吃透 CUDA 共享内存:从分块矩阵乘法到矩阵转置
一份在 LeetGPU 上刷题时整理出来的实战笔记。两道题都标着 "Easy",但真正写对、写快,需要理解 GPU 的执行模型和内存模型。本文按照"为什么慢 → 怎么优化 → 每一行代码到底在干什么"的顺序,把分块矩阵乘法(Tiled Matrix Multiplication)和矩阵转置(Matrix Transpose)讲清楚。
GPU 编程里有一条贯穿始终的哲学:用片上的高速缓存(共享内存)去安抚全局显存的坏脾气。 这两道题就是理解这条哲学最好的练习。
第一部分:分块矩阵乘法
朴素写法为什么不够快
最直观的写法是:每个线程负责输出矩阵 C 的一个元素,直接从全局显存里把 A 的一整行、B 的一整列读出来做点积。代码很短,逻辑也对,但当矩阵大到 M=8192, N=6144, K=4096 时,它会因为太慢而过不了性能测试。
原因在于:GPU 的全局显存(也就是显卡参数里的 8G、16G)容量很大,但访问延迟很高、带宽是宝贵资源。朴素写法里,同一行的数据会被同一行上的每个输出元素反复地从全局显存里读取,造成巨大的带宽浪费。
解决思路是分块(Tiling):让同一个线程块(Block)里的线程协同工作,先把 A 和 B 的一小块子矩阵(Tile,例如 16×16)搬进 GPU 上速度快几十倍的共享内存(Shared Memory / SRAM),在共享内存里完成这一块的部分乘加,再滑动到下一块。这样每个数据从慢速显存里只读一次,之后的复用都发生在高速缓存里。
⚠️ 先说一个最容易翻车的坑:到底谁是收缩维度
不同资料对矩阵乘法的维度命名不一样。很多教科书和 cuBLAS 习惯写成 A(M×K) · B(K×N) = C(M×N),收缩维度(点积的长度)叫 K。
但本题的定义是:
A 的维度是 M × N
B 的维度是 N × K
C 的维度是 M × K
点积沿着 N 方向进行可以用最小的测试用例验证:A = [[1,2,3]](1×3,所以 M=1, N=3),B = [[4],[5],[6]](3×1,所以 N=3, K=1),结果 C = [[32]],因为 1×4 + 2×5 + 3×6 = 32。
教训:动手写之前,一定要先从题目和测试用例里确认每个矩阵的真实形状、哪一维是收缩维,而不是凭对"标准约定"的记忆去套。 维度搞反,最典型的症状就是越界写入或者结果只算对了第一个元素。下面所有代码都基于本题的定义:收缩维是 N。
GPU 是怎么被调度起来的:执行模型
在看 kernel 之前,先理解启动 kernel 的三行代码。可以把 GPU 计算想象成包工头分配搬砖任务:
dim3 threadsPerBlock(TILE_SIZE, TILE_SIZE); // 定义"一个施工小队"的规模
dim3 blocksPerGrid((K + TILE_SIZE - 1) / TILE_SIZE, // 定义"一共派多少个小队"
(M + TILE_SIZE - 1) / TILE_SIZE);
matrix_multiplication_kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K);threadsPerBlock:一个线程块里有多少线程。 dim3 是 CUDA 内置的、含 x/y/z 三维的结构体。这里定义了一个 16×16 的二维线程块,也就是一个 Block 里有 256 个线程。这 256 个线程是一支"紧密合作的小队":它们被分配到同一个物理核心(SM)上,共享同一块高速共享内存,并且能通过 __syncthreads() 互相等待和沟通。在矩阵乘法里,它们刚好共同负责一个 16×16 的数据块。
blocksPerGrid:整个网格里有多少个线程块。 我们的目标是把输出矩阵 C(M 行 × K 列)像贴瓷砖一样完全覆盖,所以要派出足够多的小队。这里的除法是向上取整(下一节细讲):x 方向铺满 K 列需要多少块,y 方向铺满 M 行需要多少块。
<<<...>>>:执行配置。 这个三尖括号语法告诉 GPU 驱动:"按我划分好的网格和小队规模,把所有线程叫醒,开干!"。kernel 函数内部的代码是写给每一个线程看的——成千上万个线程并行执行同一份代码,只是各自处理的数据位置不同。
计算全局坐标:row = blockIdx.y * TILE_SIZE + ty
每个线程醒来后第一件事是"我是谁、我在哪"——算出自己负责 C 里的哪一行哪一列。
int row = blockIdx.y * TILE_SIZE + ty;
int col = blockIdx.x * TILE_SIZE + tx;公式的逻辑是:前面若干个完整块跳过的距离 + 块内的局部偏移。
blockIdx.y * TILE_SIZE:找到当前块的起点。如果你在第blockIdx.y个块里(索引从 0 开始),意味着上面已经堆了这么多个完整的块,每个块高TILE_SIZE。比如blockIdx.y = 2、TILE_SIZE = 16,那么前两个块(块 0、块 1)已经占了第 0~31 行,所以当前块从第 32 行开始。+ ty:再加上线程在块内部的局部行号。
一个生活比喻(小区与门牌号):
TILE_SIZE= 每个小区有 16 栋楼blockIdx.y= 你在第 2 号小区ty= 你在本小区的第 5 栋楼- 你的绝对楼号 = 前面小区的楼总数(2 × 16)+ 本小区楼号(5)= 37 号楼
col 的算法完全对称,只是换到水平方向(X 轴)去找全局列坐标。
为什么 X 对应列、Y 对应行
这是初学者把维度搞反的"重灾区"。根源是两套坐标系的习惯冲突:
- C++ / 数学习惯:先行后列。 定位元素先说第几行,再说第几列,
Matrix[row][col]。 - CUDA / 图形学习惯:先 X 后 Y。 CUDA 出自做显卡的 NVIDIA,沿用了笛卡尔坐标系:X 轴水平(管列),Y 轴垂直(管行)。
把矩阵画在屏幕上看:宽度方向是列数(在 X 轴上移动是在跨列),高度方向是行数(在 Y 轴上移动是在跨行)。而 dim3 的构造函数严格按 (x, y, z) 顺序赋值——第一个参数给 .x,第二个给 .y。
| 物理方向 | 笛卡尔坐标 (CUDA) | 矩阵属性 | 本题变量 |
|---|---|---|---|
| 水平 ↔ | X 轴 .x |
列 / 宽度 | K |
| 垂直 ↕ | Y 轴 .y |
行 / 高度 | M |
所以为了让 X 轴去管列、Y 轴去管行,必须把含 K(列)的式子放第一位、含 M(行)的式子放第二位。一个口诀:X 是宽,Y 是高;涉及 x 就去找列和 col,涉及 y 就去找行和 row。 如果写反了,整个工作网格相当于旋转了 90 度盖在矩阵上,必然大面积越界。
向上取整:(N + TILE_SIZE - 1) / TILE_SIZE
int numTiles = (N + TILE_SIZE - 1) / TILE_SIZE;这是 C/C++ 里实现向上取整(Ceiling Division)的经典技巧,数学上等价于 ⌈N / TILE_SIZE⌉。
为什么需要向上取整? 因为点积长度是 N,但每次只能搬 TILE_SIZE 个元素。如果 N 不能被整除,比如 N=35, TILE_SIZE=16,前两次处理了 32 个,还剩 3 个没算。为了这最后 3 个,必须再多滑动一次(第 3 次),哪怕这一块填不满(不足的部分在 kernel 里补 0)。所以只要有余数,就得多加一个 Tile。
这个公式怎么做到的? C/C++ 的整数除法是向下取整(截断)的,35 / 16 = 2,会漏掉尾巴。给被除数加上"比除数小 1 的数"就能修正:
- 没余数:
(32 + 15) / 16 = 47 / 16 = 2,结果不变 ✓ - 有余数:
(35 + 15) / 16 = 50 / 16 = 3,成功进位 ✓
生活比喻(包大巴): N=35 人的旅游团,每辆大巴 16 座,要租几辆?直接 35/16=2 辆会有 3 个人没车坐被留在原地。用公式 (35+16-1)/16 = 3 辆,前两辆坐满,第三辆坐 3 人(空着的 13 个座位就相当于代码里补的 0),所有人都能出发。
顺带说清一个常见疑惑:M、N 的向上取整在哪? 其实它们也做了,只是发生在 CPU 端的 blocksPerGrid 里(决定派多少个线程小队去覆盖 C 的 M 行 K 列);而 N 的向上取整发生在 kernel 内部(决定单个线程要循环搬几次砖)。一句话——M、N 决定招多少工人,N 决定每个工人在走廊里来回搬几趟。
行优先:为什么一维指针能表示二维矩阵
题目的函数签名传进来的是 const float*(一维指针),并且说明"所有矩阵以行优先(row-major)格式存储"。
计算机内存本质是一条直线,没有真正的二维结构。行优先就是把二维矩阵"拍扁"成一维:先连续存第一行,接着第二行……一个 3×4 的矩阵
0 1 2 3
4 5 6 7
8 9 10 11在物理内存里就是 [0,1,2,3,4,5,6,7,8,9,10,11]。
要访问第 r 行第 c 列,就用通用公式把二维坐标换算成一维偏移:
一维索引 = 当前行号 × 矩阵总列数 + 当前列号直觉是:先跨过前面 r 个完整的行(每行长"总列数"),再往前走 c 步。套用到本题(注意每个矩阵的"总列数"不同):
- 读 A(M×N,行跨度 N):行是
row,列是t*TILE_SIZE + tx,索引 =row * N + (t*TILE_SIZE + tx) - 读 B(N×K,行跨度 K):行是
t*TILE_SIZE + ty,列是col,索引 =(t*TILE_SIZE + ty) * K + col - 写 C(M×K,行跨度 K):索引 =
row * K + col
那为什么不直接用 float** 二维指针? 因为性能。一维数组在内存里绝对连续,GPU 读取连续地址时会触发内存合并(Memory Coalescing),一次就把一批数据抓回来;而 float** 需要先读一个指针、再跳到那个地址去读数据,这种"指针追逐"在 GPU 上会让性能断崖式下跌。
至于 kernel 里自己声明的 __shared__ float sA[TILE_SIZE][TILE_SIZE],因为大小是编译期已知的,编译器知道它的宽度,所以可以放心用 sA[ty][tx] 这种语法糖——底层它依然会被编译器自动展开成 行 × 宽度 + 列 的一维计算。
完整代码
#include <cuda_runtime.h>
#define TILE_SIZE 16 // 16×16 = 256 线程/块,对各种 GPU 架构都安全兼容
__global__ void matrix_multiplication_kernel(const float* A, const float* B,
float* C, int M, int N, int K) {
__shared__ float sA[TILE_SIZE][TILE_SIZE];
__shared__ float sB[TILE_SIZE][TILE_SIZE];
int tx = threadIdx.x;
int ty = threadIdx.y;
// 输出矩阵 C 是 M×K,所以全局行受 M 限制、全局列受 K 限制
int row = blockIdx.y * TILE_SIZE + ty;
int col = blockIdx.x * TILE_SIZE + tx;
float sum = 0.0f;
// 收缩维是 N,沿 N 方向滑动数据块
int numTiles = (N + TILE_SIZE - 1) / TILE_SIZE;
for (int t = 0; t < numTiles; ++t) {
// 1. 加载 A 的数据块(A 是 M×N,行跨度 N),越界补 0
int a_col = t * TILE_SIZE + tx;
if (row < M && a_col < N) {
sA[ty][tx] = A[(size_t)row * N + a_col];
} else {
sA[ty][tx] = 0.0f;
}
// 2. 加载 B 的数据块(B 是 N×K,行跨度 K),越界补 0
int b_row = t * TILE_SIZE + ty;
if (col < K && b_row < N) {
sB[ty][tx] = B[(size_t)b_row * K + col];
} else {
sB[ty][tx] = 0.0f;
}
// 等整个 Block 都加载完
__syncthreads();
// 3. 计算这一块的局部点积
#pragma unroll
for (int i = 0; i < TILE_SIZE; ++i) {
sum += sA[ty][i] * sB[i][tx];
}
// 再次同步,防止快线程提前覆盖共享内存
__syncthreads();
}
// 4. 写回 C(M×K,行跨度 K),最后做一次边界检查
if (row < M && col < K) {
C[(size_t)row * K + col] = sum;
}
}
extern "C" void solve(const float* A, const float* B, float* C,
int M, int N, int K) {
dim3 threadsPerBlock(TILE_SIZE, TILE_SIZE);
// x 对应列 (K),y 对应行 (M)
dim3 blocksPerGrid((K + TILE_SIZE - 1) / TILE_SIZE,
(M + TILE_SIZE - 1) / TILE_SIZE);
matrix_multiplication_kernel<<<blocksPerGrid, threadsPerBlock>>>(A, B, C, M, N, K);
cudaDeviceSynchronize();
}几个细节值得记住:extern "C" 保留 C 风格的函数名,避免 C++ 的名称修饰(Name Mangling),便于评测系统或从 Python(ctypes/CFFI)调用编译出的动态库;__shared__ float[16][16] 的大小必须和 threadsPerBlock(16,16) 严格对齐,否则线程索引会撑爆共享内存;#pragma unroll 提示编译器展开内层定长循环,省掉每次迭代的分支判断开销。
第二部分:矩阵转置
转置在数学上简单到只是"行列互换",但在 GPU 上如果写得随意,性能会非常拉垮。它是理解内存合并和Bank 冲突的绝佳例子。
朴素转置为什么慢:跨步访问
最直观的写法是:
output[x * rows + y] = input[y * cols + x]; // 朴素版,正确但很慢问题出在写入端。先要理解 GPU 的"强迫症"——内存合并:当一个线程束(Warp,32 个线程)同时访问全局显存时,
- 合并访问(极快):32 个线程访问的地址连续,硬件打包成 1 次内存交互就搞定。
- 跨步访问(极慢):32 个线程的地址是跳跃的,硬件无法打包,每个线程都要单独发起一次访问,还白白浪费整条缓存行的带宽。
朴素转置里,读 input 时连续线程读连续地址(合并,快);但写 output 时索引是 x * rows + y,连续的线程(连续的 x)被乘上了 rows,于是线程 0 写地址 0、线程 1 跳到 rows、线程 2 跳到 2*rows……它们在物理内存上像天女散花一样被打散,写入带宽暴跌。
救星:用共享内存做"中转站"
思路是把一次"读快、写慢"拆成"读快 → 在高速缓存里中转 → 写快":
- 合并读取:一个 Block 的线程把输入的一个数据块连续地读进共享内存
tile。 - 块内转置:在共享内存里把读写坐标
[ty][tx]和[tx][ty]对调。共享内存快几十倍且不怕跨步,这一步几乎免费。 - 合并写入:通过坐标错位计算,让这批线程从
tile取出转置好的数据,并且仍然连续地写入 output。
生活比喻(快递分拣): 要把按"省份"打包的快递重新按"城市"分类发出。 朴素转置 = 工人从车上拿下连续一排快递,然后各自满场乱跑去不同城市的仓库(跨步写入,低效)。 共享内存转置 = 车旁放一张大分拣桌(tile),工人把连续一排快递先全扔上桌(连续读,快),在桌面上飞快地按城市理好(共享内存内部转置,快),最后一起抱起"北京"那一堆齐步走进北京仓库(连续写,快)。
核心技巧之一:写入阶段的"乾坤大挪移"
// 读取阶段:当前线程在输入矩阵的坐标
int in_x = blockIdx.x * TILE_SIZE + tx;
int in_y = blockIdx.y * TILE_SIZE + ty;
// 写入阶段:block 的归属对调(x↔y),但线程的局部排位 tx/ty 不变!
int out_x = blockIdx.y * TILE_SIZE + tx;
int out_y = blockIdx.x * TILE_SIZE + ty;注意写入阶段:本该用 blockIdx.x 的 out_x 用了 blockIdx.y,反之亦然。这是因为转置后,输入里属于第 blockIdx.x 列的块,在输出里要变成第 blockIdx.y 行——块的归属地交换了。
但关键在于:线程本身不能乱。 为了让 GPU 一次性连续写入,连续的线程号 tx 依然要负责连续的内存地址 out_x。所以我们"交换了块的归属(blockIdx.x 和 y 互换),却保留了工人的局部排位(tx、ty 依旧对应 X、Y)"。真正的行列交换发生在从共享内存取数那一步:tile[tx][ty](注意下标顺序反了)。
顺便回答一个常见疑问:两道题计算全局坐标的公式其实完全一样(X 永远绑
tx、Y 永远绑ty),只是变量换了名字、Grid 覆盖的目标矩阵不同。乘法里 Grid 直接盖在输出矩阵 C 上,算出的坐标就是 C 的 row/col,可以直接写回;转置里 Grid 盖在输入矩阵上,所以先把坐标叫in_x/in_y提醒自己"这只是读取坐标",写出去时还要再做一次上面的块归属交换。
核心技巧之二:+1 消除 Bank 冲突
__shared__ float tile[TILE_SIZE][TILE_SIZE + 1]; // 列维度故意 +1这个看似多余的 +1 叫内存填充(Memory Padding),专门用来消除共享内存里致命的性能杀手——Bank 冲突(Bank Conflict)。
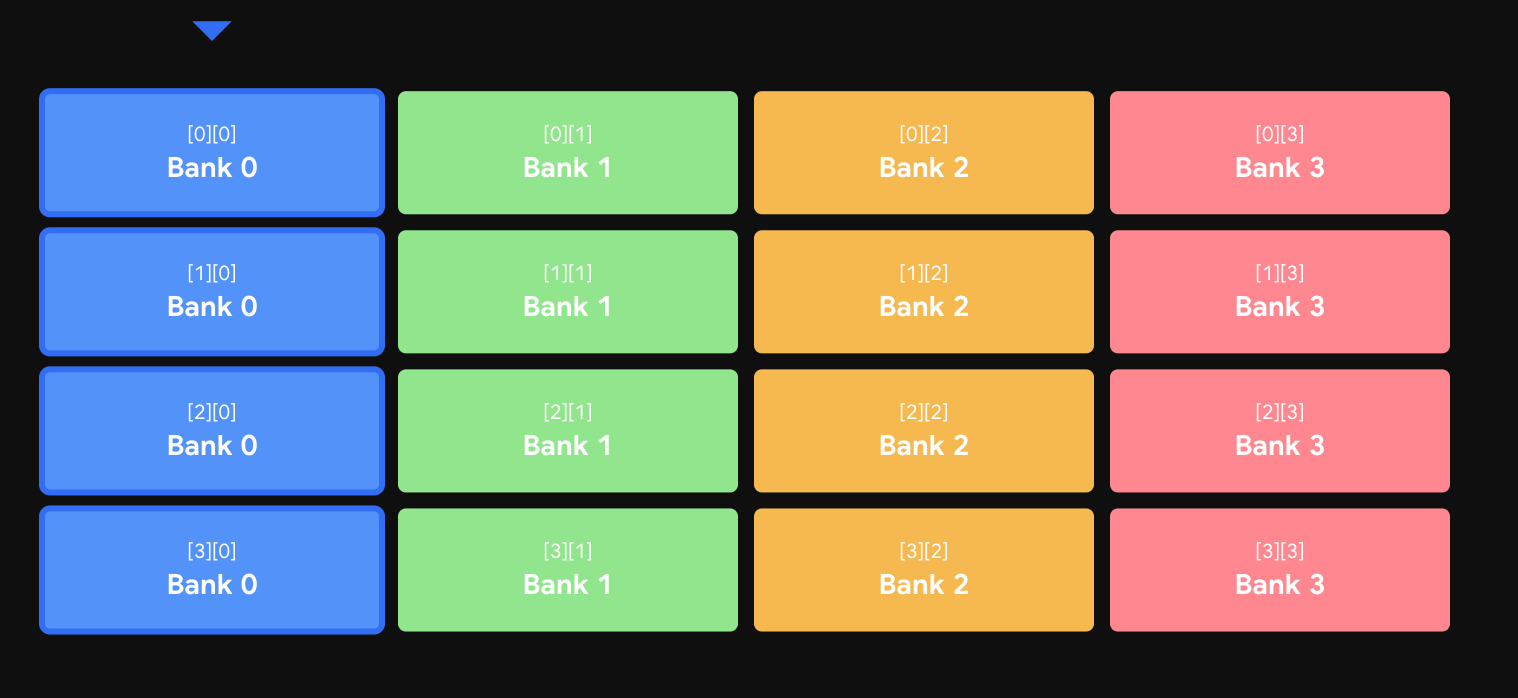
硬件背景:什么是 Bank? 别把共享内存想成一个连续的大水池。物理上它被切成 32 个独立的列,叫 Banks。规则是:一个 Warp 的 32 个线程同时访问共享内存时,如果分别落在 32 个不同的 Bank 上,就能在 1 个时钟周期内并行取出(跑满带宽);如果多个线程挤在同一个 Bank 上,就只能排队,一个一个来(这就是 Bank 冲突,最坏情况慢 32 倍)。
地址按 4 字节(一个 float)的"字"循环分配给 Bank:地址 0→Bank 0、地址 1→Bank 1、……、地址 31→Bank 31、地址 32→Bank 0(循环)。
灾难现场(不加 +1)。 假设 TILE_SIZE = 32,声明 tile[32][32]。写入 tile[ty][tx] 时连续没问题。但读取时坐标反过来变成 tile[tx][ty],于是同一时刻 32 个线程要读的是同一列 tile[0][0], tile[1][0], ..., tile[31][0]。算一下它们的一维索引和 Bank:
tile[0][0] → 0×32+0 = 0 → Bank 0
tile[1][0] → 1×32+0 = 32 → Bank 0
tile[2][0] → 2×32+0 = 64 → Bank 0
... → 全是 Bank 0 !!同一列的元素全挤在 Bank 0,32 个线程排长队——32 路 Bank 冲突,惨烈。
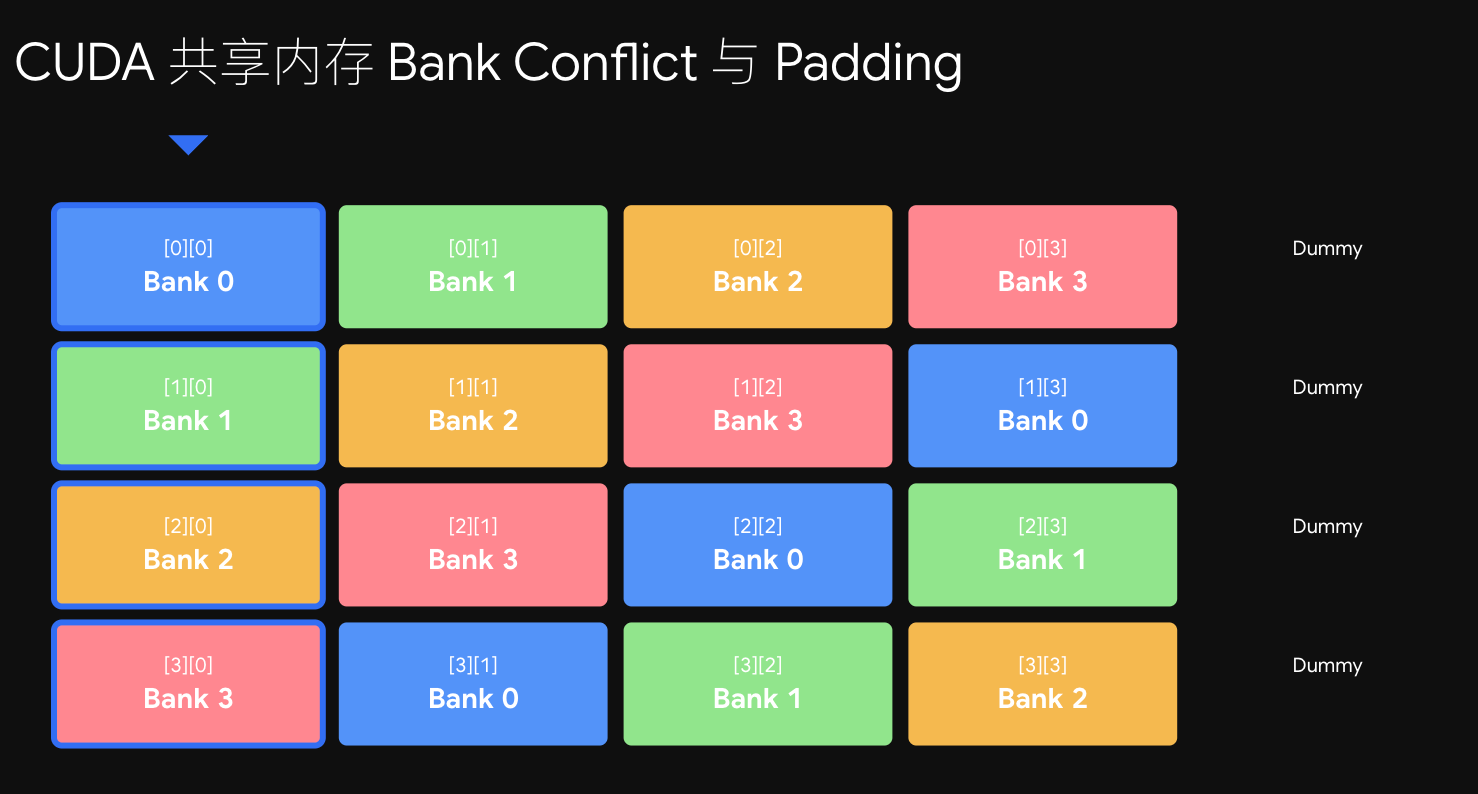
化腐朽为神奇(加 +1)。 改成 tile[32][33],相当于每行末尾塞一个废弃空间(排队时每排满 32 人就故意空一个位)。再算同一列:
tile[0][0] → 0×33+0 = 0 → Bank 0
tile[1][0] → 1×33+0 = 33 → Bank 1
tile[2][0] → 2×33+0 = 66 → Bank 2
tile[3][0] → 3×33+0 = 99 → Bank 3
... → 0,1,2,3,...,31 全错开 !!仅仅因为每行多偏移 1,原本垂直成一线的元素在 Bank 映射上变成了一条斜线,32 个线程刚好分散到 Bank 0~31,零冲突。这个 +1 不存任何真实数据、程序也不读它,唯一使命就是当垫脚石把后面的地址往后推一位——用每行浪费 4 字节的极小代价,换来共享内存带宽的彻底解放。
完整代码
#include <cuda_runtime.h>
#define TILE_SIZE 16
__global__ void matrix_transpose_kernel(const float* input, float* output,
int rows, int cols) {
// 列维度 +1 消除 Bank 冲突(不影响数据读取,只是物理上错开存储位置)
__shared__ float tile[TILE_SIZE][TILE_SIZE + 1];
int tx = threadIdx.x;
int ty = threadIdx.y;
// 1. 合并读取:当前线程在输入矩阵 (rows×cols) 的坐标
int in_x = blockIdx.x * TILE_SIZE + tx; // 列方向 → cols
int in_y = blockIdx.y * TILE_SIZE + ty; // 行方向 → rows
if (in_x < cols && in_y < rows) {
// 展平为一维时用 size_t 防止超大矩阵索引溢出
tile[ty][tx] = input[(size_t)in_y * cols + in_x];
}
__syncthreads(); // 等整个 Block 搬运完
// 2. 合并写入:block 归属对调,线程局部排位不变
int out_x = blockIdx.y * TILE_SIZE + tx; // 输出矩阵 (cols×rows) 的列 → rows
int out_y = blockIdx.x * TILE_SIZE + ty; // 输出矩阵的行 → cols
if (out_x < rows && out_y < cols) {
// 从共享内存按转置坐标 [tx][ty] 取数,写回 output(行跨度为 rows)
output[(size_t)out_y * rows + out_x] = tile[tx][ty];
}
}
extern "C" void solve(const float* input, float* output, int rows, int cols) {
dim3 threadsPerBlock(TILE_SIZE, TILE_SIZE);
// Grid 基于输入矩阵划分:X 对应 cols,Y 对应 rows
dim3 blocksPerGrid((cols + TILE_SIZE - 1) / TILE_SIZE,
(rows + TILE_SIZE - 1) / TILE_SIZE);
matrix_transpose_kernel<<<blocksPerGrid, threadsPerBlock>>>(input, output, rows, cols);
cudaDeviceSynchronize();
}为什么这样就跑满了带宽?读取时 tile[ty][tx] = input[...],tx 连续、in_x 也连续,32 个线程要的是连续的 32 个 float,一次内存传输搞定;写入时 output[...] = tile[tx][ty],我们强制让 out_x 跟着 tx 变化,写出去的也是连续地址,又是一次传输搞定。两次极顺畅的全局访问之间,那个"别扭"的行列交换被塞进了快几十倍、且加了 +1 防冲突的共享内存里完成。
GPU 矩阵转置:内存访问模式演示
把两道题串起来
回头看,两道题的优化套路是同一个:全局显存又大又慢、还有内存合并和 Bank 冲突这些坏脾气,所以我们用片上的高速共享内存做缓存和中转,把对全局显存的访问都收拾成连续、对齐、只读一次的样子。
几条可以带走的经验:
动手前先确认维度。 谁是收缩维、每个矩阵的真实形状是什么、行跨度是哪一维——从题目和测试用例里核实,别凭"标准约定"的记忆硬套。维度搞反是这类题最常见、最难查的错误来源。
记住坐标口诀。 CUDA 里 X 是宽(列)、Y 是高(行);涉及 .x/tx 就去找列和 col,涉及 .y/ty 就去找行和 row。
理解执行模型。 threadsPerBlock 决定组队方式,blocksPerGrid 决定阵型大小,kernel 是一声令下后成千上万线程并行执行的同一份动作指令;每个线程都要先算清自己的全局坐标,再处理对应的数据。
为内存合并而设计。 让连续的线程访问连续的地址,是 GPU 性能的命脉。当读和写无法同时连续时(比如转置),就用共享内存做中转。
别忘了 Bank 冲突。 当共享内存出现"按列访问"的模式时,一个 [TILE][TILE+1] 的填充往往就能带来成倍的提速。
这五条几乎适用于所有把数据搬进共享内存来加速的 CUDA 题目。把它们吃透,再去看更进阶的寄存器分块(Register Tiling)、双缓冲(Double Buffering)等优化,思路就会顺很多。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)