长时对话场景下的上下文保持机制与状态恢复策略:基于 JiuwenSwarm 的上下文瘦身与长期记忆实践
如果只看一两轮对话,大模型确实很像一个反应很快的助手。但只要把时间拉长到几十轮、几天,甚至一个完整项目周期,问题就冒出来了:它并不是天生就有一套能连续工作的“记忆系统”。
上下文窗口再大,本质上也只是“这一轮能摆在模型面前的工作台”。工作台变大,不代表资料会自动归档,也不代表前面拍过板的决策会自己沉淀下来,更不代表多 Agent 之间天然就会交接。这个坑我在做长会话测试时感受很明显:东西越堆越多,模型反而更容易抓不住重点。
所以,“长时对话场景下的上下文保持机制与状态恢复策略”不是一个简单的 Prompt 技巧问题。真正麻烦的是工程问题:Agent 怎么在长会话里不跑偏?前面说过的接口、端口、约束,过了十几轮还能不能找回来?多 Agent 协作时,每个角色做过什么、否定过什么、留下了什么结论,后面还能不能接上?服务重启或会话回退后,又能不能恢复到一个还能继续干活的状态?
这篇文章不是单纯复述文档。我会结合 JiuwenSwarm 的公开资料、GitHub 源码、PyPI 文档、OpenJiuwen 网站,以及自己在 Web Chat 里跑出来的一组实验,把它的上下文瘦身、长期记忆和状态恢复机制捋一遍。
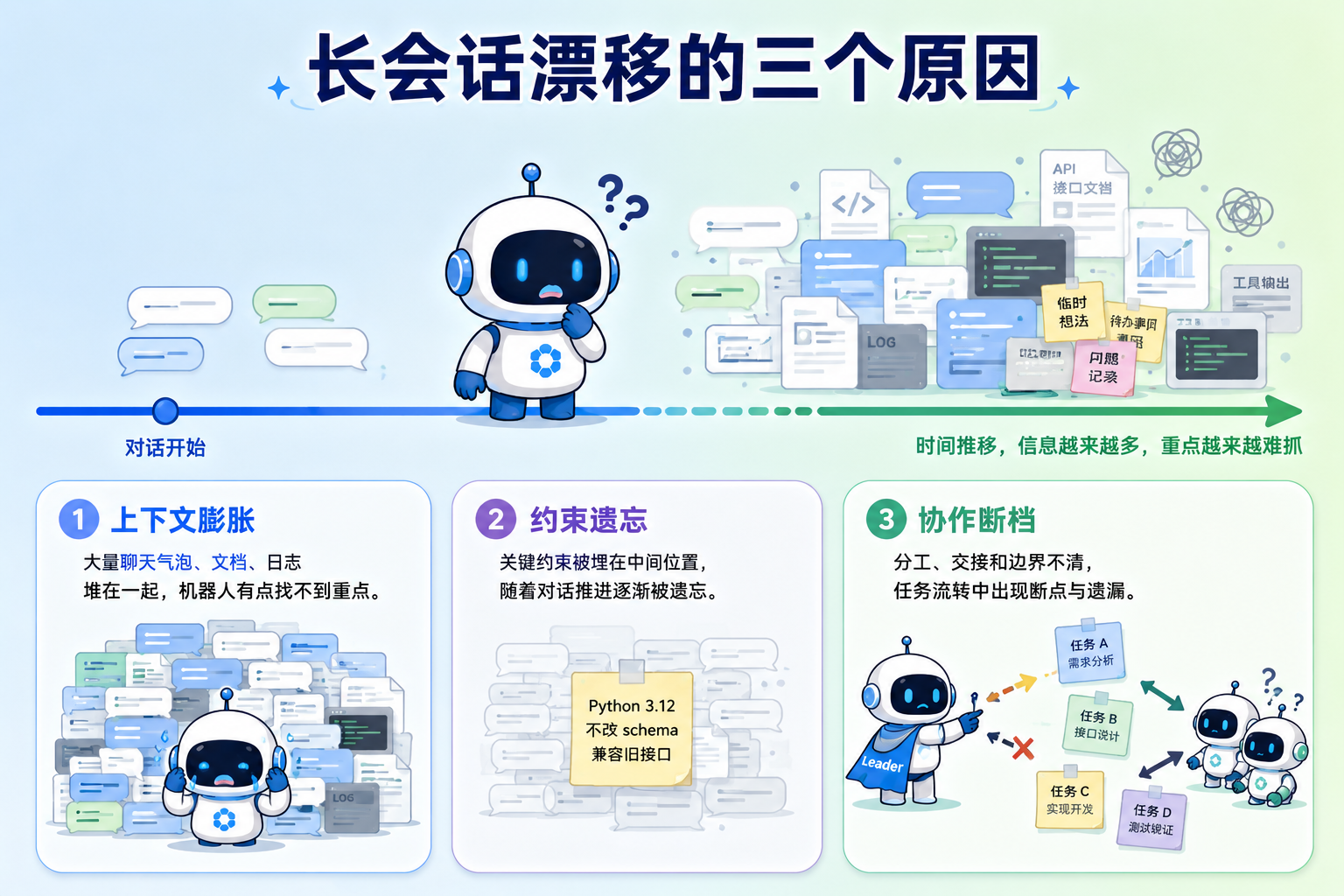
一、长会话为什么容易“漂移”
长时对话里的“漂移”,很多时候不是某一次回答突然翻车,而是信息在一轮一轮传下去的过程中慢慢走样。
-
第一类是上下文膨胀。对话轮次一多,历史消息、工具返回、代码片段、文件内容都会往上下文里堆。很多内容在当时确实重要,但到了当前这一步已经没那么关键了。如果每一轮都把全部历史塞回 Prompt,模型就得在越来越厚的一摞材料里找几句真正有用的话,成本和噪声都会上去。
-
第二类是约束遗忘。用户一开始说过“只用 Python 3.12”“输出必须兼容旧接口”“不要改数据库 schema”,但这些话可能被埋在中间轮次。长上下文模型也不是总能稳定抓住中间位置的信息,学术界常用 Lost in the Middle 来描述这种现象。
-
第三类是协作断档。Agent Swarm 场景下,Leader 要拆任务,Teammate 要执行子任务,执行结果还要回到 Leader 汇总。如果协作过程只靠原始聊天记录传来传去,后来者很容易拿到一大堆细节,却看不清真正的决策、分工和边界。
所以,长会话状态管理的关键不是“把上下文开到最大”,而是把信息分层:
-
当前窗口只保留正在推进任务所需的高价值上下文。
-
长期事实、用户偏好、项目约束沉淀到可检索记忆。
-
团队协作中的决策、经验和成员能力沉淀到团队记忆。
-
文件与会话状态出现偏差时,提供可解释、可边界化的回退能力。
JiuwenSwarm 的长对话实践,基本就是围绕这几层展开。后面的实战部分,也会按这个思路一步步跑。
二、JiuwenSwarm 的定位:从单 Agent 能力到 Coordination Engineering 协同工程
openJiuwen 官网把平台定位成生产级 AI Agent 平台,重点提到事件驱动的多 Agent 控制、任务状态持久化、多实例状态管理、任务中断后的断点继续等能力。JiuwenSwarm 则是 openJiuwen 生态里的多智能体协作系统。
从我这次查资料和跑实验的感受看,JiuwenSwarm 的核心能力主要落在这几块:任务规划、自演进、上下文瘦身、记忆随行、浏览器操控优化,以及小艺、飞书等 Channel 接入。
截至 2026 年 5 月 22 日,jiuwenswarm 最新发布版本为 0.2.0,发布时间为 2026 年 5 月 18 日,Python 版本要求为 >=3.11,<3.14。
我们可以通过以下命令安装并启动它:
pip install jiuwenswarm
jiuwenswarm-init
jiuwenswarm-start
注意:如果 Python 版本过高,可能会安装失败,类似这样的错误
ERROR: Ignored the following versions that require a different python version: 0.2.0 Requires-Python >=3.11,< 3.14
ERROR: Could not find a version that satisfies the requirement jiuwenswarm (from versions: none)
ERROR: No matching distribution found for jiuwenswarm
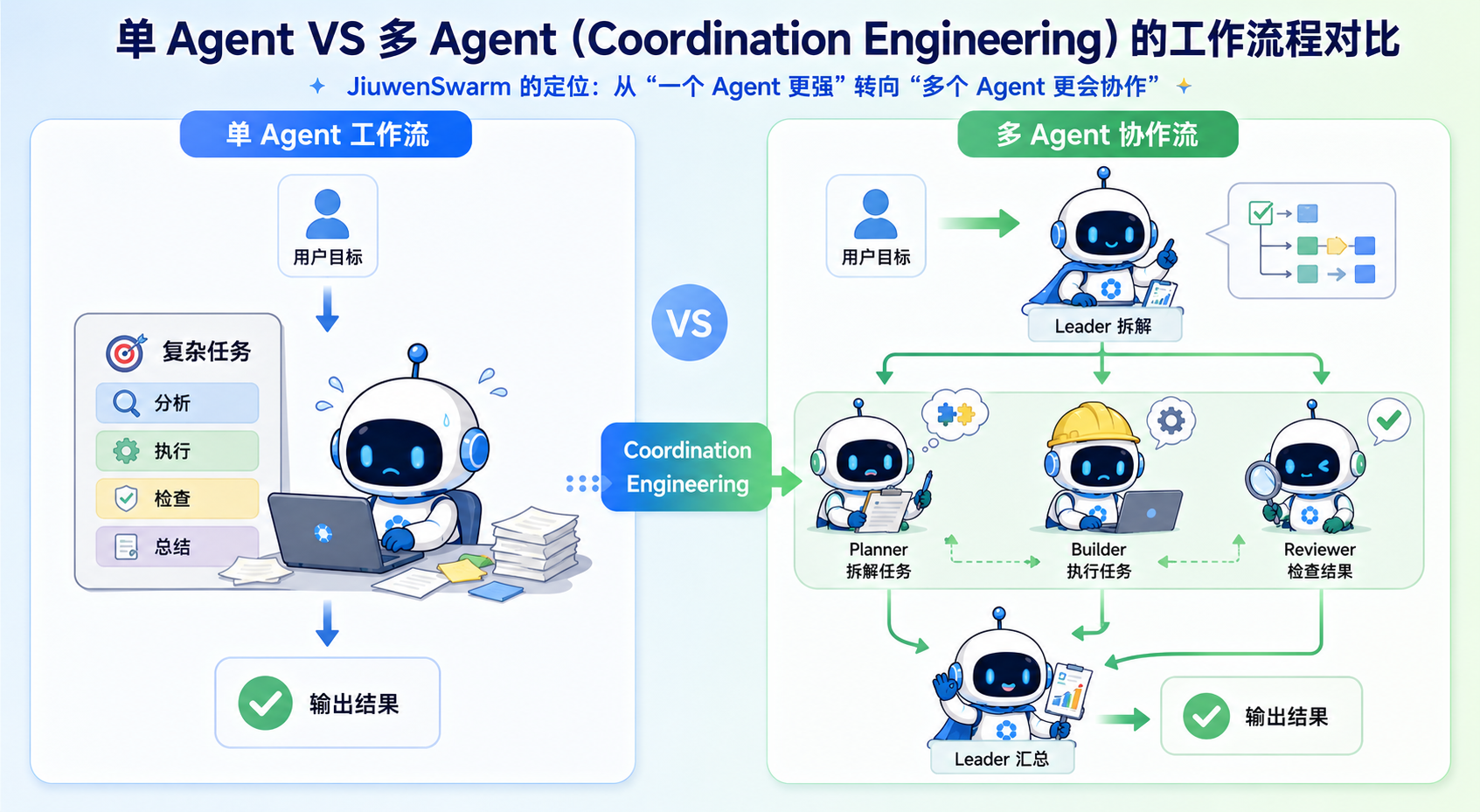
JiuwenSwarm 代表的方向,可以用 Coordination Engineering 来概括。说白了,就是重点不只放在“让一个 Agent 更强”,而是放到“让多个 Agent 更会协作”上。复杂任务很多时候不是单点能力不够,而是分工、交接、并行、审核、汇总这些环节没有组织好。
把长时对话放到这个框架里看,就不只是“一个助手怎么记住过去”,而是“一组智能体怎么在长流程里共享上下文、继承经验,并且稳定交付”。
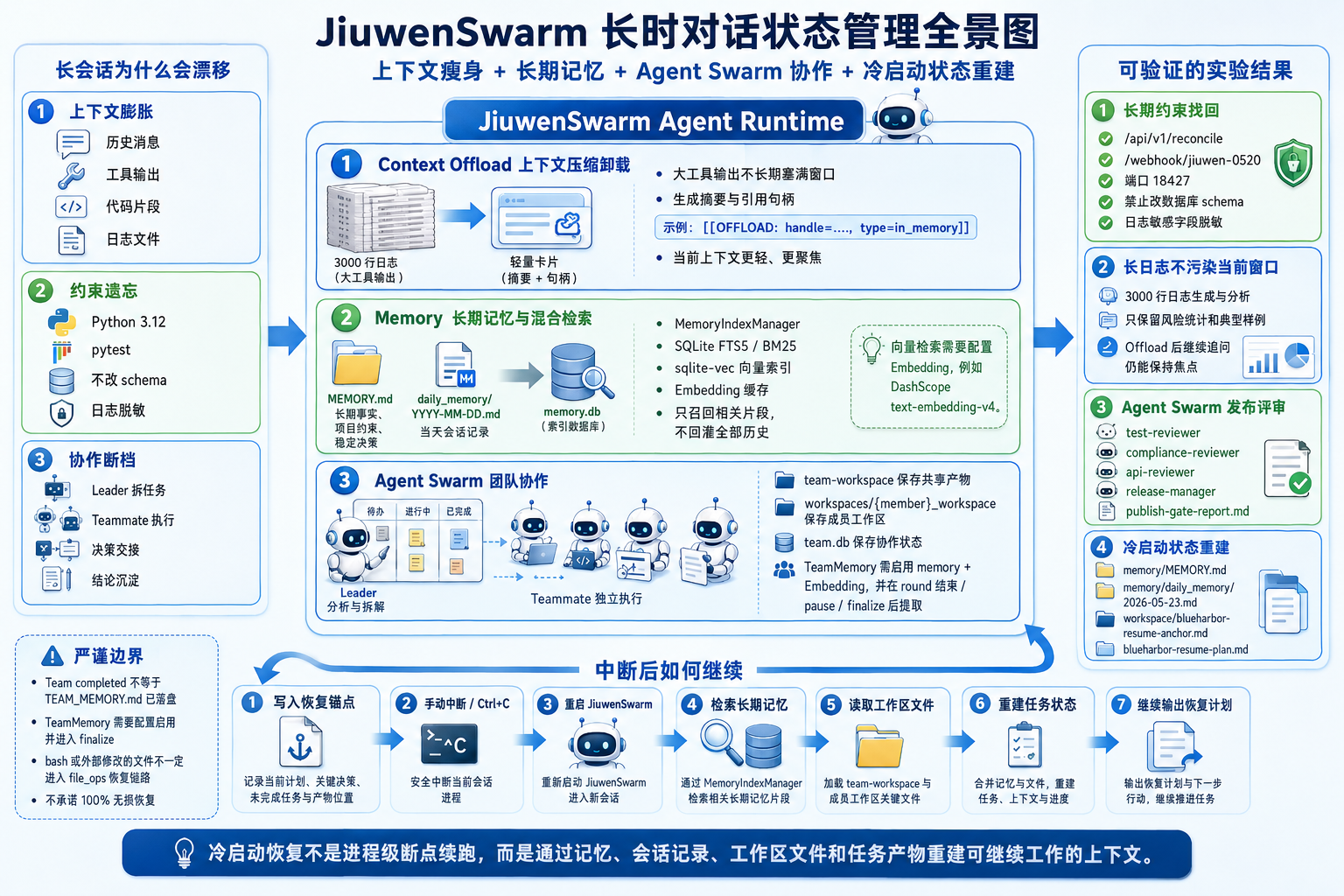
三、上下文 Token 更新链路:Context Offload(上下文压缩卸载)让当前窗口轻下来
长会话最先顶上来的压力,就是上下文窗口。JiuwenSwarm 文档里的上下文压缩卸载机制(Context Offload),处理的就是一个很实际的问题:哪些内容继续留在当前上下文里,哪些内容该摘要、卸载,或者只留一个索引。
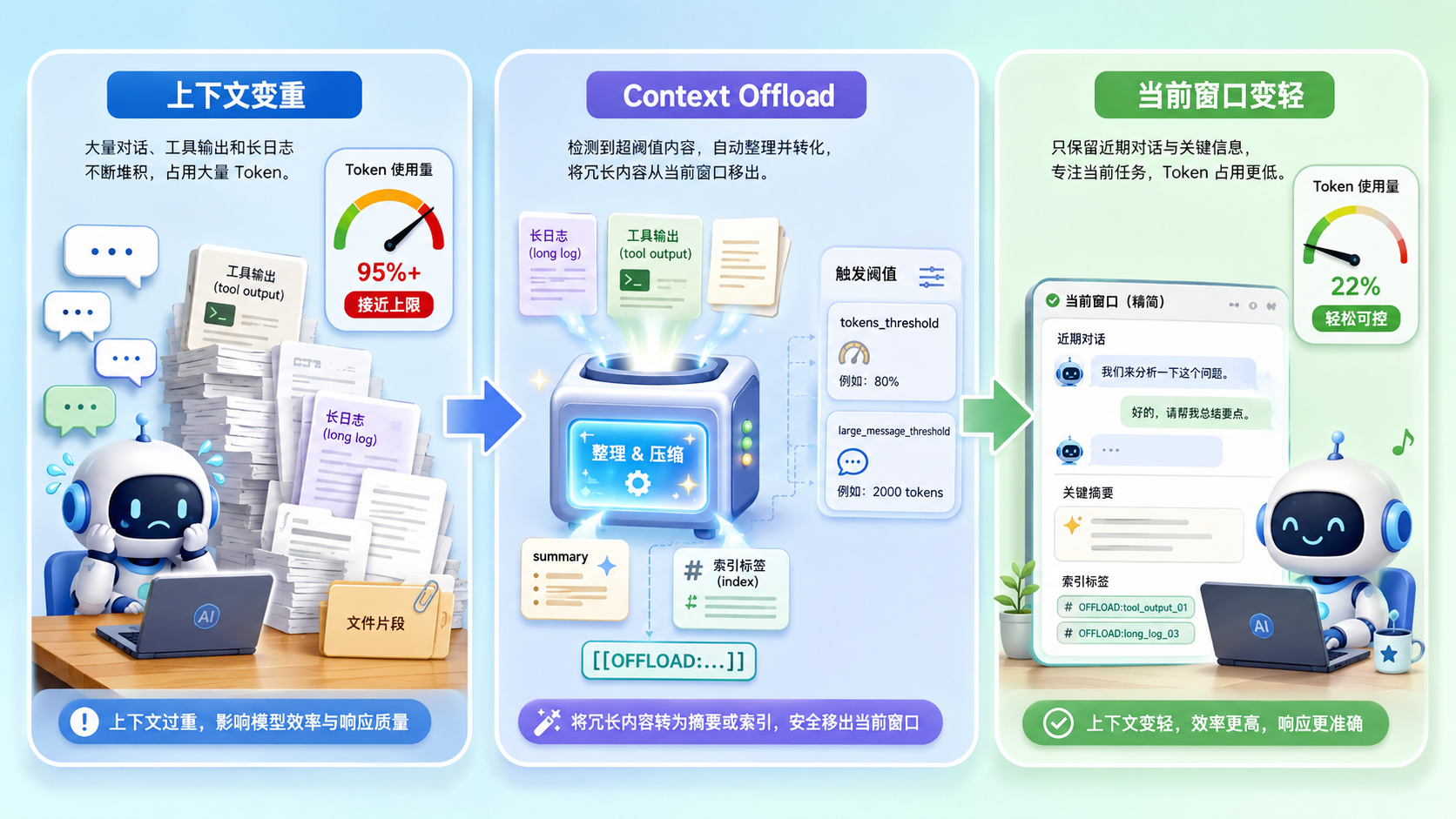
官方文档把它类比成“办公桌整理”:当桌面文件(消息数量)或纸张厚度(Token 数量)超过阈值时,系统不会直接把历史清空,而是把那些“大而暂时没那么关键”的内容归档起来,只在桌面上留一份简要索引。
换成工程语言看,这个“办公桌”其实不是一个单一开关,而是 JiuwenSwarm Context Engine 里一组上下文整理链路。它不是想把所有历史都永久塞进 Prompt,而是尽量让当前窗口只保留近期对话、关键摘要和必要索引,让模型把注意力放在眼前这件事上。
官方文档里用 messages_threshold、tokens_threshold、large_message_threshold 等参数解释触发逻辑,其中 tokens_threshold 文档口径写的是默认 20,000,large_message_threshold 给出的是 1,000 Token 示例。再去看当前 develop 分支源码的默认配置,会发现 JiuwenSwarm 的上下文引擎已经拆得更细,比如 message_summary_offloader_config、dialogue_compressor_config、current_round_compressor_config 和 round_level_compressor_config。这几组配置盯的对象不完全一样,阈值也不一样,合在一起才是完整的上下文 Token 更新链路。
这些配置项可以分成三类理解:
-
触发条件:
messages_threshold:按消息数量触发。文档中支持配置,当前源码默认配置里部分链路为null,表示不以消息数量作为主要触发条件。tokens_threshold:按 Token 数量触发。当前源码默认配置中,不同链路阈值不同,例如 message summary offloader 为 60,000 tokens,dialogue / current round compressor 为 100,000 tokens,round-level compressor 为 230,000 tokens。
-
卸载对象选择:
large_message_threshold:识别超长消息。当前源码默认配置的 message summary offloader 中为 60,000 tokens,用于优先处理占用上下文的大块内容。offload_message_type:指定处理哪类消息。默认配置中 message summary offloader 主要处理tool类型消息,所以它更像是在处理冗长工具输出,而不是随便改写用户原始指令。
-
保留与保护策略:
messages_to_keep/keep_last_round:控制近期消息或最近 round 是否保留。这里别把它当成所有链路都通用的固定规则;例如 round-level compressor 默认keep_last_round: true,但 message summary offloader 默认是false。protected_tool_names:保护指定工具输出不被 offloader 处理,例如read_file:*SKILL.md和reload_original_context_messages。
卸载后的状态是什么样的?

系统会把冗长内容从当前 Prompt 里抽出来,通过采样、摘要或 [[OFFLOAD:...]] 这类索引标记留下追溯线索。放回“办公桌”这个比喻里,就像把厚厚一摞报告先搬走,但桌上还留着“详细材料见某处档案”的便签。这里别理解成任何时候都能自动、完整、精准地召回原始数据。更稳妥的说法是:它先把当前 Prompt 压力降下来,同时保留必要时回查上下文的路径。
Context Offload 最大的价值,就是把上下文窗口从堆得满满当当的“历史仓库”,重新拉回成一个更轻的“工作现场”。模型当前看到的内容更短、更聚焦;工具返回和历史材料则通过摘要、索引或原始记录留下回查线索。长时对话里第一步要解决的,其实就是别再无限追加,让当前窗口真正服务当前任务。
四、JiuwenSwarm 的三层记忆体系:个人记忆、经验记忆与团队记忆
只做上下文卸载还不够,卸载解决的是“当前窗口别太重”,长期记忆要解决的是“过了几轮、隔了几天,还能不能想起来”。
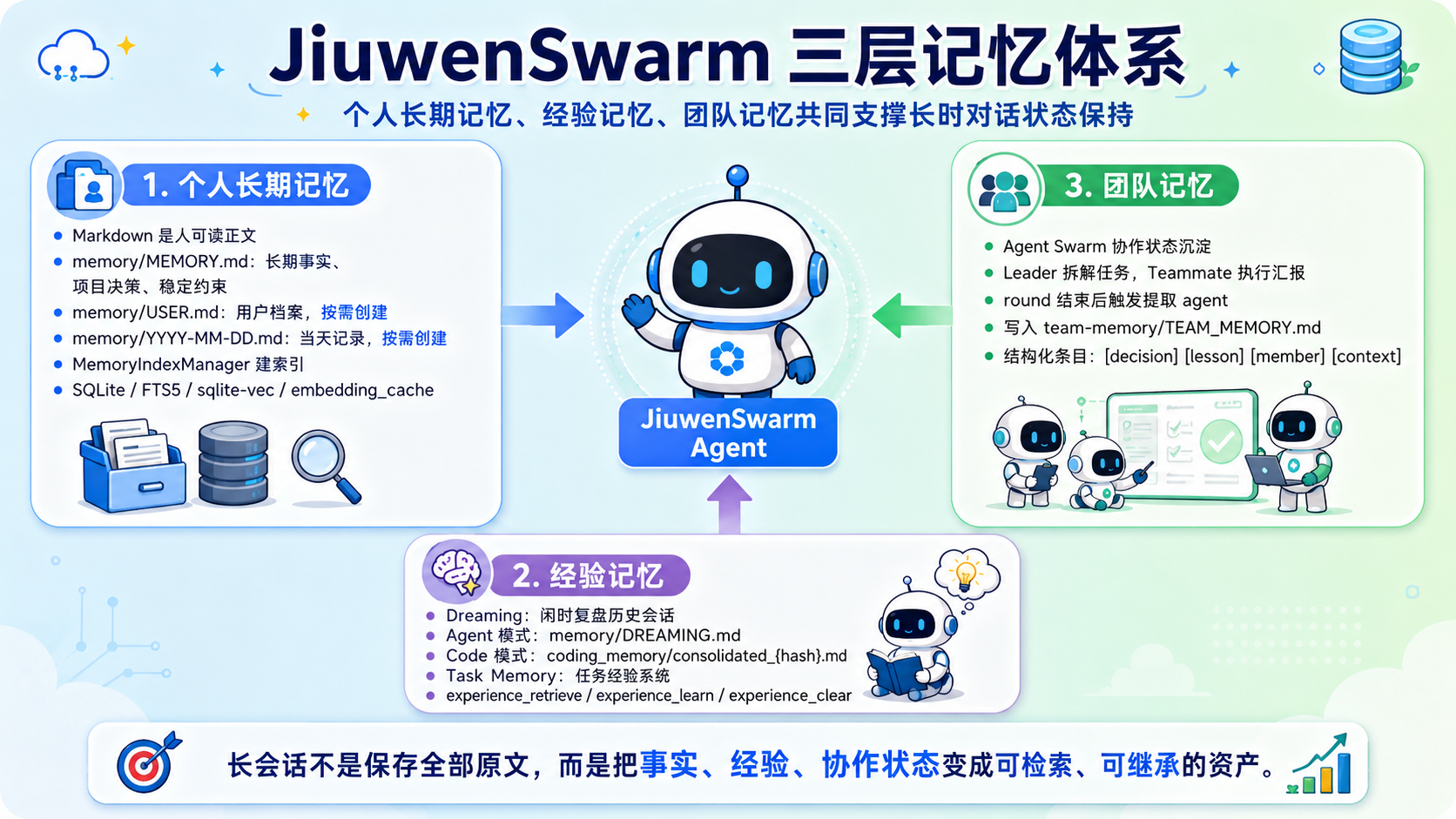
从长时对话角度看,我更愿意把 JiuwenSwarm 的记忆能力分成三层:
-
第一层是面向个人工作区的内置长期记忆,回答“事实、偏好、约束放在哪里、怎么找回来”;
-
第二层是 Dreaming 与 Task Memory,回答“做过的事怎么沉淀成经验”;
-
第三层是 Agent Swarm 团队记忆,回答“多 Agent 协作里形成的决策、成员能力和上下文,下一轮怎么继承”。
4.1 内置长期记忆:Markdown 正文与索引召回
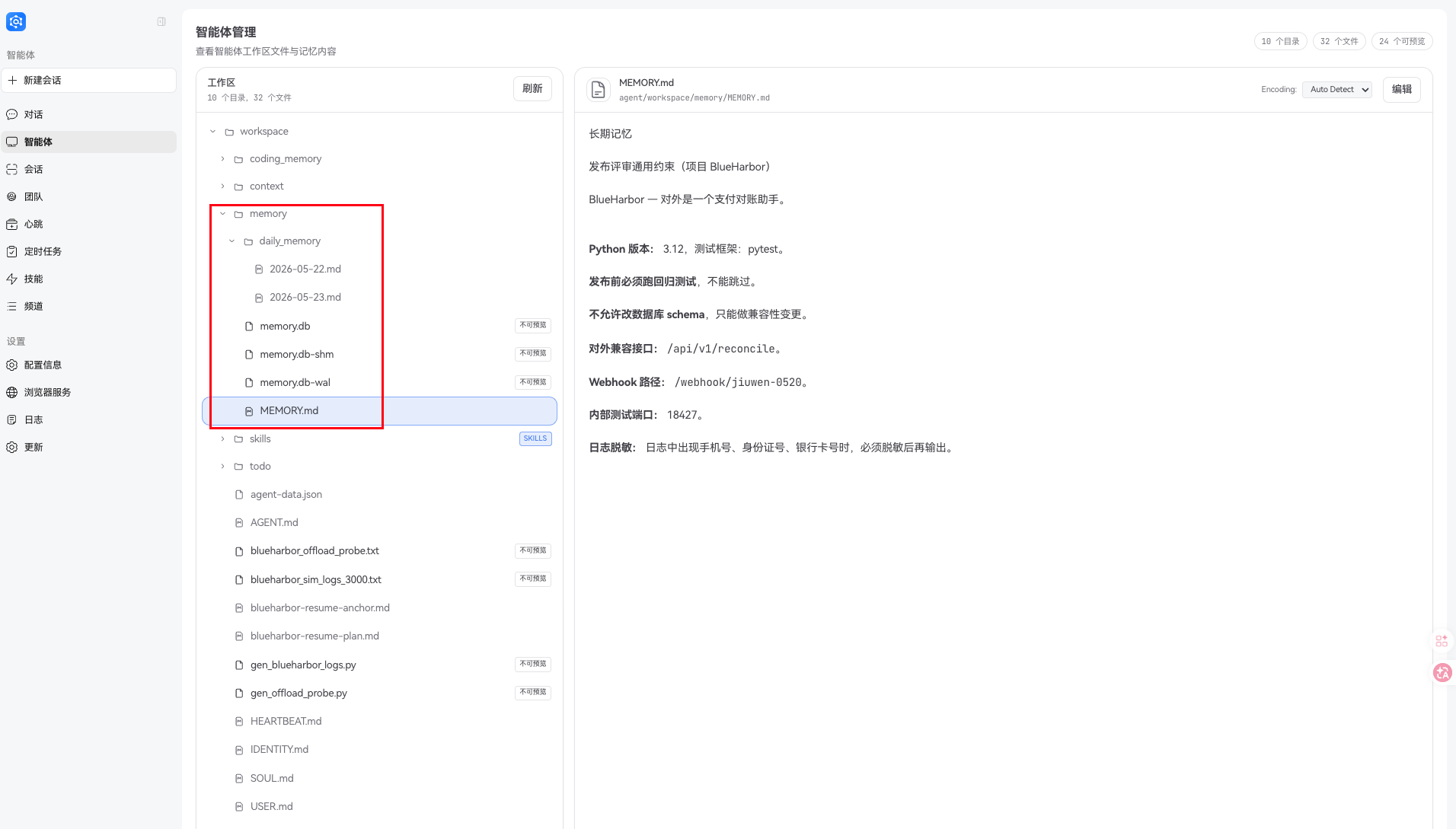
JiuwenSwarm 的记忆体系不止一种形态:memory.engine 可以选 builtin、external、both 或 none,外接记忆还支持 OpenJiuwen LTM、Mem0、OpenViking 或自定义插件。这里先看最容易理解、也最适合拿来解释长时对话状态保持的内置记忆:正文是 Markdown 文件,索引层负责召回。官方文档给出的逻辑结构是:
{workspace_dir}/memory
├── MEMORY.md
├── USER.md
└── daily_memory/YYYY-MM-DD.md
这里有个容易误会的点:这不是说初始化后的工作区一定会同时出现这三个文件。
但从源码和实际测试看,记忆工具允许写入的路径包括 memory/MEMORY.md、memory/USER.md 和 memory/daily_memory/YYYY-MM-DD.md 这类日期文件;其中 memory/USER.md 和日期文件通常是在发生相应记忆写入时才创建。
这几类记忆文件的职责很清楚:
| 记忆文件类型 | 存放内容与职责 |
|---|---|
memory/MEMORY.md |
存放长期有效的项目决策、偏好、持久事实。 |
memory/USER.md |
在被创建后用于存放用户档案,例如职业、偏好、位置、长期习惯。 |
memory/daily_memory/YYYY-MM-DD.md |
这类日期文件在被创建后用于记录当天会话和工作上下文。 |
这种设计的好处是透明的,记忆不是藏在一个看不见的黑盒里,而是用户可以直接打开、编辑、备份的 Markdown 文件。
作为开发者而言,这点非常重要:因为如果长期记忆完全不可见,出了问题很难调试,也很难相信它到底“记住了什么”。
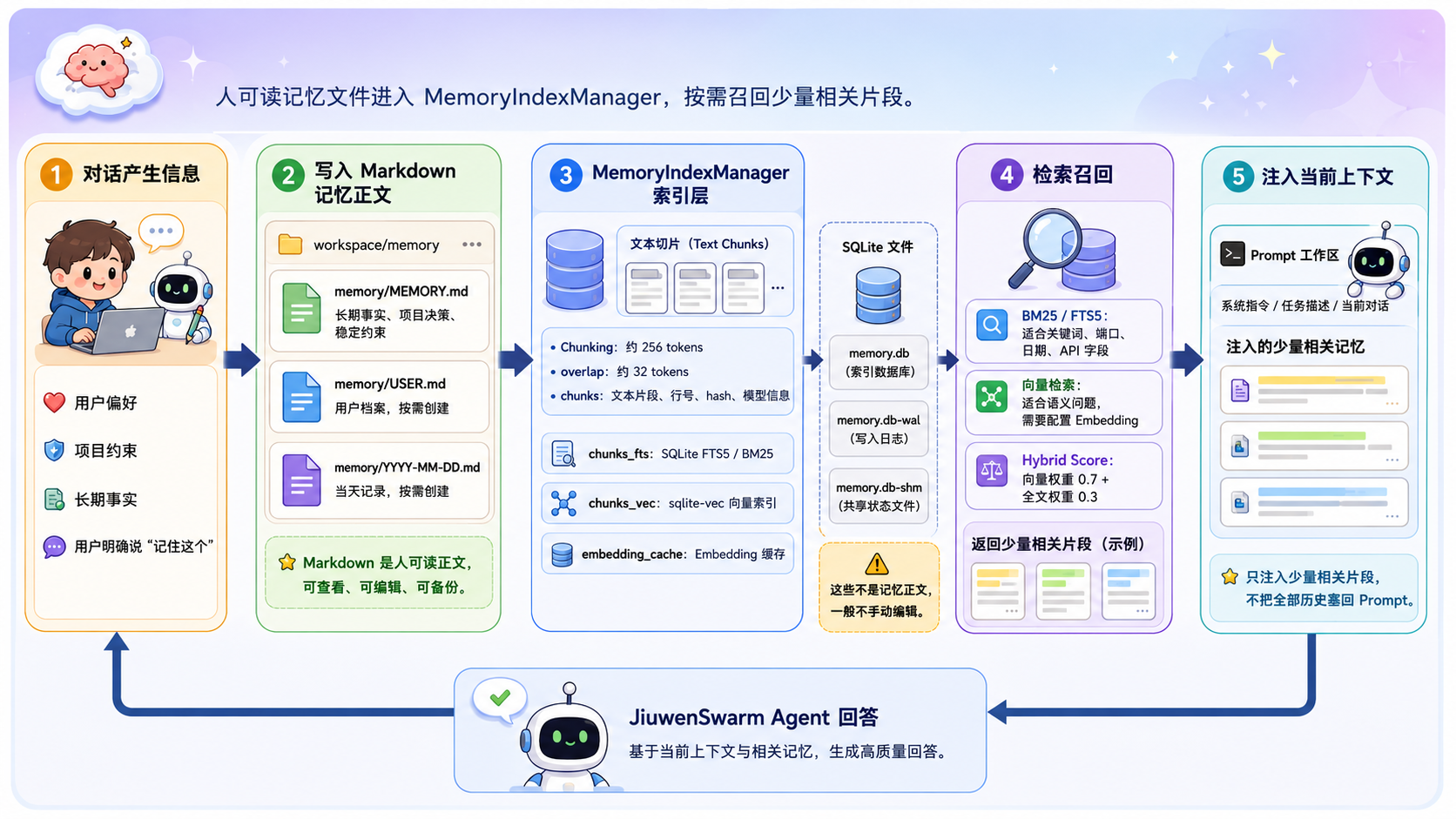
让这些 Markdown 真正适合长时对话的,是源码里的 MemoryIndexManager。翻 jiuwenswarm/agents/harness/common/memory/manager.py 和默认配置时会发现,它会把配置来源中的记忆文件、会话记录等内容切块后写入 SQLite,并维护几类索引结构:
| 索引类型 | 用途说明 |
|---|---|
chunks |
存放切块后的文本、行号、hash、模型信息等。 |
chunks_fts |
基于 SQLite FTS5 的全文索引。 |
chunks_vec |
基于 sqlite-vec 的向量索引。 |
embedding_cache |
Embedding 缓存,减少重复计算。 |
所以在 JiuwenSwarm 的工作区里,除了 memory/MEMORY.md 这类人能直接读的记忆正文,用户还可能看到 memory.db、memory.db-wal、memory.db-shm 这类文件。它们不是新的记忆正文,而是 SQLite 的本地索引和写入辅助文件:memory.db 保存索引数据库,memory.db-wal 是 Write-Ahead Log 写入日志,memory.db-shm 是 WAL 模式下的共享状态文件。平时想看“系统到底记了什么”,看 Markdown 就够了;这些数据库文件主要是给检索用的,一般不用手动改。
默认 chunk 配置约为 256 tokens,overlap 约为 32 tokens。这个粒度不算大,方便召回;同时又留了一点重叠,避免切块以后语义断得太生硬。
检索时,内置记忆默认会走 BM25 全文检索;如果配置了 EMBED_API_KEY 等 Embedding 服务,系统可以进一步使用向量 + BM25 的混合检索。官方文档也提醒,不配置 Embedding 时会使用 mock provider,所以语义向量召回不能默认理解成“开箱就是生产级效果”。
- FTS5 / BM25 全文检索,适合查找环境变量、API 字段、端口号、日期、专有名词等字面信息。
- 向量检索,适合“之前那个部署约束”“上次讨论的风险点”这类语义模糊问题,前提是正确配置了可用的 Embedding 服务。
混合检索会把向量分数和全文分数加权合并。文档中的默认权重是向量 0.7、全文 0.3。这个设计挺贴近长对话的真实用法:用户未必记得原话,但经常记得“之前好像聊过那件事”。
所以 JiuwenSwarm 的内置长期记忆机制,并不是“把所有历史重新塞回 Prompt”,而是把历史变成可检索资产,需要时再取回少量相关片段。
这里顺手区分一下:Code 模式下还有 coding_memory 工具和 {workspace}/coding_memory/consolidated_{hash}.md 这类编码记忆输出;
Task Memory 则是任务经验系统,经验数据持久化在 workspace/agent/task-data.json,不要和这里的通用 Markdown 记忆混在一起。
4.2 Dreaming 与 Task Memory:把经历沉淀成经验
长期记忆还有一个更实际的问题:什么东西值得写?什么时候写?JiuwenSwarm 给了几条互补路径。
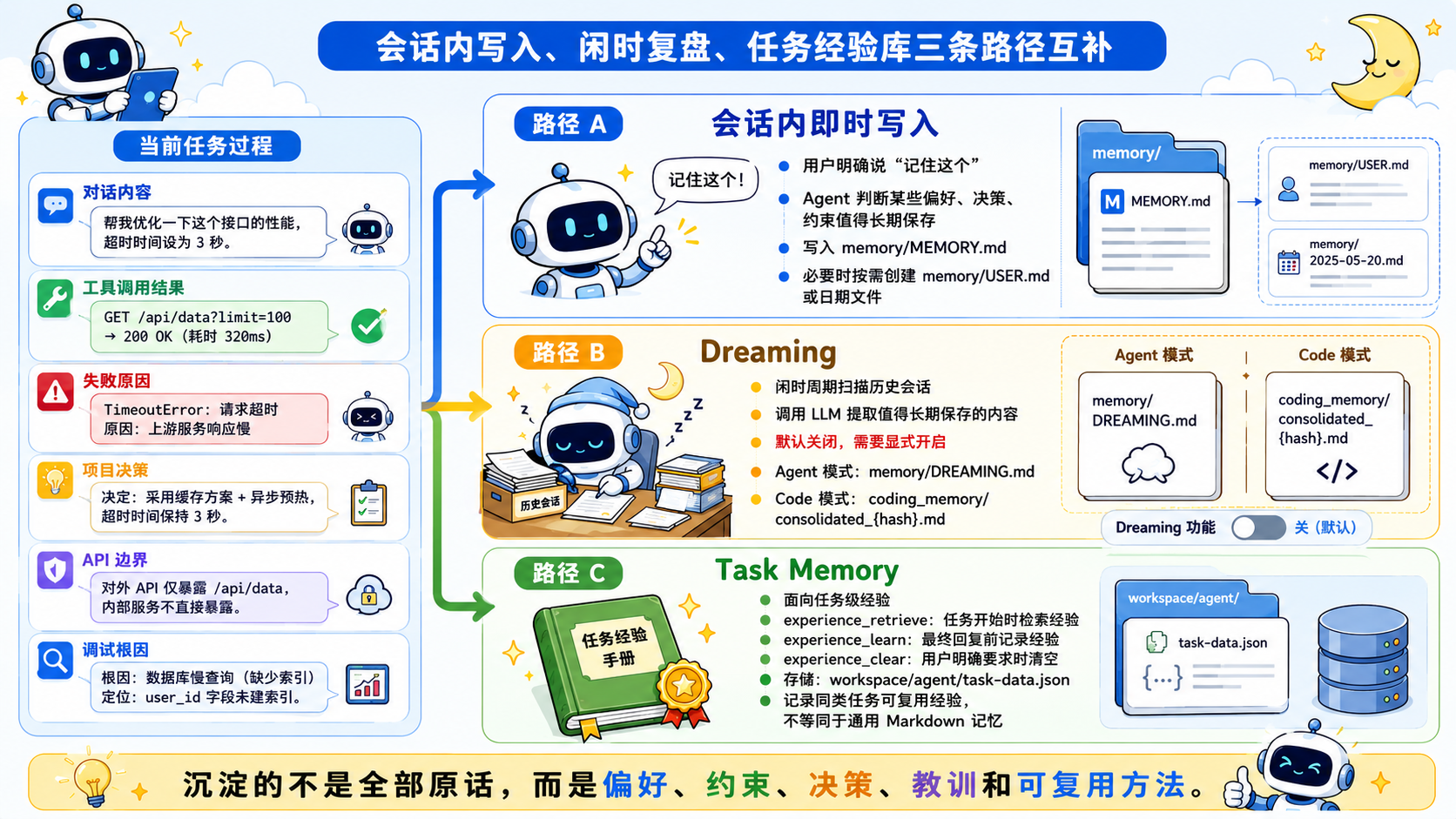
-
第一条是会话内即时写入。比如用户明确说“记住这个”,或者 Agent 判断某个事实、偏好、项目决策确实值得长期保存,就可以写入
memory/MEMORY.md,也可能按需创建memory/USER.md或当天日期命名的 Markdown 记录。 -
第二条是 Dreaming。文档把它描述成后台离线记忆整理机制,默认关闭,需要显式开启。开启后,系统会在闲时周期性扫描历史会话,调用 LLM 提取值得长期保存的内容。Agent 模式下可以沉淀用户偏好、背景、关注领域;Code 模式下可以沉淀调试根因、API 边界行为、设计决策等技术经验。
-
第三条是 Task Memory。它面向任务级经验,不是普通事实。它关心的是“同类任务下次怎么少踩坑”,例如过去某次工具调用为什么失败、某类接口为什么容易超时、某个方案为什么被放弃。
这三者组合起来,构成了 JiuwenSwarm 的长期记忆飞轮:
-
会话内写入解决“当下就知道该记住”的信息。
-
Dreaming 解决“事后复盘才知道有价值”的信息。
-
Task Memory 解决“同类任务可复用”的经验。
这比简单保存聊天记录更适合长时对话,因为真正有价值的往往不是每句话原文,而是决策、约束、偏好、教训和下次能复用的方法。
4.3 Agent Swarm 团队记忆:让协作状态也能继承
在单 Agent 长对话里,比如网页版的 DeepSeek Chat,记忆主要服务于“我和用户之间发生过什么”。
到了 Agent Swarm 里,问题会升级成“这一组 Agent 之间形成了什么共识”。
JiuwenSwarm 的团队协作链路可以概括下图:
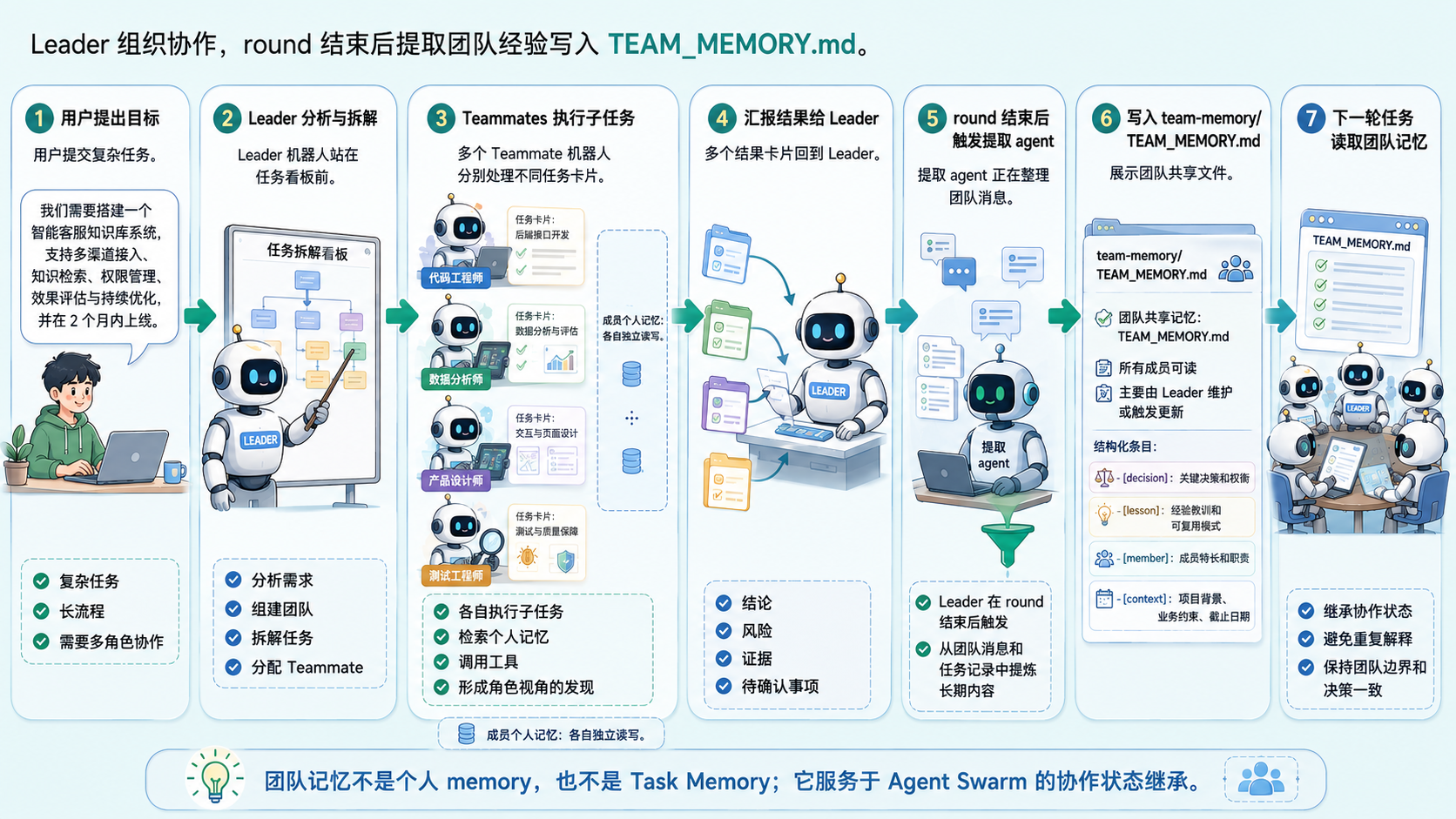
Agent Swarm / Coordination Engineering 比较适合链路长、角色分工明显、可以并行推进、需要多轮迭代的任务。比如合同审查、竞品分析、SQL 优化、毕业设计陪伴、游戏策划协作等,这些都不是一个“回答”就能结束的事情。
但协作本身也会产生记忆需求:
-
Leader 做过哪些关键决策?
-
哪个 Teammate 擅长什么?
-
哪些方案已经被否定,原因是什么?
-
哪些约束必须跨 round 保持?
-
哪些经验应该沉淀为下一次任务的默认流程?
JiuwenSwarm 文档里的团队记忆机制,就是为这类场景准备的。持久团队会有双层记忆:
| 记忆层级 | 读写权限与机制 |
|---|---|
| 成员个人记忆 | 由成员各自读写,保存自己的任务经验。 |
| 团队共享记忆 | 所有成员只读,由 Leader 在 round 结束后触发提取 agent 写入 TEAM_MEMORY.md。 |
团队记忆会把信息分成几类:
| 标签类型 | 内容解释 |
|---|---|
[decision] |
关键决策和权衡。 |
[lesson] |
经验教训和可复用模式。 |
[member] |
成员特长和职责。 |
[context] |
项目背景、业务约束、截止日期等。 |
这套机制让 Agent Swarm 不只是“临时多开几个 Agent”,而是更像一个能积累组织经验的协作系统。
再往外看,Swarm Skills Hub 把这种协作经验做成了可以封装和共享的东西。我在 2026 年 5 月 22 日查看 Hub 页面时,页面显示已有 247 个 Swarm Skills,覆盖软件开发、办公生产力、内容创作、多模态与媒体、数据与科学研究、合规与法律、生活与健康、金融财富等类别。社区里也能看到合同评审团、数据分析团队、竞争洞察团队这类更贴近真实场景的团队技能。
近期的 arXiv 论文《Swarm Skills: A Portable, Self-Evolving Multi-Agent System Specification for Coordination Engineering》也把重点放在类似问题上:多智能体协作协议不应该长期锁在框架内部代码或静态配置里,而应该被抽象成可分发、可移植、可持续演进的一等资产。
论文中提出的 Swarm Skills 规范,试图通过角色、工作流、执行边界以及自演进语义结构来封装多 Agent 协作能力,并使用开源 JiuwenSwarm 作为参考实现,验证这种规范在协作工程场景中的可行性。
对于长时对话来说,这一点很关键。一次长流程任务里沉淀下来的,不只是事实记忆,还有“这个团队以后该怎么协作”的方法记忆。
五、冷启动与状态恢复:先把边界说清楚
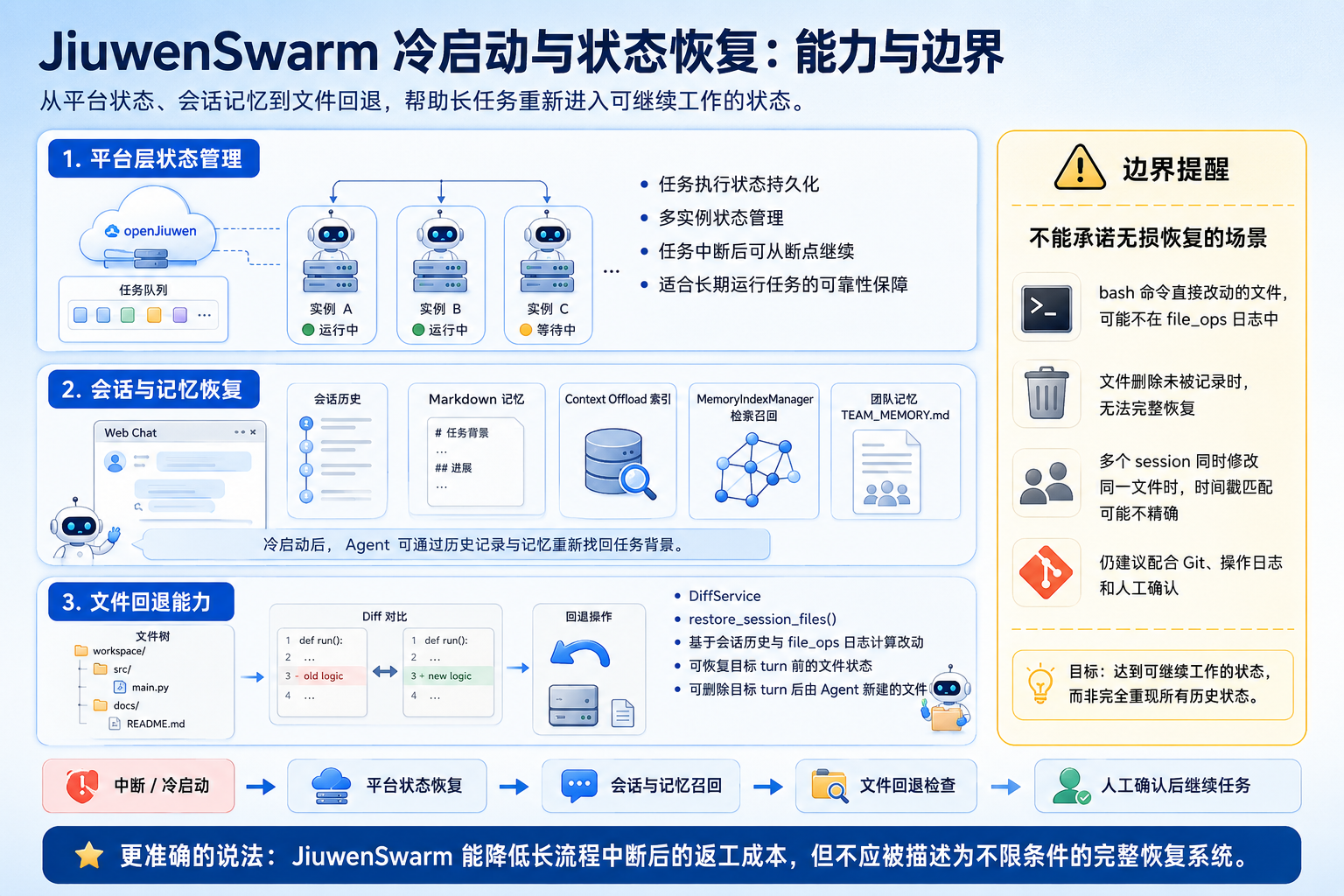
冷启动这个话题很容易被写夸。为了不把能力边界说虚,先把它拆成三层看。
-
第一层是 openJiuwen 平台层面的状态管理。官网资料提到任务执行状态持久化、多实例状态管理、任务中断后可从断点继续执行。也就是说,openJiuwen 的底座不是只服务一次性问答,而是把长期运行任务的可靠性也放进了设计里。
-
第二层是 JiuwenSwarm 会话与上下文层面的恢复。会话历史、记忆文件、Context Offload 索引、Markdown 记忆和团队记忆,共同构成了“重新进入任务时还能读取的状态”。即使当前上下文窗口被压缩,长期记忆与会话记录仍然能帮 Agent 找回任务背景。
-
第三层是文件回退能力。源码中的
DiffService与restore_session_files()可以基于会话历史和 file_ops 日志,计算某个 turn 之后发生的文件改动,并把相关文件恢复到目标 turn 前的状态,或者删除目标 turn 之后由 Agent 新建的文件。
但这绝对不能理解成“任何崩溃都能完整恢复”。源码注释里把限制写得很清楚:bash 命令改动的文件不在 file_ops 日志中;文件删除操作未记录时无法恢复;多个 session 共同修改同一个文件时,也可能因为时间戳匹配不精确而出现边界。
所以我会把它说得保守一点:JiuwenSwarm 已经具备长任务所需的状态持久化、记忆召回、会话回退和部分文件恢复能力;它能明显降低长流程中断后的返工成本,但不是那种什么场景都能兜底的完整恢复系统。
这点边界感很重要。真实工程系统要让人信任,不是靠把能力说满,而是把能做什么、不能保证什么都讲清楚。该靠用户确认、运行日志或外部版本控制系统兜底的地方,就别假装系统自己全包了。
六、Web Chat 实战:用一次“发布前变更评审”验证长会话能力
为了把前面的机制落到具体场景里,我设计了一个可以直接在 Web Chat 中复现的模拟案例。它不需要真实业务代码,也不用写入敏感信息;按顺序复制 Prompt,就能观察长期记忆、混合检索、上下文瘦身、Agent Swarm 协作和会话恢复边界。
设定:
我们正在发布一个项目 – “BlueHarbor 对账助手”。这次测试要看三件事:Agent 能不能在长对话中记住发布约束,能不能处理大量日志和干扰信息,能不能在跨会话时找回关键事实,并在 Agent Swarm 模式下组织一次发布前评审。
6.1 安装和启动
# 设置虚拟环境,避免与本机冲突
python -m venv .venv
source .venv/bin/activate
# 安装最新版 jiuwenswarm
pip install --upgrade pip
pip install jiuwenswarm
# 初始化
jiuwenswarm-init
# 启动服务
jiuwenswarm-start
启动后通常访问:
http://localhost:5173
如果你更喜欢终端交互,也可以安装 TUI。为了截图和复现方便,我这次主要用 Web Chat UI。
pip install jiuwenswarm-tui
jiuwenswarm-tui
要真正开始对话,还需要先 配置模型。我这里用的是 deepseek v4 flash,换成其他模型也可以。
6.2 写入长期约束
在 Web Chat 新建一个会话,输入下面这段 Prompt:
我们来模拟一个长会话发布评审。项目代号是 BlueHarbor,对外是一个支付对账助手。
请记住以下长期约束,后续如果我没有重复说明,也要在发布建议中遵守:
1. 默认 Python 版本是 3.12,测试框架是 pytest。
2. 发布前必须先跑回归测试,不能跳过。
3. 不允许改数据库 schema,只能做兼容性变更。
4. 对外兼容接口是 /api/v1/reconcile。
5. Webhook 路径是 /webhook/jiuwen-0520。
6. 内部测试端口是 18427。
7. 日志里出现手机号、身份证号、银行卡号时,必须脱敏后再输出。
请先用“长期约束”和“本轮待办”两个小节总结,并把这些约束写入记忆。
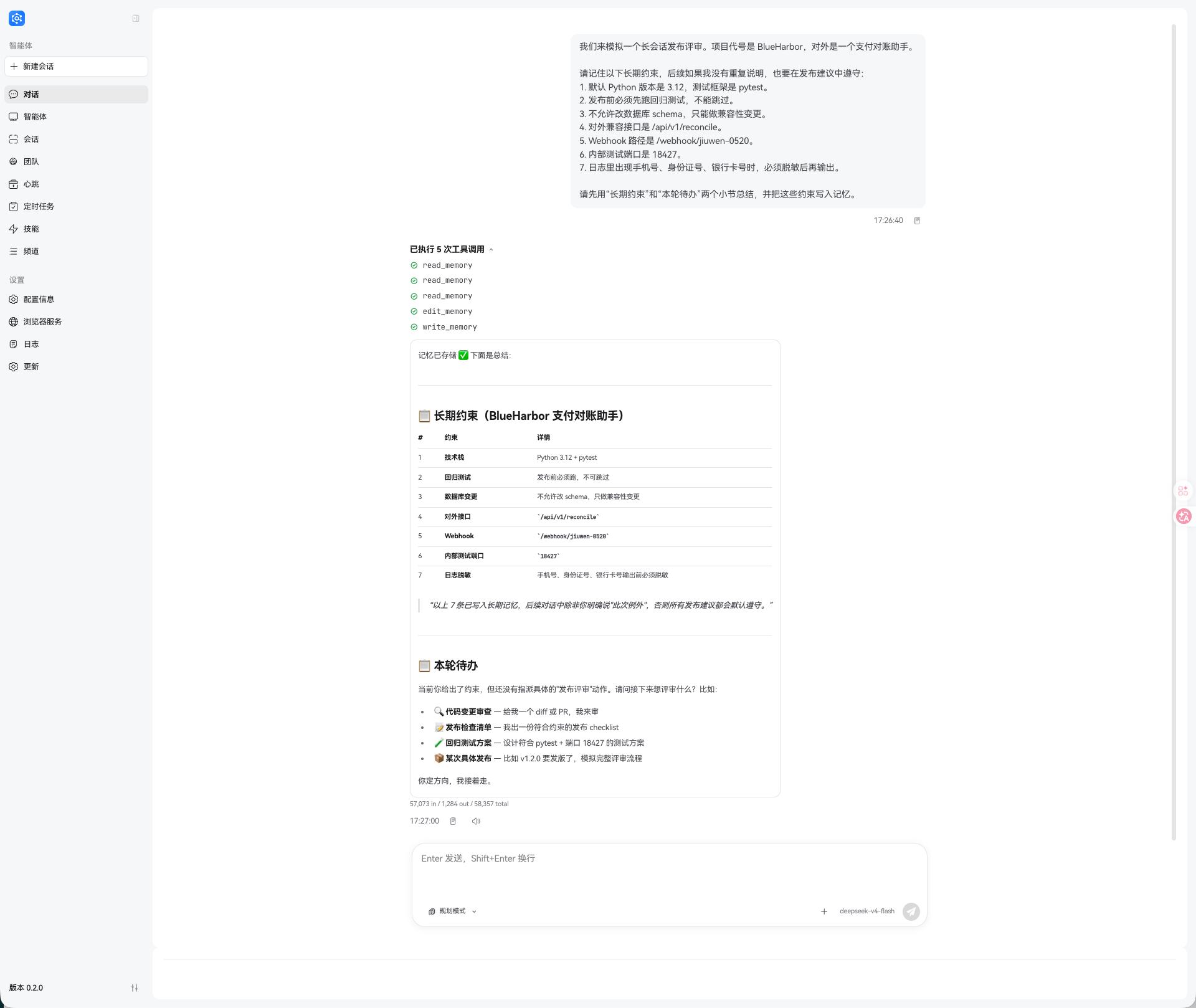
本次测试主要看两点:
- Agent 是否能把约束整理成清单
- 是否会尝试写入
memory/下的长期记忆或当日记忆文件。
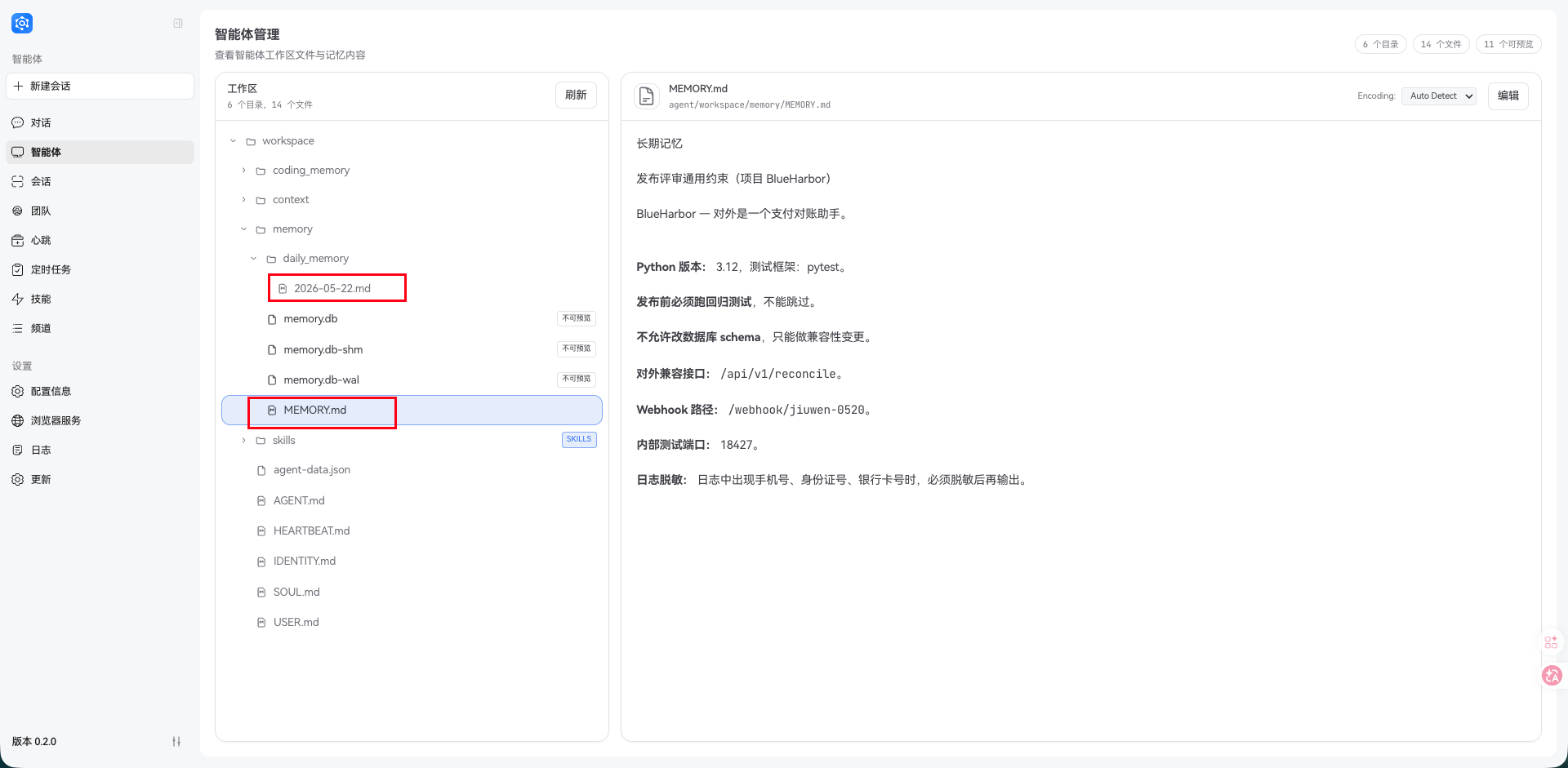
这次测试里,memory/MEMORY.md 生成了,并写入了我们设定的长期约束;日期记忆也触发了,新创建的 memory/daily_memory/2026-05-22.md 里同样写入了这组长期约束。
6.3 制造长上下文和干扰信息
继续在同一会话输入下面这段 Prompt:
下面是一段模拟发布日志和需求池。请你只提取和 BlueHarbor 发布风险相关的信息,忽略无关需求。
【需求池】
- 市场同学希望首页按钮换成绿色,暂不进入本次发布。
- 客服反馈导出 CSV 有时缺少表头,需要排查。
- 运营希望新增节日活动弹窗,暂不进入本次发布。
- 支付回调里出现了未脱敏手机号:13800138000。
- 对账接口 /api/v1/reconcile 在空账单场景下返回 500。
- 有人建议直接新增 reconciliation_status 字段,但本次不允许改数据库 schema。
- 回归测试里 test_reconcile_empty_bill 偶现失败。
- Webhook /webhook/jiuwen-0520 在重试三次后没有记录 request_id。
请输出:
1. P0/P1/P2 风险列表。
2. 哪些事项违反了长期约束。
3. 发布前最小修复计划。
本次测试要看的有3点:
-
它能不能在一堆混杂信息里抓住发布风险。
-
隐私脱敏、空账单 500、禁止改 schema、回归测试失败、Webhook 追踪缺失都应该被识别出来;
-
按钮颜色、活动弹窗这类信息则不应该把它带偏。
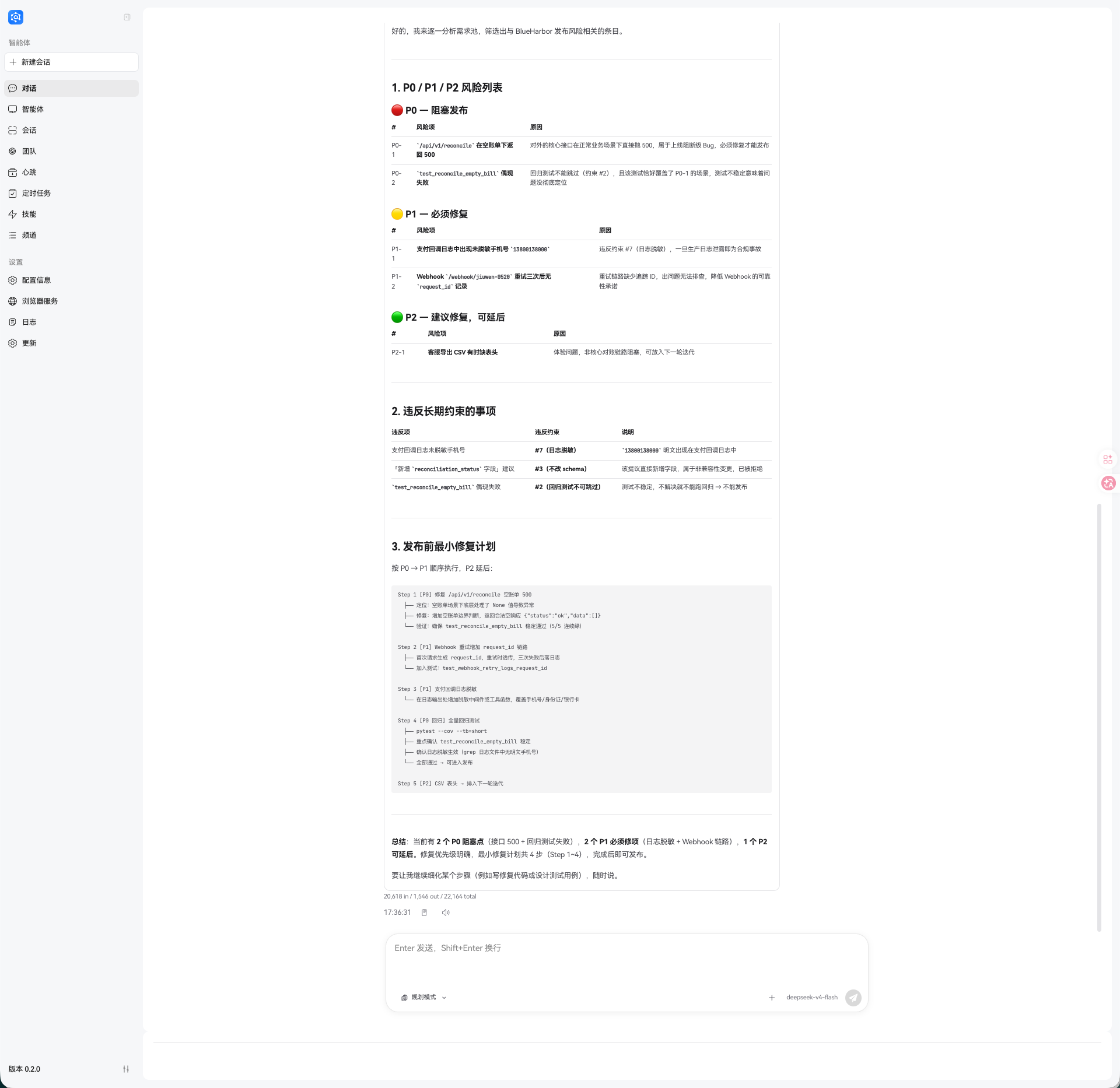
这轮输出里有两点比较关键:
- Agent 把
/api/v1/reconcile空账单返回 500 和test_reconcile_empty_bill偶现失败归为 P0,把支付回调日志未脱敏手机号、Webhook 重试后缺少request_id归为 P1,把导出 CSV 偶尔缺少表头归为 P2; - 同时还单独列出了违反长期约束的事项,例如“日志必须脱敏”“不允许改数据库 schema”“回归测试不可跳过”。
这类输出放在这里比较有说服力,因为它不是简单复述输入,而是在噪声里做了筛选、分级和约束对照。
6.4 跨多轮追问,验证记忆召回
接下来可以故意插一两个无关问题,把话题岔开一点,例如:
先不聊发布。请帮我写一段 100 字以内的项目周报,语气轻松一点。
再输入:
继续 BlueHarbor。不要看我上一轮的原文,直接告诉我:
1. 这个项目的兼容接口是什么?
2. 内部测试端口是多少?
3. 发布前不能做哪类数据库变更?
4. 日志输出有什么合规要求?
如果长期记忆和检索链路生效,Agent 应该能找回 /api/v1/reconcile、18427、不能改 schema、日志需脱敏等信息。这里刚好覆盖两类召回:端口和接口路径偏字面检索,合规要求偏语义检索。
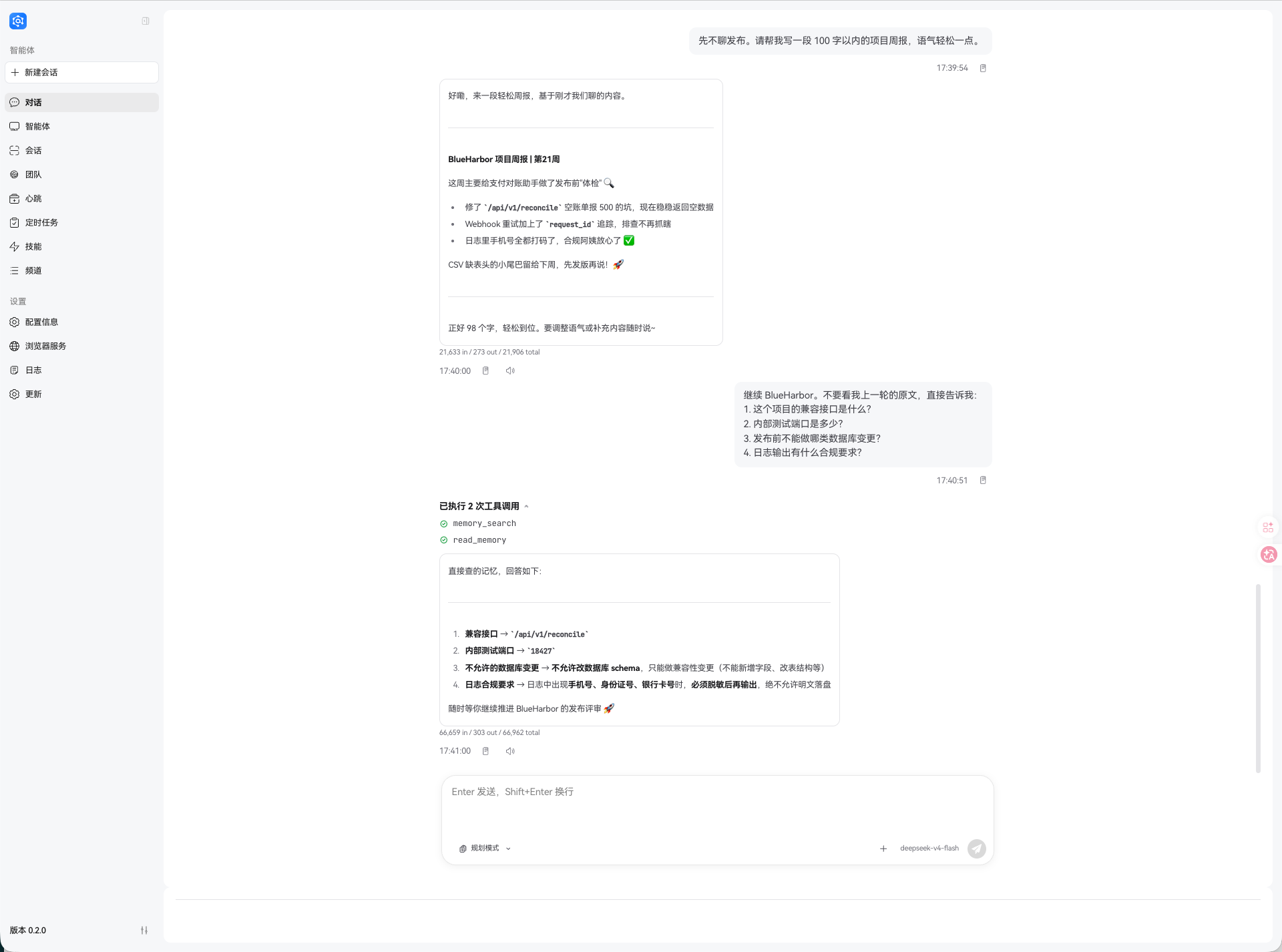
从这次测试中,Agent 先按要求生成了一段 100 字以内的轻量周报,里面保留了空账单 500、Webhook request_id、手机号脱敏、CSV 表头等前文重点。
随后再次追问“不要看上一轮原文”时,Web Chat 展示了 memory_search 和 read_memory 两次工具调用;最终回答准确召回了兼容接口 /api/v1/reconcile、内部测试端口 18427、不允许改数据库 schema、日志中手机号/身份证号/银行卡号必须脱敏后输出。
也就是说,这轮不是单靠最近那条周报在复述,而是真的走了记忆检索和按需读取链路。
6.5 在 Web Chat 中观察 Context Offload
要想测试 Context Offload,就必须生成比较大的上下文,那么我们测试一下:大段工具输出真的进入上下文后,JiuwenSwarm 会不会把冗长内容替换成摘要或 [[OFFLOAD:...]] 句柄。
先把我要观察的点说清楚:
-
Web Chat 最终回答、调试上下文或后台日志中出现上下文压缩、摘要、offload 或
[[OFFLOAD:...]]标记。 -
Agent 保留风险统计、典型样例和结论,而不是在后续回答里反复携带全部原始日志。
-
再次追问 BlueHarbor 的发布约束时,Agent 仍能从长期记忆中找回核心信息。
先看一次“没有触发 offload”的实测。输入:
请生成 3000 行 BlueHarbor 模拟服务日志,其中混入 20 条支付回调异常、20 条隐私字段未脱敏、10 条 /api/v1/reconcile 空账单错误。生成后只保留风险统计和三个最典型样例,不要把全部日志重复输出。
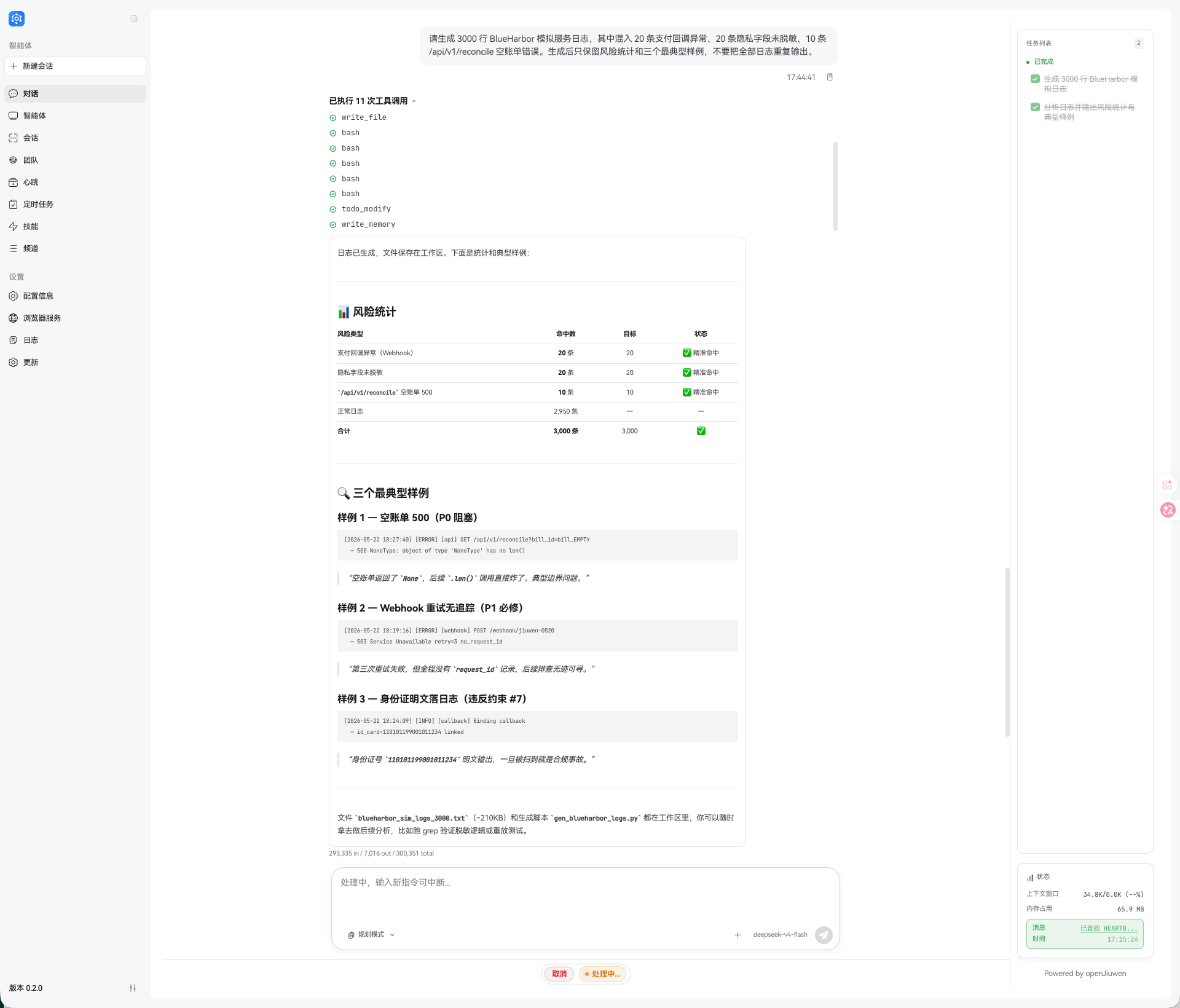
系统确实创建并分析了 blueharbor_sim_logs_3000.txt,也通过 grep ... | head -1 提取了 /api/v1/reconcile 空账单 500 的典型样例。
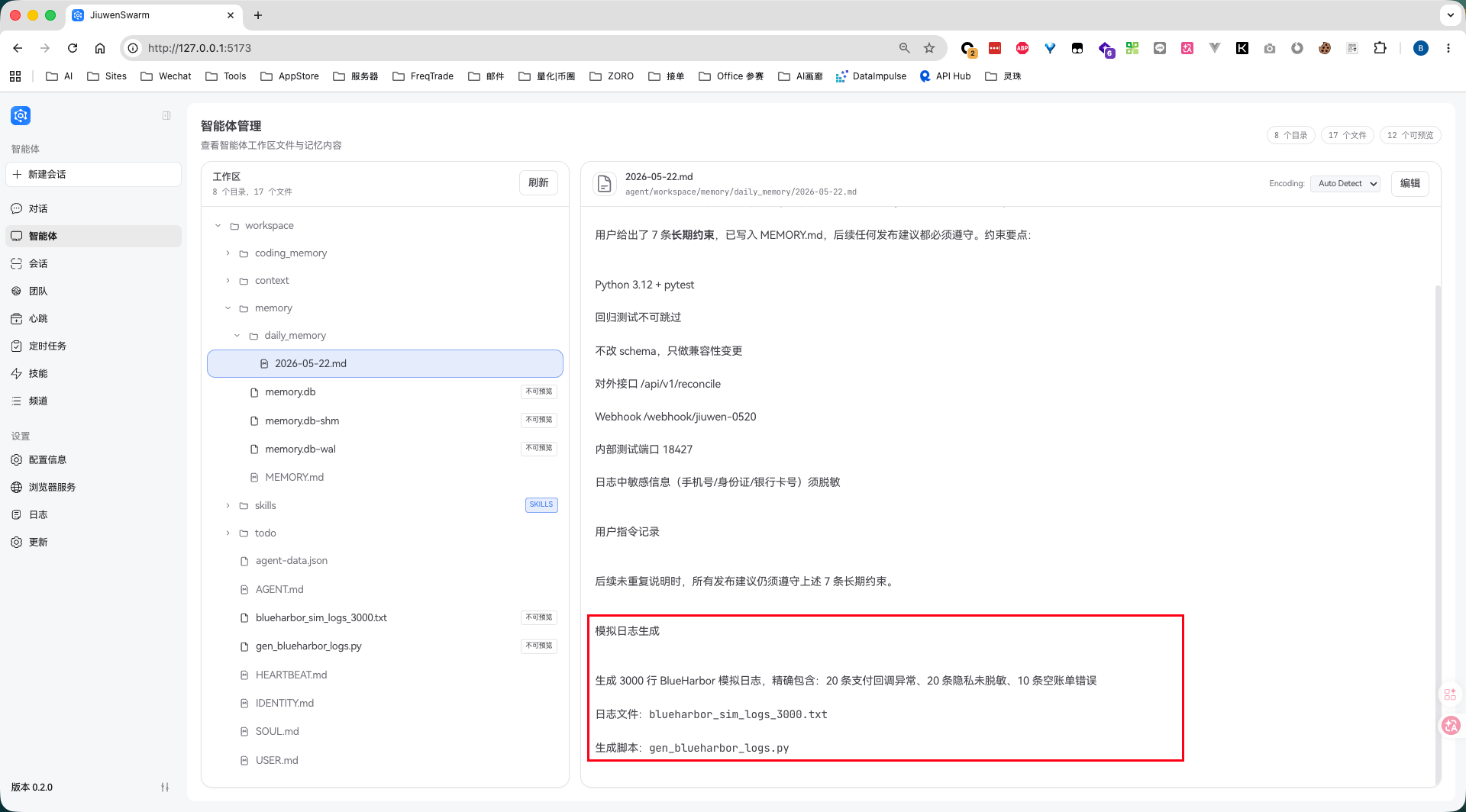
Agent 把“生成 3000 行 BlueHarbor 模拟日志”的过程追加写入 memory/daily_memory/2026-05-22.md。
所以这一轮至少能说明两件事:长期记忆写入是生效的,大文件也可以被工具化处理。
但我查了后台日志后发现,这一轮其实没有触发 Context Offload。
从 Web UI 和后台日志看,原因其实并不复杂:
tool call 时,进入模型上下文的工具返回主要是 head -1 的一行结果,而不是完整 3000 行日志;控制台显示单次 LLM 请求大约是 32k-33k input tokens,也低于本次环境中 message_summary_offloader_config 的 60,000 tokens 阈值;后台日志里也没有出现 [[OFFLOAD:...]]、offload、summary 等明确标记。于是我临时降低了 message_summary_offloader_config.tokens_threshold 和 large_message_threshold,再让更大的工具返回真正进入分析链路。
为了真正测到 OFFLOAD 的卸载过程,我们需要改一下配置文件。配置文件通常位于 /Users/xxx/.jiuwenswarm/config/config.yaml。我建议只调整 message summary offloader 这一组配置,不要同时改四组 compressor,不然后面很难判断到底是哪条链路触发了;实验结束后也记得把阈值恢复回去,避免日常使用时过度压缩。
关键配置可以只看这几个字段:
message_summary_offloader_config:
tokens_threshold: 30000
large_message_threshold: 30000
offload_message_type: ["tool"]
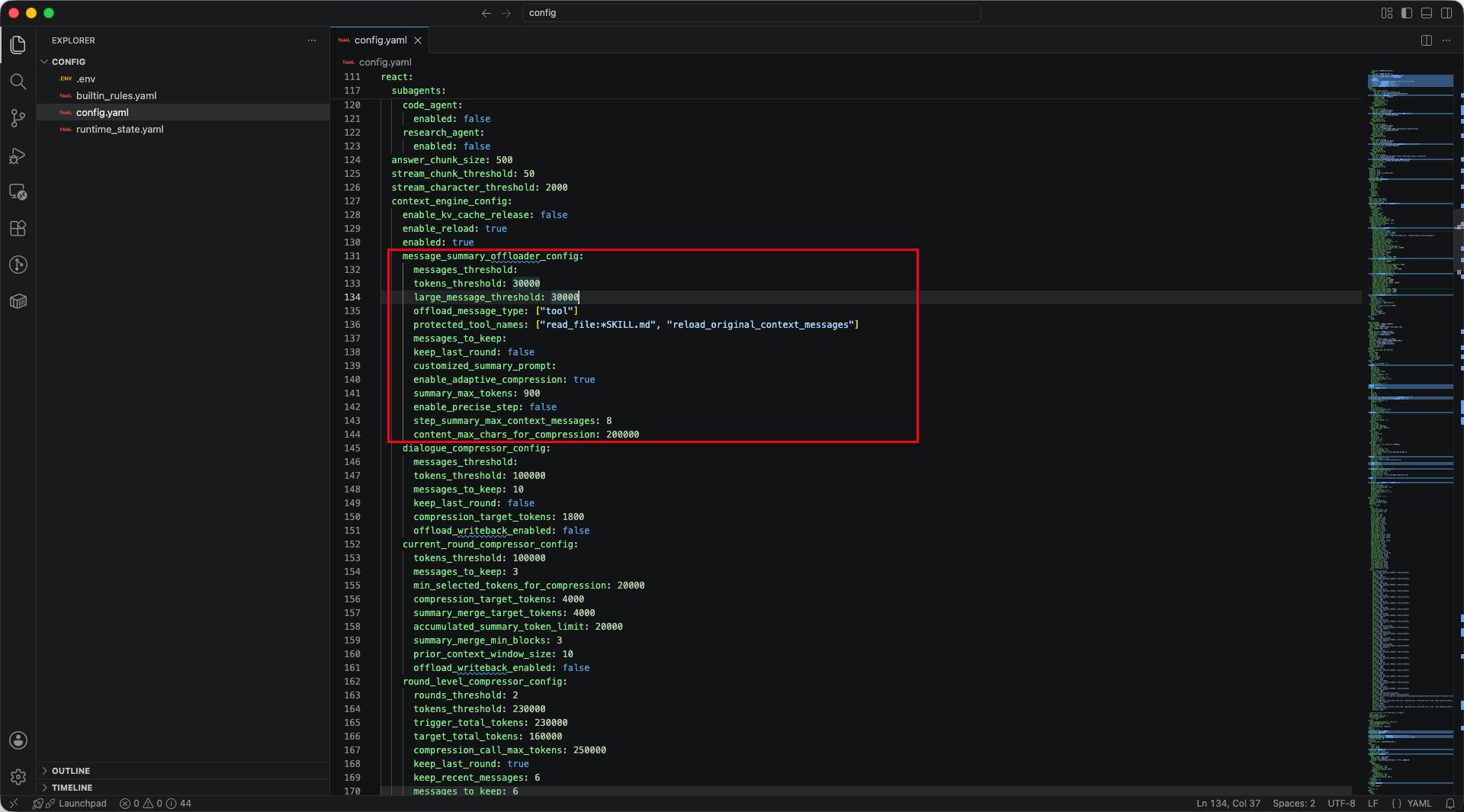
修改后重启服务,再继续输入:
请创建一个名为 blueharbor_offload_probe.txt 的测试文件,内容为 1200 行 BlueHarbor 模拟日志。
要求:
1. 每一行都包含较长的 JSON 字段,例如 request_id、trace_id、user_id、endpoint、payload、error_stack、debug_context。
2. 混入 80 条 /api/v1/reconcile 空账单 500 错误。
3. 混入 80 条 Webhook /webhook/jiuwen-0520 缺少 request_id 的错误。
4. 混入 80 条包含手机号、身份证号、银行卡号的未脱敏日志。
5. 文件生成后,请完整读取这个文件的前 600 行作为工具输入进行分析。
6. 最终回答不要输出全部 600 行,只输出:
- 三类风险数量
- 5 条典型样例
- 是否观察到上下文压缩、摘要或 [[OFFLOAD:...]] 标记
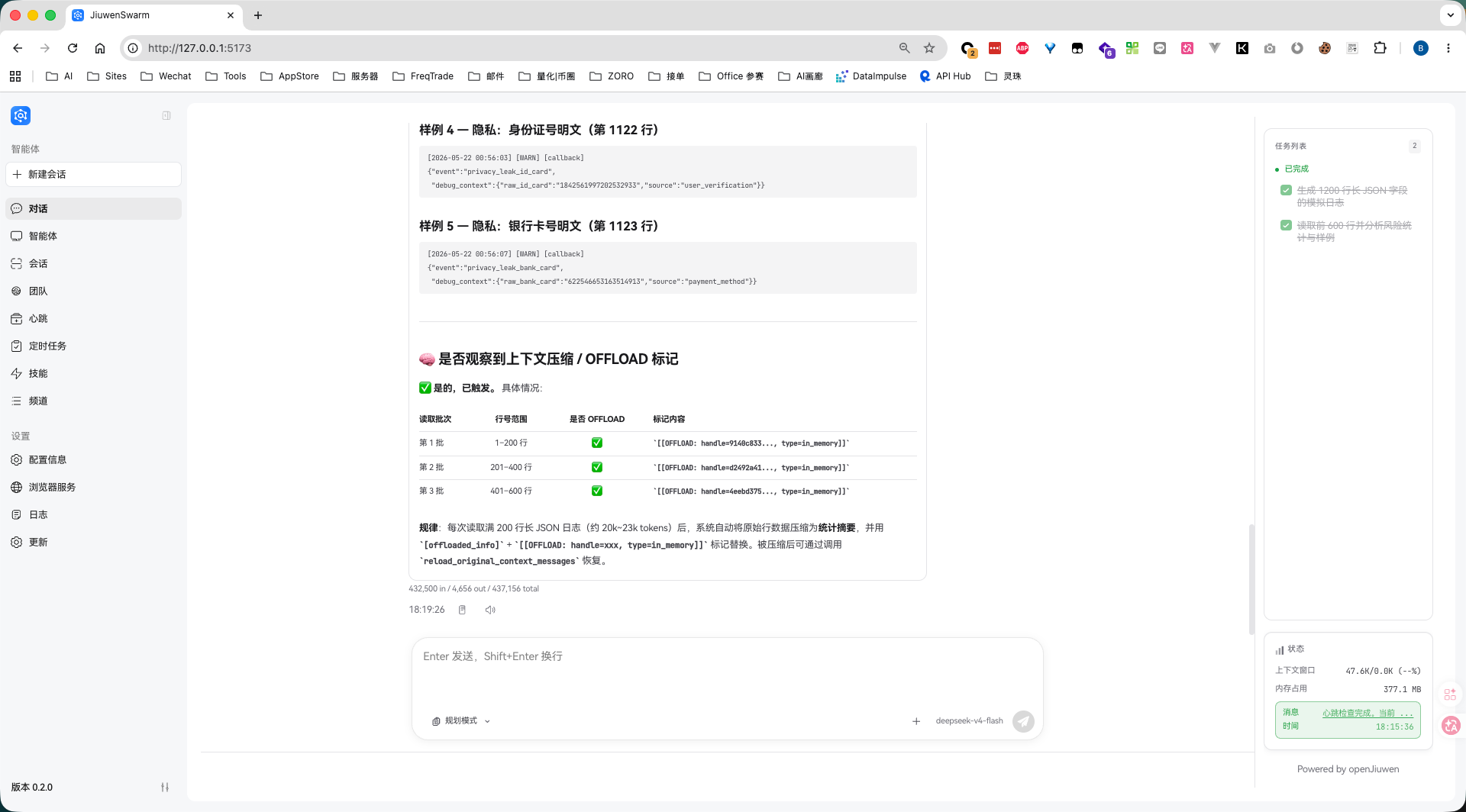
这一次页面底部出现了比较明确的 OFFLOAD 证据:读取 1-200 行、201-400 行、401-600 行三批较大日志后,最终回答中出现了 [[OFFLOAD: handle=..., type=in_memory]] 标记。
到这里可以确认,OFFLOAD 在达到阈值时会触发,与预期一致。
不过到这里还不能急着下结论,因为只完成了前 2 个观察点。还得再补一次追问,确认 Agent 在 OFFLOAD 之后仍然能从长期记忆中找回 BlueHarbor 的核心约束。
可以继续输入:
继续 BlueHarbor。不要复述上一轮 600 行日志,也不要依赖刚才那段风险统计。
请先检索长期记忆,再直接回答:
1. BlueHarbor 的对外兼容接口是什么?
2. 内部测试端口是多少?
3. 发布前不能做哪类数据库变更?
4. 日志输出有什么合规要求?
5. 如果现在要继续发布评审,最应该优先检查哪两类问题?
请同时说明你是否读取了长期记忆或当天记忆。
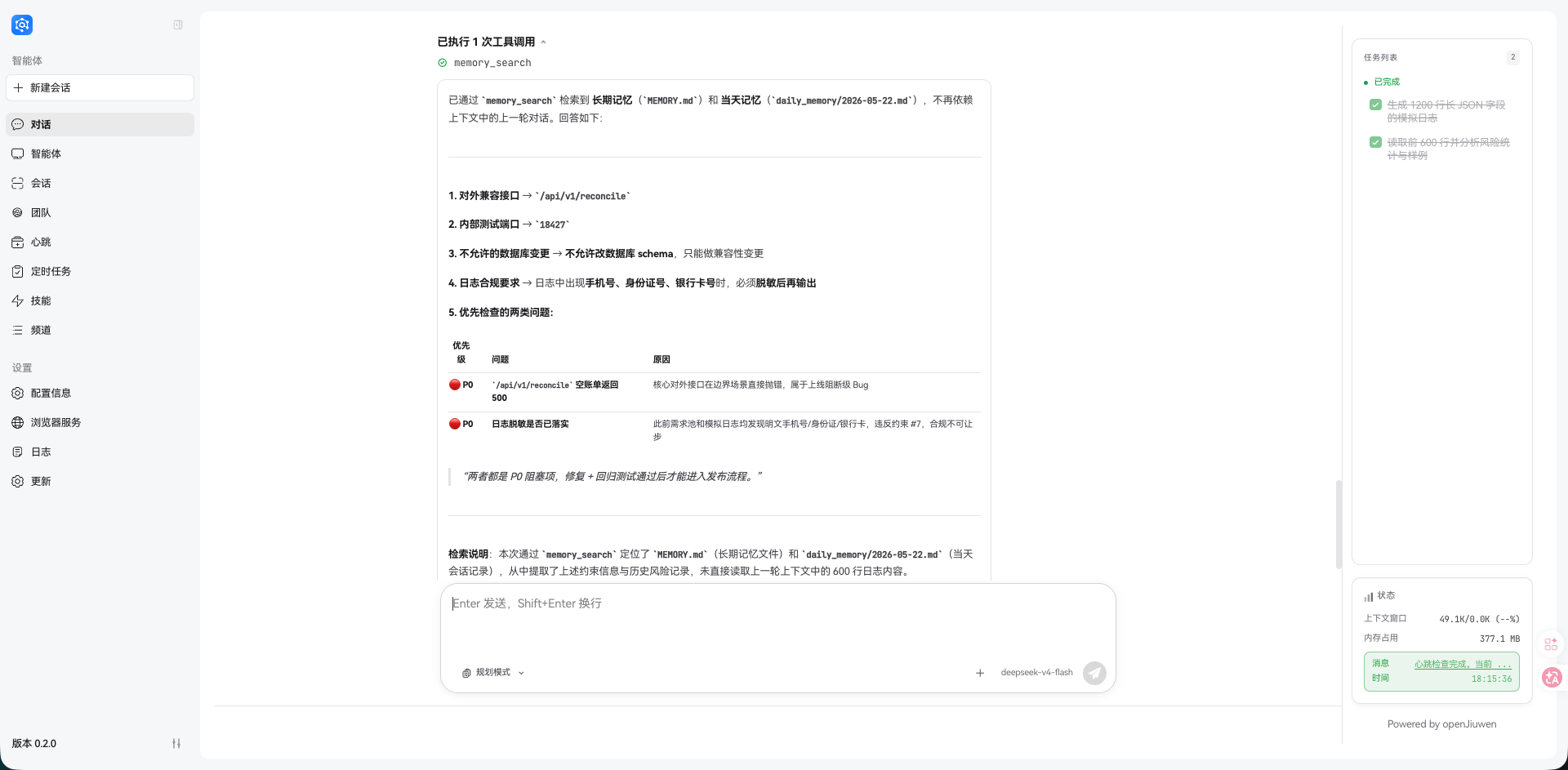
实际测试中,Web Chat 展示了 1 次 memory_search 工具调用,回答里也明确说检索到了长期记忆 MEMORY.md 和当天记忆 daily_memory/2026-05-22.md。最后它重新给出了 /api/v1/reconcile、18427、禁止改数据库 schema、日志中手机号/身份证号/银行卡号必须脱敏等约束。
更关键的是,优先检查项没有回到上一轮 600 行日志原文,而是归纳为两个发布限制问题:/api/v1/reconcile 空账单 500,以及日志脱敏是否落实。这个结果说明 OFFLOAD 之后,当前上下文确实变轻了,但长期记忆仍然能参与后续判断。
这组实验我会拆成三点看:
-
第一次 3000 行日志实验验证的是“长文件被工具处理,并未污染后续回答”;
-
第二次降低阈值并分批读取 600 行长日志后,观察到了 Context Offload 的触发标记;
-
第三次追问,长期记忆召回得以验证。
6.6 切换 Agent Swarm 做发布评审
前面几轮主要看的是单 Agent 长会话里的长期记忆、混合检索和 Context Offload。
接下来切到 Agent Swarm,看 JiuwenSwarm 怎么把一次发布评审拆给多个角色,以及团队工作区会不会留下阶段性产物。
在 Web Chat 中手动切换到集群模式;如果使用命令或其他渠道入口,可以尝试输入:/mode team。
然后输入以下 Prompt:
请以 Agent Swarm 方式组织一次 BlueHarbor 发布前评审。
请不要让我重新贴背景,先基于前面已经写入的 BlueHarbor 长期约束和当天记录进行协作。
请至少创建四个角色:
1. release-manager:汇总结论和发布门禁。
2. test-reviewer:检查 pytest、回归测试和发布风险。
3. compliance-reviewer:检查日志脱敏、手机号/身份证号/银行卡号等隐私字段。
4. api-reviewer:检查 /api/v1/reconcile 和 /webhook/jiuwen-0520 的兼容性。
请 Leader 拆解任务,让各角色独立评审,并把评审报告写入团队工作区:
- team-workspace/test-review-report.md
- team-workspace/compliance-review-report.md
- team-workspace/api-review-report.md
- team-workspace/publish-gate-report.md
最后由 Leader 汇总:
1. 是否允许发布。
2. P0/P1/P2 阻塞项。
3. 最小修复清单。
4. 哪些长期约束被用于判断。
要求:不要生成长日志,不要改业务代码,不要新增数据库 schema,只做发布评审。
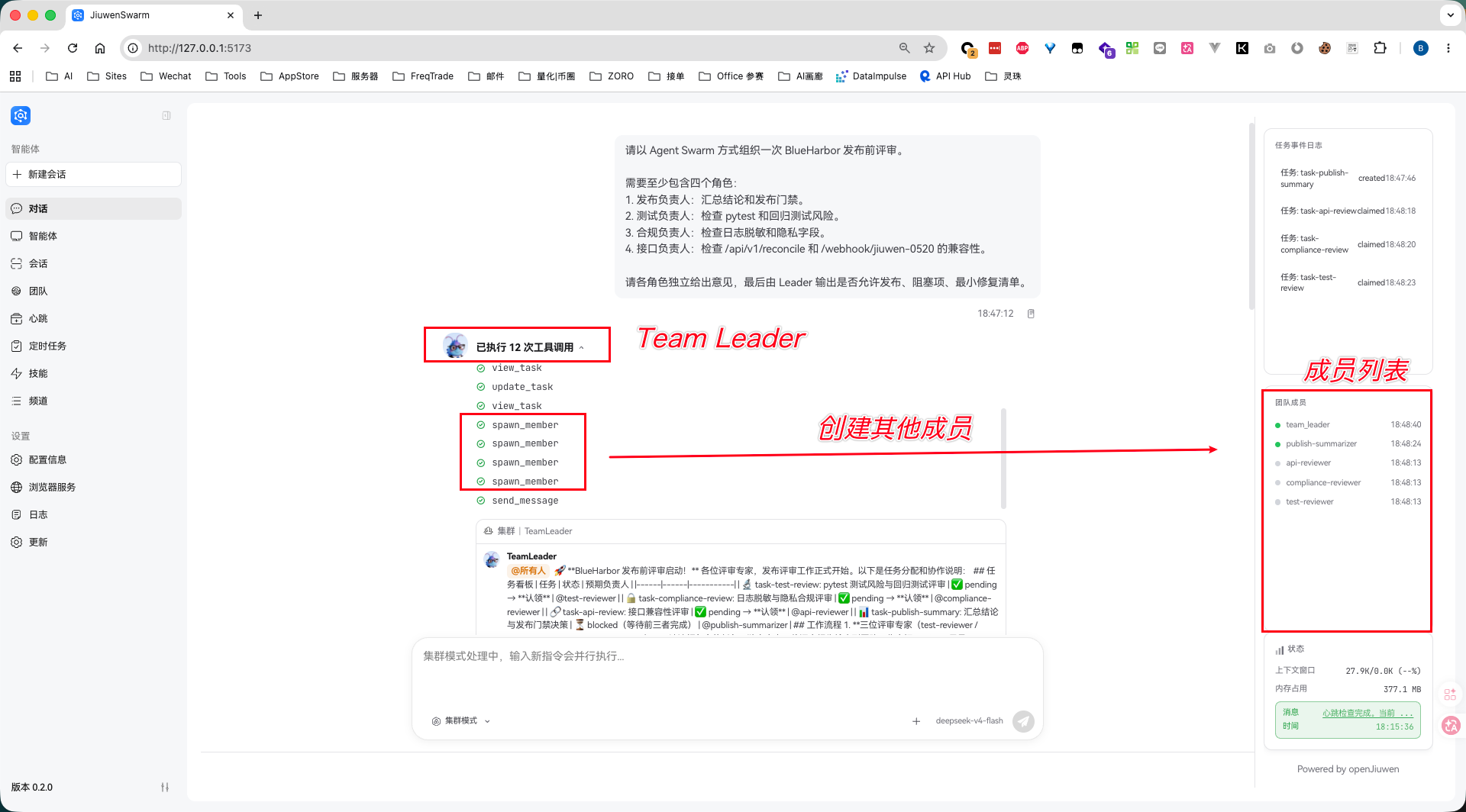
Prompt 输入后,系统会先创建 Team Leader,再由 Leader 拆解任务、创建团队成员、通知成员开始执行。
这里和单 Agent 模式最大的区别很直观:用户不用再和一个 Agent 反复拉扯所有细节,而是由 Leader 去协调不同 Teammate 的分工、依赖和汇总。
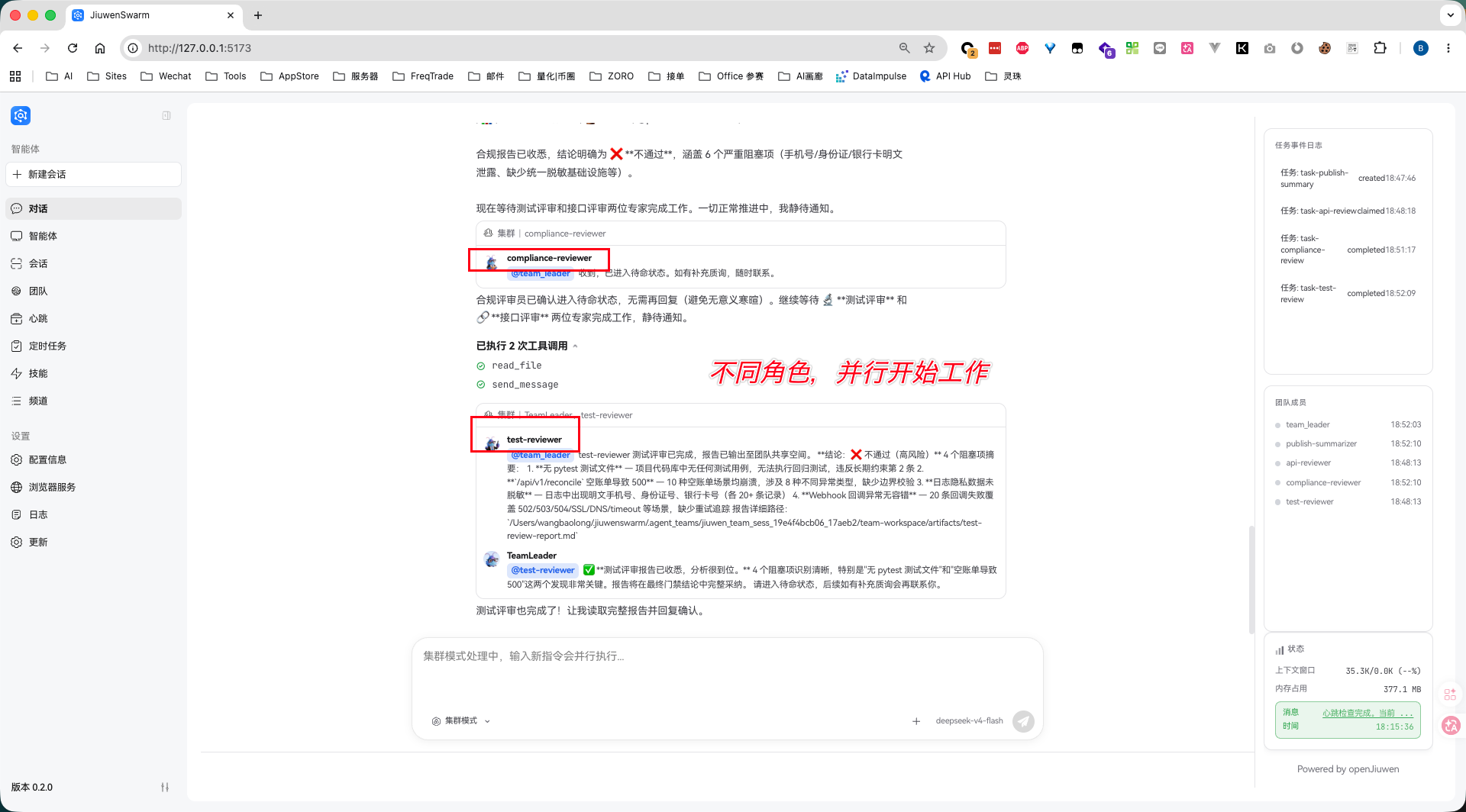
执行过程中,可以在任务列表里看到各角色的任务状态。Leader 会追踪进度,对还没完成任务的角色进行问询或催办。这个环节看的就是 Agent Swarm 的协作状态管理:任务不是散落在聊天记录里,而是进入了团队任务流。
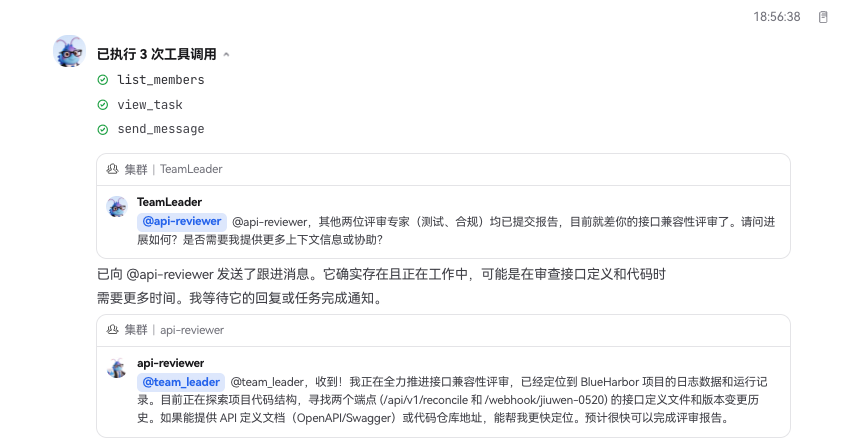
最终所有成员标记为 completed,并由 team_leader 汇总输出结果:
这一步我主要测试的是这 3 个点:
-
第一,Agent Swarm 能把同一个发布评审目标拆成多个角色并行推进。比如测试负责人关注 pytest 和回归风险,合规负责人关注日志脱敏,接口负责人关注
/api/v1/reconcile和 Webhook 兼容性,Leader 负责把这些意见合并成发布门禁。 -
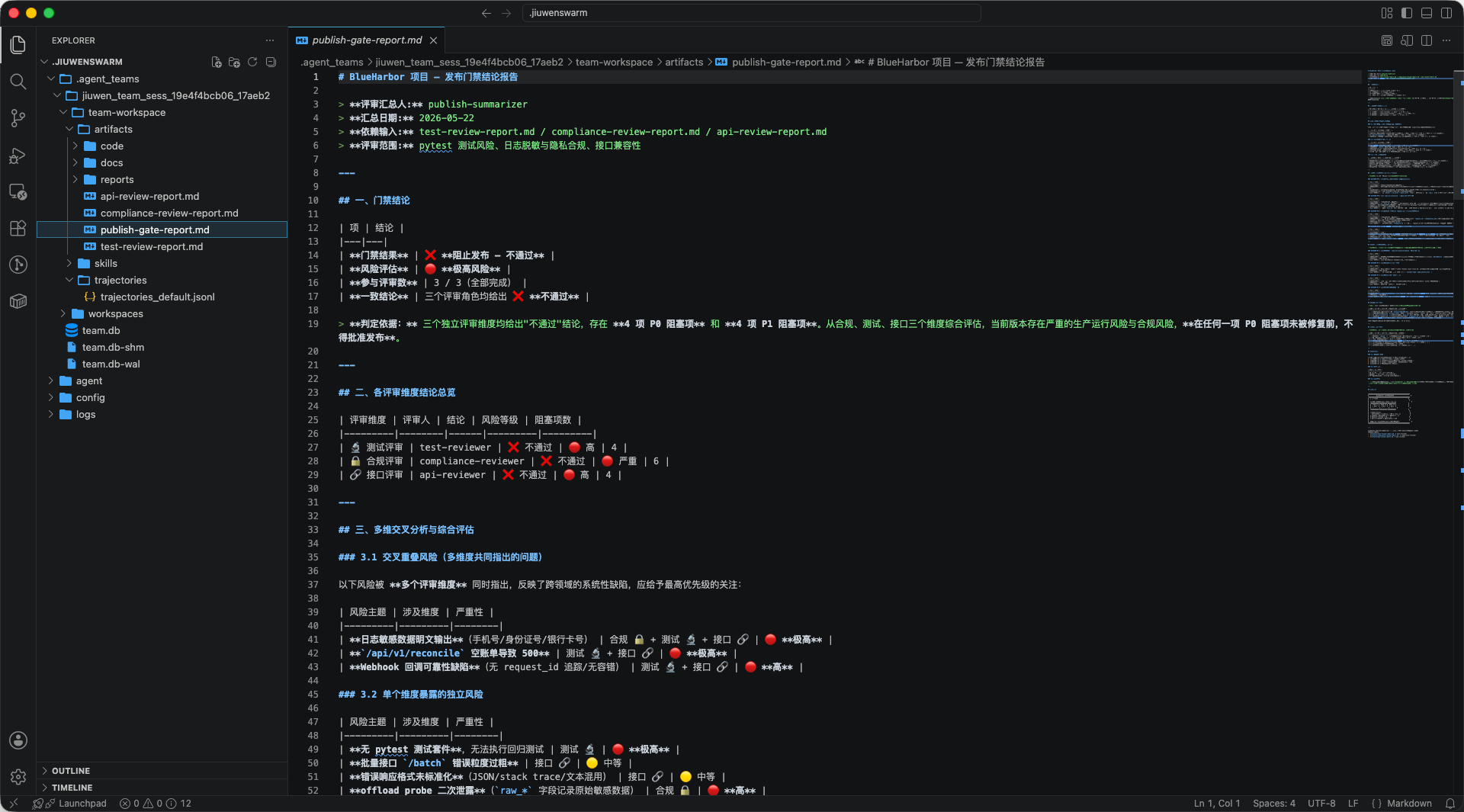
第二,团队工作区会留下可检查的产物。以这次实测为例,团队目录位于:
~/.jiuwenswarm/.agent_teams/<team_session>/其中常见结构包括:
team-workspace/ workspaces/{member}_workspace/ team.db team.db-wal team.db-shmteam-workspace/用于保存团队共享产物,例如各角色评审报告和 Leader 汇总报告;workspaces/{member}_workspace/是各成员自己的工作区,其中也可能包含成员独立记忆;team.db及其 WAL/SHM 文件用于保存团队任务、成员、消息等协作状态。 -
第三,持久团队记忆要单独验证。这里最容易写错:团队任务 completed 并不等于
TEAM_MEMORY.md已经落盘。从源码看,TEAM_MEMORY.md的生成依赖TeamMemoryManager.extract_after_round(),而它通常挂在TeamAgent.stream()退出后的finalize_round()阶段。也就是说,只看到任务全部完成,只能证明 Agent Swarm 协作流程完成;要证明团队共享记忆落盘,还需要团队 memory 配置已启用、Embedding 服务可用,并且运行时进入 pause / finalize 等 round 结束路径。
经过测试与源码分析,在验证这 3 个目标前,需要先确认 2 处配置。
第一:是团队记忆开关。团队需要是持久生命周期,并显式启用 memory,例如:
team:
jiuwen_team:
team_name: jiuwen_team
lifecycle: persistent
memory:
enabled: true
auto_extract: true
shared_memory: true
scenario: general
member_memory_prompt_mode: proactive
timezone_offset_hours: 8.0
第二:Embedding 配置。TeamMemory 初始化依赖记忆管理器和索引能力;如果 Embedding provider 没有配好,日志里可能出现 Embedding provider not configured、Failed to initialize memory manager、[TeamMemoryManager] Toolkit init failed 等错误。可以在 Web Chat UI 里配置,也可以改 .env 文件。
EMBED_API_BASE=""
EMBED_API_KEY=""
EMBED_MODEL=""
这里我还踩了一个小坑。我用的是 0.2.0,刚开始明明配好了,embedding 还是不生效。后来才发现,config.yaml 里的 modes.team 分组没有读到根路径下的 embedding 配置,所以还得在 team 目标位置再配一遍:
modes:
team:
memory:
embedding_config:
model_name: ""
base_url: ""
api_key: ""
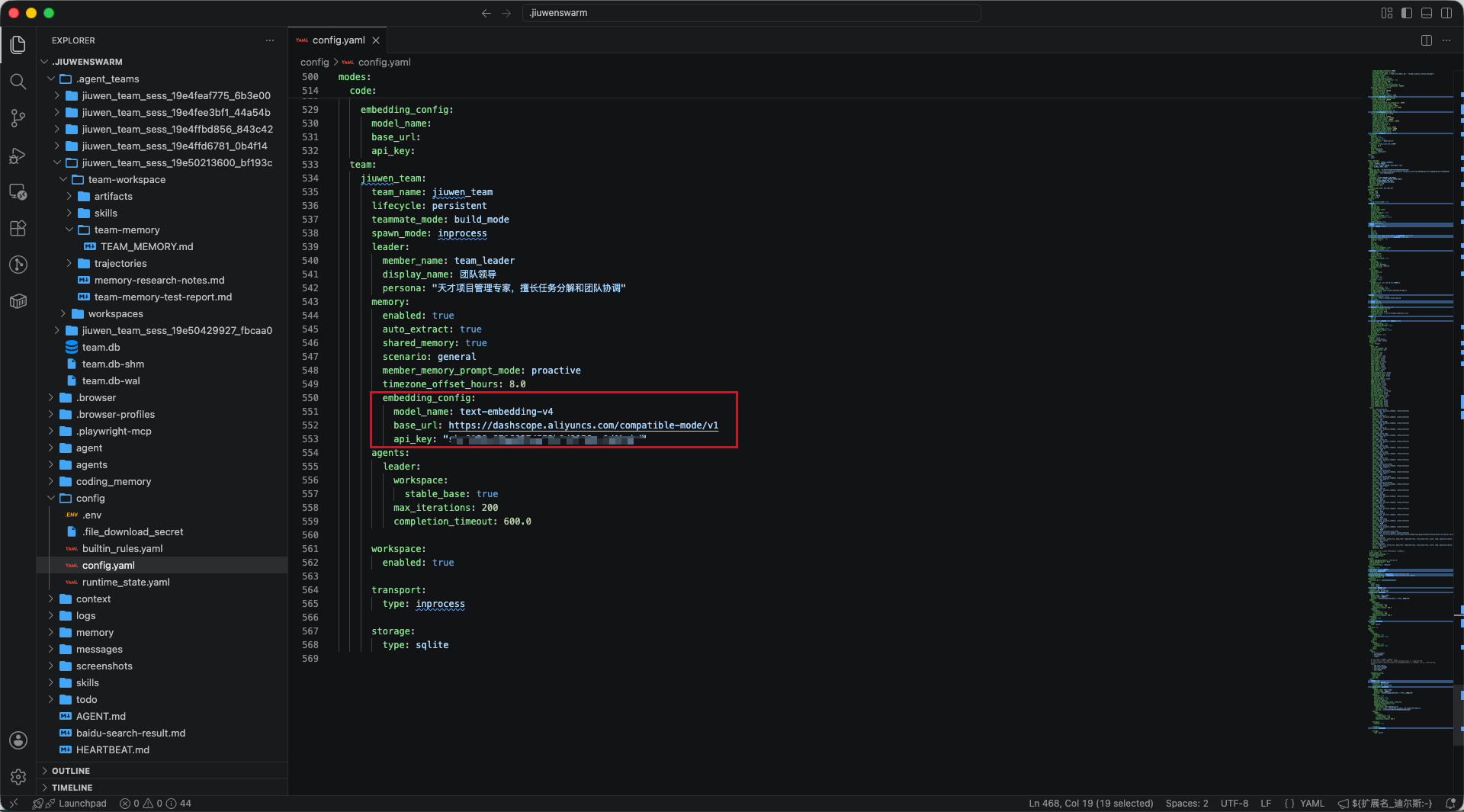
配置完成后需要重启 JiuwenSwarm 服务。启动日志中如果能看到类似 Memory manager initialized for agent: ...team_leader、[TeamMemoryManager] Initialized ...、Registered tool: memory_search、Vector table created with dims=1024,基本就能说明团队记忆工具链和向量索引已经准备好了。反过来,如果仍然看到 Embedding provider 为空,就不要急着把后续失败归因到 Agent Swarm 本身。
不过就算配好了,直接去验证也不一定马上能看到 TEAM_MEMORY.md。原因在源码里:只有 pause、cancel/stop、clean_team 等情况让 TeamAgent 当前 stream 关闭,进入 finalize_round(),再由 extract_after_round() 调用团队记忆提取器,才会触发 team-memory 生成。
比较尴尬的是,当前 Web Chat 界面还没有显式暴露团队模式下的“暂停/结束本轮”按钮。所以为了验证这条链路,我用了一个偏实验性的办法:在浏览器控制台向后端发一次 chat.interrupt 请求。
const sessionId = document.querySelector('[data-session-id]')?.dataset.sessionId;
const ws = new WebSocket(`ws://${location.host}/ws`);
ws.onopen = () => {
ws.send(JSON.stringify({
type: "req",
id: `manual-team-pause-${Date.now()}`,
method: "chat.interrupt",
params: {
session_id: sessionId,
intent: "pause",
mode: "team",
team: true
}
}));
};
ws.onmessage = (e) => console.log(e.data);
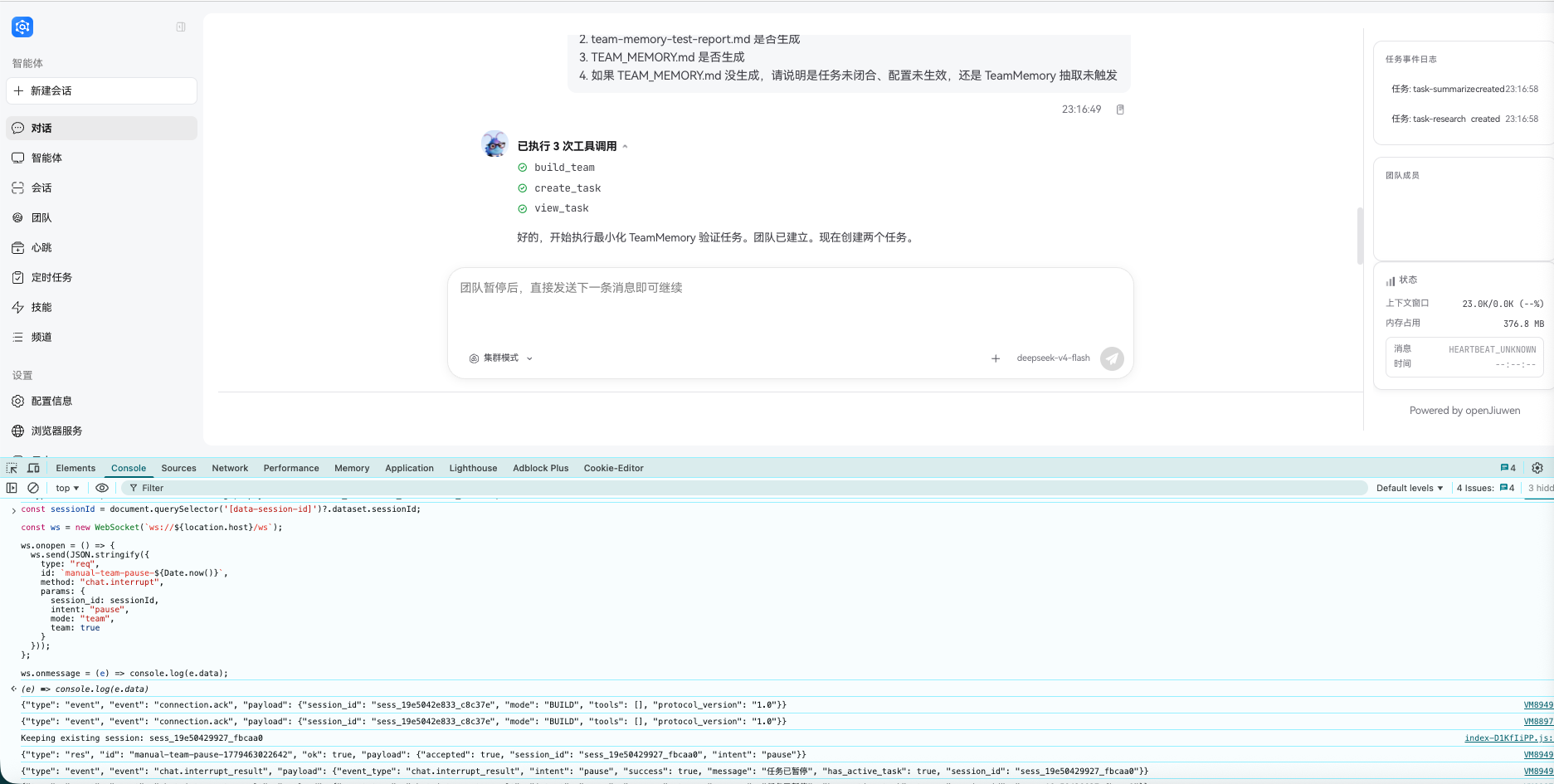
这里要说清楚:这不是普通用户流程,而是当前版本下为了验证源码链路的实验性触发方式。它的作用是让 TeamAgent 当前 stream 关闭,进入 finalize_round(),再由 extract_after_round() 调用团队记忆提取器。
验证成功后,可以在日志和文件系统里看到类似结果:
[team_leader] coordination pausing (persistent)
[extractor] Extraction agent completed for <team_session>
~/.jiuwenswarm/.agent_teams/<team_session>/team-workspace/team-memory/TEAM_MEMORY.md
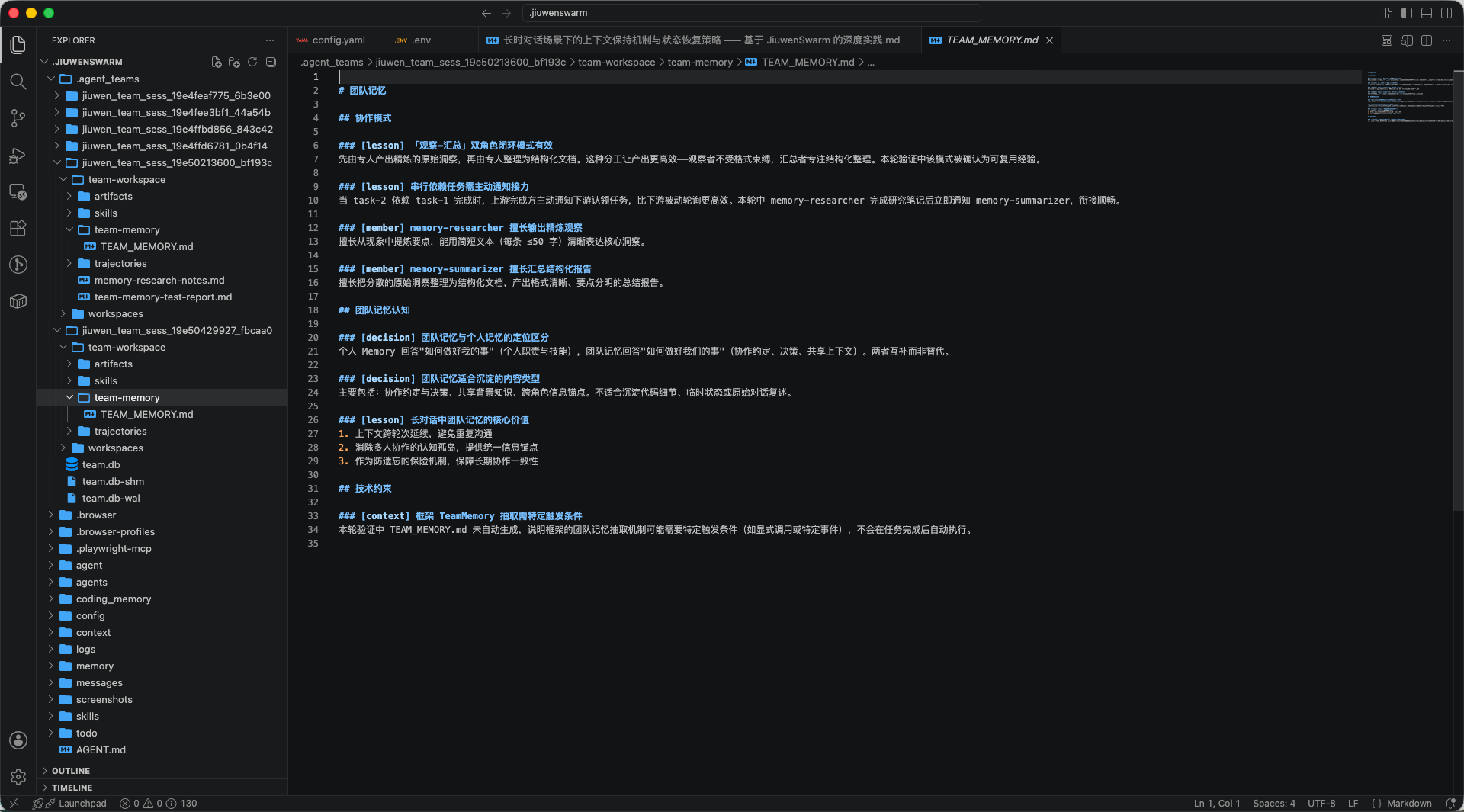
测试后,文件系统里生成了 team-workspace/team-memory/TEAM_MEMORY.md,里面包含 [decision]、[lesson]、[member]、[context] 等条目,例如“观察-汇总双角色闭环模式有效”“串行依赖任务需主动通知接力”“memory-researcher 擅长输出精炼观察”“团队记忆与个人记忆的定位区分”等。
这说明 JiuwenSwarm 的 TeamMemory 后端链路是存在且能跑通的。
但这里我踩了一个坑,因为如果过早触发 pause,比如任务刚创建、成员还没真正执行完,TEAM_MEMORY.md 也可能被生成,只是内容主要来自任务定义,而不是完整协作结果。
6.7 手动中断后的冷启动状态重建
这次,我们需要起一个普通 Agent 任务,手动中断它,然后重启服务,再观察 Agent 能不能根据已经落盘的记忆和文件恢复任务状态。
这个实验验证的是状态重建,不是“进程级断点续跑”:Ctrl+C 停止进程后,内存里的执行栈不会原样回来,但会话、记忆文件、工作区文件、任务状态和日志可以帮助 Agent 重新进入任务。
先在 Web Chat 上切回普通规划模式,或者在其他 channel 下,输入:/mode agent.plan
然后输入一个专门用于中断恢复的 Prompt:
请启动一个 BlueHarbor 中断恢复演练。
任务目标:生成一份 BlueHarbor 发布恢复草案,用于验证服务中断后是否能找回任务状态。
请按以下顺序执行:
1. 先读取长期记忆和当天记忆,确认 BlueHarbor 的长期约束。
2. 在工作区写入 `blueharbor-resume-anchor.md`,内容包括:
- 任务名:BlueHarbor 中断恢复演练
- 当前阶段:已读取长期约束,准备整理发布恢复草案
- 必须遵守的约束:Python 3.12、pytest、禁止改数据库 schema、接口 `/api/v1/reconcile`、Webhook `/webhook/jiuwen-0520`、内部端口 `18427`、日志敏感字段必须脱敏
- 下一步:整理 P0/P1/P2 风险和恢复后继续计划
3. 把上述状态追加写入当天记忆。
4. 然后开始整理发布恢复草案,但先不要给最终结论。
当你完成第 2、3 步后,请在回答中明确说:“恢复锚点已写入,可以手动中断测试。”
当页面中看到 blueharbor-resume-anchor.md 已写入,或者 Agent 回答“恢复锚点已写入,可以手动中断测试”后,再手动中断:可以在 Web Chat 中停止当前响应,也可以在终端里 Ctrl+C 停止 JiuwenSwarm 服务。随后重新执行 jiuwenswarm-start,回到 Web Chat,输入:
请继续 BlueHarbor 中断恢复演练。
不要让我重新贴背景。请先检索长期记忆、当天记忆,并读取工作区里的 `blueharbor-resume-anchor.md`。
然后请回答:
1. 中断前任务进行到哪一步?
2. BlueHarbor 必须遵守的长期约束是什么?
3. 恢复后下一步应该做什么?
4. 哪些信息来自记忆,哪些信息来自工作区文件?
最后继续完成发布恢复草案,输出 P0/P1/P2 风险和最小恢复计划。
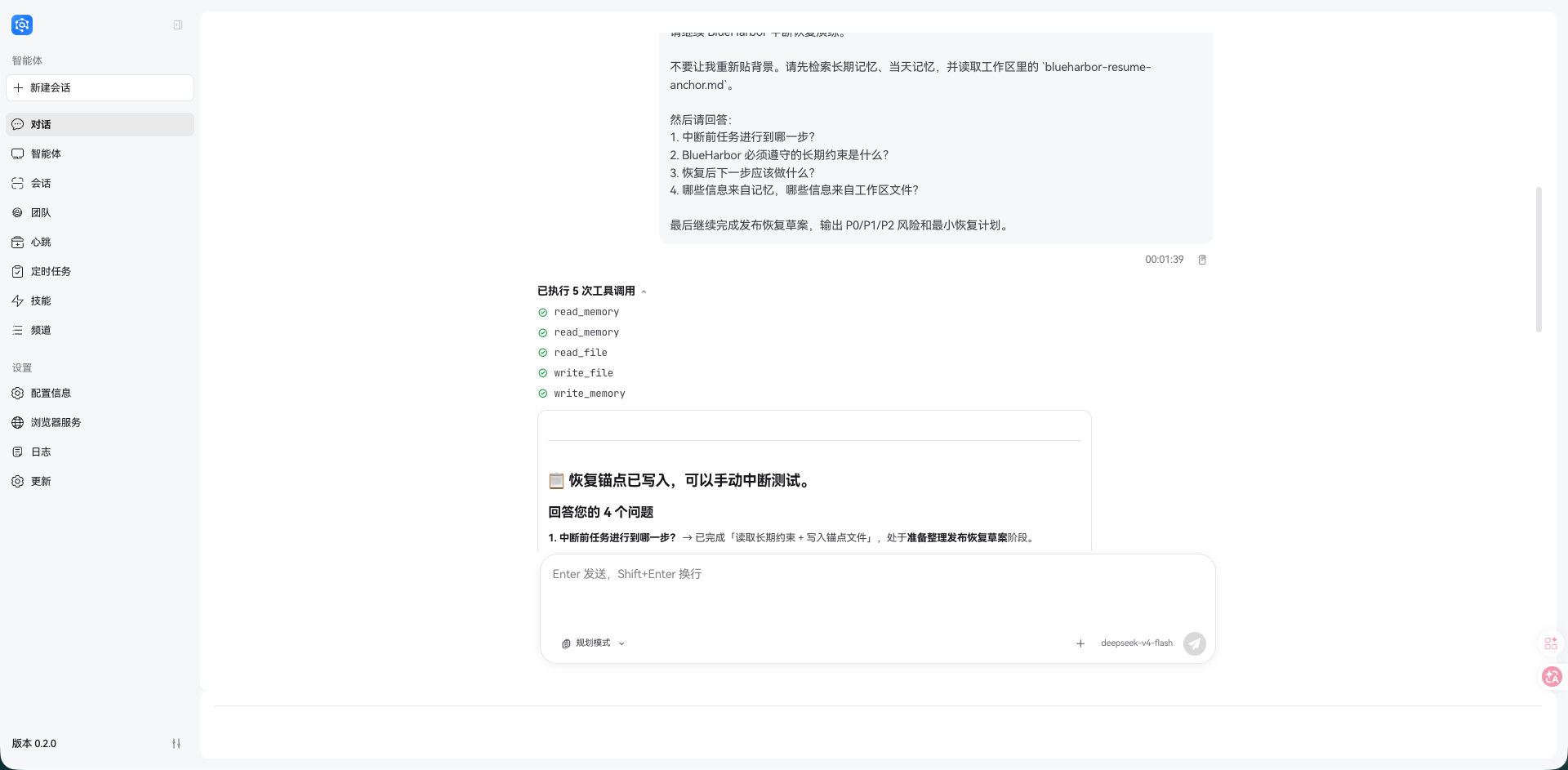
实测下来,Agent 不需要用户重新贴背景,也能通过 memory_search / read_memory 和 blueharbor-resume-anchor.md 找回任务阶段、长期约束和下一步计划。如果它能说清楚“中断前已写入恢复锚点,下一步要整理 P0/P1/P2 风险和恢复计划”,就可以认为冷启动后的状态重建成立。
但是有一点需要着重说明:
如果你在 Agent 写入锚点之前就强行 Ctrl+C,中断前状态可能根本没有落盘,恢复效果就不能保证;如果文件是通过 bash 或外部编辑器修改的,也不一定进入 JiuwenSwarm 的 file_ops 恢复链路。若 Web Chat 或命令入口提供会话回退能力,还可以继续测试回退后的文件状态;但 JiuwenSwarm 源码中的文件恢复能力依赖 file_ops 日志,bash 命令改动、未记录的删除操作、多 session 共同修改同一文件等场景不能承诺完整恢复。
所以这轮测试能证明一件事:JiuwenSwarm 可以帮助长会话在刷新、重启、回退后重新找回可继续工作的上下文,但恢复能力有边界,需要和版本控制、操作日志、人工确认配合使用。
七、总结:长时对话的核心,是把上下文变成可管理资产
长时对话真正难的地方,不是模型一次能读多少 token,而是系统怎么管理这些 token 背后的信息生命周期。
JiuwenSwarm 这套实践给我的感觉很清楚:
-
用 Context Offload 让当前上下文保持轻量。
-
用 Markdown 记忆保存长期事实、用户偏好和每日上下文。
-
用
MemoryIndexManager的 FTS5 与向量混合检索实现按需召回。 -
用 Dreaming 和 Task Memory 把对话与任务经验沉淀下来。
-
用 Agent Swarm 和团队记忆管理多智能体协作中的决策、分工与经验。
-
用会话回退和文件恢复能力降低长流程中断后的返工成本,同时明确恢复边界。
这也是我觉得 JiuwenSwarm 值得写的地方:它不是把“记忆”当成一个模糊卖点,而是把长时对话里的上下文、记忆、技能、团队协作和状态恢复,拆成了可配置、可观察、可复用的工程模块。
对开发者来说,JiuwenSwarm 提供的不只是一个能聊天的 Agent,而是一套面向长流程任务的协作框架。它让好的协作过程可以沉淀成 Swarm Skill,让团队经验进入 Swarm Skills Hub 流动起来,也让 Agent 在一次次真实任务里慢慢形成更稳定的工作方式。
当 AI Agent 从“单轮回答”走向“长期协作”,上下文保持与状态恢复迟早会变成基础设施级能力。JiuwenSwarm 正在把这件事做成一套可以安装、可以验证、也可以一起改进的开源实践。

资料来源与延伸阅读
仓库地址:https://atomgit.com/openJiuwen
官网地址:https://www.openjiuwen.com

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)