一文搞懂模型名称的 B、GGUF、MTP、A3B、E4B 都是啥意思
你是不是也被各种模型名搞懵了?打开 Ollama 或者 HuggingFace,满屏的 Qwen3.6-27B-MTP-GGUF、Qwen3.6-35B-A3B、google/gemma-4-E4B-it…… 乍一看还以为是系统乱码了。
别慌,今天咱们就大白话把这些模型名拆开揉碎,让你以后看到模型名就像看菜名一样明白——这什么菜、什么口味、多大份、我电脑能不能跑得动。
一、模型名里的「B」,到底啥意思?
你肯定见过7B、14B、30B、120B这里的 B 不是字母 B 也不是维生素 B,而是 Billion(十亿) 的缩写。
一个 7B 模型,就是有 70 亿个参数。参数你可以粗暴理解为模型的「脑细胞数量」—— 参数越多,理论上模型知道的东西越多、推理能力越强。
🌰 举个栗子:
- 3B 模型 ≈ 30 亿参数 → 跟一本百科全书差不多
- 7B 模型 ≈ 70 亿参数 → 能把大英百科全书背下来还附带些论文
- 70B 模型 ≈ 700 亿参数 → 相当于读过博士后的超级学霸
但参数多 ≠ 一定更好。就像人一样,会读书不代表会办事。而且参数越多,电脑越吃力(后面会讲到底要多好的电脑才能跑)。

二、Qwen3.6-27B-MTP-GGUF拆解
拿这个最典型的例子,一刀一刀拆:
|
部分 |
含义 |
大白话 |
|
Qwen3.6 |
模型家族名 + 版本 |
通义千问第 3.6 代 |
|
27B |
270 亿参数 |
这模型的脑容量 |
|
MTP |
Multi-Token Prediction多 Token 预测 |
推理加速技术 ,训练时让模型学会一次预测多个字 |
|
GGUF |
GPT-Generated Unified Format统一模型格式 |
模型文件的"包装盒" ,告诉你怎么打开它 |
🔍 深入说说 MTP(Multi-Token Prediction)
传统大模型生成文字就像你一个字一个字地蹦:"我—今—天—吃—了—一—个—苹—果"。每次只能推下一个字,效率不高。
MTP 就不一样了,它训练时就学会了 一次预测未来好几个字。就像你看一句话的前半段,脑里已经猜到后半段——"我今天吃了一个____",你大概率猜到是"苹果"。
MTP 让模型能同时预测后面 2 个甚至更多 token,好处就是:推理速度翻倍,响应少等一半时间。Qwen3 系列的 MTP 版实测速度比普通版快了差不多 2 倍。
💡 一句话:带 MTP 的模型 ≈ 模型界的"看完上句猜下句"选手,又快又准。
🔍 再深入说说 GGUF 和量化
GGUF 是 llama.cpp 社区搞出来的模型文件格式。之前流行的 GGML 已被淘汰,现在是 GGUF 的天下。
GGUF 本身不代表"质量差",它是一个能装各种精度模型的容器格式。但 GGUF 文件名里通常会跟量化标记,比如 Q4_K_M.gguf,这才是灵魂。
📊 GGUF 量化后缀全解
|
后缀 |
含义 |
每参数 bit |
7B 模型大小 |
质量 |
|
Q2_K |
2 bit 量化 |
~2.6 |
~2.7 GB |
明显下降 |
|
Q3_K |
3 bit 量化 |
~3.4 |
~3.3 GB |
中等下降 |
|
Q4_0 |
4 bit 基础量化 |
~4.0 |
~4.1 GB |
轻微下降 |
|
Q4_K_M |
4 bit K-quant 中 |
~4.5 |
~4.5 GB |
⭐ 性价比之选 |
|
Q5_K_M |
5 bit K-quant 中 |
~5.5 |
~5.2 GB |
几乎无损 |
|
Q6_K |
6 bit 量化 |
~6.5 |
~5.8 GB |
接近无损 |
|
Q8_0 |
8 bit 量化 |
~8.5 |
~7.7 GB |
几乎无损 |
|
F16 |
半精度(未量化) |
16 |
~14 GB |
无损失 |
💡 小白选量化口诀:内存够大选 Q5_K_M 或 Q6_K,省空间选 Q4_K_M(这是绝大多数人的甜点档)。Q2_K 和 Q3 只在实在跑不动时才考虑,能明显感受到"脑雾"。
K 是啥意思? K-quant(K-quantization)是 GGUF 社区的"按重要性分配精度"策略。重要的参数用高精度,不重要的用低精度,同样的 bit 数下 K 系列质量更好。所以 Q4_K_M 比 Q4_0 好得多。
三、A3B和 E4B——MoE 模型的秘密暗号
这两个后缀都指向同一个东西:MoE(Mixture of Experts,混合专家模型)。
MoE 模型是什么🤔?想象一个公司:
普通模型 = 一个全能员工,什么都会但一个人处理所有事,累死累活。
MoE 模型 = 一个公司,各个部门都有专业专家(Experts)。来一个问题,只叫相关领域的几个专家来干活,其他人继续喝茶。所以——总员工很多,但每次只出动一小批人。
这就解释了为什么 MoE 模型名字里会有两个数字。
🔍 Qwen/Qwen3.6-35B-A3B
|
符号 |
意思 |
大白话 |
|
35B |
总参数 350 亿 |
公司总员工数 |
|
A3B |
Active 3B,活跃参数 30 亿 |
每次只叫 30 亿参数干活 ≈ 每次只出动这几个专家 |
💡 所以这个模型:大脑有 350 亿个脑细胞,但每次思考只用其中 30 亿。它效果接近 35B,跑起来却只消耗 3B 模型的资源。
就像公司有 350 人,但每次只派 3 个专家去开会——开销只有 3 个人的茶水费,产出却是 350 人公司的水平。
🔍 google/gemma-4-E4B-it
Google 的 Gemma 4 也是 MoE,但命名方式不同:
|
符号 |
意思 |
大白话 |
|
E |
Experts |
专家数 |
|
4B |
~40 亿活跃参数 |
每次干活调动的脑细胞 |
|
it |
Instruction-Tuned 指令微调版 |
已经训练好了怎么听话 |
所以 Gemma-4-E4B 拆开就是:Google Gemma 第 4 代,MoE 架构,推理时激活约 40 亿参数,已做指令微调可直接聊天用。
🔑 核心记住:看 MoE 模型,别只看总参数,更要看活跃参数(A5B / E4B)。跑一个 300B 总参数的 MoE 模型,可能只需要 30B 活跃参数的显存——省钱的秘密就在这里!
四、那些让人摸不着头脑的「奇葩」模型名
正经命名看完了,来点娱乐——模型界的"起名鬼才"们:
|
模型名 |
槽点 / 解读 |
|
SOLAR-10.7B-Instruct |
10.7B? 大家都取整数,你整个 10.7 是什么鬼?强迫症当场崩溃。实际是通过 depth up-scaling 把 10.7B 小模型"拉长"层数得来的。 |
|
NousResearch/Hermes-3-Llama-3.1-405B-FP8 |
命名链比论文题目还长 :微调方 → 项目名 → 基座 → 参数 → 精度,读完整条命气都喘不上来。 |
|
Phi-3-mini-4k-instruct |
4k 不是分辨率 ,是上下文长度 4096 tokens。没看过文档的人第一反应:这模型还是显示器? |
|
SmolLM2-135M-Instruct |
Smol = Small? 135M(1.35 亿参数)确实是 mini 战斗机,手机都能跑。但"Smol"这个拼写是认真的吗…… |
|
DeepSeek-R1-Distill-Qwen-7B |
蒸馏(Distill)= 大模型当老师教小模型。但"老师-方法-学生-大小"四层嵌套,像俄罗斯套娃。 |
|
c4ai-command-r-plus |
c4ai → Cohere for AI,command → 产品线,r → 版本代号,plus → 加强版。 字母+单词+符号大杂烩,像路由器型号一样难记。 |
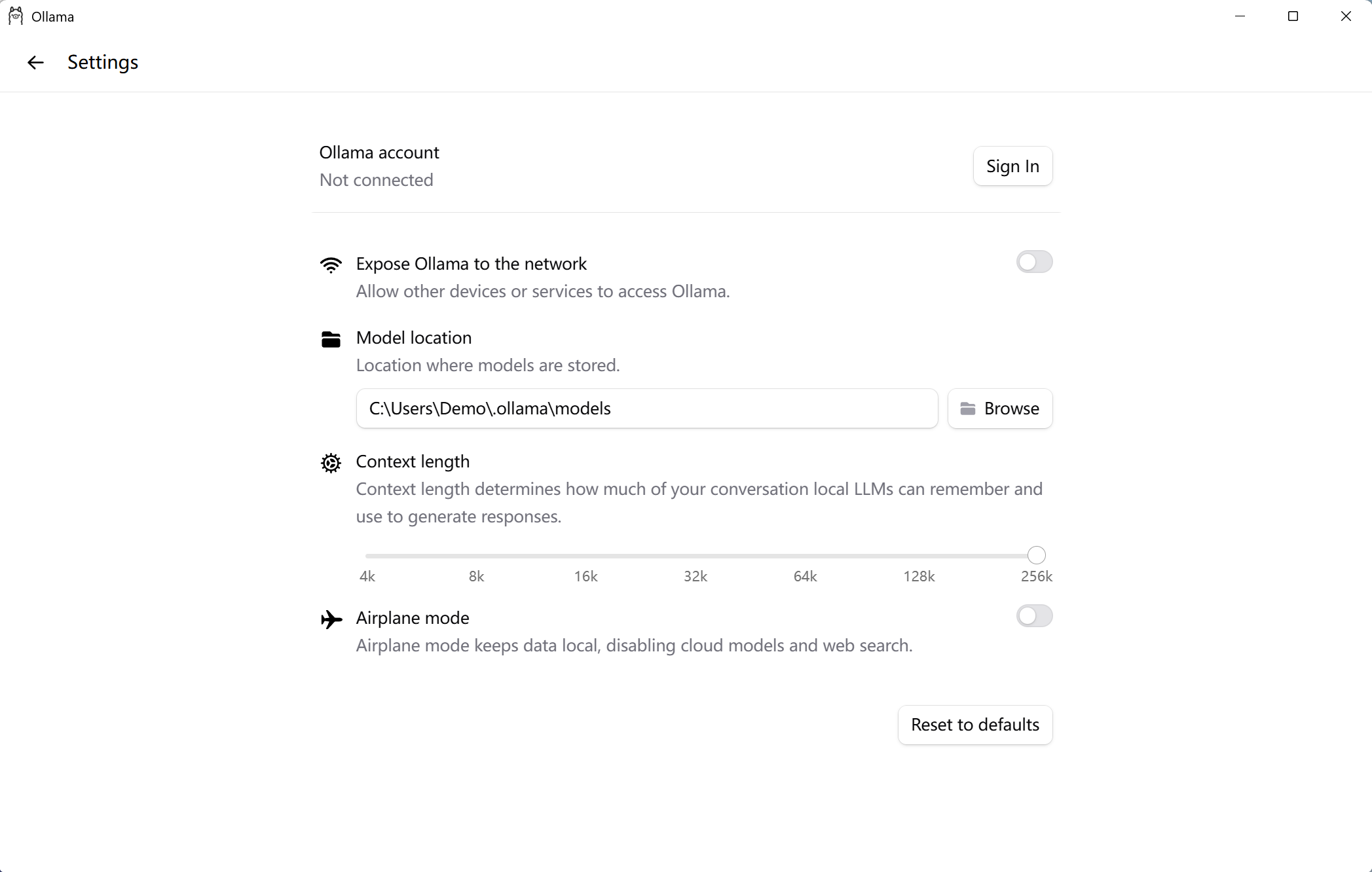
五、多好的配置能跑多大模型?
灵魂拷问来了:我这台电脑到底能跑多大的模型?
关键看两个硬件:显存(VRAM)和内存(RAM)。模型量化后的大小决定了你能不能把它塞进去。以下以 Q4_K_M 量化为例:
|
参数量 |
Q4_K_M 大小 |
最低显存要求 |
推荐配置 |
体验 |
|
1B~3B |
~0.8~2 GB |
4 GB 集成显卡 |
轻薄本、手机、树莓派 |
⚡ 飞快,简单问答够用 |
|
7B~8B |
~4.5 GB |
6 GB 显存 |
RTX 3060+ / M 系列 Mac |
⭐ 主流甜点级,日常够用 |
|
14B~20B |
~8~12 GB |
12 GB 显存 |
RTX 4070+ (12G) / 二手 3090 |
👍 推理能力明显更强 |
|
32B~35B |
~18~20 GB |
24 GB 显存 |
RTX 4090 / 双卡 3090 / Mac 64G+ |
💪 较强,需显卡投资 |
|
70B~72B |
~40 GB |
48 GB 显存 |
双 4090 / A100 / Mac 128G+ |
🔥 强但门槛高 |
|
100B+ |
~60+ GB |
80 GB+ 显存 |
A100 / H100 / 服务器集群 |
🚀 工作站级,个人烧钱 |
不过目前市面上已经有一些专门用于AIPC的CPU支持本地跑120B以上大参数模型了,如AMD 395
⚠️ 重要提醒:如果显存不够,有些工具会自动把一部分模型放到系统内存里跑(这叫 CPU offloading),速度会大幅变慢(可能慢 10 倍)。所以想体验丝滑,尽量让模型完全放进显存。
Mac 用户注意:Apple Silicon(M 系列芯片)走统一内存架构,没有独立显存概念。所以 64 GB 内存的 Mac = 64 GB"显存"可用,跑 70B 模型甚至能全放进内存——这是 Mac 跑大模型的巨大优势。
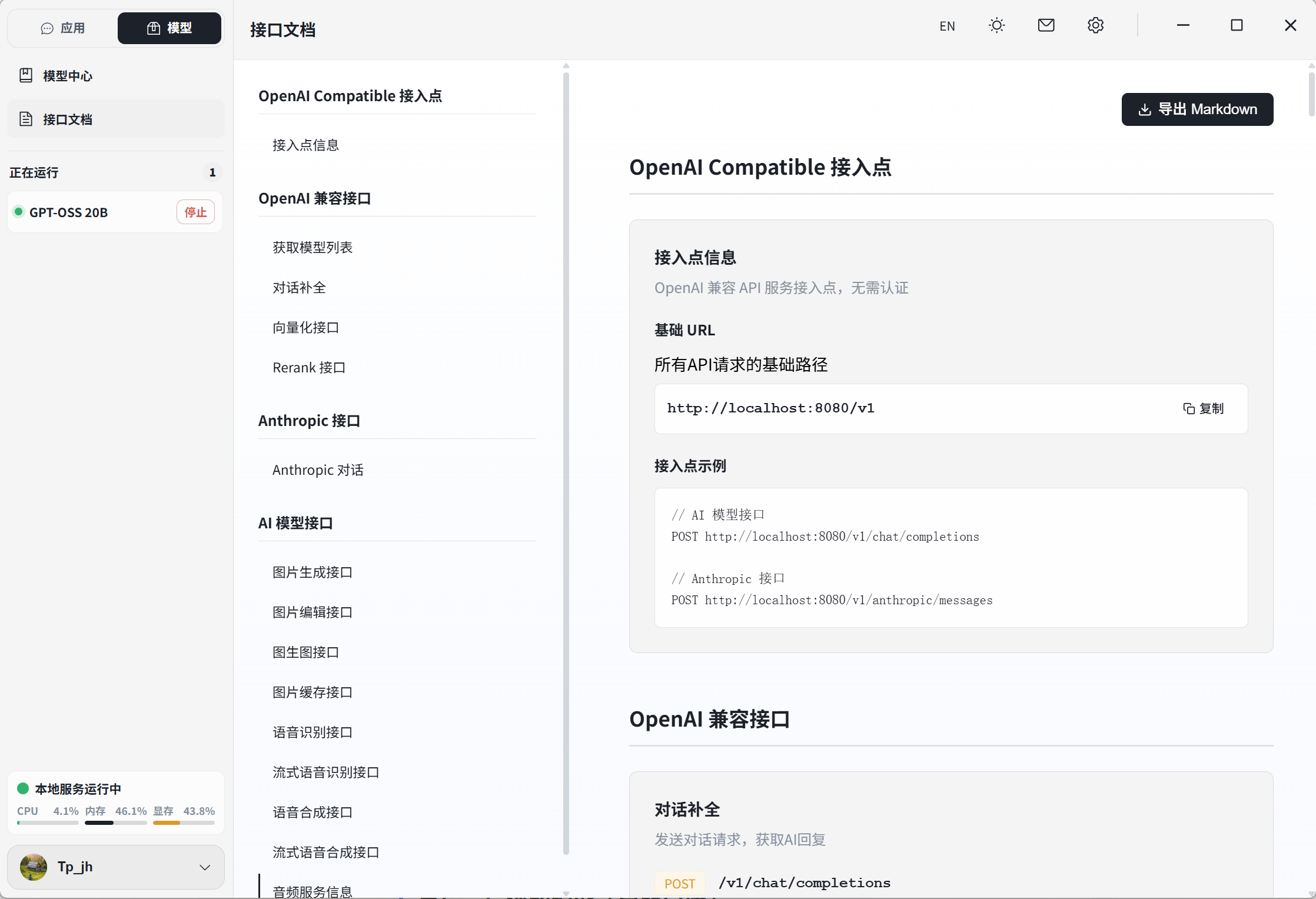
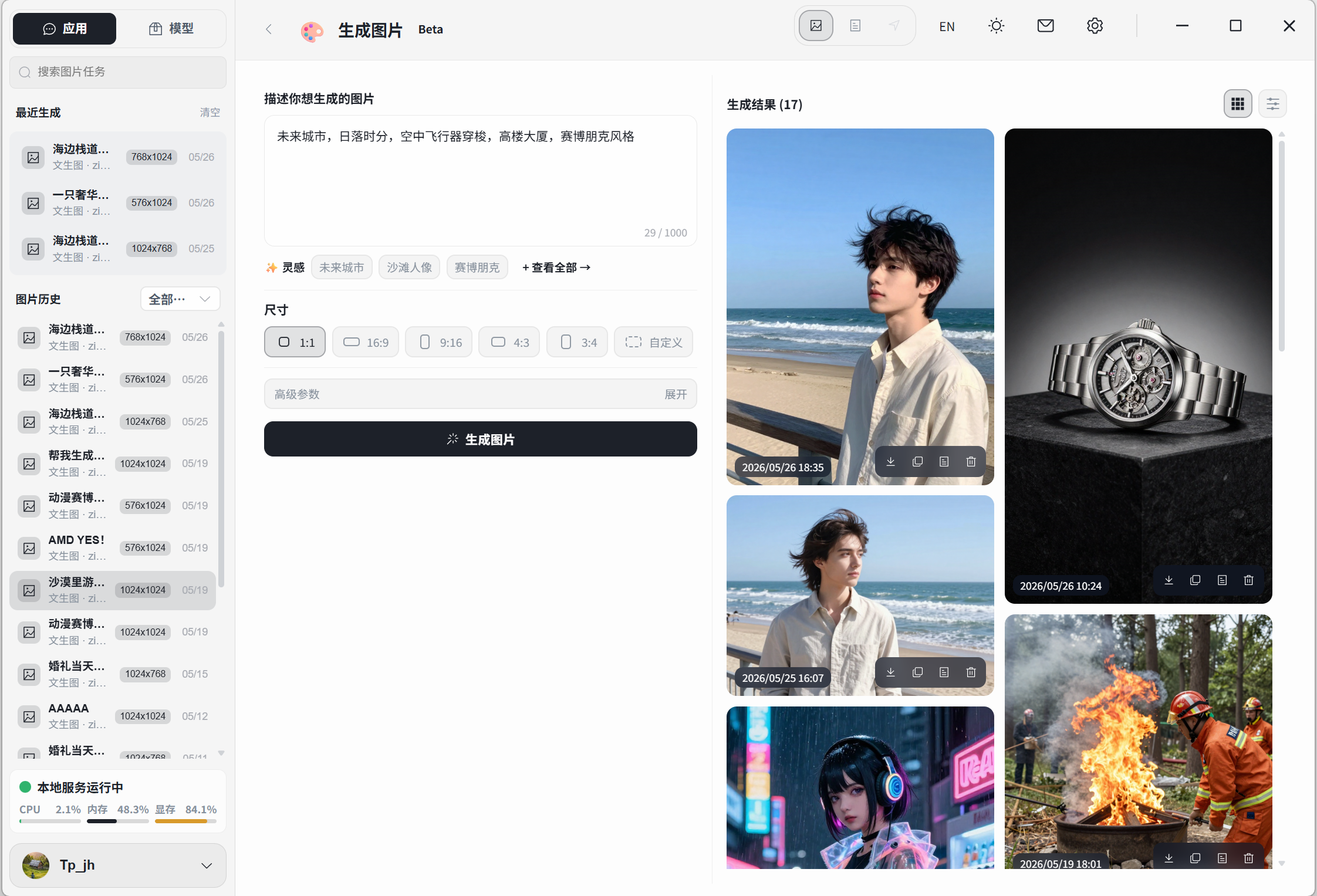
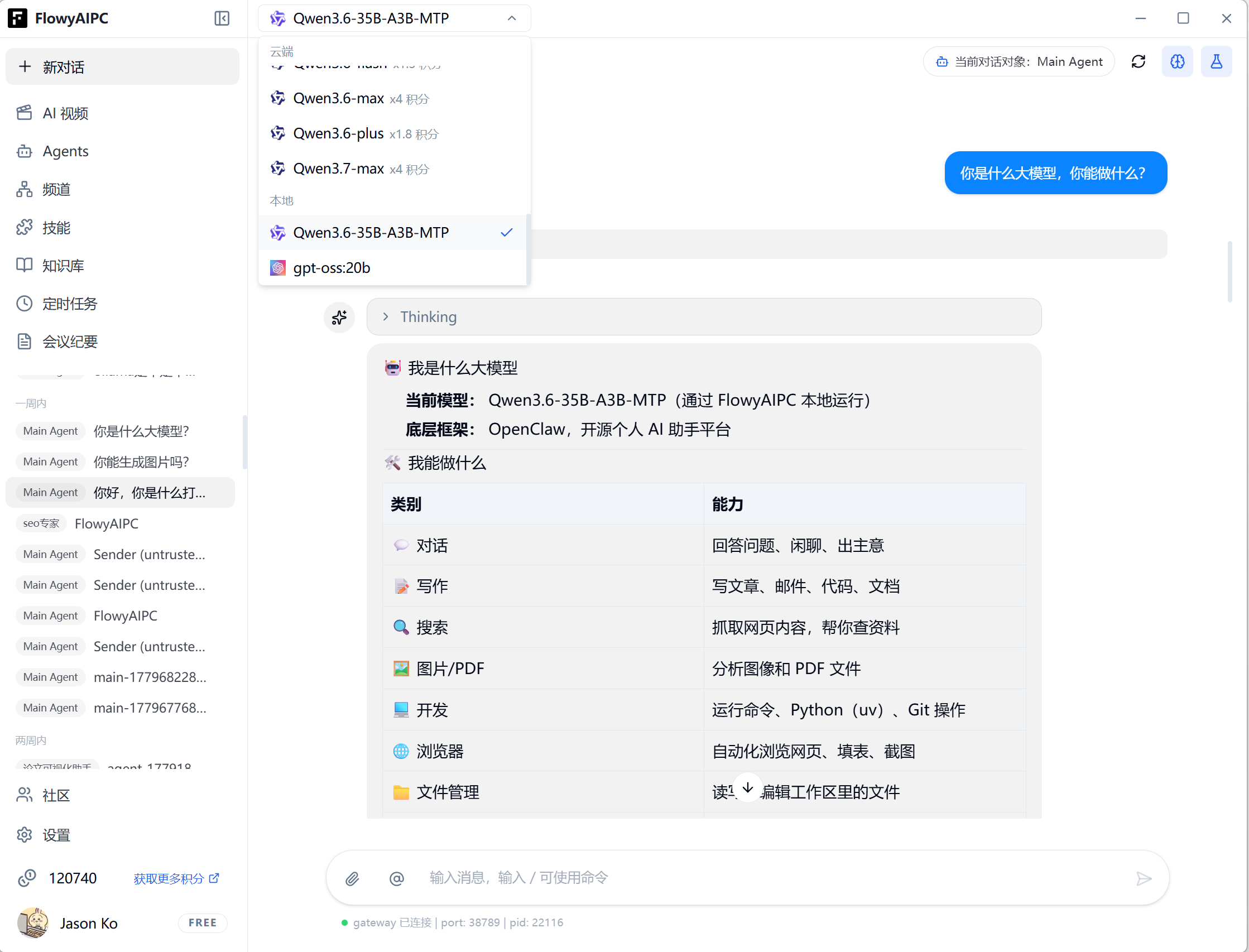
六、跑本地模型的主流工具,怎么选?
搞懂了模型名,也知道自己电脑能跑啥了,那用什么工具来跑呢?目前最主流的三剑客:Ollama、LM Studio 和牧马人 Herdsman。
🐪 Ollama
装机量最大,简单粗暴
- ✅ 一行命令 ollama run llama3 就搞定,零配置
- ✅ 社区模型超级多,开箱即用
- ✅ 生态最好,周边工具(Open WebUI、Continue 等)无缝对接
- ❌ CLI 命令行为主,小白上手有门槛
- ❌ 自定义量化参数、高级配置不太方便
- ❌ Windows 下需要 WSL2,略折腾
适合人群:开发者、喜欢命令行的、需要集成到工具链中的
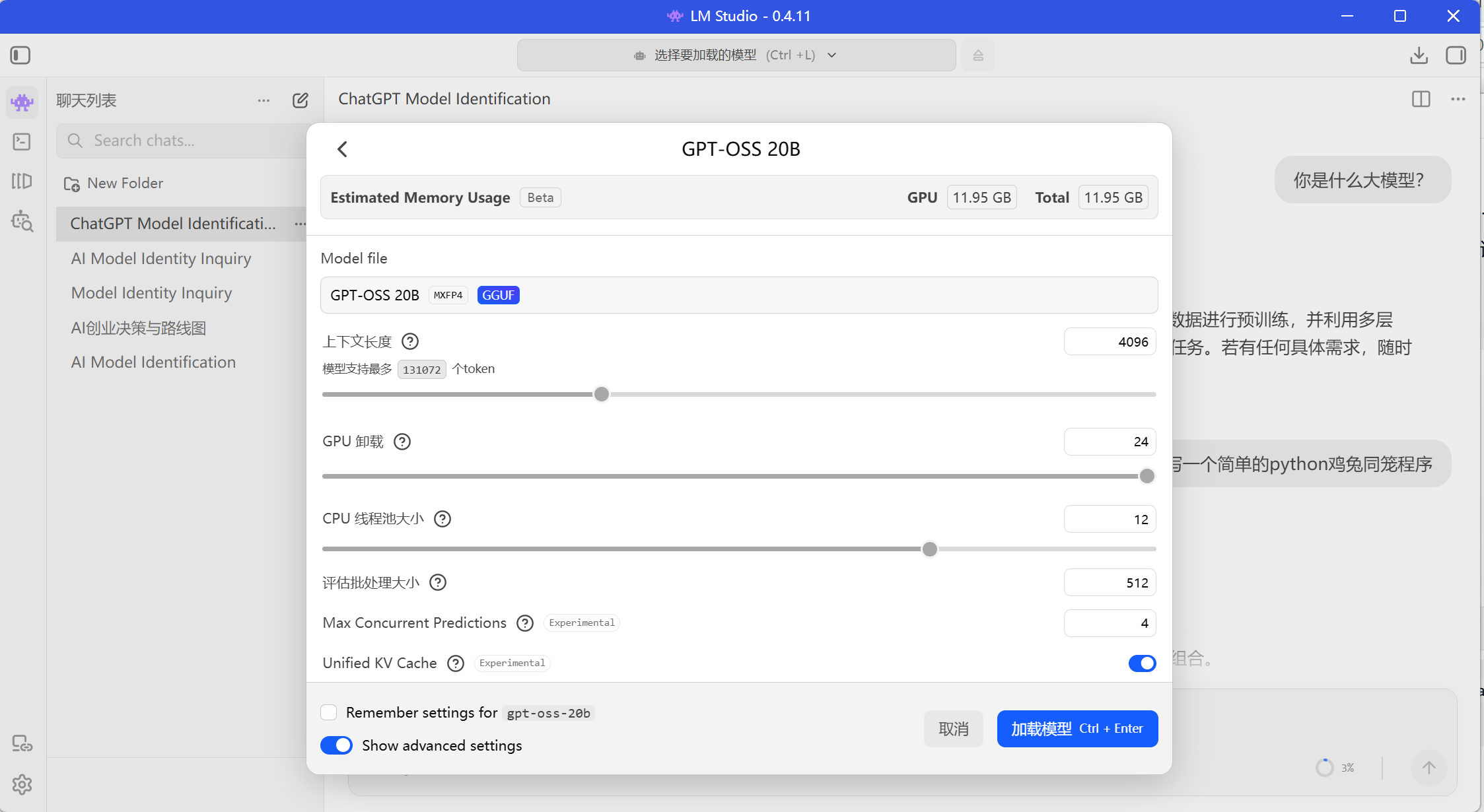
🖥️ LM Studio
图形界面最友好,颜值党首选
- ✅ 纯图形界面,下载 → 选模型 → 加载 → 聊天,完全鼠标操作
- ✅ 内置模型搜索和下载功能,不用去 HF 扒拉
- ✅ 可以自建 OpenAI 兼容的本地 API 服务
- ✅ Win/Mac 原生支持,不需要 WSL
- ❌ 高级功能不如 Ollama 灵活
- ❌ 没有命令行生态,不能脚本化批量操作
- ❌ 简体中文语言不友好,中英文结合的那种
- ❌ 大模型切换时偶尔有内存泄漏问题
适合人群:普通用户、懂英文、不想碰命令行的朋友、随手试用模型
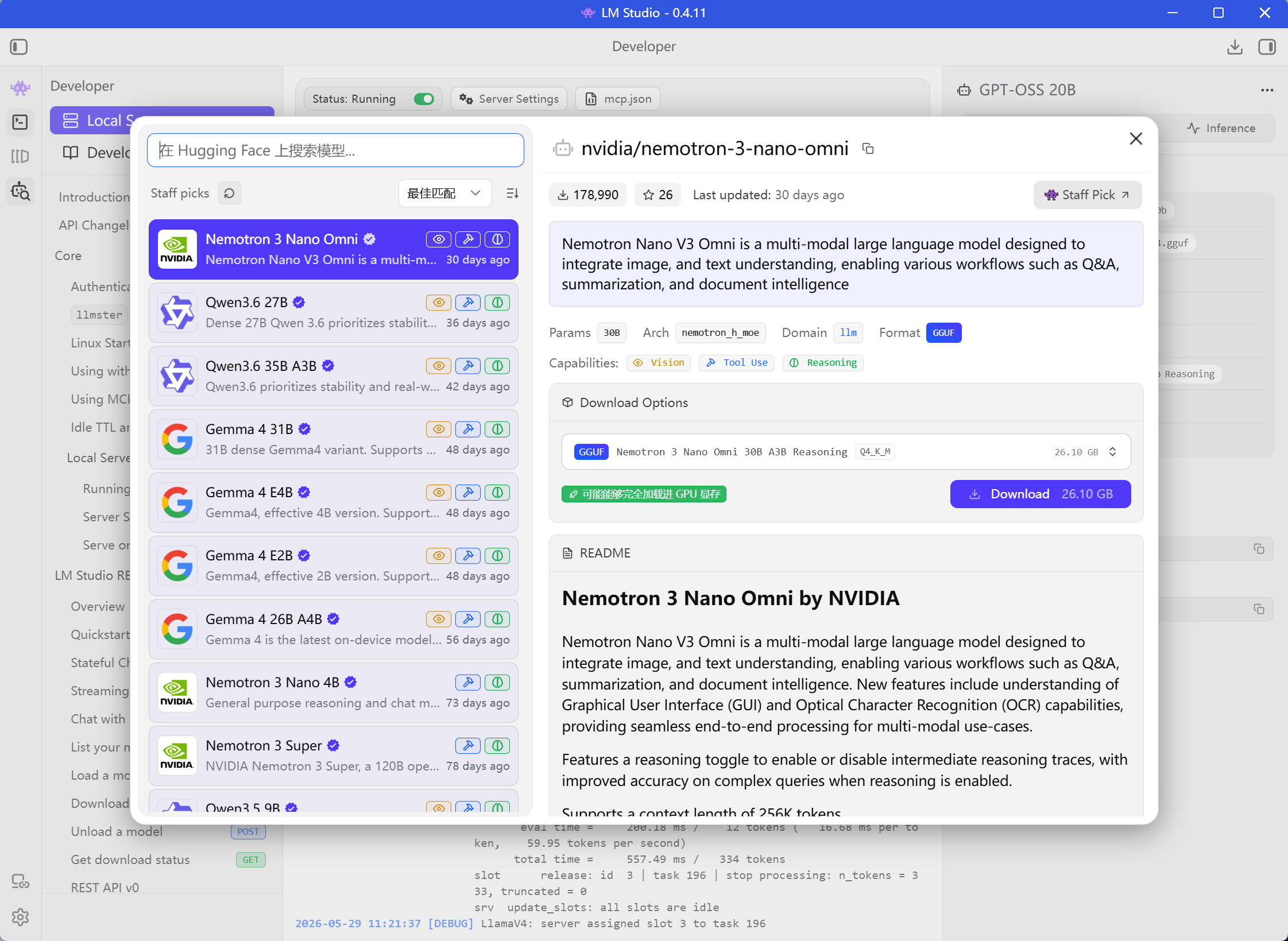
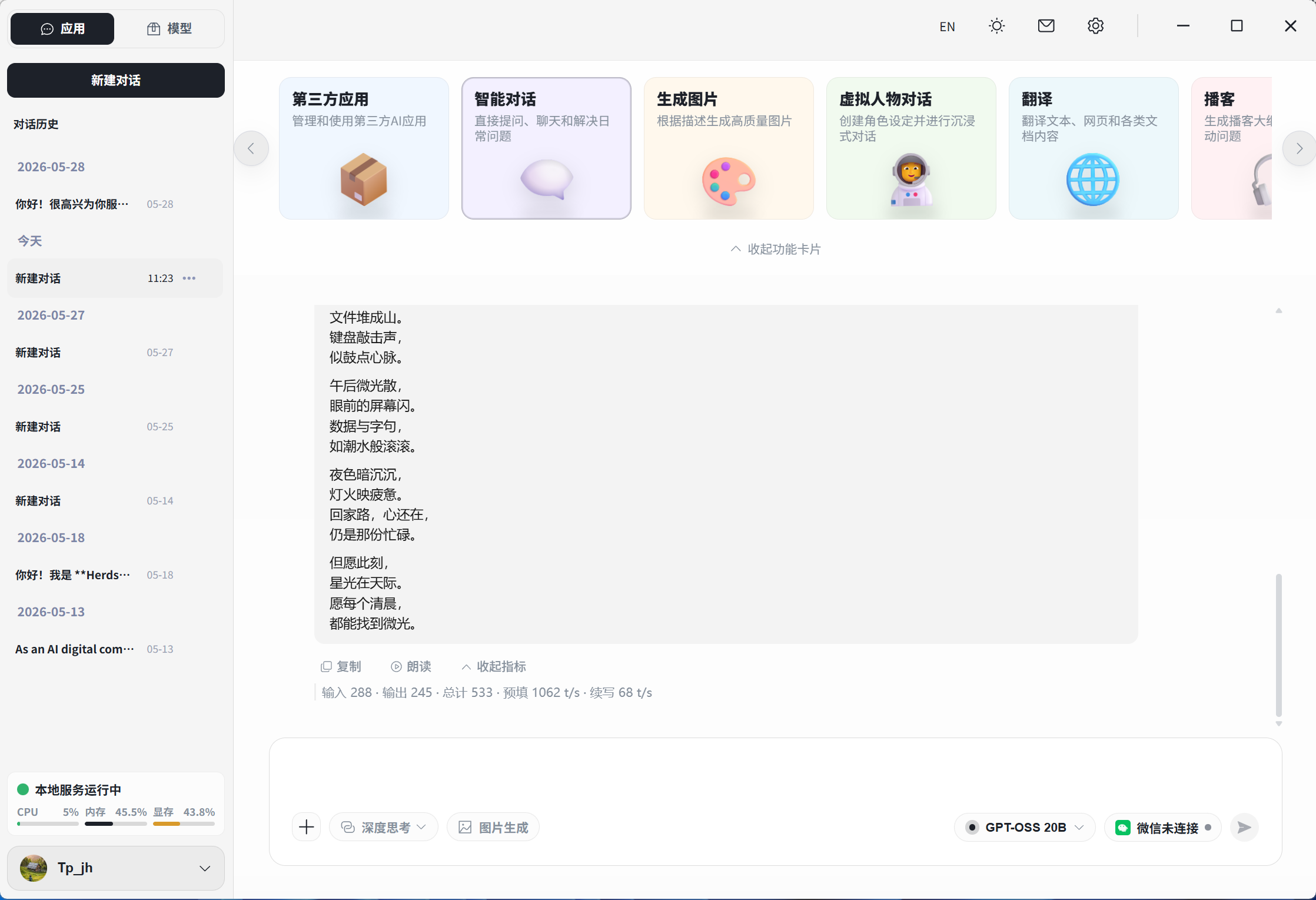
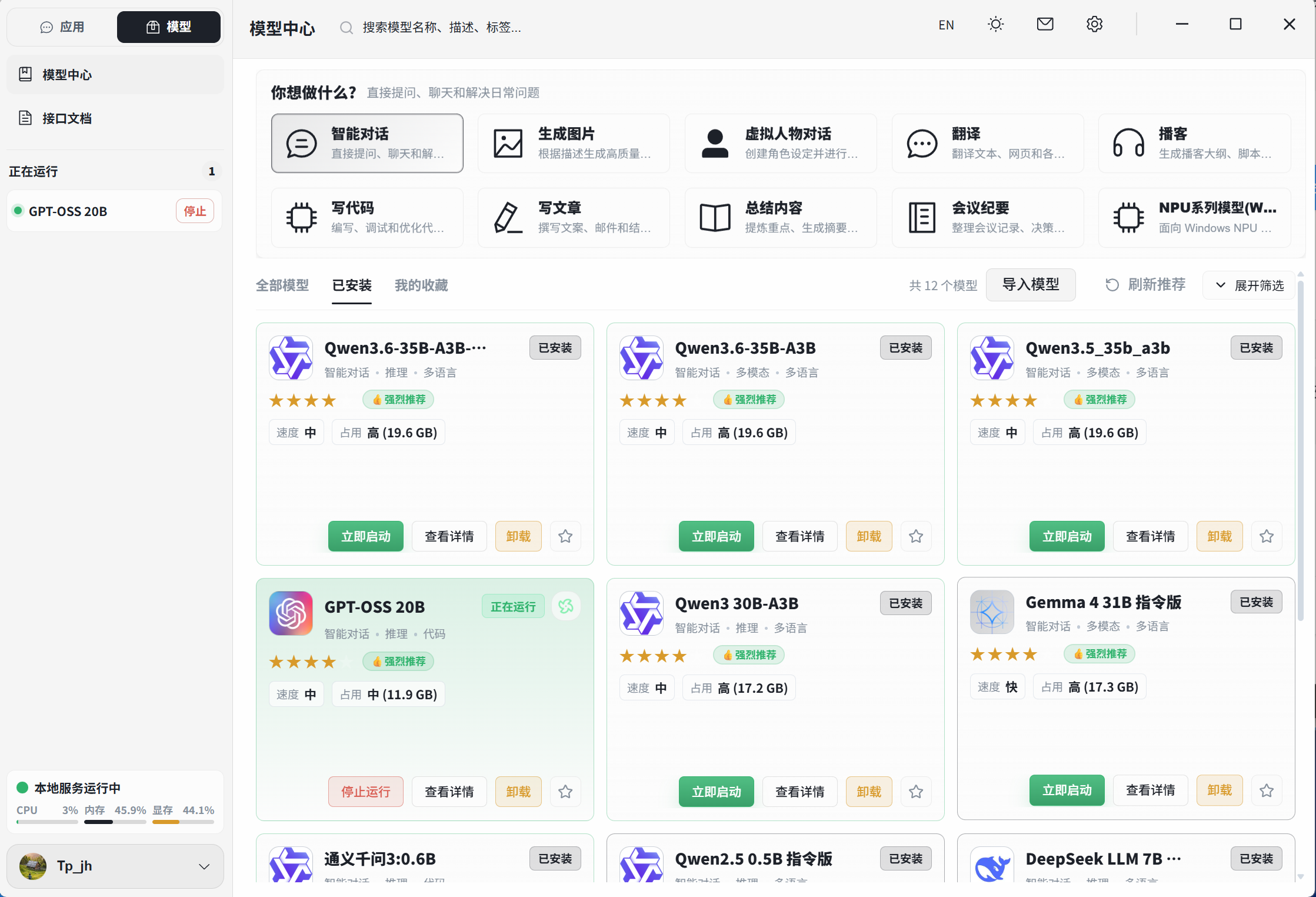
🐴 牧马人本地推理引擎 Herdsman
本土新秀,自动化调度特化
- ✅ 原生中文界面,对国内用户友好
- ✅ 智能模型推荐:根据硬件配置推荐最合适的模型
- ✅ 内置大量工具并支持FlowyAIPC一键调用
- ✅ 集成文生图、图片编辑、播客、NPU模型等,开箱可用
- ✅ 国产开发,更新快,社区响应积极
- ❌ 社区生态不如 Ollama 丰富
- ❌ 模型数量还在持续增加中
- ❌ 偏 Agent / Workflow 方向,只想纯聊天可能觉得功能太重
适合人群:国内小白用户、想一站式解决(推理+Agent+RAG)、需要模型智能调度
🏆 怎么选?简单粗暴建议:
• 纯命令行、开发者、集成到项目 → Ollama/strong>
• 只看界面、聊天用 → LM Studio
• 小白入门、办公用,需要中文生态、Agent 工作流、模型自动调度 → 牧马人 Herdsman
总结:给你的模型「算命口诀」
最后来点好记的,以后看到模型名快速拆解:
🧾 模型名拆解口诀:
① 看开头——什么家族的(Qwen / Llama / Gemma / DeepSeek / Phi……)
② 看中间数字——参数大小(7B / 70B / 35B-A3B / 4-E4B)
③ 看后缀——技术标注(MTP / GGUF / Instruct / Distill / FP8 / Q4_K_M)
④ 看量化标记——如果是 .gguf,看 Q 后面的数字,越小越省显存但越"笨"
看完这篇,以后再也不用对着模型名发懵了 🎯自己动手试试看:
Qwen3.6-27B-MTP-GGUF → 通义千问 × 27B × 多 Token 预测 × GGUF 量化版
Qwen3.6-35B-A3B → 通义千问 × 35B 总参数 × 每次激活 3B 的 MoE
google/gemma-4-E4B-it → Google × 第 4 代 × 激活 4B 的 MoE × 已调教可直接对话

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)