手机里的计算摄影--景深虚化算法
手机里的计算摄影–景深虚化算法
玩过摄影的同学都知道,光圈越大,景深越浅,焦距越长,景深越浅;所谓 景深:指相机拍摄时,在画面中能形成清晰成像的空间距离范围。在这个范围内的物体成像锐利,超出范围的前景与背景则会呈现不同程度的模糊。在单反摄影时代,因为单反的镜头可以做得很大,所以景深由镜头光学性质本身就能决定,但是在手机摄影时代,手机的光圈无法做得很大,而且焦距一般也较小,所以很难直接依赖镜头的光学特性来实现景深虚化。
不过随着深度学习的发展,这个特性其实也越来越可以用算法实现了。2018 年 TOG 的经典工作 DeepLens,第一次用纯单张图像 + 端到端神经网络,实现了可自由调焦、可控光圈、高清无伪影的计算摄影虚化效果,为后来手机 AI 摄影奠定了重要思路。这篇文章就带你读懂:单张照片如何 “凭空” 算出单反级虚化。

摘要
本文研究者们旨在从单张全对焦图像生成高分辨率浅景深(DoF)图像,并支持对焦距离与光圈大小的可控调节。为此,本文提出一种新颖的神经网络模型,由深度预测模块、镜头模糊模块与引导上采样模块组成。所有模块均可微分,并从数据中学习得到。
为训练深度预测模块,本文作者采集了一个包含2462张由手机双摄拍摄的RGB-D图像数据集,并借助现有分割数据集提升边缘预测效果。本文进一步利用带真实深度信息的合成数据集监督镜头模糊模块与引导上采样模块的训练。实验验证了本系统与训练策略的有效性。
本文方法能够生成高质量、高分辨率的浅景深图像,相比基线方法与现有单图浅景深合成方案,产生的伪影显著更少。与基于双摄深度相机的当前最优浅景深方案——iPhone人像模式相比,本文方法生成效果与之相当,同时支持更灵活地选择对焦点与光圈大小,且不受特定拍摄硬件的限制。

- 图 1 这里展示的每一幅高分辨率浅景深图像,均由神经网络系统对一张全对焦输入图像进行单次前向推理后合成生成。用户可通过调整对焦平面与光圈大小,对系统进行自由交互控制。
引言
浅景深(DoF)效果是摄影中常用的重要技术,它通过模糊画面其余区域,将观众的注意力引导至对焦主体上。这类图像通常需要使用昂贵的单反相机与大光圈镜头拍摄,普通摄影爱好者难以轻松获取。此外,图像拍摄完成后,很难再重新对焦到其他区域,也无法调整虚化程度。
本文研究者们提出训练一套神经网络系统,用于在普通相机或移动设备拍摄的全对焦照片上,合成浅景深效果。该网络由三个模块构成:用于单图像深度估计的深度预测模块、用于预测空间变化模糊核的镜头模糊模块,以及用于生成高分辨率浅景深图像的引导上采样模块。
整个网络是完全可微分的,因此可以进行端到端训练。然而,包含多样化场景与非静态内容的“全对焦–浅景深”图像对训练数据难以采集。一种可行方案是利用深度图,通过现有渲染方法生成真实场景的真实浅景深图像,但基于图像的渲染方法会产生各类伪影,导致真值数据存在缺陷。另一种方案是使用无伪影的合成数据,但难点在于让模型从合成数据泛化到真实图像。
基于以上分析,本文作者采用分段式训练策略:深度预测需要对场景的语义理解,因此在真实图像上训练以保证泛化能力;而基于预测深度渲染景深效果主要涉及底层操作,在真实数据与合成数据上具有一致性,因此镜头模糊模块与引导上采样模块在高质量合成图像上联合训练,以减轻伪影。
为训练深度预测模块,本文作者采集了包含2462张真实环境RGB‑D图像的新数据集,这些图像由手机双摄相机获取。相比现有RGB‑D数据集,该数据集内容更丰富,更贴近日常拍摄场景与常见摄影主体。本文研究者们还利用现有显著目标检测数据集,增加前景分割辅助任务以增强训练,提升物体边界处的预测质量,让深度预测模块在多样化内容与图像类型上具备更好的泛化性。
镜头模糊模块与引导上采样模块基于预测深度图生成高分辨率浅景深图像。为联合训练这两个模块,本文引入包含精确深度与遮挡信息的合成数据集,可用于渲染无伪影的浅景深监督信号。训练中还对已知深度进行随机扰动,使模型对不准确的深度图更鲁棒。推理时,引导上采样模块可循环使用,生成任意分辨率的高清结果(本文中最高达到2K)。
用户研究表明,本文方法的结果显著优于现有单图像方案,效果与需要双摄深度输入的iPhone人像模式相当。本文方法可适用于任意相机,支持用户以交互速度控制对焦点与虚化程度(2048分辨率约0.7秒),还可用于老照片、绘画等更通用的场景。
2 相关工作
深度重建是计算机视觉领域的经典问题,相关研究成果丰富。本文作者主要回顾基于学习的单目深度估计方法、与镜头模糊相关的深度研究,以及镜头模糊渲染、散焦估计领域的相关工作。
单目深度估计
卷积神经网络(CNN)已被证明能有效学习场景先验,用于单张图像深度预测,通常以深度相机输出作为监督信号进行训练。但深度相机在测量范围、图像质量、便携性与分辨率上存在局限,导致基于原始深度数据训练的模型往往只能在有限场景(如室内、街景、地标)下有效。
有研究使用光圈堆栈作为深度预测监督信号,在花卉与室内场景上效果较好,但仅依靠光圈监督会出现深度模糊问题,在多样化场景中效果不稳定。本文实验也表明,仅使用光圈监督无法生成高质量结果。
多图深度估计
利用多图间对应关系是获取深度信息的最常用方式,已有多项工作将其用于浅景深效果生成。例如,手机可通过对焦堆栈、双目相机、小基线连拍、视频多帧等方式计算深度,再结合对焦图像完成浅景深合成,均采用“先算深度、再做渲染”的两阶段流程。
与之不同,本文方法仅从单张图像计算深度,并引入可微分浅景深渲染器,让模型对深度估计误差具备鲁棒性。
镜头模糊效果
基于单张RGB‑D图像的镜头模糊方法无法生成完全精确结果,因为散焦模糊需要获取被遮挡区域的信息。现有近似方法可分为物体空间方法与图像空间方法:
- 物体空间方法:基于光线追踪与真实相机模型,渲染效果更真实,但耗时高,且需要难以获取的3D场景表示。
- 图像空间方法:直接在单张图像上操作,将浅景深渲染作为后处理步骤,效率更高,可转化为固定可微分层。但这类方法通常使用固定卷积核,在深度不连续处易出现亮度渗漏,对前景遮挡物处理不佳。
本文提出的镜头模糊模块受真实光学原理启发,能够生成更具挑战性的前景失焦等效果。
移动端浅景深(人像模式)
高端手机(如iPhone、Google Pixel 2)的人像模式可模拟浅景深,依赖多目、双像素或前景分割掩码获取深度,但用户无法自由调整对焦点与虚化强度。
相比之下,本文方法无需专用深度硬件,即可生成质量相当的结果,并支持交互式调整浅景深参数。
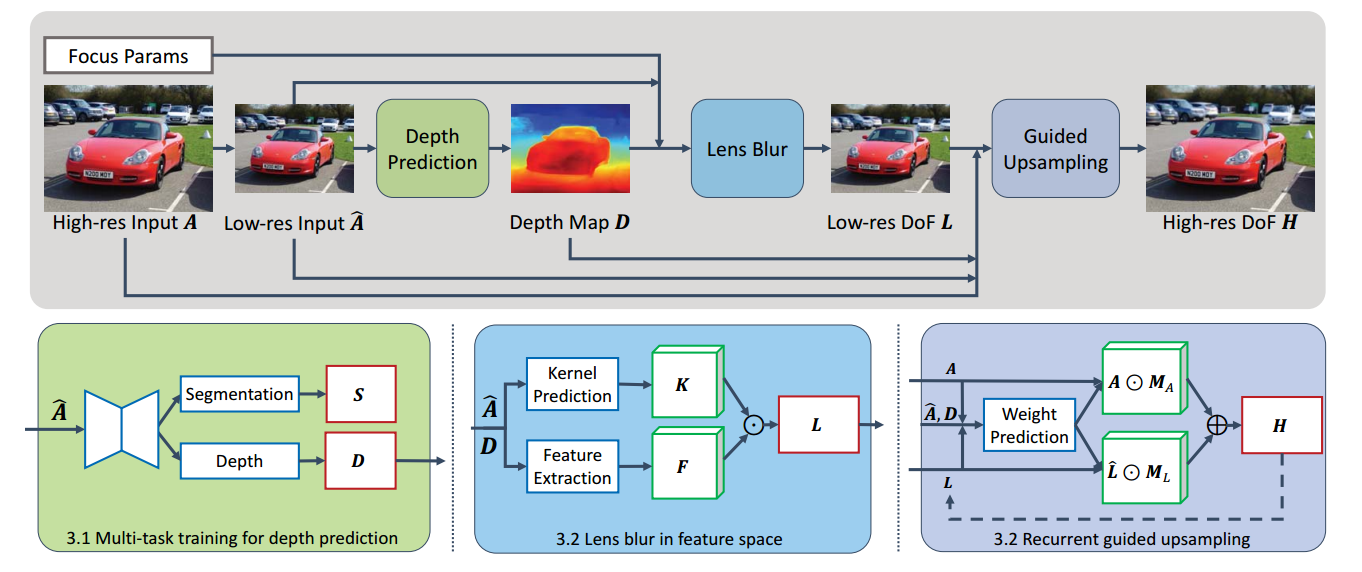
- 图 2 方法总览。从宏观流程(上部)来看,本文研究者们从全对焦输入图像A^\hat{A}A^中预测得到低分辨率深度图DDD。深度图DDD、全对焦图像A^\hat{A}A^与对焦参数一同用于生成低分辨率浅景深图像LLL,随后LLL被上采样为最终的高分辨率输出图像HHH。从细节流程(下部)来看,深度预测模块以A^\hat{A}A^为输入,联合预测带有监督信号的深度图DDD与分割图SSS。镜头模糊模块计算空间可变核KKK,并将其应用于降维后的特征图FFF以生成低分辨率浅景深图像LLL。引导上采样模块以2倍倍率循环对浅景深图像进行超分辨率处理,直至恢复至原始分辨率。红色块代表监督信号,蓝色块为可学习模块,绿色块为中间特征图。
3 方法(Method)
本文作者未采用端到端黑盒回归,而是遵循物理成像原理,设计由深度预测、镜头模糊、引导上采样三大可微模块组成的 pipeline,并采用真实数据+合成数据分段训练,这是本文最核心的创新。
系统流程:
- 从全对焦图像 A^\hat{A}A^ 预测低分辨率深度图 DDD
- 用 DDD、A^\hat{A}A^ 与对焦参数生成低分辨率浅景深图 LLL
- 经引导上采样得到高分辨率输出 HHH
3.1 深度预测(Depth Prediction)
本文作者使用全卷积网络做单目深度估计,并采用多任务联合训练(深度+前景分割)。
-
网络结构
- 编码器:ResNet-50 前14个块 + 空洞卷积 + 金字塔池化(1×1/2×2/4×4/8×8)
- 解码器:3 次 2× 双线性上采样 + 跳跃连接
- 输出头:两个并行小头,分别输出深度图与前景分割图
-
深度处理
浅景深只需要相对深度,因此本文作者将深度取反得到视差,并归一化到 [0,1]。 -
多任务损失函数
Jd(θd)=∥D−Dg∥1+γ×∥S−Sg∥1 J_{d}\left(\theta_{d}\right)=\left\| D-D^{g}\right\| _{1}+\gamma \times\left\| S-S^{g}\right\| _{1} Jd(θd)=∥D−Dg∥1+γ×∥S−Sg∥1- $ D :预测深度;:预测深度;:预测深度; D^g $:深度真值
- $ S :预测分割;:预测分割;:预测分割; S^g $:分割真值
- $ \gamma $:平衡系数
作用:强制深度预测在物体边界更准确,显著减少虚化伪影。
3.2 镜头模糊渲染(Lens Blur Rendering)
这是本文最核心创新:不在图像域直接做空间变模糊,而是在低维特征空间做可微模糊,大幅节省显存与计算。
3.2.1 特征空间内的镜头模糊
模块分为:特征提取网络 + 核预测网络
- 特征提取:4 层卷积,输出通道数 c≪k2c \ll k^2c≪k2
- 核预测:输入深度、对焦平面、光圈,输出 h×w×ch×w×ch×w×c 的 1×1 核张量
渲染公式:
Li(x,y)=∑j=1cK(x,y,j)×Fi(x,y,j) L_{i}(x, y)=\sum_{j=1}^{c} K(x, y, j) × F_{i}(x, y, j) Li(x,y)=j=1∑cK(x,y,j)×Fi(x,y,j)
- FiF_iFi:第 iii 通道特征图
- KKK:预测的核张量
- LiL_iLi:输出浅景深图像
优势:避免直接计算 H×W×k2H×W×k^2H×W×k2 巨型核张量,显存占用降至原来的 10% 以下。
3.2.2 对焦深度与光圈控制
- 对焦深度:用符号深度图编码
D~=D−df \tilde{D}=D-d_{f} D~=D−df - 光圈大小:训练时固定最大光圈 rmr^mrm;测试时按比例缩放深度
α=r∗rm \alpha=\frac{r^{*}}{r^{m}} α=rmr∗
实现连续、可交互的光圈强度控制。
3.2.3 循环引导上采样(核心创新)
普通上采样会丢失对焦细节或产生模糊伪影。本文作者提出加权融合上采样:
H=MA⊙A+ML⊙L H=M_{A} \odot A+M_{L} \odot L H=MA⊙A+ML⊙L
- HHH:最终高分辨率浅景深图
- AAA:高清全对焦原图
- L^\hat{L}L^:低分辨率浅景深双线性上采样结果
- MA,MLM_A, M_LMA,ML:网络预测的空间权重图
逻辑:
- 对焦区域:信任高清原图 AAA
- 失焦区域:信任模糊结果 L^\hat{L}L^
支持循环 2 倍上采样,可输出任意高分辨率(本文最高 2K)。

- 图 3 镜头模糊方法对比。本文方法能够生成更准确的对焦 / 散焦边界,而合成孔径方法以及 Yang 等人 [2016] 的光线追踪方法会对高对比度区域产生过度模糊。

- 图 4 不同上采样方法的对比。本文方法在对焦区域保留了细节,且不会产生伪影。
3.2.4 联合训练与归一化损失(核心创新)
传统 L1/L2 损失对深度不连续边界关注不足。本文作者提出归一化损失:
Jf(X∣θ)=∑iwiL(Xi,Yi)∑iwi J_{f}(X|\theta )=\frac {\sum _{i}w_{i}L(X_{i},Y_{i})}{\sum _{i}w_{i}} Jf(X∣θ)=∑iwi∑iwiL(Xi,Yi)
其中权重 wi=∣Xi−Yi∣αw_i = |X_i-Y_i|^\alphawi=∣Xi−Yi∣α,α=1.5\alpha=1.5α=1.5。
代入 L1 损失后:
Jf(X∣θ)=∑i∣Xi−Yi∣α+1∑i∣Xi−Yi∣α J_{f}(X | \theta)=\frac{\sum _{i}\left|X_{i}-Y_{i}\right|^{\alpha+1}}{\sum _{i}\left|X_{i}-Y_{i}\right|^{\alpha}} Jf(X∣θ)=∑i∣Xi−Yi∣α∑i∣Xi−Yi∣α+1
作用:强制网络重点学习边缘与难样本,大幅减少物体边缘渗漏、重影、过曝。
整体联合损失:
argminθl,θhJf(L∣θl)+β⋅Jf(H∣θh) \underset{\theta _{l},\theta _{h}}{\operatorname{argmin}} J_{f}(L|\theta _{l})+\beta \cdot J_{f}(H|\theta _{h}) θl,θhargminJf(L∣θl)+β⋅Jf(H∣θh)
-
图 5 不同损失函数的对比。本文所提出的归一化损失能够减少对焦 / 散焦边界以及背景高对比度区域处的伪影。
-
方法部分核心创新
- 分段训练策略
深度模块用真实RGB-D数据,模糊与上采样用无伪影合成数据,兼顾泛化性与画质。 - 特征空间模糊
不在图像域做卷积,而是在低维特征空间用1×1核,显存暴减、速度大幅提升。 - 引导加权上采样
对焦区用原图、失焦区用模糊结果,保留细节且无伪影,支持任意分辨率输出。 - 归一化损失
自动聚焦深度不连续边界,解决虚化最容易出现的边缘伪影难题。
- 分段训练策略
4 数据集(Datasets)
本文作者指出,采集同时包含全对焦图像、浅景深真值、深度真值、对焦参数的数据集难度极高,因此采用真实数据 + 合成数据两套数据集,分别训练不同模块。
4.1 iPhone 深度数据集
- 为训练深度预测模块,本文作者自建iPhone 深度数据集。
- 数据来源:使用 iPhone 双摄相机,通过定制 iOS App 采集。
- 数量:共 2462 张 RGB-D 图像,过滤低质量深度后得到。
- 分辨率:深度图为 768×1024。
- 划分:训练集 2262 张,测试集 200 张。
- 优势:场景更贴近日常摄影,比 NYU v2、KITTI 等通用深度数据集更适合浅景深生成。
- 局限:真实深度含噪声,基于它渲染的浅景深会有伪影,因此不用于训练模糊与上采样模块。
4.2 合成浅景深数据集
- 为提供无伪影、无深度噪声的监督信号,本文作者构建合成浅景深数据集。
- 构建方式:
- 选取 300 张无前景的 iPhone 图像作为背景。
- 使用 3662 张前景抠图与掩码叠加。
- 组合为三层深度平面,生成精确深度与遮挡信息。
- 数量:18K 训练样本,500 测试样本。
- 优势:深度完全准确、被遮挡区域信息完整,渲染无伪影。
- 训练增强:训练时随机腐蚀/膨胀深度图,提升模型对深度误差的鲁棒性。
5 实验(Experiments)
本文作者从深度预测、浅景深生成、消融实验、用户研究四方面验证方法有效性。
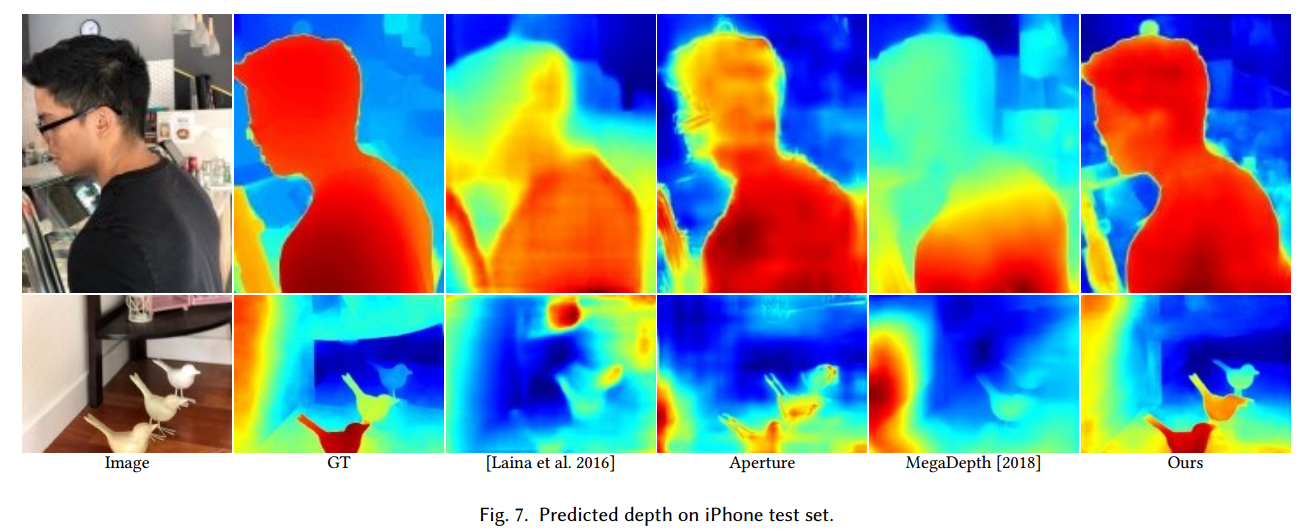
5.1 深度预测评估
- 对比方法:Laina 2016、MegaDepth、Aperture(仅用浅景深监督)。
- 指标:平均绝对误差 MAE。
- 结果:本文方法在 iPhone 测试集上 MAE=0.116,显著低于所有对比方法。
- 结论:本文的多任务训练 + 专用数据集让深度边界更清晰,更适合虚化渲染。
5.2 浅景深结果评估
- 对比基线:
- 直接回归(Pix2Pix)
- Aperture 方法
- MegaDepth + Yang 2016 传统渲染
- 指标:PSNR、SSIM
- 结果:
- 本文方法 PSNR=28.235,SSIM=0.908
- 显著优于所有基线
- 视觉结论:本文方法无边缘渗漏、无重影、无过曝,物体边缘干净自然。
5.3 消融实验
本文作者验证了三个关键设计的必要性:
- 深度监督至关重要
仅用浅景深监督(Aperture)会导致深度不准,虚化效果差。 - 学习式模糊优于传统渲染
本文模糊模块能补偿深度误差,而 Yang 2016 会在边界产生伪影。 - 特征空间模糊效率极高
特征通道 32 时效果最优,显存仅为原图空间模糊的 12.5%。 - 扰动深度训练更鲁棒
使用扰动深度训练,比用完美真值更适配真实深度预测误差。
5.4 用户研究
- 实验 1:对比 iPhone 人像模式
本文方法效果与 iPhone 相当,但无需双摄硬件,可自由调焦。 - 实验 2:对比 MegaDepth + Yang 2016
用户显著偏好本文结果。 - 速度:2K 分辨率仅需 0.7 秒,支持交互式调节。
5.5 局限
- 单目深度预测仍存在误差,会导致局部虚化错误。
- 受 GPU 内存限制,主计算需在低分辨率进行。
- 现有数据无法支持全部模块端到端联合训练。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 1
1 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)