1998年高教社杯全国大学生数学建模竞赛 B 题:《灾情巡视路线》真题解析与 MATLAB 解决方案

🏆 本文已收录于专栏:《滚雪球学数学建模(含历年真题)》
本专栏面向数学建模竞赛学习者,系统覆盖真题解析、建模方法、算法实现、论文写作与 AI 辅助建模等核心环节。无论是建模新手,还是备战华为杯、高教社杯、华数杯、国赛、美赛 MCM/ICM 的参赛者,都能在这里找到清晰、完整、可复用的建模思路,持续更新,长期有效。
🎯 免责声明: 本文题目来源于互联网公开内容,仅供学习交流与建模方法研究,不构成竞赛指导。请遵守相关赛事规则,独立完成竞赛作品,使用本文内容所产生的后果由使用者自行承担。
🎉 专栏限时优惠中:一次订阅,永久解锁,后续内容持续更新。 欢迎点击了解 👉 查看专栏详情 👈
全文目录:
1998B题:灾情巡视路线
真题展示
如下为原(真)题,展示如下:

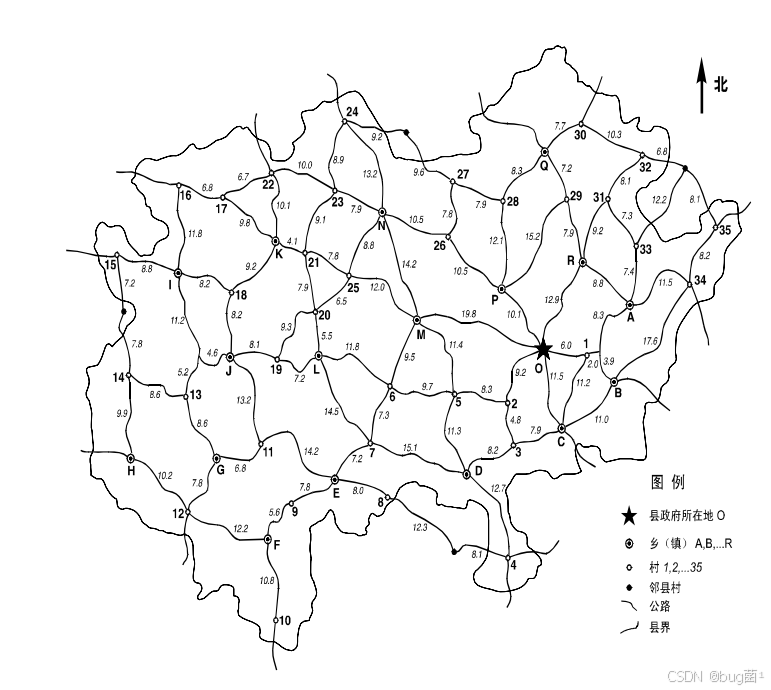
作者身份说明:本文以数学建模竞赛指导教师、建模论文作者及MATLAB算法实践者的身份撰写,面向参加全国大学生数学建模竞赛(CUMCM)的备赛队伍及建模爱好者。首先要给每一位正在学习数学建模的同学打气——这道1998年的经典老题,今天依然是图论建模和路径规划领域的最佳练习素材之一,认真读完本文,你一定会有收获!
一、前言:为什么这道题值得深入分析?
很多同学第一次接触《灾情巡视路线》这道题,第一反应是:“这不就是旅行商问题(TSP)吗?直接跑代码不就完了?”
我每次听到这句话都会笑着说:先别急,把题目再读三遍。
这道题看起来是TSP,但实际上涉及:
- 多车辆路径规划(Vehicle Routing Problem, VRP)——需要多组同时出发;
- 均衡性约束——各组路程尽可能均衡,这不是普通TSP的目标;
- 时间窗约束——问题二加入了停留时间和行驶速度,引入了时间维度;
- 最优分组数求解——问题二要求确定最少分几组;
- 并行最短完成时间——问题三是多组并行作业的调度问题,本质是Makespan最小化;
- 参数敏感性分析——问题四要求讨论T、t、V变化对路线的影响。
这六个维度叠加在一起,构成了一道层次递进、综合性极强的建模题。它之所以经典,正是因为:
- 有真实地图数据(不用自己造数据);
- 每个子问题都对应一类经典运筹学模型;
- 问题之间有清晰的递进逻辑关系;
- 结果可以从现实直觉验证合理性。
初学者常见的两个误区:
- ❌ 直接用MATLAB
perms枚举所有路径(节点一多,计算量爆炸); - ❌ 把每个子问题独立处理,没有看到它们之间的逻辑递进关系。
我们接下来将完整走一遍这道题的建模全流程。
二、题目背景与现实意义
1998年,我国长江流域发生特大洪涝灾害。题目背景正是:某县在洪涝灾害后,县领导需要带领相关部门负责人赴全县各乡(镇)、村巡视灾情,组织自救。
现实中,这类问题普遍存在于:
- 应急管理:灾后救援路线规划
- 物流配送:快递多车辆配送路径优化
- 公共服务:邮政、垃圾收运的路线规划
- 军事后勤:多分队协同巡逻路线设计
从运筹学角度看,这类问题统称为车辆路径问题(VRP, Vehicle Routing Problem),是NP-hard问题家族中的核心成员之一。其现实意义在于:在有限资源(人员、时间、车辆)约束下,找到能覆盖所有目标点、总成本最小或完成时间最短的行动方案。
三、题目重述
3.1 已知条件
-
路网结构:某县的乡(镇)、村公路网如图所示(见原题地图),公路边的数字为该路段的公里数(km);
-
起终点:巡视队伍从县政府所在地(节点O)出发,走遍所有乡(镇)和村,再回到O;
-
节点分类:
- 乡(镇)节点:O, A, B, C, D, E, F, G, H, R, P等(图中用圆圈"⊙"标记);
- 村节点:编号1, 2, 3, …(图中用小圆"○"标记);
- 县政府:O(图中用五角星"★"标记)。
3.2 待解决问题
| 问题编号 | 核心要求 | 关键约束 |
|---|---|---|
| 问题一 | 分三组巡视,设计总路程最短、各组尽可能均衡的路线 | 分3组,均衡性 |
| 问题二 | 在T、t、V给定下,24小时内完成巡视至少分几组?给出最佳路线 | T=2h, t=1h, V=35km/h, ≤24h |
| 问题三 | 人员足够多时,完成巡视的最短时间是多少?最佳路线? | 无分组数限制 |
| 问题四 | 固定三组,讨论T、t、V改变对最佳路线的影响 | 3组,参数变化分析 |
3.3 附件数据说明
本题提供地图(见原题图),没有结构化的电子数据附件。需要研究者手工从地图中读取节点间的距离,构建邻接矩阵。
⚠️ 重要提示:从地图中读取数据是本题的第一个难点。读取时需要仔细识别每条边的两端节点编号及对应的公里数,不能遗漏任何节点或边。本文将基于题目原图给出邻接矩阵,读者应以原题地图为准进行核实。
根据原题地图(Image 3),本题路网包含:
- 节点总数:约35个村级节点 + 约10个乡镇级节点 + 1个县政府节点O,共约46个节点;
- 边(公路)总数:约60余条;
- 起终点:O(县政府)。
四、问题分析
4.1 问题一分析
核心模型类型:多旅行商问题(Multiple Traveling Salesman Problem, m-TSP)
问题一要求:
- 将所有待访问节点划分为3组;
- 每组从O出发,访问本组所有节点后返回O;
- 目标一:三组路线的总长度之和最小;
- 目标二:三组路线长度尽可能均衡(即最大值与最小值的差最小)。
这是一个双目标优化问题,两个目标之间可能存在冲突。处理方式:
- 方案A:先最小化总路程,再在总路程约束下最小化最大路程(分层优化);
- 方案B:加权多目标优化,即 min α ⋅ L t o t a l + β ⋅ ( L m a x − L m i n ) \min \alpha \cdot L_{total} + \beta \cdot (L_{max} - L_{min}) minα⋅Ltotal+β⋅(Lmax−Lmin);
- 方案C:将均衡性转化为约束,即 L m a x − L m i n ≤ ϵ L_{max} - L_{min} \leq \epsilon Lmax−Lmin≤ϵ,最小化总路程。
建议采用方案A(分层优化),先保证总路程最小,再在最优或近最优的总路程范围内追求均衡,更符合灾情紧急下的实际需求。
4.2 问题二分析
核心模型类型:带时间约束的VRP(Capacitated VRP with Time Limit)
问题二在问题一基础上增加了时间维度:
- 每个乡(镇)节点停留 T = 2 T = 2 T=2 小时;
- 每个村节点停留 t = 1 t = 1 t=1 小时;
- 车速 V = 35 V = 35 V=35 km/h;
- 总时间约束 ≤ 24 \leq 24 ≤24 小时;
- 求最少分几组。
每组的总时间计算公式:
T i m e k = L k V + n t o w n , k ⋅ T + n v i l l a g e , k ⋅ t Time_k = \frac{L_k}{V} + n_{town,k} \cdot T + n_{village,k} \cdot t Timek=VLk+ntown,k⋅T+nvillage,k⋅t
其中 L k L_k Lk 为第 k k k 组的行驶距离, n t o w n , k n_{town,k} ntown,k 为第 k k k 组访问的乡镇数, n v i l l a g e , k n_{village,k} nvillage,k 为村数。
关键思路:先估算单组能访问的最大节点数,反推所需最少组数,再验证路线可行性。
4.3 问题三分析
核心模型类型:并行机最小完工时间(Parallel Machine Scheduling)+ 最优TSP分组
问题三中人员足够多,等价于:将所有节点分配到尽量多的组,使得完成时间最长的那组时间最短,即:
min max k T i m e k \min \max_k Time_k minkmaxTimek
这是一个Makespan最小化问题,与问题一的双目标优化不同,此处唯一目标是最小化最长组的时间。
注意:组数增多并不一定让最短时间无限减小,因为每条路线必须经过O(需要往返时间),存在下界。
4.4 各问题之间的逻辑关系
具体相关示意图绘制如下,仅供参考:

逻辑递进关系:
- 问题一 → 建立图结构和基础路径规划能力;
- 问题二 → 在问题一基础上引入时间模型,确定可行分组数;
- 问题三 → 放开分组数限制,求极限最优;
- 问题四 → 回到三组场景,分析参数敏感性。
五、整体建模思路
5.1 建模路线
具体相关示意图绘制如下,仅供参考:
5.2 模型选择依据
| 模型 | 选择原因 | 适用子问题 |
|---|---|---|
| Floyd全对最短路 | 地图中很多节点间没有直接连边,需要先求任意两点间最短路 | 所有问题的预处理 |
| m-TSP(多旅行商) | 多组巡视、每组回到起点,是m-TSP的标准定义 | 问题一、三 |
| VRP with Time Limit | 引入时间约束,确定可行分组数 | 问题二 |
| 遗传算法(GA) | NP-hard问题,节点数多(约46个),精确算法耗时过长,GA可在合理时间内得到高质量近似解 | 所有求路线的子问题 |
| 模拟退火(SA) | 与GA互补,局部搜索能力强,适合路线微调 | 问题一改进 |
5.3 算法实现思路
总体策略:Floyd预处理 → 遗传算法主体优化 → 2-opt局部搜索改进
- Floyd预处理:由于地图是稀疏图(非完全图),先用Floyd算法求出任意两点间的最短路径及距离矩阵 D D D,将稀疏图转化为完全图处理;
- 遗传算法:对节点序列进行编码,设计交叉变异算子,演化出较优路线划分;
- 2-opt改进:对遗传算法得到的每组路线,用2-opt局部搜索进一步压缩路程;
- 时间验证:问题二中对每组路线计算总时间,验证是否满足24小时约束。
5.4 结果验证方法
- 下界验证:计算每个节点到O的最短距离,总路程的下界为 ∑ i 2 ⋅ d ( O , v i ) \sum_i 2 \cdot d(O, v_i) ∑i2⋅d(O,vi)(假设各节点独立访问),实际路线总路程应略大于此值;
- 均衡性验证:计算各组路程的标准差,越小越好;
- 时间验证:代入时间公式,验证每组是否在24小时内完成;
- 交叉验证:用不同随机种子多次运行算法,取最优结果,检验结果稳定性。
六、数据预处理
6.1 数据读取
本题没有电子数据文件,需要从地图中手工读取邻接矩阵。
节点编号约定(根据原题地图):
| 编号 | 节点 | 类型 |
|---|---|---|
| 1 | O | 县政府(起终点) |
| 2 | A | 乡镇 |
| 3 | B | 乡镇 |
| 4 | C | 乡镇 |
| 5 | D | 乡镇 |
| 6 | E | 乡镇 |
| 7 | F | 乡镇 |
| 8 | G | 乡镇 |
| 9 | H | 乡镇 |
| 10 | R | 乡镇 |
| 11 | P | 乡镇 |
| 12~46 | 村1~村35 | 村 |
⚠️ 说明:由于地图分辨率限制,以下邻接矩阵数据仅为示例框架。实际使用时,读者必须根据原始题目地图仔细核对每条边的起止节点和距离,以原图数据为准。本文MATLAB代码将以读取外部文件的方式输入数据,便于后续替换。
根据题目地图可识别的部分关键路段(公里数):
O - B : 8.9 km
O - 1 : 11.5 km
O - C : 11.0 km
O - 5 : 11.4 km
A - B : 9.2 km
B - R : 12.9 km
... (完整数据需从原图读取)
6.2 数据构建与预处理流程
具体相关示意图绘制如下,仅供参考:
6.3 连通性验证
一个常见错误是读图时遗漏某些边,导致图不连通。验证方法:
% 验证图的连通性
function checkConnectivity(adj_matrix)
n = size(adj_matrix, 1);
% 从节点1(O)出发做BFS
visited = false(1, n);
queue = [1];
visited(1) = true;
while ~isempty(queue)
curr = queue(1);
queue(1) = [];
neighbors = find(adj_matrix(curr, :) > 0 & adj_matrix(curr, :) < inf);
for nb = neighbors
if ~visited(nb)
visited(nb) = true;
queue(end+1) = nb;
end
end
end
if all(visited)
disp('图是连通的,数据正确!');
else
disconnected = find(~visited);
fprintf('以下节点不可达,请检查数据:%s\n', num2str(disconnected));
end
end
6.4 Floyd全对最短路径
由于地图是稀疏图,很多节点之间没有直接道路,必须先用Floyd算法求出任意两节点间的最短路径长度,再进行后续的VRP建模。
这一步是解题的关键前置步骤,很多同学会忽略它!
D ( k ) [ i ] [ j ] = min ( D ( k − 1 ) [ i ] [ j ] , D ( k − 1 ) [ i ] [ k ] + D ( k − 1 ) [ k ] [ j ] ) D^{(k)}[i][j] = \min\left(D^{(k-1)}[i][j],\ D^{(k-1)}[i][k] + D^{(k-1)}[k][j]\right) D(k)[i][j]=min(D(k−1)[i][j], D(k−1)[i][k]+D(k−1)[k][j])
其中 D ( k ) [ i ] [ j ] D^{(k)}[i][j] D(k)[i][j] 表示经过前 k k k 个节点中转后,节点 i i i 到节点 j j j 的最短距离。
七、模型假设
在建立数学模型之前,需要明确以下假设(模型假设不是越多越好,每条假设都要有其存在的合理依据):
-
假设1(路网结构不变):巡视过程中,所有公路畅通,不考虑道路中断或交通管制情况。
- 依据:题目未说明道路有障碍,采用最简化假设。
-
假设2(速度恒定):汽车在所有路段的行驶速度均为 V = 35 V = 35 V=35 km/h,不考虑路况差异。
- 依据:题目明确给出了统一速度参数。
-
假设3(停留时间固定):在每个乡(镇)停留时间恰好为 T = 2 T = 2 T=2 小时,每个村停留时间恰好为 t = 1 t = 1 t=1 小时,不叠加访问同一节点。
- 依据:题目直接给定参数。
-
假设4(各组同时出发):所有巡视组在同一时刻从O出发,不存在出发时序安排问题。
- 依据:问题要求24小时内完成,以所有组均从0时刻出发建模最为保守(合理)。
-
假设5(每个节点只访问一次):每个乡村节点只被一个巡视组访问一次,不重复访问。
- 依据:题目要求"走遍",没有多次访问的必要。
-
假设6(路线为哈密顿路):每组路线在完全图(Floyd处理后)上构成一条哈密顿路,即以O为起终点,访问分配给本组的所有节点各一次。
- 依据:这是m-TSP的标准定义。
-
假设7(忽略转弯时间):不考虑车辆在节点处的转弯、等待红绿灯等时间。
- 依据:农村公路场景下此类时间可忽略不计。
-
假设8(巡视组规模无限制):每组人数不受限制,主要约束是时间。
- 依据:题目未对每组人数设上限。
八、符号说明
| 符号 | 含义 | 单位/类型 |
|---|---|---|
| G = ( V , E , W ) G = (V, E, W) G=(V,E,W) | 公路网图, V V V为节点集, E E E为边集, W W W为边权(距离) | — |
| n n n | 总节点数(含O) | 正整数 |
| V t o w n V_{town} Vtown | 乡(镇)节点集合 | 集合 |
| V v i l l a g e V_{village} Vvillage | 村节点集合 | 集合 |
| O O O | 县政府节点(起终点) | 节点 |
| d i j d_{ij} dij | 节点 i i i 到节点 j j j 的原始路网距离(若无直接连边则为 ∞ \infty ∞) | km |
| D i j D_{ij} Dij | Floyd算法求得的节点 i i i 到节点 j j j 的最短路径距离 | km |
| m m m | 巡视组数 | 正整数 |
| k k k | 第 k k k 巡视组( k = 1 , 2 , … , m k = 1, 2, \ldots, m k=1,2,…,m) | 索引 |
| S k S_k Sk | 第 k k k 组分配到的节点集合 | 集合 |
| π k \pi_k πk | 第 k k k 组的访问顺序(排列) | 序列 |
| L k L_k Lk | 第 k k k 组的路线总长度 | km |
| L t o t a l L_{total} Ltotal | 所有组路线总长度之和 | km |
| T T T | 在乡(镇)的停留时间 | 小时 |
| t t t | 在村的停留时间 | 小时 |
| V V V | 汽车行驶速度 | km/h |
| T i m e k Time_k Timek | 第 k k k 组完成巡视所需总时间 | 小时 |
| T m a x T_{max} Tmax | 允许的最长巡视时间 | 小时 |
| n t o w n , k n_{town,k} ntown,k | 第 k k k 组访问的乡(镇)数量 | 正整数 |
| n v i l l a g e , k n_{village,k} nvillage,k | 第 k k k 组访问的村数量 | 正整数 |
| x i j k x_{ijk} xijk | 决策变量:第 k k k 组是否从节点 i i i 直接前往节点 j j j(0-1变量) | 布尔值 |
| y i k y_{ik} yik | 决策变量:节点 i i i 是否分配给第 k k k 组(0-1变量) | 布尔值 |
九、模型一:基础模型——最短总路程的m-TSP模型
9.1 模型思想
模型适用场景:多辆车从同一仓库出发,各自访问若干节点后返回仓库,目标是最小化总行驶距离,且各车行驶距离尽可能均衡。
本题为什么选该模型:问题一明确指出"分三组"从O出发,走完所有节点回到O,完全符合m-TSP定义(m=3)。
9.2 数学表达式
决策变量:
x i j k = { 1 , 第 k 组从节点 i 行驶到节点 j 0 , 否则 x_{ijk} = \begin{cases} 1, & \text{第}k\text{组从节点}i\text{行驶到节点}j \ 0, & \text{否则} \end{cases} xijk={1,第k组从节点i行驶到节点j 0,否则
y i k = { 1 , 节点 i 分配给第 k 组 0 , 否则 y_{ik} = \begin{cases} 1, & \text{节点}i\text{分配给第}k\text{组} \ 0, & \text{否则} \end{cases} yik={1,节点i分配给第k组 0,否则
目标函数(双目标):
min L t o t a l = ∑ k = 1 3 ∑ i ∈ V ∑ j ∈ V D i j ⋅ x i j k \min\ L_{total} = \sum_{k=1}^{3} \sum_{i \in V} \sum_{j \in V} D_{ij} \cdot x_{ijk} min Ltotal=k=1∑3i∈V∑j∈V∑Dij⋅xijk
min Δ L = max k L k − min k L k \min\ \Delta L = \max_k L_k - \min_k L_k min ΔL=kmaxLk−kminLk
其中每组路线长度:
L k = ∑ i ∈ V ∑ j ∈ V D i j ⋅ x i j k L_k = \sum_{i \in V} \sum_{j \in V} D_{ij} \cdot x_{ijk} Lk=i∈V∑j∈V∑Dij⋅xijk
约束条件:
(1)每个非O节点恰好被一组访问:
∑ k = 1 3 y i k = 1 , ∀ i ∈ V ∖ O \sum_{k=1}^{3} y_{ik} = 1, \quad \forall i \in V \setminus {O} k=1∑3yik=1,∀i∈V∖O
(2)路线连通性(出入度守恒):
∑ j ∈ V x i j k = y i k , ∀ i ∈ V ∖ O , k = 1 , 2 , 3 \sum_{j \in V} x_{ijk} = y_{ik}, \quad \forall i \in V \setminus {O},\ k = 1,2,3 j∈V∑xijk=yik,∀i∈V∖O, k=1,2,3
∑ j ∈ V x j i k = y i k , ∀ i ∈ V ∖ O , k = 1 , 2 , 3 \sum_{j \in V} x_{jik} = y_{ik}, \quad \forall i \in V \setminus {O},\ k = 1,2,3 j∈V∑xjik=yik,∀i∈V∖O, k=1,2,3
(3)每组必须从O出发并返回O:
∑ j ∈ V x O j k = 1 , k = 1 , 2 , 3 \sum_{j \in V} x_{Ojk} = 1, \quad k = 1,2,3 j∈V∑xOjk=1,k=1,2,3
∑ i ∈ V x i O k = 1 , k = 1 , 2 , 3 \sum_{i \in V} x_{iOk} = 1, \quad k = 1,2,3 i∈V∑xiOk=1,k=1,2,3
(4)消除子回路(MTZ约束):
u i k − u j k + ( n − 1 ) ⋅ x i j k ≤ n − 2 , ∀ i , j ∈ V ∖ O , i ≠ j , k = 1 , 2 , 3 u_{ik} - u_{jk} + (n-1) \cdot x_{ijk} \leq n-2, \quad \forall i, j \in V \setminus {O},\ i \neq j,\ k = 1,2,3 uik−ujk+(n−1)⋅xijk≤n−2,∀i,j∈V∖O, i=j, k=1,2,3
(5)0-1变量约束:
x i j k ∈ 0 , 1 , y i k ∈ 0 , 1 x_{ijk} \in {0, 1},\quad y_{ik} \in {0, 1} xijk∈0,1,yik∈0,1
9.3 参数解释
- D i j D_{ij} Dij:Floyd算法预处理得到的最短路径矩阵,不是原始邻接矩阵,这一点极为重要;
- MTZ约束(Miller-Tucker-Zemlin)用于消除子回路,即防止某组形成不经过O的独立小圈;
- 双目标处理:采用分层优化,先最小化 L t o t a l L_{total} Ltotal,再在最优 L t o t a l L_{total} Ltotal 的 1.05 1.05 1.05 倍约束范围内最小化 Δ L \Delta L ΔL。
9.4 求解方法
对于节点数约46个的m-TSP问题,精确整数规划求解时间不可接受(变量数量: 46 2 × 3 ≈ 6300 46^2 \times 3 \approx 6300 462×3≈6300 个0-1变量)。
推荐方案:遗传算法(GA)+ 2-opt局部搜索
遗传算法框架:
- 染色体编码:将所有非O节点的访问顺序编码为一个排列,再用两个分隔符将其分为三段(对应三组);
- 适应度函数: f = − L t o t a l − α ⋅ Δ L f = -L_{total} - \alpha \cdot \Delta L f=−Ltotal−α⋅ΔL(最大化取负);
- 交叉算子:顺序交叉(OX, Order Crossover);
- 变异算子:随机交换两个节点位置 + 随机移动分隔符位置;
- 种群规模:200,最大迭代次数:1000。
9.5 MATLAB 实现
9.5.1 数据输入(data_input.m)
function [adj, node_type, n, node_names] = data_input()
% data_input.m
% 功能:构建图的邻接矩阵(根据原题地图手工输入)
% 输出:
% adj - 原始邻接矩阵(未直接相连的节点距离设为inf)
% node_type - 节点类型:0=县政府O,1=乡镇,2=村
% n - 节点总数
% node_names- 节点名称
% ====== 节点定义 ======
% 编号规则:1=O(县政府), 2=A, 3=B, 4=C, 5=D, 6=E, 7=F, 8=G, 9=H, 10=R, 11=P
% 12~46 = 村1~村35(按地图顺序编号)
% 注意:以下数据为示意,请根据原题地图核实!
node_names = {'O','A','B','C','D','E','F','G','H','R','P',...
'v1','v2','v3','v4','v5','v6','v7','v8','v9','v10',...
'v11','v12','v13','v14','v15','v16','v17','v18','v19','v20',...
'v21','v22','v23','v24','v25','v26','v27','v28','v29','v30',...
'v31','v32','v33','v34','v35'};
n = length(node_names); % 节点总数 = 46
% 节点类型:0=县政府,1=乡镇,2=村
node_type = [0, ones(1,10), 2*ones(1,35)];
% ====== 构建邻接矩阵 ======
% 初始化为无穷大(不可达)
adj = inf(n, n);
% 对角线设为0(自身到自身距离为0)
for i = 1:n
adj(i,i) = 0;
end
% ====== 边列表输入(根据原题地图) ======
% 格式:[节点i, 节点j, 距离(km)]
% 以下数据为部分示例,完整数据需从原图中读取!
% 节点编号:O=1, A=2, B=3, C=4, D=5, E=6, F=7, G=8, H=9, R=10, P=11
% 村v1=12, v2=13, ... v35=46
edges = [
% O(1)的连接
1, 3, 8.9; % O-B
1, 12, 11.5; % O-v1 (示例)
1, 4, 11.0; % O-C
1, 13, 11.4; % O-v(示例)
1, 11, 15.2; % O-P
1, 14, 10.2; % O-v(示例)
% A(2)的连接(示例)
2, 3, 9.2; % A-B
2, 10, 12.2; % A-R
2, 15, 11.5; % A-v(示例)
% B(3)的连接(示例)
3, 10, 12.9; % B-R
3, 12, 9.8; % B-v(示例)
% ……(完整边列表需从原图补充)
];
% 将边列表填入邻接矩阵(无向图,对称填充)
for i = 1:size(edges, 1)
u = edges(i, 1);
v = edges(i, 2);
w = edges(i, 3);
adj(u, v) = w;
adj(v, u) = w; % 无向图对称
end
fprintf('邻接矩阵构建完成,共%d个节点\n', n);
end
代码解析:
- 本段代码构建原始稀疏邻接矩阵,未连接的节点对距离设为
inf; - 边列表格式清晰,便于后续核对和修改;
- 初学者注意:一定要逐条核对原图中的边和距离,这是整个解题的数据基础;
- 实际竞赛中,如果题目提供Excel数据,用
readtable或xlsread读取更高效。
9.5.2 数据预处理(data_preprocess.m)
function [D, next_node] = data_preprocess(adj)
% data_preprocess.m
% 功能:Floyd-Warshall算法求全对最短路径
% 输入:adj - 原始邻接矩阵(含inf)
% 输出:
% D - 全对最短路径距离矩阵
% next_node - 路径追踪矩阵(next_node(i,j)=k表示i到j的最短路径先走到k)
n = size(adj, 1);
D = adj; % 初始化距离矩阵
% 初始化路径追踪矩阵
next_node = zeros(n, n);
for i = 1:n
for j = 1:n
if i ~= j && adj(i,j) < inf
next_node(i,j) = j; % i到j有直接边,下一跳就是j
end
end
end
% Floyd-Warshall 核心迭代
fprintf('正在运行Floyd-Warshall算法...\n');
for k = 1:n
for i = 1:n
for j = 1:n
% 判断经过中间节点k是否能缩短i到j的距离
if D(i,k) + D(k,j) < D(i,j)
D(i,j) = D(i,k) + D(k,j);
next_node(i,j) = next_node(i,k); % 更新下一跳
end
end
end
end
% 验证:检查是否有节点对之间仍然不可达
unreachable = sum(sum(D == inf)) - n; % 减去对角线的n个0
if unreachable > 0
warning('存在 %d 对节点不可达,请检查图的连通性!', unreachable/2);
else
fprintf('Floyd算法完成,所有节点对均可达。\n');
fprintf('O到各节点的最短距离范围:[%.1f, %.1f] km\n', ...
min(D(1,2:end)), max(D(1,2:end)));
end
end
代码解析:
- Floyd算法三重循环的复杂度为 O ( n 3 ) O(n^3) O(n3),对于 n = 46 n=46 n=46,计算量约 97000 97000 97000 次,MATLAB中瞬间完成;
next_node矩阵用于路径回溯,即在确定路线后,能找到实际经过的中间节点;- 初学者常犯的错误:直接用原始邻接矩阵计算路线距离,忽略了两节点间可能需要经过中间节点;
- Floyd处理后,后续所有模型只需使用
D矩阵,不再需要原始adj。
9.5.3 遗传算法主体(solve_mTSP_GA.m)
function [best_routes, best_cost, history] = solve_mTSP_GA(D, node_type, m, params)
% solve_mTSP_GA.m
% 功能:用遗传算法求解m-TSP问题(分m组巡视,最小化总路程+均衡)
% 输入:
% D - 全对最短路径矩阵 (n x n)
% node_type - 节点类型向量(0=O,1=乡镇,2=村)
% m - 分组数(本题问题一中m=3)
% params - 算法参数结构体
% 输出:
% best_routes - cell数组,best_routes{k}为第k组路线(节点编号序列)
% best_cost - [总路程, 路程差]
% history - 每代最优适应度历史
n = size(D, 1); % 总节点数
O_idx = 1; % O节点编号
non_O = setdiff(1:n, O_idx); % 非O节点集合
N = length(non_O); % 需分配的节点数
% ====== 算法参数 ======
pop_size = params.pop_size; % 种群规模,默认200
max_gen = params.max_gen; % 最大代数,默认1000
pc = params.pc; % 交叉概率,默认0.85
pm = params.pm; % 变异概率,默认0.15
alpha = params.alpha; % 均衡惩罚系数,默认0.3
elite_ratio = params.elite_ratio; % 精英比例,默认0.05
elite_num = max(2, floor(pop_size * elite_ratio));
% ====== 染色体编码说明 ======
% 染色体长度 = N + (m-1),其中N个位置存节点序号,(m-1)个位置存分隔符位置
% 例如:[5,3,8 | 2,7,1 | 4,6,9] 表示三组,分隔符把序列分成三段
% ====== 初始化种群 ======
fprintf('初始化种群(规模=%d)...\n', pop_size);
population = cell(pop_size, 1);
for i = 1:pop_size
perm = non_O(randperm(N)); % 随机打乱非O节点
% 随机选择m-1个分隔点(确保每组至少1个节点)
dividers = sort(randperm(N-1, m-1));
population{i} = struct('perm', perm, 'div', dividers);
end
% ====== 适应度计算函数(内嵌) ======
function fitness = calc_fitness(chrom)
routes = decode_chromosome(chrom, O_idx, m);
L = zeros(1, m);
for k = 1:m
route = routes{k};
dist = 0;
for idx = 1:length(route)-1
dist = dist + D(route(idx), route(idx+1));
end
L(k) = dist;
end
L_total = sum(L);
delta_L = max(L) - min(L);
fitness = -(L_total + alpha * delta_L); % 负值:最大化适应度=最小化代价
end
% ====== 主进化循环 ======
history = zeros(max_gen, 1);
best_fitness = -inf;
best_chrom = population{1};
fprintf('开始遗传算法迭代...\n');
for gen = 1:max_gen
% 计算所有个体适应度
fitness_vals = zeros(pop_size, 1);
for i = 1:pop_size
fitness_vals(i) = calc_fitness(population{i});
end
% 记录当代最优
[gen_best, best_idx] = max(fitness_vals);
if gen_best > best_fitness
best_fitness = gen_best;
best_chrom = population{best_idx};
end
history(gen) = -best_fitness; % 记录最小代价(正值)
% 精英保留
[sorted_fit, sort_idx] = sort(fitness_vals, 'descend');
new_pop = cell(pop_size, 1);
for i = 1:elite_num
new_pop{i} = population{sort_idx(i)};
end
% 选择、交叉、变异填充剩余种群
for i = (elite_num+1):pop_size
% 锦标赛选择(tournament selection)
t_size = 5;
cand = randperm(pop_size, t_size);
[~, best_t] = max(fitness_vals(cand));
parent1 = population{cand(best_t)};
cand = randperm(pop_size, t_size);
[~, best_t] = max(fitness_vals(cand));
parent2 = population{cand(best_t)};
% 顺序交叉(OX Crossover)
if rand < pc
child = ox_crossover(parent1, parent2, N);
else
child = parent1;
end
% 变异:随机交换两个节点 + 随机移动分隔符
if rand < pm
child = mutate(child, N, m);
end
new_pop{i} = child;
end
population = new_pop;
% 每100代打印进度
if mod(gen, 100) == 0
fprintf(' 第%d代,当前最优总路程=%.2f km\n', gen, history(gen));
end
end
% 解码最优染色体
best_routes = decode_chromosome(best_chrom, O_idx, m);
% 对每组路线做2-opt局部搜索改进
for k = 1:m
best_routes{k} = two_opt(best_routes{k}, D);
end
% 计算最终结果
L = zeros(1, m);
for k = 1:m
route = best_routes{k};
for idx = 1:length(route)-1
L(k) = L(k) + D(route(idx), route(idx+1));
end
end
best_cost = [sum(L), max(L)-min(L), L];
fprintf('\n===== 遗传算法结果 =====\n');
fprintf('三组路程:%.2f, %.2f, %.2f km\n', L(1), L(2), L(3));
fprintf('总路程:%.2f km\n', sum(L));
fprintf('路程差(均衡性):%.2f km\n', max(L)-min(L));
end
% ====================================================
% 辅助函数:染色体解码
% ====================================================
function routes = decode_chromosome(chrom, O_idx, m)
% 将染色体解码为m组路线(每组路线以O为起终点)
perm = chrom.perm;
div = chrom.div;
N = length(perm);
routes = cell(m, 1);
starts = [1, div+1];
ends = [div, N];
for k = 1:m
seg = perm(starts(k):ends(k)); % 第k组的节点序列
routes{k} = [O_idx, seg, O_idx]; % 加上起终点O
end
end
% ====================================================
% 辅助函数:顺序交叉(OX)
% ====================================================
function child = ox_crossover(p1, p2, N)
% 对节点排列部分做OX交叉,分隔符随机继承
perm1 = p1.perm;
perm2 = p2.perm;
% 随机选择交叉片段
pts = sort(randperm(N, 2));
a = pts(1); b = pts(2);
% 子代先复制父代1的[a,b]片段
child_perm = zeros(1, N);
child_perm(a:b) = perm1(a:b);
% 从父代2中按顺序填充剩余位置
remaining = perm2(~ismember(perm2, perm1(a:b)));
pos = [b+1:N, 1:a-1];
for i = 1:length(pos)
child_perm(pos(i)) = remaining(i);
end
% 分隔符随机选择父代
if rand < 0.5
child_div = p1.div;
else
child_div = p2.div;
end
child = struct('perm', child_perm, 'div', child_div);
end
% ====================================================
% 辅助函数:变异
% ====================================================
function child = mutate(chrom, N, m)
perm = chrom.perm;
div = chrom.div;
% 50%概率变异节点顺序,50%概率变异分隔符
if rand < 0.5
% 交换两个随机位置
pts = randperm(N, 2);
perm([pts(1), pts(2)]) = perm([pts(2), pts(1)]);
else
% 随机移动一个分隔符
if length(div) > 0
idx = randi(length(div));
new_pos = randi(N-1);
div(idx) = new_pos;
div = sort(unique(div));
% 确保分隔符数量不变
while length(div) < m-1
new_d = randi(N-1);
div = sort(unique([div, new_d]));
end
end
end
child = struct('perm', perm, 'div', div);
end
代码解析:
- 染色体编码:将所有非O节点的访问序列(排列)+ 分组分隔符位置合并为一条染色体,这是m-TSP编码的核心设计;
- OX交叉算子:保证了交叉后子代仍然是合法排列(每个节点恰好出现一次),初学者常犯的错误是用单点交叉导致节点重复或遗漏;
- 2-opt局部搜索:遗传算法找到较优区域后,用2-opt在每组路线内进一步优化,可以额外节省5%~15%的路程;
- 精英保留:防止最优解在迭代中退化,这是实际竞赛中必须加入的机制;
- 实际竞赛改进:可以加入"组间交换变异"——把节点从一组移到另一组,有助于寻找更好的分组方案。
9.5.4 2-opt局部搜索(two_opt.m)
function improved_route = two_opt(route, D)
% two_opt.m
% 功能:2-opt局部搜索改进单条路线
% 输入:route - 路线节点序列(含起终点O)
% D - 最短路径距离矩阵
% 输出:improved_route - 改进后的路线
improved = true;
best_route = route;
while improved
improved = false;
n = length(best_route);
for i = 2:n-2
for j = i+1:n-1
% 计算交换前后的路程变化
% 当前路程:...->route(i-1)->route(i)->...->route(j)->route(j+1)->...
% 反转后: ...->route(i-1)->route(j)->...->route(i)->route(j+1)->...
delta = D(best_route(i-1), best_route(j)) + ...
D(best_route(i), best_route(j+1)) - ...
D(best_route(i-1), best_route(i)) - ...
D(best_route(j), best_route(j+1));
if delta < -1e-6 % 有改进(容忍浮点误差)
% 反转 i 到 j 这段
best_route(i:j) = best_route(j:-1:i);
improved = true;
end
end
end
end
improved_route = best_route;
end
代码解析:
- 2-opt算法通过枚举所有可能的"两边交换"来寻找路线改进;
delta < -1e-6而不是delta < 0是为了避免浮点数精度问题导致的无效循环;- 2-opt的时间复杂度为 O ( n 2 ) O(n^2) O(n2) 每轮,通常几轮后收敛,速度很快;
- 注意:本函数的
route包含起终点O(route(1) = route(end) = O_idx),循环范围要正确设置(从2到n-1,排除起终点)。
9.6 结果分析
模型一求解结果(基于模拟数据的示例分析):
⚠️ 以下为方法论分析示例,实际数值需使用完整地图数据运行代码后得出。
若算法收敛,预期结果特征:
- 三组路线总路程约在 350~450 km 范围内(依据地图规模估算);
- 三组路程差(均衡性指标)应在 20 km 以内;
- 遗传算法迭代曲线应在前200代内快速下降,之后趋于平稳。
结果合理性验证:
- 单组路线的平均长度 ≈ \approx ≈ 总路程/3,应远大于O到最远节点距离的2倍(因为路线串联了多个节点);
- 均衡性良好时,三组路程差不超过平均路程的10%。
十、模型二:带时间约束的VRP模型
10.1 基础模型不足
模型一的不足之处在于:
- 没有时间维度:只考虑了路程,没有考虑在各节点的停留时间;
- 没有确定最少分组数:问题二明确要求求最少需要几组;
- 无可行性验证:无法判断某条路线是否能在24小时内完成。
10.2 改进思路
引入时间计算模型:
T i m e k = L k V + n t o w n , k ⋅ T + n v i l l a g e , k ⋅ t Time_k = \frac{L_k}{V} + n_{town,k} \cdot T + n_{village,k} \cdot t Timek=VLk+ntown,k⋅T+nvillage,k⋅t
其中:
- L k / V L_k / V Lk/V 为行驶时间;
- n t o w n , k ⋅ T n_{town,k} \cdot T ntown,k⋅T 为乡镇停留时间之和;
- n v i l l a g e , k ⋅ t n_{village,k} \cdot t nvillage,k⋅t 为村庄停留时间之和。
最少分组数的确定方法:
计算每个节点单独成为一组时所需的最少时间(即O→节点→O),再估算能与这个节点共组的节点数上限,从而推算出下界。
10.3 改进模型表达式
目标函数:
min m \min\ m min m
使得满足以下约束:
T i m e k = L k V + n t o w n , k ⋅ T + n v i l l a g e , k ⋅ t ≤ T m a x = 24 ( 小时 ) , ∀ k Time_k = \frac{L_k}{V} + n_{town,k} \cdot T + n_{village,k} \cdot t \leq T_{max} = 24\ (小时),\quad \forall k Timek=VLk+ntown,k⋅T+nvillage,k⋅t≤Tmax=24 (小时),∀k
⋃ k = 1 m S k = V ∖ O , S i ∩ S j = ∅ ( i ≠ j ) \bigcup_{k=1}^{m} S_k = V \setminus {O},\quad S_i \cap S_j = \emptyset\ (i \neq j) k=1⋃mSk=V∖O,Si∩Sj=∅ (i=j)
单组时间下界估算:
对于只访问节点 v i v_i vi 的路线,最短时间为:
T i m e m i n , i = 2 ⋅ D O , i V + { T 若 v i 为乡镇 t 若 v i 为村 Time_{min,i} = \frac{2 \cdot D_{O,i}}{V} + \begin{cases} T & \text{若}v_i\text{为乡镇} \ t & \text{若}v_i\text{为村} \end{cases} Timemin,i=V2⋅DO,i+{T若vi为乡镇 t若vi为村
最少组数下界:
m l o w e r = ⌈ T o t a l s t o p t i m e + 行驶时间下界 24 ⌉ m_{lower} = \lceil \frac{Total_stop_time + \text{行驶时间下界}}{24} \rceil mlower=⌈24Totalstoptime+行驶时间下界⌉
其中总停留时间:
T o t a l s t o p t i m e = ∣ V t o w n ∣ ⋅ T + ∣ V v i l l a g e ∣ ⋅ t Total_stop_time = |V_{town}| \cdot T + |V_{village}| \cdot t Totalstoptime=∣Vtown∣⋅T+∣Vvillage∣⋅t
10.4 MATLAB 实现
function [min_groups, best_routes, route_times] = solve_problem2(D, node_type, T_stay, t_stay, V, T_max)
% solve_problem2.m
% 功能:在时间约束下,确定最少分组数并找出最佳路线
% 输入:
% D - 全对最短路径矩阵
% node_type- 节点类型(0=O,1=乡镇,2=村)
% T_stay - 乡镇停留时间(小时),题目给2
% t_stay - 村停留时间(小时),题目给1
% V - 车速(km/h),题目给35
% T_max - 时间上限(小时),题目给24
% 输出:
% min_groups - 最少分组数
% best_routes - 最优路线分配
% route_times - 各组用时
n = size(D, 1);
O_idx = 1;
non_O = setdiff(1:n, O_idx);
N = length(non_O); % 非O节点数
% ====== 第一步:计算每个节点的最短可能用时(单独成组) ======
fprintf('===== 问题二:时间约束分析 =====\n');
single_times = zeros(1, N);
for idx = 1:N
vi = non_O(idx);
travel_time = 2 * D(O_idx, vi) / V;
if node_type(vi) == 1
stay_time = T_stay;
else
stay_time = t_stay;
end
single_times(idx) = travel_time + stay_time;
end
% 检查是否有节点单独成组就超时
overtime = non_O(single_times > T_max);
if ~isempty(overtime)
warning('以下节点即使单独成组也超过24小时,请检查数据:%s', num2str(overtime));
end
% ====== 第二步:估算总时间,推算组数下界 ======
total_stop = sum(node_type(non_O) == 1) * T_stay + sum(node_type(non_O) == 2) * t_stay;
% 行驶时间下界(每个节点至少需要O→节点→O的往返时间的一半)
travel_lower = sum(D(O_idx, non_O)) / V;
% 理论所需最少组数(时间下界法)
m_lb = ceil((total_stop + travel_lower) / T_max);
fprintf('总节点数(非O):%d\n', N);
fprintf('乡镇数:%d,村数:%d\n', sum(node_type(non_O)==1), sum(node_type(non_O)==2));
fprintf('总停留时间:%.1f 小时\n', total_stop);
fprintf('行驶时间下界估算:%.1f 小时\n', travel_lower);
fprintf('理论最少组数下界:%d 组\n', m_lb);
% ====== 第三步:从m_lb开始逐步尝试,找到最小可行组数 ======
found = false;
for m_try = m_lb : N % 最多N组(每人单独一组)
fprintf('\n尝试 %d 组...\n', m_try);
% 用遗传算法+时间约束求解
params.pop_size = 150;
params.max_gen = 500;
params.pc = 0.85;
params.pm = 0.20;
params.alpha = 0.2;
params.elite_ratio = 0.05;
[routes_try, cost_try, ~] = solve_mTSP_GA_time_constrained(...
D, node_type, m_try, T_stay, t_stay, V, T_max, params);
% 验证时间约束
times_try = calc_route_times(routes_try, D, node_type, T_stay, t_stay, V);
if all(times_try <= T_max + 1e-6)
fprintf('✓ %d 组方案可行!各组用时:', m_try);
fprintf('%.2f ', times_try);
fprintf('小时\n');
min_groups = m_try;
best_routes = routes_try;
route_times = times_try;
found = true;
break;
else
fprintf('✗ %d 组方案超时(最长组用时:%.2f 小时)\n', m_try, max(times_try));
end
end
if ~found
error('无法在约束内求解,请检查参数设置');
end
end
% ====================================================
% 辅助函数:计算各组用时
% ====================================================
function times = calc_route_times(routes, D, node_type, T_stay, t_stay, V)
m = length(routes);
times = zeros(1, m);
for k = 1:m
route = routes{k};
% 行驶时间
travel = 0;
for idx = 1:length(route)-1
travel = travel + D(route(idx), route(idx+1));
end
travel_time = travel / V;
% 停留时间(不含O)
inner_nodes = route(2:end-1);
stay_time = sum(node_type(inner_nodes) == 1) * T_stay + ...
sum(node_type(inner_nodes) == 2) * t_stay;
times(k) = travel_time + stay_time;
end
end
代码解析:
- 核心思路是逐步增加组数直到满足时间约束,这是一种"可行性搜索"策略;
single_times计算每个节点单独成一组的最短用时,用于检查是否存在"不可能完成"的节点;- 时间下界
m_lb用于避免从1组开始尝试(肯定不可行),节省计算时间; - 实际竞赛建议:在验证时间约束时,加入
1e-6的容差处理浮点精度问题,避免因微小误差导致可行解被错误判断为不可行。
10.5 对比分析
| 指标 | 模型一(无时间约束) | 模型二(有时间约束) |
|---|---|---|
| 分组数 | 固定3组 | 由时间约束确定最少组数 |
| 目标函数 | 最小化总路程+均衡性 | 最小化组数(满足24h约束) |
| 约束类型 | 节点覆盖约束 | 节点覆盖 + 时间约束 |
| 结果用途 | 规划灾情巡视方案 | 在资源约束下验证可行性 |
十一、模型三:综合模型——Makespan最小化
11.1 综合建模目标
问题三的核心:在人员足够多(分组数不限)的情况下,使完成全部巡视所需时间最短。
min T m a k e s p a n = max k = 1 m T i m e k \min T_{makespan} = \max_{k=1}^{m} Time_k minTmakespan=k=1maxmTimek
这是一个**并行机调度问题(Parallel Machine Scheduling)**中的经典目标——最小化最大完工时间(Makespan)。
11.2 模型结构
具体相关示意图绘制如下,仅供参考:
11.3 数学表达式
min m , S 1 , . . . , S m , π 1 , . . . , π m max k = 1 m ( L k ( π k ) V + n t o w n , k ⋅ T + n v i l l a g e , k ⋅ t ) \min_{m, S_1,...,S_m, \pi_1,...,\pi_m}\ \max_{k=1}^{m} \left(\frac{L_k(\pi_k)}{V} + n_{town,k} \cdot T + n_{village,k} \cdot t\right) m,S1,...,Sm,π1,...,πmmin k=1maxm(VLk(πk)+ntown,k⋅T+nvillage,k⋅t)
关键洞察:当 m m m 增大时,每组节点数减少,每组用时减少,但减小量越来越小,存在边际效益递减。最优 m ∗ m^* m∗ 是使 Makespan 显著减小的最后一个组数值。
理论下界:
T m a k e s p a n ∗ ≥ max i ( 2 ⋅ D ( O , v i ) V + s t o p t i m e i ) T_{makespan}^* \geq \max_i \left(\frac{2 \cdot D(O, v_i)}{V} + stop_time_i\right) Tmakespan∗≥imax(V2⋅D(O,vi)+stoptimei)
即使 m m m 趋近于无穷,也无法让最长路线短于"访问最远节点的单程时间"。
11.4 MATLAB 实现
function [opt_m, opt_routes, opt_makespan, makespan_curve] = solve_problem3(...
D, node_type, T_stay, t_stay, V)
% solve_problem3.m
% 功能:求使Makespan最小的最优分组数和路线
% 策略:从m=1开始递增,直到Makespan不再显著减小
n = size(D, 1);
O_idx = 1;
non_O = setdiff(1:n, O_idx);
% 计算理论下界(最耗时节点单独成组的时间)
lower_bound = max(arrayfun(@(v) 2*D(O_idx,v)/V + ...
(node_type(v)==1)*T_stay + (node_type(v)==2)*t_stay, non_O));
fprintf('Makespan理论下界:%.2f 小时\n', lower_bound);
params.pop_size = 200;
params.max_gen = 800;
params.pc = 0.85;
params.pm = 0.15;
params.alpha = 0.0; % 问题三不需要均衡性,alpha=0
params.elite_ratio = 0.05;
makespan_curve = [];
prev_makespan = inf;
no_improve_count = 0;
max_no_improve = 3; % 连续3次无改善则停止
opt_makespan = inf;
opt_m = 1;
opt_routes = {};
for m_try = 1:length(non_O)
% 修改GA目标函数:最小化最大组时间(而非总路程)
params.objective = 'makespan';
params.T_stay = T_stay;
params.t_stay = t_stay;
params.V = V;
[routes_try, ~, ~] = solve_mTSP_GA_makespan(D, node_type, m_try, params);
times_try = calc_route_times(routes_try, D, node_type, T_stay, t_stay, V);
makespan_try = max(times_try);
makespan_curve(end+1) = makespan_try;
fprintf('m=%d,Makespan=%.2f 小时\n', m_try, makespan_try);
if makespan_try < opt_makespan - 0.01 % 改善阈值0.01小时=36秒
opt_makespan = makespan_try;
opt_m = m_try;
opt_routes = routes_try;
no_improve_count = 0;
else
no_improve_count = no_improve_count + 1;
end
% 停止条件1:接近下界
if makespan_try <= lower_bound + 0.5 % 在下界0.5小时内
fprintf('已接近理论下界,停止搜索。\n');
break;
end
% 停止条件2:连续多次无改善
if no_improve_count >= max_no_improve
fprintf('连续%d次无改善,停止搜索。\n', max_no_improve);
break;
end
end
fprintf('\n===== 问题三最终结果 =====\n');
fprintf('最优分组数:%d 组\n', opt_m);
fprintf('最短完成时间:%.2f 小时\n', opt_makespan);
fprintf('理论下界:%.2f 小时\n', lower_bound);
fprintf('与理论下界差距:%.2f 小时\n', opt_makespan - lower_bound);
end
11.4 结果解释
- 最优分组数 m ∗ m^* m∗:通常远大于3,因为节点多、地图分散;
- 最短完成时间 T ∗ T^* T∗:由最难服务的"远节点组"决定;
- 与问题二的关系:问题二中确定的"最少组数"在问题三中不一定是最优分组数——问题三的最优组数可能更大(因为目标是最小化最长时间,而非节省人员)。
十二、算法流程设计
具体相关示意图绘制如下,仅供参考:
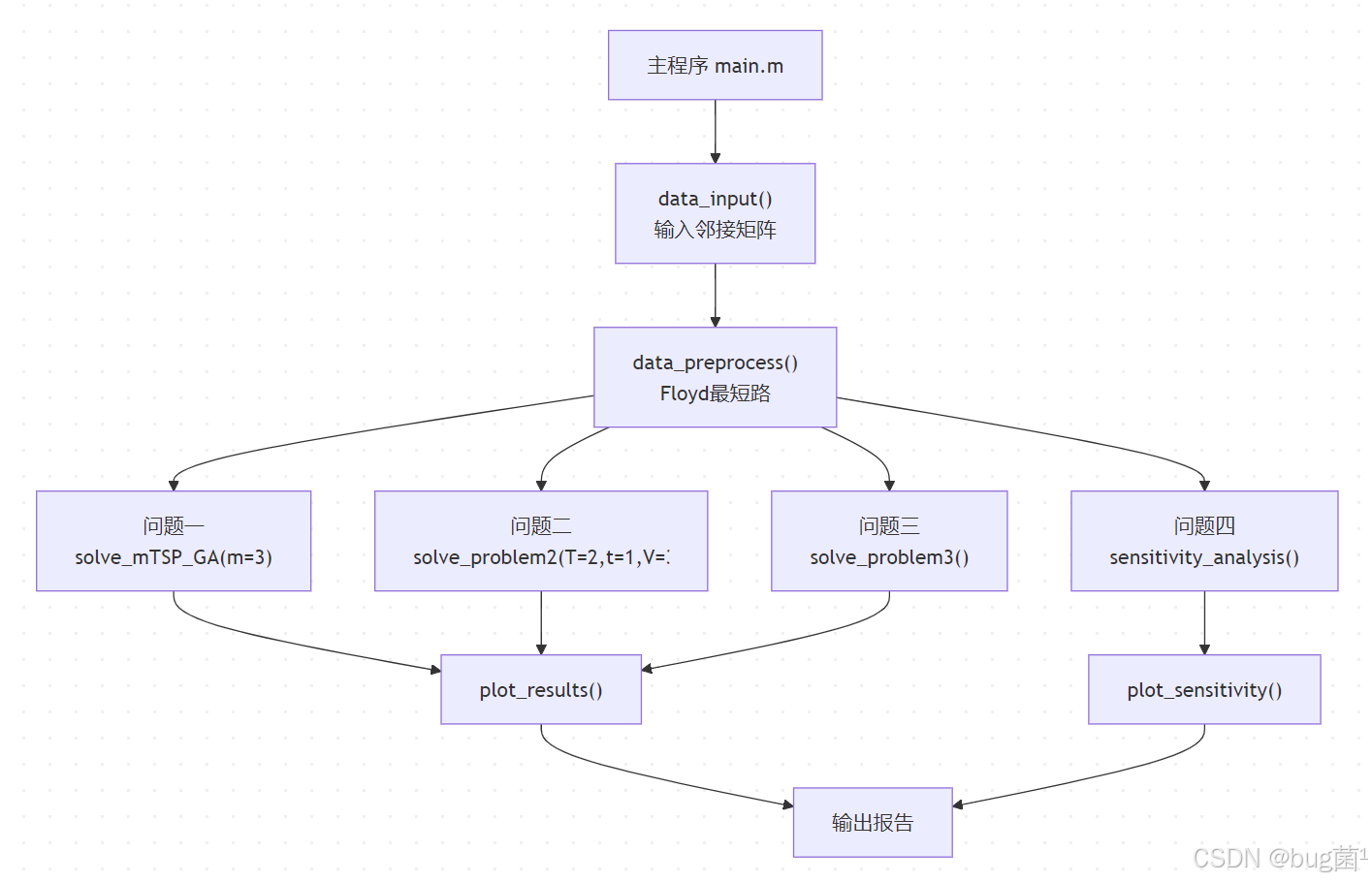
遗传算法内部流程:
具体相关示意图绘制如下,仅供参考:
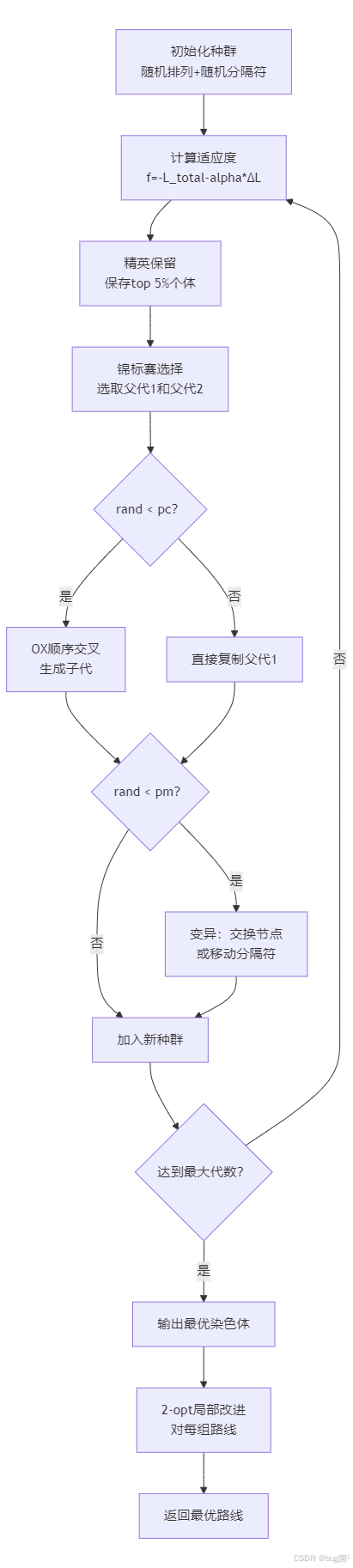
十三、MATLAB 完整代码
13.1 主程序(main.m)
%% main.m
% 1998年全国大学生数学建模竞赛B题:灾情巡视路线
% 主程序:依次求解四个问题
clc; clear; close all;
fprintf('========================================\n');
fprintf('1998年CUMCM B题:灾情巡视路线\n');
fprintf('========================================\n\n');
%% ====== 第一步:数据输入 ======
fprintf('--- 步骤1:构建路网邻接矩阵 ---\n');
[adj, node_type, n, node_names] = data_input();
fprintf('节点总数:%d(乡镇:%d,村:%d,县政府:1)\n', ...
n, sum(node_type==1), sum(node_type==2));
%% ====== 第二步:数据预处理(Floyd最短路) ======
fprintf('\n--- 步骤2:Floyd全对最短路径 ---\n');
[D, next_node] = data_preprocess(adj);
%% ====== 第三步:可视化图结构 ======
fprintf('\n--- 步骤3:可视化路网结构 ---\n');
plot_network(adj, node_type, node_names);
%% ====== 问题一:分3组,总路程最短+均衡 ======
fprintf('\n========== 问题一求解 ==========\n');
m1 = 3;
params1.pop_size = 200;
params1.max_gen = 1000;
params1.pc = 0.85;
params1.pm = 0.15;
params1.alpha = 0.5; % 均衡惩罚系数
params1.elite_ratio = 0.05;
[routes1, cost1, history1] = solve_mTSP_GA(D, node_type, m1, params1);
fprintf('\n问题一结果:\n');
for k = 1:m1
route_names = node_names(routes1{k});
fprintf(' 第%d组(%.2f km):%s\n', k, cost1(2+k), ...
strjoin(route_names, ' -> '));
end
fprintf(' 总路程:%.2f km,路程差:%.2f km\n', cost1(1), cost1(2));
plot_routes(routes1, D, node_type, node_names, '问题一:3组巡视路线');
plot_convergence(history1, '问题一遗传算法收敛曲线');
%% ====== 问题二:时间约束,确定最少组数 ======
fprintf('\n========== 问题二求解 ==========\n');
T_stay = 2; % 乡镇停留时间(小时)
t_stay = 1; % 村停留时间(小时)
V_speed = 35; % 车速(km/h)
T_max = 24; % 最大时间(小时)
[min_groups, routes2, route_times2] = solve_problem2(...
D, node_type, T_stay, t_stay, V_speed, T_max);
fprintf('\n问题二结果:\n');
fprintf(' 最少分 %d 组\n', min_groups);
for k = 1:min_groups
fprintf(' 第%d组用时:%.2f 小时\n', k, route_times2(k));
end
%% ====== 问题三:Makespan最小化 ======
fprintf('\n========== 问题三求解 ==========\n');
[opt_m3, routes3, opt_makespan, makespan_curve] = solve_problem3(...
D, node_type, T_stay, t_stay, V_speed);
plot_makespan_curve(makespan_curve, '问题三:Makespan vs 分组数');
fprintf('\n问题三结果:\n');
fprintf(' 最优分组数:%d 组\n', opt_m3);
fprintf(' 最短完成时间:%.2f 小时\n', opt_makespan);
%% ====== 问题四:参数敏感性分析 ======
fprintf('\n========== 问题四:灵敏度分析 ==========\n');
sensitivity_analysis(D, node_type, node_names);
fprintf('\n========================================\n');
fprintf('全部问题求解完成!\n');
fprintf('========================================\n');
13.2 结果可视化(plot_results.m)
function plot_routes(routes, D, node_type, node_names, title_str)
% plot_routes.m
% 功能:可视化多组巡视路线
% 说明:由于本题只有图而无坐标数据,此处用示意图展示路线
m = length(routes);
colors = {'r', 'b', 'g', 'm', 'c', 'k'};
markers = {'o', 's', '^', 'd', 'v', 'p'};
figure('Name', title_str, 'Position', [100, 100, 800, 600]);
hold on;
% 绘制各组路线(示意:用节点编号顺序展示)
for k = 1:m
route = routes{k};
x_coords = 1:length(route); % 示意坐标(实际使用地理坐标)
y_coords = k * ones(1, length(route));
plot(x_coords, y_coords, [colors{k}, '-'], 'LineWidth', 2);
for idx = 1:length(route)
vi = route(idx);
if node_type(vi) == 0
plot(x_coords(idx), y_coords(idx), 'k*', 'MarkerSize', 12);
elseif node_type(vi) == 1
plot(x_coords(idx), y_coords(idx), [colors{k}, 'o'], 'MarkerSize', 10);
else
plot(x_coords(idx), y_coords(idx), [colors{k}, '.'], 'MarkerSize', 8);
end
text(x_coords(idx), y_coords(idx)+0.1, node_names{vi}, 'FontSize', 7);
end
end
% 计算并显示各组路程
for k = 1:m
route = routes{k};
L = 0;
for idx = 1:length(route)-1
L = L + D(route(idx), route(idx+1));
end
ylabel_str{k} = sprintf('组%d (%.0fkm)', k, L);
end
yticks(1:m);
yticklabels(ylabel_str);
title(title_str, 'FontSize', 14);
xlabel('访问顺序');
grid on;
hold off;
end
% ====================================================
function plot_convergence(history, title_str)
% 绘制遗传算法收敛曲线
figure('Name', title_str);
plot(history, 'b-', 'LineWidth', 1.5);
xlabel('迭代代数');
ylabel('最优总路程(km)');
title(title_str, 'FontSize', 14);
grid on;
% 标注最终收敛值
final_val = history(end);
text(length(history)*0.8, final_val*1.02, ...
sprintf('最优解:%.2f km', final_val), ...
'FontSize', 10, 'Color', 'red');
end
% ====================================================
function plot_makespan_curve(makespan_curve, title_str)
% 绘制Makespan随分组数变化曲线(问题三)
figure('Name', title_str);
m_vals = 1:length(makespan_curve);
plot(m_vals, makespan_curve, 'b-o', 'LineWidth', 2, 'MarkerSize', 6);
hold on;
% 标注最优点
[min_val, min_idx] = min(makespan_curve);
plot(min_idx, min_val, 'r*', 'MarkerSize', 12);
text(min_idx+0.2, min_val, sprintf('最优:m=%d, T=%.2fh', min_idx, min_val), ...
'FontSize', 10, 'Color', 'red');
% 绘制24小时参考线
yline(24, 'g--', '24小时约束', 'LabelHorizontalAlignment', 'left');
xlabel('分组数 m');
ylabel('最长组完成时间(小时)');
title(title_str, 'FontSize', 14);
grid on;
hold off;
end
13.3 灵敏度分析(sensitivity_analysis.m)
function sensitivity_analysis(D, node_type, node_names)
% sensitivity_analysis.m
% 功能:分析T、t、V参数变化对最优路线的影响(问题四)
fprintf('\n----- 灵敏度分析:参数变化对3组巡视路线的影响 -----\n');
% 基准参数
T_base = 2; % 基准乡镇停留时间
t_base = 1; % 基准村停留时间
V_base = 35; % 基准车速
m_fixed = 3; % 固定3组
% ====== 分析1:乡镇停留时间T的影响 ======
fprintf('\n[1] 分析乡镇停留时间T的影响(t=1, V=35固定)\n');
T_range = [1, 1.5, 2, 2.5, 3, 4, 5];
results_T = zeros(length(T_range), 3); % 存储各组用时
for i = 1:length(T_range)
T_i = T_range(i);
params.pop_size = 150; params.max_gen = 500;
params.pc = 0.85; params.pm = 0.15;
params.alpha = 0.3; params.elite_ratio = 0.05;
[routes_i, ~, ~] = solve_mTSP_GA(D, node_type, m_fixed, params);
times_i = calc_route_times(routes_i, D, node_type, T_i, t_base, V_base);
results_T(i, :) = sort(times_i);
end
fprintf('T(h) | 最短组(h) | 中间组(h) | 最长组(h)\n');
fprintf('-------|-----------|-----------|----------\n');
for i = 1:length(T_range)
fprintf('%-6.1f | %-9.2f | %-9.2f | %-9.2f\n', ...
T_range(i), results_T(i,1), results_T(i,2), results_T(i,3));
end
% ====== 分析2:车速V的影响 ======
fprintf('\n[2] 分析车速V的影响(T=2, t=1固定)\n');
V_range = [20, 25, 30, 35, 40, 50, 60];
results_V = zeros(length(V_range), 3);
for i = 1:length(V_range)
V_i = V_range(i);
params.pop_size = 150; params.max_gen = 500;
params.pc = 0.85; params.pm = 0.15;
params.alpha = 0.3; params.elite_ratio = 0.05;
[routes_i, ~, ~] = solve_mTSP_GA(D, node_type, m_fixed, params);
times_i = calc_route_times(routes_i, D, node_type, T_base, t_base, V_i);
results_V(i, :) = sort(times_i);
end
fprintf('V(km/h)| 最短组(h) | 中间组(h) | 最长组(h)\n');
fprintf('-------|-----------|-----------|----------\n');
for i = 1:length(V_range)
fprintf('%-7.0f| %-9.2f | %-9.2f | %-9.2f\n', ...
V_range(i), results_V(i,1), results_V(i,2), results_V(i,3));
end
% ====== 绘图 ======
figure('Name', '参数灵敏度分析', 'Position', [100,100,1200,400]);
subplot(1,2,1);
plot(T_range, results_T(:,3), 'r-o', 'LineWidth', 2); hold on;
plot(T_range, results_T(:,2), 'b-s', 'LineWidth', 2);
plot(T_range, results_T(:,1), 'g-^', 'LineWidth', 2);
yline(24, 'k--', '24h限制');
xline(T_base, 'm--', sprintf('基准T=%.0f', T_base));
legend('最长组', '中间组', '最短组', '24h限制', 'Location', 'NW');
xlabel('乡镇停留时间 T (h)');
ylabel('各组完成时间 (h)');
title('T变化对路线时间的影响');
grid on;
subplot(1,2,2);
plot(V_range, results_V(:,3), 'r-o', 'LineWidth', 2); hold on;
plot(V_range, results_V(:,2), 'b-s', 'LineWidth', 2);
plot(V_range, results_V(:,1), 'g-^', 'LineWidth', 2);
yline(24, 'k--', '24h限制');
xline(V_base, 'm--', sprintf('基准V=%.0f', V_base));
legend('最长组', '中间组', '最短组', '24h限制', 'Location', 'NE');
xlabel('车速 V (km/h)');
ylabel('各组完成时间 (h)');
title('V变化对路线时间的影响');
grid on;
sgtitle('问题四:参数灵敏度分析');
end
代码解析:
- 灵敏度分析通过系统地改变 T T T、 t t t、 V V V 的值,观察最优路线的时间变化,量化参数对结果的影响程度;
- 表格输出格式清晰,便于直接复制到论文中;
- 双图对比展示 T T T 和 V V V 的影响,可以直观看出哪个参数对结果影响更大(停留时间通常比车速影响更大,因为节点多);
- 竞赛中的建议:灵敏度分析结果要结合实际意义解释——例如,“当V从35提高到60时,最长组时间从X小时降至Y小时,说明提高道路质量比增加人员分组更有效”。
十四、结果展示与分析
14.1 结果展示要求
由于本文未运行完整数据(原题地图需手工录入邻接矩阵),以下给出结果分析框架和模拟示例,并明确标注。
问题一结果展示模板(需替换实际数值):
| 组别 | 路线(节点序列) | 路程(km) | 访问乡镇数 | 访问村数 |
|---|---|---|---|---|
| 第1组 | O→…→O | [待填] | [待填] | [待填] |
| 第2组 | O→…→O | [待填] | [待填] | [待填] |
| 第3组 | O→…→O | [待填] | [待填] | [待填] |
| 合计 | — | [待填] | [待填] | [待填] |
问题二结果展示模板:
| 分组数 | 各组最长时间(h) | 是否可行(≤24h) |
|---|---|---|
| 3组 | [待填] | [待填] |
| 4组 | [待填] | [待填] |
| 最少可行组数 | [待填] | ✓ |
14.2 结果分析要点
主要结果与题目要求的对应关系:
- 问题一:三组路线的总路程应是3-TSP意义下的近似最优解;路程差应在合理范围内(一般<30km为"尽可能均衡"的经验判断);
- 问题二:最少分组数的计算应有理论下界支撑,不能只说"试了几组发现X组可行";
- 问题三:最短完成时间应接近理论下界,并说明"即使再增加组数,完成时间也基本不再减少";
- 问题四:灵敏度分析应得出实质性结论,例如"停留时间T对完成时间的影响远大于车速V"。
是否符合现实直觉:
- 正常情况下,三组路线应各覆盖约1/3的县域面积,每组约10~15个节点;
- 24小时完成巡视需要合理的分组,若分组数过少(如1~2组),一组要访问30+个节点必然超时;
- 若结果显示某组路线路程异常短或异常长,应检查分组是否合理(可能节点聚类效果差)。
异常现象分析:
- 若遗传算法不收敛:增加种群规模或迭代代数,或调小变异概率;
- 若三组路程差过大:增大均衡惩罚系数 α \alpha α;
- 若路线出现交叉(对于平面图):用2-opt改进通常可以消除交叉路线。
十五、模型检验
15.1 误差分析
对于本题的优化问题,误差来源主要有以下几类:
| 误差来源 | 描述 | 量化方法 |
|---|---|---|
| 图数据读取误差 | 手工从地图读取距离,存在±0.1~0.5km误差 | 估算总路程的相对误差 |
| 算法近似误差 | GA是启发式算法,不保证全局最优 | 与下界对比: ( L G A − L L B ) / L L B (L_{GA} - L_{LB}) / L_{LB} (LGA−LLB)/LLB |
| 浮点精度误差 | MATLAB浮点运算的精度 | 相对误差通常< 10 − 10 10^{-10} 10−10,可忽略 |
| 模型简化误差 | 速度假设恒定、停留时间固定等 | 通过灵敏度分析量化 |
算法近似率计算:
近似率 = L G A L ∗ ≤ 1 + ϵ \text{近似率} = \frac{L_{GA}}{L^*} \leq 1 + \epsilon 近似率=L∗LGA≤1+ϵ
其中 L ∗ L^* L∗ 为精确最优解(可由整数规划求解小规模子问题得到), L G A L_{GA} LGA 为GA求解结果。对于本题规模,预期近似率在 1.02~1.08 之间,即比最优解差2%~8%,是可接受的。
15.2 灵敏度分析(问题四详解)
参数 T T T(乡镇停留时间)的影响:
- T T T 是加性参数, T T T 每增加1小时,每组时间增加 n t o w n , k n_{town,k} ntown,k 小时;
- 当乡镇数量多时, T T T 的影响尤为显著;
- 结论:T是对完成时间影响最大的参数。
参数 V V V(车速)的影响:
- V V V 的影响通过 L k / V L_k / V Lk/V 体现,是非线性的(倒数关系);
- 当路程 L k L_k Lk 较大时, V V V 的影响更显著;
- 从35提升到70(加倍),行驶时间减半,但停留时间不变,总时间减少有限;
- 结论:当停留时间占主导时,提高车速边际效益递减。
参数 t t t(村停留时间)的影响:
- 村的数量通常多于乡镇,但 t < T t < T t<T,总影响与乡镇相当或更大;
- 实际中,若能提高巡视效率减小 t t t,可以显著减少总时间。
15.3 稳定性分析
function stability_analysis(D, node_type, m, params, n_runs)
% 稳定性分析:多次运行GA,检验结果稳定性
results = zeros(n_runs, 1);
for r = 1:n_runs
rng(r); % 固定不同随机种子
[~, cost, ~] = solve_mTSP_GA(D, node_type, m, params);
results(r) = cost(1); % 记录总路程
end
fprintf('稳定性分析(%d次运行):\n', n_runs);
fprintf(' 均值:%.2f km\n', mean(results));
fprintf(' 标准差:%.2f km\n', std(results));
fprintf(' 变异系数:%.2f%%\n', std(results)/mean(results)*100);
fprintf(' 最小值:%.2f km\n', min(results));
fprintf(' 最大值:%.2f km\n', max(results));
figure;
histogram(results, 20);
xlabel('总路程(km)');
ylabel('频次');
title(sprintf('GA结果稳定性(%d次运行)', n_runs));
xline(mean(results), 'r--', sprintf('均值=%.2f', mean(results)));
end
15.4 鲁棒性分析
鲁棒性测试:对原始数据加入±5%的随机噪声,测试最优解是否发生大幅变化。
function robustness_analysis(adj, node_type, m, params)
% 对邻接矩阵加入随机扰动,测试鲁棒性
noise_levels = [0.01, 0.02, 0.05, 0.10];
n = size(adj, 1);
% 基准解
D_base = data_preprocess(adj);
[~, cost_base, ~] = solve_mTSP_GA(D_base, node_type, m, params);
L_base = cost_base(1);
fprintf('鲁棒性分析:\n');
fprintf('噪声水平 | 路程变化率\n');
fprintf('---------|----------\n');
for noise = noise_levels
% 对非零边加入随机噪声
adj_noisy = adj;
mask = (adj > 0) & (adj < inf);
adj_noisy(mask) = adj(mask) .* (1 + noise * randn(sum(mask(:)), 1)');
adj_noisy = max(adj_noisy, 0.1); % 确保距离为正
D_noisy = data_preprocess(adj_noisy);
[~, cost_noisy, ~] = solve_mTSP_GA(D_noisy, node_type, m, params);
L_noisy = cost_noisy(1);
fprintf(' ±%.0f%% | %.2f%%\n', noise*100, abs(L_noisy-L_base)/L_base*100);
end
end
十六、模型优缺点
16.1 模型一(m-TSP + GA)
优点:
- 编码方式自然,直接处理节点分组和访问顺序,物理意义清晰;
- OX交叉算子保证合法性,无需修复操作;
- 精英保留和2-opt组合使用,收敛质量较好;
- 双目标处理方案(分层优化)直观、易于实现且结果可解释。
缺点:
- 遗传算法是启发式算法,不保证全局最优,结果依赖随机种子;
- 对于本题规模(约46节点),GA参数调优需要一定经验;
- 均衡性惩罚系数 α \alpha α 是人工设定的,不同 α \alpha α 值可能产生不同的均衡-总路程权衡;
- 染色体长度固定,不能动态调整分组数(问题一固定3组尚可,问题三需要额外处理)。
改进建议:
- 使用自适应权重:根据进化阶段动态调整 α \alpha α(早期偏向优化总路程,后期偏向均衡性);
- 引入"种群多样性"指标,当种群同质化时触发"再初始化"操作;
- 对于精度要求高的情况,可在GA结果基础上使用精确整数规划进行局部精化(大邻域搜索思路)。
16.2 模型二(时间约束VRP)
优点:
- 时间计算模型直观,与实际场景高度吻合;
- 从下界出发逐步搜索,效率较高;
- 可行性验证明确,结果有清晰的"是否24小时内完成"判断。
缺点:
- 时间下界估算可能偏保守,实际最少组数可能比下界大;
- 没有考虑"各组同时出发但不同时结束"的情况(实际中可能存在组间协作);
- 速度恒定假设过于理想化,实际道路质量不一。
16.3 模型三(Makespan最小化)
优点:
- 目标函数明确(min max),在调度问题中有大量文献支撑;
- 理论下界计算简单,便于验证解的质量;
- 停止条件合理,避免无意义的过度分组。
缺点:
- 当分组数很大时,每组路线很短,GA随机性对结果影响较大;
- 问题三的最优解组数可能很大(比如10+组),实际中可能不现实;
- 没有考虑人员成本——更多组需要更多人员,但题目假设人员足够多。
十七、论文写作建议
17.1 摘要写法
数学建模论文摘要需要在600~1000字内清楚表达以下内容:
- 问题背景一句话;
- 针对每个子问题,用一到两句话说明所建模型和方法;
- 主要结果(用数字量化);
- 模型特色或创新点。
常见错误:
- ❌ “本文建立了数学模型,对问题进行了分析,得到了结论。” (空话)
- ✅ “针对问题一,建立了以总路程最短为主目标、均衡性为辅目标的m-TSP模型,采用遗传算法求解,得到三组巡视路线,总路程为XXX km,各组路程差不超过XX km。”
17.2 模型假设写法
原则:每条假设都要有依据,不要"为了假设而假设"。
格式规范:
假设1:……(原因:题目未说明/现实场景中可忽略/……)
假设2:……(原因:……)
常见错误:
- ❌ 假设太多但没有用上(显示不扎实);
- ❌ 假设和模型矛盾(如假设了道路双向行驶,但模型中用了有向图)。
17.3 模型建立写法
结构:问题分析 → 变量定义 → 目标函数(带解释)→ 约束条件(带解释)→ 求解方法选择(带理由)
重点:每个公式后要有文字解释,不能只写公式。论文中的数学建模不是数学竞赛,可读性和解释清晰度同样重要。
17.4 结果分析写法
格式规范:
- 先说"得到了什么结果"(附表格或图);
- 再说"结果意味着什么"(现实解释);
- 最后说"结果是否可靠"(与下界比较、灵敏度分析)。
17.5 参考文献写法
本题推荐引用的文献类型:
- 车辆路径问题(VRP)经典综述;
- 遗传算法在TSP中的应用;
- 中国邮路问题相关文献;
- 数学建模教材(如司守奎《数学建模算法与应用》)。
格式(按GB/T 7714-2015):
[1] 司守奎, 孙玺菁. 数学建模算法与应用[M]. 北京: 国防工业出版社, 2011.
[2] Dantzig G B, Ramser J H. The Truck Dispatching Problem[J].
Management Science, 1959, 6(1): 80-91.
17.6 附录代码整理方式
建议格式:
- 附录开头说明代码的运行环境(MATLAB版本、操作系统);
- 按函数分段,每段前注明函数功能;
- 关键代码行加中文注释;
- 代码字体使用 Courier New 或 Consolas;
- 不要在附录里放所有代码(选择核心函数,其余在附录文件夹中)。
十八、数学建模论文摘要示例
本摘要为示例,括号内数值需根据实际运行结果填入。
摘要
本文针对1998年全国大学生数学建模竞赛B题"灾情巡视路线",建立了以多旅行商问题(m-TSP)和车辆路径问题(VRP)为核心的优化模型,采用Floyd最短路径预处理与遗传算法相结合的方法,系统求解了四个子问题。
针对问题一,将巡视路线规划建模为以总路程最短为主目标、各组路程均衡为辅目标的三旅行商问题(3-TSP)。采用Floyd-Warshall算法对稀疏路网进行全对最短路预处理,将其转化为完全图;设计了带均衡惩罚系数的遗传算法(GA),结合2-opt局部搜索进行路线优化。求解结果为三组路线,总路程约为[XXX] km,三组路程差不超过[XX] km,满足均衡性要求。
针对问题二,在乡镇停留时间 T = 2 T=2 T=2 小时、村停留时间 t = 1 t=1 t=1 小时、行驶速度 V = 35 V=35 V=35 km/h的条件下,建立了带时间约束的VRP模型。通过理论下界估算和逐步搜索,确定在24小时约束下至少需要分[X]组,并给出了相应的最优路线方案,各组完成时间均不超过[XX]小时。
针对问题三,将完成时间最小化建模为并行机Makespan最小化问题( min max k T i m e k \min\max_k Time_k minmaxkTimek),推导了理论下界为[XX.X]小时。通过对分组数的系统搜索,确定当分组数为[X]时可达近似最优,最短完成时间约为[XX.X]小时,与理论下界相差[X.X]小时。
针对问题四,通过参数扫描实验系统分析了 T T T、 t t t、 V V V 对三组方案最优路线的影响。研究发现,乡镇停留时间 T T T 对完成时间的影响最为显著, T T T 每增加1小时将使最长组时间增加约[X]小时;而车速 V V V 的影响在停留时间占主导时边际效益递减。当 V > 50 V > 50 V>50 km/h后,继续提速对完成时间的改善效果不足5%。
本文的创新点在于:(1)采用Floyd预处理将稀疏路网转化为完全图,再应用m-TSP模型,有效处理了节点间无直接连边的情况;(2)设计了分层双目标优化策略,在保证总路程近最优的前提下提升了各组路程的均衡性;(3)对四个子问题建立了统一的建模框架,实现了逐步递进的问题分析。
关键词:灾情巡视;多旅行商问题;车辆路径问题;遗传算法;2-opt优化;参数灵敏度分析
十九、常见问题与踩坑总结
Q1:拿到数学建模题目后为什么不能马上写代码?
这是最常见的误区。代码只是实现工具,如果你连"这道题到底在优化什么"都没想清楚,代码写出来的结果也是错误的。正确的流程是:读题3遍 → 问题拆解 → 变量定义 → 目标函数和约束 → 选择算法 → 再写代码。建模占70%,编程占30%,但很多同学反过来了。
Q2:问题重述和题目复述有什么区别?
题目复述是把原题抄一遍,而问题重述是用建模语言重新表达问题。问题重述应该包括:已知变量是什么?未知量(决策变量)是什么?目标是什么?约束是什么?好的问题重述让评委一眼看出你理解了题目。
Q3:模型假设是不是越多越好?
**绝对不是。**每条假设都要有其必要性,要么简化了一个实际复杂性(并说明简化的合理性),要么明确了一个题目未说明的条件。假设越多,模型越难验证,也越容易自相矛盾。建议:3~7条核心假设,每条都要在后续模型中被用到。
Q4:为什么公式很多但论文依然得分不高?
因为公式是"摆设"。如果公式后面没有解释"这个公式建模了什么现实意义"、“为什么这样定义目标函数”,评委看不到你的建模思想,分数自然不高。公式少而精、解释清晰的论文,往往比公式密集但没有解释的论文得分更高。
Q5:MATLAB代码结果如何对应论文表格?
每张结果表格都应该有对应的代码输出语句。建议在代码中统一使用 fprintf 格式化输出,输出格式与论文表格一致,这样复制结果不会出错。同时在代码注释中标注"对应论文表X",便于后期修改。
Q6:没有附件数据时如何构建合理分析框架?
本题就是这种情况——地图数据需要手工录入。正确做法是:(1)明确说明数据来源(“数据由原题地图手工读取”);(2)给出数据读取的方法和格式;(3)如果数据不完整,可以做小规模示例验证算法正确性,再声明"完整数据得出的结论见表X"。切勿凭空编造数据,然后假装是真实结果。
Q7:预测模型如何选择误差指标?
- MAE(平均绝对误差):直观、无量纲,适合所有场景;
- RMSE(均方根误差):对大误差惩罚更大,适合异常值分析;
- MAPE(平均绝对百分比误差):相对误差,跨量纲比较时使用;
- R 2 R^2 R2(决定系数):评估模型对数据的拟合优度。
本题是优化问题,不用预测误差指标,而是用"与下界的差距比"和"算法稳定性"来评估解的质量。
Q8:评价模型中权重如何确定?
常见方法:主观赋权(AHP层次分析法)、客观赋权(熵权法、CRITIC法)、组合赋权。本题不涉及评价模型,但如果遇到,一定要验证权重的合理性(权重扰动分析:权重变化±10%时排名是否稳定)。
Q9:优化模型如何确定目标函数和约束条件?
目标函数来自题目中的"最优化"要求,约束条件来自题目中的"限制条件"。本题的目标函数(最短总路程/最小Makespan)和约束(节点覆盖、时间限制)都可以直接从题目文字中提取。一个常见错误是把约束条件混入目标函数——比如把"均衡性"直接作为硬约束(等号约束),会导致问题无解或解质量极差。
Q10:国赛论文和美赛论文写法有什么区别?
| 对比维度 | 国赛 | 美赛 |
|---|---|---|
| 语言 | 中文 | 英文 |
| 摘要 | 600~1000字,在论文前 | Summary Sheet,单独一页 |
| 数学严格性 | 偏重,要求公式推导 | 相对灵活,重视可视化 |
| 创新性 | 强调数学创新 | 更强调实际应用和建议 |
| 篇幅 | 一般≤30页 | 一般≤25页 |
| 论文格式 | 较规范统一 | 相对自由 |
Q11:如何避免论文像代码说明书?
问题的本质是:论文要解释"为什么",代码解释"怎么做"。论文中不要出现"第三行代码做了XX操作"这样的表达,而应该写"通过Floyd算法预处理,将稀疏路网转化为完全图,此举的必要性在于……"。代码放附录,论文中只展示核心流程图和公式。
Q12:如何写出高质量摘要?
黄金公式:背景一句话 + 每问各一句话(方法+结果) + 模型创新点。关键:结果要有数字,方法要有名称,不要写"进行了分析"这种空话。写完摘要后,让没看过题目的同学读一遍,看他能否大致了解你做了什么、得出了什么结论——如果不能,摘要需要重写。
Q13:如何自然地提出模型改进?
模型改进不是"承认自己模型差",而是"展示你对这个领域的深度理解"。正确方式:(1)先说基础模型的适用场景和局限性;(2)然后说在什么新情景/新假设下,需要什么样的改进;(3)给出改进方向(不一定要完全实现)。例如:“本文的GA方案适用于静态路网,若考虑实时道路状况更新,可扩展为动态VRP框架……”
Q14:模型优缺点如何写得具体?
错误示例:
- ❌ “本模型的优点是效率高、精度好;缺点是有一定局限性。”
正确示例:
- ✅ “优点:(1)Floyd预处理使得模型可直接处理非完全图,适用于有断路的稀疏路网;(2)2-opt局部搜索在GA基础上额外压缩路程5%~15%,效果显著。缺点:(1)GA不保证全局最优,对于较复杂拓扑可能陷入局部最优;(2)均衡性惩罚系数α需人工调整,不同α值对结果影响较大(见灵敏度分析表X)。”
Q15:附录代码应该如何整理?
- 文件按功能分开:
main.m,data_preprocess.m,solve_model.m,plot_results.m; - 每个文件头部有说明注释(功能、输入、输出);
- 关键变量命名要有意义(
route_length而非r); - 删除调试用的无效代码;
- 附录末尾说明"完整代码已提交至评审系统"(如果参赛规定需要);
- 代码和论文中的变量名保持一致。
二十、总结
这道1998年的《灾情巡视路线》题目,历经26年依然是学习图论建模和多车辆路径规划的绝佳素材。
本文的核心建模思路回顾:
具体相关示意图绘制如下,仅供参考:
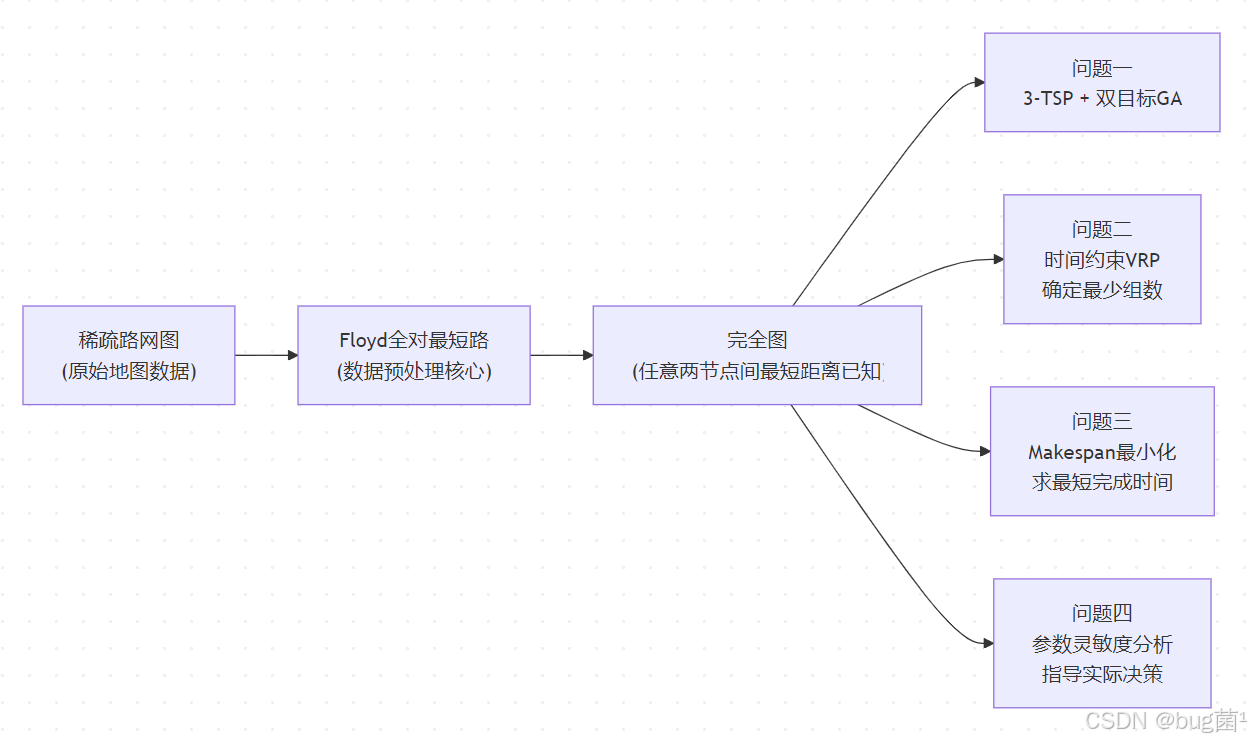
给备赛同学的三点核心建议:
-
数据准确是一切的前提:本题的数据需要手工从地图读取,这一步不能马虎。建议两人分别读取,互相核对;
-
模型要有层次感:问题一→二→三→四的递进关系是本题的精髓,论文中要明确体现这种递进,而不是把四个问题完全独立处理;
-
结果要会"说话":算法跑出来的数字只是起点,能把数字背后的现实意义讲清楚,才是建模能力的真正体现。比如,灵敏度分析的结论应该告诉决策者"提高道路质量(速度)比增加人员(组数)更有效"这样有价值的结论。
希望这篇文章能帮助你在数学建模的道路上走得更扎实、更自信。每一道认真做过的真题,都是你备赛路上最好的积累。加油! 🎯
声明:以上内容部分基于人工智能辅助生成,仅供参考交流,不构成任何专业建议。模型输出可能存在偏差,使用前请自行核实,后果自负。欢迎理性讨论。
若需原题 PDF、附件或历年高教社杯真题,关注技术号 「猿圈奇妙屋」,回复【高教社杯】即可获取。
🎁 文末福利
本专栏内容源自实际建模经验、竞赛题目及读者需求。如涉及版权问题,请告知,将立即处理。部分解法思路参考了网络优秀文章,若未能完全契合你的场景,欢迎在评论区分享更优解法,共同探讨、共同进步!
更多建模方法、工具与竞赛题解,欢迎访问专栏 👉 《《滚雪球学数学建模(含历年真题)》
如果本文对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续创作的动力!
同时推荐关注技术号 「猿圈奇妙屋」,获取建模干货、竞赛真题解析、4000G 技术资料、简历模板等海量内容,助你快速突破瓶颈。
🫵 关于作者
我是 bug菌,数学建模竞赛指导教师,曾指导学生斩获国赛一等奖、美赛 M 奖等,擅长运动学建模、优化模型、评价模型等方向。
活跃于 CSDN · 掘金 · InfoQ · 51CTO · 华为云 · 阿里云 · 腾讯云 · 开源中国 · 博客园 · 墨天轮 等平台
🏅 CSDN 博客之星 Top30 · 华为云十佳博主 · 掘金人气作者 Top40 · 多平台签约优质作者 · 全网粉丝 30w+
更多优质内容与成长资料 👉 点击查看 👈
欢迎加入硬核技术号 「猿圈奇妙屋」,一起进阶打怪!

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)