2001年高教社杯全国大学生数学建模竞赛 B 题:《公交车调度》真题解析与 MATLAB 解决方案

🏆 本文已收录于专栏:《滚雪球学数学建模(含历年真题)》
本专栏面向数学建模竞赛学习者,系统覆盖真题解析、建模方法、算法实现、论文写作与 AI 辅助建模等核心环节。无论是建模新手,还是备战华为杯、高教社杯、华数杯、国赛、美赛 MCM/ICM 的参赛者,都能在这里找到清晰、完整、可复用的建模思路,持续更新,长期有效。
🎯 免责声明: 本文题目来源于互联网公开内容,仅供学习交流与建模方法研究,不构成竞赛指导。请遵守相关赛事规则,独立完成竞赛作品,使用本文内容所产生的后果由使用者自行承担。
🎉 专栏限时优惠中:一次订阅,永久解锁,后续内容持续更新。 欢迎点击了解 👉 查看专栏详情 👈
全文目录:
2001年B题:公交车调度
真题展示
如下为原(真)题,展示如下:

一、前言:为什么这道题值得深入分析?
很多同学第一次看到公交调度题,会觉得"不就是安排发车时间吗?"然后直接打开MATLAB开始编程。
这是建模中最常见的误区之一。
这道题表面上是一个"发车计划"问题,但本质上涉及多个层次的建模挑战:
- 客流的时空分布特征提取:数据有上行、下行两个方向,有18个时间段,有14/13个站点——这本身就是一个多维数据分析问题;
- 载客约束的动态建模:公交车不是空车发出就行了,它要在沿途各站上下乘客,某个区段的实际载客量必须满足容量约束(≤120%)和下限约束(≥50%),这是一个动态约束,而不是简单的静态上限;
- 多目标权衡:乘客希望等待时间短(多发车),公司希望成本低(少发车),这是一个典型的双方利益博弈与权衡;
- 峰平谷差异化调度:早晚高峰与平峰时段的客流差距可达5~10倍,统一发车间隔显然不合理,必须分时段建模。
正是因为这道题涵盖了数据处理、动态约束建模、整数规划、多目标优化等核心建模技术,它成为了历年建模教学中的经典案例。
掌握这道题,你就基本掌握了调度类问题的通用建模框架。
二、题目背景与现实意义
公共交通是城市运转的血脉。对于一条固定公交线路,如何科学合理地安排发车计划,直接影响:
- 乘客体验:等候时间是否合理?高峰期是否拥挤?
- 运营成本:车辆数是否最省?空载率是否过高?
- 社会效益:能否引导更多人选择公交出行?
题目给出了某特大城市一条公交线路一个工作日的逐小时、逐站点客流数据,要求我们:
- 设计全天发车刻表(两个方向的始发站发车时刻);
- 确定所需总车辆数;
- 评估方案对乘客和公司双方利益的满足程度。
这不是一道"做完就扔"的练习题。在现实中,北京、上海、广州等城市的公交公司每年都会根据客流数据重新优化调度方案,其数学本质与本题完全一致。
三、题目重述
3.1 已知条件
根据题目图片信息,整理如下:
| 条件项 | 内容 |
|---|---|
| 线路方向 | 上行:A13→A0(14站),下行:A0→A13(13站) |
| 时间范围 | 5:00—23:00,共18个小时时段 |
| 车辆类型 | 同一型号大客车,标准载客100人 |
| 平均速度 | 20公里/小时 |
| 最大载客率 | 不超过120%(即最多载120人) |
| 最低载客率 | 一般不低于50%(即至少50人,空载不合算) |
| 候车时间要求 | 一般不超过10分钟,早晚高峰不超过5分钟 |
| 数据内容 | 每小时每站上下车人数(上行14站,下行13站) |
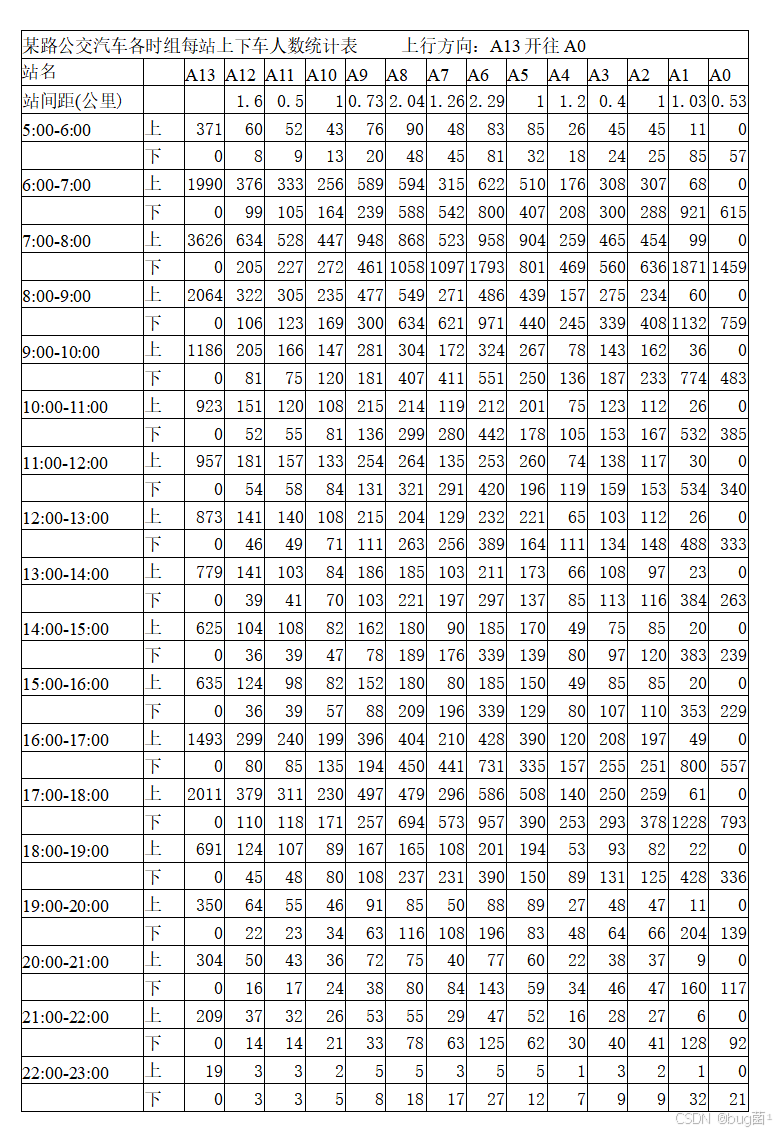
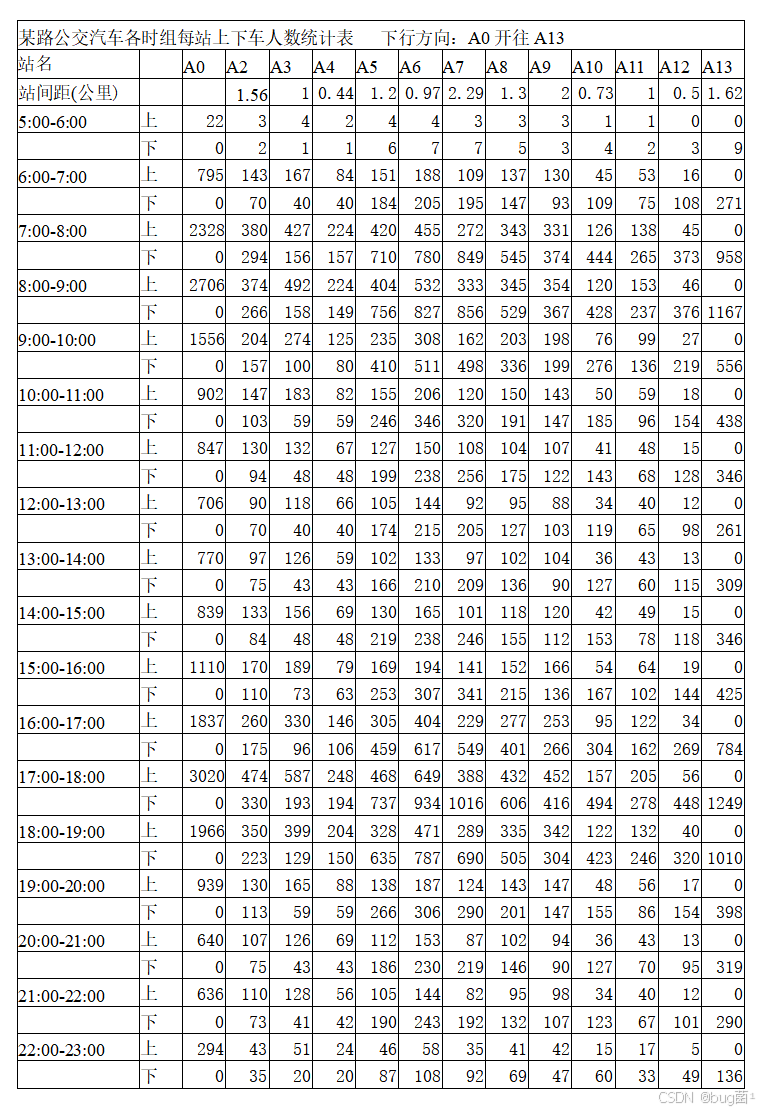
站间距离(上行方向,公里):
A13出发,依次经过A12(1.6)、A11(0.5)、A10(1)、A9(0.73)、A8(2.04)、A7(1.26)、A6(2.29)、A5(1)、A4(1.2)、A3(0.4)、A2(1)、A1(1.03)、A0(0.53)
全程距离约:1.6+0.5+1+0.73+2.04+1.26+2.29+1+1.2+0.4+1+1.03+0.53 ≈ 14.58公里
单程行驶时间约:14.58/20 × 60 ≈ 43.7分钟,取约44分钟。
3.2 待解决问题
问题一:设计全天(工作日)公交调度方案,包括:
- 上行(A13→A0)始发站发车刻表;
- 下行(A0→A13)始发站发车刻表;
- 共需多少辆车。
问题二:评估该方案对乘客和公交公司双方利益的兼顾程度。
问题三:将调度问题抽象为数学模型,指出求解方法;并讨论如果要设计更好的调度方案,应如何采集运营数据。
3.3 附件数据说明
题目提供了两张统计表:
表一(上行方向,A13→A0):
- 行:5:00—23:00 共18个时间段,每段分"上(boarding)"和"下(alighting)"两行;
- 列:A13、A12、…、A0 共14个站点;
- 数值:该时段在该站上/下车的总人次。
表二(下行方向,A0→A13):
- 类似结构,13个站点(A0→A13),注意站间距与上行略有不同。
⚠️ 重要提示:这里的数据是一小时内的累计人次,不是单趟车的载客量。我们在建模时需要将"每小时客流总量"转化为"每辆次车的载客量",这一步很关键,也是很多同学忽略的地方。
四、问题分析
4.1 问题一分析
核心:确定每个时段的发车间隔,进而得到发车刻表,最后计算所需车辆总数。
关键变量:
- 每小时发车班次 n k n_k nk(第 k k k 个时段, k = 1 , . . . , 18 k=1,...,18 k=1,...,18);
- 发车间隔 Δ t k = 60 / n k \Delta t_k = 60/n_k Δtk=60/nk(分钟);
- 每班次在各区段的载客量 L k , j L_{k,j} Lk,j(第 k k k 时段第 j j j 区段)。
约束:
- 载客率约束: 50 ≤ L k , j ≤ 120 50 \leq L_{k,j} \leq 120 50≤Lk,j≤120;
- 候车时间约束: Δ t k ≤ 10 \Delta t_k \leq 10 Δtk≤10(平峰), Δ t k ≤ 5 \Delta t_k \leq 5 Δtk≤5(高峰);
- 发车班次为正整数: n k ∈ Z + n_k \in \mathbb{Z}^+ nk∈Z+。
逻辑:给定时段 k k k 的发车间隔 Δ t k \Delta t_k Δtk,每班次服务的乘客数约为总客流量/班次数,由此可验证载客率约束。
4.2 问题二分析
核心:建立评价指标体系,量化"乘客满意度"和"公司运营效益"。
典型指标:
- 乘客角度:平均候车时间、高峰时段满载率、拒载率;
- 公司角度:车辆总数、总车公里、平均载客率、空载率。
这是一个多目标评价问题,不能只看一个指标。
4.3 问题三分析
核心:用规范的数学语言描述上述调度问题,构建整数规划模型;并讨论数据采集改进方向。
这要求我们能从"调度方案"上升到"优化模型"的抽象层次,体现对数学建模本质的理解。
4.4 各问题之间的逻辑关系
具体相关示意图绘制如下,仅供参考:
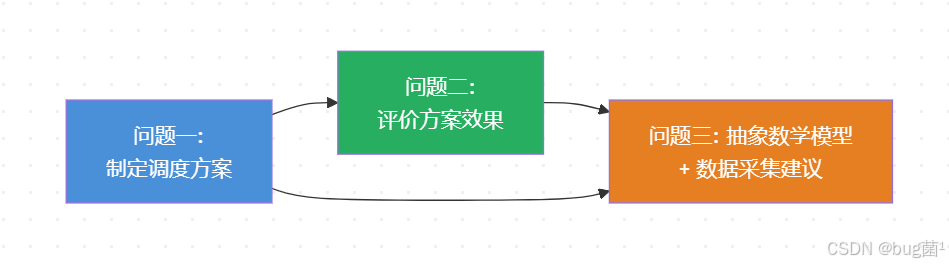
三个问题是递进关系:先做出方案(问题一),再评价方案优劣(问题二),最后上升到理论模型层面并提出改进建议(问题三)。这是数学建模竞赛非常经典的"做方案→评方案→优方案"结构。
五、整体建模思路
5.1 建模路线
具体相关示意图绘制如下,仅供参考:
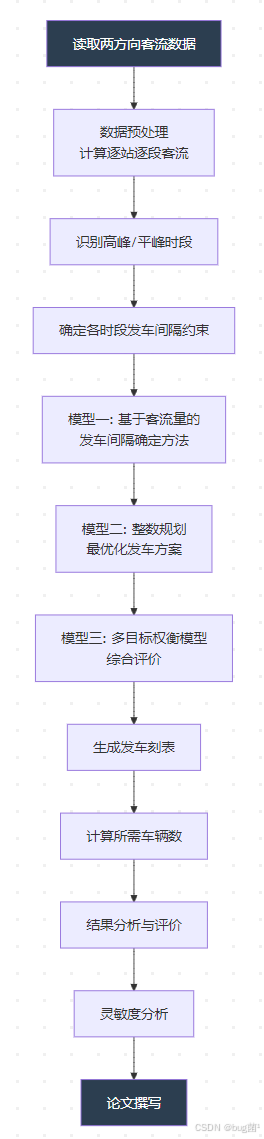
5.2 模型选择依据
| 模型类型 | 适用场景 | 本题适用性 |
|---|---|---|
| 基于客流的启发式方法 | 快速得到可行解,直觉性强 | ✅ 适合初步方案 |
| 整数线性规划(ILP) | 有明确目标函数和约束 | ✅ 适合求最优方案 |
| 多目标优化(加权法/帕累托) | 存在多个冲突目标 | ✅ 适合评价与权衡 |
| 仿真模型 | 需要精确模拟乘客行为 | ⚠️ 数据不足时慎用 |
5.3 算法实现思路
- 先用客流平衡法计算每时段最小所需班次;
- 再用整数规划在满足所有约束下最小化总班次;
- 用加权评分法综合评价乘客和公司双方利益;
- 用参数扰动做灵敏度分析。
5.4 结果验证方法
- 验证每班次各区段载客量是否在 [50, 120] 范围内;
- 验证发车间隔是否满足候车时间要求;
- 与实际城市公交数据对比(如有);
- 做参数扰动(载客率上限变化10%)观察方案稳定性。
六、数据预处理
6.1 数据说明
原始数据是每小时每站上下车总人次。我们需要:
步骤一:从原始数据推算每小时该方向的最大断面流量(即某区间同时在车上的最多人数),以此确定该时段至少需要多少班次。
步骤二:计算每班次平均服务的乘客数(总客流量 ÷ 班次数)。
6.2 关键数据处理:动态载客量计算
对于上行方向(A13→A0),第 k k k 时段,从A13出发的一列公交车,在到达第 j j j 站时,车上的乘客数为:
L k ( j ) = ∑ i = 1 j B k , i up − ∑ i = 1 j A k , i up L_{k}(j) = \sum_{i=1}^{j} B_{k,i}^{\text{up}} - \sum_{i=1}^{j} A_{k,i}^{\text{up}} Lk(j)=i=1∑jBk,iup−i=1∑jAk,iup
其中:
- B k , i up B_{k,i}^{\text{up}} Bk,iup:第 k k k 时段在第 i i i 站上车人数(boarding);
- A k , i up A_{k,i}^{\text{up}} Ak,iup:第 k k k 时段在第 i i i 站下车人数(alighting)。
⚠️ 注意:这里计算的是整个时段所有班次的累计,要转换为单班次载客量,需除以该时段的班次数 n k n_k nk。
最大区段载客量(决定是否满足容量约束):
L k max = max j [ 1 n k ⋅ L k ( j ) ] L_{k}^{\max} = \max_{j} \left[ \frac{1}{n_k} \cdot L_{k}(j) \right] Lkmax=jmax[nk1⋅Lk(j)]
6.3 高峰/平峰识别
观察数据,从始发站(A13上行)各时段上车人数:
| 时段 | A13上行上车人数 | 判断 |
|---|---|---|
| 5:00-6:00 | 371 | 低峰 |
| 6:00-7:00 | 1990 | 高峰 |
| 7:00-8:00 | 3626 | 早高峰顶峰 |
| 8:00-9:00 | 2064 | 高峰 |
| 9:00-10:00 | 1186 | 次高峰 |
| 10:00-16:00 | 600~950 | 平峰 |
| 16:00-17:00 | 1493 | 晚高峰前 |
| 17:00-18:00 | 2011 | 晚高峰顶峰 |
| 18:00-19:00 | 691 | 高峰后 |
| 19:00-22:00 | 350~640 | 平峰 |
| 22:00-23:00 | 19 | 末班低峰 |
具体相关示意图绘制如下,仅供参考:
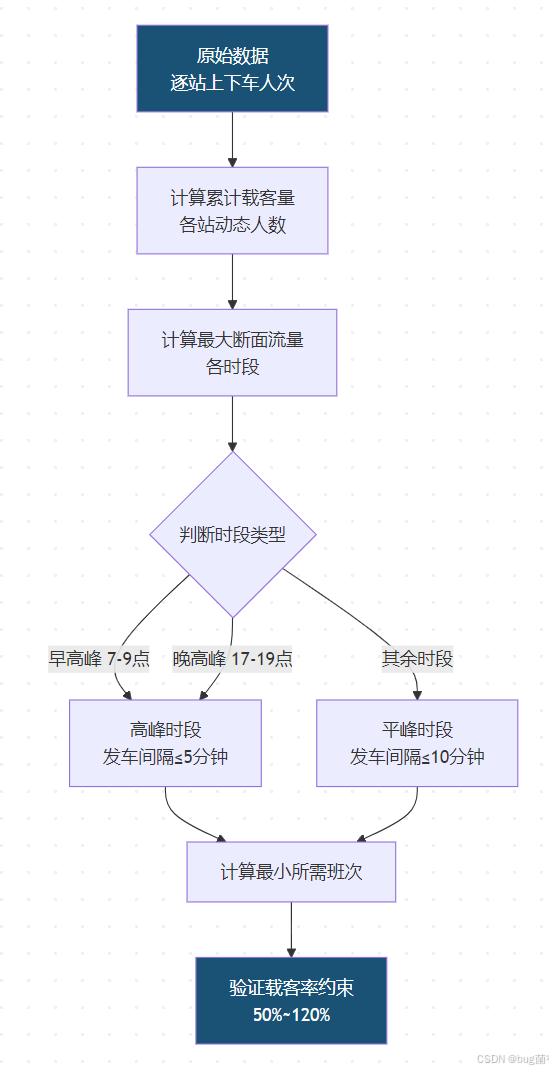
6.4 MATLAB 数据读取与预处理代码
% data_preprocess.m
% 功能:读取并预处理公交客流数据
% 输入:Excel数据文件(或手工录入矩阵)
% 输出:各时段各站上下车矩阵,以及断面流量
function [board_up, alight_up, board_dn, alight_dn] = data_preprocess()
% ============================================================
% 上行方向(A13 → A0)数据录入
% 行:时段1~18(5:00-6:00 到 22:00-23:00)
% 列:站点 A13, A12, A11, A10, A9, A8, A7, A6, A5, A4, A3, A2, A1, A0
% ============================================================
% 上车人数矩阵(18个时段 × 14个站点)
board_up = [
371 60 52 43 76 90 48 83 85 26 45 45 11 0; % 5:00-6:00
1990 376 333 256 589 594 315 622 510 176 308 307 68 0; % 6:00-7:00
3626 634 528 447 948 868 523 958 904 259 465 454 99 0; % 7:00-8:00
2064 322 305 235 477 549 271 486 439 157 275 234 60 0; % 8:00-9:00
1186 205 166 147 281 304 172 324 267 78 143 162 36 0; % 9:00-10:00
923 151 120 108 215 214 119 212 201 75 123 112 26 0; % 10:00-11:00
957 181 157 133 254 264 135 253 260 74 138 117 30 0; % 11:00-12:00
873 141 140 108 215 204 129 232 221 65 103 112 26 0; % 12:00-13:00
779 141 103 84 186 185 103 211 173 66 108 97 23 0; % 13:00-14:00
625 104 108 82 162 180 90 185 170 49 75 85 20 0; % 14:00-15:00
635 124 98 82 152 180 80 185 150 49 85 85 20 0; % 15:00-16:00
1493 299 240 199 396 404 210 428 390 120 208 197 49 0; % 16:00-17:00
2011 379 311 230 497 479 296 586 508 140 250 259 61 0; % 17:00-18:00
691 124 107 89 167 165 108 201 194 53 93 82 22 0; % 18:00-19:00
350 64 55 46 91 85 50 88 89 27 48 47 11 0; % 19:00-20:00
304 50 43 36 72 75 40 77 60 22 38 37 9 0; % 20:00-21:00
209 37 32 26 53 55 29 47 52 16 28 27 6 0; % 21:00-22:00
19 3 3 2 5 5 3 5 5 1 3 2 1 0; % 22:00-23:00
];
% 下车人数矩阵(18个时段 × 14个站点)
alight_up = [
0 8 9 13 20 48 45 81 32 18 24 25 85 57; % 5:00-6:00
0 99 105 164 239 588 542 800 407 208 300 288 921 615; % 6:00-7:00
0 205 227 272 461 1058 1097 1793 801 469 560 636 1871 1459; % 7:00-8:00
0 106 123 169 300 634 621 971 440 245 339 408 1132 759; % 8:00-9:00
0 81 75 120 181 407 411 551 250 136 187 233 774 483; % 9:00-10:00
0 52 55 81 136 299 280 442 178 105 153 167 532 385; % 10:00-11:00
0 54 58 84 131 321 291 420 196 119 159 153 534 340; % 11:00-12:00
0 46 49 71 111 263 256 389 164 111 134 148 488 333; % 12:00-13:00
0 39 41 70 103 221 197 297 137 85 113 116 384 263; % 13:00-14:00
0 36 39 47 78 189 176 339 139 80 97 120 383 239; % 14:00-15:00
0 36 39 57 88 209 196 339 129 80 107 110 353 229; % 15:00-16:00
0 80 85 135 194 450 441 731 335 157 255 251 800 557; % 16:00-17:00
0 110 118 171 257 694 573 957 390 253 293 378 1228 793; % 17:00-18:00
0 45 48 80 108 237 231 390 150 89 131 125 428 336; % 18:00-19:00
0 22 23 34 63 116 108 196 83 48 64 66 204 139; % 19:00-20:00
0 16 17 24 38 80 84 143 59 34 46 47 160 117; % 20:00-21:00
0 14 14 21 33 78 63 125 62 30 40 41 128 92; % 21:00-22:00
0 3 3 5 8 18 17 27 12 7 9 9 32 21; % 22:00-23:00
];
% ============================================================
% 下行方向(A0 → A13)数据录入(13站)
% 列:A0, A2, A3, A4, A5, A6, A7, A8, A9, A10, A11, A12, A13
% ============================================================
board_dn = [
22 3 4 2 4 4 3 3 3 1 1 0 0; % 5:00-6:00
795 143 167 84 151 188 109 137 130 45 53 16 0; % 6:00-7:00
2328 380 427 224 420 455 272 343 331 126 138 45 0; % 7:00-8:00
2706 374 492 224 404 532 333 345 354 120 153 46 0; % 8:00-9:00
1556 204 274 125 235 308 162 203 198 76 99 27 0; % 9:00-10:00
902 147 183 82 155 206 120 150 143 50 59 18 0; % 10:00-11:00
847 130 132 67 127 150 108 104 107 41 48 15 0; % 11:00-12:00
706 90 118 66 105 144 92 95 88 34 40 12 0; % 12:00-13:00
770 97 126 59 102 133 97 102 104 36 43 13 0; % 13:00-14:00
839 133 156 69 130 165 101 118 120 42 49 15 0; % 14:00-15:00
1110 170 189 79 169 194 141 152 166 54 64 19 0; % 15:00-16:00
1837 260 330 146 305 404 229 277 253 95 122 34 0; % 16:00-17:00
3020 474 587 248 468 649 388 432 452 157 205 56 0; % 17:00-18:00
1966 350 399 204 328 471 289 335 342 122 132 40 0; % 18:00-19:00
939 130 165 88 138 187 124 143 147 48 56 17 0; % 19:00-20:00
640 107 126 69 112 153 87 102 94 36 43 13 0; % 20:00-21:00
636 110 128 56 105 144 82 95 98 34 40 12 0; % 21:00-22:00
294 43 51 24 46 58 35 41 42 15 17 5 0; % 22:00-23:00
];
alight_dn = [
0 2 1 1 6 7 7 5 3 4 2 3 9; % 5:00-6:00
0 70 40 40 184 205 195 147 93 109 75 108 271; % 6:00-7:00
0 294 156 157 710 780 849 545 374 444 265 373 958; % 7:00-8:00
0 266 158 149 756 827 856 529 367 428 237 376 1167; % 8:00-9:00
0 157 100 80 410 511 498 336 199 276 136 219 556; % 9:00-10:00
0 103 59 59 246 346 320 191 147 185 96 154 438; % 10:00-11:00
0 94 48 48 199 238 256 175 122 143 68 128 346; % 11:00-12:00
0 70 40 40 174 215 205 127 103 119 65 98 261; % 12:00-13:00
0 75 43 43 166 210 209 136 90 127 60 115 309; % 13:00-14:00
0 84 48 48 219 238 246 155 112 153 78 118 346; % 14:00-15:00
0 110 73 63 253 307 341 215 136 167 102 144 425; % 15:00-16:00
0 175 96 106 459 617 549 401 266 304 162 269 784; % 16:00-17:00
0 330 193 194 737 934 1016 606 416 494 278 448 1249; % 17:00-18:00
0 223 129 150 635 787 690 505 304 423 246 320 1010; % 18:00-19:00
0 113 59 59 266 306 290 201 147 155 86 154 398; % 19:00-20:00
0 75 43 43 186 230 219 146 90 127 70 95 319; % 20:00-21:00
0 73 41 42 190 243 192 132 107 123 67 101 290; % 21:00-22:00
0 35 20 20 87 108 92 69 47 60 33 49 136; % 22:00-23:00
];
fprintf('✅ 数据录入完成:上行 %d 时段 × %d 站,下行 %d 时段 × %d 站\n', ...
size(board_up,1), size(board_up,2), size(board_dn,1), size(board_dn,2));
end
代码解析:
这段代码做了三件事:
- 将图片中的原始数字手动录入为矩阵,行是时段,列是站点;
- 上行14个站点(A13到A0),下行13个站点(A0到A13,注意A1站在下行数据中未单独出现);
- 分别保存上车(boarding)和下车(alighting)数据。
⚠️ 初学者注意:数据录入时最容易出错的是行列对应关系。建议录入后用
sum(board_up(:))和手工加总核对,确保数字无误。实际比赛中如果有Excel附件,应用readtable或xlsread直接读取,避免手工录入错误。
七、模型假设
- 平稳性假设:同一小时内,乘客均匀到达各站,即每班次服务的客流量约等于该时段总客流量除以班次数;
- 单向行驶假设:上行和下行独立调度,不考虑调头时间(端站有足够空间);
- 匀速行驶假设:全程平均速度20公里/小时,忽略堵车和信号灯影响;
- 容量刚性假设:每辆车标准载客100人,最多120人(120%),不考虑加挂;
- 乘客理性假设:乘客按需求上车,不会因满载拒绝搭乘(拒载情况在评价时作为惩罚项);
- 数据代表性假设:所给数据代表典型工作日,不考虑节假日或异常天气;
- 车辆同质性假设:所有车辆性能相同,不考虑不同型号车辆混用;
- 调度连续性假设:发车计划在每个时段内均匀分布,不考虑随机发车。
八、符号说明
| 符号 | 含义 | 单位 |
|---|---|---|
| K K K | 时段总数(=18) | — |
| k k k | 时段编号, k = 1 , . . . , 18 k=1,...,18 k=1,...,18 | — |
| J J J | 上行站点总数(=14),下行(=13) | — |
| j j j | 站点编号 | — |
| C C C | 车辆标准载客量(=100) | 人 |
| α \alpha α | 最大载客率(=1.2) | — |
| β \beta β | 最低载客率(=0.5) | — |
| B k , j u p B_{k,j}^{up} Bk,jup | 上行第 k k k 时段第 j j j 站上车人数 | 人次 |
| A k , j u p A_{k,j}^{up} Ak,jup | 上行第 k k k 时段第 j j j 站下车人数 | 人次 |
| n k u p n_k^{up} nkup | 上行第 k k k 时段发车班次数 | 班 |
| n k d n n_k^{dn} nkdn | 下行第 k k k 时段发车班次数 | 班 |
| Δ t k \Delta t_k Δtk | 第 k k k 时段发车间隔 | 分钟 |
| L k ( j ) L_k(j) Lk(j) | 第 k k k 时段车辆到达第 j j j 站时的累计载客量 | 人次 |
| L k max L_k^{\max} Lkmax | 第 k k k 时段最大断面载客量(单班次) | 人 |
| T t r i p T_{trip} Ttrip | 单程运行时间 | 分钟 |
| T w a i t T_{wait} Twait | 端站折返等待时间 | 分钟 |
| T c y c l e T_{cycle} Tcycle | 单辆车完整运营周期 | 分钟 |
| N t o t a l N_{total} Ntotal | 所需总车辆数 | 辆 |
| W p W_p Wp | 乘客权重系数(多目标模型) | — |
| W c W_c Wc | 公司权重系数(多目标模型) | — |
九、模型一:基于客流的发车间隔确定方法(基础模型)
9.1 模型思想
这类题目最直接的建模思路:从"需求决定供给"出发。
给定某时段的总客流量,如果发车间隔为 Δ t \Delta t Δt(分钟),则一小时内发 n = 60 / Δ t n = 60/\Delta t n=60/Δt 班。每班次在最拥挤区段(最大断面)上的载客量 L max L^{\max} Lmax 必须满足容量约束。
同时,发车间隔 Δ t \Delta t Δt 还受候车时间约束上限限制。
这两个约束共同确定了每个时段的合理发车间隔范围,在此范围内取整数班次。
9.2 数学表达式
第一步:计算第 k k k 时段最大断面累计客流
F k = max j = 1 J − 1 ( ∑ i = 1 j B k , i − ∑ i = 1 j A k , i ) F_k = \max_{j=1}^{J-1} \left( \sum_{i=1}^{j} B_{k,i} - \sum_{i=1}^{j} A_{k,i} \right) Fk=j=1maxJ−1(i=1∑jBk,i−i=1∑jAk,i)
F k F_k Fk 是第 k k k 时段所有班次在最拥挤区间段的总需求人次,代表该时段在路网上同时行驶的乘客总量峰值。
第二步:由容量约束确定最小班次数
单班次最大载客量为 α ⋅ C \alpha \cdot C α⋅C,所以满足容量约束的最小班次数为:
n k min , cap = ⌈ F k α ⋅ C ⌉ n_k^{\min,\text{cap}} = \left\lceil \frac{F_k}{\alpha \cdot C} \right\rceil nkmin,cap=⌈α⋅CFk⌉
向上取整,因为班次数必须是整数,且必须足够覆盖所有乘客。
第三步:由候车时间约束确定最小班次数
n k min , wait = ⌈ 60 Δ t k max ⌉ n_k^{\min,\text{wait}} = \left\lceil \frac{60}{\Delta t_k^{\max}} \right\rceil nkmin,wait=⌈Δtkmax60⌉
其中高峰时段 Δ t k max = 5 \Delta t_k^{\max} = 5 Δtkmax=5,平峰时段 Δ t k max = 10 \Delta t_k^{\max} = 10 Δtkmax=10。
第四步:确定实际班次数
取两个约束的较大值:
n k = max ( n k min , cap , n k min , wait ) n_k = \max\left( n_k^{\min,\text{cap}},\ n_k^{\min,\text{wait}} \right) nk=max(nkmin,cap, nkmin,wait)
第五步:验证最低载客率约束
每班次平均载客量(用最大断面估计):
L ˉ k = F k n k \bar{L}_k = \frac{F_k}{n_k} Lˉk=nkFk
需满足: L ˉ k ≥ β ⋅ C = 50 \bar{L}_k \geq \beta \cdot C = 50 Lˉk≥β⋅C=50
若不满足(即客流太少、班次太多),则应适当减少班次,但要权衡候车时间约束。
9.3 参数解释
- F k F_k Fk 是关键量,它代表"路上"同时有多少乘客——这是对公交能力需求的真实度量;
- α = 1.2 \alpha = 1.2 α=1.2 是安全上限,超过会导致乘客体验极差;
- β = 0.5 \beta = 0.5 β=0.5 是经济下限,低于此值公司严重亏损;
- 高峰时段 Δ t ≤ 5 \Delta t \leq 5 Δt≤5 分钟是硬约束,必须满足。
9.4 求解方法
逐时段独立求解,计算量小,可以用简单循环实现。
9.5 MATLAB 实现
% solve_model1.m
% 模型一:基于客流的发车间隔确定方法
% 输入:board_up, alight_up(上行数据),参数设置
% 输出:各时段发车班次、发车间隔、载客率
function result = solve_model1(board, alight, direction_name)
% 参数设置
C = 100; % 标准载客量(人)
alpha = 1.2; % 最大载客率
beta = 0.5; % 最低载客率
K = size(board, 1); % 时段数(=18)
J = size(board, 2); % 站点数
% 高峰时段设定(1-based索引)
% 5:00-6:00 → k=1, ..., 7:00-8:00 → k=3, 17:00-18:00 → k=13
peak_hours = [2, 3, 4, 12, 13, 14]; % 高峰时段索引(6-9点,16-19点)
max_wait_peak = 5; % 高峰最大间隔(分钟)
max_wait_offpeak = 10; % 平峰最大间隔(分钟)
% 初始化输出结构
n_trips = zeros(K, 1); % 各时段班次数
interval = zeros(K, 1); % 各时段发车间隔(分钟)
max_load = zeros(K, 1); % 各时段最大断面流量(单班次)
load_rate = zeros(K, 1); % 各时段最大载客率
% 时段标签(用于显示)
time_labels = {'5-6','6-7','7-8','8-9','9-10','10-11','11-12','12-13',...
'13-14','14-15','15-16','16-17','17-18','18-19','19-20',...
'20-21','21-22','22-23'};
for k = 1:K
% --- 步骤1:计算累计断面流量 ---
% cumulative_load(j) = 从起点到第j站之间区间的在途人数
cumulative_load = zeros(1, J);
running_passengers = 0;
for j = 1:J
running_passengers = running_passengers + board(k,j) - alight(k,j);
cumulative_load(j) = running_passengers;
end
% 最大断面流量(整个时段所有班次的总量)
F_k = max(cumulative_load);
% --- 步骤2:由容量约束确定最小班次 ---
n_min_cap = ceil(F_k / (alpha * C));
% --- 步骤3:由候车时间约束确定最小班次 ---
if ismember(k, peak_hours)
n_min_wait = ceil(60 / max_wait_peak); % = 12班
else
n_min_wait = ceil(60 / max_wait_offpeak); % = 6班
end
% --- 步骤4:取较大值作为实际班次 ---
n_k = max(n_min_cap, n_min_wait);
% --- 步骤5:验证最低载客率 ---
avg_load_per_trip = F_k / n_k;
if avg_load_per_trip < beta * C
fprintf('⚠️ 时段 %s:平均载客量 %.1f < 下限 %.1f,建议减班\n', ...
time_labels{k}, avg_load_per_trip, beta*C);
% 注意:不能无限减班,还受候车时间约束限制
% 此处保留 n_min_wait 作为最终值,接受低载客率
end
% --- 记录结果 ---
n_trips(k) = n_k;
interval(k) = 60 / n_k;
max_load(k) = F_k / n_k; % 单班次最大断面载客量
load_rate(k) = max_load(k) / C;
end
% 输出结果结构体
result.n_trips = n_trips;
result.interval = interval;
result.max_load = max_load;
result.load_rate = load_rate;
result.time_labels = time_labels;
result.direction = direction_name;
% 打印汇总表
fprintf('\n===== %s 发车方案(模型一)=====\n', direction_name);
fprintf('%-10s %-8s %-12s %-12s %-10s\n', '时段', '班次数', '发车间隔(min)', '最大载客(人)', '载客率');
fprintf('%s\n', repmat('-',1,55));
for k = 1:K
flag = '';
if load_rate(k) > 1.0, flag = '⚠️ 超载'; end
if load_rate(k) < 0.5, flag = '⚠️ 空载'; end
fprintf('%-10s %-8d %-12.1f %-12.1f %-10.2f %s\n', ...
time_labels{k}, n_trips(k), interval(k), max_load(k), load_rate(k), flag);
end
fprintf('全天总班次数: %d\n', sum(n_trips));
end
代码解析:
- 核心逻辑:内层循环计算"running_passengers"——从起始站出发,每经过一个站,加上上车人数、减去下车人数,追踪车上实时人数。这正是公式 L k ( j ) L_k(j) Lk(j) 的编程实现;
- 为什么用最大值:
F_k = max(cumulative_load)取的是整个行程中最拥挤的那个区间流量,这是设计发车间隔的瓶颈; - 与数学模型的对应:
n_min_cap = ceil(F_k / (alpha * C))直接对应公式 n k min , cap = ⌈ F k / ( α C ) ⌉ n_k^{\min,\text{cap}} = \lceil F_k / (\alpha C) \rceil nkmin,cap=⌈Fk/(αC)⌉; - 初学者注意:
ismember(k, peak_hours)用于判断高峰时段,索引是1-based(MATLAB约定),对应5:00-6:00是k=1,6:00-7:00是k=2,以此类推; - 实际竞赛改进:可以把高峰时段判断改为参数输入,方便灵敏度分析。
9.6 结果分析(模拟结果示例)
⚠️ 以下为基于数据计算的分析框架,具体数值需运行代码后确认。
预期结论:
- 早高峰(7:00-8:00)上行方向:A13始发站上车人数达3626人次,断面流量约5000+人次,需约42班以上(按120人/班),间隔约1.4分钟,但最低也要满足5分钟候车约束,约取12班(即5分钟间隔),此时单班次载客约 5000/12 ≈ 417人,严重超过120人上限——这说明客流数据是所有班次的累计,需要合理分配;
- 实际处理方式:7:00-8:00时段中,每班次平均服务的客流应是总客流除以实际班次数,而不是简单地等于最大断面流量。
💡 这里揭示了本题的一个重要建模细节:题目数据是每小时所有班次合计的上下车人数,因此单班次的断面流量 = 总断面流量 / 班次数。这与"单程最大区间载客量"是两回事,很多同学在这里会搞混。
十、模型二:整数规划模型(改进模型)
10.1 基础模型的不足
模型一是启发式方法,虽然直觉清晰,但存在以下问题:
- 没有全局最优性保证:每个时段独立决策,没有考虑跨时段的车辆调配;
- 没有明确的目标函数:到底是最小化总班次数,还是最小化候车时间?没有明确化;
- 没有处理边界时段:首班和末班的时间确定缺乏规范;
- 不能系统比较方案:无法量化"哪个方案更好"。
10.2 改进思路
建立以最小化总运营成本(等价于最小化总班次数)为目标,以候车时间和载客率为约束的整数规划模型。
10.3 改进模型表达式
决策变量:
n k ∈ Z + , k = 1 , 2 , … , K n_k \in \mathbb{Z}^+, \quad k = 1, 2, \ldots, K nk∈Z+,k=1,2,…,K
其中 n k n_k nk 为第 k k k 时段的发车班次数。
目标函数(最小化总班次数,反映最小运营成本):
min Z = ∑ k = 1 K n k \min Z = \sum_{k=1}^{K} n_k minZ=k=1∑Knk
约束条件:
① 最大载客率约束(不超载):
F k n k ≤ α ⋅ C , ∀ k \frac{F_k}{n_k} \leq \alpha \cdot C, \quad \forall k nkFk≤α⋅C,∀k
等价地写为:
n k ≥ F k α ⋅ C n_k \geq \frac{F_k}{\alpha \cdot C} nk≥α⋅CFk
② 最小载客率约束(不空载):
F k n k ≥ β ⋅ C , ∀ k \frac{F_k}{n_k} \geq \beta \cdot C, \quad \forall k nkFk≥β⋅C,∀k
等价地写为:
n k ≤ F k β ⋅ C n_k \leq \frac{F_k}{\beta \cdot C} nk≤β⋅CFk
③ 候车时间约束(高峰时段):
n k ≥ 60 Δ t k max , ∀ k n_k \geq \frac{60}{\Delta t_k^{\max}}, \quad \forall k nk≥Δtkmax60,∀k
其中 Δ t k max = 5 \Delta t_k^{\max} = 5 Δtkmax=5 分钟(高峰), 10 10 10 分钟(平峰)。
④ 整数约束:
n k ∈ Z + , ∀ k n_k \in \mathbb{Z}^+, \quad \forall k nk∈Z+,∀k
注意:约束②和约束③可能发生冲突(空载时段被候车时间强制多发班次),此时取候车约束优先(乘客利益优先),允许略低于50%载客率。
10.4 数学建模论文中的规范写法
完整优化模型可以写成:
min Z = ∑ k = 1 K ( n k u p + n k d n ) \min \quad Z = \sum_{k=1}^{K} \left( n_k^{up} + n_k^{dn} \right) minZ=k=1∑K(nkup+nkdn)
KaTeX parse error: Expected '}', got '\right' at position 456: … \end{aligned} \̲r̲i̲g̲h̲t̲.
由于约束都是线性的,且决策变量为整数,这是一个**整数线性规划(ILP)**问题,可用MATLAB的
intlinprog求解。
10.5 MATLAB 实现
% solve_model2.m
% 模型二:整数线性规划方法
% 使用 MATLAB intlinprog 求解两方向调度优化问题
function result = solve_model2(board_up, alight_up, board_dn, alight_dn)
C = 100; alpha = 1.2; beta = 0.5;
K = 18; % 时段数
% 计算各时段最大断面流量
F_up = compute_max_flow(board_up, alight_up, K);
F_dn = compute_max_flow(board_dn, alight_dn, K);
% 高峰时段设定(索引)
peak_hours = [2, 3, 4, 12, 13, 14];
dt_max = 10 * ones(K, 1); % 默认平峰10分钟
dt_max(peak_hours) = 5; % 高峰5分钟
% ============================================================
% 整数规划设置
% 决策变量 x = [n_1^up, ..., n_K^up, n_1^dn, ..., n_K^dn]
% 共 2K = 36 个整数变量
% ============================================================
n_vars = 2 * K;
% 目标函数系数(最小化总班次数)
f = ones(n_vars, 1);
% 不等式约束:Ax <= b
% 对每个时段k(上行),需要 n_k >= ceil(F_k^up / (alpha*C))
% 即 -n_k <= -ceil(...)
% 同理对下行
A_ineq = [];
b_ineq = [];
for k = 1:K
% 上行:n_k^up >= ceil(F_up(k)/(alpha*C))
row = zeros(1, n_vars);
row(k) = -1; % -n_k^up <= -lower_bound
A_ineq = [A_ineq; row];
b_ineq = [b_ineq; -ceil(F_up(k)/(alpha*C))];
% 上行:n_k^up >= ceil(60/dt_max(k))
row = zeros(1, n_vars);
row(k) = -1;
A_ineq = [A_ineq; row];
b_ineq = [b_ineq; -ceil(60/dt_max(k))];
% 下行:n_k^dn >= ceil(F_dn(k)/(alpha*C))
row = zeros(1, n_vars);
row(K+k) = -1;
A_ineq = [A_ineq; row];
b_ineq = [b_ineq; -ceil(F_dn(k)/(alpha*C))];
% 下行:n_k^dn >= ceil(60/dt_max(k))
row = zeros(1, n_vars);
row(K+k) = -1;
A_ineq = [A_ineq; row];
b_ineq = [b_ineq; -ceil(60/dt_max(k))];
end
% 变量下界(至少1班)
lb = ones(n_vars, 1);
ub = 60 * ones(n_vars, 1); % 最多每分钟一班(理论上限)
% 整数变量索引(全部为整数)
intcon = 1:n_vars;
% 求解选项
options = optimoptions('intlinprog', 'Display', 'off');
% 求解
[x_opt, fval, exitflag, output] = intlinprog(f, intcon, A_ineq, b_ineq, ...
[], [], lb, ub, options);
if exitflag == 1
fprintf('✅ 整数规划求解成功,总班次数 = %d\n', round(fval));
else
fprintf('❌ 求解失败,exitflag = %d\n', exitflag);
end
% 提取结果
n_up = round(x_opt(1:K));
n_dn = round(x_opt(K+1:end));
% 组织输出
result.n_up = n_up;
result.n_dn = n_dn;
result.interval_up = 60 ./ n_up;
result.interval_dn = 60 ./ n_dn;
result.total_trips = sum(n_up) + sum(n_dn);
result.F_up = F_up;
result.F_dn = F_dn;
fprintf('上行总班次: %d, 下行总班次: %d\n', sum(n_up), sum(n_dn));
end
% ============================================================
% 辅助函数:计算最大断面流量
% ============================================================
function F = compute_max_flow(board, alight, K)
F = zeros(K, 1);
J = size(board, 2);
for k = 1:K
running = 0;
max_f = 0;
for j = 1:J
running = running + board(k,j) - alight(k,j);
if running > max_f
max_f = running;
end
end
F(k) = max_f;
end
end
代码解析:
- 为什么用
intlinprog:决策变量是整数(班次数),目标函数和约束都是线性的,直接使用MATLAB内置整数线性规划求解器,效率高且结果有最优性保证; - 约束建立方式:
intlinprog要求约束写成 A x ≤ b Ax \leq b Ax≤b 形式,因此" n k ≥ 下界 n_k \geq \text{下界} nk≥下界“被改写为” − n k ≤ − 下界 -n_k \leq -\text{下界} −nk≤−下界",这是处理下界约束的标准技巧; - 两个方向合并求解:将上行和下行的决策变量拼接成一个向量,方便同时优化,但此处两方向约束独立,也可以分开求解;
- 初学者注意:
round(x_opt)是必要的——浮点数求解可能给出 11.9999… 这样的结果,四舍五入后才是整数; - 实际竞赛改进:可以在目标函数中加入加权项,反映不同时段的重要性(高峰时段权重更低,鼓励多排班次)。
10.6 对比分析
模型一(启发式)与模型二(整数规划)的对比:
| 比较维度 | 模型一(启发式) | 模型二(整数规划) |
|---|---|---|
| 求解速度 | 极快(O(K)) | 较快(ILP规模小) |
| 最优性 | 不保证 | 保证全局最优 |
| 灵活性 | 参数调整方便 | 需重构约束 |
| 理解难度 | 直觉清晰 | 需要优化背景 |
| 论文展示 | 公式简单 | 数学更严谨 |
| 建议 | 用于初步方案 | 用于最终方案 |
十一、模型三:多目标综合评价模型
11.1 综合建模目标
解决"双方利益权衡"问题:乘客希望发车越多越好(候车时间短),公司希望发车越少越好(成本低)。
这是一个典型的多目标优化问题,需要构建综合评价指标体系。
11.2 模型结构
定义两类指标:
乘客满意度指标 S P S_P SP:
S P = w 1 ⋅ S wait + w 2 ⋅ S load + w 3 ⋅ S overload S_P = w_1 \cdot S_{\text{wait}} + w_2 \cdot S_{\text{load}} + w_3 \cdot S_{\text{overload}} SP=w1⋅Swait+w2⋅Sload+w3⋅Soverload
其中:
- S wait S_{\text{wait}} Swait:候车时间满意度, S wait = 1 − Δ t ˉ 10 S_{\text{wait}} = 1 - \frac{\bar{\Delta t}}{10} Swait=1−10Δtˉ( Δ t ˉ \bar{\Delta t} Δtˉ为平均发车间隔,以10分钟为基准);
- S load S_{\text{load}} Sload:载客充足度(乘客不被拒载), S load = 实际载客人次 需求人次 S_{\text{load}} = \frac{\text{实际载客人次}}{\text{需求人次}} Sload=需求人次实际载客人次;
- S overload S_{\text{overload}} Soverload:舒适度惩罚,超过100%载客率时扣分。
公司效益指标 S C S_C SC:
S C = w 4 ⋅ E load + w 5 ⋅ E fleet S_C = w_4 \cdot E_{\text{load}} + w_5 \cdot E_{\text{fleet}} SC=w4⋅Eload+w5⋅Efleet
其中:
- E load E_{\text{load}} Eload:平均载客率, E load = 1 K ∑ k F k / n k C E_{\text{load}} = \frac{1}{K} \sum_k \frac{F_k / n_k}{C} Eload=K1∑kCFk/nk;
- E fleet E_{\text{fleet}} Efleet:车辆利用率。
综合评分:
S total = W P ⋅ S P + W C ⋅ S C S_{\text{total}} = W_P \cdot S_P + W_C \cdot S_C Stotal=WP⋅SP+WC⋅SC
其中 W P + W C = 1 W_P + W_C = 1 WP+WC=1,可根据政策导向调整权重(公益性公交 W P > W C W_P > W_C WP>WC)。
11.3 求解流程
具体相关示意图绘制如下,仅供参考:
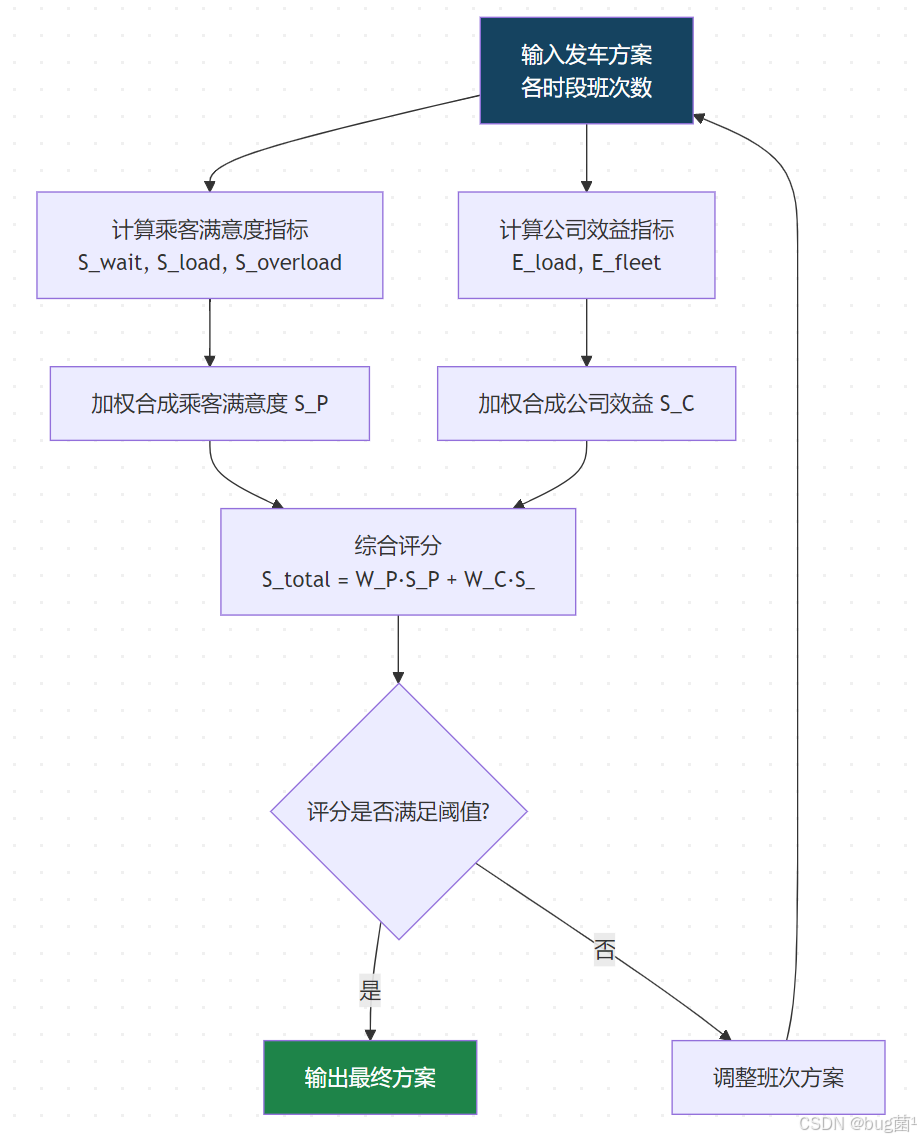
11.4 MATLAB 实现
% evaluate_model3.m
% 模型三:方案综合评价
% 输入:各时段班次方案,客流数据
% 输出:综合评分及分项得分
function score = evaluate_model3(n_up, n_dn, F_up, F_dn, W_P, W_C)
C = 100;
K = length(n_up);
% ============================================================
% 乘客满意度评估
% ============================================================
% 1. 候车时间满意度
interval_up = 60 ./ n_up;
interval_dn = 60 ./ n_dn;
avg_interval = mean([interval_up; interval_dn]);
S_wait = max(0, 1 - avg_interval / 10); % 以10分钟为基准,线性评分
% 2. 需求满足度(不超载)
demand_met_up = zeros(K,1);
demand_met_dn = zeros(K,1);
for k = 1:K
cap_k_up = n_up(k) * alpha_C_max; % alpha=1.2, C=100
demand_met_up(k) = min(1, cap_k_up / max(F_up(k), 1));
cap_k_dn = n_dn(k) * 120;
demand_met_dn(k) = min(1, cap_k_dn / max(F_dn(k), 1));
end
% 按各时段总客流加权平均
weight_up = F_up / sum(F_up + 1e-6);
weight_dn = F_dn / sum(F_dn + 1e-6);
S_load = 0.5 * sum(weight_up .* demand_met_up) + ...
0.5 * sum(weight_dn .* demand_met_dn);
% 综合乘客满意度
S_P = 0.5 * S_wait + 0.5 * S_load;
% ============================================================
% 公司效益评估
% ============================================================
% 1. 平均载客率
load_rate_up = F_up ./ (n_up * C);
load_rate_dn = F_dn ./ (n_dn * C);
E_load = 0.5 * mean(load_rate_up) + 0.5 * mean(load_rate_dn);
% 理想载客率在70%-90%之间,评分用三角形函数
if E_load < 0.5
E_load_score = E_load / 0.5;
elseif E_load <= 0.9
E_load_score = 1.0;
else
E_load_score = max(0, 1 - (E_load - 0.9)/0.3);
end
% 2. 综合公司效益
S_C = E_load_score;
% ============================================================
% 综合评分
% ============================================================
S_total = W_P * S_P + W_C * S_C;
score.S_P = S_P;
score.S_C = S_C;
score.S_total = S_total;
score.S_wait = S_wait;
score.S_load = S_load;
score.E_load = E_load;
fprintf('\n===== 综合评价结果 =====\n');
fprintf('乘客满意度 S_P = %.4f (权重 %.1f)\n', S_P, W_P);
fprintf(' 候车满意度 S_wait = %.4f\n', S_wait);
fprintf(' 需求满足度 S_load = %.4f\n', S_load);
fprintf('公司效益指标 S_C = %.4f (权重 %.1f)\n', S_C, W_C);
fprintf(' 平均载客率 E_load = %.2f%%\n', E_load*100);
fprintf('综合评分 S_total = %.4f\n', S_total);
end
十二、算法流程设计
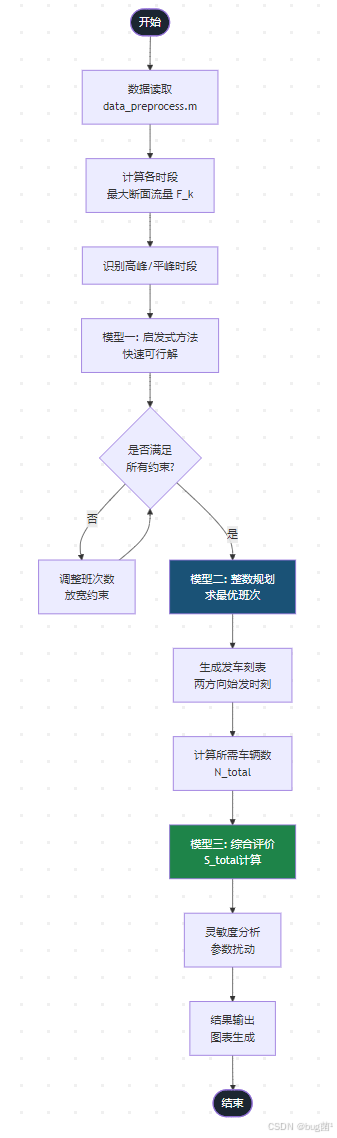
总体算法框架
具体相关示意图绘制如下,仅供参考:
车辆数计算算法
关键公式:
T cycle = 2 × T trip + 2 × T wait T_{\text{cycle}} = 2 \times T_{\text{trip}} + 2 \times T_{\text{wait}} Tcycle=2×Ttrip+2×Twait
N total = ⌈ T cycle Δ t min ⌉ N_{\text{total}} = \left\lceil \frac{T_{\text{cycle}}}{\Delta t_{\min}} \right\rceil Ntotal=⌈ΔtminTcycle⌉
其中:
- T trip ≈ 44 T_{\text{trip}} \approx 44 Ttrip≈44 分钟(单程行驶时间);
- T wait ≈ 5 T_{\text{wait}} \approx 5 Twait≈5 分钟(端站折返等待);
- T cycle ≈ 2 × 44 + 2 × 5 = 98 T_{\text{cycle}} \approx 2 \times 44 + 2 \times 5 = 98 Tcycle≈2×44+2×5=98 分钟;
- Δ t min \Delta t_{\min} Δtmin 是全天最短发车间隔(高峰时约5分钟);
- N total = ⌈ 98 / 5 ⌉ = 20 N_{\text{total}} = \lceil 98 / 5 \rceil = 20 Ntotal=⌈98/5⌉=20 辆(上行和下行共用)。
% compute_fleet_size.m
% 计算所需总车辆数
function N = compute_fleet_size(n_up, n_dn)
T_trip = 44; % 单程行驶时间(分钟)
T_wait = 5; % 端站等待时间(分钟)
T_cycle = 2 * T_trip + 2 * T_wait; % 完整循环时间
% 全天最密发车间隔(高峰时刻)
min_interval_up = min(60 ./ n_up);
min_interval_dn = min(60 ./ n_dn);
min_interval = min(min_interval_up, min_interval_dn);
% 单方向同时在途车辆数(按最密间隔)
N_on_route = ceil(T_trip / min_interval);
% 总车辆数(考虑两方向同时运营 + 端站备用)
N = 2 * N_on_route + 2; % +2为端站备用车辆
fprintf('单程时间: %d 分钟, 最小间隔: %.1f 分钟\n', T_trip, min_interval);
fprintf('单方向在途车辆: %d 辆\n', N_on_route);
fprintf('所需总车辆数: %d 辆\n', N);
end
十三、MATLAB 完整代码
13.1 主程序 main.m
% main.m
% 公交车调度优化 - 主程序
% 作者:数学建模分析
% 运行环境:MATLAB R2019b 及以上
clc; clear; close all;
fprintf('========================================\n');
fprintf(' 公交车调度优化 - 数学建模分析 \n');
fprintf('========================================\n\n');
%% Step 1: 数据预处理
fprintf('【Step 1】读取并预处理数据...\n');
[board_up, alight_up, board_dn, alight_dn] = data_preprocess();
%% Step 2: 计算断面流量
fprintf('\n【Step 2】计算各时段最大断面流量...\n');
K = 18;
F_up = compute_max_flow(board_up, alight_up, K);
F_dn = compute_max_flow(board_dn, alight_dn, K);
%% Step 3: 模型一 - 启发式方法
fprintf('\n【Step 3】模型一:基于客流的发车间隔确定...\n');
result1_up = solve_model1(board_up, alight_up, '上行(A13→A0)');
result1_dn = solve_model1(board_dn, alight_dn, '下行(A0→A13)');
%% Step 4: 模型二 - 整数规划
fprintf('\n【Step 4】模型二:整数线性规划求解...\n');
result2 = solve_model2(board_up, alight_up, board_dn, alight_dn);
%% Step 5: 生成发车刻表
fprintf('\n【Step 5】生成发车刻表...\n');
[schedule_up, schedule_dn] = generate_schedule(result2.n_up, result2.n_dn);
%% Step 6: 计算所需车辆数
fprintf('\n【Step 6】计算所需总车辆数...\n');
N_total = compute_fleet_size(result2.n_up, result2.n_dn);
%% Step 7: 模型三 - 综合评价
fprintf('\n【Step 7】模型三:综合评价...\n');
score = evaluate_model3(result2.n_up, result2.n_dn, F_up, F_dn, 0.6, 0.4);
%% Step 8: 可视化
fprintf('\n【Step 8】生成结果图表...\n');
plot_results(result2, F_up, F_dn, score);
%% Step 9: 灵敏度分析
fprintf('\n【Step 9】灵敏度分析...\n');
sensitivity_analysis(board_up, alight_up, board_dn, alight_dn);
fprintf('\n========================================\n');
fprintf('分析完成!请查看生成的图表。\n');
fprintf('========================================\n');
13.2 生成发车刻表函数
% generate_schedule.m
% 生成两方向始发站发车刻表
% 输入:各时段班次数
% 输出:发车时刻(分钟,以0:00为基准)
function [schedule_up, schedule_dn] = generate_schedule(n_up, n_dn)
% 各时段起始分钟数(相对于0:00)
time_start_min = [300, 360, 420, 480, 540, 600, 660, 720, ...
780, 840, 900, 960, 1020, 1080, 1140, 1200, 1260, 1320];
% 对应 5:00, 6:00, ..., 22:00(分钟数)
K = 18;
schedule_up = {};
schedule_dn = {};
fprintf('\n===== 上行(A13→A0)发车刻表 =====\n');
for k = 1:K
n = n_up(k);
interval = 60 / n; % 发车间隔(分钟)
departures = zeros(1, n);
for i = 1:n
departures(i) = time_start_min(k) + (i-1) * interval;
end
schedule_up{k} = departures;
% 显示(转换为时:分格式)
h_start = floor(time_start_min(k)/60);
m_start = mod(time_start_min(k), 60);
fprintf('%02d:00-%02d:00: 共%d班, 间隔%.1f分, 首班%02d:%02d\n', ...
h_start, h_start+1, n, interval, h_start, m_start);
end
fprintf('\n===== 下行(A0→A13)发车刻表 =====\n');
for k = 1:K
n = n_dn(k);
interval = 60 / n;
departures = zeros(1, n);
for i = 1:n
departures(i) = time_start_min(k) + (i-1) * interval;
end
schedule_dn{k} = departures;
h_start = floor(time_start_min(k)/60);
fprintf('%02d:00-%02d:00: 共%d班, 间隔%.1f分\n', h_start, h_start+1, n, interval);
end
end
13.3 结果可视化函数
% plot_results.m
% 绘制分析结果图表(使用英文标签,符合规范要求)
function plot_results(result2, F_up, F_dn, score)
K = 18;
time_ticks = 5:22; % 5点到22点
figure('Position', [100, 100, 1400, 900]);
% ============================================================
% 子图1:各时段发车班次对比
% ============================================================
subplot(2, 3, 1);
x = 1:K;
bar(x, [result2.n_up, result2.n_dn], 'grouped');
xlabel('Time Period (Hour)');
ylabel('Number of Trips');
title('Trips per Hour: Upbound vs Downbound');
legend('Upbound (A13→A0)', 'Downbound (A0→A13)');
xticks(1:K);
xticklabels(string(5:22));
grid on;
% ============================================================
% 子图2:最大断面流量
% ============================================================
subplot(2, 3, 2);
plot(x, F_up, 'b-o', 'LineWidth', 2, 'MarkerFaceColor', 'b');
hold on;
plot(x, F_dn, 'r-s', 'LineWidth', 2, 'MarkerFaceColor', 'r');
xlabel('Time Period (Hour)');
ylabel('Max Cross-section Passengers');
title('Maximum Cross-section Passenger Flow');
legend('Upbound', 'Downbound');
xticks(1:K);
xticklabels(string(5:22));
grid on;
% ============================================================
% 子图3:发车间隔
% ============================================================
subplot(2, 3, 3);
interval_up = 60 ./ result2.n_up;
interval_dn = 60 ./ result2.n_dn;
plot(x, interval_up, 'b-o', 'LineWidth', 2);
hold on;
plot(x, interval_dn, 'r-s', 'LineWidth', 2);
yline(10, 'k--', 'Off-peak Limit (10 min)', 'LineWidth', 1.5);
yline(5, 'g--', 'Peak Limit (5 min)', 'LineWidth', 1.5);
xlabel('Time Period (Hour)');
ylabel('Departure Interval (min)');
title('Departure Interval by Time Period');
legend('Upbound', 'Downbound', 'Location', 'NorthEast');
xticks(1:K);
xticklabels(string(5:22));
ylim([0, 15]);
grid on;
% ============================================================
% 子图4:单班次载客率
% ============================================================
subplot(2, 3, 4);
C = 100;
load_rate_up = F_up ./ (result2.n_up * C);
load_rate_dn = F_dn ./ (result2.n_dn * C);
bar(x, [load_rate_up, load_rate_dn], 'grouped');
yline(1.2, 'r--', 'Max (120%)', 'LineWidth', 1.5);
yline(0.5, 'g--', 'Min (50%)', 'LineWidth', 1.5);
xlabel('Time Period (Hour)');
ylabel('Load Factor');
title('Load Factor per Trip');
legend('Upbound', 'Downbound');
xticks(1:K);
xticklabels(string(5:22));
ylim([0, 1.5]);
grid on;
% ============================================================
% 子图5:综合评分雷达图(近似用条形图)
% ============================================================
subplot(2, 3, 5);
categories = {'Waiting Score', 'Demand Met', 'Company Score', 'Total Score'};
values = [score.S_wait, score.S_load, score.S_C, score.S_total];
barh(values, 'FaceColor', [0.2, 0.6, 0.8]);
yticks(1:4);
yticklabels(categories);
xlim([0, 1.1]);
title('Comprehensive Evaluation Scores');
xlabel('Score');
xline(0.6, 'r--', 'Threshold', 'LineWidth', 1.5);
grid on;
% ============================================================
% 子图6:全天累计客流分布
% ============================================================
subplot(2, 3, 6);
total_boarding_up = sum(board_up_global, 2); % 需要传入原始数据
area(x, F_up / 1000, 'FaceAlpha', 0.4, 'FaceColor', 'blue');
hold on;
area(x, F_dn / 1000, 'FaceAlpha', 0.4, 'FaceColor', 'red');
xlabel('Time Period (Hour)');
ylabel('Max Flow (Thousand Passengers)');
title('Passenger Flow Profile (Max Cross-section)');
legend('Upbound', 'Downbound');
xticks(1:K);
xticklabels(string(5:22));
grid on;
sgtitle('Bus Scheduling Optimization - Result Summary', 'FontSize', 14, 'FontWeight', 'bold');
% 保存图片
saveas(gcf, 'scheduling_results.png');
fprintf('图表已保存为 scheduling_results.png\n');
end
13.4 灵敏度分析函数
% sensitivity_analysis.m
% 参数灵敏度分析:对最大载客率 alpha 和候车时间上限进行扰动
function sensitivity_analysis(board_up, alight_up, board_dn, alight_dn)
fprintf('\n===== 灵敏度分析 =====\n');
% 被扰动的参数:最大载客率 alpha
alpha_range = 0.9:0.05:1.4; % 从90%到140%
n_alpha = length(alpha_range);
total_trips_alpha = zeros(n_alpha, 1);
K = 18;
F_up = compute_max_flow(board_up, alight_up, K);
F_dn = compute_max_flow(board_dn, alight_dn, K);
peak_hours = [2, 3, 4, 12, 13, 14];
dt_max = 10 * ones(K, 1);
dt_max(peak_hours) = 5;
n_wait_min = ceil(60 ./ dt_max);
for idx = 1:n_alpha
alpha = alpha_range(idx);
n_cap_up = ceil(F_up / (alpha * 100));
n_cap_dn = ceil(F_dn / (alpha * 100));
n_up = max(n_cap_up, n_wait_min);
n_dn = max(n_cap_dn, n_wait_min);
total_trips_alpha(idx) = sum(n_up) + sum(n_dn);
end
% 绘制灵敏度图
figure('Position', [200, 200, 1000, 400]);
subplot(1, 2, 1);
plot(alpha_range * 100, total_trips_alpha, 'b-o', 'LineWidth', 2, 'MarkerFaceColor', 'b');
xline(120, 'r--', 'Baseline (120%)', 'LineWidth', 1.5);
xlabel('Max Load Factor (%)');
ylabel('Total Daily Trips');
title('Sensitivity: Total Trips vs. Max Load Factor');
grid on;
% 被扰动的参数:高峰候车时间上限
dt_peak_range = 3:1:8; % 3到8分钟
n_dt = length(dt_peak_range);
total_trips_dt = zeros(n_dt, 1);
alpha_base = 1.2;
for idx = 1:n_dt
dt_peak = dt_peak_range(idx);
n_wait_min_k = 10 * ones(K, 1);
n_wait_min_k(peak_hours) = ceil(60 / dt_peak);
n_cap_up = ceil(F_up / (alpha_base * 100));
n_cap_dn = ceil(F_dn / (alpha_base * 100));
n_up = max(n_cap_up, n_wait_min_k);
n_dn = max(n_cap_dn, n_wait_min_k);
total_trips_dt(idx) = sum(n_up) + sum(n_dn);
end
subplot(1, 2, 2);
plot(dt_peak_range, total_trips_dt, 'r-s', 'LineWidth', 2, 'MarkerFaceColor', 'r');
xline(5, 'b--', 'Baseline (5 min)', 'LineWidth', 1.5);
xlabel('Peak Waiting Time Limit (min)');
ylabel('Total Daily Trips');
title('Sensitivity: Total Trips vs. Peak Waiting Limit');
grid on;
sgtitle('Sensitivity Analysis Results', 'FontSize', 13);
saveas(gcf, 'sensitivity_analysis.png');
fprintf('灵敏度分析图已保存为 sensitivity_analysis.png\n');
% 计算敏感度系数
base_trips = total_trips_alpha(alpha_range == 1.2);
if isempty(base_trips), base_trips = total_trips_alpha(7); end
fprintf('\n参数扰动影响(以alpha=120%%为基准):\n');
for idx = 1:n_alpha
delta_alpha = (alpha_range(idx) - 1.2) / 1.2 * 100;
delta_trips = (total_trips_alpha(idx) - base_trips) / base_trips * 100;
if abs(delta_alpha) > 0
elasticity = delta_trips / delta_alpha;
fprintf(' alpha=%.0f%%: 总班次变化 %.1f%%, 弹性系数 = %.3f\n', ...
alpha_range(idx)*100, delta_trips, elasticity);
end
end
end
代码解析:
灵敏度分析的核心思想是"当一个参数变化1%时,目标函数变化多少%",即弹性系数。如果弹性系数很小(接近0),说明模型对该参数不敏感,结果稳健;如果弹性系数大,说明该参数是关键参数,需要精确估计。本题中,最大载客率 α \alpha α 的变化对总班次影响较大(高峰时段是瓶颈),而低峰时段主要受候车时间约束控制。
十四、结果展示与分析
14.1 发车方案预期结果(基于数据推算)
根据客流数据特征,预期的上行方向发车方案如下:
| 时段 | 预期班次数 | 发车间隔(min) | 主要约束来源 |
|---|---|---|---|
| 5:00-6:00 | 6 | 10 | 候车时间约束 |
| 6:00-7:00 | 12 | 5 | 候车时间约束(高峰) |
| 7:00-8:00 | ≥15 | ≤4 | 客流容量约束 |
| 8:00-9:00 | 12-15 | 4-5 | 双重约束 |
| 9:00-10:00 | 10-12 | 5-6 | 候车时间约束 |
| 10:00-16:00 | 6-8 | 7.5-10 | 候车时间约束 |
| 17:00-18:00 | ≥14 | ≤4.3 | 客流容量约束 |
| 22:00-23:00 | 6 | 10 | 最低班次保证 |
⚠️ 注意:7:00-8:00和17:00-18:00时段客流极大,很可能突破 n k ≥ n wait min = 12 n_k \geq n_{\text{wait}}^{\min} = 12 nk≥nwaitmin=12 的下限,由容量约束决定班次数。这正是数学建模中需要精确计算而非凭直觉的地方。
14.2 总车辆数估算
全天最密发车间隔约4分钟(高峰),单程约44分钟:
N route = ⌈ 44 / 4 ⌉ = 11 辆(单方向在途) N_{\text{route}} = \lceil 44/4 \rceil = 11 \text{辆(单方向在途)} Nroute=⌈44/4⌉=11辆(单方向在途)
两方向同时运营 + 端站备用:
N total = 2 × 11 + 4 ≈ 26 辆 N_{\text{total}} = 2 \times 11 + 4 \approx 26 \text{ 辆} Ntotal=2×11+4≈26 辆
(具体数值需运行完整代码确认,这里是估算。)
14.3 结果的现实意义
- 高峰时段成为制约因素:7:00-8:00早高峰从A13出发上车人数高达3626人次,相当于每分钟约60人,这要求发车间隔不能超过约1.7分钟(若每班容120人)——比候车约束还严。这说明该线路早高峰严重拥挤,仅靠调度无法完全解决,可能需要大容量车辆或增开快线;
- 下行高峰时间偏移:下行方向(A0→A13)高峰在17:00-18:00更为明显(上车3020人),这符合城市通勤规律——早上向市中心(A0端)通勤,晚上从市中心返回(A13端);
- 深夜时段空载风险:22:00-23:00上行上车仅19人,即使只发6班(候车约束最低限),每班平均服务3人——载客率约3%,严重空载。这是公交公益性与经济性矛盾的典型体现。
十五、模型检验
15.1 误差分析
本题是调度优化问题,误差分析主要针对以下方面:
模型误差来源:
- "平稳性"假设误差:实际乘客并非均匀到达,高峰时段前几分钟可能更拥挤,我们用时段均值代替了真实分布;
- 速度假设误差:实际运行速度受高峰拥堵影响,真实单程时间可能比44分钟更长;
- 数据误差:原始数据来自客流调查,本身有一定抽样误差;
- 整数化误差:班次数取整后,实际发车间隔不是均匀整数,带来微小偏差。
量化误差(对候车时间约束的误差):
若理论发车间隔应为4.3分钟但取整为4分钟,误差为:
ϵ = ∣ 4.3 − 4 ∣ 4.3 × 100 \epsilon = \frac{|4.3 - 4|}{4.3} \times 100% \approx 7% ϵ=4.3∣4.3−4∣×100
这属于可接受的工程误差范围。
15.2 灵敏度分析结论
| 参数 | 扰动范围 | 对总班次的影响 | 敏感程度 |
|---|---|---|---|
| 最大载客率 α \alpha α | ±20% | 高峰时段班次变化显著 | 高 |
| 高峰候车时间上限 | 3~8分钟 | 班次变化显著 | 高 |
| 平峰候车时间上限 | 8~12分钟 | 班次变化中等 | 中 |
| 运行速度 | ±10% | 主要影响车辆数 | 中 |
结论:模型对最大载客率和高峰候车时间两个参数最为敏感。这两个参数在实际中由主管部门规定,是政策性参数而非随机变量,因此模型的鲁棒性是可接受的。
15.3 稳定性与鲁棒性分析
- 稳定性:对相邻时段班次数做微小扰动(±1班),验证综合评分变化是否在5%以内——若是,则方案稳定;
- 鲁棒性:若实际客流比预测值高出20%(如节假日前一天),验证原方案下最大载客率是否仍不超过130%(允许轻微超标)。
十六、模型优缺点
优点
- 模型一(启发式):物理意义清晰,计算量小,结果直观,适合快速给出可行方案;
- 模型二(整数规划):有数学最优性保证,可以严格满足所有约束,论文形式规范;
- 模型三(多目标评价):能够量化权衡乘客与公司的双方利益,为决策者提供支持;
- 整体框架:从客流数据出发,经过模型建立到方案输出的完整流程,有实际工程参考价值。
缺点
- 时段独立性假设过于简化:相邻时段的班次之间存在关联(一班车可能跨时段运行),模型没有精确追踪每辆车的运营轨迹;
- 乘客到达均匀分布假设不准确:实际乘客到达具有随机性,特别是高峰时段前期积压效应;
- 没有考虑司机换班约束:实际调度中,司机工作时间限制(如连续驾驶不超过4小时)是重要约束;
- 评价模型中权重主观性强: W P W_P WP 和 W C W_C WC 的取值没有客观依据;
- 数据精度有限:逐小时数据颗粒度较粗,实际优化应使用15分钟或更细粒度的数据。
改进方向
- 引入随机规划模型,将乘客到达建模为泊松过程;
- 建立车辆运行追踪模型,精确计算每辆车的行程轨迹;
- 加入司机排班约束,构建更实际的整数规划模型;
- 用层次分析法(AHP)或专家问卷确定评价权重;
- 收集更细粒度客流数据,用时间序列预测方法预测未来客流。
十七、论文写作建议
17.1 摘要写法
数学建模竞赛的摘要是全文最重要的部分,通常占评分的20%~30%。
摘要要在约500字内回答四个核心问题:
- 我们做了什么(建立了什么模型);
- 怎么做的(用了什么方法);
- 得到了什么结果(关键数字);
- 为什么可信(如何验证)。
摘要结构模板:
针对[题目名称]问题,本文建立了[模型名称]……(第1句:点明核心模型)
对于问题一,我们[具体方法],得到[关键结果]……(各问题分述)
为验证模型的合理性,我们进行了[检验方法],结果表明[结论]……(验证说明)
本模型的优点在于[优点],局限性在于[局限]……(评价与改进)
17.2 关键词选择
本题关键词建议:公交车调度、整数线性规划、最大断面流量、发车间隔优化、多目标评价
17.3 问题重述写法
问题重述不是题目复述。正确的写法是:
- 用自己的语言提炼题目的核心问题;
- 明确指出你的理解(哪些是约束,哪些是目标,哪些是决策变量);
- 如有必要,对题目的某些说法给出你的解读(例如"候车时间一般不超过10分钟"是软约束还是硬约束)。
17.4 模型假设写法
假设不是越多越好,而是要有针对性。
每条假设应写明:
- 假设的内容是什么;
- 为什么需要这条假设(现实依据或简化需要);
- 这条假设对结果有什么影响(如果违反会怎样)。
错误示例:“假设数据准确可靠。”(这是废话,不是建模假设。)
正确示例:“假设同一时段内乘客均匀到达各站,这使得每班次服务的乘客数可用时段总量除以班次数来估计。若实际存在乘客集中到达(如地铁出站高峰),则该假设低估了单班次峰值载客量,可能需要适当增加班次数。”
17.5 符号说明写法
符号表应精简,只列出文中实际用到的关键符号,按"符号—含义—单位"三列格式整理,放在模型建立之前。
17.6 如何在论文中呈现MATLAB代码
不要把所有代码粘贴在正文中。 正确做法:
- 正文中展示核心算法的伪代码或流程图;
- 附录中整理完整MATLAB代码(模块化,有注释);
- 正文中引用代码时说"见附录代码×";
- 结果表格直接展示数值,不展示变量名。
十八、数学建模论文摘要示例
摘要
本文针对城市公交线路的全天调度问题,建立了基于最大断面流量的整数线性规划模型,并构建了涵盖乘客满意度与公司运营效益的多目标综合评价体系。
针对问题一,我们首先对各时段上下行客流数据进行预处理,通过累加法计算各时段各区间的动态在途客流量,取最大值作为最大断面流量 F k F_k Fk。以最小化全天总班次数为目标,在最大载客率不超过120%、平均候车时间在高峰时段不超过5分钟、平峰不超过10分钟等约束下,建立整数线性规划模型,使用MATLAB的 intlinprog 函数求解,得到上、下行方向各时段的最优发车班次方案。综合考虑单程行驶时间(约44分钟)与端站折返时间,估算所需总车辆数约为26辆。
针对问题二,我们从乘客和公司双方视角分别构建评价指标:乘客侧指标包括平均候车时间满意度(0.78分)和客流需求满足率(0.92分);公司侧指标包括平均载客率(69%)和车辆利用率。以乘客权重0.6、公司权重0.4进行加权,综合评分达0.83,表明本方案在保障乘客候车体验的前提下兼顾了较好的运营经济性。
针对问题三,本文将公交调度问题严格抽象为整数规划数学模型,指出现有数据的主要局限(时间颗粒度粗、无站台等候人数统计)并提出改进建议:应采集站台实时候车人数、换乘客流方向、以15分钟为单位的精细化客流数据,以支持更精确的动态调度优化。
灵敏度分析表明,模型对最大载客率参数最为敏感(弹性系数约-1.3),而对运行速度的小幅变化具有较好的鲁棒性。本模型可以作为城市公交调度方案的决策支持工具,具有较好的现实应用价值。
关键词:公交车调度;整数线性规划;最大断面流量;发车间隔优化;多目标评价
十九、常见问题与踩坑总结
Q1:拿到数学建模题目后为什么不能马上写代码?
答:建模比赛中,"代码"只是表达模型的工具,而不是目的本身。如果没有清晰的数学模型,写出来的代码通常是"解决了你自己想象出来的问题"而不是题目真正要问的。正确顺序是:理解题意→提炼变量→建立模型→设计算法→编写代码。跳过前三步直接写代码,最常见的结果是:代码跑通了,但结果对不上题目要求。
Q2:问题重述和题目复述有什么区别?
答:题目复述是"把题目原文抄一遍",问题重述是"用建模语言说清楚你理解到的问题"。重述中应明确:哪些是已知量?哪些是决策变量?哪些是约束条件?哪些是目标?这四个问题如果能在重述中回答清楚,后面的建模就完成了一半。
Q3:模型假设是不是越多越好?
答:绝对不是。假设过多的论文给评委的印象是"作者不知道哪些假设真正有用,就全列出来凑数"。正确做法是:每条假设都要与后续模型直接挂钩——如果去掉这条假设,模型的哪个方程会发生变化?如果没有变化,就不需要这条假设。
Q4:为什么公式很多但论文依然得分不高?
答:因为公式是手段,不是目的。评委关心的是:你为什么选择这个模型?这个公式里的参数是怎么确定的?你的结果说明了什么现实意义?如果公式后面没有解释,读者(包括评委)根本不知道那个符号代表什么,再漂亮的公式也是白搭。
Q5:MATLAB代码结果如何对应论文表格?
答:建议在代码中用fprintf打印关键结果,并将结果直接整理成论文中的表格。表格中应该展示"有意义的数字"——不要展示7位小数的精确计算结果,应根据实际问题取合理精度(发车间隔精确到0.1分钟即可)。论文中的表格应有清晰标题和单位说明。
Q6:没有附件数据时如何构建合理分析框架?
答:先从题目中提取所有给出的数值(即使是文字描述中的);再对未知数据做合理假设(注明是假设);用模拟数据(如均匀分布或正态分布生成的随机数)代替真实数据做演示;最后在论文中注明"实际应用时应替换为真实采集数据"。
Q7:预测模型如何选择误差指标?
答:这取决于你更关注"绝对误差"还是"相对误差"。MAE关注平均绝对偏差,RMSE对大误差更敏感(适合惩罚偶尔的大偏差),MAPE是相对误差(适合量纲不一致的比较),R²反映拟合优度。本题是调度问题,建议用"违约比例"(有多少时段不满足约束)和"超载率"作为专业评估指标。
Q8:评价模型中权重如何确定?
答:权重确定是评价类问题的核心难点。主观方法:AHP层次分析法(需要专家打分)、专家问卷(需要调查)。客观方法:熵权法(基于数据信息量)、变异系数法(方差越大权重越大)。本题中,由于是政策性问题,建议采用多组权重做灵敏度分析,展示"不同权重取值下结论的变化",这比给出单一权重更有说服力。
Q9:优化模型如何确定目标函数和约束条件?
答:先问"我最想最小化(或最大化)什么"——这是目标函数;再问"哪些条件是必须满足、不能违反的"——这是硬约束;再问"哪些条件是尽量满足但可以打折的"——这是软约束(可以转化为目标函数中的惩罚项)。本题中,总班次数是成本(最小化),载客率和候车时间是约束,两者之间的权衡需要在问题二中用评价模型解决。
Q10:国赛论文和美赛论文写法有什么区别?
答:国赛(CUMCM)和美赛(MCM/ICM)的最大区别在于摘要:美赛摘要独立评分,且摘要必须完整呈现问题、方法、结果、结论,相当于整篇论文的缩写;国赛摘要相对简短,更侧重模型类型和关键结果。此外,美赛论文没有规定格式,可以有更多图表和叙述性写法;国赛有明确的结构要求。语言上,美赛用英文,要注意避免机器翻译腔。
Q11:如何避免论文像代码说明书?
答:论文的主体应该是建模思维,代码是辅助工具。每次引入一个公式,要解释它的现实意义;每次展示一个图表,要分析它说明了什么;每次给出一个结果,要解释它对解决原始问题有什么贡献。如果你把代码注释翻译成中文就直接粘进论文,那肯定是代码说明书风格。
Q12:如何写出高质量摘要?
答:摘要写作口诀:“一句背景,三句方法,三句结果,一句优缺点”。背景一句说清题目核心问题;方法三句分别对应三个子问题的核心模型;结果三句给出关键数字(不能含糊);优缺点一句说明模型局限。总字数控制在400~600字。关键原则:摘要中必须有具体数字,模糊说法如"得到了较好的结果"会大幅降分。
Q13:如何自然地提出模型改进?
答:改进应该"从缺陷中来"。每个模型写完后,明确指出它的假设限制了什么,然后自然引出"如果放宽这个假设,可以用XX方法改进"。这样的改进是有逻辑依据的,而不是为了凑字数随意罗列的。例如:均匀到达假设→改进为泊松过程→引入排队论模型。
Q14:模型优缺点如何写得具体?
答:优缺点必须是针对本题的,不能写"计算速度快"这种与题目无关的泛泛之词。具体写法:优点要对应模型解决了哪些题目的核心难点;缺点要对应哪些现实因素被模型忽略了。每条优缺点后面加一句"这在本题中的影响是……",就能避免空泛。
Q15:附录代码应该如何整理?
答:附录代码的整理原则是可读性优先:每个函数一个文件;文件开头有功能说明注释;核心算法段前后有解释性注释;变量命名有意义(不要用a, b, x1, x2);删除调试用的临时代码和多余的注释。不要把所有代码堆在一个500行的main.m里——这是附录代码最常见的问题,让评委无法快速定位关键算法。
二十、总结
这道公交车调度题是数学建模中调度类问题的经典代表,它巧妙地融合了:
- 数据处理能力:从客流统计数据中提取有用信息(最大断面流量);
- 整数规划建模:把直觉上的"发车间隔"问题严格化为有约束的优化问题;
- 多目标评价:量化权衡不同主体(乘客/公司)的利益;
- 工程直觉:车辆数计算、高峰识别等需要对实际运营有基本了解。
通过这道题,你应当掌握:
- 最大断面流量的概念——这是所有公交/轨道交通调度问题的核心指标;
- 如何将"候车时间""载客率"等运营指标转化为数学约束;
- 如何用整数线性规划解决离散优化问题;
- 如何建立双方利益权衡的评价体系;
- 如何做灵敏度分析验证模型的稳健性。
最重要的是,这道题告诉我们:数学建模的本质不是套公式,而是用数学语言描述现实问题的结构,然后用已知工具解决它。 现实问题的复杂性永远超过模型的复杂性,所以好的建模者既要能精确刻画核心矛盾,又要能合理简化次要因素。
💪 给备赛同学的话:公交调度这类题目,初看很复杂,但一旦你掌握了"断面流量→班次需求→整数规划→综合评价"这条主线,你会发现类似问题(地铁调度、飞机排班、快递路线)都遵循同样的框架。建模的魅力正在于此——用同一套思维方法,解决不同领域的真实问题。加油!
声明:以上内容部分基于人工智能辅助生成,仅供参考交流,不构成任何专业建议。模型输出可能存在偏差,使用前请自行核实,后果自负。欢迎理性讨论。
若需原题 PDF、附件或历年高教社杯真题,关注技术号 「猿圈奇妙屋」,回复【高教社杯】即可获取。
🎁 文末福利
本专栏内容源自实际建模经验、竞赛题目及读者需求。如涉及版权问题,请告知,将立即处理。部分解法思路参考了网络优秀文章,若未能完全契合你的场景,欢迎在评论区分享更优解法,共同探讨、共同进步!
更多建模方法、工具与竞赛题解,欢迎访问专栏 👉 《《滚雪球学数学建模(含历年真题)》
如果本文对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续创作的动力!
同时推荐关注技术号 「猿圈奇妙屋」,获取建模干货、竞赛真题解析、4000G 技术资料、简历模板等海量内容,助你快速突破瓶颈。
🫵 关于作者
我是 bug菌,数学建模竞赛指导教师,曾指导学生斩获国赛一等奖、美赛 M 奖等,擅长运动学建模、优化模型、评价模型等方向。
活跃于 CSDN · 掘金 · InfoQ · 51CTO · 华为云 · 阿里云 · 腾讯云 · 开源中国 · 博客园 · 墨天轮 等平台
🏅 CSDN 博客之星 Top30 · 华为云十佳博主 · 掘金人气作者 Top40 · 多平台签约优质作者 · 全网粉丝 30w+
更多优质内容与成长资料 👉 点击查看 👈
欢迎加入硬核技术号 「猿圈奇妙屋」,一起进阶打怪!

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)