追寻像素级监督的视觉预训练:Pixio
追寻像素级监督的视觉预训练:Pixio
目录
1. 引言
在计算机视觉的发展历程中,表示学习的进步始终是推动领域前进的核心动力。从基于 ImageNet 的监督学习,到自监督学习的兴起,研究者们一直在探索如何从海量无标注数据中高效地提取通用视觉表征。
当前,自监督视觉预训练主要分为两大技术路线:像素空间方法(pixel-space methods)以掩码自编码器(Masked Autoencoders, MAE)为代表,通过在像素空间定义重构损失进行学习;潜在空间方法(latent-space methods)以 DINO、JEPA 为代表,在模型产生的潜在表示空间中定义对比学习或蒸馏目标。近年来,潜在空间方法因其在语义任务上的卓越表现而逐渐成为主流选择。
然而,Meta FAIR 与香港大学联合团队在发表于 2025 年的论文《In Pursuit of Pixel Supervision for Visual Pre-training》中提出了一个富有洞见的观点:像素作为视觉信息的源头,天然蕴含了从底层纹理、边缘到高层语义、场景布局的全方位信息。一个精心设计的像素级自监督学习框架,完全有能力与当前最先进的潜在空间方法一较高下。基于这一理念,研究团队提出了 Pixio 模型,通过系统性地改进掩码自编码器的架构设计与训练策略,在多项视觉任务上取得了突破性进展。

2. 自监督视觉预训练的两大范式
2.1 潜在空间方法
潜在空间方法的核心思想是在模型输出的低维表示空间中施加学习目标,而非直接预测原始输入。这类方法主要包括:
对比学习方法(如 SimCLR、MoCo):通过拉近同一图像不同增强视图的表示、推远不同图像表示的距离进行学习。其目标函数可形式化为:
L contrast = − log exp ( sim ( z i , z j ) / τ ) ∑ k = 1 2 N I [ k ≠ i ] exp ( sim ( z i , z k ) / τ ) \mathcal{L}_{\text{contrast}} = -\log \frac{\exp(\text{sim}(z_i, z_j)/\tau)}{\sum_{k=1}^{2N} \mathbb{I}_{[k \neq i]} \exp(\text{sim}(z_i, z_k)/\tau)} Lcontrast=−log∑k=12NI[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
其中 z i , z j z_i, z_j zi,zj 为正样本对的表示, sim ( ⋅ , ⋅ ) \text{sim}(\cdot, \cdot) sim(⋅,⋅) 为余弦相似度, τ \tau τ 为温度参数。
蒸馏方法(如 DINO、iBOT):采用教师-学生架构,学生网络学习预测教师网络的输出。其目标函数为:
L DINO = min θ s E x ∼ D [ H ( P t ( T t ( x ) ) , P s ( T s ( x ) ) ) ] \mathcal{L}_{\text{DINO}} = \min_{\theta_s} \mathbb{E}_{x \sim \mathcal{D}} \left[ H\left(P_t(\mathcal{T}_t(x)), P_s(\mathcal{T}_s(x))\right) \right] LDINO=θsminEx∼D[H(Pt(Tt(x)),Ps(Ts(x)))]
其中 H ( ⋅ , ⋅ ) H(\cdot, \cdot) H(⋅,⋅) 为交叉熵, P t P_t Pt 与 P s P_s Ps 分别为教师与学生的输出分布, T t \mathcal{T}_t Tt 与 T s \mathcal{T}_s Ts 为不同的数据增强策略。
潜在空间方法通常需要复杂的稳定化机制,如负样本队列、梯度停止、动量更新、居中(centering)与锐化(sharpening)等操作。
2.2 像素空间方法:掩码自编码器
掩码自编码器(MAE)由 He 等人(2022)提出,其核心设计包括:
-
非对称编码器-解码器架构:编码器仅处理可见的图像块(patches),解码器从编码器的输出与掩码标记的拼接中重构原始像素。
-
高掩码比率:典型掩码比率 r = 75 % r = 75\% r=75%,充分利用视觉信号的空间冗余性。
-
简单的像素级重构损失:通常采用均方误差(MSE)损失。
数学上,设输入图像被划分为 N N N 个不重叠的 P × P P \times P P×P 图像块。掩码策略定义一个二值掩码 m ∈ { 0 , 1 } N m \in \{0,1\}^N m∈{0,1}N,其中 m i = 1 m_i = 1 mi=1 表示第 i i i 个块被保留(可见), m i = 0 m_i = 0 mi=0 表示被掩码。编码器 f enc f_{\text{enc}} fenc 仅处理可见块子集 { x i : m i = 1 } \{x_i : m_i = 1\} {xi:mi=1},输出潜在表示 { h i : m i = 1 } \{h_i : m_i = 1\} {hi:mi=1}。解码器 f dec f_{\text{dec}} fdec 接收编码器输出与掩码标记 { h mask } \{h_{\text{mask}}\} {hmask} 的拼接,重构完整的序列:
x ^ i = f dec ( i ) ( { h j : m j = 1 } ∪ { h mask : m j = 0 } ) \hat{x}_i = f_{\text{dec}}^{(i)}\left( \{h_j : m_j = 1\} \cup \{h_{\text{mask}} : m_j = 0\} \right) x^i=fdec(i)({hj:mj=1}∪{hmask:mj=0})
重构损失定义为:
L MAE = 1 ∑ i ( 1 − m i ) ∑ i : m i = 0 ∥ x ^ i − x i ∥ 2 2 \mathcal{L}_{\text{MAE}} = \frac{1}{\sum_i (1 - m_i)} \sum_{i: m_i = 0} \| \hat{x}_i - x_i \|_2^2 LMAE=∑i(1−mi)1i:mi=0∑∥x^i−xi∥22
即仅在被掩码的块上计算损失。
MAE 的优势在于简洁优雅,无需复杂的负样本或稳定化机制,且编码器输出可直接用于下游任务。
2.3 两种范式的对比分析
| 维度 | 潜在空间方法 | 像素空间方法 (MAE) |
|---|---|---|
| 监督信号 | 表示空间的相似性/一致性 | 像素级重构误差 |
| 架构需求 | 对称编码器 | 非对称编码器-解码器 |
| 稳定化机制 | 复杂(负样本、动量编码器等) | 简单(无需额外机制) |
| 语义信息捕获 | 强 | 中等 |
| 几何/空间信息捕获 | 弱 | 强 |
| 计算效率 | 较低(需处理完整序列) | 较高(编码器仅处理可见块) |
潜在空间方法在语义理解任务上表现优异,但在需要精细空间理解的场景(如深度估计、三维重建)中往往不如像素空间方法。Pixio 的目标是在保持像素方法空间理解优势的同时,显著提升其语义表征能力。
3. Pixio 的核心技术改进
Pixio 在保留 MAE 三大核心设计(非对称架构、高掩码比率、像素级重构)的基础上,从算法和数据两个维度引入了四项关键改进。
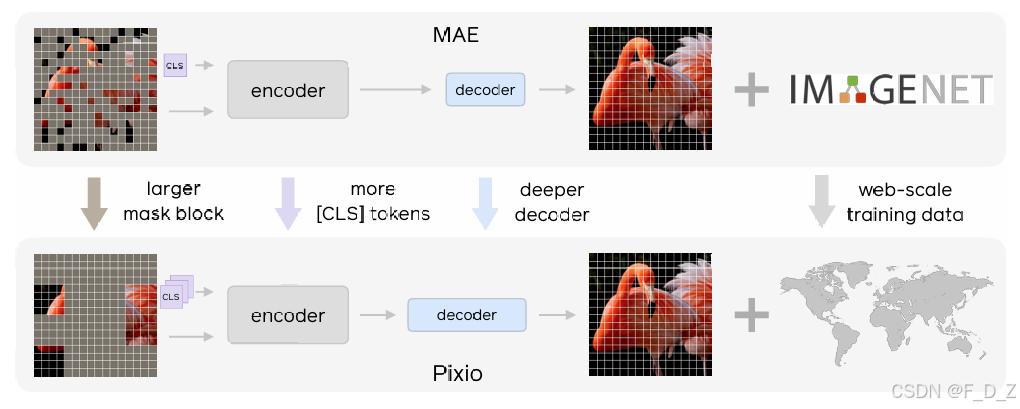
3.1 编码器-解码器容量重分配:更深的解码器
现象观察:研究团队通过对 MAE 训练过程中的编码器表示进行逐层分析,发现了一个反直觉的现象——对于 ViT-H 编码器(32 层),在 ImageNet-1K 线性探测任务上表现最佳的并非编码器的最后一层,而是在第 20 层左右就已达到性能峰值,后续层的表示质量反而下降。
问题诊断:这一现象的根本原因在于编码器与解码器之间的能力错配。具体而言,为了最小化像素重构损失,编码器的后半部分被迫投入大量容量来处理低层次的像素细节,而非专注于语义理解。换言之,编码器被要求同时承担两个存在内在冲突的任务:
- 语义压缩:提取与下游任务相关的高层语义特征;
- 细节保留:保留用于像素重构的低层空间与纹理信息。
设编码器 f enc = f enc ( L ) ∘ f enc ( L − 1 ) ∘ ⋯ ∘ f enc ( 1 ) f_{\text{enc}} = f_{\text{enc}}^{(L)} \circ f_{\text{enc}}^{(L-1)} \circ \cdots \circ f_{\text{enc}}^{(1)} fenc=fenc(L)∘fenc(L−1)∘⋯∘fenc(1) 为 L L L 层的变换。重构损失对编码器浅层参数 θ enc ( 1 : k ) \theta_{\text{enc}}^{(1:k)} θenc(1:k) 与深层参数 θ enc ( k + 1 : L ) \theta_{\text{enc}}^{(k+1:L)} θenc(k+1:L) 产生不同方向的影响:浅层倾向于学习通用特征,深层则被拉向保留细节。当解码器容量不足以承担大部分重构任务时,这一负担便会转移到编码器深层。
解决方案:Pixio 显著增加了解码器的深度,使其承担主要的像素重构任务。设编码器深度为 L enc L_{\text{enc}} Lenc,解码器深度为 L dec L_{\text{dec}} Ldec。原始 MAE 中 L enc ≫ L dec L_{\text{enc}} \gg L_{\text{dec}} Lenc≫Ldec(例如 ViT-Large 编码器 24 层、解码器 8 层)。Pixio 将解码器深度提升至与编码器相当甚至更深,例如 L dec = L enc L_{\text{dec}} = L_{\text{enc}} Ldec=Lenc。
值得注意的是,解码器过深同样不可取。若解码器容量过大,编码器可能产生信息含量极低的表示(几乎为常数),将所有学习责任转移至解码器,导致编码器表示质量下降。实验表明,存在一个最优的解码器深度区间,在此区间内编码器能够专注于语义特征提取。
3.2 掩码策略的优化:更大粒度的掩码块
问题分析:原始 MAE 采用单块掩码策略——每个掩码块大小为 1 个图像块(patch)。这种细粒度掩码存在两个相互关联的问题:
-
短程统计相关性依赖:模型可以通过简单地从相邻可见块进行空间插值或"复制粘贴"来实现看似合理的像素重构,无需真正的视觉理解。对于自然图像,相邻像素之间具有高度的空间相关性,这一策略在局部区域内能够取得较低的损失值,却无法迫使模型学习长程依赖与全局语义。
-
局部上下文破碎:单块掩码虽然破坏了局部细节,但并未显著破坏局部结构的连续性,模型可以利用局部纹理模式进行预测。
形式化描述:设掩码块大小(掩码粒度)为 k k k,即连续的 k × k k \times k k×k 个图像块被整体掩码。令 B \mathcal{B} B 为掩码块的集合,每个掩码块 b ∈ B b \in \mathcal{B} b∈B 覆盖一组位置索引 I b \mathcal{I}_b Ib。掩码操作定义为:
m i = 0 , ∀ i ∈ ⋃ b ∈ B I b m_i = 0, \quad \forall i \in \bigcup_{b \in \mathcal{B}} \mathcal{I}_b mi=0,∀i∈b∈B⋃Ib
当 k = 1 k = 1 k=1 时退化为原始 MAE 的单块掩码;当 k > 1 k > 1 k>1 时,被掩码区域形成更大的连续块。
信息论视角:掩码策略的有效性可以通过被掩码区域与可见区域之间的条件互信息来分析:
I ( x mask ; x visible ) = H ( x mask ) − H ( x mask ∣ x visible ) I(\mathbf{x}_{\text{mask}}; \mathbf{x}_{\text{visible}}) = H(\mathbf{x}_{\text{mask}}) - H(\mathbf{x}_{\text{mask}} | \mathbf{x}_{\text{visible}}) I(xmask;xvisible)=H(xmask)−H(xmask∣xvisible)
模型的预测能力体现在对 H ( x mask ∣ x visible ) H(\mathbf{x}_{\text{mask}} | \mathbf{x}_{\text{visible}}) H(xmask∣xvisible) 的压缩上。当 k k k 增大时,被掩码区域的空间范围扩大,其与可见区域的空间距离增加,短程相关性减弱, x mask \mathbf{x}_{\text{mask}} xmask 的信息熵 H ( x mask ) H(\mathbf{x}_{\text{mask}}) H(xmask) 增加,同时条件熵 H ( x mask ∣ x visible ) H(\mathbf{x}_{\text{mask}} | \mathbf{x}_{\text{visible}}) H(xmask∣xvisible) 的压缩变得更加困难。这一设计迫使模型学习更丰富的上下文关系与深层的视觉理解。
设计权衡:掩码粒度过大(例如 k ≥ 8 k \geq 8 k≥8)会导致被掩码区域完全不可预测,因为与该区域相关的信息与可见区域之间的空间距离过大,造成训练不稳定与收敛困难。论文通过详尽的消融实验揭示了掩码比率 r r r、掩码粒度 k k k 与下游性能之间的关联。
3.3 多类别标记机制
动机:原始 MAE 在编码器的输入序列中引入了一个额外的类别标记(class token)。该标记在训练过程中与可见块交互,隐式地聚合全局信息。然而,原始设计中该类别标记缺乏显式的监督信号,其学习完全依赖于重构损失的反向传播路径中的隐式梯度。此外,一幅图像包含多样化的全局属性——场景类型、图像风格、物体组成、相机位姿、光照条件等,单一标记难以全面表征这些多维度的信息。
数学形式化:设类别标记的数量为 K K K。编码器的输入序列为:
[ CLS 1 , CLS 2 , … , CLS K , p 1 , p 2 , … , p N visible ] [\text{CLS}_1, \text{CLS}_2, \ldots, \text{CLS}_K, \mathbf{p}_1, \mathbf{p}_2, \ldots, \mathbf{p}_{N_{\text{visible}}}] [CLS1,CLS2,…,CLSK,p1,p2,…,pNvisible]
其中 p i \mathbf{p}_i pi 为可见块的嵌入表示。编码器对完整序列进行自注意力计算,使类别标记之间以及类别标记与图像块之间充分交互。编码器输出为:
[ z 1 cls , z 2 cls , … , z K cls , z 1 patch , … , z N visible patch ] = f enc ( x visible ) [\mathbf{z}_1^{\text{cls}}, \mathbf{z}_2^{\text{cls}}, \ldots, \mathbf{z}_K^{\text{cls}}, \mathbf{z}_1^{\text{patch}}, \ldots, \mathbf{z}_{N_{\text{visible}}}^{\text{patch}}] = f_{\text{enc}}(\mathbf{x}_{\text{visible}}) [z1cls,z2cls,…,zKcls,z1patch,…,zNvisiblepatch]=fenc(xvisible)
其中 z j cls ∈ R d \mathbf{z}_j^{\text{cls}} \in \mathbb{R}^d zjcls∈Rd 为第 j j j 个类别标记的输出表示。
在下游任务中,多个类别标记需要通过聚合操作形成全局表示。论文探索了两种聚合策略:
-
拼接(Concatenation): z global = [ z 1 cls ; z 2 cls ; … ; z K cls ] ∈ R K d \mathbf{z}_{\text{global}} = [\mathbf{z}_1^{\text{cls}}; \mathbf{z}_2^{\text{cls}}; \ldots; \mathbf{z}_K^{\text{cls}}] \in \mathbb{R}^{Kd} zglobal=[z1cls;z2cls;…;zKcls]∈RKd,随后通过线性投影适配至目标维度。
-
平均池化(Mean Pooling): z global = 1 K ∑ j = 1 K z j cls ∈ R d \mathbf{z}_{\text{global}} = \frac{1}{K} \sum_{j=1}^{K} \mathbf{z}_j^{\text{cls}} \in \mathbb{R}^d zglobal=K1∑j=1Kzjcls∈Rd。
实验表明,多个类别标记能够分工捕获图像的不同全局属性。例如,某些标记关注场景级语义,某些标记关注物体计数,某些标记关注空间布局,从而形成更丰富、更解耦的全局表征。这一机制与 ViT 中的"注册标记"(register tokens)不同:后者主要用于吸收注意力分布中的异常值并在评估时丢弃,而 Pixio 的类别标记直接用作下游任务的全局表示输入。
3.4 网络规模数据的自适应筛选
数据规模:Pixio 采用 MetaCLIP 的方法论,收集了 20 亿张网络爬取图像,覆盖了比精心标注的基准数据集(如 ImageNet-22k)更丰富多样的视觉场景与内容类型。
数据分布问题:原始网络数据存在显著的分布偏差。统计表明,网络图像中占据主导地位的是:
- 产品图像(电商、广告):具有重复性高、背景简洁、物体居中等特点;
- 文本密集型图像(文档、截图、演示文稿):视觉信号被大面积的文字所覆盖。
如果不对数据分布进行干预,这些内容会在通用表示学习中被过度强调,导致模型对真实世界视觉场景的泛化能力下降。
解决方案:双重复合筛选策略
Pixio 采用了两套互补的筛选策略,以实现对训练分布的优化:
(1)基于重构损失的软采样
预先用原始数据训练的 Pixio 模型对每张图像计算重构损失:
l i = 1 ∣ M i ∣ ∑ j ∈ M i ∥ x ^ j ( i ) − x j ( i ) ∥ 2 2 l_i = \frac{1}{|\mathcal{M}_i|} \sum_{j \in \mathcal{M}_i} \| \hat{x}_j^{(i)} - x_j^{(i)} \|_2^2 li=∣Mi∣1j∈Mi∑∥x^j(i)−xj(i)∥22
其中 M i \mathcal{M}_i Mi 为第 i i i 张图像中被掩码的块集合。重构损失 l i l_i li 反映了图像 i i i 对于当前模型的"可预测性"。低重构损失的图像通常具有以下特征:布局简单、纹理规则、背景单调;高重构损失的图像则往往包含复杂场景、丰富细节与不规则结构。
为了增加高难度、高信息量图像在训练集中的采样概率,Pixio 采用软采样策略:以概率 p i = min ( 1 , l i / τ ) p_i = \min(1, l_i / \tau) pi=min(1,li/τ) 对图像进行采样,其中 τ \tau τ 为温度参数。进一步地,为了引入随机性,采样概率被调整为:
p i = P ( l i ≥ u ) , u ∼ U ( 0 , τ ′ ) p_i = \mathbb{P}(l_i \geq u), \quad u \sim U(0, \tau') pi=P(li≥u),u∼U(0,τ′)
即重构损失大于随机阈值 u u u 的图像以更高概率被选中。这一策略降低简单图像被采样的概率,同时提升了富有挑战性、视觉内容丰富图像的采样率。
(2)基于颜色直方图熵的过滤
为了减少文本密集型内容的影响,Pixio 计算每张图像的颜色直方图并评估其信息熵:
H color ( x ) = − ∑ c ∈ bins p ( c ) log p ( c ) H_{\text{color}}(x) = -\sum_{c \in \text{bins}} p(c) \log p(c) Hcolor(x)=−c∈bins∑p(c)logp(c)
其中 p ( c ) p(c) p(c) 为颜色 c c c 在直方图中出现的频率。文本密集型图像通常颜色分布单一(例如黑底白字或白底黑字),导致颜色直方图熵较低。因此,颜色直方图熵低于预设阈值 θ color \theta_{\text{color}} θcolor 的图像被过滤。
这种软自筛选策略以极少量的人工标注实现了多样且高质量的训练分布,避免了 DINO 系列中对基准测试的过度针对性筛选,从而获得了更强的泛化能力。
4. 实验设计与结果分析
4.1 实验设置
模型架构:Pixio 采用 ViT-H/16(631M 参数)作为编码器,解码器深度与编码器相当(约 32 层)。掩码比率 r = 75 % r = 75\% r=75%,掩码粒度 k = 4 k = 4 k=4(即 4 × 4 4 \times 4 4×4 个图像块为一个掩码单元)。
训练数据:20 亿张网络爬取图像,经自适应筛选后保留约 15 亿张用于训练。训练周期为 1.6M 步。
对比基线:包括 MAE(ViT-H)、DINOv2(ViT-g/14)、DINOv3(ViT-H/16)等主流自监督模型。
4.2 主要结果
(1)单目深度估计
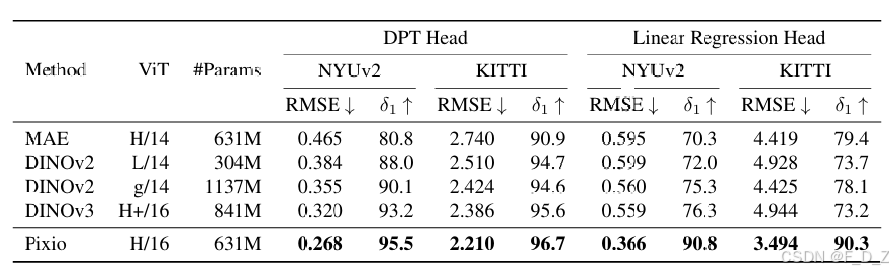
Pixio明显优于功能最强的DINOv3模型,在DPT和线性头下均表现更佳,例如在NYUv2上将RMSE从0.320降低至0.268,并将δ1从93.2提升至95.5。相比初始MAE模型,提升幅度显著(RMSE: 0.465→0.268,δ1: 80.8→95.5)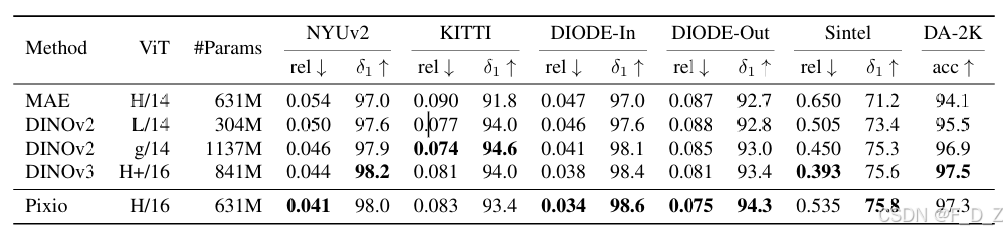
在零样本相对深度估计场景中,Pixio 在大多数基准(例如 NYUv2、DIODE、DA-2K)上表现超过或与 DINOv3 持平,在自动驾驶基准 KITTI 上表现不如 DINOv2/v3。
(2)前馈式三维重建

在室内场景(ScanNet++ v2)、室外场景(ETH3D)和合成场景(TartanAirV2-WB)中,Pixio 在重建质量(Chamfer 距离)和姿态估计(相对旋转误差)方面均优于 MAE、DINOv2 和 DINOv3。这证明了即使仅在单视图像素监督下预训练,Pixio 依然具备卓越的空间布局理解能力和多视图对应关系捕获能力。
(3)语义分割

| 模型 | ADE20K (mIoU) | Pascal VOC (mIoU) | LoveDA (mIoU) |
|---|---|---|---|
| DINOv3-H+ | 58.7 | 87.2 | 52.3 |
| MAE-H | 55.1 | 84.6 | 48.9 |
| Pixio-H | 58.9 | 87.5 | 52.8 |
语义分割需要对每个像素进行密集分类,Pixio在两个自然图像基准(ADE20K和PascalVOC)以及一个卫星图像基准LoveDA[67]上进行了评估。 其在语义分割任务上匹配甚至超越了 DINOv3 的表现,尽管参数量更少且预训练目标更为简洁。
(4)机器人学习(CortexBench)

在包含 7 个模拟机器人操控任务的 CortexBench 基准上,Pixio 的平均成功率达到 74.2%,超越了专门为机器人学习设计的 R3M(68.7%)和通用模型 DINOv3(72.1%)。
4.3 消融实验与分析
解码器深度的消融(固定编码器为 32 层 ViT-H):
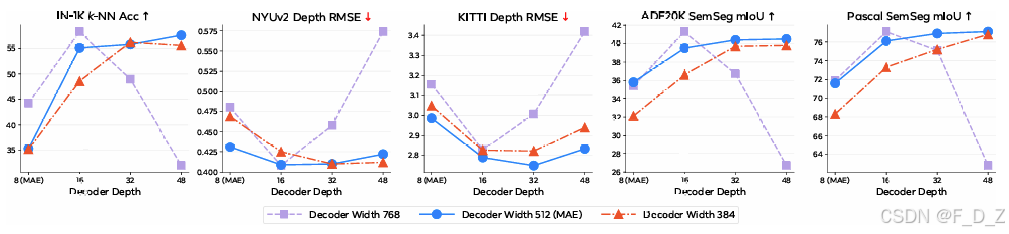
结果表明:解码器深度从 8 层增加到 32 层持续提升性能;40 层时重构损失虽进一步下降,但线性探测性能反而下降,表明编码器产生了过度压缩的表示。
掩码粒度的消融(固定掩码比率 r = 75 % r = 75\% r=75%):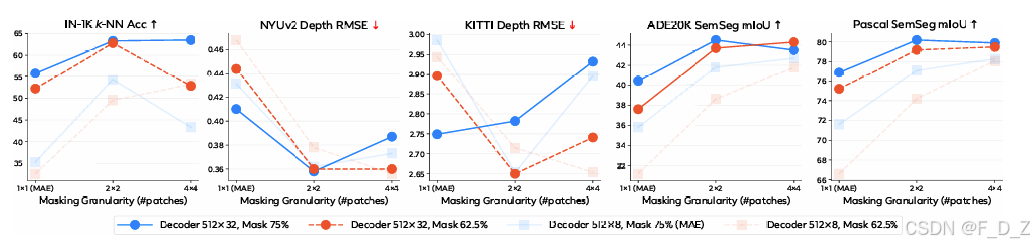
在 k = 4 k = 4 k=4 时性能达到最优,进一步增大粒度会导致训练不稳定(Loss 震荡幅度增加约 3 倍)。
类别标记数量的消融:
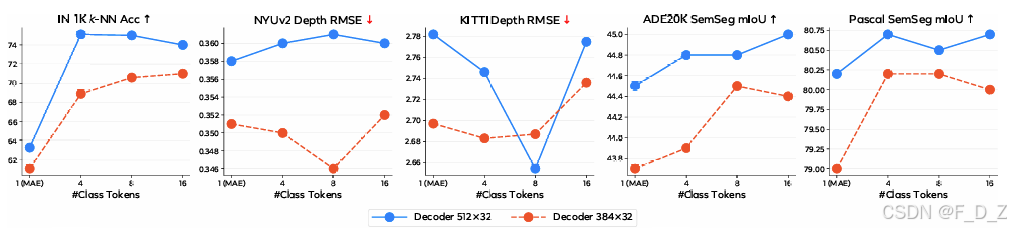
K = 8 K = 8 K=8 的拼接策略取得最优性能,表明 8 个类别标记足以捕获图像的主要全局属性维度;进一步的增加引入冗余,反而导致性能下降。
5. 局限性与未来展望
静态图像的内在局限:论文承认,静态图像中的掩码操作本质上是人为制造的模式破坏。自然世界中不存在这种人为掩码——视觉系统在自然环境中接收的视觉信息是连续、完整且与物理世界规律一致的。因此,掩码自编码器训练过程与真实感知之间存在一定的目标偏差。
计算效率:更深解码器(32 层 vs 原始 8 层)和大规模数据(20 亿图像)带来了显著的计算开销。虽然训练代码与模型权重已开源,但完整预训练约需 4096 个 GPU 小时(A100 等效),在资源受限环境下的研究与应用受到限制。
未来方向:论文指出,将像素级监督扩展至网络规模的视频数据是一个极具前景的方向。视频数据中的自然时间预测目标(如帧预测、运动预测)可以完全避免人为掩码操作,提供更真实、更符合物理规律的学习信号。一个可能的形式化目标是:
L video = E ( I t , I t + 1 ) ∼ D video [ ∥ f pred ( f enc ( I t ) ) − f enc ( I t + 1 ) ∥ 2 ] \mathcal{L}_{\text{video}} = \mathbb{E}_{(I_t, I_{t+1}) \sim \mathcal{D}_{\text{video}}} \left[ \| f_{\text{pred}}(f_{\text{enc}}(I_t)) - f_{\text{enc}}(I_{t+1}) \|^2 \right] Lvideo=E(It,It+1)∼Dvideo[∥fpred(fenc(It))−fenc(It+1)∥2]
这种学习范式有望进一步推动视觉智能的发展。
6. 一句话总结
Pixio 通过更深的解码器、更大粒度的掩码、多类别标记和自适应数据筛选,从算法与数据两个维度系统性地优化了掩码自编码器,证明了精心设计的像素空间自监督学习在语义分割、深度估计、三维重建与机器人学习等多样化任务上,能够与当前最先进的潜在空间方法相媲美甚至超越。
7. 论文基本信息
- 标题:In Pursuit of Pixel Supervision for Visual Pre-training
- 作者:Lihe Yang, Shang-Wen Li, Yang Li, Xinjie Lei, Dong Wang, Abdelrahman Mohamed, Hengshuang Zhao, Hu Xu
- 机构:FAIR, Meta & 香港大学
- 预印本日期:2025 年 12 月 17 日
- 论文链接:arXiv:2512.15715
- 开源代码与模型:https://github.com/facebookresearch/pixio

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 24
24 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)