从 VLA 到 WAM、VAM 与 UAM:机器人基础模型如何从“看见就做”走向“预测世界再行动”
0. 引言:机器人基础模型的范式转变
过去两年,具身智能最重要的变化之一,是机器人策略模型开始从“看图输出动作”转向“理解任务、预测后果、再执行动作”。这个变化让机器人不再只是模仿演示轨迹,而是逐步具备语义理解、物理预判和自我修正能力。
理解这条路线,可以先抓住几个关键词:VA、VLA、WAM、VAM、UAM 和强化学习后训练。VA 解决视觉到动作,VLA 加入语言理解,WAM 引入未来预测,VAM 借用视频先验,UAM 则处理语义理解和运动控制之间的结构分工。
这些概念不是互相替代的标签,而是一条连续演进线上的不同能力模块。它们共同回答一个问题:机器人怎样从“看到当前画面后立刻反应”,走向“先理解目标,再推演世界变化,最后选择更稳的动作”。
可以先用下面五个层次建立整体认识:
- VA 到 VLA:机器人从只看图像输出动作,发展到能理解自然语言指令并生成动作。
- VLA 内部演进:动作生成从自回归 token、扩散去噪,继续走向流匹配和动作专家。
- WAM 与 VAM:模型不再只预测动作,而是引入未来视频、未来 latent 或世界状态预测,让动作带有物理后果约束。
- UAM:在 VLA 微调中重新划分语义理解和视觉运动控制的职责,避免动作数据侵蚀 VLM 的语义能力。
- RL 与自进化闭环:机器人把真实执行中的成功、失败、near-miss、预测误差和候选轨迹转化为后训练资产。
本文的核心判断是:机器人基础模型正在从行为克隆式的模仿系统,演进为同时具备语义理解、物理预测、动作生成、风险评估和自我修正能力的世界交互模型。
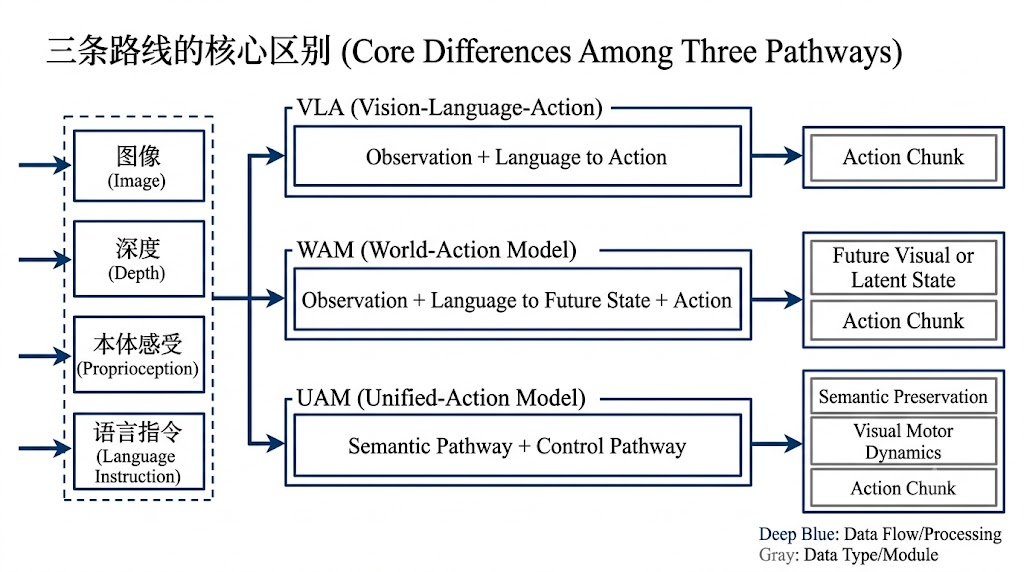
图 1:VLA、WAM、UAM 的核心区别。VLA 强调视觉语言到动作,WAM 强调动作之前预测未来,UAM 强调语义通路和运动控制通路的结构分工。
从建模目标看,VLA、WAM、UAM/VAM 的差别可以用几组公式抓住。公式并不是为了增加复杂度,而是帮助我们看清模型到底在学习什么。VLA 学习的是当前观测和语言指令条件下的动作分布:
p ( a t ∣ o t , l ) p(a_t \mid o_t, l) p(at∣ot,l)
WAM 进一步要求模型学习未来状态与动作之间的联合分布:
p ( o t + 1 : t + H , a t : t + H ∣ o t , l ) p(o_{t+1:t+H}, a_{t:t+H} \mid o_t, l) p(ot+1:t+H,at:t+H∣ot,l)
VAM 则可以看作 WAM 的轻量化或工程折中版本,它不一定显式生成完整未来视频,而是借助预训练视频生成模型的 latent 表征作为物理先验:
a t : t + H = π θ ( z t : t + H v i d e o , o t , l ) a_{t:t+H} = \pi_{\theta}(z^{video}_{t:t+H}, o_t, l) at:t+H=πθ(zt:t+Hvideo,ot,l)
UAM 关注的问题又不同。它不是只问“动作怎么生成”,而是问:当 VLM 被微调成 VLA 时,如何保住原本的开放词汇视觉语言理解能力。如果动作数据过窄,模型可能为了拟合控制信号而忘掉语义能力,所以 UAM 用双通路结构分担压力。
这几个方向共同构成机器人基础模型的主线:VA 让机器人会模仿,VLA 让机器人听得懂,WAM/VAM 让机器人会预判,UAM 让机器人不忘语义,RL 与自进化闭环让机器人从真实交互中持续变强。
1. 从 VA 到 VLA:机器人控制为什么需要语言
在 VLA 之前,许多端到端机器人策略更接近 VA(Vision-Action)。以 ACT(Action Chunking with Transformers)为代表的方案,核心是学习视觉观测到动作序列的映射。它输入相机图像,输出关节角、末端位姿或夹爪开合等控制量。VA 的优点是链路短、推理快、工程上容易接入高频控制;缺点也很明显:它不理解自然语言任务。
这意味着,如果机器人只训练过“抓红色方块”,它未必能理解“把蓝色圆柱放进盒子里”。即使两个任务的动作结构相似,缺少语言接口的 VA 模型也很难把人类意图迁移到新任务上。
开放家庭、办公室、仓储和医院环境中,任务往往不是固定菜单,而是人用自然语言提出的临时目标。因此,机器人策略必须从“视觉到动作”升级为“视觉、语言、动作”的统一建模。
VLA 的突破就在这里。它把视觉编码器、语言模型和动作头连接起来,让机器人不仅看到物体,还能理解“拿起杯子”“把餐桌收拾干净”“避开玻璃杯后把碗放进洗碗机”这类开放指令。
RT-1 把多任务机器人控制转成序列建模问题,RT-2 进一步把互联网规模视觉语言模型接入机器人动作生成。OpenVLA 则推动了开源复现路径,用大规模真实机器人演示数据训练通用 VLA,并强调 LoRA 微调、量化部署和社区可复现性。
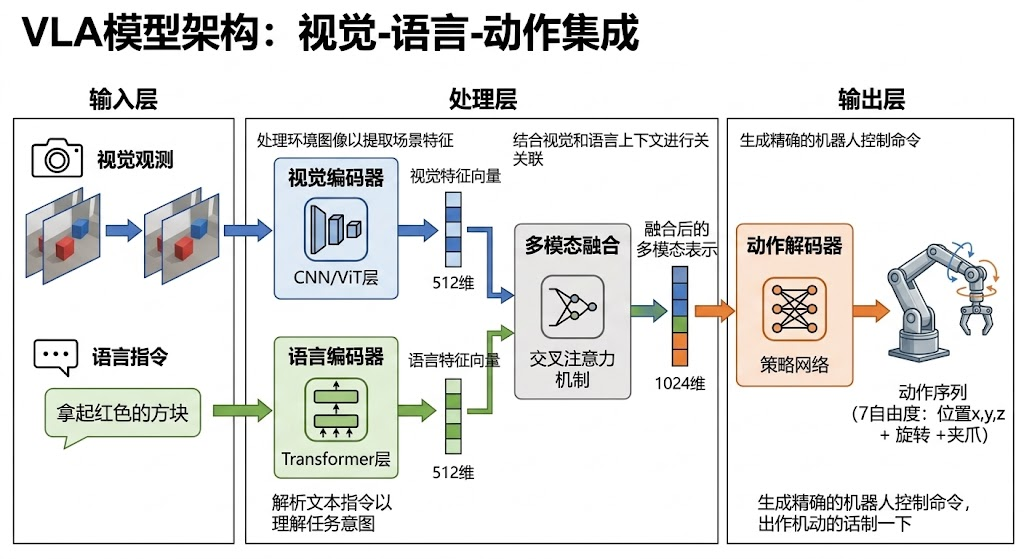
图 2:VLA 将视觉、语言和动作统一起来。图像提供场景状态,语言提供任务目标,动作头输出可执行控制序列。
一个典型 VLA 系统通常包含四个部分:
- 视觉编码器:把 RGB、RGB-D、多视角图像或视频切成视觉 token。
- 语言编码器或 LLM 主干:理解自然语言任务、物体语义、空间关系和常识约束。
- 多模态融合模块:让视觉 token 与文本 token 在 Transformer 中交互。
- 动作头或动作解码器:输出 action chunk、动作 token 或连续动作向量。
这里的关键是,VLA 输出的往往不是单个电机命令,而是一段短时动作片段:
A t : t + H = [ a t , a t + 1 , … , a t + H ] A_{t:t+H} = [a_t, a_{t+1}, \ldots, a_{t+H}] At:t+H=[at,at+1,…,at+H]
这种 action chunk 可以减少模型调用频率,让动作更平滑,也让模型表达“短时运动意图”。例如抓杯子时,机器人不是每一步都重新思考,而是一次生成未来 0.5 到 2 秒的末端位姿、腕部旋转和夹爪闭合信号。
2. 动作 Tokenizer:VLA 的监督语言
VLA 看起来是多模态模型问题,实质上很大一部分难点落在 动作表示 上。语言模型天然擅长预测离散 token,但机器人控制量是连续、高维、高频的。如何把连续动作变成模型能预测、能学习、能泛化的动作 token,直接决定 VLA 的训练效率和部署延迟。
最朴素的做法是把每个动作维度分 bin,把连续值量化成离散 id。RT-2 一类方法就将机器人动作空间离散化,然后像生成文本一样生成动作 token。这种方案容易复用语言模型架构,但也带来误差累积、精度损失和推理延迟问题。
import numpy as np
def uniform_action_tokenize(action_chunk, low, high, bins=256):
"""
最简单的动作离散化示例。
action_chunk: [T, D],T 是动作片段长度,D 是动作维度。
low/high: 每个动作维度的上下界。
"""
x = np.clip(action_chunk, low, high)
scaled = (x - low) / (high - low + 1e-8)
tokens = np.floor(scaled * (bins - 1)).astype(np.int64)
return tokens.reshape(-1)
def uniform_action_detokenize(tokens, low, high, T, D, bins=256):
ids = tokens.reshape(T, D).astype(np.float32)
scaled = ids / (bins - 1)
return scaled * (high - low) + low
从公式上看,动作 tokenizer 做的是:
z 1 : B = T o k e n i z e r ( A t : t + H ) z_{1:B} = \mathrm{Tokenizer}(A_{t:t+H}) z1:B=Tokenizer(At:t+H)
动作 decoder 再把 token 还原为机器人执行的连续动作:
A ^ t : t + H = D e c o d e r ( z 1 : B ) \hat{A}_{t:t+H} = \mathrm{Decoder}(z_{1:B}) A^t:t+H=Decoder(z1:B)
这里的 B 是 token budget。它越大,动作细节越容易保留,但自回归预测要生成的 token 越多,推理越慢;它越小,模型更快,但精细抓取、插入、旋转这类控制动作容易损失。动作 tokenizer 因此不是普通压缩器,而是 VLA 的监督目标设计器。

图 3:ActionCodec 类工作把动作 tokenizer 从“重建器”重新定义为“适合 VLA 学习的动作监督设计器”。
好的动作 tokenizer 至少要满足四个要求:
- 相似动作对应相似 token:同一种稳定抓取里的轻微手抖不应变成完全不同的 token 序列。
- 控制 token 预算:过多 token 会拉高自回归推理延迟,过少 token 会损失动作细节。
- 避免拟合无关噪声:动作数据中的高频抖动、操作者习惯和标注噪声不应被认真编码成语义监督。
- 降低错误传播:自回归生成时,一个 token 错误不应让后续动作全部崩掉。
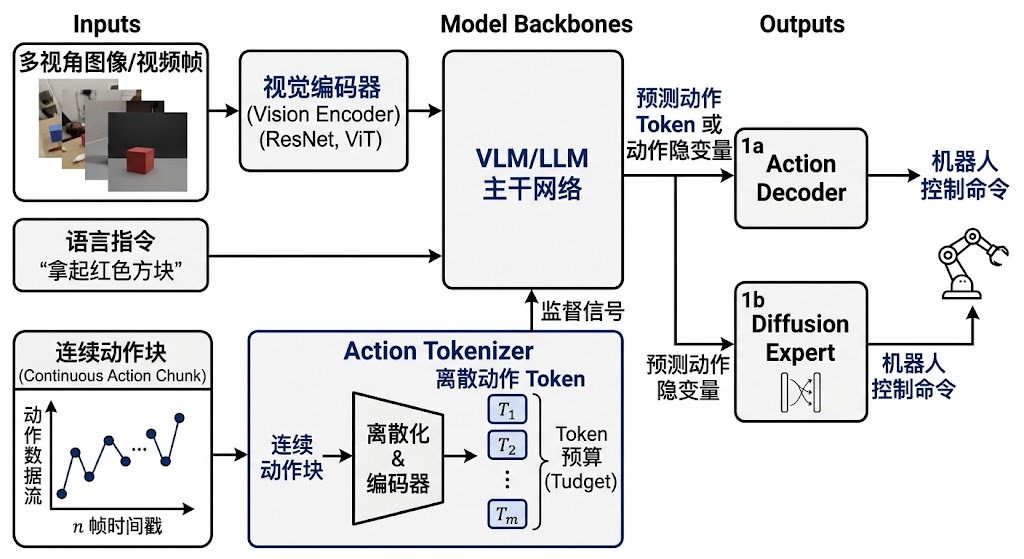
图 4:动作表示影响模型训练目标、推理延迟和控制质量。近年的 VLA 讨论已经从“模型多大”转向“动作如何被表示和学习”。
3. VLA 的三类动作生成路线:自回归、扩散与流匹配
理解 VLA 时,不能只看它接入了 VLM,还要看它怎样生成动作。当前主流做法可以分成三条路线:自回归、扩散和流匹配。三者的差别,本质上是连续机器人动作如何被模型表示、学习和实时生成。
3.1 自回归路线:把动作当成语言 token 生成
自回归路线的核心思想是,将连续动作离散成动作 token,然后从左到右逐个预测。这种路线最大的优势是可以复用 LLM/VLM 的成熟架构和预训练权重。RT-2 就是这一方向的代表,它把机器人动作离散化为多个 bin,并把动作 id 加入词表,让模型像生成文本一样生成动作。
自回归 VLA 的优点是训练简单、语言能力迁移直接、工程范式清楚;缺点是串行生成带来延迟,动作维度越高、chunk 越长,token 越多。同时,前面 token 的错误可能影响后续 token,导致动作漂移。对于高频控制和精细操作,自回归路线通常需要借助动作压缩、缓存、并行解码或低频策略高频控制器组合来缓解延迟。
3.2 扩散路线:从噪声中生成动作轨迹
扩散路线把动作生成看成一个去噪过程。训练时,模型学习从带噪动作恢复干净动作;推理时,从随机噪声开始迭代去噪,生成符合当前观测和语言指令的动作序列。
扩散策略的优势是能并行生成整段动作,天然适合多模态动作分布。同一个目标可能有多种可行抓取路径,扩散模型可以表示这种“一题多解”的动作空间。
缺点是采样需要多步迭代,计算成本较高。虽然可以通过 DDIM、少步采样、蒸馏等方式加速,但采样步数过少可能降低动作质量。因此,扩散路线适合动作多样性强、轨迹全局一致性重要的任务,但实时性优化会成为部署重点。
3.3 流匹配路线:学习从噪声到动作的速度场
流匹配可以看作扩散路线的进一步简化。它不显式模拟复杂扩散过程,而是直接学习从噪声分布流向目标动作分布的速度场。推理时,只需较少采样步数就能生成平滑动作。
π0 系列模型常被用来说明这一路线。π0 采用视觉语言专家与动作专家结合的架构,通过流匹配生成连续动作序列。它的价值不只在速度,还在动作的平滑性。
对拉拉链、擦拭、旋转瓶盖、插入等接触密集任务来说,动作的微小抖动就可能导致失败。流匹配生成的连续轨迹更符合这类控制需求,因此也更适合真实机器人上的精细操作。
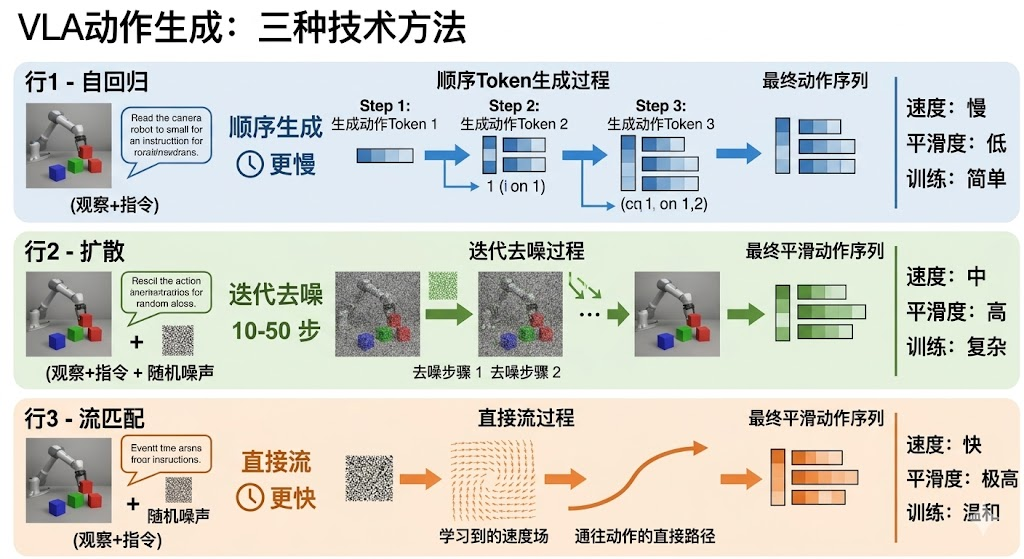
图 5:流匹配路线强调从噪声到动作的连续流动,相比自回归 token 更适合生成平滑连续的 action chunk。
三条路线可以这样对比:
| 路线 | 动作表示 | 优势 | 局限 | 适合场景 |
|---|---|---|---|---|
| 自回归 | 离散动作 token | 复用 LLM,训练简单,语言迁移好 | 串行延迟、误差累积、量化损失 | 开放语言任务、低频控制、快速复现 |
| 扩散 | 连续动作去噪 | 多模态动作强,整段动作一致 | 多步采样成本高 | 复杂轨迹、多个可行动作方案 |
| 流匹配 | 连续速度场 | 平滑、高效、少步生成 | 训练与调度仍需精细设计 | 精细操作、接触密集控制、实时部署 |
4. VLA 生态:从开源基座到性能标杆
从现有技术生态看,VLA 已经不是单一模型,而是形成了多层路线。不同模型的差异不只在参数规模,也在动作生成机制、数据组织方式、机器人本体适配能力和真实部署目标。
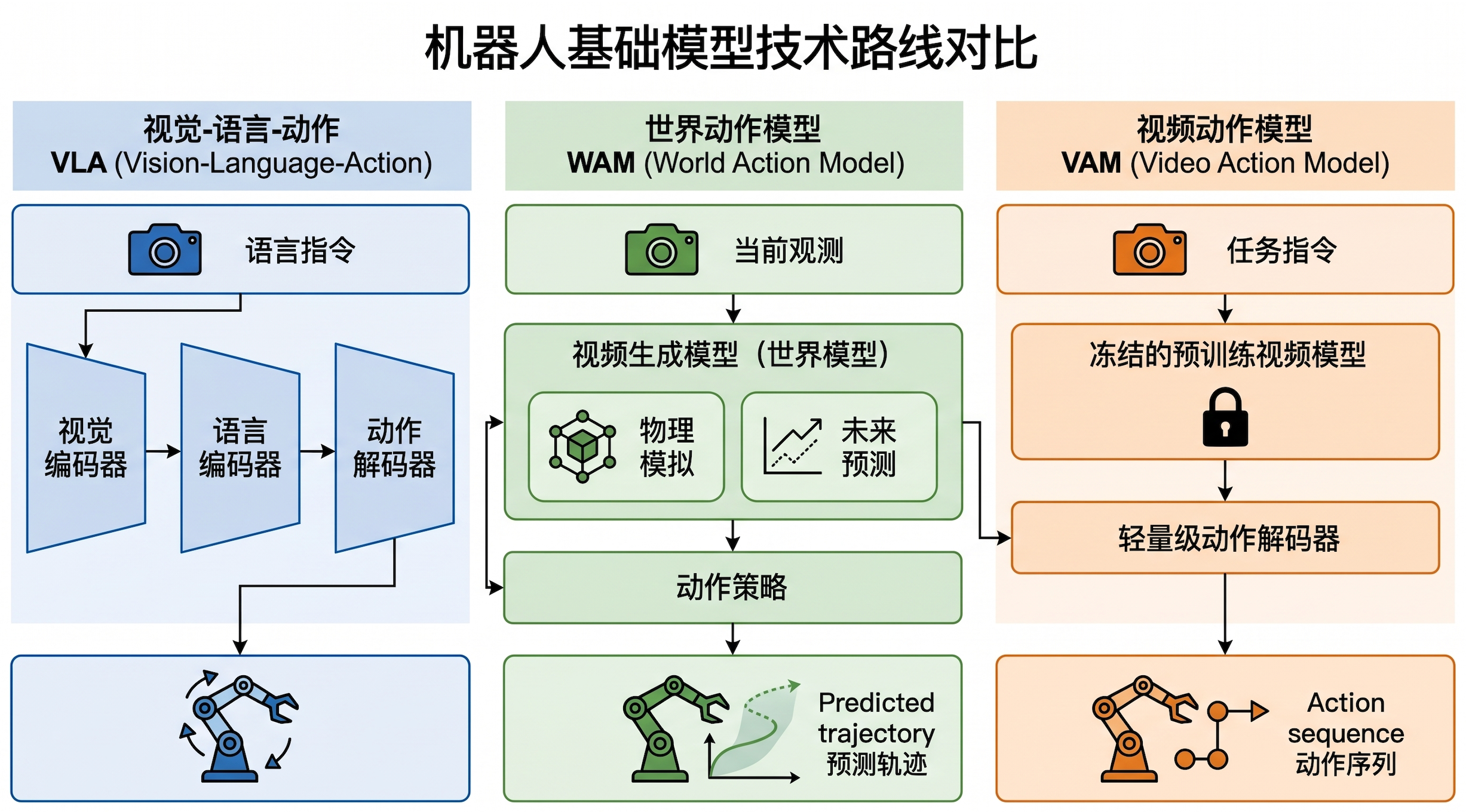
图 6:机器人基础模型路线正在从单一 VLA 扩展到 VLA、WAM、VAM、RL 后训练等多分支融合。
可以按工程定位把代表模型分成几类。
第一类是 语义迁移型 VLA。RT-2、OpenVLA 这类模型强调把 VLM 的互联网语义知识迁移到机器人控制中。OpenVLA 的意义不仅在于模型本身,还在于它把大规模机器人演示、开源权重、LoRA 微调和量化部署组织成社区可复现路线。
第二类是 高性能动作生成型 VLA。π0 系列代表了“视觉语言专家 + 动作专家 + 流匹配”的思路,重点解决动作连续性、接触任务和泛化问题。π0.5、π0.7 进一步强调知识隔离、提示条件化和世界模型式子目标。
第三类是 轻量化与端侧部署型 VLA。SmolVLA 这类模型的价值在于让普通 GPU 或个人设备也能运行 VLA,为研究者、小团队和边缘设备部署降低门槛。
第四类是 跨本体泛化型 VLA。X-VLA 通过软提示等方式编码机器人本体信息,使模型能够适配不同机器人平台。跨本体泛化非常关键,因为真实机器人领域很少有统一动作空间:双臂、轮式底盘、人形机器人、灵巧手、机械臂末端执行器的控制维度都不同。
第五类是 世界模型增强型 VLA。WALL-A、DreamZero、Motus 等工作强调不只输出动作,还要让模型形成对未来世界变化的预测或 latent 表征。这样做的意义是把“动作后果”纳入策略内部,而不是让模型只记住训练轨迹。
| 模型/方向 | 主要特点 | 更适合解决的问题 |
|---|---|---|
| RT-2 | 将 VLM 语义能力接入机器人动作 | 语义迁移、开放词汇任务 |
| OpenVLA | 开源 VLA 基座,支持微调与社区复现 | 通用机器人策略原型 |
| SmolVLA | 小参数、低资源部署 | 端侧运行、轻量研究 |
| X-VLA | 软提示适配不同机器人本体 | 跨平台迁移 |
| π0 系列 | 流匹配与动作专家 | 精细操作、连续控制 |
| WALL-A / DreamZero / Motus | 引入世界模型或视频动作联合建模 | 长时任务、物理预判、后训练 |
需要注意的是,参数规模并不是唯一指标。机器人模型的真实价值还取决于控制频率、动作稳定性、失败恢复能力、跨场景泛化和真实机器人成功率。一个更小但能稳定闭环控制的模型,往往比一个只能离线生成漂亮视频的大模型更有工程意义。
5. VLA 的根本局限:强语义不等于强物理预见
VLA 的核心问题在于,它大多仍是从当前观测和语言指令到动作的响应式映射:
VLA : ( o t , l ) → a t : t + H \text{VLA}: (o_t, l) \rightarrow a_{t:t+H} VLA:(ot,l)→at:t+H
它可以知道“杯子”“水槽”“餐桌收拾干净”是什么意思,也可能学过很多抓取和放置轨迹,但它未必显式知道某个动作会让杯子倾斜、滑落、碰到旁边的碗,或者让后续任务进入不可恢复状态。
这种局限在短时抓取中未必明显,因为很多任务靠模仿就能完成。但在长时任务、接触密集任务、可变形物体操作和开放家庭场景中,机器人必须理解动作会如何改变世界。机器人不是在图像里做选择,而是在物理环境里持续干预;每一步动作都会改变下一步观测,而下一步观测又会影响后续动作。
因此,世界模型重新回到机器人学习中心。世界模型的基本形式是:
p ( o t + 1 ∣ o t , a t ) p(o_{t+1} \mid o_t, a_t) p(ot+1∣ot,at)
它不是为了生成“好看的未来视频”,而是为了服务控制、规划、评估和后训练。一个未来视频即使清晰,如果不能被动作控制、不能保持接触关系、不能预测失败风险,也不能算真正的机器人世界模型。
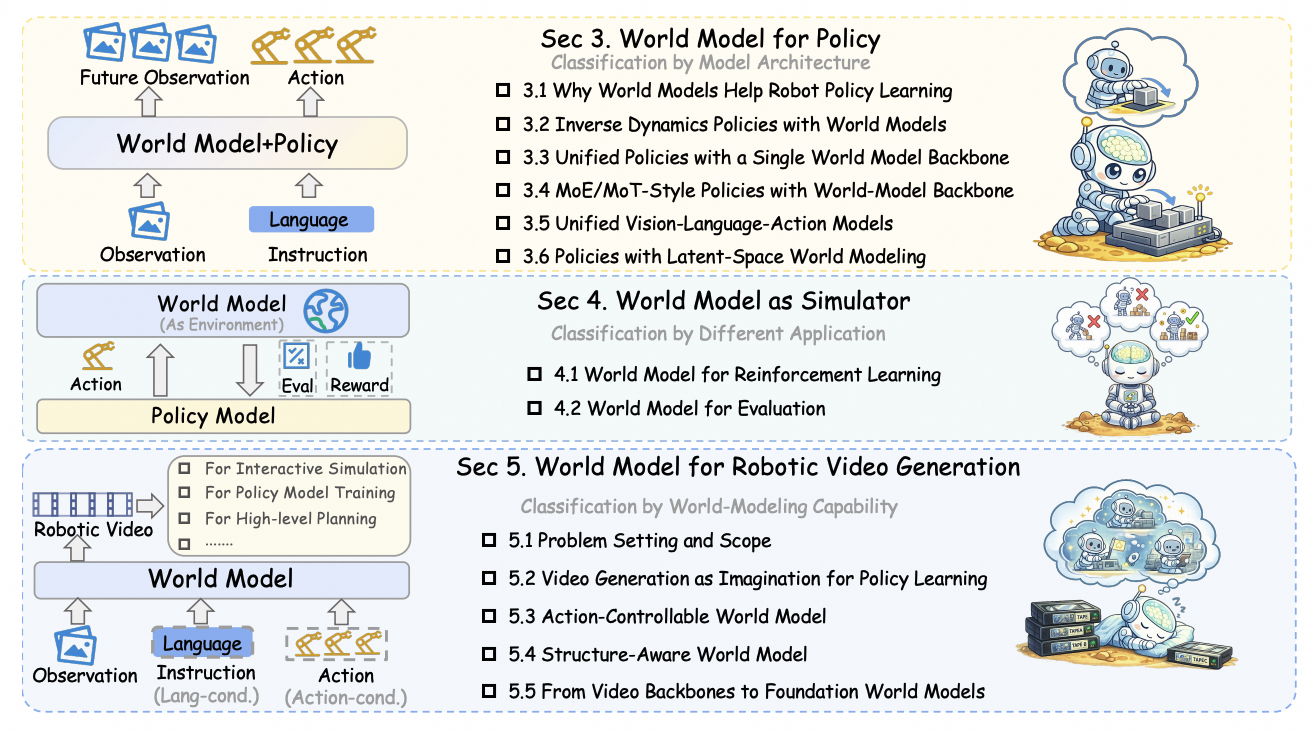
图 7:机器人世界模型可以分为策略内世界模型、学习型模拟器和机器人视频生成三条线。关键问题不是视频像不像,而是能否服务动作决策。
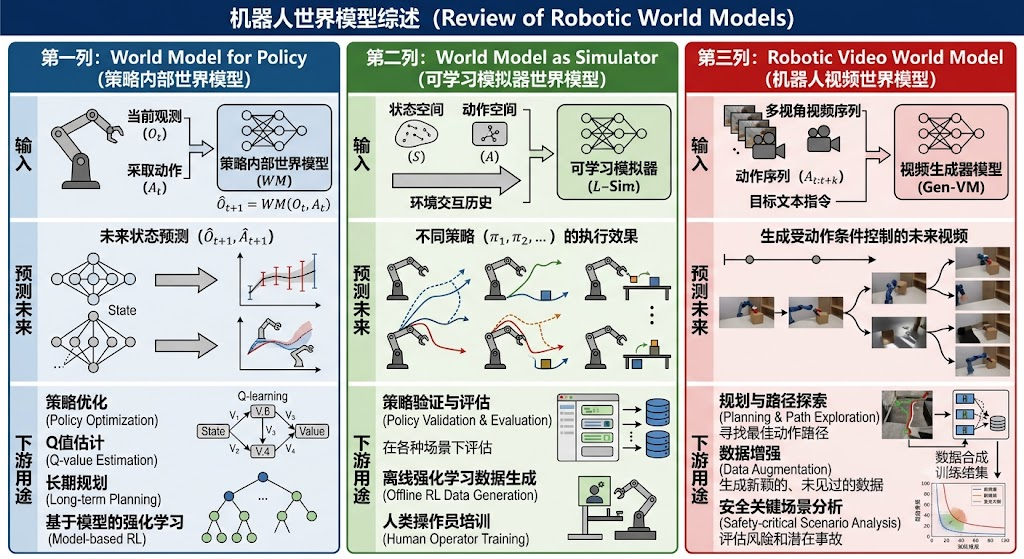
图 8:世界模型进入机器人基础模型后,评估标准从视觉保真度扩展到物理一致性、动作可执行性和策略收益。
6. WAM:把“预测未来”并入动作生成
WAM(World Action Model)可以理解为 VLA 与世界模型的合流。标准 VLA 建模的是:
p ( a t : t + H ∣ o t , l ) p(a_{t:t+H} \mid o_t, l) p(at:t+H∣ot,l)
WAM 建模的是:
p ( o t + 1 : t + H , a t : t + H ∣ o t , l ) p(o_{t+1:t+H}, a_{t:t+H} \mid o_t, l) p(ot+1:t+H,at:t+H∣ot,l)
这一步的意义不是多输出一段视频,而是让动作生成被未来状态约束。机器人在执行之前先形成关于世界演化的内部表征,再依据这个表征生成动作,就有机会利用物体位移、接触变化、遮挡、风险和任务进度来选择更稳的动作。
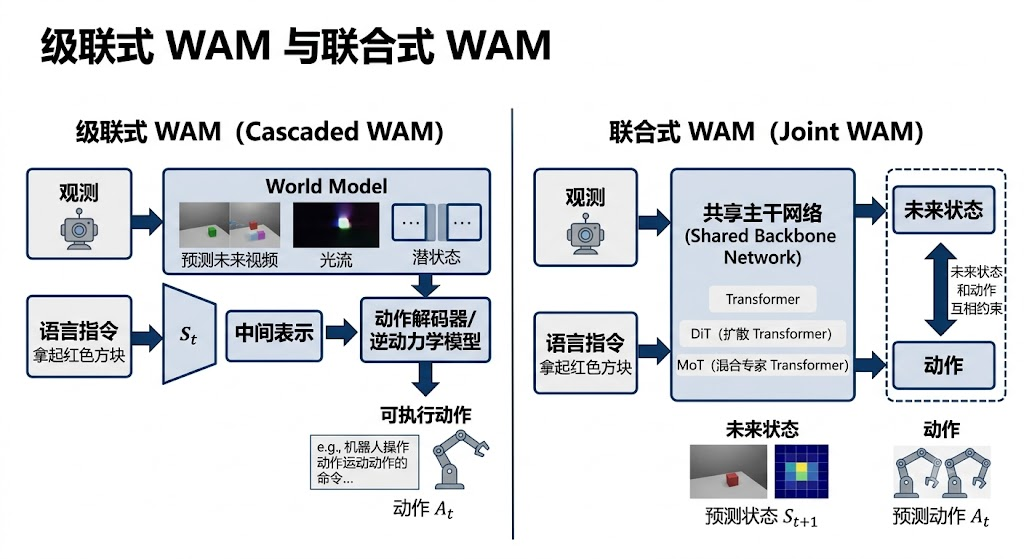
图 9:WAM Survey 对 VLA、World Model 和 WAM 的边界做了形式化区分。WAM 的核心是未来状态与动作的联合建模。
WAM 大致可以分成两类。
级联式 WAM 是先预测未来,再从未来反推动作。例如先用视频生成模型合成任务执行过程,再用逆动力学模型从视频里恢复动作。这类方法解释性强,中间未来视频、光流或语义图可以被人检查。
它的问题是误差会层层传递。如果未来视频偏了,动作也会跟着偏;如果逆动力学模型较弱,视频看起来合理也不一定能转成可执行控制。因此,级联式 WAM 的关键在于未来预测和动作恢复都要足够可靠。
联合式 WAM 是把未来状态和动作放进同一个生成过程,例如共享一个 DiT 主干,同时去噪未来视频 latent 和动作 latent,或者用多专家 Transformer 让理解专家、视频专家和动作专家共享注意力。
这类方法耦合更深,更有可能学到动作与世界变化之间的内在关系。代价是训练、调度、推理和评估都更复杂,因为模型必须同时处理“未来是否合理”和“动作是否可执行”两个问题。
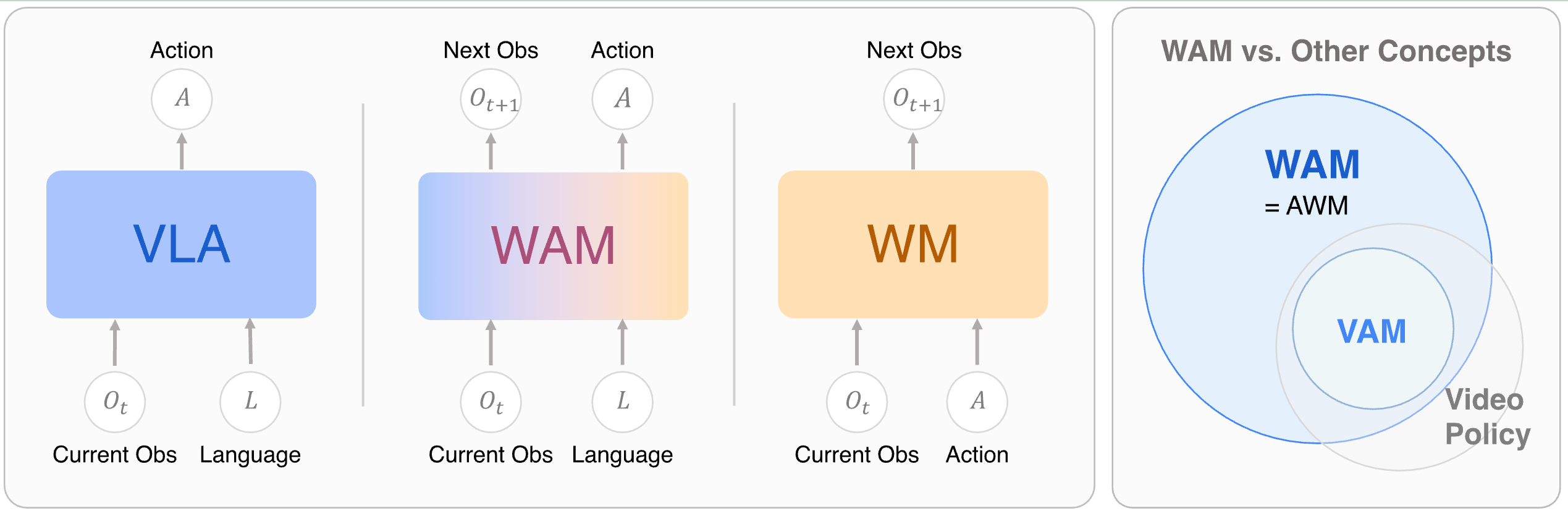
图 10:级联式 WAM 更可解释,联合式 WAM 更统一。工程上常见路线是先用未来 latent 或短 horizon 预测降低成本,再逐步扩展到长时视频和动作联合生成。
6.1 DreamZero:视频扩散骨干进入闭环控制
DreamZero 适合用来理解联合式 WAM 的工程哲学。它以预训练视频扩散骨干为基础,把视频和动作放进同一个自回归闭环控制流程中。
这个方向特别依赖工程细节,例如真实观测替换想象帧、异步执行、缓存、量化优化等。它们的作用是把原本很重的视频扩散模型,尽量推向真实机器人可以承受的实时闭环控制。
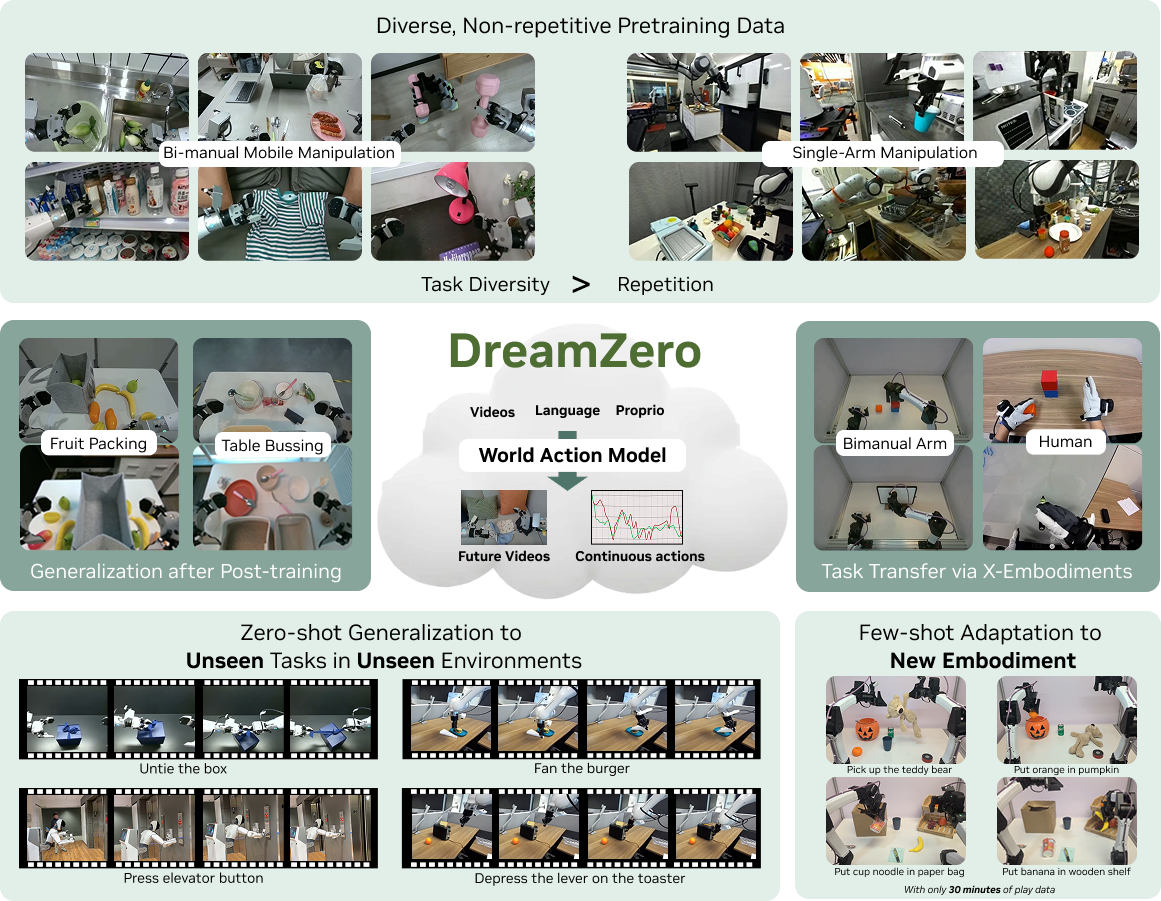
图 11:DreamZero 将预训练视频扩散骨干改造成闭环 World Action Model,强调未来状态与动作的联合建模。
DreamZero 的核心启发是:未来预测不能无限滚动幻想。真实机器人每执行一段动作,就会得到真实相机反馈。用真实观测替换预测帧,本质上是在闭环中持续校正世界模型,避免预测误差长时间累积。
6.2 Motus:用多专家框架统一理解、世界建模与动作
Motus 则体现另一种思路:用统一多模态框架承载理解、视频生成和动作预测。它引入理解专家、视频专家和动作专家,通过 Mixture-of-Transformers 和 UniDiffuser 式调度支持多种模式:世界模型、VLA、逆动力学、视频生成、视频动作联合预测等。
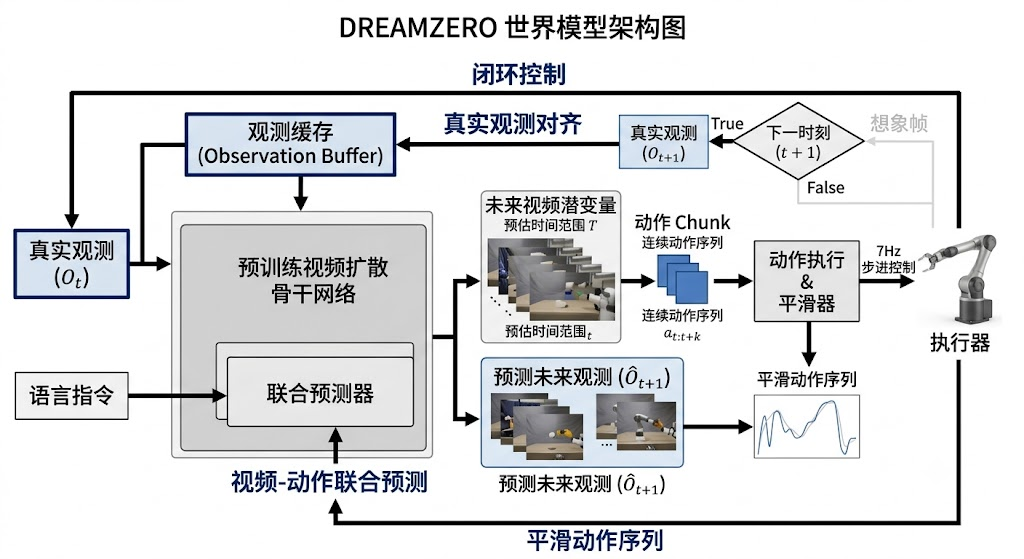
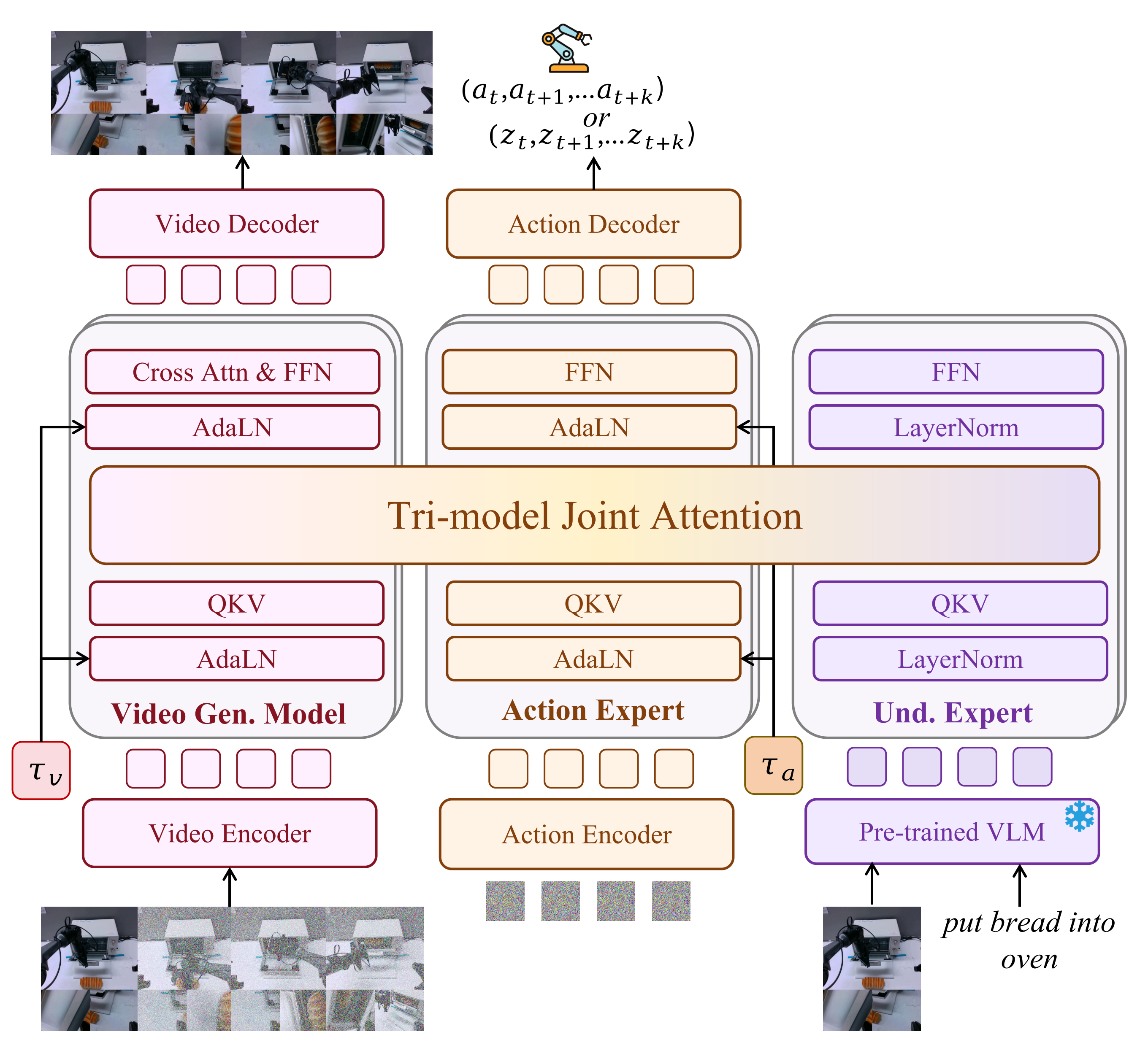
图 12:Motus 使用理解、视频和动作三类专家,让语义理解、世界建模和动作生成在共享注意力中交换信息。
DreamZero 更强调实时闭环和真实执行对齐;Motus 更强调统一建模和跨具身动作抽象。二者的共同点是,它们都不满足于“看见就做”,而是把未来状态纳入动作生成过程。
6.3 WAM 推理:候选未来与动作绑定
WAM 的推理方式也不同于普通 VLA。它可以同时生成多条 future-action 候选,然后依据价值、风险和不确定性选择执行哪一条。
def wam_candidate_selection(world_action_model, obs, instruction, k=8):
"""
简化版 WAM 推理流程:
生成多条 future-action 候选,再根据价值、风险和不确定性选择动作。
"""
rollouts = []
for _ in range(k):
future, action_chunk, scores = world_action_model.sample(
observation=obs,
language=instruction,
return_future=True,
return_action=True,
)
utility = scores["value"] - 0.7 * scores["risk"] - 0.3 * scores["uncertainty"]
rollouts.append({
"future": future,
"action": action_chunk,
"scores": scores,
"utility": utility,
})
best = max(rollouts, key=lambda item: item["utility"])
return best["action"], rollouts
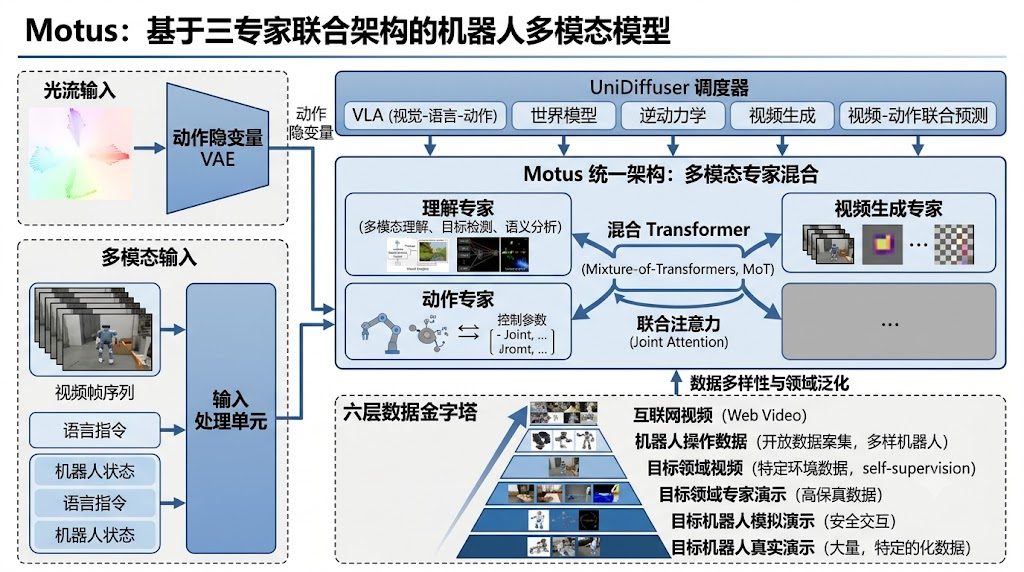
图 13:WAM 不只输出动作,还输出与动作绑定的未来候选。这些候选记录了模型当时如何权衡价值、风险和不确定性。
这种机制非常重要。对于真实机器人,未执行的候选不是强监督标签,但它们记录了模型在同一状态下认为哪些路径可行、哪些路径危险、哪些路径不确定。这些信息可以进入偏好学习、风险排序和失败分析。
7. VAM:借用视频生成模型的物理先验
VAM(Video Action Model)可以放在 WAM 和 VLA 之间理解。WAM 倾向于把世界预测显式纳入动作生成,甚至生成未来视频或未来 latent;VAM 则更务实:它不一定从头训练一个机器人世界模型,而是直接借用预训练视频生成模型的物理先验。
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)