ICLR 2026 | 时间序列预测新思路:改数据不改模型,TATO降低13.6%平均MSE
论文聚焦时间序列预测中的大时间序列模型(LTMs)零样本/跨域应用问题。LTMs虽能用单一预训练模型服务多任务,但真实时间序列存在强多样性与非平稳性,不同领域的周期、趋势、异常和尺度差异明显,导致冻结模型在新域上精度与泛化难兼顾。
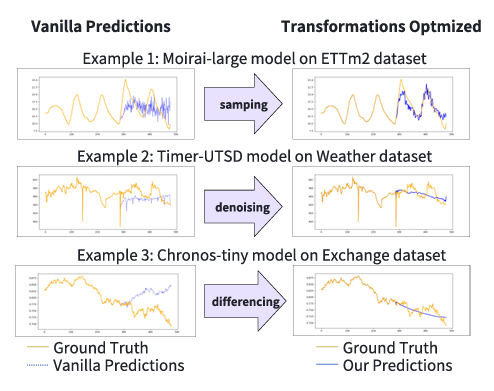
现有做法常对每个领域微调LTM,但会增加训练成本、产生多个模型实例,并可能削弱通用性。作者的核心动机是:不改模型参数,而是通过自动优化输入数据变换,让数据更适配冻结LTM。图1展示了下采样、异常修正、差分等变换可明显改善预测,说明数据侧适配有潜力。

另外我整理了,科研工具资料包:写作/阅读/编码/文献/实验/绘图,全流程照搬,感兴趣的dd,希望能帮到你!
二、核心方法
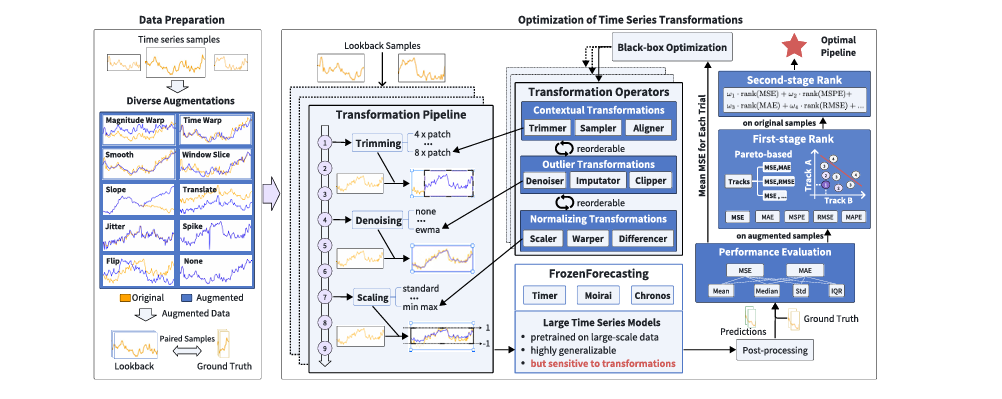
整体思路:TATO在时间序列预处理域搜索最优变换流水线,使单个冻结LTM适配不同下游领域。
核心优化目标为: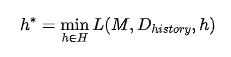
其中,(M)为冻结LTM,(H)为变换流水线配置空间,(h)为候选流水线,(D_{history})用于搜索,(D_{future})仅用于最终测试。
TATO包含三类九种算子:
-
上下文切片:Trimmer、Sampler、Aligner,调整回看长度、采样频率和patch对齐。
-
尺度归一化:Scaler、Differencer、Warper,处理尺度、趋势和方差不稳定。
-
异常处理:Imputator、Denoiser、Clipper,缓解异常点和噪声影响。
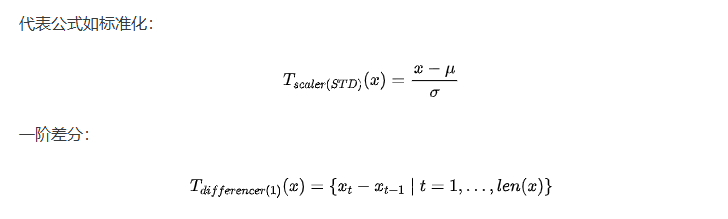
流程上,TATO先对历史样本做增强,如翻转、扭曲、噪声、平移、加斜率,以提升搜索鲁棒性;再用TPE等黑盒超参数优化搜索流水线;最后用两阶段Pareto排序筛选候选。第一阶段在增强样本和多指标上剔除风险流水线,第二阶段只在原始样本上按MSE、MAE等加权排序。
三、实验验证与效果
实验覆盖ETT四个子集、Electricity、Exchange、Traffic、Weather,模型包括Timer-UTSD、Timer-LOTSA、Moirai-small/base/large、Chronos-tiny。评价指标包括MSE、MAE及其统计量。
相对提升定义为: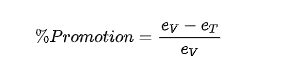
其中 (e_V) 为原始冻结LTM误差,(e_T) 为使用TATO后的误差。结果显示,TATO在96个主要评估项中84.3%不低于基线,平均MSE降低13.6%,最高在Exchange上降低65.4%。
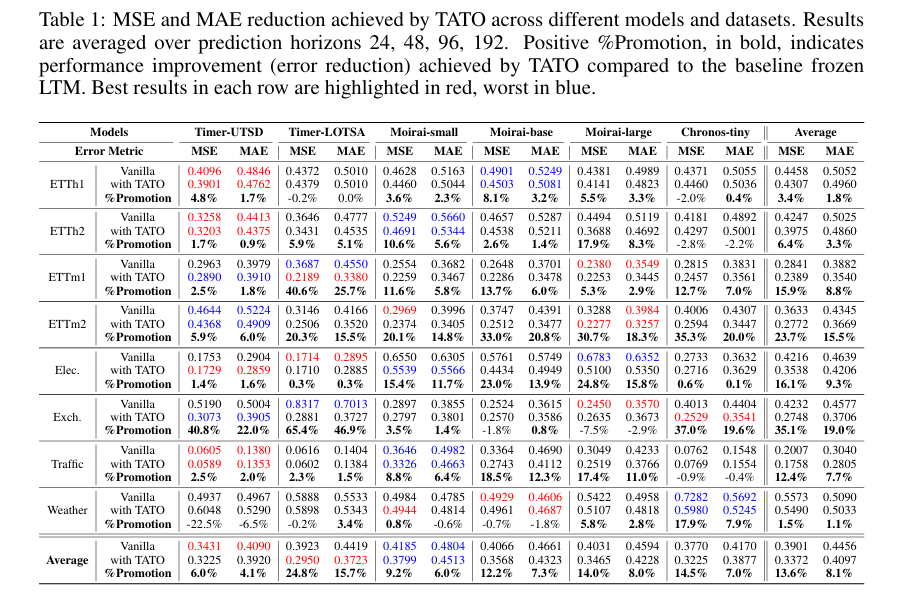
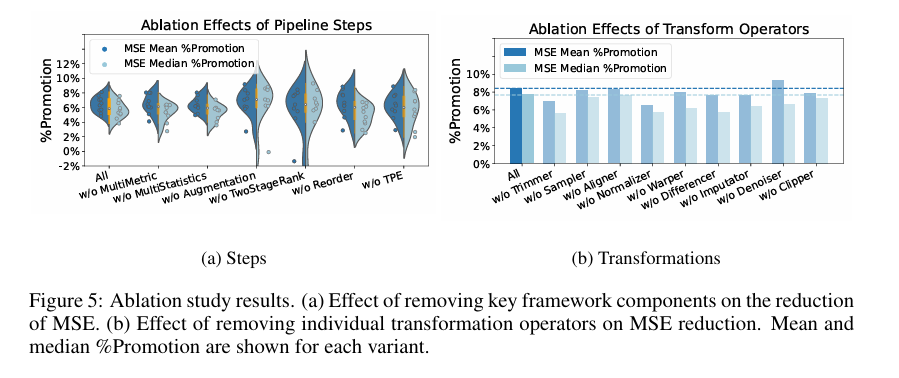
效率方面,多数优化在120秒内完成;推理阶段额外变换开销在batch size为1时低于3毫秒。消融实验表明,Trimmer和Scaler很关键;两阶段排序虽不一定带来最高均值提升,但能增强稳定性。
四、小编总结
这篇论文的重点不是再训练一个更强模型,而是提出“让数据适配模型”的TATO框架。它通过自动搜索时间序列变换流水线,在保持LTM冻结的前提下提升跨域预测效果。实验说明,该方法轻量、通用,并能与微调互补,适合需要单一基础模型服务多个时间序列领域的场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)