2305.03495, 2023.
[39] Bernardino Romera- Paredes, Mohammadamin Barekatain, Alexander Novikov, Matej Balog, M Pawan Kumar, Emilien Dupont, Francisco JR Ruiz, Jordan S Ellenberg, Pengming Wang, Omar Fawzi, et al. Mathematical discoveries from program search with large language models. Nature, 625(7995):468- 475, 2024.
[40] Jurgen Schmidhuber. A neural network that embeds its own meta- levels. In IEEE International Conference on Neural Networks, 1993.
[41] Nadine Schneider, Nikolaus Stiefl, and Gregory A Landrum. What’s what: The (nearly) definitive guide to reaction role assignment. Journal of chemical information and modeling, 56(12):2336- 2346, 2016.
[42] Srijan Shakya, Anamaria- Roberta Hartl, Sepp Hochreiter, and Korbinian Poppel. Adaptive retrieval helps reasoning in llms - but mostly if it’s not used, 2026. URL https://arxiv.org/abs/2602.07213.
[43] Asankhaya Sharma. Openevolve: an open- source evolutionary coding agent. https://github.com/algorithmicsuperintelligence/openevolve, 2025. URL https://github.com/algorithmicsuperintelligence/openevolve. GitHub repository.
[44] Jake Snell, Kevin Swersky, and Richard S. Zemel. Prototypical networks for few- shot learning. In Advances in Neural Information Processing Systems, 2017.
[45] Rich Sutton. The bitter lesson, 2019. URL http://www.incompleteideas.net/Inc Ideas/BitterLesson. html, 2019.
===== 第 13 页 =====
[46] Sebastian Thrun and Lorien Pratt. Learning to learn: Introduction and overview. In Learning to learn, pp. 3- 17. Springer, 1998.
[47] Muxin Tian, Zhe Wang, Blair Yang, Zhenwei Tang, Kunlun Zhu, Honghua Dong, Hanchen Li, Xinxi Xie, Guangjing Wang, and Jiaxuan You. Swe- bench mobile: Can large language model agents develop industry- level mobile applications? In arXiv preprint, 2026. URL https://api.semanticscholar.org/CorpusID:285462974.
[48] Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain- of- thought reasoning for knowledge- intensive multi- step questions, 2023. URL https://arxiv.org/abs/2212.10509.
[49] Chenghao Xiao, G Thomas Hudson, and Noura Al Moubayed. Rar- b: Reasoning as retrieval benchmark, 2024. URL https://arxiv.org/abs/2404.06347.
[50] Yiming Xiong, Shengran Hu, and Jeff Clune. Learning to continually learn via meta- learning agentic memory designs. In OpenReview, 2026. URL https://api.semanticscholar.org/CorpusID:285454009.
[51] Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V Le, Denny Zhou, and Xinyun Chen. Large language models as optimizers. In The Twelfth International Conference on Learning Representations, 2023.
[52] Haoran Ye, Xuning He, Vincent Arak, Haonan Dong, and Guojie Song. Meta context engineering via agentic skill evolution. arXiv preprint arXiv:2601.21557, 2026.
[53] Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. Textgrad: Automatic “differentiation” via text, 2024. URL https://arxiv.org/abs/2406.07496.
[54] Mert Yuksekgonul, Daniel Kocja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, and Yu Sun. Learning to discover at test time, 2026. URL https://arxiv.org/abs/2601.16175.
[55] Mert Yuksekgonul, Daniel Kocja, Xinhao Li, Federico Bianchi, Jed McCaleb, Xiaolong Wang, Jan Kautz, Yejin Choi, James Zou, Carlos Guestrin, et al. Learning to discover at test time. arXiv preprint arXiv:2601.16175, 2026.
[56] Alex L. Zhang, Tim Kraska, and Omar Khattab. Recursive language models, 2026. URL https://arxiv.org/abs/2512.24601.
[57] Guibin Zhang, Haotian Ren, Chong Zhan, Zhenhong Zhou, Junhao Wang, He Zhu, Wangchunshu Zhou, and Shuicheng Yan. Memevolve: Meta- evolution of agent memory systems. arXiv preprint arXiv:2512.18746, 2025.
[58] Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xionghui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, Bingnan Zheng, Bang Liu, Yuyu Luo, and Chenglin Wu. Aflow: Automating agentic workflow generation, 2025. URL https://arxiv.org/abs/2410.10762.
[59] Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, V. Kamanuru, Jay Raintom, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and K. Olukotun. Agentic context engineering: Evolving contexts for self- improving language models. In arXiv preprint arXiv:2510.04618, 2025.
[60] Xiang Zhang, Junbo Zhao, and Yann LeCun. Character- level convolutional networks for text classification, 2016. URL https://arxiv.org/abs/1509.01626.
===== 第 14 页 =====
A 提议者定性行为
本节考察提议者在搜索过程中如何使用文件系统,基于 TerminalBench-2 运行(10 次迭代,Claude Opus 4.6)。
A.1 文件访问统计
为了验证提议者实质性地使用了文件系统而非默认进行局部编辑,我们记录了每次迭代的所有文件读取。
表 8 总结了结果。提议者每次迭代读取中位数 82 个文件(范围 69-99),大致平均分布在先前的套件源代码(41%)和执行轨迹(40%)之间,其余部分用于分数摘要(6%)和其他文件(13%)。这证实了提议者的访问模式是非马尔可夫的:它通常会检查大部分可用的历史记录,而不仅仅是最近一次父代的信息。
| 统计量 | 值 |
|---|---|
| 每次迭代读取的文件数(中位数) | 82 |
| 每次迭代读取的文件数(范围) | 69–99 |
| 文件类型细分 | |
| 套件源代码 | 41% |
| 执行轨迹 | 40% |
| 分数/摘要文件 | 6% |
| 其他 | 13% |
表 8:TerminalBench-2 搜索运行(10 次迭代,Claude Opus 4.6)的提议者文件访问统计。提议者广泛地从文件系统中读取,对先前的源代码和执行轨迹的关注大致相等。
===== 第 15 页 =====
A.2 定性行为:对先前失败的因果推理
TerminalBench-2 的搜索日志揭示了一个清晰的叙事弧线,其中提议者从自己的退化中学习。它没有在局部编辑中随机游走,而是形成了一个关于早期候选方案为何失败的明确诊断,然后转向更安全的设计模式。下面日志框内的所有文本均逐字引自提议者在每次迭代中记录的推理(强调部分为原文所有)。
迭代 1-2:有前途的错误修复被提示编辑混淆。 前两次迭代都将看似合理的结构修复与提示模板修改捆绑在一起,并且都从 (64.4%) 的 Terminus-KIRA 基线急剧退化。迭代 1 针对来自泄漏终端标记的观察污染,并添加了一个循环中断器:
假设:CMDEN 标记片段泄漏到长期运行任务的 LLM 观察中,导致模型混淆并进入无限无工具调用循环。剥离这些标记 + 添加循环中断器将恢复浪费的步骤。
该候选方案还引入了一个新的以清理为导向的提示模板和一个验证检查清单。迭代 2 提出了一个不同的状态机修复:
双重确认完成机制导致验证循环。在轨迹中观察到,代理提前解决了任务,但每个验证命令都会重置 pending completion,需要另一个 task_complete → checklist → verify 循环,从而额外消耗 15-40+ 步。
第二个候选方案完全移除了待完成机制,同时保留了标记剥离和新提示。它仍然退化,这给了提议者两个具有不同结构更改但共享一个提示干预的失败候选方案。
迭代 3:提议者识别出混杂因素。 到迭代 3 时,提议者明确推断退化主要不是由于结构错误修复本身:
先前的尝试:evo_marker_fix (58.9%, -5.6pp), evo_single.confirm (57.8%, -6.7pp) —— 两者都退化了。退化的根本原因:提示模板更改(清理指令)导致代理在完成任务前删除了必要的状态。结构错误修复与有害的提示更改混杂在一起。evo_strip_only 隔离了两个经过验证的结构修复。
这是轨迹中的关键因果步骤。提议者注意到前两次失败的共同因素不是特定的错误修复,而是以清理为重点的提示重写。因此,它恢复到原始提示,并仅测试标记剥离和循环中断器。结果候选方案仍然略逊一筹((63.3%) -1.1pp),但比早期版本损失小得多,这支持了混杂诊断。
迭代 4-6:对已诊断故障模式的直接修复仍然退化。 接下来的三次迭代继续探索设计空间的同一部分,但现在对完成逻辑为何脆弱有了更明确的理论。迭代 4 将失败归因于一个具体的状态机错误,其中验证命令重置完成标志并将代理困在重复的检查清单循环中:
删除重置完成标志的两行 self._pending_completion ≡ False。这修复了一个状态机错误:(1) 代理调用 task_complete → 看到 QA 检查清单,_pending_completion ≡ True (2) 代理运行验证命令 → _pending_completion ≡ False(错误!)(3) 代理再次调用 task_complete → 再次看到检查清单 → 无限循环。
提议者甚至引用了具体的轨迹证据,指出 configure-git-webserver 在有效解决问题后,代理陷入 30-60 步验证旋涡,产生了基线失败。迭代 5 尝试在保留
===== 第 16 页 =====
确认机制的同时软化清理语言,但仍然编辑了提示并严重退化。迭代 6 返回到更安全的 evo_strip_only 基础,并提出了一个系统级优化:
当终端输出未更改时,空命令会浪费完整的 LLM 往返。智能等待(在下次 LLM 调用前轮询面板最多 (3\times 5) 次)可在长期运行任务上节省 5-15 轮。
该更改也退化了。至此,提议者学到了一个具体的经验教训:修改提示和完成流程风险很高,即使局部假设听起来合理。
迭代 7:获胜的候选方案。 在连续六次退化之后,提议者将策略从修改控制循环转变为在循环开始前添加信息:
所有 6 次先前迭代都从 64.4% 的基线退化了,因为它们修改了完成流程、提示模板或观察处理。evo_env_bootstrap 采用了一种不同的方法——纯粹是附加性的。它在第一次 LLM 调用之前通过单个 shell 命令收集环境快照,并将其附加到初始提示中。没有其他方法被更改。这应该可以在依赖关系重的任务上消除 3-5 轮浪费的探索回合,而不会在已经通过的任务上带来退化风险。
该候选方案是迄今为止最好的结果。重要的不仅仅是迭代 7 获胜,而是提议者阐述了为什么它应该更安全:它避免了触及先前脆弱的完成机制,而是添加了主要在困难任务上有用的信息。
迭代 8:组合。 在找到一个附加改进后,提议者接下来尝试将其与早期的结构修复相结合:
结合两个正交的修复——环境快照(节省早期探索回合)+ 带无工具调用循环中断器的标记剥离——将产生 +1-3pp 的增益,因为它们解决了独立的故障模式,而没有触及提示或确认流程(这在之前 7 次迭代中的 5 次中导致了退化)。
迭代 10:跨运行迁移。 提议者引用了另一个单独的早期搜索运行的结果:
进化历史显示“不要清理服务工件”价值 +18pp。Iter 9 (evo_no_cleanup_directive) 针对相同的想法,但在评估前崩溃了。
总结。 搜索轨迹表明提议者做的不仅仅是随机变异。在前七次迭代中,它识别出一个混杂因素,测试了隔离混杂因素的假设,观察到控制流和提示编辑仍然脆弱,然后有意识地转向一个纯粹的附加修改,该修改成为运行中最好的候选方案。它随后尝试将该获胜想法与早期修复组合,甚至跨运行迁移经验。这种对先前失败进行因果推理的能力正是完整历史文件系统访问所支持的,也是压缩反馈优化器无法支持的。
B 发现的套件
Meta-Harness 发现了特定于当前问题设置的可执行推理时过程。这些套件是结构化的、领域特定的策略,通常具有非平凡的控制流,如路由、过滤和条件上下文构建,仅根据是否能提高搜索集性能来选择。本节提供了代表性套件的紧凑、方法风格的抽象,总结了驱动推理时行为的主要行为和控制流决策。作为参考,每个发现的套件的完整实现大约有 100-1000 行代码。
===== 第 17 页 =====
B.1 文本分类套件
在在线文本分类中,Meta-Harness 发现了一个基于记忆的套件家族,而不是单个规范策略。表 9 报告了主搜索中非支配变体的帕累托前沿,所有这些变体仅根据搜索集性能选择。我们在此重点介绍两个代表性端点:Meta-Harness(草稿验证),上下文最低的前沿点,以及 Meta-Harness(标签引导查询),主文中使用的最高准确率前沿点。
概述。 两个套件都维护一个不断增长的过去标记示例的记忆,并在推理时从该记忆构建提示。不同之处在于用于查询记忆的控制流。Meta-Harness(草稿验证)使用两次短调用,并明确测试模型的首次猜测与检索到的反例,而 Meta-Harness(标签引导查询)花费更大的单次调用预算来明确标签空间和局部决策边界。图 5 和图 6 总结了这两个程序。
Meta-Harness(草稿验证)。 对应的发现文件是 draft_verification.py。这个轻量级变体将预测转化为两步过程。它首先检索 5 个最相似的标记示例并做出一个草稿预测。然后,它基于该草稿标签重新查询相同的记忆,检索 5 个具有相同标签的确认者和 5 个具有不同标签的挑战者,并询问模型是维持还是修正其初始答案。关键的发现行为是第二次检索依赖于查询和草稿预测,因此套件可以呈现针对模型当前猜测的反例,而不仅仅是通用的近邻。如果积累的标记示例太少,程序回退到标准的单次调用少样本提示。
- 阶段 1:草稿。检索 5 个最近的标记示例并请求初始预测。
- 阶段 2:验证。基于草稿标签进行条件检索,然后在做出最终预测前展示支持和挑战性的示例。
- 冷启动。如果可用的标记示例少于 5 个,则跳过两阶段过程,使用标准的单次调用少样本提示。
- 为什么成本低。两次调用都使用较短的检索上下文,因此即使有两次模型调用,总体上下文成本也保持在前沿的低端。
===== 第 18 页 =====
Meta-Harness(标签引导查询)。 对应的发现文件是 label_primed_query_anchored.py。这个最强的变体使用一个由三部分组成的较大单次调用。它首先以一个标签引子开始,列出有效的输出标签,然后构建一个覆盖部分,每个标签包含一个与查询相关的示例,最后添加以查询为中心的锚定对比对,将具有不同标签的高度相似示例并排放置。覆盖块暴露了整个标签空间,而对比块则围绕当前查询锐化了局部决策边界。在代码中,套件通过对过去标记示例进行 TF-IDF 检索和一个以查询为中心的配对规则(从同一局部邻域选择对比示例)来实现这一点。
- 标签引子。在展示任何示例之前列出有效的输出标签,让模型预先看到完整的答案空间。
- 覆盖块。对于每个已知标签,检索最与查询相关的标记示例,并为每个类别包含一个代表性示例。
- 对比块。构建具有不同标签的高度相似示例对,以便提示暴露围绕当前查询的局部决策边界。
- 检索规则。使用 TF-IDF 相似度和以查询为中心的伙伴选择,而不是与标签无关的最近邻。
B.2 数学检索套件
本小节描述了 Meta-Harness 为数学推理发现的检索套件(第 4.2 节)。最终的套件是一个紧凑的四路由 BM25 程序,其结构是通过搜索涌现的,而非事后手动指定。以下所有设计选择——路由谓词、重排序项、去重阈值和每条路由的示例数量——均由外部循环在 40 次进化迭代中选择。
===== 第 19 页 =====
表 9:主文本分类搜索中发现的帕累托最优变体,权衡平均准确率与上下文成本。主文中选定的系统是 Meta-Harness(标签引导查询)。Ctx 表示输入上下文中的平均额外字符数(千)。
概述。 在推理时,套件将每个问题精确地分配给四个路由之一:组合数学、几何学、数论或代数和其它问题的默认路由。门控被实现为轻量级的词法谓词,作用于问题陈述,包括关键字集合和一小部分用于几何记法的正则表达式特征。套件不会跨路由聚合输出:一旦选择了一个路由,只有该路由会为最终提示检索示例。所有路由都使用 BM25 作为底层检索机制,作用于上述过滤后的语料库。BM25 索引使用一个数学感知的分词器,该分词器保留 LaTeX 标记(例如,(\backslash \mathrm{frac}),({2}))作为原子单位。选定的套件是搜索期间由提议者自主合并的两个成功搜索谱系的结果:一个基于原始 BM25 贡献了更强的几何路由,而另一个基于去重和难度重排序贡献了更强的组合数学路由。图 8 给出了最终程序的紧凑流程图。
- 组合数学:获取 20 个 BM25 候选,去重至 8 个,按词法分数和难度重排序,然后返回前 3 个。这是套件明确权衡多样性与难题匹配的主要路由。
- 几何:返回 1 个困难的 NuminaMath 参考以及 2 个原始 BM25 邻居。搜索始终偏爱这里的原始结构匹配,而不是难度重排序。
- 数论:获取 12 个 BM25 候选,并使用词法分数、难度以及对早期陈述技术的解决方案的小额奖励进行重排序。这偏爱证明策略明确展示的示例。
- 默认:获取 10 个 BM25 候选,按词法分数和难度重排序,并根据顶部检索分数集中的程度选择自适应数量的示例。
===== 第 20 页 =====
B.3 TerminalBench-2 套件
发现的 TerminalBench-2 套件构建在 Terminus-KIRA [25] 之上,继承了其原生工具调用(取代 Terminus 2 基于 ICL 的 JSON 解析)、30KB 输出上限和多视角完成检查清单。Meta-Harness 发现的主要修改是环境引导:在代理循环开始之前,套件运行一个复合 shell 命令来收集沙盒环境的快照,并将其注入到初始提示中。提议者的假设,逐字引自搜索日志,如下:
假设:在第一次 LLM 轮次之前注入环境快照(操作系统、已安装语言、包管理器、/app 内容)将减少依赖关系重任务上 3-5 轮的浪费探索。更改:添加了 _gather_env_snapshot(),它运行一个单一的复合 shell 命令来收集工作目录、/app 列表、可用的编程语言(python, gcc, node, java, rustc, go)、包管理器(pip, apt)[…] 并作为 [Environment Snapshot] 块注入。
快照包括:工作目录、/app 列表(对于大目录截断至 20 项)、可用的编程语言及其版本(Python、GCC、G++、Node、Java、Rust、Go)、已安装的包管理器(pip、apt-get)以及可用内存。这消除了代理通常需要 2-4 轮探索来发现可用工具和文件的过程,使模型能够立即开始有效工作。引导命令有 15 秒超时保护,并静默失败,因此不会在不寻常的环境中破坏代理。完整实现相较于 Terminus-KIRA 增加了大约 80 行代码。图 9 总结了套件结构。
每个任务的分析。 与 Terminus-KIRA 相比,发现的套件在 89 个任务中的 7 个上取得了进步,其中最显著的改进是在 protein-assembly 和 path-tracing 上。获得进步的任务有一个共同特性:它们需要领域特定的工具,其可用性无法预先假设(生物信息学库、渲染管道、国际象棋引擎、加密工具、CoreWars 模拟器)。如果没有引导,代理会花费
===== 第 21 页 =====
前 2-4 轮探查环境;在轮次预算紧张或早期错误假设会级联放大的任务上,这些浪费的轮次可能决定通过还是失败。这表明引导的价值在环境不明确,且代理需要将其策略与实际安装的内容相匹配时最大。
C 数据集详情
C.1 OOD 文本分类数据集
- SciCite 是由 Cohan et al. [14] 引入的一个 3 类引用意图分类基准。每个示例包含来自科学论文的引用上下文,根据引用的修辞角色(如背景、方法或结果)进行标记。该任务测试模型是否能从局部科学上下文中推断出一篇论文引用另一篇论文的原因。
- FiNER-139 是由 Loukas et al. [29] 引入的一个金融数字实体识别基准。它包含来自财务文件的词级注释,有 139 个细粒度的 XBRL 实体类型,使其比标准的句子级分类任务精细得多。该基准测试模型是否能从上下文中识别和分类数字金融实体。
- Amazon Reviews 是由 Keung et al. [22] 引入的多语言亚马逊评论语料库的英文部分。在我们的设置中,它被用作一个 5 类评论评分预测任务,标签对应于评论的星级评分。该基准评估从产品评论文本中进行通用领域情感和评分预测。
- Financial PhraseBank 是由 Malo et al. [32] 引入的一个 3 类金融情感基准。它包含来自金融新闻和相关经济文本的句子,标记为正面、中性或负面市场情感。该任务评估金融领域的特定领域情感分类。
- GoEmotions 是由 Demszky et al. [15] 引入的一个细粒度情感分类基准。它包含带有 27 个情感类别加一个中性类别注释的英文 Reddit 评论,通常被视为一个 28 类分类任务。该基准测试超越粗粒度正负情感之外的细致情感识别。
- Banking77 是由 Casanueva et al. [11] 引入的一个细粒度意图分类基准。它包含在线银行用户话语,标记有 77 个意图,涵盖了广泛的客户服务请求。该任务评估具有大标签空间的单一领域意图检测。
- AG News 是一个 4 类新闻主题分类基准,通常与 Zhang et al. [60] 的文本分类设置相关联。示例标记有广泛的新闻类别,如世界、体育、商业和科学/技术。它是主题分类的标准通用领域基准。
- SciTail 是一个科学领域的文本蕴涵基准,其任务是预测在科学推理环境中,假设是否蕴含前提 [24]。
- TweetEval (Hate) 是 Barbieri et al. [7] 引入的 TweetEval 基准中的仇恨言论子集。它是一个用于在统一社交媒体评估套件中检测仇恨与非仇恨内容的二元推文分类任务。该基准测试在嘈杂、短文本社交媒体中进行鲁棒分类。
C.2 数学检索语料库
表 10 列出了第 4.2 节中使用的检索语料库的组成数据集。原始源包含的问题多于最终语料库;在合并前应用了几个过滤步骤。NuminaMath-1.5 被过滤到竞赛数学子集(AMC/AIME、奥赛参考、数论、不等式和相关源),丢弃了低质量的网络抓取条目。OpenMathReasoning 被去重为每个问题一个解决方案(保留在独立验证器上通过率最高的解决方案),并且源与任何评估基准系列(IMO、AIME、HMMT、SMT、USAMO、Putnam)匹配的问题在去重前被移除。然后,整个语料库使用精确前缀匹配和模糊 Jaccard 相似度(阈值 0.8)对所有评估基准和搜索期间使用的搜索集进行去污染;在任何一种标准下与 eval 问题匹配的语料库问题都被丢弃。来自 OpenMathReasoning 和 DeepMath 的解决方案被截断至 5,000 个字符以限制检索上下文长度。在运行时,选定的套件进一步限制检索条目,要求解决方案非空且短于 4,000 个字符。检索到的解决方案在插入提示时再次被截断至 3,000 个字符。对于几何路由,套件还从难度大于 6 的 NuminaMath 问题构建一个单独的硬参考索引。
C.3 数学 IMO 水平测试集
正文汇总了来自 IMO-AnswerBench、IMO-ProofBench、ArXivMath December 2025 和 ArXivMath January 2026 的 200 个 IMO 水平问题的结果。200 问题评估集由 IMO-AnswerBench 的 100 个分层子集以及其他三个基准的所有问题组成。这种按基准的细分很有用,因为四个数据集混合了答案式、证明式和研究式问题,为简洁起见,正文中将其汇总在一起。如果包含,本节中的表格应为五个未见的模型分别报告每个基准的基本情况和 Meta-Harness 结果。
===== 第 22 页 =====
表 10:数学检索语料库中的数据集(总计 535K 个问题)。Sol. Len 是解决方案长度的中位数(字符数)。Proof 指示数据集是否包含证明类型问题(根据答案或问题类型字段)。
- 截断至 5,000 个字符;实际解决方案更长。
| 数据集 | 问题数 | 解决方案长度 | 证明 (%) |
|---|---|---|---|
| OpenMathReasoning | 281,743 | 5,000+* | 34% |
| DeepMath-103K | 103,021 | 5,000+* | 0% |
| NuminaMath-1.5 | 129,520 | 1,376 | 13% |
| PolyMath | 11,083 | 363 | 0% |
| Omni-MATH | 4,289 | 829 | 0% |
| FineProofs-SFT | 4,275 | 3,977 | 100% |
| AIME 1983–2024 | 933 | — | 0% |
| Putnam-AXIOM | 492 | 888 | 100% |
| 总计 | 535,356 | 5,000+* | 22% |
| 数据集 | 问题数 |
|---|---|
| IMO-AnswerBench | 100 |
| IMO-ProofBench | 60 |
| ArXivMath Dec. 2025 | 17 |
| ArXivMath Jan. 2026 | 23 |
| 总计 | 200 |
D 实际实施技巧
Meta-Harness 在很大程度上是领域无关的:我们期望它适用于语言模型被特定任务套件包装的任何设置。然而,在一个新领域应用它需要在 LLM 辅助编码的相对较新的模式下操作,提议者依赖于先前运行的长时程历史,并编写其效果可能许多步之后才显现的程序。为了使这个工作流程可靠运行,我们发现在本文研究的三个领域中,有一小部分实际选择始终很重要。以下指南本身并不是关于该方法的科学主张;它们是构建和运行系统的工程经验,我们希望这将使未来的工作更容易在其他领域应用 Meta-Harness。
编写一个好的技能描述。 技能文本是与搜索交互的主要界面,其质量是循环是否有效的最强杠杆。提议者接收一个自然语言的技能描述 [5],该描述定义了其角色、目录布局、CLI 命令和输出格式。在实践中,技能描述应该约束输出和与安全相关的行为,而不是约束提议者的诊断程序:它应该指定什么是禁止的、要产生什么工件以及要优化什么目标,同时让模型自由检查分数、轨迹和先前的代码。我们从检查 Meta-Harness 运行的日志中得到的直觉是,经过足够多的迭代后,积累的轨迹通常比技能描述本身更能塑造提议者的行为。根据我们的经验,迭代技能文本对搜索质量的影响比更改迭代次数或种群大小更大。在提交完整运行之前,预计要进行几次短进化运行(每次 3-5 次迭代)专门用于调试和完善技能描述。
从一个基线套件和一个对该基线困难的搜索集开始。 编写一个简单的基线(例如,少样本提示),然后通过过滤基线出错或选择困难实例的多样性子集来构建搜索集。如果基线已经使评估饱和,那么搜索就没有什么可优化的。保持搜索集足够小,以便每次运行进行大约 50 次完整评估(在我们的分类实验中为 50-100 个示例,
===== 第 23 页 =====
数学检索为 88 个问题);快速、有区分度的评估比大型评估更有价值。
- 以易于导航的格式记录所有内容。 评估代码应以提议者可以可靠查询的形式编写代码、分数和执行轨迹。在实践中,这意味着使用机器可读格式如 JSON,分层组织工件,选择合理且一致的文件名,并采用使简单工具如正则表达式搜索也能良好工作的命名方案。
- 使日志可通过小型 CLI 查询(可选,但有帮助)。 每个套件获得一个包含源代码、分数和执行轨迹的目录,但随着历史增长,仅靠原始文件系统访问变得繁琐。一个显示帕累托前沿、展示前 (k) 个套件、以及比较不同运行之间代码和结果的简短 CLI 可以使体验存储更容易使用,并且查询此类 CLI 与编码代理训练的工作流程非常接近。如果存在相关的离线经验(来自其他模型的轨迹、已解决的问题语料库、相关论文),将其转换为相同的目录结构也可以帮助预热探索并激发新想法。这一层有助于提议者节省可能浪费在导航上的令牌。
- 在昂贵的基准测试之前进行轻量级验证。 编写一个小型验证测试,导入模块,实例化类,并在一个小型示例集上调用这两个方法。搜索过程中提出的套件应在完全评估之前通过此测试。一个简单的测试脚本可以在几秒钟内捕获大多数格式错误或无法运行的候选方案,并使失败成本接近于零。
- 在提议者之外自动化评估。 运行评估足够简单,不值得让提议者去做。一个单独的套件应该对候选方案进行评分,并将结果写入文件系统。
E 扩展相关工作
本附录扩展了第 2 节中的简要讨论,并将 Meta-Harness 置于我们无法在正文中详细讨论的几个邻近工作线的背景下。一个反复出现的区别是,Meta-Harness 优化可执行的套件实现,并通过文件系统向提议者提供对先前代码、分数和执行轨迹的选择性访问。
AlphaEvolve / OpenEvolve。 AlphaEvolve [35] 和 OpenEvolve [43] 通过 LLM 引导的变异和结构化反馈来进化代码:提议者接收一个包含标量分数的程序数据库(每步 4-22K 令牌;表 1),并对锦标赛选择的父代应用固定的变异策略。这些方法设计用于算法发现和优化(数学猜想、调度启发式、硬件内核),其中搜索目标是一个无状态的单函数,具有清晰的标量目标,并且变异是局部的。套件工程是一个不同的领域:套件是有状态程序,跨许多示例积累经验,并且一个单一的设计选择(例如,在内存中存储什么)可能会级联贯穿整个评估序列。Meta-Harness 通过给一个无结构的编码代理完整的文件系统访问权限来解决这个问题,让其可以选择性地读取任何先前候选方案的源代码、执行轨迹和分数。
GEPA。 GEPA [1] 在反馈丰富性方面是最接近的文本优化器,提供每个候选方案的执行轨迹。它设计用于具有短反馈循环的任务(数学问题、指令遵循、代码优化)上的提示优化,其中每个执行轨迹是单个 LLM 调用或一个短管道。在这个领域中,每个候选方案的反思效果很好:一个提示,一个答案,一个分数。套件工程需要同时跨许多示例和许多候选方案进行推理:理解为什么一个检索策略对一类问题有效而对另一类问题退化,需要比较整个种群的执行轨迹。GEPA 一次操作一个候选方案(每步 2-8K 令牌;表 1),具有固定的批评格式,必须预先预测哪些信息是相关的。Meta-Harness 让提议者同时访问所有先前的候选方案,并让代理决定检查什么。
===== 第 24 页 =====
提示编排框架。 有几个系统提供了用于组合多阶段 LLM 程序的结构化抽象。LMQL [8]、LangChain [13] 和 DSPy [23] 通过为提示模板、控制流和模块化 LLM 管道提供更高级别的接口,使提示工程更加系统化。这些框架帮助开发者指定和组织 LLM 程序,但它们通常仍然需要手动设计检索策略、内存更新和编排逻辑。Meta-Harness 在不同的层面上操作:它在可执行代码中搜索这些策略的实现,将套件本身作为优化目标。
[文件内容结束]

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献300条内容
已为社区贡献300条内容

所有评论(0)