显存都去哪了:从 FP32 Master Weight 讲透大模型训练的显存账本
训练一个 10B 模型,权重本体明明只占 20GB,为什么动不动就要吃掉一两百 GB 显存?这篇文章把"显存到底被谁吃掉了"这件事彻底讲清楚。核心绕不开一个看似可有可无、却经常被面试官追问的概念——FP32 Master Weight。
一、先建立一个直觉:把训练当成"记账"
要理解显存,先不谈比特,先打个比方。
把训练模型想象成记账。模型的每个参数都是账本上的一个数字,训练就是在不断地修改这些数字。而账本本身,可以用不同精度去记:
- FP32(32 位):精确到"厘"的高精度账本。又大又准,但很重、翻起来慢、占地方。
- FP16 / BF16(16 位):只记到"元"的简易账本。很轻、算得飞快,但记不了那么精细。
在深入探讨底层机制之前,我们先给出一个最直接的宏观结论。对于一个 10B(百亿参数)的大模型,如果你采用目前主流的混合精度(FP16/BF16)+ Adam 优化器进行训练,单卡的“静态显存”占用粗略估算公式是:12 到 16 倍的参数量。
我们把这笔账拆开来看(以 1 字节 Byte = 8 比特 bit 为基准):
模型权重 (Model Weights):采用 16 位精度,每个参数占 2 字节。
消耗:10B × 2 = 20 GB
梯度 (Gradients):采用 16 位精度,每个参数占 2 字节。
消耗:10B × 2 = 20 GB
Adam 优化器状态 (Optimizer States):需要保存一阶动量 (m) 和二阶动量 (v),且必须是 32 位高精度,每个参数占 4 + 4 = 8 字节。
消耗:10B × 8 = 80 GB
算到这里,总计是 120 GB(相当于 12 倍参数量)。
但是,在绝大多数主流训练框架中,还会默认开启一项隐藏消费:FP32 Master Weight(高精度主权重)。它要求为每个参数再额外分配 4 字节的空间,这意味着还要再吃掉 40 GB。
加上它,静态显存的总开销直接飙升到 160 GB(16 倍参数量)。
明明本体只有 20GB,为什么训练起来却要 160GB?为什么那个“吃掉” 40GB 的 FP32 Master Weight 时而必须保留,时而又能扔掉?这篇文章,我们就把“显存到底被谁吃掉了”这件事彻底讲清楚。
二、FP32 Master Weight:它到底是什么,为什么说它"可有可无"
2.1 它解决的问题:别让小更新被"抹零"
设想某个参数当前是:
weight = 1.000000
本次更新 update = 0.000001如果参数只用 16 位低精度格式存储,这个极小的 update 很可能因为精度不够,在相加时被直接舍入掉——参数纹丝不动,模型这一步等于白学了。
在动辄几十上百万步、学习率很小的大模型训练里,这种"小更新被抹零"的累积损失是致命的。
工程师的解法是:让计算用低精度,让更新用高精度。具体的数据流是这样的:
FP32 master weight(后台高精度主账本)
│ cast 转成低精度
▼
BF16 / FP16 model weight(前台简易账本,用于计算)
│ forward / backward
▼
gradient 梯度
│
▼
Adam 用 m / v 和梯度,更新 FP32 master weight
│ 再 cast 回去
▼
新的 BF16 / FP16 model weight一句话概括它的本质:用低精度跑计算图,用高精度保存参数的真实更新轨迹。
2.2 关键认知:它是"工程选择",不是 Adam 的硬性要求
很多人误以为 master weight 是 Adam 算法的一部分,其实不是。
Adam 算法本身必须维护的状态只有四样:参数 θ、梯度 g、一阶动量 m、二阶动量 v。
至于参数 θ 究竟存成 BF16、FP16,还是额外再保留一份 FP32 的 master copy——这是训练框架和精度策略决定的,不是算法强制的。
所以"FP32 master weight 可有可无",不是因为它不重要,而是因为它取决于一连串前置条件:你用的是 FP16 还是 BF16、参数本体以什么精度存、optimizer update 是否需要在 FP32 上完成、框架是否已经用别的方式保证了数值稳定,以及你愿不愿意用额外显存去换训练稳定性。
三、同样是 16 bit,FP16 和 BF16 为什么脾气差这么多?
这是最容易被问倒、也最值得讲透的一点。
结论先行:BF16 和 FP16 在物理上都是 16 个比特,占用的存储和带宽完全一样。它们之所以"脾气"和"饭量"天差地别,是因为对这 16 个格子的分配方式完全不同。
3.1 浮点数的三段式结构
计算机存小数,本质上用的是科学记数法 a×2^b,由三部分构成:
- 符号位:正负号,占 1 bit。
- 指数位(exponent):决定这个数能表示的范围有多大、多小(对应科学记数法里的 b)。
- 尾数位(mantissa):决定这个数的精度有多高(对应 a能写几位有效数字)。
记住一个对应关系:指数位管"范围",尾数位管"精度"。 三种格式的全部差异,都来自这两块格子怎么切。
3.2 三种格式的比特分配
| 格式 | 总位数 | 符号位 | 指数位 (exponent) | 尾数位 (mantissa) | 最大可表示值 | 性格 |
|---|---|---|---|---|---|---|
| FP32 | 32 | 1 | 8 | 23 | ~3.4 × 10³⁸ | 又大又精,但重 |
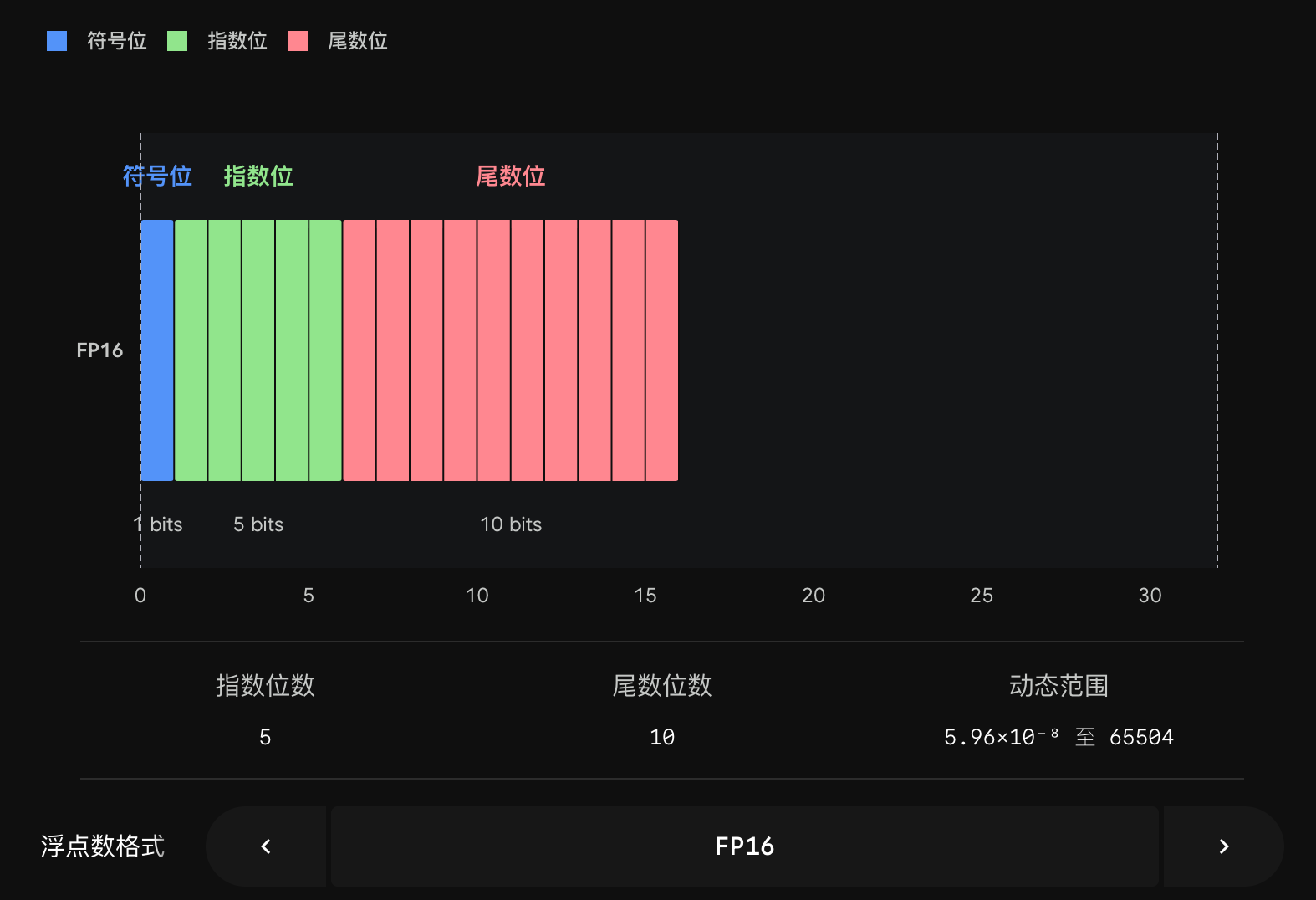
| FP16 | 16 | 1 | 5 | 10 | ~65504 | 精度尚可,范围窄,娇气 |
| BF16 | 16 | 1 | 8 | 7 | ~3.4 × 10³⁸ | 范围同 FP32,精度低,抗造 |
把它们的比特排布画出来,关系一目了然:
FP32: S | EEEEEEEE | MMMMMMMMMMMMMMMMMMMMMMM
1 | 8 | 23
BF16: S | EEEEEEEE | MMMMMMM ← 直接砍掉 FP32 尾部 16 位,指数位原样保留
1 | 8 | 7
FP16: S | EEEEE | MMMMMMMMMM ← 重新切分,牺牲范围去保精度
1 | 5 | 10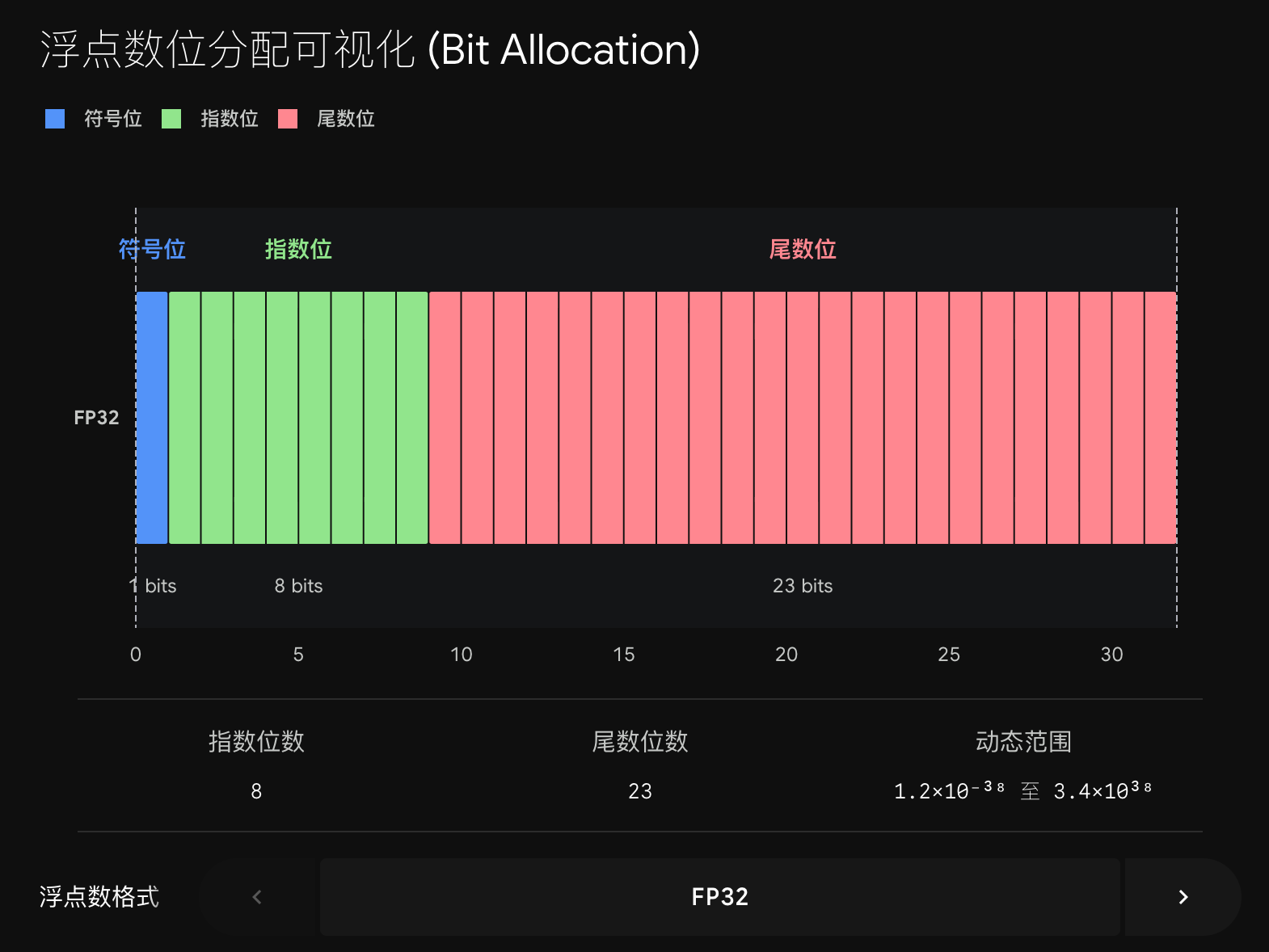
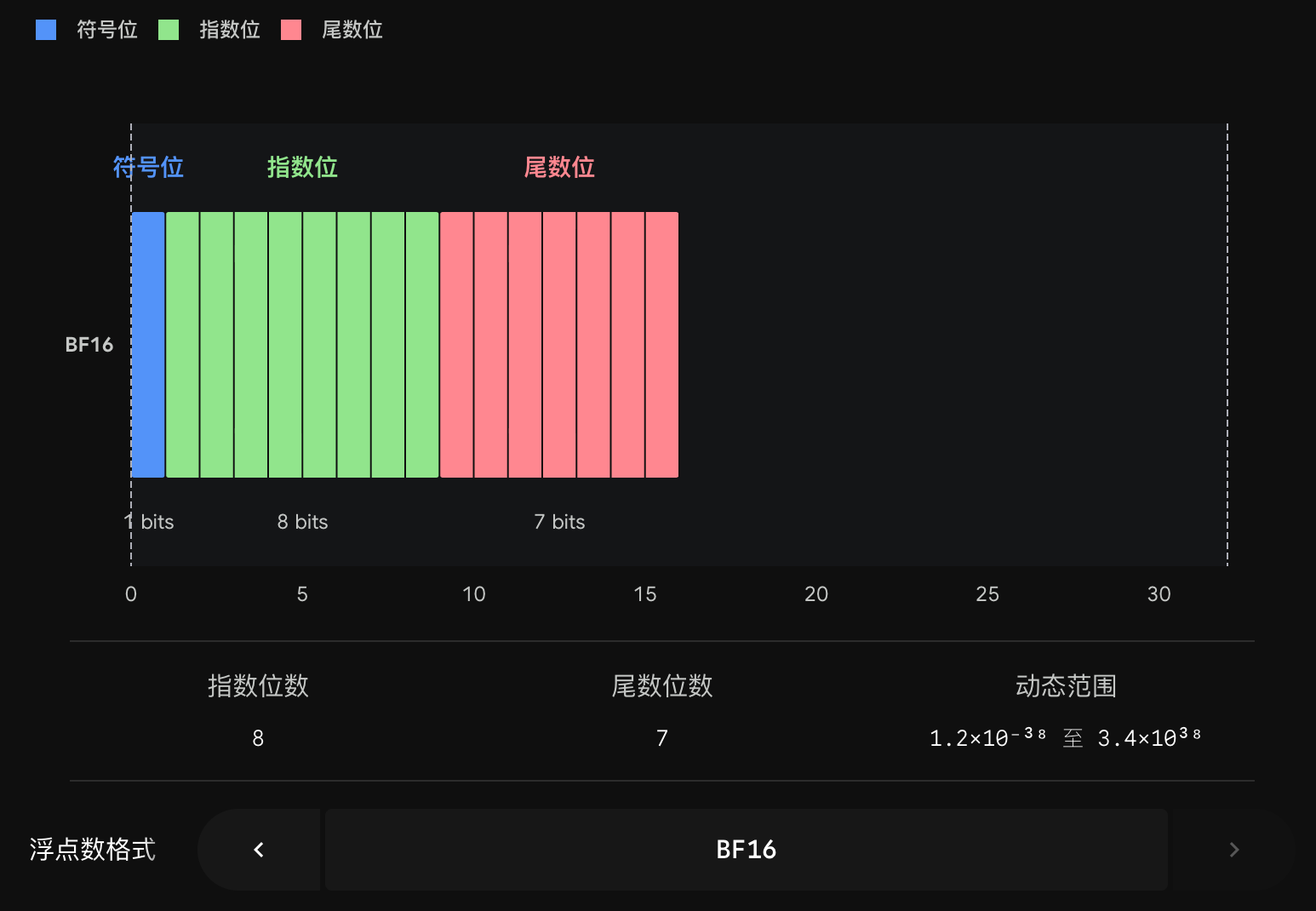
BF16 的诞生堪称"暴力美学":它全称 Brain Floating Point,是 Google Brain 团队为深度学习量身设计的。面对 FP16 容易溢出的痛点,他们做了一个简单粗暴的决定——直接把 FP32 的前 16 个比特"一刀切"下来,后面的 16 位当垃圾扔掉。于是 BF16 完整继承了 FP32 的 8 位指数位,代价是尾数位只剩可怜的 7 位(比 FP16 的 10 位还少)。
3.3 为什么 BF16"心大",FP16"娇气"
差别全在指数位上。
- FP16 只有 5 位指数,最大只能表示到 65504。大模型训练里梯度偶尔飙升一下,很容易就超过这个上限,直接触发
NaN或Inf,行话叫溢出(Overflow),整个训练当场崩溃。所以 FP16 通常必须配合 loss scaling(把 loss 放大再缩小)才能稳住。这就是它"娇气"的由来。 - BF16 有完整的 8 位指数,最大能表示到 ~3.4 × 10³⁸,和 FP32 一个量级。它几乎不会溢出,通常也不需要 loss scaling。这就是它"心大""抗造"的根源。
代价当然有。来看三种账本怎么记同一个数:
| 要记的数 | FP32 | FP16 | BF16 |
|---|---|---|---|
| 1,000,000.12345 | 1,000,000.12345(精确) | 记不了,超过 65504 直接死机 | 1,000,000.0(量级能记,零头被抹平) |
BF16 的特点是量级能扛住,但小数点后的零头会被"粗线条"地抹掉。
3.4 为什么这种取舍恰好适合深度学习
因为神经网络训练,恰恰是一个对范围敏感、对精度不敏感的过程。
权重差个 0.001,根本不影响模型最终把图片认成猫还是狗;但如果训练中途因为某个梯度数值太大溢出崩溃,几百万美元的电费就直接打了水漂。保住范围远比保住精度重要——这就是为什么如今的大模型几乎全面抛弃 FP16、拥抱 BF16。
四、为什么 Adam 的 m / v 通常仍然是 FP32?
即便用了 BF16、省掉了 master weight,Adam 的两个动量状态 m 和 v 一般仍然坚持用 FP32。
原因藏在它们的更新公式里:
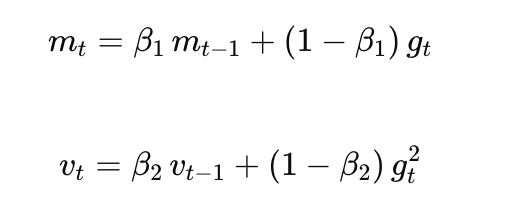
m 和 v 记录的是模型长期累积的历史经验(动量与方差)。尤其 v,常见的 β2=0.999意味着它每一步只挪动极小的一点。这种"长期、缓慢、靠累加"的状态,如果用低精度存,每一步的舍入误差会不断叠加,最终明显影响收敛——所谓"差之毫厘,谬以千里"。
所以业界的典型组合是:
- weight:BF16
- gradient:BF16 / FP32(视框架而定)
- m / v:FP32(基本不省)
- master weight:可选
可以这么记:master weight 可以省,但 Adam 的 m / v 通常不能随便动。 它们才是真正的"显存刺客"。
五、算总账:10B 模型的显存到底怎么估
现在把账算清楚。一个 10B(百亿参数)模型,BF16 权重本体只有 10B × 2 bytes = 20GB,剩下的全是训练态的"配套设施"。
| 显存组成 | 精度 | 每参数字节 | 10B 模型占用 |
|---|---|---|---|
| 模型权重 weight | BF16 | 2 | 20 GB |
| 梯度 gradient | BF16 | 2 | 20 GB |
| Adam 一阶动量 m | FP32 | 4 | 40 GB |
| Adam 二阶动量 v | FP32 | 4 | 40 GB |
| FP32 master weight(可选) | FP32 | 4 | 40 GB |
于是得到两档结果:
- 不保留 master weight:2 + 2 + 4 + 4 = 12 bytes/参数 → 约 120 GB
- 保留 master weight:再 + 4 = 16 bytes/参数 → 约 160 GB
这两个数字并不矛盾,差异完全来自"master weight 是实现相关的可选项"。
一个值得记住的经验法则:用 Adam + 混合精度 + master weight 训练,大约是 16 bytes / 参数;省掉 master weight 则约 12 bytes / 参数。把参数量乘上去,就是训练态静态显存的快速估算。
六、实战决策:什么时候留,什么时候扔
对 10B 模型来说,一份 FP32 master weight 就是 10B × 4 bytes = 40GB——这 40GB 很贵,所以是否保留需要认真权衡。
- 倾向保留 master weight 的场景:用 FP16 训练;训练本身不稳定;batch 很小、梯度噪声大;学习率很小、参数更新幅度极小;模型对数值精度敏感;或者你就是想把收敛稳定性拉满。
- 倾向丢弃 master weight 的场景:用 BF16 训练;显存压力很大;该配置下 BF16 更新已被验证稳定可收敛(即所谓 True BF16 Training);或者你需要把每个参数省下的这 4 bytes 显存抠出来。
一句话:FP16 偏向保留,BF16 可以尝试丢弃,但前提是验证过能收敛。
七、还没算完:静态底座之外的显存
上面算出的 120 / 160 GB,只是训练的静态底座。真正跑起来,还有几块动态开销:
- Activation(激活值):前向传播产生的中间结果,要留着供反向传播用。它随 batch size、序列长度、层数线性增长,是真正"会变"的大头,重负载下甚至能超过静态底座。
- CUDA workspace:算子(如矩阵乘、卷积)运行时需要的临时缓冲区。
- 通信 buffer:多卡训练里 all-reduce / all-gather 等集合通信所需的暂存空间。
- 显存碎片:分配/释放过程中产生的不可用空隙。
最后还有一个绕不开的现实问题:既然要 160GB,而单张 H100 才 80GB,10B 模型到底怎么训?
答案是并行与分片。实践中我们几乎不会把全部状态压在一张卡上,而是用 ZeRO / FSDP 把开销切分到 N 张卡:
- ZeRO-1:切分 optimizer states(m / v / master)
- ZeRO-2:在 ZeRO-1 基础上再切分 gradients
- ZeRO-3 / FSDP:连 parameters 一起切分
切分之后,每张卡分担的优化器显存大约降为原来的 1/N。这正是为什么一个名义上要 160GB 的模型,能在一堆 80GB 甚至更小的卡上跑起来。先把单卡总账算清楚,再除以并行度,才是工程上真实的显存图景。
八、一句话总结(面试速答版)
FP32 master weight 不是 Adam 算法强制要求的状态,而是混合精度训练里的工程选择。它让 forward / backward 用 BF16 或 FP16 加速,但 optimizer update 仍在 FP32 主权重上完成,从而避免小幅参数更新被低精度舍入掉。
FP16 因为动态范围小,通常更依赖 FP32 master weight 和 loss scaling;BF16 的指数位和 FP32 一样是 8 位,动态范围更大、稳定性好得多,所以有些框架可以做 true BF16 training,不额外保存 master weight。但 Adam 的 m / v 一般仍是 FP32,因为它们是长期累积状态。
所以显存估算分两档:10B BF16 + Adam,无 master weight 约 120GB,保留 FP32 master weight 再加 40GB、共约 160GB——这还不含 activation、workspace 和通信 buffer,也未考虑多卡分片。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)