【WAM篇】25:LAPA——不看动作标签,也能从海量视频里学会“怎么动“
级联式 WAM 的隐式规划一支,把"机器人到底要花多少钱采数据"这个老大难问题,第一次撬动到了"看视频就能预训练"的新地基上。
在前几篇里我们反复遇到一个尴尬:要训练一个能干活的机器人大脑,最缺的从来不是算力,而是带动作标签的数据。互联网上有看不完的人类做饭、收拾屋子、组装零件的视频,但这些视频里没有一行写着"此刻机械臂的七个关节角度是多少、夹爪开合了几毫米"。于是绝大多数视觉-语言-动作模型(VLA,Vision-Language-Action,简单说就是"看到画面+听懂指令→直接吐出机器人动作"的网络)都被死死卡在一个小数据池里:只能用人类遥控真机一条一条采来的、昂贵又稀少的"动作标注轨迹"。
LAPA(Latent Action Pretraining from videos,“从视频中做潜在动作预训练”)的回答非常硬核:既然没有真动作标签,那我们就自己"发明"一套动作标签——从无标注视频里无监督地学出一套抽象的"潜在动作",先拿它把模型大规模预训练好,最后只用极少量真实机器人数据,把这套抽象动作"翻译"成真正的关节指令。这篇工作发表在 ICLR 2025,是级联式 WAM 中"基于潜在表征的隐式规划"路线上一块重要的奠基石。
一、要解决什么问题:动作标签是具身智能的"卡脖子"环节
先打个比方。教一个孩子学骑车,最有效的方式当然是手把手地扶着、纠正每一个动作——这对应机器人领域的遥操作数据(人类远程操控真机,记录下每一帧画面和对应的精确动作)。它质量极高、对齐严格,但代价是:得有人、有真机、有场地,一小时只能采那么几十上百条。
可这世界上还躺着另一座金矿:互联网视频。YouTube 上无数人在切菜、叠衣服、拧螺丝,环境千变万化、任务五花八门,规模是遥操作数据的成千上万倍。问题是,这些视频只有画面,没有动作。你能看到一只手把杯子从左边挪到右边,却不知道驱动这只手的肌肉/关节信号是什么。
这就形成了具身智能里最割裂的一道鸿沟:
- 遥操作数据:动作精确,但贵、少、本体单一;
- 互联网视频:海量、多样,但完全没有动作标签。
过去的尝试要么只能在小小的遥操作池里"近亲繁殖",要么试图用视频做预训练却用不上其中的"动作信息"(比如只学个视觉表征)。LAPA 的野心,是把互联网视频真正变成"可用于学动作"的预训练语料。
二、核心思想与直觉:用 VQ-VAE 给"两帧之间发生了什么"发一张身份证
LAPA 的核心 idea 用一句人话讲就是:
看一段视频里相邻的两帧,中间画面发生了变化,这个"变化"本身就隐含着一个动作;我们用一个无监督模型把这个"变化"压缩成一小串离散编码,称之为"潜在动作"——它不是真实的关节角度,却是一个跨场景、跨机器人都通用的"动作的抽象语言"。
为什么这招行得通?关键在于一个朴素的物理直觉:画面怎么变,是被"动作"驱动的。手向前伸,杯子的位置就变;夹爪一合,物体就被抓起。如果一个模型能学会"看着当前帧和未来帧,反推出是什么让画面这样变化",那它学到的东西,本质上就是一种与动作高度相关的表征——哪怕它从没见过任何真实动作标签。
这正是逆动力学(Inverse Dynamics,“看前后两帧画面,倒推出中间执行了什么动作”)的思路。而 LAPA 的巧妙之处是把这个"倒推出的动作"用 VQ-VAE(Vector-Quantized Variational Auto-Encoder,向量量化变分自编码器,简单说就是"把连续信息压成一本’有限词表’里的离散编码"的网络)量化成了一小串离散 token。
为什么要量化成离散 token?因为这样一来,这些"潜在动作 token"就和文字 token 长得一模一样了——既然现成的大语言模型擅长"预测下一个词",那它也就能被改造成"预测下一个潜在动作",从而无缝接入大模型的预训练框架。这就把"学动作"巧妙地伪装成了"学语言"。
放到 WAM 的谱系里看:LAPA 属于级联式 WAM 中"基于潜在表征的隐式规划"一支。它不像早期的 UniPi 那样真的去生成像素级的未来视频(那样又慢又贵),而是停留在压缩后的"潜在动作"空间里做规划——这也是后续 villa-X、Motus 等一系列"潜在动作"工作的共同起点。
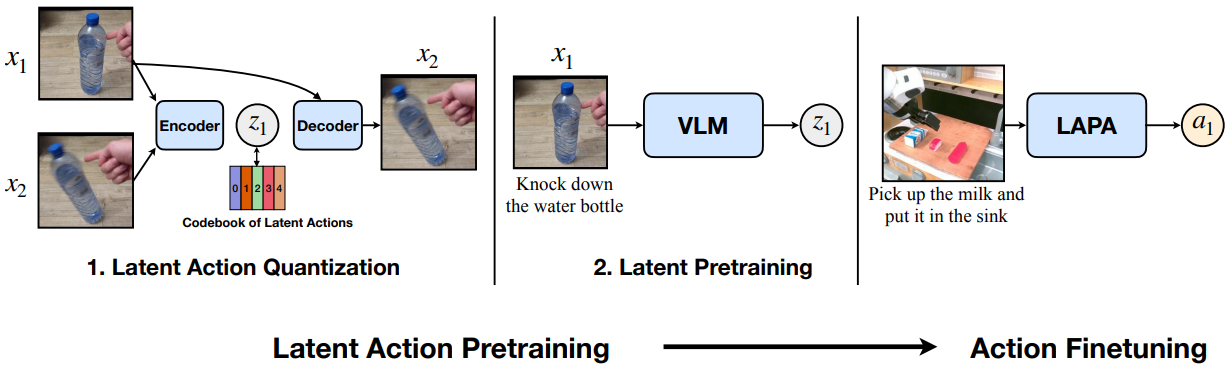
三、方法详解:三段式流水线
LAPA 把整个训练拆成清晰的三步,可以理解为"先造一套动作的密码本 → 用密码本大规模预训练 → 最后把密码翻译成真动作"。
| 阶段 | 在干什么 | 用什么数据 | 直觉类比 |
|---|---|---|---|
| ① 潜在动作量化 | 无监督学出"两帧→潜在动作"的密码本 | 无标注视频 | 发明一套描述动作的"速记符号" |
| ② 潜在预训练 | 让大模型学会"看图+听指令→预测潜在动作" | 海量视频(含人类视频) | 用速记符号大量练习"看到什么该怎么动" |
| ③ 动作微调 | 把潜在动作映射成真实关节指令 | 少量遥操作数据 | 把速记符号翻译成机器人能执行的真话 |
3.1 第一阶段:无监督学一套"潜在动作密码本"
这一步训练一个潜在动作量化模型,它由一对"编码器-解码器"组成:
- 编码器(一个同时含空间与时间注意力的 Transformer,类似 C-ViViT 那种视频分词器):吃进当前帧 xtx_txt 和未来某一帧 xt+Hx_{t+H}xt+H(HHH 是固定的时间窗口跨度),输出一小串离散的潜在动作 token ztz_tzt。注意这里编码器看得到"未来",所以它本质是个逆动力学模型——它在回答"是什么动作把画面从 xtx_txt 变成了 xt+Hx_{t+H}xt+H"。
- 解码器:只拿当前帧 xtx_txt 和那串潜在动作 ztz_tzt,通过交叉注意力去重建未来帧 xt+Hx_{t+H}xt+H。
训练目标就是让重建出来的未来帧尽量接近真实未来帧。这里有个关键约束:潜在动作 ztz_tzt 是一个信息瓶颈——它被量化成很小的离散码本(codebook),容量有限。这就逼着模型只能把"画面之间真正有意义的变化(也就是动作)“塞进 ztz_tzt,而不能把整张图都背下来。换句话说,瓶颈越窄,ztz_tzt 就越纯粹地代表"动作"而非"外观”。
工程上 LAPA 用了几个稳定训练的小技巧:用 NSVQ(noise-substitution vector quantization,一种用噪声替代来避免量化梯度断裂的技巧)防止梯度坍塌;解码时对图像 patch 嵌入做停止梯度;早期训练阶段做码本替换以最大化码本利用率(避免大量码字被闲置)。这些都是为了让那本"动作密码本"学得既丰富又不浪费。
3.2 第二阶段:用潜在动作做大规模预训练
有了密码本,第二阶段就把一个**70 亿参数的大世界模型(LWM-Chat-1M)**当骨干,让它做一件事:给定当前画面 xtx_txt 和语言指令,自回归地预测出接下来的潜在动作 token ztz_tzt。
这一步妙在哪?因为潜在动作已经是离散 token,整个任务就和"语言模型预测下一个词"完全同构——视觉编码器冻住,语言模型主体放开训练,再接一个专门的潜在动作输出头(词表大小就是码本大小 ∣C∣|C|∣C∣)。于是模型在海量视频上反复练习"看到这个场景、听到这个指令,下一步该往哪个’抽象动作’走",把跨场景、跨任务的动作先验狠狠灌进了大模型的权重里——全程不需要一个真实动作标签。
3.3 第三阶段:用极少量真机数据做"翻译"微调
预训练好的模型只会说"潜在动作"这门抽象语言,还不会真正驱动电机。第三阶段就把潜在动作输出头换成一个真实动作输出头,用少量遥操作数据微调:把连续的真实动作空间均匀分箱(离散化),让模型学会"我刚才想的那个潜在动作,对应到真机上就是这组关节指令"。
由于前两阶段已经把"看场景→该怎么动"的大半功夫练好了,这最后一步只需要很少的真机数据就能完成对齐——这正是 LAPA 大幅降低标注需求的根本原因。
核心公式与逻辑梳理
把 LAPA 三段流水线背后的数学骨架抽出来,整体逻辑是这样一条链:
- 逆动力学编码:相邻两帧 (xt, xt+H)(x_t,\,x_{t+H})(xt,xt+H) 进 C-ViViT 编码器,得到帧嵌入差 dt=et+H−etd_t=e_{t+H}-e_tdt=et+H−et;
- 向量量化:把这个连续差值用最近邻投到一本"动作码本" {zk}\{z_k\}{zk} 上,得到离散潜在动作 ztz_tzt;
- 未来重建:解码器只看当前帧 xtx_txt 和 ztz_tzt,反推未来帧 x^t+H\hat{x}_{t+H}x^t+H,重建误差倒推优化整本码本;
- 大模型预训练:把 ztz_tzt 当成"语言 token",让 LWM 在海量视频上做"看图+听指令→预测下一个潜在动作";
- 真机微调:换上真实动作输出头,用极少量遥操作数据把潜在动作翻译成离散化关节指令。
下面挑出 4 个关键式子。
(1) 潜在动作的最近邻量化(码本查表)
zt=argminzk ∥dt−zk∥22z_t=\arg\min_{z_k}\,\big\|d_t-z_k\big\|_2^2zt=argzkmin dt−zk 22
符号说明:dt=et+H−etd_t=e_{t+H}-e_tdt=et+H−et 是当前帧与未来帧的嵌入差,可以理解成"画面变化的连续向量";{zk}k=1∣C∣\{z_k\}_{k=1}^{|C|}{zk}k=1∣C∣ 是大小为 ∣C∣|C|∣C∣ 的码本(即"动作密码本"),每个 zk∈RDz_k\in\mathbb{R}^{D}zk∈RD 是一个候选潜在动作向量;∥⋅∥22\|\cdot\|_2^2∥⋅∥22 是平方欧氏距离。这条式子在做什么:把"画面之间连续的变化"硬塞进一本有限的离散词表里——通过取最近邻,每两帧之间发生的事都会被指认为码本中的某一条"动作密码"。这就把"动作"从连续向量空间压成了离散 token,为后面无缝接大语言模型铺平了路。
(2) NSVQ:用噪声替代量化误差防止梯度坍塌
d^t=dt+∥dt−zt∥∥v∥⋅v,v∼N(0,I)\hat{d}_t=d_t+\frac{\|d_t-z_t\|}{\|v\|}\cdot v,\quad v\sim\mathcal{N}(0,I)d^t=dt+∥v∥∥dt−zt∥⋅v,v∼N(0,I)
符号说明:d^t\hat{d}_td^t 是"经过噪声替代的连续嵌入",会被送进解码器;vvv 是从标准正态分布采的随机向量,分母是它的范数(用来归一化),分子是量化误差的范数。这条式子在做什么:经典 VQ-VAE 训练时常出现"码本被冷落、梯度断在量化操作上"的崩塌;这里用一段"幅度等于量化误差、方向是随机"的噪声把误差替代掉,保证梯度能顺畅流回编码器,同时还鼓励整本码本被均衡使用——这是 LAPA 训练稳定的关键工程技巧之一。
(3) 解码器以"当前帧 patch + 潜在动作"重建未来帧
x^t+H=D(Attn(sg[pt], d^t, d^t))\hat{x}_{t+H}=\mathcal{D}\Big(\mathrm{Attn}\big(\mathrm{sg}[p_t],\,\hat{d}_t,\,\hat{d}_t\big)\Big)x^t+H=D(Attn(sg[pt],d^t,d^t))
符号说明:D\mathcal{D}D 是空间 Transformer 解码器;ptp_tpt 是当前帧 xtx_txt 的 patch 嵌入;sg[⋅]\mathrm{sg}[\cdot]sg[⋅] 是"停止梯度"操作;Attn(Q,K,V)\mathrm{Attn}(Q,K,V)Attn(Q,K,V) 是标准的交叉注意力,这里把"当前帧 patch"当 Query、把潜在动作 d^t\hat{d}_td^t 同时当 Key 和 Value。这条式子在做什么:解码器只能看到"当前画面"和"那一小串潜在动作",凭这两样去还原未来。停止梯度避免解码器反过来"教"编码器作弊(譬如把整张未来图直接塞进 ptp_tpt)。换句话说——潜在动作是一道带宽很窄的瓶颈,只有把"动作"塞进去、解码器才重建得出未来,这就逼着 ztz_tzt 学到的就是动作本身。
(4) 重建损失(一阶段总目标)
LLAM=∥xt+H−x^t+H∥22\mathcal{L}_{\text{LAM}}=\big\|x_{t+H}-\hat{x}_{t+H}\big\|_2^2LLAM= xt+H−x^t+H 22
符号说明:左边是真实未来帧,右边是上一步重建出来的未来帧。这条式子在做什么:整本码本、编码器、解码器,都是被这一个朴素的"未来预测误差"反向传播给共同优化的。没有任何动作监督——纯粹是"画面层面的自洽"。这就是 LAPA 能吃无标注视频的根因。
(5) 第二阶段:把潜在动作 token 接入语言模型
Lpretrain=−∑tlogPθ(zt ∣ x≤t, ℓ)\mathcal{L}_{\text{pretrain}}=-\sum_{t}\log P_\theta\big(z_t\,\big|\,x_{\le t},\,\ell\big)Lpretrain=−t∑logPθ(zt x≤t,ℓ)
符号说明:ℓ\ellℓ 是语言指令,x≤tx_{\le t}x≤t 是到目前为止看到的画面,PθP_\thetaPθ 是 LWM 主体(70 亿参数)输出在码本 {1,…,∣C∣}\{1,\dots,|C|\}{1,…,∣C∣} 上的 softmax;这就是经典的"下一个 token 预测"交叉熵。这条式子在做什么:完全套用语言模型的预训练框架——只不过"下一个词"换成了"下一个潜在动作"。模型在海量视频上反复练习这件事,就把"看到什么场景该往哪个抽象动作走"的先验灌进了权重。第三阶段的微调只是把输出头从"码本词表"换成"离散化的真实动作 bin",损失形式完全一致:−∑tlogPθ(at∣x≤t,ℓ)-\sum_t\log P_\theta(a_t\mid x_{\le t},\ell)−∑tlogPθ(at∣x≤t,ℓ)。
把这五条式子串起来看,LAPA 干的事情极其干净——用一个 L2 重建损失把动作压成离散密码本,再用一个交叉熵把这本密码本塞进大语言模型的预训练机器,仅此而已。整套范式的优雅恰恰来自这种"把动作伪装成语言"的同构。
四、实验怎么做·结果说明了什么
LAPA 用了多套数据预训练并在仿真与真机上验证:人类视频用了 Something-Something v2(约 22 万条人类操作视频);跨本体机器人数据用了 Bridgev2(约 6 万条 WidowX 轨迹)和 Open-X(约 97 万条多样机器人演示);仿真则用 Language Table。
4.1 真机操作:不用动作标签,竟然反超用了标签的 SOTA
最震撼的结果在真机桌面操作(54 次评测)上:
| 方法 | 预训练数据 | 平均成功率 |
|---|---|---|
| LAPA | Open-X | 50.1% |
| OpenVLA | Open-X | 43.9% |
| LAPA | Bridgev2 | 36.8% |
| OpenVLA | Bridge | 30.8% |
在同样的数据来源下,LAPA 比 OpenVLA(当时用真实动作标签训练的代表性 SOTA)高出约 6 个百分点。更关键的是任务设定——这些任务需要语言条件理解、对未见物体的泛化、对未见指令的语义泛化,而 LAPA 在这些"考验泛化"的维度上全面占优。
最反直觉的一点是:只用人类视频(完全没有任何机器人动作)预训练的 LAPA,竟然超过了用真实机器人动作标签训练的 OpenVLA——尽管"人类的手"和"机器人的夹爪"之间存在巨大的本体差异。这强有力地证明:人类视频里蕴含的动作先验,是真的能迁移到机器人身上的。
4.2 跨环境泛化(Language Table)
| 方法 | 已见场景 | 未见场景 |
|---|---|---|
| LAPA | 33.6% | 29.6% |
| 从零训练 | 15.6% | 15.2% |
LAPA 把成功率几乎翻倍,并显著超过 UniPi、VPT 等此前从视频学策略的方法。这说明潜在动作预训练带来的不只是"记住训练任务",而是真正可迁移的能力。
4.3 效率:训练成本只有别人的 1/30 到 1/40
这是另一个让人印象深刻的数字。LAPA 的潜在预训练总共只花了约 272 个 H100 GPU 小时(8 张 H100 跑 34 小时,批大小 128),而 OpenVLA 当年的预训练耗费约 21500 个 A100 小时——LAPA 的预训练效率高出 30 到 40 倍,却换来了更强的下游表现。而且实验发现,单个 epoch 的训练就能达到最优。这背后的逻辑是:潜在动作预训练绕开了像素级生成的沉重负担,又能直接吃无标注视频,自然又快又省。
4.4 消融与"潜在动作到底学到了什么"
- 缩放规律:骨干模型越大、Bridgev2 数据越多,性能越好——说明这套范式吃得下规模红利。
- 潜在动作空间:在 SIMPLER 上,码本的"词表大小"比"序列长度"更重要;时间窗口 HHH 在大范围内都鲁棒,只有取极端值才退化。
- 可解释性:在 Language Table 上,学到的潜在动作在二维空间里呈现出有意义的聚类;在人类视频上,它既捕捉了手的移动,也捕捉了相机视角的变化;在 Open-X 多本体数据上,同一个潜在动作在不同机器人身上会产生语义一致的行为——这正是"抽象动作语言可跨本体迁移"的直接证据。
五、亮点与为什么重要
LAPA 最大的贡献,是把"机器人预训练"从"动作标签的牢笼"里解放了出来。它证明了三件事:
- 无标注视频可以直接用来学动作先验——只要先无监督地造一套潜在动作密码本,就能把视频变成预训练语料;
- 离散潜在动作 = 把"学动作"伪装成"学语言",从而无缝继承大语言模型的全部预训练机器与缩放红利;
- 极少量真机数据即可完成最后的"翻译",标注需求被大幅压缩。
对后续工作而言,LAPA 几乎定义了"潜在动作"这一研究方向的范式雏形:先有 IDM 式编码器学潜在动作、再有大模型预测潜在动作、最后映射到真动作。本系列后面的 villa-X 正是沿着这条路继续走,并针对 LAPA 的短板做了关键改进。
六、局限与未解
作者也坦诚地指出了几处不足:
- 精细动作仍是软肋:像"抓取"这种需要毫米级精度的动作,LAPA 表现欠佳——根本原因是这类动作的微调数据太少(如仅 150 条轨迹不够用)。潜在动作擅长捕捉"大方向的运动",对高频、精细的操作还力不从心。
- 推理延迟:和此前的 VLA 一样,实时部署的延迟仍是挑战。
- 数据域局限:当前只在操作类视频上验证,导航、自动驾驶等其他域尚未探索。
- 本体差异未消除:尽管整体表现强劲,"人类的手→机器人"之间的鸿沟依然存在,潜在动作并不能完全抹平它。
这些局限恰好为后来者留了空间——尤其是"潜在动作没有被真实物理动力学’接地’"这一点,正是 villa-X 要补的最大一块。
七、在 WAM 谱系中的位置
放进 WAM 的大图景里,LAPA 处在这样一个坐标:
- 范式归属:级联式 WAM → 基于潜在表征的隐式规划。它和 VPP、S-VAM 一样,都拒绝了"解码回像素再提动作"的笨重路线,转而在压缩的潜在空间里规划。
- 承上:它继承了 Genie 等"从无标注视频学潜在动作模型"的思想,但把落点放在了"下游真机控制"上,并第一次系统地证明了潜在动作预训练在真机上能反超有标签的 SOTA。
- 启下:它直接催生了"潜在动作"这一子方向。villa-X(本系列第 28 篇)指出 LAPA 的潜在动作"没有被机器人的物理动力学接地",于是引入本体感受前向动力学模型来弥补;Motus 等则进一步把它做成统一的潜在动作世界模型。
一句话总结 LAPA 的历史地位:它让"看视频就能学动作"从口号变成了可复现、能反超 SOTA 的硬实力,为整条潜在动作路线奠了基。
八、参考
- 论文标题:Latent Action Pretraining from Videos(LAPA)
- 作者:Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Se June Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, Lars Liden, Kimin Lee, Jianfeng Gao, Luke Zettlemoyer, Dieter Fox, Minjoon Seo 等
- 会议/年份:ICLR 2025
- 链接:https://openreview.net/forum?id=VYOe2eBQeh ;arXiv 预印本见 https://arxiv.org/abs/2410.11758
注:本文为基于该论文的学习性梳理与解读,方法、数据集与基准名称均保留英文原名以便检索;具体数字以原论文为准。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 1
1 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)