从 0 到 1 构建车辆图片旋转角度检测分类模型

一、背景
在物流运输业务中,司机需要上传车头照片、货物装载照片、雨布覆盖照片等运输过程凭证。当前系统采用 Qwen 多模态模型对图片进行自动审核,但实际应用发现,部分司机上传的图片存在横屏拍摄或旋转 90°、180°、270° 等情况,导致模型对车辆和货物状态的识别准确率下降。
通过业务验证发现,对图片进行方向矫正后,多模态模型的审核效果得到明显提升。因此,在图片审核流程前增加车辆图片旋转角度检测与自动矫正模块,对提升审核准确率、降低人工干预成本具有重要意义。
因此,我们需要构建一个能够自动判断车辆图片旋转角度,并自动将图片纠正回正常方向的小模型。
这篇文章记录的是我作为一名 Java 开发人员,从 0 到 1 构建车辆图片旋转角度检测分类模型的完整过程。它不是一篇只讲理论的深度学习文章,而是从工程落地角度出发,把问题定义、数据准备、模型选择、训练、评估、推理、ONNX 导出、Java 服务部署、置信度阈值、人工复核闭环等环节完整串起来。
二、问题定义
一开始很容易把这个问题想复杂。现在大模型、视觉语言模型、生成式 AI 很火,很多人遇到图片相关问题都会下意识想到“要不要用大模型”。但车辆图片旋转角度检测这个任务,本质上并不需要大语言模型,也不需要生成式视觉模型。
这个任务的目标非常明确:输入一张车辆图片,判断这张图片为了恢复到正确方向,需要顺时针旋转多少度。
也就是说,模型的输出只有四种可能:
0°
90°
180°
270°因此,这个任务本质上是一个标准的四分类图像分类任务。
更准确地说,它是:
车辆图片方向识别 + 自动旋转纠正输入是车辆图片,输出是图片需要旋转的角度。例如:
{
"angle_required": 90,
"confidence": 0.982
}这里的 angle_required = 90 表示当前图片需要顺时针旋转 90 度,才能恢复到正常方向。
这个定义非常重要。模型不是要识别“这是什么车”,也不是要识别“这是车头还是车尾”,更不是要理解复杂语义。它只需要判断图片方向是否正常,以及如果不正常,应该旋转多少度。
所以这个任务最适合使用轻量、稳定、推理速度快、容易部署的 CNN 图像分类模型,而不是大模型。
三、标签定义?
这个项目最关键、也最容易搞错的地方,是标签定义。
很多人第一反应会把标签定义成:
当前图片被旋转了多少度比如原图顺时针旋转 90 度,就给它打标签 90。
但这个定义在业务系统里容易造成混乱。因为系统真正关心的不是“这张图片当前被旋转了多少度”,而是:
为了把这张图片纠正回正常方向,需要顺时针旋转多少度也就是说,标签应该表示“纠正动作”,而不是“当前状态”。
假设我们有一张方向正确的车辆图片。我们基于这张图片自动生成四类训练样本:
|
生成方式 |
当前图片状态 |
标签含义 |
label |
|
原图 |
已经正确 |
不需要旋转 |
0 |
|
原图顺时针旋转 90° |
图片歪了 90° |
需要再顺时针旋转 270° 才能纠正 |
270 |
|
原图顺时针旋转 180° |
图片倒置 |
需要顺时针旋转 180° 才能纠正 |
180 |
|
原图顺时针旋转 270° |
图片歪了 270° |
需要再顺时针旋转 90° 才能纠正 |
90 |
为什么“原图顺时针旋转 90° 后”,标签不是 90,而是 270?
原因很简单:如果一张正确图片已经被顺时针旋转了 90 度,要让它恢复正确方向,就必须继续顺时针旋转 270 度。这样总共旋转 360 度,才能回到原始方向。
因此,本项目的标签含义必须统一为:
为了纠正当前图片,需要顺时针旋转多少度四个类别的业务含义如下:
|
类别 |
含义 |
|
0 |
当前方向正确,不旋转 |
|
90 |
顺时针旋转 90° |
|
180 |
顺时针旋转 180° |
|
270 |
顺时针旋转 270° |
四、整体技术路线
从 Java 工程开发者的角度看,这个项目可以拆成两部分:模型训练部分和业务部署部分。
模型训练阶段主要使用 Python、PyTorch、torchvision 等深度学习工具完成。
业务部署阶段则更适合结合 Java 技术栈来完成。训练完成后,将 PyTorch 模型导出为 ONNX 格式,然后在 Java 服务中通过 ONNX Runtime 加载模型,完成图片预处理、模型推理、置信度判断、图片旋转和接口返回。
整体流程如下:
收集方向正确的车辆图片
↓
清洗、去重、确认方向正确
↓
按原始图片划分 train / val / test
↓
在每个集合内部生成 0 / 90 / 180 / 270 四类旋转样本
↓
选择模型架构,例如 MobileNetV3 / EfficientNet-B0 / ResNet18
↓
使用 ImageNet 预训练权重做迁移学习
↓
训练并保存最佳模型 .pth
↓
使用 test 集做最终评估
↓
导出 ONNX 模型和 meta.json
↓
Java 服务使用 ONNX Runtime 推理
↓
根据预测角度和置信度自动旋转或进入人工复核
↓
线上错误样本回流,持续优化模型五、数据准备
深度学习项目里,数据质量往往比模型选择更重要。对于车辆图片旋转角度检测任务,最理想的数据来源是一批已经人工确认方向正确的车辆图片。
例如我们可以准备一个目录:
raw_correct_images/
car_0001.jpg
car_0002.jpg
car_0003.jpg
...这个目录里必须放“已经确认方向正确”的车辆图片。也就是说,图片中的车辆应该是正常观看方向,不能已经横着、倒着或方向异常。
数据量方面,可以按照项目阶段逐步推进:
|
阶段 |
原始正确图数量 |
自动扩增后样本量 |
|
Demo 跑通 |
500 张 |
2000 张 |
|
初步可用 |
1000~2000 张 |
4000~8000 张 |
|
生产初版 |
3000~5000 张 |
12000~20000 张 |
|
稳定生产 |
10000 张以上 |
40000 张以上 |
这里需要注意,真正重要的是“原始正确图”的数量,而不是扩增后的数量。因为每张原始图都会生成 4 张旋转图,如果原始图太少,即使扩增后数量看起来很多,本质上还是来自少量车辆图片,模型很容易记住具体图片,而不是真正学习车辆方向特征。
原始图片应该尽量覆盖真实业务场景,包括:
白天图片
夜晚图片
雨天图片
户外道路图片
车头近景
车头远景
车头局部
车牌清晰图片
车牌模糊图片
新能源车
燃油车
不同车身颜色
不同拍摄距离
不同手机型号
不同背景复杂度不要只使用特别干净、特别标准、特别像样例图的数据。训练集如果过于理想,上线后很容易在真实场景中翻车。
六、为什么要先划分原始图,再生成旋转样本?
数据集划分也非常关键。错误的做法是先把所有原始图生成 4 类旋转图,然后再随机划分 train、val、test。
这样做会导致一个严重问题:同一张原图的不同旋转版本可能同时出现在训练集和测试集中。比如 car_0001 的 0 度版本在 train,90 度版本在 test。这样模型测试时其实见过同一张车图,只是旋转角度不同,最终测试准确率会虚高,不能真实反映上线效果。
正确做法是:
第一步:先按原始图片维度划分 train / val / test
第二步:在每个集合内部再生成 0 / 90 / 180 / 270 四类样本例如原始正确图 10000 张,按照 8:1:1 划分:
train 原始图:8000 张
val 原始图:1000 张
test 原始图:1000 张然后分别在三个集合内部生成旋转样本:
|
数据集 |
0 |
90 |
180 |
270 |
总数 |
|
train |
8000 |
8000 |
8000 |
8000 |
32000 |
|
val |
1000 |
1000 |
1000 |
1000 |
4000 |
|
test |
1000 |
1000 |
1000 |
1000 |
4000 |
这样才能保证测试集里的车辆图片是真正没有被模型见过的新图片。
七、数据目录设计
最终训练目录可以设计成标准分类任务目录:
dataset/
train/
0/
90/
180/
270/
val/
0/
90/
180/
270/
test/
0/
90/
180/
270/其中:
train:训练集,用来让模型学习参数
val:验证集,用来在训练过程中选择最佳模型
test:测试集,用来在训练完成后做最终客观评估每个目录下的 0、90、180、270 子目录代表四个方向纠正类别。这里再次强调,这些类别不是图片当前旋转角度,而是图片为了恢复正常方向需要顺时针旋转的角度。
训练过程中通常会输出:
train_loss
train_acc
val_loss
val_acc其中 train_acc 表示模型在训练集上的准确率,val_acc 表示模型在验证集上的准确率。一般保存模型时会优先保存 val_acc 最好的那一轮,而不是训练集准确率最高的那一轮。
因为如果训练集准确率很高,但验证集准确率较低,说明模型可能只是记住了训练图片,没有真正学会方向判断,这就是过拟合。
八、数据质量检查与去重
在训练模型之前,至少要做四类检查。
第一,检查是否存在完全重复图片。比如同一张图片只是文件名不同,但内容完全一样。
第二,检查是否存在近似重复图片。比如同一辆车、同一角度、连续拍摄的多张照片,或者同一段视频中截取的相邻帧。
第三,检查是否存在跨集合重复。也就是同一张或高度相似的图片同时出现在 train、val、test 中。这是最严重的问题,会导致测试集准确率虚高。
第四,检查四类数量是否均衡。因为每张原始图都会生成四个方向样本,所以理论上每个类别数量应该完全一致。如果某一类数量明显少于其他类别,说明数据生成过程中可能存在图片读取失败、保存失败、目录缺失或人工移动文件等问题。
上线前还应该额外准备一批真实业务图片作为独立验收集。这个验收集最好来自真实线上环境,不参与训练和调参,只用于评估模型上线前是否真正适应业务场景。
九、数据增强策略
除了固定生成 0、90、180、270 四类旋转样本之外,还可以在训练过程中加入一些轻量数据增强,以提升模型泛化能力。
推荐使用的增强包括:
|
增强方式 |
是否建议 |
说明 |
|
亮度变化 |
建议 |
适应白天、夜晚、曝光差异 |
|
对比度变化 |
建议 |
适应不同相机和图像压缩 |
|
模糊 |
建议 |
适应手抖、运动模糊、低质量图片 |
|
JPEG 压缩 |
建议 |
适应业务系统压缩后的图片 |
|
噪声 |
建议 |
适应低光照和摄像头噪声 |
|
小角度旋转 ±3° |
可以 |
适应轻微歪斜 |
|
随机裁剪 |
可以 |
适应车辆不居中的情况 |
|
大幅透视变换 |
谨慎 |
过强可能改变方向特征 |
|
水平翻转 |
谨慎 |
可能改变车头、车牌、左右结构 |
|
垂直翻转 |
不建议 |
业务中几乎不会出现,且容易引入异常分布 |
增强不是越多越好。这个任务的目标是判断方向,过强的数据增强可能会破坏方向特征,反而让模型学习困难。
十、模型选择
对于这个任务,最适合的是轻量 CNN 分类模型。常见候选包括 MobileNetV3、EfficientNet-B0/B1、ResNet18、ConvNeXt-Tiny、YOLO 分类模型等。
整体对比如下:
|
模型 |
特点 |
训练难度 |
推理速度 |
精度潜力 |
适用场景 |
|
MobileNetV3 |
轻量、速度快、参数少 |
低 |
很快 |
中等偏高 |
CPU、移动端、边缘部署、低成本服务 |
|
EfficientNet-B0/B1 |
精度和速度平衡好 |
中低 |
快 |
高 |
服务端生产初版 |
|
ResNet18 |
结构简单、稳定、容易训练 |
很低 |
快 |
中等 |
快速验证、Baseline |
|
ConvNeXt-Tiny |
新一代 CNN,精度潜力高 |
中 |
中等 |
高 |
后期追求更高准确率 |
|
YOLO 分类模型 |
工程化方便,训练部署一体化 |
低 |
快 |
中高 |
团队熟悉 YOLO 生态 |
|
CLIP |
图文对齐能力强 |
中高 |
慢 |
不一定最高 |
冷启动、辅助判断 |
|
ViT |
Transformer 图像模型 |
高 |
中慢 |
高但依赖数据 |
大数据、大算力、研究型优化 |
目前这里选择的是MobileNetV3-Large ,它的优势是轻量、推理快、部署简单,对 CPU 友好,非常适合 Java 后端服务调用 ONNX Runtime 进行批量图片方向纠正。EfficientNet-B0 的优势是精度和速度更均衡,适合作为生产初版模型。
不建议第一版直接使用 ViT 或 CLIP。因为这个任务是规则清晰的四分类方向判断,CNN 已经非常适合。ViT 对数据量和训练策略更敏感,CLIP 推理成本较高,而且对精确旋转方向未必比专门训练的小模型稳定。
十一、MobileNetV3 说明
MobileNetV3 是一种轻量级卷积神经网络,主要面向移动端、边缘设备和低成本部署场景。它的核心优势是:
模型小
推理快
对 CPU 友好
部署成本低
训练和调试相对简单在车辆图片自动旋转场景中,输入图片内容比较固定,基本都是车辆;输出类别也很少,只有 0、90、180、270 四类;任务不需要复杂语义理解,只需要判断车辆、地面、车灯、车牌、车窗、车身轮廓等方向性特征。
MobileNetV3 能够学习这些方向性视觉特征。例如正常车辆图片中,通常会有以下规律:
地面在下方
天空或背景在上方
车轮靠下
车灯左右分布
车牌一般是水平的
车标位于车头中部
前挡风玻璃在车头上半部分
进气格栅在中下部当图片旋转 90 度或 270 度时,这些结构会发生明显变化。模型通过训练可以学习到这些规律,从而判断图片需要旋转的角度。
MobileNetV3 有 Small 和 Large 两个常用版本。对于本项目,如果不是部署到非常弱的设备,一般建议优先使用 MobileNetV3-Large。它仍然很轻,但精度通常比 Small 更好。
十二、训练方式
所谓从零训练,就是模型参数完全随机初始化,然后只靠我们自己的车辆图片数据训练。这样通常需要大量数据和较强训练经验,不适合初版项目。
更合理的方式是使用 ImageNet 预训练模型做迁移学习。
基本流程如下:
加载 ImageNet 预训练 MobileNetV3
↓
替换最后分类层
↓
原本输出 1000 类,改成输出 4 类
↓
使用车辆旋转数据微调
↓
保存验证集准确率最好的模型比如 MobileNetV3 原本是用于 ImageNet 1000 类分类,我们只需要把最后分类头替换成 4 分类输出:
0
90
180
270训练策略可以分两阶段:
第一阶段,冻结 backbone,只训练最后分类层。这样训练更稳定,适合刚开始跑通流程。
第二阶段,解冻部分后层,用较低学习率微调。这样可以让模型更适应车辆图片方向识别任务。
如果使用本地电脑训练,没有 GPU 也能跑,只是会慢一些。代码里可以自动判断:
def get_device(device_arg: str | None = None) -> torch.device:
if device_arg:
return torch.device(device_arg)
return torch.device("cuda" if torch.cuda.is_available() else "cpu")也就是:
有 CUDA → 用 GPU
没有 CUDA → 用 CPU训练命令示例:
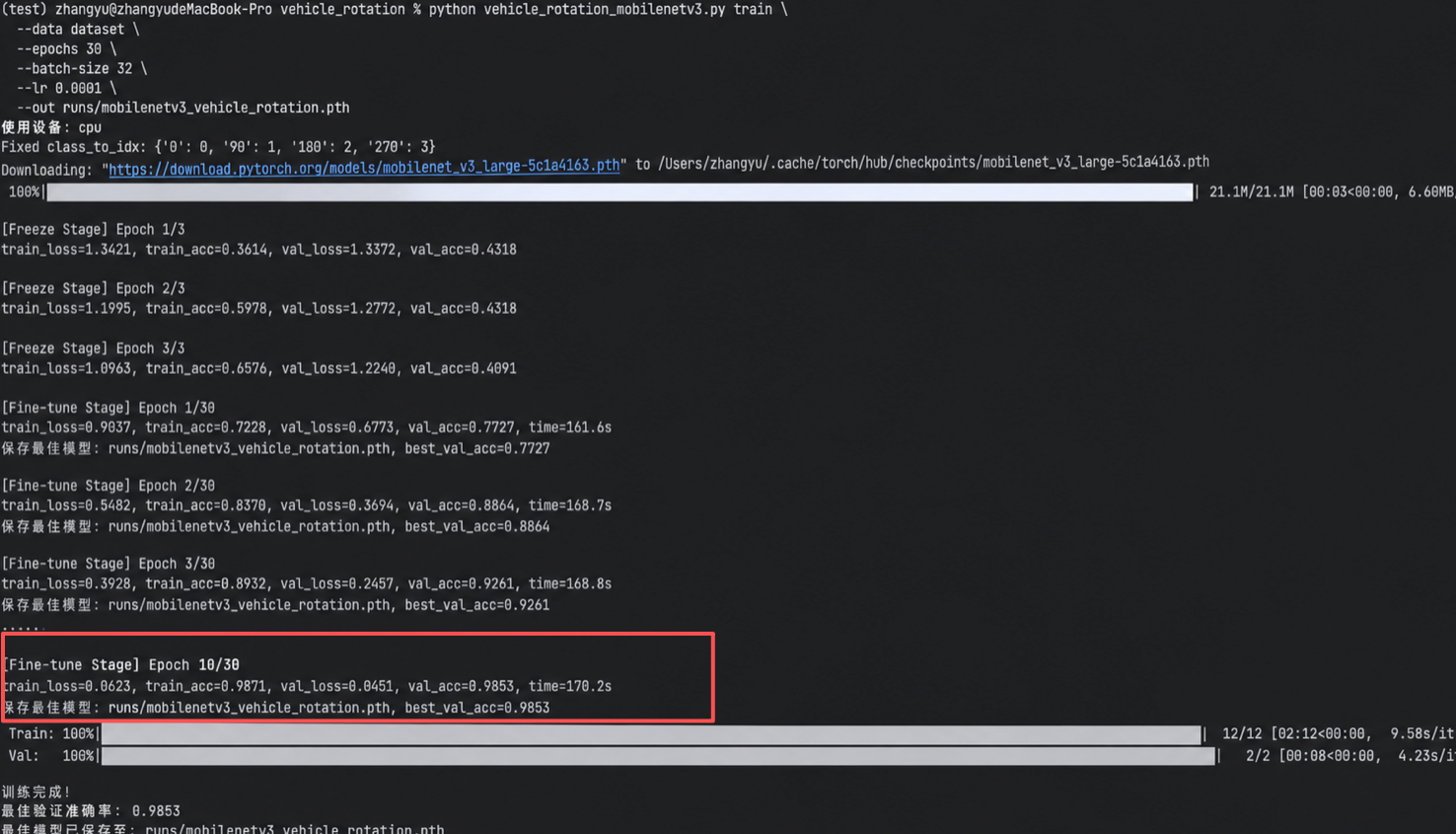
python vehicle_rotation_mobilenetv3.py train \
--data /path/to/dataset \
--epochs 30 \
--batch-size 8 \
--lr 0.0001 \
--out runs/mobilenetv3_vehicle_rotation.pth十三、模型评估
很多初学者训练完模型后,只看一个 accuracy。这个指标当然重要,但在生产系统里远远不够。
本项目至少应该关注以下指标:
|
指标 |
含义 |
|
四分类准确率 |
0、90、180、270 判断是否正确 |
|
precision |
某一类预测结果中有多少是真的 |
|
recall |
某一类真实样本中有多少被识别出来 |
|
f1-score |
precision 和 recall 的综合指标 |
|
confusion matrix |
看哪些类别容易混淆 |
|
自动处理率 |
有多少图片能自动旋转 |
|
自动处理错误率 |
自动旋转部分有多少转错 |
|
后续 AI 识别提升率 |
图片转正后对车牌识别、车辆检测是否有提升 |
评估命令示例:
python vehicle_rotation_mobilenetv3.py eval \
--data /path/to/dataset \
--weights runs/mobilenetv3_vehicle_rotation.pth这个命令不会重新训练模型,只会读取 test 文件夹中的图片,逐张预测方向类别,然后统计准确率、分类报告和混淆矩阵。
评估时尤其要看 90 和 270 是否经常混淆。因为从视觉上看,90 度和 270 度都是横向图片,如果车辆局部特征不明显,模型可能会混淆这两类。
一个比较理想的测试结果可能类似:
总体准确率:98.87%
四类 f1-score:基本都在 98.75% 以上
四类样本数:完全均衡
错误数量:45 / 3988这种结果说明模型在均衡测试集上具有较好的方向判别能力,且不存在明显类别偏置。但即使准确率很高,也不能直接说明可以全量自动旋转。生产系统更关心的是:高置信度自动处理的那部分图片,错误率能不能足够低。
十四、置信度阈值
模型每次预测时,不仅会输出类别,还会输出置信度。例如:
{
"predicted_angle_clockwise": 90,
"confidence": 0.963,
"auto_rotated": true,
"need_manual_review": false
}如果置信度足够高,就自动旋转。如果置信度较低,就不要自动处理,而是进入人工复核。
例如可以设置不同阈值观察效果
因此,生产系统的核心策略应该是:
高置信度自动旋转
低置信度进入人工复核
人工修正结果回流训练集
模型持续迭代备注:对于车辆图片旋转的这个场景来说,因为在未处理前,线上就已经有一部分图片被旋转的图片,那么对于上了分类模型后,当模型置信度达到阈值直接旋转,如果未达到则也不需要进入人工,而是直接忽略,大模型只是对部分少量旋转图片识别准确率不好,但是并不能不能处理该类问题。这是这类场景的策略,如果是其他类,需要结合具体的场景来看,有的可以结合大模型做兜底,有的可能需要进行人工复核。
十五、单张图片推理与自动旋转
训练完成后,可以对单张图片进行推理:
python vehicle_rotation_mobilenetv3.py infer ^
--weights runs/mobilenetv3_vehicle_rotation.pth ^
--image test_car.jpg ^
--out corrected_car.jpg ^
--threshold 0.95返回结果类似:
{
"predicted_angle_clockwise": 90,
"confidence": 0.963,
"auto_rotated": true,
"need_manual_review": false
}含义是:当前图片需要顺时针旋转 90 度才能纠正,模型置信度为 0.963,高于阈值 0.95,因此系统自动旋转图片。
十六、为什么上线推荐 ONNX,而不是直接用 .pth?
训练阶段通常会保存 PyTorch 权重文件:
runs/mobilenetv3_vehicle_rotation.pth但正式上线时,更推荐导出为 ONNX:
runs/mobilenetv3_vehicle_rotation.onnx
runs/mobilenetv3_vehicle_rotation.meta.json导出命令示例:
python vehicle_rotation_mobilenetv3.py export-onnx \
--weights runs/mobilenetv3_vehicle_rotation.pth \
--out runs/mobilenetv3_vehicle_rotation.onnx.pth 和 .onnx 的区别可以这样理解:
|
对比项 |
.pth |
.onnx |
|
主要用途 |
训练、继续微调、本地调试 |
正式推理部署 |
|
是否依赖 PyTorch |
强依赖 |
不强依赖 |
|
是否依赖原始模型代码 |
依赖 |
基本不依赖 |
|
部署语言 |
主要是 Python |
Java、C++、Go、Python 等都可以 |
|
服务端推理 |
可以,但环境较重 |
更推荐 |
|
移动端/跨平台 |
不方便 |
更方便 |
|
性能优化 |
依赖 PyTorch |
可接 ONNX Runtime、TensorRT、OpenVINO |
.pth 是 PyTorch 权重文件,使用它推理时,服务器必须安装 Python、PyTorch、torchvision,并且需要保留模型结构代码。
.onnx 是更适合部署的模型格式。Java 服务可以通过 ONNX Runtime 直接加载 .onnx 模型,不需要 PyTorch 环境,也不需要训练代码。
因此推荐策略是:
训练阶段:使用 .pth
评估阶段:使用 .pth
本地调试:使用 .pth
正式上线推理:优先使用 .onnx同时需要保存 .meta.json,里面记录输入尺寸、类别映射、输出解释等信息。例如:
{
"input_size": 224,
"classes": ["0", "90", "180", "270"],
"id_to_angle": {
"0": 0,
"1": 90,
"2": 180,
"3": 270
}
}服务端推理时,模型输出通常是 logits,需要做 softmax,再取最大概率类别,然后通过 id_to_angle 转成需要顺时针旋转的角度。
十七、Java 推理时要注意的预处理一致性
具体部署的时候,可以使用python的flaskweb服务,也可以使用java来调用部署。Java 部署时,最容易出问题的是图片预处理不一致。
训练时模型看到的图片一般经过以下处理:
resize
center crop 或直接 resize
RGB 转换
归一化
转换为 tensor
通道顺序 CHW
batch 维度 NCHWJava 端必须和训练端保持一致。比如训练时使用 ImageNet 预训练模型,通常会使用以下均值和方差:
mean = [0.485, 0.456, 0.406]
std = [0.229, 0.224, 0.225]Java 端读取图片后,需要将像素值从 0255 转成 01,再做归一化:
R = (R / 255.0 - mean[0]) / std[0]
G = (G / 255.0 - mean[1]) / std[1]
B = (B / 255.0 - mean[2]) / std[2]同时要注意通道顺序。Java 图片读取通常是 HWC,也就是高度、宽度、通道;但 ONNX 模型通常需要 NCHW,也就是:
batch, channel, height, width如果这里写错,模型可能还能跑,但预测结果会非常差,而且很难排查。
十八、Java 图片旋转逻辑
当模型预测角度后,Java 端可以根据 angle 执行旋转:
angle = 0:不旋转
angle = 90:顺时针旋转 90°
angle = 180:旋转 180°
angle = 270:顺时针旋转 270°注意这里要和标签定义保持一致。模型输出的是“为了纠正图片,需要顺时针旋转多少度”,所以 Java 端应该直接按这个角度顺时针旋转。
伪代码如下:
if (confidence < threshold) {
return manualReviewResult(angle, confidence);
}
BufferedImage correctedImage;
switch (angle) {
case 0:
correctedImage = originalImage;
break;
case 90:
correctedImage = rotateClockwise90(originalImage);
break;
case 180:
correctedImage = rotate180(originalImage);
break;
case 270:
correctedImage = rotateClockwise270(originalImage);
break;
default:
throw new IllegalArgumentException("Unsupported angle: " + angle);
}不要在 Java 端再反向理解一遍标签,否则很容易把 90 和 270 搞反。
十九、上线验收标准
为了让这个模型真正可上线,不能只看一次测试集 accuracy。建议制定一套验收标准:
第一,测试集四分类准确率达到业务要求。例如初版可以要求 95% 以上,生产版可以要求 98% 以上。
第二,四类 precision、recall、f1-score 均衡,不能某一类明显偏低。
第三,混淆矩阵中 90 和 270 的混淆不能过高。
第四,在真实业务验收集上测试,而不是只在自动生成的 test 集上测试。
第五,高置信度自动处理错误率低于业务容忍阈值。例如:
confidence > 0.95 时,自动处理错误率 < 0.5%第六,低置信度样本不允许模型“不确定还强行旋转”。
第七,服务端推理耗时满足业务要求。例如单张图片 CPU 推理和旋转总耗时控制在可接受范围内。
第八,模型结果可追踪。每次推理要记录图片 ID、预测角度、置信度、是否自动旋转、是否人工复核、最终人工结果等信息。
第九,模型在进行上线前,要进行高并发压测,避免模型处理速度过慢影响业务系统。
结语
车辆图片旋转角度检测模型看起来只是一个小模型,但它完整覆盖了深度学习项目从 0 到 1 的关键链路:问题定义、标签设计、数据生成、数据划分、模型选择、迁移学习、训练评估、置信度阈值、ONNX 导出、部署和数据闭环。
真正做完这个项目后,我们会发现,深度学习模型落地并不是只写几行训练代码。一个可用的模型系统,必须同时回答以下问题:
数据从哪里来?
标签如何定义?
训练集和测试集是否泄漏?
模型为什么这样选?
训练效果怎么判断?
置信度阈值怎么设置?
低置信度样本怎么办?
模型如何部署到线上服务?
线上错误样本如何回流?
后续如何持续优化?只要把这些问题逐一解决,车辆图片自动旋转就不再是一个抽象的 AI 概念,而会变成一个稳定、快速、可部署、可迭代的工程能力。
踩坑整理
数据集准备
1:数据标签容易定义错。标签不是“图片当前旋转了多少度”,而是“为了把图片纠正回来,需要顺时针旋转多少度”。
2:数据集不需要四个旋转角度都整理很多图片,只需要搜集正确视角的图片,然后通过工具代码自动对正确的图片进行旋转生成其他三个视角的图片
3:各个分类数据数量和质量要均衡,数据集要覆盖各类情况,不要仅挑选清晰拍摄规范的图片。
训练批次大小设置
训练时 batch-size 不能盲目设置太大。batch-size 越大,占用的显存或内存越高。本地电脑性能有限时,如果 batch-size 设置过大,训练过程可能会变慢,甚至直接被系统 kill 掉。
如果是本地电脑或者显存较小,可以把 batch-size 设置为 8。训练轮次可以先设置 30,但不一定必须训练满 30 轮。应该观察每一轮的验证集准确率,如果验证集准确率已经很高并且不再提升,就可以提前停止。
踩坑:我的本地是MAC电脑,设置的批次过大导致训练过程中出现了 zsh: killed 的问题为了解决该问题,最终将 batch-size 从 32 调整为 8,并建议后续逐步尝试 16,而不是直接使用 32。同时建议训练时保持插电、不合盖,并减少 DataLoader 的 num_workers 数量,以提高训练稳定性

训练时间
训练时间和电脑性能、数据量、batch-size、epoch 数量都有关系。本地 CPU 或普通电脑训练会比较慢,完整跑 30 个 epoch 可能需要较长时间。
训练时不一定必须跑满所有 epoch,应该重点观察每一轮的验证集准确率。如果验证集准确率已经很高,并且连续多轮提升不明显,就可以提前停止训练。否则继续训练只会浪费时间,还可能出现过拟合。
实际训练时建议关注:
train_loss
train_acc
val_loss
val_acc其中最重要的是 val_acc。模型保存时也应该优先保存验证集准确率最高的一轮,而不是训练集准确率最高的一轮。
|
指标 |
名称 |
含义 |
理想变化趋势 |
说明 |
|
train_loss |
训练损失 |
模型在训练集上的平均预测误差 |
↓逐渐减小 |
反映模型对训练样本的拟合程度,数值越小说明预测结果越接近真实标签 |
|
train_acc |
训练准确率 |
模型在训练集上的分类正确率 |
↑逐渐增大 |
衡量模型学习训练样本特征的能力,准确率越高表示训练效果越好 |
|
val_loss |
验证损失 |
模型在验证集上的平均预测误差 |
↓逐渐减小 |
用于评估模型在未参与训练数据上的泛化能力,是判断过拟合的重要指标 |
|
val_acc |
验证准确率 |
模型在验证集上的分类正确率 |
↑逐渐增大 |
反映模型在未知样本上的实际分类性能,通常作为模型选择和保存的主要依据 |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)