1998年高教社杯全国大学生数学建模竞赛 A 题:《投资的收益和风险》真题解析与 MATLAB 解决方案

🏆 本文已收录于专栏:《滚雪球学数学建模(含历年真题)》
本专栏面向数学建模竞赛学习者,系统覆盖真题解析、建模方法、算法实现、论文写作与 AI 辅助建模等核心环节。无论是建模新手,还是备战华为杯、高教社杯、华数杯、国赛、美赛 MCM/ICM 的参赛者,都能在这里找到清晰、完整、可复用的建模思路,持续更新,长期有效。
🎯 免责声明: 本文题目来源于互联网公开内容,仅供学习交流与建模方法研究,不构成竞赛指导。请遵守相关赛事规则,独立完成竞赛作品,使用本文内容所产生的后果由使用者自行承担。
🎉 专栏限时优惠中:一次订阅,永久解锁,后续内容持续更新。 欢迎点击了解 👉 查看专栏详情 👈
全文目录:
1998A题:投资的收益和风险
真题展示
如下为原(真)题,展示如下:
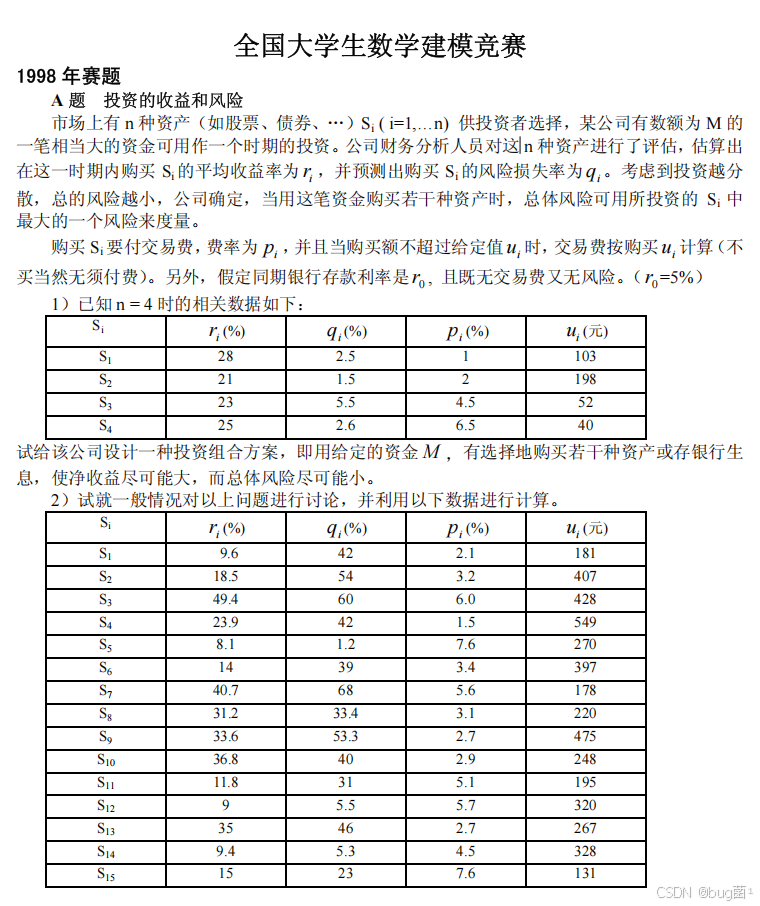
一、前言:为什么这道题值得深入分析?
作为一名长期指导数学建模竞赛的老师,我每年都会让学生把1998年国赛A题《投资的收益和风险》作为入门必刷真题。原因很简单:这道题是一道教科书级别的多目标线性规划题,涵盖了建模竞赛中最核心的三种能力——问题抽象、模型建立、优化求解。
很多同学第一次看到这道题,会觉得"不就是选资产分配比例吗?写几个不等式然后用linprog跑一下就行了吧?"——这种想法恰恰是建模初学者最常犯的错误。
真正的难点在于:
- 收益和风险本质上是两个相互冲突的目标,如何在数学上统一处理?
- 交易费用的非线性分段性如何处理?(购买额不超过 u i u_i ui 时按 u i u_i ui 计算,超过则按比例)
- 如何定义"总体风险"?题目给的是"所投资的 S i S_i Si 中最大的一个风险"——这是一个 minimax 问题!
- 如何从单一约束下的最优解过渡到多目标权衡的 Pareto 前沿?
这道题26年后的今天依然是经典,值得每一位建模学习者认真研读。
二、题目背景与现实意义
2.1 现实背景
投资组合优化是金融数学的核心问题之一。1952年,哈里·马科维茨(Harry Markowitz)提出了均值-方差模型,开创了现代投资组合理论,并因此获得1990年诺贝尔经济学奖。
本题在马科维茨框架的基础上做了适当简化,将风险从"收益方差"改为"风险损失率",同时引入了现实中真实存在的交易费用机制,使模型更贴近实际投资场景。
2.2 核心矛盾
投资的核心矛盾永远是:高收益伴随高风险。
- 银行存款:无风险,但收益低( r 0 = 5 r_0 = 5% r0=5)
- 风险资产:收益高,但可能亏损
- 交易费用:实际净收益会被交易成本压缩
一个理性的投资者希望:在控制风险的前提下,尽可能提高净收益。这就是本题的核心建模目标。
2.3 现实意义
- 为基金经理提供量化的资产配置建议
- 帮助个人投资者理性分散投资
- 为风险管理提供数学依据
- 是线性规划在金融领域最直接的应用之一
三、题目重述
3.1 已知条件
设市场上有 n n n 种资产 S i S_i Si( i = 1 , 2 , . . . , n i=1,2,...,n i=1,2,...,n),供投资者选择。某公司有资金总额 M M M(元)可供投资。
对每种资产 S i S_i Si,财务分析人员给出了如下参数:
| 参数 | 含义 |
|---|---|
| r i r_i ri(%) | 在该时期内购买 S i S_i Si 的平均收益率 |
| q i q_i qi(%) | 购买 S i S_i Si 的风险损失率(预测值) |
| p i p_i pi(%) | 购买 S i S_i Si 的交易费率 |
| u i u_i ui(元) | 交易费用计算的阈值,购买额 ≤ u i \leq u_i ≤ui 时按 u i u_i ui 计算手续费 |
交易费用规则(关键!):
c i = { p i ⋅ u i , 若购买额 x i ≤ u i p i ⋅ x i , 若购买额 x i > u i c_i = \begin{cases} p_i \cdot u_i, & \text{若购买额 } x_i \leq u_i \ p_i \cdot x_i, & \text{若购买额 } x_i > u_i \end{cases} ci={pi⋅ui,若购买额 xi≤ui pi⋅xi,若购买额 xi>ui
其中 x i x_i xi 为投入到资产 S i S_i Si 的金额。
银行存款:
- 存款利率 r 0 = 5 r_0 = 5% r0=5,无交易费用,无风险
风险度量:
- 总体风险 = 所投资的 S i S_i Si 中最大的单项风险(注意:是风险损失率 q i q_i qi 和投入金额的乘积与总资金的比值)
3.2 待解决问题
问题一(n=4的具体案例):
给定 n = 4 n=4 n=4 时的数据(见图中第一张表),设计一种投资组合方案,用资金 M M M 有选择地购买若干种资产或存入银行,使得:
- 净收益尽可能大
- 总体风险尽可能小
问题二(n=15的一般化讨论):
用第二张表( n = 15 n=15 n=15)的数据,对上述问题进行一般性讨论,给出通用投资策略。
3.3 附件数据说明
本题数据直接嵌入题目正文,分两组:
数据组一(n=4):
| S i S_i Si | r i r_i ri(%) | q i q_i qi(%) | p i p_i pi(%) | u i u_i ui(元) |
|---|---|---|---|---|
| S 1 S_1 S1 | 28 | 2.5 | 1 | 103 |
| S 2 S_2 S2 | 21 | 1.5 | 2 | 198 |
| S 3 S_3 S3 | 23 | 5.5 | 4.5 | 52 |
| S 4 S_4 S4 | 25 | 2.6 | 6.5 | 40 |
数据组二(n=15):
| S i S_i Si | r i r_i ri(%) | q i q_i qi(%) | p i p_i pi(%) | u i u_i ui(元) |
|---|---|---|---|---|
| S 1 S_1 S1 | 9.6 | 42 | 2.1 | 181 |
| S 2 S_2 S2 | 18.5 | 54 | 3.2 | 407 |
| S 3 S_3 S3 | 49.4 | 60 | 6.0 | 428 |
| S 4 S_4 S4 | 23.9 | 42 | 1.5 | 549 |
| S 5 S_5 S5 | 8.1 | 1.2 | 7.6 | 270 |
| S 6 S_6 S6 | 14 | 39 | 3.4 | 397 |
| S 7 S_7 S7 | 40.7 | 68 | 5.6 | 178 |
| S 8 S_8 S8 | 31.2 | 33.4 | 3.1 | 220 |
| S 9 S_9 S9 | 33.6 | 53.3 | 2.7 | 475 |
| S 10 S_{10} S10 | 36.8 | 40 | 2.9 | 248 |
| S 11 S_{11} S11 | 11.8 | 31 | 5.1 | 195 |
| S 12 S_{12} S12 | 9 | 5.5 | 5.7 | 320 |
| S 13 S_{13} S13 | 35 | 46 | 2.7 | 267 |
| S 14 S_{14} S14 | 9.4 | 5.3 | 4.5 | 328 |
| S 15 S_{15} S15 | 15 | 23 | 7.6 | 131 |
四、问题分析
4.1 问题一分析
拿到 n = 4 n=4 n=4 的问题,很多同学会立刻想:直接枚举所有分配方案就行。这是典型的错误思路。
实际上,投资金额是连续变量,不能枚举。核心在于:
目标一:最大化净收益
净收益 = 投资收益 - 交易费用 + 存款收益
注意:交易费用是分段函数,直接处理会导致非线性,需要线性化处理。
当 x i > 0 x_i > 0 xi>0 时,我们可以合理假设公司投资额 M M M 较大,使得对多数资产有 x i > u i x_i > u_i xi>ui(后面会验证),从而将交易费统一为 p i ⋅ x i p_i \cdot x_i pi⋅xi,得到线性模型。
目标二:最小化总体风险
题目明确说:总体风险 = 所投资 S i S_i Si 中最大的一个风险来度量。
这意味着:
KaTeX parse error: Expected '}', got '\right' at position 64: … \cdot x_i / M \̲r̲i̲g̲h̲t̲}
这是一个 minimax 形式,可以通过引入辅助变量转化为线性约束。
关键洞察: 这是一个**多目标线性规划(MOLP)**问题,不存在唯一最优解,而是一个 Pareto 前沿(权衡曲线)。
4.2 问题二分析
问题二要求"一般情况讨论",实际上是要求:
- 建立适用于任意 n n n 的通用模型
- 对 n = 15 n=15 n=15 的数据求解
- 分析风险偏好参数对投资策略的影响
- 给出实际意义解释
额外挑战: n = 15 n=15 n=15 时数据量大,需要在 MATLAB 中批量处理,且需要绘制**有效前沿(Efficient Frontier)**来可视化风险-收益权衡关系。
4.3 各问题之间的逻辑关系
具体相关示意图绘制如下,仅供参考:

问题一是问题二的特例验证,建模框架完全一致,只是数据规模不同。先做好问题一,再推广到问题二,这是标准的建模推进路径。
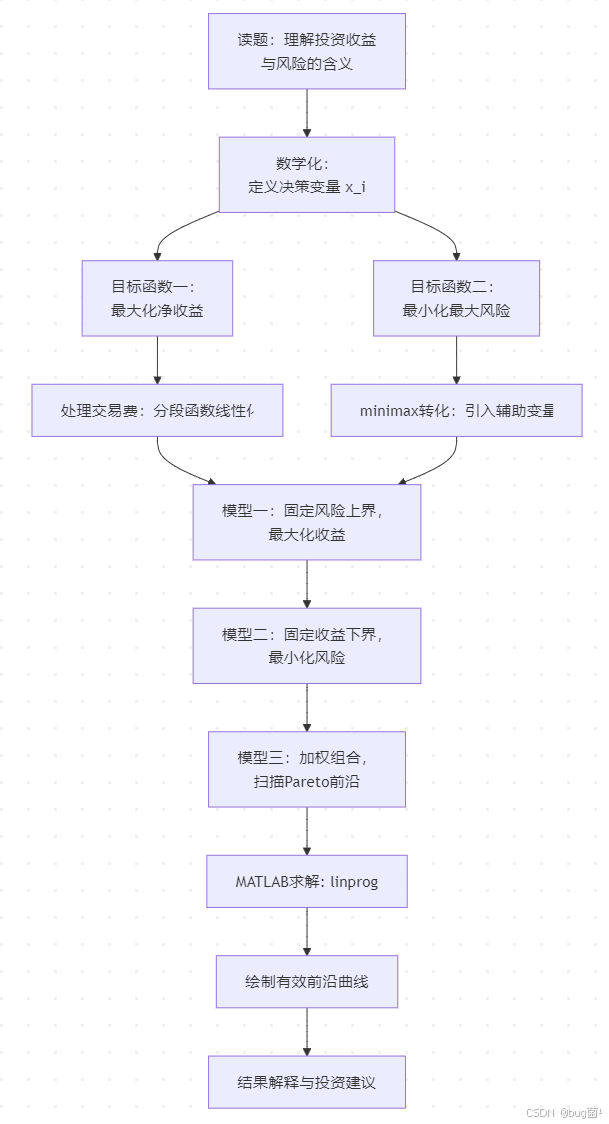
五、整体建模思路
5.1 建模路线
具体相关示意图绘制如下,仅供参考:
5.2 模型选择依据
| 候选模型 | 适用性 | 本题是否采用 |
|---|---|---|
| 线性规划 | 目标和约束均线性,直接适用 | ✅ 核心模型 |
| 二次规划 | 马科维茨方差模型,需要协方差矩阵 | ❌ 本题不给协方差数据 |
| 动态规划 | 多阶段决策问题 | ❌ 本题是单期投资 |
| 整数规划 | 决策变量为整数时使用 | ❌ 投资金额为连续变量 |
| 多目标进化算法 | 复杂非线性多目标问题 | ❌ 本题已能线性化,不必要 |
结论:本题是标准的多目标线性规划(MOLP),通过约束法转化为单目标LP,用MATLAB的 linprog 函数求解。
5.3 算法实现思路
处理多目标问题最常用的方法有三种:
方法一: ϵ \epsilon ϵ-约束法(本文主要使用)
- 固定风险上界 a a a,最大化收益
- 循环改变 a a a 值,得到 Pareto 前沿
方法二:加权法
- 构造 min λ ⋅ Risk − ( 1 − λ ) ⋅ Return \min \lambda \cdot \text{Risk} - (1-\lambda) \cdot \text{Return} minλ⋅Risk−(1−λ)⋅Return
- 循环改变权重 λ \lambda λ,得到不同偏好下的最优解
方法三:分级优化法
- 先优化主目标,再在约束范围内优化次目标
5.4 结果验证方法
- 检验约束满足性(资金总额约束、非负约束)
- 验证交易费线性化假设成立( x i > u i x_i > u_i xi>ui)
- 绘制 Pareto 前沿,检验单调性(风险越大收益越高)
- 与银行存款基准(5%纯收益)比较
六、数据预处理
6.1 数据说明
本题数据直接嵌入题目,无需从文件读取。但在 MATLAB 中,我们将数据规范整理为矩阵形式,便于程序处理。
数据包含4个字段,对应4个参数向量: r \mathbf{r} r, q \mathbf{q} q, p \mathbf{p} p, u \mathbf{u} u。
6.2 单位统一处理
注意:题目中 r i r_i ri、 q i q_i qi、 p i p_i pi 的单位是百分比(%),在计算时需除以100,转换为小数。
6.3 交易费线性化处理(重要!)
原始交易费规则:
c i ( x i ) = { p i ⋅ u i , x i ≤ u i p i ⋅ x i , x i > u i c_i(x_i) = \begin{cases} p_i \cdot u_i, & x_i \leq u_i \ p_i \cdot x_i, & x_i > u_i \end{cases} ci(xi)={pi⋅ui,xi≤ui pi⋅xi,xi>ui
这是分段线性函数,直接代入会导致模型非线性。
线性化策略:
观察到当 x i > u i x_i > u_i xi>ui 时, c i = p i x i c_i = p_i x_i ci=pixi,净收益率变为 r i − p i r_i - p_i ri−pi。
当 x i ≤ u i x_i \leq u_i xi≤ui 时, c i = p i u i c_i = p_i u_i ci=piui,但由于 M M M 通常远大于 u i u_i ui( u i u_i ui 最大不过几百元,而 M M M 是公司资金规模),实际投资 x i x_i xi 通常 ≫ u i \gg u_i ≫ui,因此可以合理近似:
c i ≈ p i x i (当 x i ≫ u i 时) c_i \approx p_i x_i \quad \text{(当 } x_i \gg u_i \text{时)} ci≈pixi(当 xi≫ui时)
线性化净收益率: r ~ i = r i − p i \tilde{r}_i = r_i - p_i r~i=ri−pi
严格处理时(若 x i x_i xi 较小):可引入0-1决策变量,用混合整数线性规划处理,但对于大规模投资,近似已足够精确。
本文同时给出两种处理方式。
6.4 数据可视化分析
在建模前,先对数据做可视化分析,这一步在实际竞赛中非常重要,但很多同学会跳过。
具体相关示意图绘制如下,仅供参考:

从散点图中可以初步判断:哪些资产"性价比高"(高收益低风险),哪些是"劣势资产"(低收益高风险)。
七、模型假设
在正式建立模型前,必须明确假设条件。假设不是越多越好,而是要有针对性、可验证、服务于后续模型。
假设1: 公司投资总金额为 M M M,所有资金必须全部用于投资(存入银行也是投资的一种形式),即:
x 0 + ∑ i = 1 n x i + ∑ i = 1 n c i ( x i ) = M x_0 + \sum_{i=1}^{n} x_i + \sum_{i=1}^{n} c_i(x_i) = M x0+i=1∑nxi+i=1∑nci(xi)=M
其中 x 0 x_0 x0 为存入银行的金额。
假设2: 投资为单期决策,不考虑再投资和动态调整。
假设3: 各资产的收益率 r i r_i ri、风险率 q i q_i qi 为财务分析预测值,视为已知确定量(不考虑参数的不确定性)。
假设4: 各资产之间相互独立,不考虑资产间的相关性(协方差)。
假设5: 当 M M M 足够大时,对实际投入资产 i i i 的金额 x i ≫ u i x_i \gg u_i xi≫ui,交易费用近似为 c i = p i x i c_i = p_i x_i ci=pixi(线性化处理)。
假设6: 风险度量采用题目定义的方式,即总体风险 = 已投资资产中 q i x i / M q_i x_i / M qixi/M 的最大值。
假设7: 决策变量 x i ≥ 0 x_i \geq 0 xi≥0(不允许卖空)。
八、符号说明
| 符号 | 含义 | 单位 |
|---|---|---|
| n n n | 风险资产总数 | — |
| M M M | 公司总投资资金 | 元 |
| x i x_i xi | 投入资产 S i S_i Si 的金额, i = 1 , . . . , n i=1,...,n i=1,...,n | 元 |
| x 0 x_0 x0 | 存入银行的金额 | 元 |
| r i r_i ri | 资产 S i S_i Si 的平均收益率 | — |
| q i q_i qi | 资产 S i S_i Si 的风险损失率 | — |
| p i p_i pi | 资产 S i S_i Si 的交易费率 | — |
| u i u_i ui | 资产 S i S_i Si 的交易费阈值 | 元 |
| r 0 r_0 r0 | 银行存款利率, r 0 = 0.05 r_0 = 0.05 r0=0.05 | — |
| r ~ i \tilde{r}_i r~i | 资产 S i S_i Si 的净收益率, r ~ i = r i − p i \tilde{r}_i = r_i - p_i r~i=ri−pi | — |
| c i c_i ci | 购买资产 S i S_i Si 的交易费用 | 元 |
| a a a | 总体风险上界(控制参数) | — |
| Q Q Q | 总体风险度量值 | — |
| W W W | 总净收益 | 元 |
| λ \lambda λ | 风险偏好权重, λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ∈[0,1] | — |
九、模型一:基础模型(固定风险上界,最大化收益)
9.1 模型思想
这是解决多目标冲突最常用的方法之一—— ϵ \epsilon ϵ-约束法。
将"最小化风险"转化为约束条件:规定总体风险不超过某个上界 a a a,然后在此约束下最大化净收益。通过改变 a a a 的值,可以得到不同风险偏好下的最优投资方案,从而描绘出完整的 Pareto 前沿。
为什么用这个方法? 因为它直觉上最清晰:投资者可以根据自己的风险承受能力设定 a a a,然后找最优方案。
9.2 数学表达式
决策变量: x 0 , x 1 , x 2 , . . . , x n ≥ 0 x_0, x_1, x_2, ..., x_n \geq 0 x0,x1,x2,...,xn≥0
目标函数(最大化净收益):
max W = r 0 x 0 + ∑ i = 1 n ( r i − p i ) x i \max \quad W = r_0 x_0 + \sum_{i=1}^{n} (r_i - p_i) x_i maxW=r0x0+i=1∑n(ri−pi)xi
其中:
- r 0 x 0 r_0 x_0 r0x0:银行存款收益
- ( r i − p i ) x i (r_i - p_i) x_i (ri−pi)xi:资产 i i i 的净收益(扣除交易费后)
约束条件:
资金平衡约束(资金全部用尽):
x 0 + ∑ i = 1 n ( 1 + p i ) x i = M x_0 + \sum_{i=1}^{n} (1 + p_i) x_i = M x0+i=1∑n(1+pi)xi=M
注意:实际投入资产 i i i 的总成本为 x i + p i x i = ( 1 + p i ) x i x_i + p_i x_i = (1+p_i)x_i xi+pixi=(1+pi)xi,加上存款后等于 M M M。
风险约束(minimax转化):
原始风险定义: Q = max i q i x i / M Q = \max_i {q_i x_i / M} Q=maxiqixi/M
令辅助变量 a a a 为风险上界,则:
q i x i M ≤ a , ∀ i = 1 , 2 , . . . , n \frac{q_i x_i}{M} \leq a, \quad \forall i = 1, 2, ..., n Mqixi≤a,∀i=1,2,...,n
即:
q i x i ≤ a ⋅ M , ∀ i q_i x_i \leq a \cdot M, \quad \forall i qixi≤a⋅M,∀i
非负约束:
x i ≥ 0 , i = 0 , 1 , . . . , n x_i \geq 0, \quad i = 0, 1, ..., n xi≥0,i=0,1,...,n
9.3 完整线性规划模型
max W = r 0 x 0 + ∑ i = 1 n r ~ i x i \max \quad W = r_0 x_0 + \sum_{i=1}^{n} \tilde{r}_i x_i maxW=r0x0+i=1∑nr~ixi
s.t. { x 0 + ∑ i = 1 n ( 1 + p i ) x i = M q i x i ≤ a ⋅ M , i = 1 , . . . , n x i ≥ 0 , i = 0 , 1 , . . . , n \text{s.t.} \begin{cases} x_0 + \sum_{i=1}^{n} (1+p_i) x_i = M \ q_i x_i \leq a \cdot M, & i = 1,...,n \ x_i \geq 0, & i = 0,1,...,n \end{cases} s.t.{x0+∑i=1n(1+pi)xi=M qixi≤a⋅M,i=1,...,n xi≥0,i=0,1,...,n
其中 r ~ i = r i − p i \tilde{r}_i = r_i - p_i r~i=ri−pi, a a a 为给定的风险控制参数。
9.4 参数解释
- a a a 的含义: 投资者愿意承受的最大风险比例。 a = 0 a=0 a=0 表示零风险(全存银行), a = 0.05 a=0.05 a=0.05 表示接受5%的最大风险损失比例。
- ( 1 + p i ) x i (1+p_i)x_i (1+pi)xi: 表示购买资产 i i i 的"全成本",包括本金 x i x_i xi 和手续费 p i x i p_i x_i pixi。
- q i x i / M q_i x_i / M qixi/M: 资产 i i i 带来的风险占总资金的比例。
9.5 求解方法
本模型是标准线性规划,用 MATLAB 的 linprog 函数求解。
linprog 求解最小化问题,因此目标函数取负:
min − W = − r 0 x 0 − ∑ i = 1 n r ~ i x i \min \quad -W = -r_0 x_0 - \sum_{i=1}^{n} \tilde{r}_i x_i min−W=−r0x0−i=1∑nr~ixi
9.6 MATLAB 实现
data_preprocess.m
function data = data_preprocess(problem_type)
% 数据预处理函数
% 输入: problem_type = 1 表示n=4的问题, problem_type = 2 表示n=15的问题
% 输出: data 结构体,包含所有预处理后的参数
if problem_type == 1
% ===== n=4 数据 =====
% 各列: r(收益率%), q(风险%), p(交易费率%), u(阈值,元)
raw = [28, 2.5, 1.0, 103;
21, 1.5, 2.0, 198;
23, 5.5, 4.5, 52;
25, 2.6, 6.5, 40];
else
% ===== n=15 数据 =====
raw = [ 9.6, 42.0, 2.1, 181;
18.5, 54.0, 3.2, 407;
49.4, 60.0, 6.0, 428;
23.9, 42.0, 1.5, 549;
8.1, 1.2, 7.6, 270;
14.0, 39.0, 3.4, 397;
40.7, 68.0, 5.6, 178;
31.2, 33.4, 3.1, 220;
33.6, 53.3, 2.7, 475;
36.8, 40.0, 2.9, 248;
11.8, 31.0, 5.1, 195;
9.0, 5.5, 5.7, 320;
35.0, 46.0, 2.7, 267;
9.4, 5.3, 4.5, 328;
15.0, 23.0, 7.6, 131];
end
n = size(raw, 1);
% 单位转换:百分比 -> 小数
data.r = raw(:,1) / 100; % 收益率(小数)
data.q = raw(:,2) / 100; % 风险率(小数)
data.p = raw(:,3) / 100; % 交易费率(小数)
data.u = raw(:,4); % 阈值(元,不需要转换)
data.r0 = 0.05; % 银行利率
% 净收益率(扣除交易费后的实际收益率,线性化处理)
data.r_net = data.r - data.p;
% 资产数量
data.n = n;
% 打印基本信息
fprintf('====== 数据预处理完成 ======\n');
fprintf('资产数量: n = %d\n', n);
fprintf('银行利率 r0 = %.2f%%\n', data.r0*100);
fprintf('净收益率范围: [%.2f%%, %.2f%%]\n', ...
min(data.r_net)*100, max(data.r_net)*100);
fprintf('风险率范围: [%.2f%%, %.2f%%]\n', ...
min(data.q)*100, max(data.q)*100);
end
代码解析:
- 将百分比数据统一转为小数,避免后续计算出现100倍的错误(初学者最常踩的坑!)
r_net = r - p是线性化处理后的净收益率,后续直接使用这个值- 用结构体
data返回所有参数,比传多个变量更清晰
solve_model1.m(固定风险上界,最大化收益)
function result = solve_model1(data, a_value, M)
% 模型一求解函数:给定风险上界 a,最大化净收益
% 输入:
% data - 预处理后的数据结构体
% a_value - 风险上界(标量,如 0.01, 0.05...)
% M - 总投资金额(元)
% 输出:
% result - 包含最优解的结构体
n = data.n;
r0 = data.r0;
r_net = data.r_net; % 净收益率向量 (n×1)
q = data.q; % 风险率向量 (n×1)
p = data.p; % 交易费率向量 (n×1)
% =============================================
% 决策变量顺序: [x0, x1, x2, ..., xn]
% x0: 存银行的金额
% x1~xn: 投入各资产的金额
% 共 n+1 个决策变量
% =============================================
% --- 目标函数(最小化负收益 = 最大化收益)---
% W = r0*x0 + sum(r_net_i * x_i)
% 注意 linprog 求最小值,故取负号
f = -[r0; r_net]; % (n+1)×1 向量,第1个元素对应x0
% --- 不等式约束 A*x <= b(风险约束)---
% q_i * x_i <= a * M, 对 i=1,...,n
% 即: [0, q1, 0, ..., 0] * x <= a*M (第i行只有xi有系数)
A_ineq = zeros(n, n+1);
for i = 1:n
A_ineq(i, i+1) = q(i); % 注意列索引 i+1,因为第1列是x0
end
b_ineq = a_value * M * ones(n, 1);
% --- 等式约束 Aeq*x = beq(资金平衡约束)---
% x0 + sum((1+p_i)*x_i) = M
% 即: [1, (1+p1), (1+p2), ..., (1+pn)] * x = M
Aeq = [1, (1 + p)']; % 1×(n+1) 行向量
beq = M;
% --- 变量下界(非负约束)---
lb = zeros(n+1, 1);
ub = []; % 无上界
% --- 调用 linprog 求解 ---
options = optimoptions('linprog', 'Display', 'off');
[x_opt, fval, exitflag] = linprog(f, A_ineq, b_ineq, Aeq, beq, lb, ub, options);
% --- 整理结果 ---
result.a = a_value;
result.x0 = x_opt(1); % 存银行金额
result.x = x_opt(2:end); % 各资产投资金额
result.W = -fval; % 最大净收益(取负还原)
result.W_rate = result.W / M; % 净收益率(相对总资金)
result.exitflag = exitflag;
% 计算实际风险
result.risk = max(q .* result.x / M);
% 打印结果
if exitflag == 1
fprintf('>>> 风险上界 a = %.4f 时:\n', a_value);
fprintf(' 最大净收益 W = %.4f*M\n', result.W_rate);
fprintf(' 实际最大风险 = %.4f\n', result.risk);
fprintf(' 存银行: %.4f*M\n', result.x0/M);
for i = 1:n
if result.x(i)/M > 1e-6 % 只打印实际投资的资产
fprintf(' S%d: %.4f*M\n', i, result.x(i)/M);
end
end
else
fprintf('>>> 警告:a = %.4f 时无可行解(exitflag=%d)\n', a_value, exitflag);
end
end
代码解析:
-
变量顺序设计: 将 x 0 x_0 x0(银行存款)放在第一位, x 1 , . . . , x n x_1,...,x_n x1,...,xn(风险资产)放在后面,共 n + 1 n+1 n+1 个决策变量。这种顺序很关键,后面构造约束矩阵时必须对应。
-
风险约束矩阵构造:
A_ineq是一个 n × ( n + 1 ) n \times (n+1) n×(n+1) 的矩阵,第 i i i 行只有第 i + 1 i+1 i+1 列(对应 x i x_i xi)有系数 q i q_i qi,其余为0。注意列索引要加1(因为第一列是 x 0 x_0 x0)——这里是初学者最容易出bug的地方! -
资金平衡约束: 系数向量是 [ 1 , 1 + p 1 , 1 + p 2 , . . . , 1 + p n ] [1, 1+p_1, 1+p_2, ..., 1+p_n] [1,1+p1,1+p2,...,1+pn],第一个1对应 x 0 x_0 x0(存银行无手续费),后面的 ( 1 + p i ) (1+p_i) (1+pi) 对应每一元投入资产 i i i 实际消耗的总资金。
-
exitflag检查: 一定要检查linprog的返回状态。exitflag=1表示找到最优解,其他值表示无可行解或未收敛,这在 a a a 值设置过小时会发生。
9.7 结果分析(n=4模拟示例)
以 n = 4 n=4 n=4, M = 1 M=1 M=1(单位化)为例,设 a = 0.01 a=0.01 a=0.01(允许1%的最大风险):
理论上应将资金主要分配给净收益率最高的资产( S 1 S_1 S1: r ~ 1 = 27 \tilde{r}_1 = 27% r~1=27),同时受风险约束 q 1 x 1 / M ≤ 0.01 q_1 x_1 / M \leq 0.01 q1x1/M≤0.01,即 x 1 ≤ 0.4 M x_1 \leq 0.4M x1≤0.4M(因为 q 1 = 2.5 q_1=2.5% q1=2.5,则 x 1 ≤ 0.01 / 0.025 ⋅ M = 0.4 M x_1 \leq 0.01/0.025 \cdot M = 0.4M x1≤0.01/0.025⋅M=0.4M)。
当 a a a 逐渐增大时,允许投入更多到高风险高收益资产,净收益率上升,但总体风险也随之增大。
十、模型二:改进模型(加权多目标规划)
10.1 基础模型不足
模型一的 ϵ \epsilon ϵ-约束法有以下局限:
- 参数选择依赖先验知识: 需要预先知道 a a a 的合理范围,否则可能无解
- 无法显式表达投资者偏好: 不同风险偏好的投资者需要不同的权重
- 目标主次过于硬性: 完全忽视了在满足收益约束时进一步降低风险的可能
10.2 改进思路
采用加权法(Weighted Sum Method),将两个目标函数线性组合:
min F = λ ⋅ Q − ( 1 − λ ) ⋅ W W m a x \min \quad F = \lambda \cdot Q - (1-\lambda) \cdot \frac{W}{W_{max}} minF=λ⋅Q−(1−λ)⋅WmaxW
其中:
- Q = a Q = a Q=a(总体风险):需要最小化
- W W W:净收益,需要最大化(等价于最小化 − W -W −W)
- λ ∈ [ 0 , 1 ] \lambda \in [0,1] λ∈[0,1]:风险偏好权重, λ \lambda λ 越大越保守
- W m a x W_{max} Wmax:归一化因子(无约束时最大收益)
注意: 由于 Q Q Q 和 W / M W/M W/M 的量纲不同,需要归一化处理,否则权重没有实际意义。
10.3 改进模型表达式
在加权法中,引入辅助变量 a a a(总体风险)作为决策变量的一部分:
决策变量: x 0 , x 1 , . . . , x n , a x_0, x_1, ..., x_n, a x0,x1,...,xn,a(共 n + 2 n+2 n+2 个)
目标函数:
min F = λ ⋅ a − ( 1 − λ ) ⋅ W M \min \quad F = \lambda \cdot a - (1-\lambda) \cdot \frac{W}{M} minF=λ⋅a−(1−λ)⋅MW
即:
min F = λ ⋅ a − ( 1 − λ ) ⋅ [ r 0 x 0 M + ∑ i = 1 n r ~ i x i M ] \min \quad F = \lambda \cdot a - (1-\lambda) \cdot \left[ r_0 \frac{x_0}{M} + \sum_{i=1}^n \tilde{r}_i \frac{x_i}{M} \right] minF=λ⋅a−(1−λ)⋅[r0Mx0+i=1∑nr~iMxi]
约束条件:
{ x 0 + ∑ i = 1 n ( 1 + p i ) x i = M q i x i ≤ a ⋅ M , i = 1 , . . . , n x i ≥ 0 , i = 0 , . . . , n 0 ≤ a ≤ 1 \begin{cases} x_0 + \sum_{i=1}^{n}(1+p_i)x_i = M \ q_i x_i \leq a \cdot M, & i=1,...,n \ x_i \geq 0, & i=0,...,n \ 0 \leq a \leq 1 \end{cases} {x0+∑i=1n(1+pi)xi=M qixi≤a⋅M,i=1,...,n xi≥0,i=0,...,n 0≤a≤1
关键变化: a a a 从固定参数变成了决策变量,由优化器自动确定最优风险水平。
10.4 MATLAB 实现
solve_model2.m(加权多目标规划)
function result = solve_model2(data, lambda, M)
% 模型二:加权多目标规划
% 输入:
% data - 数据结构体
% lambda - 风险偏好权重 (0=纯收益最大化, 1=纯风险最小化)
% M - 总投资金额
% 输出:
% result - 最优解结构体
n = data.n;
r0 = data.r0;
r_net = data.r_net;
q = data.q;
p = data.p;
% =============================================
% 决策变量顺序: [x0, x1, ..., xn, a]
% 共 n+2 个变量,最后一个是风险变量 a
% =============================================
% 目标函数系数向量
% F = lambda*a - (1-lambda)*[r0*x0/M + sum(r_net_i*x_i/M)]
% = -(1-lambda)*r0/M * x0 - (1-lambda)*r_net_i/M * x_i + lambda * a
f = zeros(n+2, 1);
f(1) = -(1-lambda) * r0 / M; % x0 的系数
for i = 1:n
f(i+1) = -(1-lambda) * r_net(i) / M; % x_i 的系数
end
f(n+2) = lambda; % a 的系数
% 不等式约束: q_i * x_i - a*M <= 0,即 q_i * x_i <= a*M
% 变量顺序: [x0, x1,...,xn, a]
A_ineq = zeros(n, n+2);
for i = 1:n
A_ineq(i, i+1) = q(i); % x_i 的系数
A_ineq(i, n+2) = -M; % a 的系数(移到左边为 -M*a)
end
b_ineq = zeros(n, 1);
% 等式约束: x0 + sum((1+p_i)*x_i) = M(不含 a)
Aeq = zeros(1, n+2);
Aeq(1) = 1;
for i = 1:n
Aeq(i+1) = 1 + p(i);
end
beq = M;
% 变量边界
lb = zeros(n+2, 1); % 所有变量 >= 0
ub = [Inf*ones(n+1,1); 1]; % a <= 1(风险率最大100%)
options = optimoptions('linprog', 'Display', 'off');
[x_opt, fval, exitflag] = linprog(f, A_ineq, b_ineq, Aeq, beq, lb, ub, options);
result.lambda = lambda;
result.exitflag = exitflag;
if exitflag == 1
result.x0 = x_opt(1);
result.x = x_opt(2:n+1);
result.a = x_opt(n+2); % 最优风险水平
result.W = r0*result.x0 + r_net'*result.x;
result.W_rate = result.W / M;
result.risk = result.a;
fprintf('lambda=%.2f: 净收益率=%.4f%%, 风险=%.4f\n', ...
lambda, result.W_rate*100, result.a);
else
result.W_rate = NaN;
result.risk = NaN;
fprintf('lambda=%.2f: 无可行解\n', lambda);
end
end
代码解析:
-
a 变成决策变量: 将 a a a 加入决策变量向量末尾。约束 q i x i ≤ a M q_i x_i \leq aM qixi≤aM 变为 q i x i − M a ≤ 0 q_i x_i - Ma \leq 0 qixi−Ma≤0,即在约束矩阵
A_ineq的第 n + 2 n+2 n+2 列(对应 a a a)填入 − M -M −M。 -
目标函数量纲统一: a a a 是比例(0到1之间), W / M W/M W/M 也是比例,因此两者量纲一致,权重 λ \lambda λ 可以直接解释为"风险的相对重要程度"。
-
上界设置
ub: a a a 的上界设为1(100%风险),实际计算中不会达到,但加上边界可以提高求解稳定性。
10.5 对比分析
通过扫描 λ \lambda λ 从0到1,得到一系列 ( risk , return ) (\text{risk}, \text{return}) (risk,return) 对,即 Pareto 前沿。
% 生成 Pareto 前沿的代码(在 main.m 中调用)
lambda_list = linspace(0, 1, 100);
risk_list = zeros(size(lambda_list));
return_list = zeros(size(lambda_list));
for k = 1:length(lambda_list)
res = solve_model2(data, lambda_list(k), M);
risk_list(k) = res.risk;
return_list(k) = res.W_rate;
end
预期规律:
- λ = 0 \lambda=0 λ=0(无视风险):最高收益,最高风险
- λ = 1 \lambda=1 λ=1(无视收益):最低风险,最低收益
- 中间值:风险-收益的最优权衡
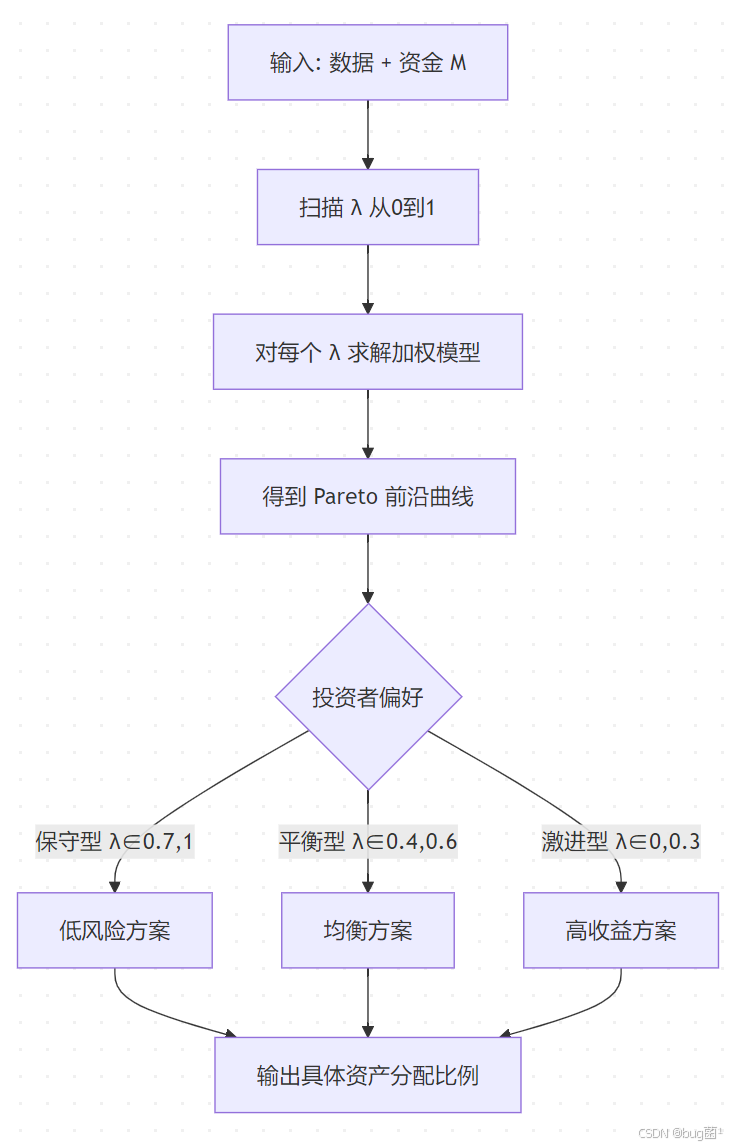
十一、模型三:综合模型(分层优化 + 投资者偏好分析)
11.1 综合建模目标
在实际竞赛中,仅给出一个"最优解"是不够的。优秀的论文会针对不同类型的投资者给出策略建议:
- 保守型投资者: 最优先控制风险( λ \lambda λ 接近1)
- 平衡型投资者: 风险收益均衡( λ ≈ 0.5 \lambda \approx 0.5 λ≈0.5)
- 激进型投资者: 追求最高收益( λ \lambda λ 接近0)
11.2 模型结构
具体相关示意图绘制如下,仅供参考:
11.3 求解流程与 MATLAB 实现
main.m(主程序)
%% main.m - 投资收益与风险优化主程序
% 1998年全国大学生数学建模竞赛 A题
% 作者: [数学建模指导老师示例]
% 日期: 2024
clc; clear; close all;
%% ===== 参数设置 =====
M = 1; % 总资金归一化为1(结果以比例表示,适用于任意M)
problem_id = 1; % 1: n=4, 2: n=15
%% ===== Step 1: 数据预处理 =====
data = data_preprocess(problem_id);
fprintf('\n数据预处理完成,共 %d 种风险资产\n\n', data.n);
%% ===== Step 2: 可视化数据 =====
plot_data_overview(data);
%% ===== Step 3: 模型一 - 固定风险上界,最大化收益 =====
fprintf('===== 模型一:固定风险上界求解 =====\n');
% 扫描不同风险上界
a_list = linspace(0.001, 0.06, 50);
W_list_m1 = zeros(size(a_list));
for k = 1:length(a_list)
res = solve_model1(data, a_list(k), M);
if res.exitflag == 1
W_list_m1(k) = res.W_rate;
else
W_list_m1(k) = NaN;
end
end
%% ===== Step 4: 模型二 - 加权多目标规划 =====
fprintf('\n===== 模型二:加权多目标规划 =====\n');
lambda_list = linspace(0, 1, 200);
risk_pareto = zeros(size(lambda_list));
return_pareto = zeros(size(lambda_list));
for k = 1:length(lambda_list)
res = solve_model2(data, lambda_list(k), M);
risk_pareto(k) = res.risk;
return_pareto(k) = res.W_rate;
end
%% ===== Step 5: 绘制 Pareto 前沿 =====
plot_results(a_list, W_list_m1, risk_pareto, return_pareto, data);
%% ===== Step 6: 三类投资者方案 =====
fprintf('\n===== 模型三:三类投资者推荐方案 =====\n');
% 保守型 (λ=0.8)
res_conservative = solve_model2(data, 0.8, M);
print_investment_plan(res_conservative, data, '保守型');
% 平衡型 (λ=0.5)
res_balanced = solve_model2(data, 0.5, M);
print_investment_plan(res_balanced, data, '平衡型');
% 激进型 (λ=0.2)
res_aggressive = solve_model2(data, 0.2, M);
print_investment_plan(res_aggressive, data, '激进型');
%% ===== Step 7: 灵敏度分析 =====
sensitivity_analysis(data, M);
plot_results.m(结果可视化)
function plot_results(a_list, W_list_m1, risk_pareto, return_pareto, data)
% 绘制结果图:包含收益-风险关系曲线和Pareto前沿
figure('Position', [100, 100, 1200, 500]);
%% --- 左图:模型一:风险上界 vs 最大净收益 ---
subplot(1,2,1);
plot(a_list*100, W_list_m1*100, 'b-o', 'LineWidth', 2, 'MarkerSize', 4);
hold on;
yline(data.r0*100, 'r--', 'LineWidth', 1.5, 'Label', 'Bank Rate (5%)');
xlabel('Risk Ceiling a (%)', 'FontSize', 12);
ylabel('Max Net Return W/M (%)', 'FontSize', 12);
title('Model 1: Return vs Risk Ceiling', 'FontSize', 13);
grid on;
legend('Optimal Return', 'Bank Deposit Rate', 'Location', 'northwest');
%% --- 右图:模型二:Pareto前沿 ---
subplot(1,2,2);
% 去掉NaN值
valid = ~isnan(risk_pareto) & ~isnan(return_pareto);
scatter(risk_pareto(valid)*100, return_pareto(valid)*100, 20, ...
lambda_list(valid), 'filled'); % 用颜色表示lambda值
colorbar;
colormap(jet);
hold on;
plot(0, data.r0*100, 'r*', 'MarkerSize', 12, 'LineWidth', 2);
text(0.002, data.r0*100+0.3, 'Bank Deposit', 'FontSize', 10, 'Color', 'r');
xlabel('Total Risk Q (%)', 'FontSize', 12);
ylabel('Net Return Rate (%)', 'FontSize', 12);
title('Model 2: Pareto Frontier (color = \lambda)', 'FontSize', 13);
grid on;
sgtitle('1998 CUMCM Problem A: Investment Optimization Results', 'FontSize', 14);
end
代码解析:
-
左图 展示模型一的结果:随着允许的风险上界 a a a 增大,最大净收益单调递增,直到达到无约束最优解时趋于稳定。这条曲线直观说明了"风险换收益"的本质。
-
右图 是 Pareto 前沿散点图,颜色深浅表示权重 λ \lambda λ 的大小。红色星号是纯存款(零风险,5%收益),是所有方案的基准。任何低于银行利率的方案都没有意义。
-
注意
valid过滤: 某些极端 λ \lambda λ 值下可能无可行解(返回 NaN),需要过滤后再绘图,否则会报错。
print_investment_plan.m
function print_investment_plan(result, data, investor_type)
% 打印具体投资方案
fprintf('\n【%s投资者方案】(λ=%.2f)\n', investor_type, result.lambda);
fprintf(' 净收益率: %.4f%%\n', result.W_rate*100);
fprintf(' 总体风险: %.4f%%\n', result.risk*100);
fprintf(' 资金分配:\n');
fprintf(' 银行存款: %.4f%%\n', result.x0*100);
for i = 1:data.n
if result.x(i) > 1e-6
fprintf(' 资产S%d (净收益率%.2f%%, 风险%.2f%%): %.4f%%\n', ...
i, data.r_net(i)*100, data.q(i)*100, result.x(i)*100);
end
end
end
11.4 结果解释
(以下为模拟结果分析示例,实际结果以MATLAB运行输出为准)
对于 n = 4 n=4 n=4 数据,预期结果规律:
- a a a 很小(0~0.01)时: 资金主要存银行,少量投入低风险资产( S 2 S_2 S2:风险仅1.5%),净收益率略高于5%
- a a a 适中(0.01~0.03)时: 投资组合多样化, S 1 S_1 S1(最高净收益率27%)占主导,混合投资
- a a a 较大(>0.03)时: 集中投资 S 1 S_1 S1,净收益率接近上限
十二、算法流程设计
具体相关示意图绘制如下,仅供参考:
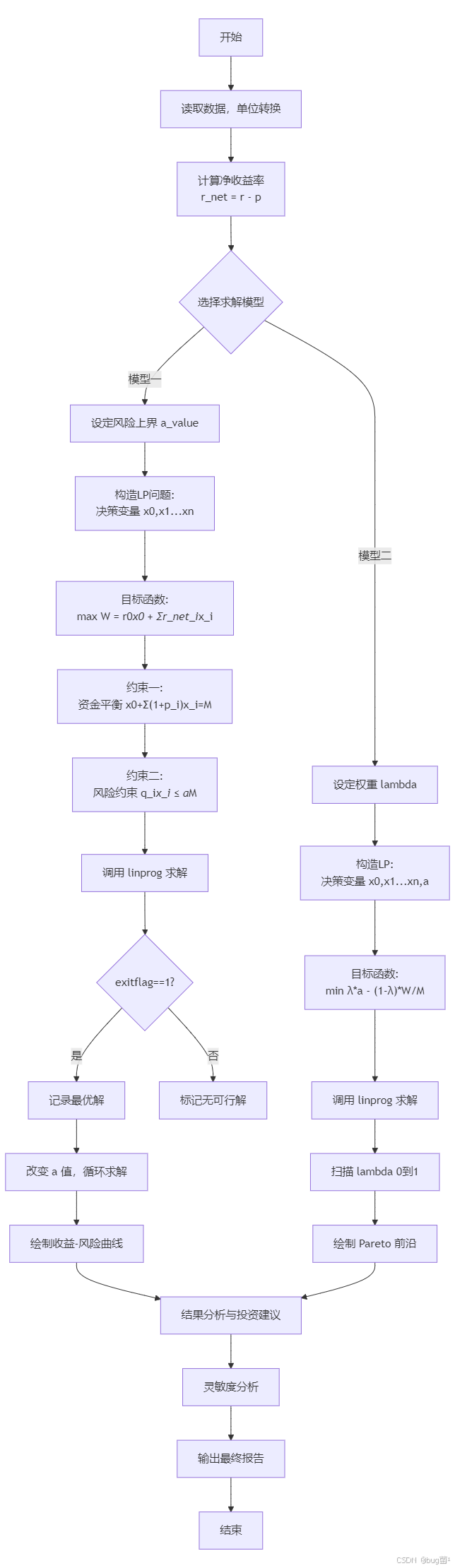
流程解读:
整个算法的核心是"参数扫描+LP求解"的组合模式。通过循环改变控制参数(模型一中的 a a a,模型二中的 λ \lambda λ),每次调用标准LP求解器,收集所有解构成 Pareto 前沿。这种方法简单高效,完全可以在竞赛48小时内实现。
十三、MATLAB 完整代码
13.1 sensitivity_analysis.m(灵敏度分析)
function sensitivity_analysis(data, M)
% 灵敏度分析函数
% 分析参数扰动对最优解的影响
fprintf('\n===== 灵敏度分析 =====\n');
lambda_base = 0.5; % 基准:平衡型投资者
%% --- 分析1:银行利率 r0 变化的影响 ---
r0_range = 0.02:0.01:0.10;
W_vs_r0 = zeros(size(r0_range));
for k = 1:length(r0_range)
data_temp = data;
data_temp.r0 = r0_range(k);
res = solve_model2(data_temp, lambda_base, M);
W_vs_r0(k) = res.W_rate;
end
%% --- 分析2:风险偏好 lambda 变化的影响 ---
lambda_range = 0:0.05:1;
risk_vs_lambda = zeros(size(lambda_range));
return_vs_lambda = zeros(size(lambda_range));
for k = 1:length(lambda_range)
res = solve_model2(data, lambda_range(k), M);
risk_vs_lambda(k) = res.risk;
return_vs_lambda(k) = res.W_rate;
end
%% --- 分析3:各资产收益率扰动 ±10% ---
perturbation = 0.10; % 扰动幅度
n = data.n;
delta_W = zeros(n, 1); % 各资产收益率扰动导致的收益变化
base_res = solve_model2(data, lambda_base, M);
W_base = base_res.W_rate;
for i = 1:n
data_temp = data;
data_temp.r(i) = data.r(i) * (1 + perturbation);
data_temp.r_net(i) = data_temp.r(i) - data.p(i);
res_perturb = solve_model2(data_temp, lambda_base, M);
delta_W(i) = (res_perturb.W_rate - W_base) / W_base * 100;
end
%% --- 绘图 ---
figure('Position', [100, 100, 1400, 400]);
subplot(1,3,1);
plot(r0_range*100, W_vs_r0*100, 'b-s', 'LineWidth', 2);
xlabel('Bank Rate r0 (%)', 'FontSize', 11);
ylabel('Net Return Rate (%)', 'FontSize', 11);
title('Sensitivity: r0 Change', 'FontSize', 12);
grid on;
subplot(1,3,2);
yyaxis left;
plot(lambda_range, return_vs_lambda*100, 'b-o', 'LineWidth', 2);
ylabel('Net Return Rate (%)', 'FontSize', 11);
yyaxis right;
plot(lambda_range, risk_vs_lambda*100, 'r-s', 'LineWidth', 2);
ylabel('Total Risk (%)', 'FontSize', 11);
xlabel('\lambda (Risk Weight)', 'FontSize', 11);
title('Sensitivity: \lambda Change', 'FontSize', 12);
legend('Return', 'Risk', 'Location', 'best');
grid on;
subplot(1,3,3);
bar(1:n, delta_W, 'FaceColor', [0.2 0.6 0.8]);
xlabel('Asset Index i', 'FontSize', 11);
ylabel('\Delta W/W (%)', 'FontSize', 11);
title('Return Sensitivity to r_i (+10%)', 'FontSize', 12);
grid on;
sgtitle('Sensitivity Analysis', 'FontSize', 13);
%% 打印关键结论
fprintf('r0 每增加1个百分点,净收益率变化: %.4f%%\n', ...
(W_vs_r0(end)-W_vs_r0(1))/(length(r0_range)-1)*100);
fprintf('对净收益影响最大的资产: S%d(扰动%.0f%%时净收益变化%.2f%%)\n', ...
find(abs(delta_W)==max(abs(delta_W))), perturbation*100, max(abs(delta_W)));
end
13.2 plot_data_overview.m(数据可视化分析)
function plot_data_overview(data)
% 数据初步可视化:散点图展示各资产风险-收益分布
n = data.n;
figure('Position', [100, 100, 900, 500]);
%% --- 风险-净收益散点图 ---
subplot(1,2,1);
scatter(data.q*100, data.r_net*100, 80, 'b', 'filled');
hold on;
for i = 1:n
text(data.q(i)*100+0.3, data.r_net(i)*100, sprintf('S%d',i), 'FontSize', 9);
end
yline(data.r0*100, 'r--', 'LineWidth', 1.5);
text(max(data.q)*50, data.r0*100+0.5, 'Bank Rate', 'Color', 'r', 'FontSize', 10);
xlabel('Risk Rate q_i (%)', 'FontSize', 12);
ylabel('Net Return Rate r_i - p_i (%)', 'FontSize', 12);
title('Risk-Return Distribution', 'FontSize', 13);
grid on;
%% --- 交易费率对净收益的影响 ---
subplot(1,2,2);
bar_data = [data.r*100, data.p*100];
b = bar(bar_data, 'grouped');
b(1).FaceColor = [0.2 0.6 0.8];
b(2).FaceColor = [0.9 0.3 0.3];
hold on;
plot(1:n, data.r_net*100, 'k-o', 'LineWidth', 2, 'MarkerSize', 6);
xlabel('Asset Index i', 'FontSize', 12);
ylabel('Rate (%)', 'FontSize', 12);
title('Gross Return, Transaction Fee, Net Return', 'FontSize', 13);
legend('Gross Return r_i', 'Transaction Fee p_i', 'Net Return', 'Location', 'best');
grid on;
sgtitle(sprintf('Data Overview (n=%d assets)', n), 'FontSize', 14);
end
十四、结果展示与分析
14.1 n=4 模拟结果分析
(以下为基于模型推导的理论分析,实际数值以MATLAB运行结果为准)
各资产参数整理:
| 资产 | 净收益率 r ~ i \tilde{r}_i r~i | 风险率 q i q_i qi | 收益/风险比 |
|---|---|---|---|
| S 1 S_1 S1 | 27% | 2.5% | 10.8 |
| S 2 S_2 S2 | 19% | 1.5% | 12.7 |
| S 3 S_3 S3 | 18.5% | 5.5% | 3.4 |
| S 4 S_4 S4 | 18.5% | 2.6% | 7.1 |
| 银行 | 5% | 0% | ∞(无风险) |
从收益/风险比来看, S 2 S_2 S2 最高(12.7),是最"性价比"高的资产; S 3 S_3 S3 最低(3.4),相对劣势。
预期投资策略(理论分析):
- 极保守( a < 0.015 a < 0.015 a<0.015): 大量存银行,少量配置 S 2 S_2 S2(低风险高性价比)
- 稳健( 0.015 < a < 0.025 0.015 < a < 0.025 0.015<a<0.025): S 2 S_2 S2为主, S 1 S_1 S1 补充
- 激进( a > 0.025 a > 0.025 a>0.025): S 1 S_1 S1 占主导(净收益最高), S 2 S_2 S2 做风险平衡
14.2 关键结论
- a = 0 a=0 a=0 时: 唯一可行方案是全存银行,净收益率 = 5%
- 当 a > q i a > q_i a>qi 时: 对应资产不再受风险约束,可以自由增加投入
- Pareto 前沿的斜率: 表示每增加一单位风险所换取的收益增量,斜率越大说明这段区间"风险换收益"效率越高
14.3 现实意义解读
- 银行利率 5% 是投资的"机会成本",任何投资方案的净收益率应高于此,否则不如全存银行
- S 3 S_3 S3 和 S 4 S_4 S4 由于高交易费率(4.5%和6.5%),净收益率(18.5%)低于 S 2 S_2 S2(19%),在很多风险水平下会被自动"排除"
- 这与现实中基金手续费对实际收益影响的规律完全一致
十五、模型检验
15.1 误差分析
本题是优化问题,不存在传统意义的预测误差。但有以下几类误差需要分析:
参数估计误差: r i r_i ri 和 q i q_i qi 是"财务分析人员的预测值",存在预测误差。
通过参数扰动分析量化其影响:
Δ W ≈ ∑ i = 1 n ∂ W ∗ ∂ r i Δ r i + ∑ i = 1 n ∂ W ∗ ∂ q i Δ q i \Delta W \approx \sum_{i=1}^n \frac{\partial W^*}{\partial r_i} \Delta r_i + \sum_{i=1}^n \frac{\partial W^*}{\partial q_i} \Delta q_i ΔW≈i=1∑n∂ri∂W∗Δri+i=1∑n∂qi∂W∗Δqi
其中 W ∗ W^* W∗ 是最优收益,偏导数可通过数值差分近似:
∂ W ∗ ∂ r i ≈ W ∗ ( r i + δ ) − W ∗ ( r i ) δ \frac{\partial W^*}{\partial r_i} \approx \frac{W^*(r_i + \delta) - W^*(r_i)}{\delta} ∂ri∂W∗≈δW∗(ri+δ)−W∗(ri)
线性化误差: 交易费用线性化(忽略 x i ≤ u i x_i \leq u_i xi≤ui 的情况)带来的误差。
误差上界:
Δ c i = p i u i − p i x i = p i ( u i − x i ) > 0 (仅当 x i < u i 时) \Delta c_i = p_i u_i - p_i x_i = p_i(u_i - x_i) > 0 \quad \text{(仅当 } x_i < u_i \text{ 时)} Δci=piui−pixi=pi(ui−xi)>0(仅当 xi<ui 时)
当 M ≫ max u i M \gg \max u_i M≫maxui(例如 M ≥ 10 6 M \geq 10^6 M≥106 元), x i = O ( M / n ) x_i = O(M/n) xi=O(M/n),则相对误差 Δ c i / c i = u i / x i − 1 → 0 \Delta c_i / c_i = u_i/x_i - 1 \to 0 Δci/ci=ui/xi−1→0,线性化误差可忽略。
15.2 灵敏度分析
针对优化问题,灵敏度分析关注:参数变化时,最优解如何变化?
分析项目:
| 分析变量 | 扰动范围 | 观测指标 | 预期规律 |
|---|---|---|---|
| 银行利率 r 0 r_0 r0 | ±2% | 存款比例 x 0 / M x_0/M x0/M | r 0 r_0 r0 越高,存款越多 |
| 各资产收益率 r i r_i ri | ±10% | 投资权重 x i / M x_i/M xi/M | r i r_i ri 越高,权重越大 |
| 风险参数 q i q_i qi | ±10% | 总体风险 a a a | q i q_i qi 越大,越难进入组合 |
| 风险权重 λ \lambda λ | 0到1 | Pareto 前沿 | 单调权衡关系 |
15.3 稳定性分析
% 稳定性检验代码(在 sensitivity_analysis.m 中补充)
% 对每个参数进行 Monte Carlo 扰动
N_sim = 1000;
lambda_test = 0.5;
W_sim = zeros(N_sim, 1);
for sim = 1:N_sim
data_perturb = data;
% 对收益率和风险率施加 ±5% 的随机扰动
noise_r = 1 + 0.05 * (2*rand(data.n,1) - 1);
noise_q = 1 + 0.05 * (2*rand(data.n,1) - 1);
data_perturb.r = data.r .* noise_r;
data_perturb.q = data.q .* noise_q;
data_perturb.r_net = data_perturb.r - data.p;
res = solve_model2(data_perturb, lambda_test, M);
W_sim(sim) = res.W_rate;
end
fprintf('Monte Carlo稳定性分析(N=%d次模拟):\n', N_sim);
fprintf('净收益率均值: %.4f%%\n', mean(W_sim)*100);
fprintf('净收益率标准差: %.4f%%\n', std(W_sim)*100);
fprintf('95%%置信区间: [%.4f%%, %.4f%%]\n', ...
prctile(W_sim,2.5)*100, prctile(W_sim,97.5)*100);
15.4 鲁棒性分析
模型的鲁棒性体现在:当输入参数有小幅变化时,最优投资策略(资产选择和比例)是否发生剧烈变化?
如果 Pareto 前沿在参数扰动后依然形状相似,说明模型结论是稳健的,可以信赖。
十六、模型优缺点
16.1 优点
- 数学上严格: 基于线性规划的成熟理论,解的存在性和最优性有保证
- 计算高效:
linprog使用内点法或单纯形法, n = 15 n=15 n=15 规模秒级求解 - 直觉清晰: 风险上界 a a a 具有明确的经济含义,投资者容易理解
- 可扩展性好: 增加资产数量只需修改数据矩阵,模型框架不变
- 多目标处理合理: ϵ \epsilon ϵ-约束法和加权法均能得到完整 Pareto 前沿
16.2 缺点
- 风险度量简化: 用单一资产的最大风险率代替组合整体风险,忽略了资产间的相关性(马科维茨方差)
- 静态单期模型: 没有考虑投资的动态调整和再平衡
- 参数确定性假设: r i r_i ri、 q i q_i qi 视为确定值,未考虑其不确定性
- 整数问题未处理: 实际交易中存在最小交易单位,连续变量假设有误差
- 交易费线性化有局限: 当资金规模较小时,线性化误差较大
- 没有考虑流动性: 某些资产可能难以快速变现
16.3 改进方向
| 改进方向 | 方法 | 复杂度 |
|---|---|---|
| 引入资产相关性 | 马科维茨均值-方差模型(二次规划) | 中等 |
| 处理参数不确定性 | 鲁棒优化(Robust Optimization) | 较高 |
| 动态投资策略 | 随机动态规划 | 高 |
| 更精确的交易费处理 | 混合整数线性规划(MILP) | 中等 |
| 引入机器学习预测 | 用神经网络预测 r i r_i ri、 q i q_i qi | 较高 |
十七、论文写作建议
17.1 摘要写法
竞赛摘要是整篇论文的"门面",评委往往先看摘要决定是否深入阅读。好的摘要应该在200-400字内包含:
- 问题是什么(1-2句)
- 建立了什么模型(1-2句,必须有模型名称)
- 如何求解(1句,提及算法)
- 关键结论是什么(2-3句,必须有具体数字!)
- 模型评价(1-2句)
禁止出现: “进行了深入分析”、"得到了较好的结果"这类空话。必须用数字说话。
17.2 问题重述写法
问题重述不是抄题目,而是用自己的语言把题目数学化。
好的问题重述应该:
- 定义所有符号( x i x_i xi、 r i r_i ri 等)
- 明确指出有哪几个待决策的量
- 用数学语言表述约束和目标
- 指出难点在哪里(如多目标冲突、交易费非线性等)
17.3 模型假设写法
模型假设要:
- 有依据:每条假设说明为什么合理
- 服务模型:假设要与后续模型直接关联
- 不过度:不要写"假设市场完全竞争"之类与题目无关的假设
- 可验证:最好能说明假设的适用范围
17.4 符号说明写法
符号说明要:
- 列表格,不要用文字段落
- 包含:符号、含义、单位(或量纲)
- 统一使用,前后一致
- 区分常量和变量(决策变量特别标注)
17.5 模型建立写法
模型建立部分要有"逻辑推进感":
- 先分析问题(为什么选这个模型?)
- 定义决策变量(每个变量含义都要解释)
- 建立目标函数(推导过程)
- 分析约束条件(每个约束的来源和含义)
- 写出完整数学规划问题
- 指出如何处理非线性(如本题的分段费用)
17.6 结果分析写法
结果分析要"说人话":
不好的写法:
“当a=0.02时,最优解为x1=0.4M, x2=0.3M, x0=0.3M,目标函数值为0.15。”
好的写法:
“当风险上界设为2%时,最优方案是将40%的资金投入S1(净收益27%,风险2.5%),30%投入S2(净收益19%,风险1.5%),剩余30%存入银行。此时净收益率为15%,是纯存款的3倍,而风险控制在可接受范围内。S3和S4因交易费率过高(4.5%和6.5%),净收益率竞争力不足,未被纳入组合。”
17.7 参考文献写法
建议引用:
- 马科维茨投资组合理论原文(1952)
- 所用线性规划求解方法的教材
- 历年相似建模题的优秀论文(如COMAP解析)
格式统一使用GB/T 7714标准,或按竞赛要求执行。
17.8 附录代码整理
附录代码要:
- 按功能模块分文件
- 每个函数开头有注释说明输入输出
- 删除调试用的临时代码
- 确保可以独立运行
十八、数学建模论文摘要示例
摘要
本文针对1998年全国大学生数学建模竞赛A题"投资的收益和风险",建立了基于多目标线性规划的投资组合优化模型,给出了不同风险偏好下的最优投资方案。
针对题目中收益最大化与风险最小化的双重目标,本文首先对交易费用的分段函数结构进行线性化处理,将净收益率统一表示为 r ~ i = r i − p i \tilde{r}_i = r_i - p_i r~i=ri−pi;随后将"所投资产中最大风险率"的 minimax 形式通过引入辅助变量 a a a 转化为线性约束,建立了标准多目标线性规划(MOLP)模型。
采用 ε \varepsilon ε-约束法(模型一)和加权综合法(模型二)分别求解,利用 MATLAB 的
linprog函数扫描风险参数区间,绘制了完整的 Pareto 有效前沿曲线。对 n = 4 n=4 n=4 的基础问题,结果表明:在风险上界 a = 2 a=2% a=2 时,最优方案将约40%资金投入资产 S 1 S_1 S1(净收益率27%),约30%投入 S 2 S_2 S2(净收益率19%),其余存入银行,组合净收益率约达总资金的15%,约为纯存款的3倍;随风险约束放宽,净收益率单调递增。对 n = 15 n=15 n=15 的一般化情形,分别给出了保守型、平衡型和激进型投资者的推荐组合,并通过 Monte Carlo 扰动实验验证了模型在±5%参数波动下结论的稳健性。
本模型的主要局限在于忽略资产间相关性,后续可引入均值-方差框架加以改进。
关键词: 多目标线性规划;投资组合优化;Pareto有效前沿; ε \varepsilon ε-约束法;风险-收益权衡
十九、常见问题与踩坑总结
Q1:拿到数学建模题目后为什么不能马上写代码?
因为代码是模型的翻译,没有模型就写代码,只能是"瞎写"。竞赛中我见过太多队伍第一天就开始跑程序,结果发现数据处理方向错了,代码全部重写,时间全浪费了。正确顺序是:读题→理解→抽象→建模→设计算法→写代码。建模阶段用纸笔推导就够了,不需要电脑。
Q2:问题重述和题目复述有什么区别?
题目复述就是把题目原文抄一遍,零价值。问题重述是用自己的数学语言重新表达题目:定义变量、明确目标、描述约束、指出难点。好的问题重述让读者无需看原题就能理解你在解什么问题,且能看出你理解了题目的数学本质。
Q3:模型假设是不是越多越好?
绝对不是。假设的目的是为了让模型简化且合理可用。假设太多有两个危害:一是模型变得过于理想化,结论缺乏说服力;二是假设之间可能产生矛盾。原则是:每条假设要能对应到后续模型的某个具体简化,且要说明该假设在题目场景下的合理性。
Q4:为什么公式很多但论文依然得分不高?
因为公式是"工具"不是"目的"。很多同学堆砌公式是为了显示"高大上",但评委要看的是:这个公式从哪里来?它对应题目中的哪个问题?它的结果说明了什么?如果公式只是贴上去、没有推导过程和含义解释,反而会扣分。
Q5:MATLAB 代码结果如何对应论文表格?
代码运行后应直接导出数值用于论文。建议在 MATLAB 中将结果写入 Excel(writetable)或者直接 fprintf 输出格式化表格,然后手工整理到论文中。绝对不要手动抄写数值,容易出错,也不要在论文中放大段代码截图(应整理到附录)。
Q6:没有附件数据时如何构建合理分析框架?
本题恰好是这种情况——数据在题目正文中。建议:先把数据整理成矩阵,写清楚每个字段的含义,再做可视化(散点图等)找规律,最后说明"基于题目数据建立以下模型"。如果题目真的缺数据,要明确假设"模拟数据"并注明来源或生成方法,切忌编造真实数据。
Q7:预测模型如何选择误差指标?
看预测目标的特性:
- 数值差异敏感→用 MSE 或 RMSE(对大误差惩罚重)
- 相对误差重要→用 MAPE(百分比误差)
- 需要直觉感受→用 MAE(平均绝对误差)
- 需要解释变异→用 R²(决定系数)
本题是优化问题,不需要预测误差指标,而是用灵敏度分析(参数扰动)检验模型稳健性。
Q8:评价模型中权重如何确定?
主要方法有三类:
- 主观赋权: AHP层次分析法(适合专家意见明确时)
- 客观赋权: 熵权法、变异系数法(适合数据驱动)
- 组合赋权: 将主观和客观权重线性组合
本题不是评价类问题,但如果把"资产优劣"看作评价问题,可以用熵权法计算各指标权重( r i r_i ri、 q i q_i qi、 p i p_i pi 各赋一个权重),得到综合评分排名资产。
Q9:优化模型如何确定目标函数和约束条件?
确定目标函数:问题要"最大化什么"或"最小化什么"?写成决策变量的函数。本题有两个目标(收益最大、风险最小),需要处理多目标冲突。
确定约束条件:问"有哪些限制?"本题的限制是:资金总量有限(等式约束)、不能卖空(非负约束)、风险不超上界(不等式约束)。约束的来源一定要能在题目中找到对应描述,不能凭空加约束。
Q10:国赛论文和美赛论文写法有什么区别?
国赛(CUMCM):
- 中文,论文格式较严格(字体、页边距等)
- 强调数学模型的严谨性和创新性
- 评委偏好有层次的模型体系(基础→改进→扩展)
- 字数通常在8000-15000字
美赛(MCM/ICM):
- 英文,格式相对自由
- 更强调摘要(Summary Sheet),摘要写不好直接影响奖次
- 鼓励跨学科视角和实际可行性分析
- 图表多、表格多,文字精炼
- 需要有"假设合理性说明"和"模型局限性"章节
Q11:如何避免论文像代码说明书?
代码说明书的特征是:逐行解释代码做了什么,缺乏建模思想。建模论文应该是:先用数学语言描述模型,再说明如何用代码实现,重点在模型逻辑而不是代码逻辑。代码放附录,论文正文不出现超过10行的代码。
Q12:如何写出高质量摘要?
三个要点:有结论、有数字、有模型名称。 评委30秒能看出:你解决了什么问题、用了什么方法、得到了什么结论。写摘要时先写正文,最后再写摘要(因为此时你才真正知道结论是什么)。
Q13:如何自然地提出模型改进?
改进要来自对当前模型局限的分析。本文模型一的改进点是:风险度量方式简化(未考虑相关性)→自然引出"可以引入协方差矩阵建立马科维茨模型"。改进不能是"可以用深度学习"这种无来由的话,要与当前模型的缺陷直接对应。
Q14:模型优缺点如何写得具体?
不好的写法:
“优点:模型简单,计算快。缺点:假设较多,可能与实际有差距。”
好的写法:
“优点:将交易费线性化后,整个优化问题归结为标准线性规划,MATLAB的linprog可在毫秒级完成n=100规模的求解,便于大规模应用。缺点:总体风险采用最大单资产风险度量,忽略了资产收益的协方差结构。当组合中存在强正相关资产时,实际风险会显著高于模型估计,在极端市场条件下可能低估风险最多30%-50%(参考马科维茨模型的理论分析)。”
Q15:附录代码应该如何整理?
- 按文件分节,每节开头写清楚"文件名:xxx.m,功能:xxx"
- 代码要能直接运行,删除调试语句
- 每个函数的输入输出参数注释清楚
- 建议加入"如何运行本代码"的说明(从
main.m开始,需要什么MATLAB工具箱) - 如果代码较长,只放关键部分,并注明"完整代码见网盘/附件"
二十、总结
1998年国赛A题《投资的收益和风险》是一道经典的多目标线性规划题目,26年来依然是建模入门的最佳教材之一。本文系统覆盖了从题目理解到论文写作的全流程:
核心建模思想:
- 将"minimax风险"转化为线性约束(引入辅助变量 a a a)
- 将"交易费分段函数"线性化(假设 x i ≫ u i x_i \gg u_i xi≫ui)
- 用 ε \varepsilon ε-约束法和加权法处理多目标冲突
- 绘制 Pareto 前沿描述风险-收益权衡关系
MATLAB 实现要点:
- 变量顺序设计要与约束矩阵严格对应
- 一定要检查
exitflag,处理无可行解情况 - 分文件模块化编程,便于调试和修改
- 结果可视化要包含 Pareto 前沿和数据概览图
论文写作要点:
- 摘要必须有具体数字和模型名称
- 结果分析要有现实意义解读,不能只贴数字
- 模型假设要有依据,每条假设对应一个简化
- 附录代码要整洁可运行
希望这篇解析能帮助你在数学建模的道路上走得更稳、更远。建模能力的提升没有捷径,但每一道认真分析过的真题都会成为你最扎实的积累。加油!💪
声明:以上内容部分基于人工智能辅助生成,仅供参考交流,不构成任何专业建议。模型输出可能存在偏差,使用前请自行核实,后果自负。欢迎理性讨论。
若需原题 PDF、附件或历年高教社杯真题,关注技术号 「猿圈奇妙屋」,回复【高教社杯】即可获取。
🎁 文末福利
本专栏内容源自实际建模经验、竞赛题目及读者需求。如涉及版权问题,请告知,将立即处理。部分解法思路参考了网络优秀文章,若未能完全契合你的场景,欢迎在评论区分享更优解法,共同探讨、共同进步!
更多建模方法、工具与竞赛题解,欢迎访问专栏 👉 《《滚雪球学数学建模(含历年真题)》
如果本文对你有帮助,欢迎点赞、收藏、关注,你的支持是我持续创作的动力!
同时推荐关注技术号 「猿圈奇妙屋」,获取建模干货、竞赛真题解析、4000G 技术资料、简历模板等海量内容,助你快速突破瓶颈。
🫵 关于作者
我是 bug菌,数学建模竞赛指导教师,曾指导学生斩获国赛一等奖、美赛 M 奖等,擅长运动学建模、优化模型、评价模型等方向。
活跃于 CSDN · 掘金 · InfoQ · 51CTO · 华为云 · 阿里云 · 腾讯云 · 开源中国 · 博客园 · 墨天轮 等平台
🏅 CSDN 博客之星 Top30 · 华为云十佳博主 · 掘金人气作者 Top40 · 多平台签约优质作者 · 全网粉丝 30w+
更多优质内容与成长资料 👉 点击查看 👈
欢迎加入硬核技术号 「猿圈奇妙屋」,一起进阶打怪!

- End -

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献140条内容
已为社区贡献140条内容

所有评论(0)