LocateAnything:基于并行框解码的快速高质量视觉语言定位
摘要
视觉语言模型(VLM)通常将视觉定位和检测形式化为坐标令牌生成问题,将每个2D框序列化为多个1D令牌,这些令牌被学习并很大程度上独立解码。这种逐令牌解码与框几何的耦合结构不匹配,并且由于严格的顺序生成而产生了实际的推理瓶颈。我们提出了LocateAnything,一个基于并行框解码(PBD)的统一生成式定位与检测框架。通过将几何元素(如边界框和点)作为原子单元一步解码,LocateAnything保持了框内几何一致性并释放了显著的并行性。我们展示了PBD既提高了解码吞吐量又提高了定位精度。我们进一步开发了一个可扩展的数据引擎,并策划了LocateAnything-Data,一个包含超过1.38亿个训练样本的大规模数据集,显著增加了高精度定位的数据多样性。大量评估表明,LocateAnything推进了速度-精度的前沿,在提高高IoU定位质量的同时实现了显著更高的解码吞吐量。结果凸显了并行框解码和大规模训练数据在实现高效、精确的统一视觉定位与检测方面的互补优势。
1. 引言
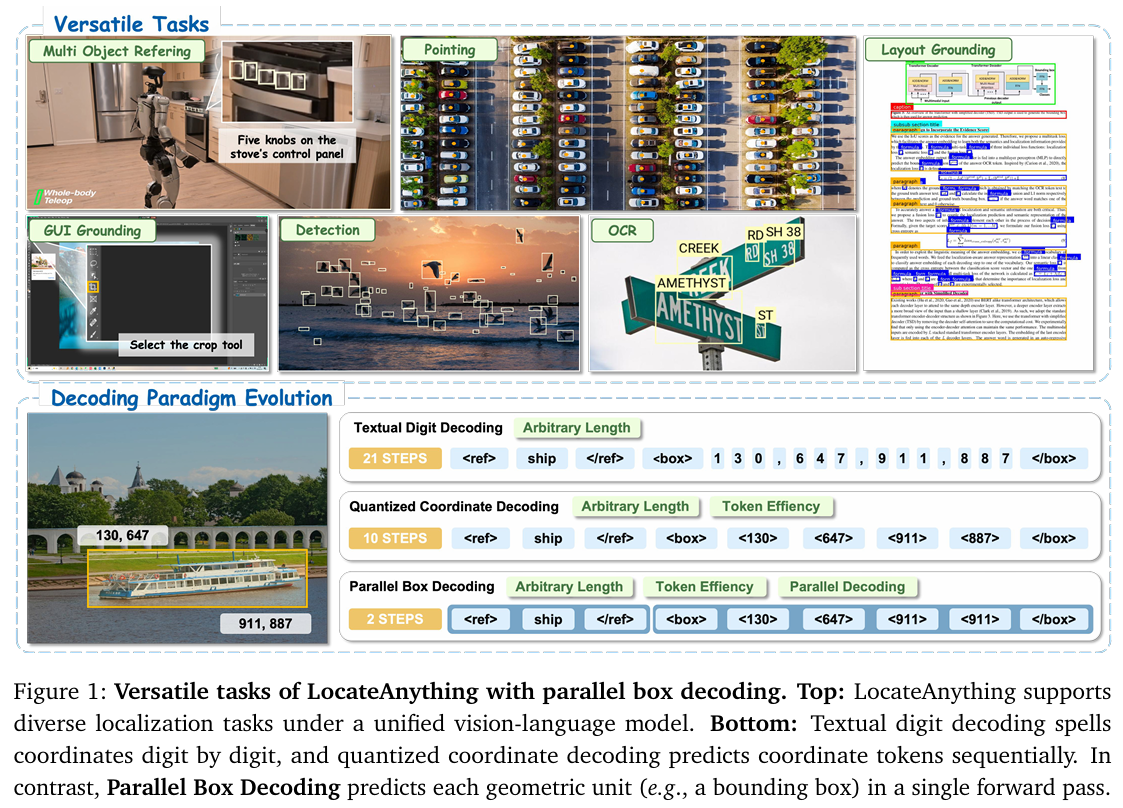
视觉语言模型(VLM)(Bai等人,2025b;Chen等人,2025;Deshmukh等人,2025;Huang等人,2026;Wang等人,2025a;Yang等人,2025a)由于其比传统专用模型(Carion等人,2020;Liu等人,2023d;Ren等人,2016;Zhang等人,2022)更广泛的知识和更强的指令跟随能力,越来越多地被用作交互式和具身系统的通用骨干。为了在物理世界中行动,VLM(Azzolini等人,2025;Bai等人,2025b;Fu等人,2025b;Wang等人,2025a;Zhan等人,2024)必须紧密地扎根于感知中——特别是,它们需要从自然语言意图中以高质量和低延迟定位任务相关实体(例如,物体(Jiang等人,2025a;Wang等人,2023b;Yu等人,2025;Zhang等人,2024b)、UI元素(Feizi等人,2025;Lin等人,2024a;Liu等人,2025e;Nayak等人,2025)、区域(Cheng等人,2024;Heinrich等人,2025;Lai等人,2024a;Ranzinger等人,2024;Ren等人,2024b;Yuan等人,2025)),这需要高水平的视觉语言定位能力。
VLM中的物体检测和定位(Jiang等人,2025a;Li等人,2025a;Man等人,2025;Peng等人,2023;Yu等人,2025;Zhan等人,2024;Zhang等人,2024c)通常被形式化为生成问题。在下一个令牌预测(NTP)范式下(Chen等人,2022b;Jiang等人,2025a;Peng等人,2023),VLM可以通过发出作为令牌序列的空间坐标来回答开放式查询。如图1底部面板所示,现有方法(Jiang等人,2025a;Peng等人,2023;Qi等人,2025;You等人,2024;Zhang等人,2024c)通常将坐标表示为文本数字(例如,“1024”表示为“1”,“0”,“2”,“4”)或量化令牌(例如,x1→y1→x2→y2x_{1} \rightarrow y_{1} \rightarrow x_{2} \rightarrow y_{2}x1→y1→x2→y2)。尽管存在差异,但这些表示将2D几何对象序列化为1D流,迫使推理时逐令牌生成。这种令牌级顺序解码成为实际瓶颈(更高的延迟和更低的吞吐量),并且未能充分利用坐标(x1,y1,x2,y2)(x_{1}, y_{1}, x_{2}, y_{2})(x1,y1,x2,y2)之间强大的结构相关性。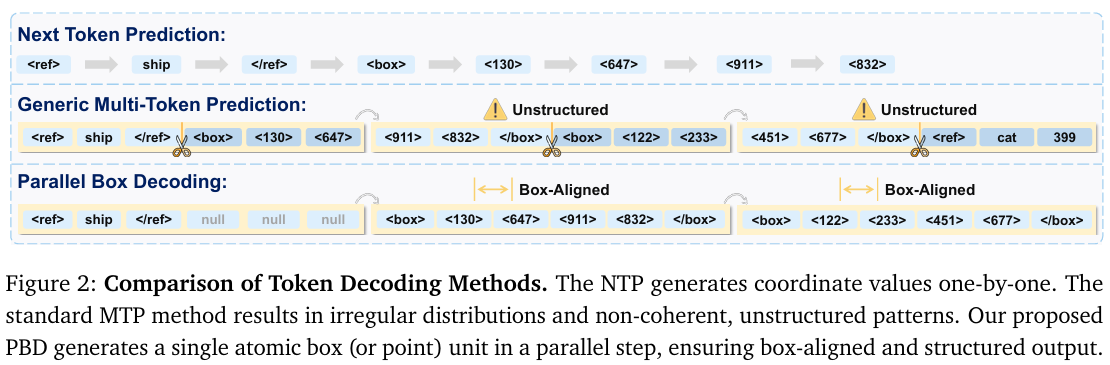
多令牌预测(MTP)(Liu等人,2025c;Nie等人,2025;Ye等人,2025b;Zeng等人,2025)提供了一种通过并行预测多个令牌来减少解码步骤的自然方法。在语言建模中,MTP通常通过以下方式实现:(i)随机选择序列中的位置,并训练模型并行预测随后的跨度(即下一块预测)(Cai等人,2024b;Li等人,2025c;Liu等人,2024a,2025c),或(ii)掩码序列中的一些令牌,并训练模型重构原始文本,例如掩码扩散建模(Arriola等人,2025;Li等人,2022;Liu等人,2025b;Nie等人,2025)。然而,这些形式在很大程度上是结构无关的:它们将输入视为通用令牌流,主要捕获由共现驱动的相关性。从随机子集推断缺失令牌要求模型表示复杂且不规则的的条件分布。对于像边界框这样紧密耦合的单元,这种监督与训练目标不匹配,因为它可以学习生成跨越边界框边界甚至物体类别的令牌组合,如图2所示。因此,模型必须适应许多不可靠的模式,引入虚假相关性,牺牲结构化解码,并放大错误传播,从而降低准确性、可靠性和解码速度。
为了协调高吞吐量解码与可靠的定位,我们提出了LocateAnything,一个基于并行框解码(PBD)的面向VLM的视觉检测与定位的统一框架。我们的关键思想是将MTP块与结构单元对齐:在训练期间,LocateAnything将每个边界框(或点)视为一个原子单元,并学习在一个并行步骤中预测完整的坐标集(x1,y1,x2,y2)(x_{1}, y_{1}, x_{2}, y_{2})(x1,y1,x2,y2)。这种框对齐的训练目标避免了坐标令牌的任意分块。结果,我们的策略提高了模型的定位性能,同时解锁了并行解码的速度优势。
通过所提出的PBD,我们研究了各种结构化边界框解码策略以平衡吞吐量和准确性。我们的观察启发了一种灵活的推理设计,通过提供三种按需模式来满足不同的延迟-鲁棒性需求。(i) 快速模式(MTP) 并行预测完整框以获得最大吞吐量,适用于延迟和计算受限的设置,如设备端机器人和具身代理。(ii) 慢速模式(NTP) 自回归解码坐标令牌以获得最大稳定性,适用于高精度标注、最终数据集筛选和面向精度的离线评估。(iii) 混合模式 默认使用快速模式,当并行输出不可靠时(例如,由于格式或一致性违规)回退到慢速模式;该模式适用于需要同时兼顾速度和精度的生产管道。总体而言,混合模式保留了并行解码的大部分速度优势,同时保持了稳健的输出。
我们的主要贡献总结如下:
- 我们提出了LocateAnything,这是通过并行框解码将多令牌预测应用于基于VLM的检测/定位的早期探索,执行框对齐解码以提高吞吐量和准确性。
- 我们提出了一种混合解码策略,该策略检测不可靠的并行块,并仅对有问题的块执行局部NTP重解码,从而在保持大部分速度提升的同时减少最坏情况下的失败。
- 广泛的评估,包括布局定位、长尾检测和GUI定位,表明LocateAnything极大地推进了速度-精度前沿,优于现有技术水平。它实现了高达2.5×2.5\times2.5×的解码吞吐量提升,同时提高了定位质量。
2. 相关工作
VLM中的视觉检测与定位。 视觉定位/检测任务传统上依赖于特定任务的头部(Carion等人,2020;Jiang等人,2024;Ren等人,2016,2024a),但最近的VLM如Qwen-VL系列(Bai等人,2025a,b)、InternVL(Chen等人,2024b)和Shikra(Chen等人,2023a)将其形式化为自回归令牌生成问题。然而,这种生成范式常常遭受结构幻觉和高延迟的困扰(Li等人,2023a)。为了缓解这些问题,Rex-Omni(Jiang等人,2025a)采用基于点的预测,而Patch-as-Decodable-Token(PaDT)(Su等人,2026)和Groma(Ma等人,2024b)利用视觉参考令牌直接指向图像块。其他创新如Pink(Xuan等人,2024)、ViP-LLaVA(Cai等人,2024a)、Griffon(Zhan等人,2024)、DnU(Lin等人,2024b)和PAM(Lin等人,2025)专注于通过视觉提示工程和多粒度特征缩放增强2D指代理解。LLMDet(Fu等人,2025b)通过数据分布调优提高检测召回率。为了绕过串行解码瓶颈,WeDetect(Fu等人,2025a)将检测视为并行检索任务。通过思维链(CoT)(Qi等人,2025)进一步集成了高级感知逻辑,而诸如Vision-R1(Zhan等人,2025)、UniVG-R1(Bai等人,2025c)和GW-VLM(Jiang等人,2026)等后训练策略利用强化学习使模型输出与视觉反馈对齐并减少定位错误(Zhang等人,2024c)。
通过MTP和扩散LLM的并行解码。 为了缓解自回归延迟,并行生成技术如MTP(Cai等人,2024b;Gloeckle等人,2024;Samragh等人,2025)同时预测多个未来令牌,通常与推测解码结合以加速推理。最近的扩展如未来摘要预测(Mahajan等人,2025)通过辅助头捕获长期依赖。同时,扩散语言模型(DLM)如LLaDA(Nie等人,2025)、Dream(Ye等人,2025b)和DiffuCoder(Gong等人,2025)将序列生成视为离散去噪过程,实现了双向上下文建模和非自回归解码。混合半自回归范式,包括块扩散(Arriola等人,2025)、SDLM(Liu等人,2025c)和Fast-dLLM v2(Wu等人,2025a),并行解码固定大小的令牌块,同时保持因果依赖以兼容KV缓存。更先进的框架(Lu等人,2025a;Wang等人,2025b)解锁了块间并行性和自适应块调度。这些范式通过DiffusionVL(Zeng等人,2025)扩展到多模态领域,将自回归LMM转换为高性能的基于扩散的模型。
LocateAnything在两个方面与现有工作不同。首先,我们不通过缓慢的NTP生成边界框,而是在单个并行步骤中输出完整的框。其次,最近的MTP范式将令牌分组为任意块。相反,我们的PBD将整个坐标集视为单个原子块,解决了NTP的碎片化和MTP的任意分块问题,无缝地统一了高吞吐量和结构一致性。
3. 方法
本节介绍LocateAnything,一个将并行框解码(PBD)集成到VLM中用于视觉检测与定位的快速高效框架。第3.1节介绍模型架构和基于块的输出形式化。第3.2节详细介绍联合训练策略,该策略将NTP与块级MTP对齐。第3.3节描述按需推理机制,其中混合模式动态平衡解码吞吐量和鲁棒性。最后,第3.4节概述我们的大规模训练数据集LocateAnything-Data的构建。
3.1. 模型架构与形式化
概述。 如图3所示,LocateAnything构建于一个在大规模图像-文本语料上预训练的本机分辨率VLM之上。该架构包括一个Moon-ViT(Kimi Team,2025)视觉编码器和一个Qwen2.5(Qwen Team,2024)语言解码器,通过MLP投影仪连接。给定输入图像I\mathcal{I}I,视觉编码器以本机分辨率提取视觉标记Z=Encoder(I)Z = \mathrm{Encoder}(\mathcal{I})Z=Encoder(I),保留了高精度定位所需的关键细粒度空间细节。这些标记随后被输入语言模型,该模型直接将它们转换为框对齐的块级预测序列。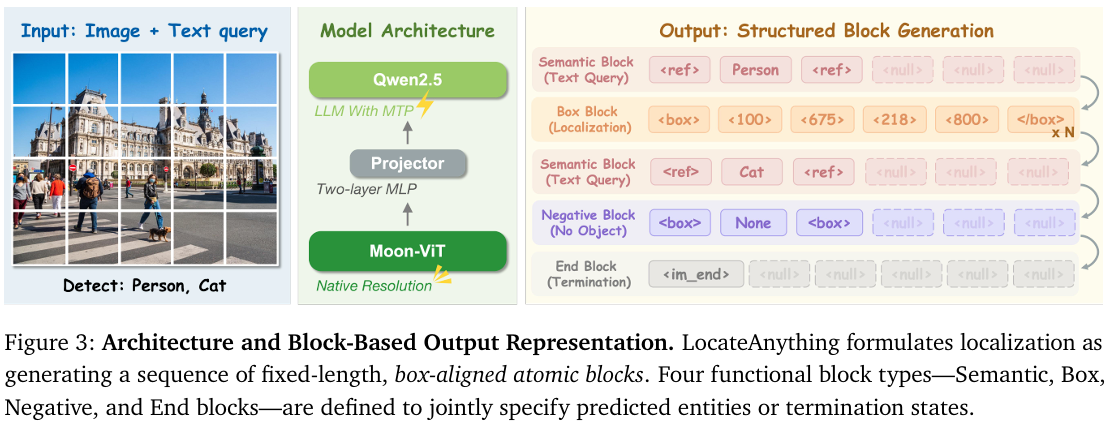
基于块的输出形式化。 为了促进PBD,我们放弃了标准的NTP坐标生成。相反,连续坐标被归一化到[0,1000][0,1000][0,1000],离散化为令牌(Chen等人,2022b;Jiang等人,2025a),并重新组织成块序列B=(b1,b2,…,bN)\mathbf{B} = (b_{1},b_{2},\ldots ,b_{N})B=(b1,b2,…,bN)。以视觉特征ZZZ和文本查询E\mathcal{E}E为条件,联合概率形式化为P(B∣Z,E)=∏i=1NP(bi∣b<i,Z,E)P(\mathbf{B}\mid \mathcal{Z},\mathcal{E}) = \prod_{i = 1}^{N}P(b_{i}\mid b_{< i},Z,\mathcal{E})P(B∣Z,E)=∏i=1NP(bi∣b<i,Z,E)。
每个块bib_{i}bi作为一个长度为常数L=6L = 6L=6的原子单元,容纳一个边界框和两个结构令牌(例如,和)。为了保证并行解码的统一张量形状,任何不足的块用填充令牌补足。我们定义了四种功能块类型:(1) 语义块:编码语言标识。如果一个表达超出单个块的容量,则将其分割到多个连续块中。(2) 框块:使用四个量化坐标表示边界框。(3) 负块:明确指示查询对象不存在。(4) 结束块:表示生成过程的终止。
3.2. 训练设计
我们的方法将边界框坐标视为不可分割的原子单元,强制执行结构化监督并解锁并行生成的能力。然而,在训练阶段直接并行化输出可能会破坏模型固有的因果推理过程。为了解决这个问题,我们引入了一种双形式训练策略,联合优化两种对齐的表示:NTP序列以保持因果推理能力,以及块级MTP形式以进行框对齐预测。为了实现这一点,我们构建了一个单一的拼接输入序列:xall=xvis⊕xq⊕xntp⊕xblkx_{\mathrm{all}} = x_{\mathrm{vis}} \oplus x_{\mathrm{q}} \oplus x_{\mathrm{ntp}} \oplus x_{\mathrm{blk}}xall=xvis⊕xq⊕xntp⊕xblk,其中⊕\oplus⊕表示序列拼接。xvisx_{\mathrm{vis}}xvis和xqx_{\mathrm{q}}xq作为共享上下文(视觉和文本查询输入),xntpx_{\mathrm{ntp}}xntp表示标准的NTP输入序列,xblkx_{\mathrm{blk}}xblk是块级MTP输入序列。本质上,它们以两种不同的格式表示相同的地面真值:令牌级表示和块级表示。
具体来说,受(Liu等人,2025a,c)的启发,xblkx_{\mathrm{blk}}xblk通过从左到右遍历xntpx_{\mathrm{ntp}}xntp,根据我们先前定义的块规则进行分割和填充来构建。在每个块内,我们保留第一个令牌作为预测上下文,而将后续所有令牌替换为[mask]令牌。这种结构促使模型在一个连贯的步骤中同时预测块内所有被掩码的令牌。值得注意的是,如果块大小设置为1,则此MTP形式自然等同于标准NTP。
注意力掩码设计。 这种双序列形式化的核心挑战是如何隔离NTP和MTP流,同时允许两者利用共享上下文。这是通过一种特殊的注意力掩码实现的(如图4所示),该掩码通过三种不同的行为来支配信息流:
- NTP的因果注意力:为了保持VLM原有的语言能力,共享上下文(xvisx_{\mathrm{vis}}xvis和xqx_{\mathrm{q}}xq)和NTP序列(xntpx_{\mathrm{ntp}}xntp)共同采用因果注意力掩码。这些段内的令牌只能关注前面的令牌。关键的是,它们被限制不能关注xblkx_{\mathrm{blk}}xblk以防止数据泄露。这种严格的因果形式与推理时标准KV缓存的使用完美对齐。
- 跨块的因果流:为了与半自回归生成过程对齐,xblkx_{\mathrm{blk}}xblk中不同块之间的注意力是严格因果的。当前块中的令牌可以关注共享上下文和所有先前已提交的块,但不能看到未来的块。这种历史可见性使模型能够学习不同框预测之间的依赖关系,有效缓解重复或缺失的边界框。
- 块内双向注意力:遵循近期生成建模中广泛采用的块因果设计(Arriola等人,2025;Fu等人,2025c;Nie等人,2025;Wang等人,2025b;Wu等人,2025a,b),同一块内的令牌共享双向注意力。这种全连接的块内交互允许模型捕获复杂的内部关系(例如,一组坐标之间的几何依赖关系),并在单个功能单元内同时解析所有内部令牌。
目标函数。 在此掩码的指导下,我们联合最小化两个序列的交叉熵损失,即L=Lntp+Lmtp\mathcal{L} = \mathcal{L}_{\mathrm{ntp}} + \mathcal{L}_{\mathrm{mtp}}L=Lntp+Lmtp。
3.3. 按需推理模式
虽然我们提出的PBD显著加速了推理,但并行解码在高度复杂的场景中面临固有的探索-利用困境,如图5所示。第一种是格式不规则,发生在包含多个跨类别实例的复杂场景中。在并行解码期间,模型可能在类别边界处挣扎,犹豫是继续预测当前类别还是转换到新类别。这种不确定性表现为单个预测块内格式错误的语法,错误地混合了结构令牌和坐标令牌(例如,<211><911><887>)。第二种是空间模糊性,当物体在规则网格(如行或列)中密集排列时出现。MTP方法可能模糊空间边界,并输出位于两个物体之间的中间坐标,从而产生低IoU预测。
这两种失败模式都可以通过NTP回退机制有效解决。NTP预测在处理复杂类别转换和密集空间布局时可以达到更高的精度。因此,在MTP推理期间,我们持续验证语法完整性并监控空间置信度。具体来说,如果同时满足两个条件,则触发模糊性触发器:(1) top-1坐标令牌的概率低于0.7,以及(2) top-5坐标令牌中的最大-最小差值在归一化的[0,1000][0,1000][0,1000]空间内超过80。一旦检测到格式违规或高空间模糊性,受损的块将被丢弃,生成过程回退到最后一个已验证的前缀。然后使用NTP自回归生成特定有问题的块的令牌。一旦该块完成,模型无缝切换回MTP进行后续预测。
基于上述讨论,我们提出了三种按需推理模式以平衡吞吐量和空间鲁棒性。(1) 慢速模式:使用标准NTP逐令牌生成输出。(2) 快速模式:利用MTP预测框对齐的块。对于每个块,丢弃填充令牌,并将剩余令牌附加到输出;已提交的令牌存储在键值缓存中,并作为后续预测步骤的因果上下文。(3) 混合模式:默认使用MTP,但当并行输出变得不可靠时无缝切换到NTP。
推理时的注意力掩码。 在推理期间,每个MTP解码步骤的注意力掩码与训练时的块因果模式(如图4所示)一致。KV缓存中所有先前提交的令牌遵循标准因果注意力,而当前MTP块中的nfuturen_{\mathrm{future}}nfuture个令牌彼此双向关注,实现并行令牌预测。同时,当前块可以关注所有前面的块,但不能访问后续块。每个MTP步骤后,KV缓存被截断以仅保留已提交的令牌,驱逐掩码令牌和重复的锚点,以确保缓存与训练时看到的因果前缀保持一致。
3.4. LocateAnything-Data
为了训练一个具备通用视觉检测与定位能力的高性能模型,我们策划了LocateAnything-Data,一个大规模、多领域的数据集。数据集构建细节见补充材料。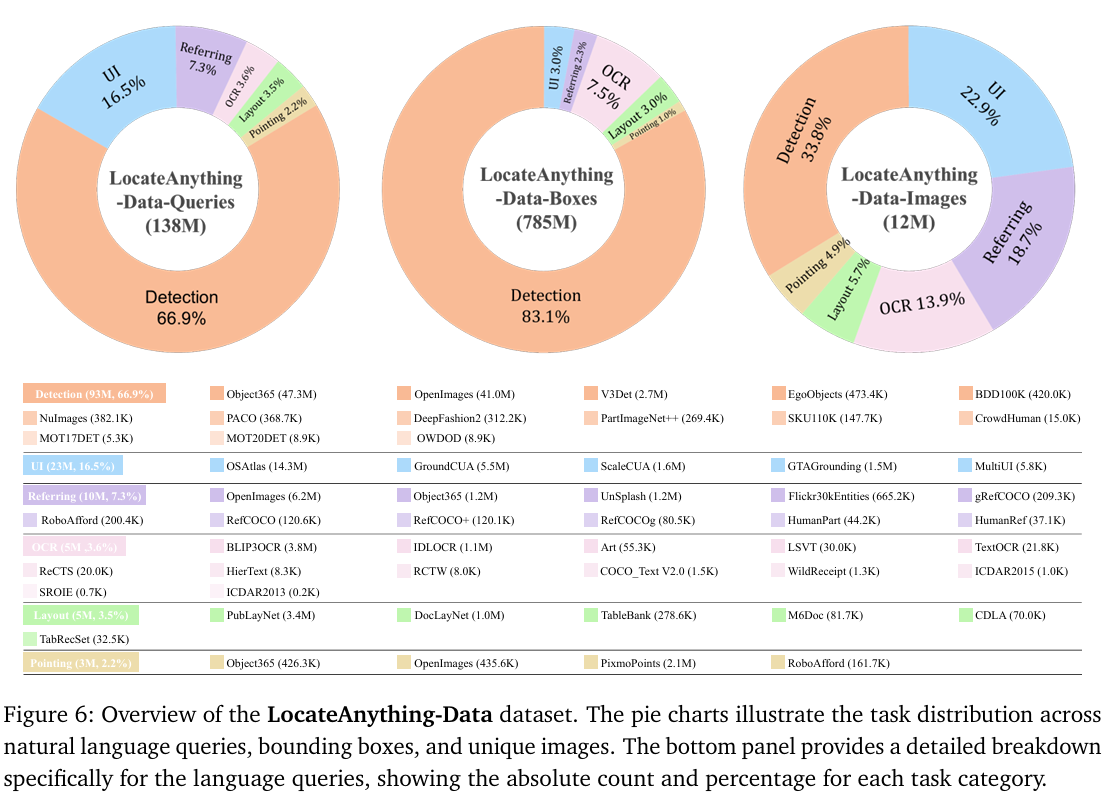
如图6所示,该数据集包含1200万张独特图像和1.38亿个自然语言查询。此外,数据集包含7.85亿个标注边界框,提供了庞大而密集的监督信号来指导LocateAnything模型的空间学习。训练语料分为六个不同的任务。(1) 通用物体检测构成基础,占查询的66.9%66.9\%66.9%,并提供必要的边界框监督(83.1%83.1\%83.1%),帮助模型实现精确密集的坐标对齐。(2) 用户界面元素定位(16.5%16.5\%16.5%的查询)使模型能够支持具身代理和图形用户界面导航任务。(3) 自然语言指代理解(7.3%7.3\%7.3%的查询)使模型能够将复杂的语言意图链接到特定的空间区域。(4) 文本定位(3.6%3.6\%3.6%的查询)确保模型能够感知并紧密定位图像中的文本信息。(5) 文档与场景布局定位(3.5%3.5\%3.5%的查询)丰富了模型的结构推理能力。(6) 基于点的定位任务(2.2%2.2\%2.2%的查询)进一步细化模型对细粒度预测的空间精度。
4. 实验
4.1. 训练细节与评估设置
训练细节。 我们首先在基础VLM上进行初始训练,完全专注于世界知识对齐,在此期间排除所有检测和定位数据。然后我们对基础VLM应用两阶段监督微调来训练我们的LocateAnything模型。在第一阶段,我们将包含1.38亿个查询的大规模混合数据纳入整体训练数据,使模型具备全面的定位和检测能力。在第二阶段,我们将通用训练数据的比例降低到20%20\%20%,同时显著增加每张图像包含许多物体的数据比例(例如,MOT20Det(Dendorfer等人,2020),SKU110K(Goldman等人,2019)),以增强模型在密集检测中的能力。对于模型消融研究,我们仅在COCO数据集(Lin等人,2014)上训练所有模型,以严格隔离PBD的架构优势与我们1.38亿大规模数据的影响。基础VLM和后续LocateAnything模型训练的详细配置见补充材料。
比较方法。 我们将LocateAnything与三类方法进行比较。(1) 专用检测器,包括代表性的通用检测模型如DETR(Carion等人,2020)和Deformable-DETR(Zhu等人,2021),开放集检测器如Grounding DINO(Liu等人,2023d),领先的文档布局分析模型DocLayout-YOLO(Zhao等人,2024),以及文本检测模型PaddleOCRv5(Cui等人,2025)。(2) 具有定位能力的通用VLM,包括Qwen3-VL(Bai等人,2025a)、DeepSeek-VL2(Wu等人,2024b)、OVIS2.5(Lu等人,2025b)、MiMo-VL(Xiaomi Team,2025)和SEED1.5-VL(Guo等人,2025)等。这些模型采用文本坐标表示和标准下一个令牌预测,为我们的并行框解码范式提供了直接比较。(3) 基于VLM的检测与定位专家,包括Rex-Omni(Jiang等人,2025a),这是与我们工作最相关的针对VLM框架中统一检测与定位的研究。对于GUI定位,我们还包括几个特定领域的专家模型(Gao等人,2026;Liu等人,2025d;Xie等人,2025;Yang等人,2025b;Ye等人,2025a;Zhou等人,2025)。
评估设置。 遵循Rex-Omni(Jiang等人,2025a)中建立的评估框架,我们在多个视觉感知任务上进行全面评估。物体检测在COCO(常见物体)、LVIS(Gupta等人,2019)(长尾分布)以及VisDrone(Du等人,2019)和Dense200(Jiang等人,2025a)(密集和小物体场景)上评估。语言感知定位任务包括RefCOCOg(Kazemzadeh等人,2014)和HumanRef(Jiang等人,2025b)上的指代表达理解(REC)。交互任务通过ScreenSpot-Pro(Li等人,2025b)上的GUI定位评估。此外,DocLayNet(Pfitzmann等人,2022)和M6Doc(Cheng等人,2023)上的布局定位,以及TotalText(Ch’ng and Chan,2017)上的OCR(文本检测与识别)一起作为场景文本和文档理解任务报告。
每个任务的指标总结如下。(1) 基于框的输出:对于检测、布局和OCR任务,如果预测框与真实框的交并比(IoU)超过某个阈值,则认为预测正确(即真阳性)。报告IoU=0.5IoU = 0.5IoU=0.5、IoU=0.95IoU = 0.95IoU=0.95以及阈值上的平均(mIoU)的F1分数。(2) 基于点的输出:对于指向任务,如果预测点落在真实分割掩码或边界框内,则认为预测正确。我们基于此正确性标准同样报告这些基于点的输出的F1分数。
4.2. 主要结果
在本节中,我们报告LocateAnything在默认混合模式下的精度指标和吞吐量(以每秒框数BPS测量,在单张NVIDIA H100 GPU上批大小为1)。快速和慢速模式的结果在补充材料中提供。
高质量多物体检测。 我们的模型在通用和复杂密集物体检测场景中均表现出强大的泛化能力。在表1的通用检测基准上,尽管模型大小相同,LocateAnything在LVIS上平均F1提升了+3.8%+3.8\%+3.8%,在COCO上提升了+1.8%+1.8\%+1.8%,优于Rex-Omni。关键的是,模型有效学习了广义的空间分布,将其检测能力迁移到未见过的、高度密集的物体类型。这体现在表2的密集检测基准上,它在VisDrone上达到39.9的平均F1,显著优于Rex-Omni的35.8。同样,它在Dense200上达到58.7的竞争力平均F1,展示了在高度重叠环境中优越的边界描绘和实例分离能力。
精确的开放世界定位能力。 LocateAnything在多样化的开放世界基准上展示了卓越的细粒度定位能力,包括用户界面定位、文档布局解析和指代表达理解。如表3所示,在ScreenSpot-Pro(Li等人,2025b)上,它达到了60.3的SOTA平均F1,超越了通用VLM如Qwen3-VL-30B-A3B以及专为UI任务设计的专用模型如GUI-Owl-32B。此外,在表4详述的文档理解任务中,LocateAnything在DocLayNet和M6Doc上分别达到76.8和70.1的平均F1,建立了新的标准,以显著优势超越了Rex-Omni。这种精确的空间推理扩展到了复杂的指代任务,如表5所示,模型在HumanRef基准上达到了78.7的平均F1,并在RefCOCOg上与顶级模型保持了高度竞争力。
卓越的解码速度。 我们模型的一个关键优势是其大幅减少的解码步骤。如表1所示,我们的模型在默认混合模式下实现了12.7 BPS,比基于文本的Qwen3-VL(1.1 BPS)快10×10\times10×以上,比基于量化的Rex-Omni(5.0 BPS)快2.5×2.5\times2.5×。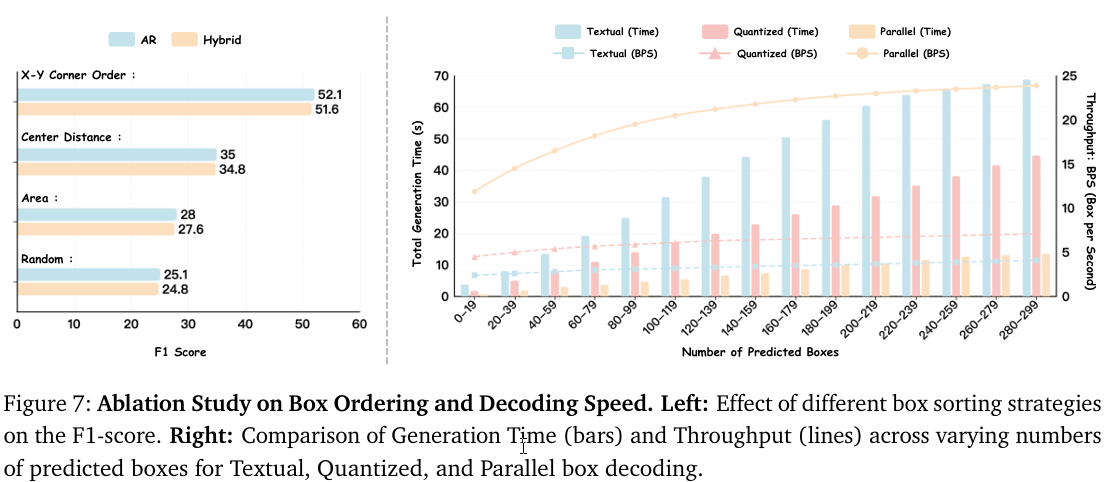
4.3. 消融研究
我们在COCO数据集上进行消融研究以验证我们的核心设计。结果见表6和图7。
坐标表示。 如表6(a)所示,在NTP范式下,文本和量化表示由于强制逐令牌生成而产生次优性能(平均F1分别为49.1和50.1)。我们的PBD(慢速模式)达到了最高的52.1 F1分数,证明了框对齐形式化提供了比1D序列化更强的空间推理监督,且不牺牲吞吐量。
MTP形式化。 表6(b)将我们的框对齐MTP与现有的结构无关MTP形式化进行比较。像SDLM和块扩散等方法迫使模型学习虚假的、未对齐的跨边界模式,遭受较低的准确性和有限的加速(例如,SDLM-B6在5.5 BPS下达到46.1 F1分数)。此外,结构无关方法(例如,SDLM-B4, B6, B8)表现出严格的速度-精度权衡,增加块大小仅带来边际吞吐量增益,同时持续降低F1分数。相比之下,我们的PBD将MTP块与结构化边界框单元严格对齐,在吞吐量(16.9 BPS)上大幅超越现有方法,同时将平均F1提高到49.6。
解码模式。 表6©消融了双形式训练(Lntp\mathcal{L}_{\mathrm{ntp}}Lntp和Lblk\mathcal{L}_{\mathrm{blk}}Lblk)的影响。使用隔离损失训练限制了模型的潜力;联合训练成功地将慢速模式的上界从50.1提高到52.1 F1分数。在推理中,快速模式(MTP)最大化吞吐量(16.9 BPS),但在复杂场景中会导致精度下降。混合模式无缝解决了这一权衡,保留了大部分速度增益(13.2 BPS),同时实现了稳健的高精度定位(51.6 F1分数)。
框输出顺序。 我们在图7(左)中研究了四种空间排序策略:XYXYXY角点顺序(按左上角xxx坐标排序,再按yyy坐标)、中心距离(边界框中心点到原点的距离)、面积(从大到小排序)和随机(随机打乱)。结果表明,XYXYXY角点顺序产生最高的F1分数。我们在数据集构建中以此设置为默认值。
吞吐量。 我们在图7(右)中比较了生成时间和吞吐量与NTP方法。随着目标框数量从20增加到300,NTP方法遭受严重的延迟瓶颈。相比之下,并行方法的生成时间几乎没有增加,在密集场景中吞吐量从12 BPS增加到约25 BPS。这些发现证实了PBD有效地打破了解码瓶颈,实现了2×2\times2×到6×6\times6×的加速。
4.4. 定性结果
图8可视化了我们模型的代表性定位结果。与其他方法的视觉比较在补充材料中提供。我们观察到三个一致的行为。(i) 组合定位:我们的模型很好地处理了属性/部分/空间/推理类型的查询,并保持空间对齐,这得益于我们训练数据的多样性和覆盖范围。(ii) 对大量实例的鲁棒性:随着目标从稀疏到拥挤,预测框保持结构化和准确,反映了我们框级解码的精度。这种鲁棒性通过我们第二阶段的训练(强调多物体图像)进一步增强,改善了实际中的密集定位。此外,我们的混合模式在多实例生成中保持大部分并行解码速度,同时提高输出稳定性。(iii) 杂乱环境中的可靠定位:在遮挡、重复纹理和网格状密集布局下,框保持紧凑且良好分离。我们的混合推理模式通过检测不可靠的并行块并在需要时回退到NTP重解码,进一步稳定了这些困难案例。

5. 结论
我们提出了LocateAnything,一个通过并行框解码重新定义VLM中视觉定位与检测的统一框架。通过将几何元素提升为原子单元而非1D流,LocateAnything使训练监督与空间坐标固有的耦合性质对齐。借助1.38亿大规模文本-图像训练查询和灵活的按需推理机制,LocateAnything不仅在各种任务上提供了SOTA精度,而且实现了比竞争方法高达2.5×2.5\times2.5×的加速。我们的方法为实时视觉感知提供了一条实用且可扩展的路径,为在延迟敏感的具身机器人和交互式代理中部署通用VLM打开了大门。
局限性。 目前,我们的模型主要使用监督微调进行训练。强化学习是一个重要的下一步,以进一步优化块级解码策略,减少回退频率,并鼓励在困难的密集/长尾案例中进行有效探索,这可以提高鲁棒性和最坏情况下的解码速度。我们将其留给未来的工作。
致谢。 作者感谢[…]的宝贵讨论和输入。
以下是论文附录部分的完整中文翻译。内容从原文第14页开始,包括训练配置、数据构建细节、附加实验和定性比较等。
A. 训练与推理配置
A.1. 训练细节
在本节中,我们提供关于数据混合策略、基础VLM和LocateAnything模型的多阶段训练管道的扩展细节。我们还将阐述两个关键的系统级技术,这些技术对于我们双形式设计下的高效训练至关重要:用于最大化GPU利用率的流打包(Stream Packing),以及用于原生支持NTP+MTP联合训练所需异构注意力掩码的MagiAttention(Zewei and Yunpeng,2025)。
为了全面概述我们的整个训练管道,表7总结了LocateAnything所有四个渐进阶段的详细优化超参数和配置。
表7:LocateAnything每个训练阶段的详细配置。
| 阶段 | 阶段1 | 阶段2 | 阶段3 | 阶段4 |
|---|---|---|---|---|
| 目标 | 世界知识注入 | 世界知识注入 | 检测与定位增强 | 检测与定位增强 |
| 数据集 | 图像描述 | 通用VQA | 检测与定位 | 20% 先前数据 + 密集数据 |
| 学习率 | 2×10−42 \times 10^{-4}2×10−4 | 4×10−54 \times 10^{-5}4×10−5 | 4×10−54 \times 10^{-5}4×10−5 | 1×10−51 \times 10^{-5}1×10−5 |
| 优化器 | AdamW | AdamW | AdamW | AdamW |
| 权重衰减 | 0.01 | 0.01 | 0.01 | 0.01 |
| 学习率调度 | 余弦 | 余弦 | 余弦 | 余弦 |
| 最大序列长度 | 32768 | 32768 | 25600 | 25600 |
| 可训练组件 | MLP | 全部 | 全部 | 全部 |
| GPU数量 | 64 | 256 | 256 | 256 |
| 训练步数 | 2000 | 20000 | 25000 | 5000 |
A.1.1. 基础VLM训练(世界知识注入)
在引入专门的检测和定位任务之前,为了建立对世界知识的稳健基础理解,我们首先预训练我们的基础VLM。这个初始对齐阶段严格排除了任何检测或边界框定位数据,并分为两个渐进阶段。
(1) 阶段1(视觉概念初始化):在此阶段,模型仅在图像描述相关数据集上训练,详见表8的“图像描述与知识”类别。这使得原生任意分辨率视觉编码器能够有效地将基础视觉特征与文本描述对齐。
(2) 阶段2(综合多模态学习):在基本图像描述能力的基础上,我们将训练语料扩展到涵盖表8中列出的所有数据集。这个综合混合跨度广泛的领域,包括数学与代码、科学、图表与表格推理、广泛的OCR任务(朴素OCR和OCR问答)、通用VQA、纯文本指令调优以及基础计数。完全整合这些多样化的数据集确保了基础模型发展出强大的推理能力和全面的多模态能力。
表8:用于初始世界知识对齐的数据集。我们在跨多个领域的多样化混合数据集上预训练基础VLM,以确保广泛覆盖通用知识。具体来说,阶段1仅纳入此处显示的图像描述相关数据集。在阶段2,此表中列出的所有数据集都被完全集成到训练过程中,以构建稳健、全面的多模态能力。
| 类别 | 数据集 |
|---|---|
| 图像描述与知识 | ShareGPT4o OpenGvLab (2024), KVQA Shah et al. (2019), Movie-Posters skvarre (2024), Google-Landmark Weyand et al. (2020), WikiArt HugGAN (2024), Weather-QA Ma et al. (2024a), Coco-Colors hazal karakus (2024), music-sheet EmileEsmaili (2024), SPARK Yu et al. (2024b), Image-Textualization Pi et al. (2024), SAM-Caption PixArt-alpha (2024), Tmdb-Celeb-10k Ashraq (2024), CC3M Sharma et al. (2018), pixmo-cap Deitke et al. (2025), Multi-UI Liu et al. (2024b), RICO Deka et al. (2017) |
| 数学与代码 | GeoQA+ Cao and Xiao (2022), MathQA Yu et al. (2023a), CLEVR-Math/Super Li et al. (2023b); Lindstrom and Abraham (2022), Geometry3K Lu et al. (2021a), MAVIS-math-rule-geo Zhang et al. (2024d), MAVIS-math-metagen Zhang et al. (2024d), InterGPS Lu et al. (2021a), Raven Zhang et al. (2019a), GEOS Seo et al. (2015), UniGeo Chen et al. (2022a), Design2Code Si et al. (2025), OpenMathInstruct Toshniwal et al. (2024) |
| 科学 | AI2D Kembhavi et al. (2016), ScienceQA Lu et al. (2022a), TQA Kembhavi et al. (2017), PathVQA He et al. (2020), SciQA Auer et al. (2023), Textbooks-QA, VQA-RAD Lau et al. (2018), VisualWebInstruct TIGER-Lab (2024), PMC-VQA Zhang et al. (2023a) |
| 图表与表格 | ChartQA Masry et al. (2022), MMC-Inst Liu et al. (2023b), DVQA Kafle et al. (2018), PlotQA Methani et al. (2020), LRV-Instructio Liu et al. (2023a), TabMWP Lu et al. (2022b), UniChart Masry et al. (2023), Vistext Tang et al. (2023), TAT-DQA Zhu et al. (2022), VQAonBD, FigureQA Kahou et al. (2017), Chart2Text Kantharaj et al. (2022), RobuT (Wikisql, SQA, WTQ) Zhao et al. (2023), MultiHiertt Zhao et al. (2022), MMTab Zheng et al. (2024a) |
| 朴素OCR | SynthDoG Kim et al. (2022), MTWI He et al. (2018), LVST Sun et al. (2019), SROIE Huang et al. (2019), FUNSD Jaume et al. (2019), Latex-Formula OleehyO (2024), IAM Marti and Bunke (2002), Handwriting-Latex aidapearson (2023), Art Chng et al. (2019), CTW Yuan et al. (2019), ReCTs Zhang et al. (2019b), COCO-Text Veit et al. (2016), SVRD Yu et al. (2023b), Hiertext Long et al. (2023), RoadText Tom et al. (2023), MapText Li et al. (2024b), CAPTCHA parasam (2024), Est-VQA Wang et al. (2020), HME-100K TAL (2023), TAL-OCR-ENG TAL (2023), TAL-HW-MATH TAL (2023), IMGURSK Krishnan et al. (2023), ORAND-CAR Diem et al. (2014), Invoices-and-Receipts-OCR mychen76 (2024), Chrome-Writing Mouchère et al. (2016), IIIT5k Mishra et al. (2012), K12-Printing TAL (2023), Memotion Ramamoorthy et al. (2022), Arxiv2Markdown, Handwritten-Mathematical-Expression Azu (2023), WordArt Xie et al. (2022), RenderedText wendler (2024), Handwriting-Forms if (2024) |
| OCR问答 | DocVQA Clark and Gardner (2018), InfoVQA Mathew et al. (2022), TextVQA Singh et al. (2019), ArxivQA Li et al. (2024a), ScreenCQA Hsiao et al. (2022), DocReason mPLUG (2024), Ureader Ye et al. (2023), FinanceQA Sujet Al et al. (2024), DocMatrix Laurencon et al. (2024a), A-OKVQA Schwenk et al. (2022), Diagram-Image-To-Text Kamizuru00 (2024), MapQA Chang et al. (2022), OCRVQA Mishra et al. (2019), ST-VQA Biten et al. (2019), SlideVQA Tanaka et al. (2023), PDF-VQA Ding et al. (2023), SQuAD-VQA, VQA-CD Mahamoud et al. (2024), Block-Diagram shreyanshu09 (2024), MTVQA Tang et al. (2024), ColPali Faysse et al. (2024), BenthamQA Mathew et al. (2021), VSR Zhang et al. (2021), pixmo-docs Deitke et al. (2025) |
| 通用VQA | LLaVA-150K Liu et al. (2023c), LVIS-Instruct4V Wang et al. (2023a), ALLaVA Chen et al. (2024a), Laion-GPT4V LAION (2023), LLAVAR Zhang et al. (2023b), SketchyVQA Tu et al. (2023), VizWiz Gurari et al. (2018), IDK Cha et al. (2024), AlfworldGPT, LNQA Pont-Tuset et al. (2020), Face-Emotion FastJobs (2024), SpatialSense Yang et al. (2019), Indoor-QA kermberke (2024), Places365 Zhou et al. (2017), MMInstruct Liu et al. (2024c), DriveLM Sima et al. (2023), YesBut Nandy et al. (2024), WildVision Lu et al. (2024), LLaVA-Critic-113k Xiong et al. (2024), PhyCritic Xiong et al. (2026), RLAIF-V Yu et al. (2024a), VQAv2 Goyal et al. (2017), MMRA Wu et al. (2024a), KONIQ Hosu et al. (2020), MMDU Liu et al. (2024d), Spot-The-Diff Jhamtani and Berg-Kirkpatrick (2018), Hateful-Memes Kiela et al. (2020), COCO-QA Ren et al. (2015), NLVR Suhr et al. (2017), Mimic-CGD Laurencon et al. (2024b), Datikz Belouadi et al. (2023), Chinese-Meme Contributors (2024), IconQA Lu et al. (2021b), Websight Laurencon et al. (2024c), OmniAlign Zhao et al. (2025), pixmo-cap-qa Deitke et al. (2025), pixmo-ask-model-anything Deitke et al. (2025), Cauldron Laurencon et al. (2024b) |
| 纯文本 | Orca Lian et al. (2023), Orca-Math Mitra et al. (2024), OpenCodeInterpreter Zheng et al. (2024b), MathInstruct Yue et al. (2023), WizardLM Xu et al. (2023), TheoremQA Chen et al. (2023b), OpenHermes2.5 Teknium (2023), NuminaMath-CoT Li et al. (2024), Python-Code-25k fyttech (2024), Infinity-Instruct BAAI (2024), Python-Code-Instructions-18k-Alpaca iamtaran (2024), Ruozhiba LooksJuicy (2024), InfinityMATH Zhang et al. (2024a), StepDPO Lai et al. (2024b), TableLLM Zhang et al. (2024e), UltraInteract-sft Yuan et al. (2024) |
| 计数 | FSC147 Ranjan et al. (2021), TallyQA Acharya et al. (2019) |
A.1.2. LocateAnything微调(检测与定位增强)
在完成初始世界知识对齐之后,我们使用精心设计的两阶段SFT策略来训练LocateAnything模型,该策略针对细粒度检测和定位进行了定制。这构成了我们管道的最后两个阶段(利用正文图5中呈现的数据)。
(1) 阶段3(综合检测与定位):我们将包含1.38亿个查询的大规模混合数据纳入整体训练数据,使模型具备全面的定位和检测能力。在此阶段,所有模型组件都被完全解冻并训练。我们将最大序列长度设置为25,600,并采用学习率为4×10−54 \times 10^{-5}4×10−5的余弦调度。
(2) 阶段4(密集检测增强):为了进一步提高模型在密集场景中的召回率,我们将通用训练数据的比例降低到20%20\%20%,同时显著增加每张图像包含许多物体的数据比例(例如,MOT20Det,SKU110K)。所有组件保持可训练,最大序列长度保持在25,600。学习率衰减到1×10−51 \times 10^{-5}1×10−5。
A.1.3. 流打包(Stream Packing)
我们双形式(NTP + MTP)设计训练的一个关键挑战是,不同样本在经过块级扩展后表现出高度可变的序列长度。基于填充的朴素批处理会导致显著的GPU内存浪费和低算术利用率。为了解决这个问题,我们采用了一种在线流打包策略,该策略动态地将多个可变长度样本组装成一个密集打包的序列,达到目标预算(例如,36,864个令牌)。具体来说,我们的打包管道通过三个核心机制运作。
- 加权采样:一个无限迭代器根据预先指定的混合权重从多个异构数据集中抽取样本。
- 最佳拟合缓冲:一个固定大小的缓冲区(默认大小32)存储待处理的样本。当组装一个批次时,打包器首先扫描缓冲区,寻找仍适合剩余令牌预算的最大样本——这是一种最佳拟合递减启发式方法,经验上产生>95%>95\%>95%的打包效率。如果没有缓冲样本适合,则新抽取的样本要么直接追加(如果适合),要么放入缓冲区以备将来使用。
- 大石块优先播种:在产出完成的批次后,打包器用当前缓冲区中最大的样本播种下一个批次,确保过大的样本永远不会被饿死。
每个打包后的序列携带一个sub_sample_lengths张量,记录组成样本的边界。此元数据在下游被注意力内核消耗,以在打包序列内为每个样本构建正确的注意力掩码,防止不相关样本之间的交叉污染。
A.1.4. 用于异构掩码训练的MagiAttention
我们的双形式训练产生了一个异构的注意力掩码,它结合了标准因果注意力(用于NTP流)与块因果和块内双向模式(用于MTP流),所有这些都在一个可能包含多个样本的打包序列内。当进一步与流打包结合时,生成的注意力掩码变得高度不规则且依赖于样本,使其与假定统一因果或全注意力模式的传统Flash-Attention内核不兼容。
为了高效处理这个问题,我们利用MagiAttention(Zewei and Yunpeng,2025),一个专为具有异构掩码的超长上下文设计的分布式注意力框架。流打包和MagiAttention共同构成了一个协同训练基础设施:打包最大化每个GPU内的令牌级利用率,而MagiAttention确保生成的异构注意力掩码在分布式训练集群上被正确且高效地处理。
A.2. 推理细节
我们提供推理管道的详细描述,包括生成模式、半自回归生成循环、框感知解码策略以及所有评估中使用的超参数配置。
A.2.1. 生成超参数
我们采用核采样(nucleus sampling),温度为0.7,top-ppp为0.9,以平衡多样性和精度。应用1.1的重复惩罚以抑制重复预测。整个推理过程中启用KV缓存以避免冗余计算。MTP生成的块大小设置为6(即nfuture=6n_{\mathrm{future}} = 6nfuture=6),意味着每个并行解码步骤同时预测最多6个令牌。新生成令牌的最大数量设置为8,192。所有模型均以BF16精度和批大小1进行评估。
A.2.2. KV缓存管理
在每个MTP步骤之后,KV缓存被截断以仅包含与实际提交令牌相对应的位置(即直到当前生成前沿的前缀)。掩码令牌和重复的锚点令牌被驱逐,确保后续步骤仅关注真实生成历史。这种截断对于保持训练期间看到的因果前缀与推理期间的KV缓存状态之间的一致性至关重要。
B. LocateAnything-Data构建
B.1. 利用现有开源数据
我们首先从开源社区收集高质量的检测和定位数据集,并进行统一的格式清洗和归一化。如正文图6所示,收集的数据涵盖六个领域,覆盖多样化的视觉场景。
除GroundCUA(Feizi等人,2025)外,我们对所有其他GUI数据集使用原始标签。然而,GroundCUA数据集需要额外处理,因为其原始标签通常仅对应UI元素的简短描述。为了丰富这个特定数据集的定位查询,我们使用Qwen3-VL(Bai等人,2025a)对GroundCUA的标注进行增强。具体来说,给定原始边界框、标签和类别,我们首先在截图上渲染目标边界框,并围绕它裁剪一个局部区域。然后将完整的截图、裁剪后的区域以及标签、类别和平台元数据提供给Qwen3-VL(Bai等人,2025a)。在确定目标元素在视觉上是否可识别后,模型从三个互补的角度生成自然语言描述:外观(描述颜色、形状、图标或文本内容等视觉属性)、空间(描述元素相对于其他UI组件的相对位置)和功能(描述与元素相关的用户意图或交互语义)。通过这个过程,GroundCUA的原始离散文本标签被转换为更丰富、多维的定位查询,既具有描述性又具有可解释性。
指代和定位数据集本身的规模相对有限。为了解决这个问题,我们聚合了几个广泛使用的基准,包括Flickr30k Entities(Plummer等人,2016)、gRefCOCO(He等人,2023)、RefCOCO(Yu等人,2016)、HumanPart(Yu等人,2016)和HumanRef(Jiang等人,2025a)。此外,我们纳入了大规模检测数据集,如OpenImages(Kuznetsova等人,2020)、Objects365(Shao等人,2019)以及从Unsplash收集的图像。这些数据集作为构建我们多目标定位数据引擎的原始来源,如B.2节所述。
现有检测和定位数据集中的另一个关键问题是它们几乎只包含正样本。在此类数据上训练可能导致幻觉行为,即即使查询与图像无关,模型也会预测边界框。为了缓解这个问题,我们显式地在各个领域构建负样本。负查询的比例因领域统计数据而异(见表10)。具体来说,我们生成引用图像中不存在的对象的查询,并为它们分配正文图3中描述的负块。这种设计使模型能够学习在没有有效定位目标时放弃预测。
B.2. 多目标定位数据引擎
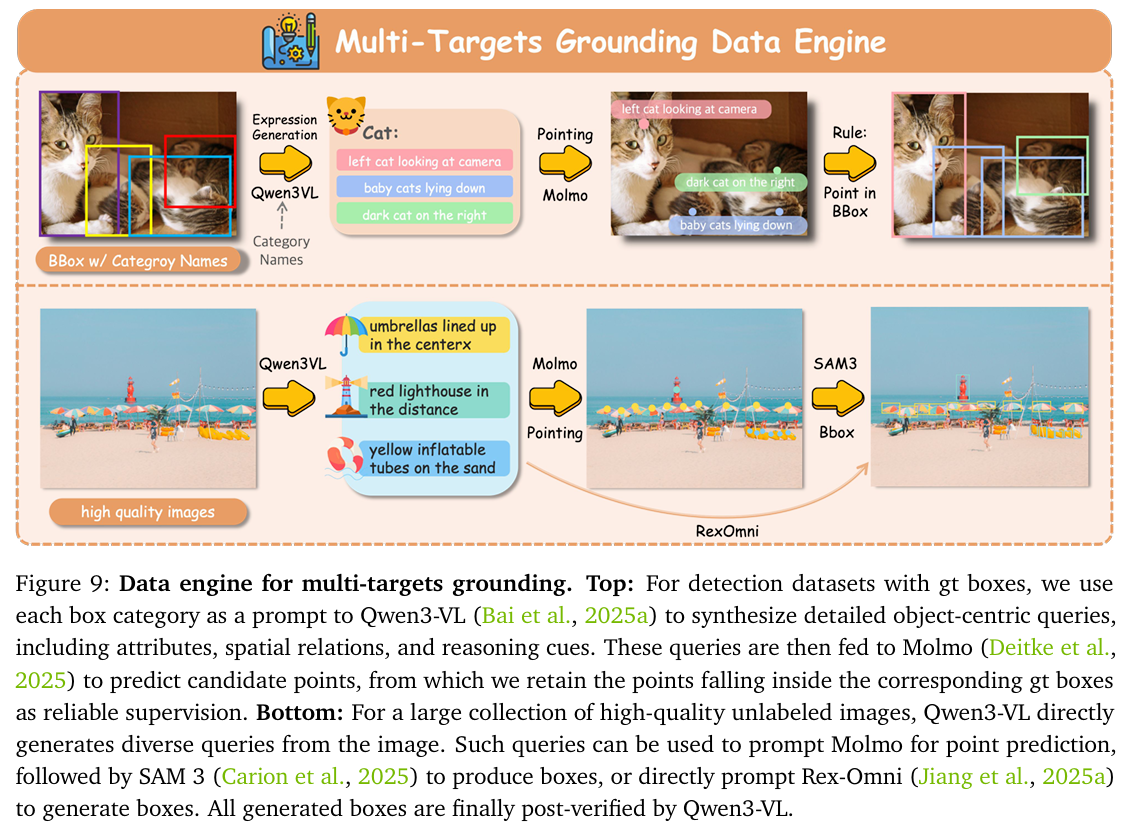
现有的开源定位数据集在规模和多样性上相对有限。为了构建大规模的多目标定位数据集,我们设计了一个数据引擎,可以从带标签的检测数据和无标签图像中自动合成定位注释,如图9所示。
从检测数据集生成: 我们首先利用高质量的检测数据集,如Open Images(Kuznetsova等人,2020)和Objects365(Shao等人,2019)。对于每个真实边界框,我们使用其类别标签作为提示,提示Qwen3-VL(Bai等人,2025a)生成一组详细的以物体为中心的查询,包括属性、空间关系和推理线索。然后使用这些查询提示Molmo(Deitke等人,2025)预测候选点。由于真实框已知,我们只保留落在对应边界框内的点,这些点作为可靠的定位监督。
从无标签图像生成: 为了进一步扩展定位目标的多样性,我们还从Unsplash和SA-1B(Kirillov等人,2023)收集了大量高质量的无标签图像。对于每张图像,Qwen3-VL直接生成一组多样化的自然语言查询,描述潜在的物体或区域。这些查询可用于提示Molmo(Deitke等人,2025)预测点,随后使用SAM 3(Carion等人,2025)将点转换为边界框。或者,查询可以直接提示Rex-Omni(Jiang等人,2025a)预测边界框。
为了确保注释质量,所有生成的框最后都通过Qwen3-VL(Bai等人,2025a)的后检查阶段进行验证,过滤掉不一致的预测。
B.3. 任务特定提示设计
如表9所示,我们全面概述了统一框架支持的多样化感知任务,以及它们对应的输出格式和问题模板。为了无缝集成多样化的视觉定位和检测能力,我们为每个任务设计了特定的文本提示。模型处理输出边界框的广泛基于区域的任务,包括物体检测、文本定位、场景文本检测和文档布局分析。此外,它还支持细粒度定位任务,如输出特定坐标点的指向任务。对于短语定位和GUI定位等服务和交互式任务,框架根据用户意图灵活预测单个/多个框或点。在提示模板中,[PHRASE]表示自由形式的自然语言描述,而[CATEGORIES]表示以逗号分隔的目标类别名称列表。这种统一的提示策略使模型能够有效地桥接自然语言指令和精确的空间坐标解码。
表9:支持的感知任务及其对应提示模板概览。[PHRASE]表示自由形式的自然语言描述,[CATEGORIES]表示以逗号分隔的类别名称列表。
| 任务 | 输出 | 问题模板 |
|---|---|---|
| 物体检测 | 框 | 定位所有与以下描述匹配的实例:[CATEGORIES]。 |
| 短语定位(单个框) | 框 | 定位与以下描述匹配的单个实例:[PHRASE]。 |
| 短语定位(多个框) | 框 | 定位与以下描述匹配的所有实例:[PHRASE]。 |
| 文本定位 | 框 | 请定位被引用为 [PHRASE] 的文本。 |
| 场景文本检测 | 框 | 检测图像中所有框格式的文本。 |
| 文档布局分析 | 框 | 检测图像中属于类别集的所有对象:[CATEGORIES]。 |
| GUI定位(框) | 框 | 定位与以下描述匹配的区域:[PHRASE]。 |
| GUI定位(点) | 点 | 指向:[PHRASE]。 |
| 指向 | 点 | 指向:[PHRASE]。 |
B.4. 数据统计与分布
我们分析了收集数据集的统计特征。表10总结了六个领域的数据集统计。总的来说,该数据集包含超过1.39亿个查询,其中超过2200万个负样本。
我们的数据集还表现出强大的多目标定位特征。与每个查询相关的目标数量在不同领域差异很大。如图10所示,每个查询的目标数量分布遵循长尾模式:大多数查询对应少量目标,而不可忽略的一部分涉及大量实例。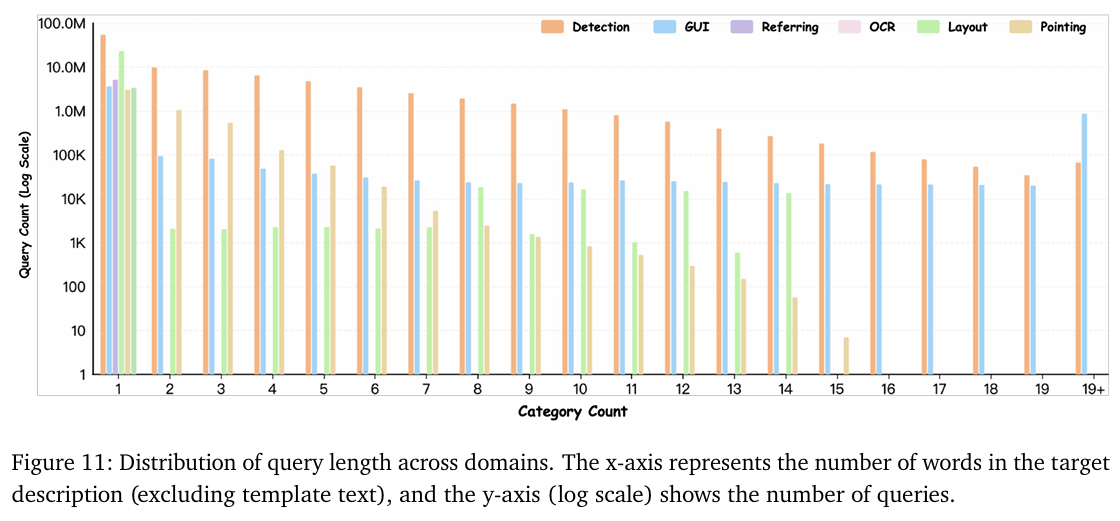
我们进一步分析了查询的语言特性。如图11所示,查询长度在不同领域有所变化,反映了用于描述视觉目标的不同定位范式和语言模式。
总体而言,这些统计突显了我们数据集的规模、多样性和多目标性质,它们共同为训练能够处理异构视觉领域和复杂语言查询的模型提供了坚实的基础。
表10:跨六个领域收集数据的统计。我们报告了查询总数和负样本数,以及每个查询的最大和平均目标数(/ Q)、每个查询的最大和平均类别数(/ Q),以及每张图像的平均目标数(/ I)。查询长度衡量去除模板文本后目标描述中的单词数,反映了用于描述定位目标的实际语言内容。
| 领域 | #查询 | #负样本 | 目标数/Q (最大) | 目标数/Q (平均) | 类别数/Q (最大) | 类别数/Q (平均) | 查询长度 (最大) | 查询长度 (平均) | 目标数/I (平均) |
|---|---|---|---|---|---|---|---|---|---|
| 检测 | 93,351,373 | 21,021,509 | 745 | 6.29 | 432 | 2.47 | 512 | 4.19 | 3,725 |
| GUI | 23,009,535 | 0 | 14 | 1.03 | 14 | 1.03 | 351 | 4.07 | 8,690 |
| 指代 | 10,141,597 | 93,396 | 81 | 2.12 | 10.8 | 0.95 | 354 | 5.48 | 6,938 |
| OCR | 5,052,040 | 0 | 2,337 | 11.89 | 1,258 | 10.45 | 11.17 | - | 2,337 |
| 布局 | 4,859,914 | 1,384,804 | 176 | 4.92 | 151 | 1.31 | 302 | 2.28 | 802 |
| 指向 | 3,148,098 | 353,366 | 675 | 3.25 | 10.8 | 0.89 | 189 | 2.63 | 1,575 |
C. 附加实验
C.1. 指向任务结果
为了进一步评估我们模型的细粒度空间感知能力,我们在基于点的定位任务上对LocateAnything-3B进行基准测试,其中模型必须预测落在目标边界框或分割掩码内的点。如表11详述,LocateAnything-3B(在混合模式下评估)在多样化的基准套件上取得了最先进的结果。
它显著优于当代视觉语言模型,包括更大的网络如OVIS2.5-9B和以点为中心的专家如Rex-Omni-3B。值得注意的是,我们的模型在COCO上得分为83.9 F1@Point,在高度密集环境Dense200上表现出色,达到87.6 F1@Point。此外,它在将复杂的人类意图与空间区域对齐方面表现卓越,在HumanRef上达到84.7 F1@Point,在RefCOCOg测试集上达到91.0 F1@Point。这些结果强调了我们的框对齐训练范式和LocateAnything-Data的大规模在建立精确几何对齐方面的有效性,并无缝扩展到基于点的生成。
表11:在多样化基准(COCO, LVIS, Dense200, VisDrone, RefCOCOg, HumanRef)上的物体指向任务性能评估。F1分数用作主要指标。此处报告混合模式的结果。
| 方法 | COCO F1@Point | LVIS F1@Point | Dense200 F1@Point | VisDrone F1@Point | HumanRef F1@Point | RefCOCOg val F1@Point | RefCOCOg test F1@Point |
|---|---|---|---|---|---|---|---|
| OVIS2.5-2B | 73.4 | 52.8 | 36.4 | 23.8 | 72.5 | 83.1 | 83.1 |
| Qwen2.5-VL-3B | 65.9 | 48.3 | 4.3 | 13.9 | 64.1 | 77.4 | 77.8 |
| Qwen2.5-VL-7B | 61.1 | 56.5 | 2.0 | 14.2 | 65.1 | 78.9 | 79.4 |
| OVIS2.5-9B | 72.6 | 61.7 | 35.0 | 18.8 | 62.3 | 85.0 | 84.5 |
| Molmo-7B-D | 77.3 | 40.3 | 33.1 | 29.2 | 70.0 | 83.7 | 83.6 |
| SEED1.5-VL | 78.2 | 70.7 | 72.1 | 56.7 | 83.1 | 83.6 | 84.2 |
| Rex-Omni-SFT-3B | 76.0 | 66.7 | 72.9 | 49.5 | 82.1 | 83.3 | 83.9 |
| Rex-Omni-3B | 80.5 | 70.8 | 82.5 | 58.9 | 83.8 | 84.7 | 85.1 |
| LocateAnything-3B | 83.9 | 76.6 | 87.6 | 60.4 | 84.7 | 91.3 | 91.0 |
C.2. 解码模式的综合性能
在本节中,我们详细介绍了LocateAnything在其三种按需解码模式下的性能:快速、混合和慢速。这些模式允许在几何精度和推理延迟之间进行动态权衡,如表12所总结。
表12:我们的快速、混合和慢速配置在多个视觉任务上的综合性能。吞吐量(以每秒框数BPS测量)在每个模式的标题中报告。对于通用检测(COCO, LVIS),我们报告平均精度(AP)、平均召回率(AR)和F1@mIoU。对于其他任务,我们报告主要的综合指标(例如,F1@mIoU,平均准确率)。
| 任务组 | 数据集 | 指标 | 快速模型 (15.3 BPS) | 混合模型 (12.7 BPS) | 慢速模型 (4.3 BPS) |
|---|---|---|---|---|---|
| 检测 | COCO | P@mIoU | 58.9 | 60.8 | 60.8 |
| R@mIoU | 46.8 | 49.7 | 50.3 | ||
| F1@mIoU | 52.2 | 54.7 | 55.1 | ||
| LVIS | P@mIoU | 64.3 | 68.4 | 68.0 | |
| R@mIoU | 37.1 | 40.3 | 42.8 | ||
| F1@mIoU | 47.0 | 50.7 | 52.6 | ||
| Dense200 | F1@mIoU | 46.8 | 61.3 | 61.5 | |
| VisDrone | F1@mIoU | 34.4 | 39.8 | 40.2 | |
| OCR | HierText | F1@mIoU | 28.8 | 29.1 | 43.2 |
| ICDAR2015 | F1@mIoU | 26.6 | 26.4 | 27.3 | |
| TotalText | F1@mIoU | 44.4 | 44.6 | 47.5 | |
| SROIE | F1@mIoU | 38.8 | 39.3 | 64.4 | |
| 布局 | DocLayNet | F1@mIoU | 67.2 | 77.7 | 80.4 |
| M6Doc | F1@mIoU | 64.1 | 70.5 | 69.7 | |
| GUI | ScreenSpot-Pro | 平均准确率 | 59.7 | 60.3 | 60.5 |
| 指代 | HumanRef | F1@mIoU | 66.8 | 78.5 | 79.1 |
| RefCOCOg val | F1@mIoU | 70.8 | 73.4 | 72.4 | |
| RefCOCOg test | F1@mIoU | 72.5 | 74.8 | 73.8 | |
| 指向 | COCO | F1@Point | 83.1 | 83.9 | 84.8 |
| LVIS | F1@Point | 74.4 | 76.6 | 76.9 | |
| Dense200 | F1@Point | 89.4 | 87.6 | 88.3 | |
| VisDrone | F1@Point | 58.1 | 60.4 | 61.3 |
C.3. 骨干泛化性
为了检验并行框解码(PBD)是否依赖于特定的视觉语言骨干,我们在Qwen3-VL-4B(Bai等人,2025a)上实例化了相同的解码设计。遵循正文消融研究中使用的受控设置,此变体仅在COCO上训练,从而隔离解码形式化与大规模数据扩展的影响。
如表13所示,PBD在Qwen3-VL-4B上持续改善了速度-精度权衡。混合配置将COCO F1从50.8提高到52.0,同时将吞吐量从2.8 BPS提高到9.4 BPS。这些结果表明,框对齐并行解码的优势并不依赖于特定的骨干架构。
表13:骨干泛化性。
| 骨干 | 解码 | F1 | BPS |
|---|---|---|---|
| Qwen3-VL-4B | NTP(基线) | 50.8 | 2.8 |
| Qwen3-VL-4B + PBD(慢速) | PBD | 52.2 | 2.8 |
| Qwen3-VL-4B + PBD(快速) | PBD | 49.6 | 11.4 |
| Qwen3-VL-4B + PBD(混合) | PBD | 52.0 | 9.4 |
C.4. 模式分析与吞吐量
我们的按需解码模式允许在几何精度和推理延迟之间进行动态权衡。
- 慢速模式(下一个令牌预测):使用标准自回归生成,此模式始终为定位精度建立上界(例如,在COCO上峰值F1@mIoU为55.1,在DocLayNet上为79.8)。通过顺序处理令牌,它保持优越的空间意识和对密集物体簇的稳健处理。
- 快速模式(多令牌预测):此模式通过并行预测完整几何元素,将推理吞吐量最大化至15.3 BPS。虽然它在复杂或高度密集的场景中会导致轻微的精度下降,但其高速输出使其成为实时应用的理想选择。
- 混合模式(自适应解码):作为生产管道的最优选择,此模式默认使用并行解码,并仅在检测到空间模糊性或格式不规则时选择性地回退到自回归生成。它以高度竞争力的12.7 BPS运行,保留了并行化的速度优势,同时保持精确的输出。
C.5. 实验设置
为确保透明度和可重复性,所有性能指标均在特定配置下报告。
- 吞吐量基准测试:所有值均以每秒框数(BPS)测量,具体在COCO数据集上评估,以提供速度比较的一致基线。
- 输入分辨率:对于COCO和LVIS基准测试,图像被调整为短边为840像素。对于所有其他基准测试,模型使用源数据的原始分辨率进行评估。
D. 定性比较
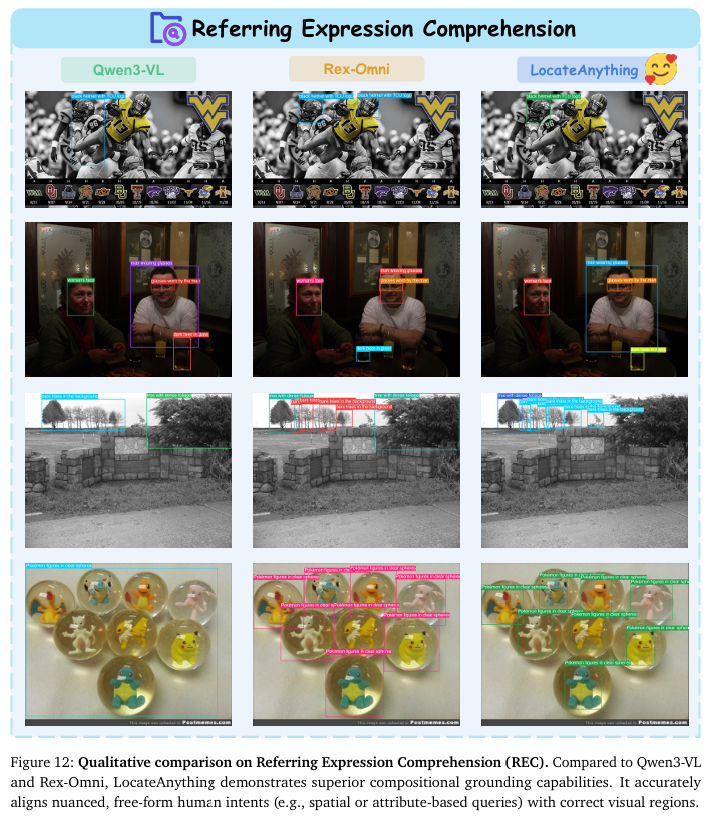
附录

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 4
4 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)