深度学习入门【完结】:【《动手学深度学习》之day6】从注意力机制开始01注意力机制 02Transformer
目录
3.1 多头注意力(multi-head attention)
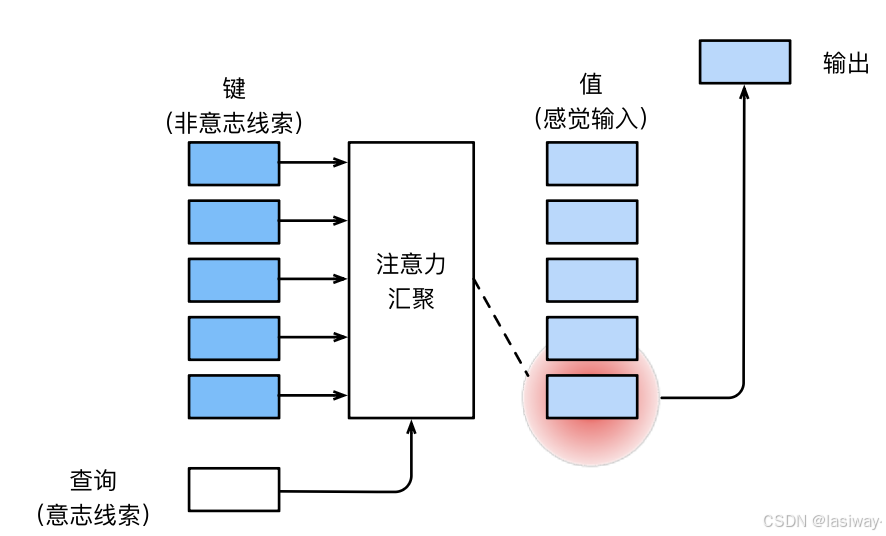
并非所有感官的输入信息都是一样的。人类从海量信息中注意到感兴趣的一小部分信息是一种选择,心理学上分为非自主性提示和自主性提示两类,来区分引导注意力的方式。那么如何用神经网络来设计注意力机制的框架?
一. 注意力机制(attention)
注意力机制与全连接层或者汇聚层的区别源于增加的自主提示。
在注意力机制中,感官输入被称为值(value),非自主性提示被称为键(key),自主性提示被称为查询(query),就是用注意力汇聚层(attention pooling)与key进行匹配,引导出最匹配的value(感官输入(sensory inputs))。
ps*:注意力机制的设计有许多替代方案。 例如可以设计一个不可微的注意力模型, 该模型可以使用强化学习方法 :cite:Mnih.Heess.Graves.ea.2014进行训练。
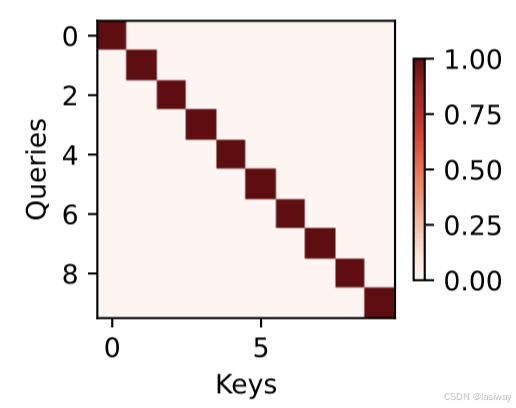
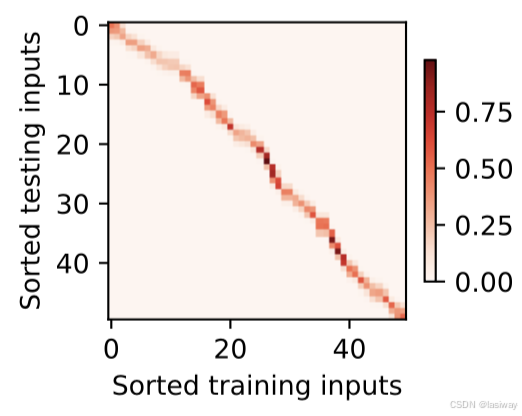
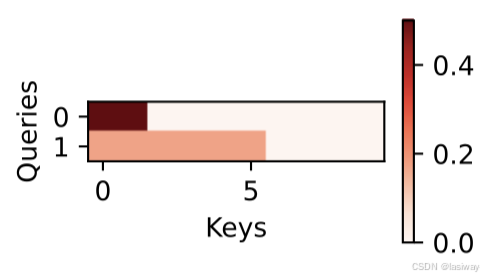
一个习惯是调用show_heatmaps函数来显示注意力权重,下图所示,仅当query=key,注意力权重=1,否则0。
1.1注意力汇聚
(1)非参注意力汇聚层 (不需要学习参数)
如,最简单的方案:平均池化。
下图用y_train 的均值预测x_test,与y_test对比。
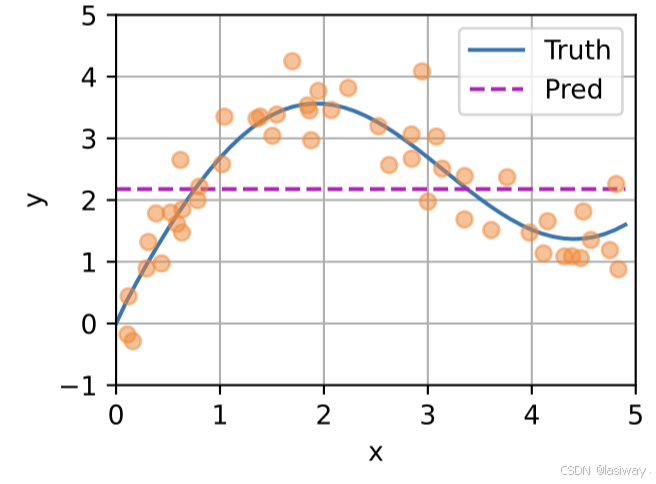
很明显平均汇聚忽略了x_test中,于是,60年代 Nadaraya-Waston核回归(Nadaraya-Watson kernel regression)提出,根据输入的位置对
进行加权,其中
是核(kernel):
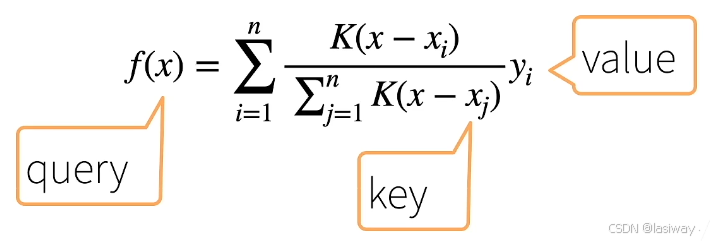
根据这个公式生成更为通用的注意力汇聚公式:
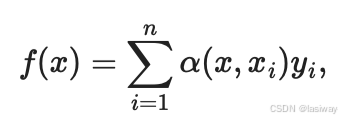
是查询,
为键值对,将查询
和
建模为注意力权重(attention weight)
,并分配给每一个对应的
值。
对于任何查询,模型在所有键值对
注意力权重都是一个有效的概率分布: 非负的,并且总和为1。
定义[高斯核](Gaussian kernel),代入上式:
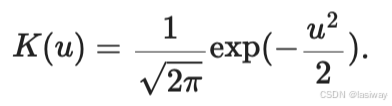
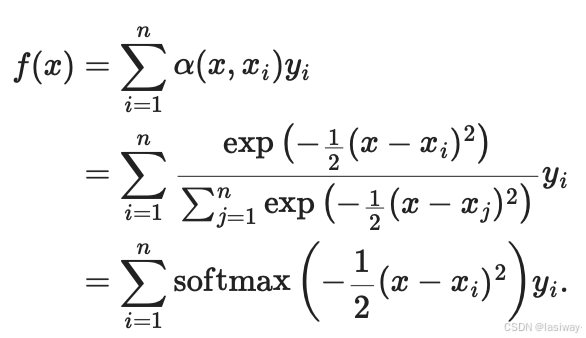
在上式中,越接近
,那么分配给这个
对应的
的权重就越大,即“获得了更多的注意力”。
用这种方法预测的结果比平均汇聚的预测更接近真实,且是平滑的。
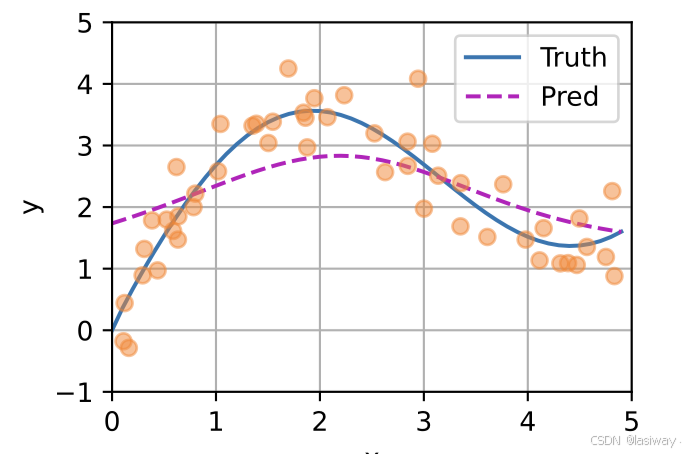
在上图中,x_test(图中黄色⭕️表示)作为query, x_train作为key,query与key越靠近,注意力权重越高。
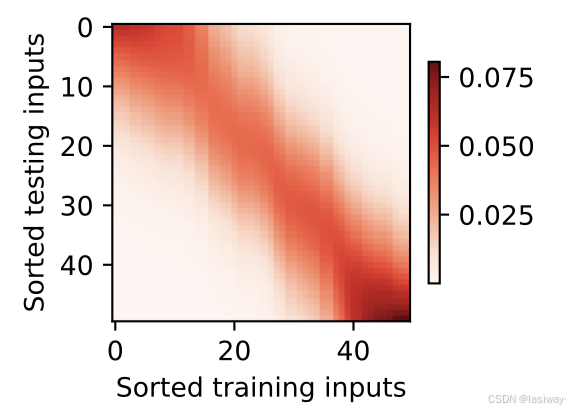
(2)带参注意力汇聚层(学习参数)
将查询与键
之间的距离乘以可学习参数
:
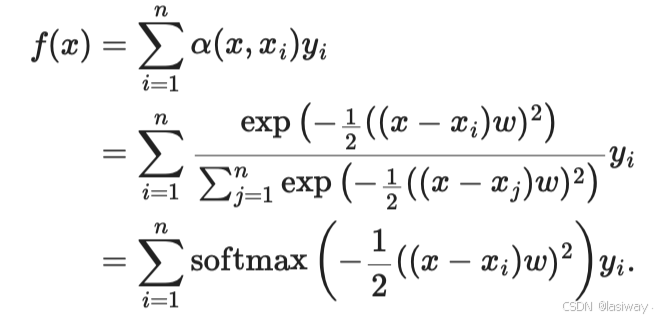
在注意力机制中,采用[批量矩阵乘法]计算小批量数据中的加权平均值。
- [批量矩阵乘法]:假设一个小批量数据包含n个矩阵
,形状为
,另一个小批量数据包含n个矩阵
,形状为
,批量矩阵乘法得到n个矩阵
,形状为
。即,假定两个张量形状分别是
和
,批量矩阵乘法输出的形状为
。
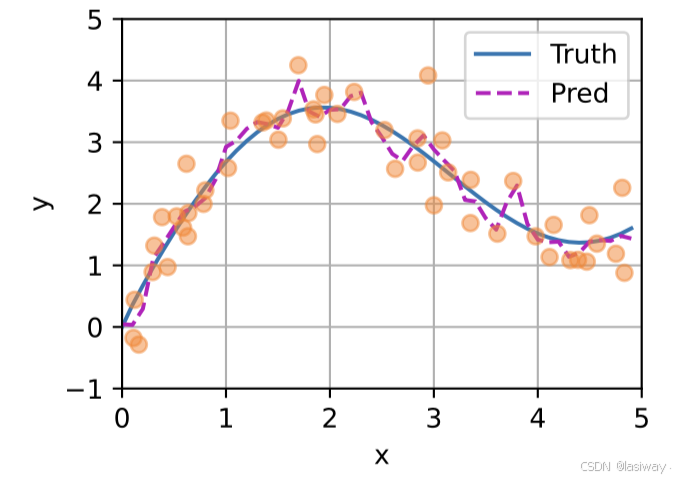
可以发现: 在尝试拟合带噪声的训练数据时, [预测结果绘制]的线不如之前非参数模型的平滑。 与非参数的注意力汇聚模型相比, 带参数的模型加入可学习的参数后, [曲线在注意力权重较大的区域变得更不平滑]。
1.2 注意力评分函数
本节将介绍两个流行的评分函数,稍后将用来实现更复杂的注意力机制。
- [注意力评分函数
]:选择不同的注意力评分函数
(1)当query和key长度不一致时,[将query和key合并,进入一个单输出单隐藏层的MLP]-[加性注意力]
(2)当query和key长度一致时,[直接将query和key做内积]-[点积注意力]
- [掩蔽softmax操作-masked_softmax]:softmax操作用于输出一个概率分布作为注意力权重。 在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。 例如,为了高效处理小批量数据集, 某些文本序列被填充了没有意义的特殊词元。 为了仅将有意义的词元作为值来获取注意力汇聚, 可以指定一个有效序列长度(即词元的个数), 以便在计算softmax时过滤掉超出指定范围的位置。
(1) [加性注意力]
![]()
![]()
![]()
(2) [缩放点积注意力]
另一种是缩放点积注意力,当查询和键具有相同的长度,实现起来简单,不需要学习参数,唯一的超参数是dropout。
假设查询和键的所有元素都是独立的随机变量, 并且都满足零均值和单位方差, 那么两个向量的点积的均值为0,方差为。 为确保无论向量长度如何, 点积的方差在不考虑向量长度的情况下仍然是1, 我们再将点积除以
, 则缩放点积注意力(scaled dot-product attention)评分函数为:
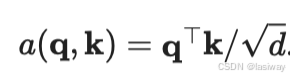
![]()
![]()
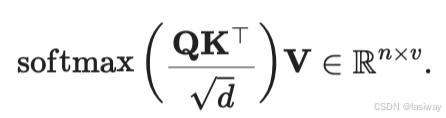
小结:不同的net,key、query的设置可以不一样。
二.加入注意力机制
回顾seq2seq:
(快捷查看深度学习入门:【《动手学深度学习》之day5】从文本序列开始01自回归 02循环神经网络RNN 03门控循环单元GRU 04长短期记忆网络LSTM 05-CSDN博客链接中第七.编码器解码器和八.seq2seq)
编码器将长度可变的输入序列转换成形状固定的上下文变量,且只用了编码器最后一个输出作为解码器的输入。
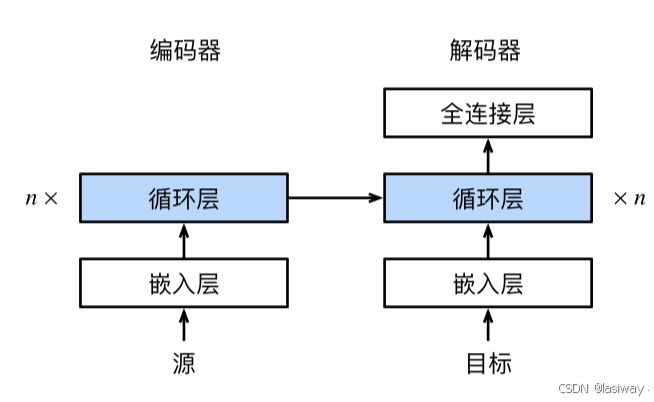
加入注意力后,变化的主要是:
上下文变量在任何解码时间步都会被替换
。 假设输入序列中有
个词元, 解码时间步
的上下文变量是注意力集中的输出 :
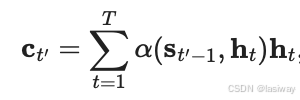
其中,时间步时的解码器隐状态
是查询(query), 编码器隐状态
既是键(key),也是值(value), 注意力权重使用加性注意力打分函数。
- 编码器对每次词的输出作为key和value
- 解码器RNN对上一个词的输出是query
- 注意力的输出和下一个词的词嵌入合并送入解码器
#[带有注意力机制解码器的基本接口]
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError2.1 将Bahdanau 注意力加入seq2seq
[Bahdanau注意力的架构]:
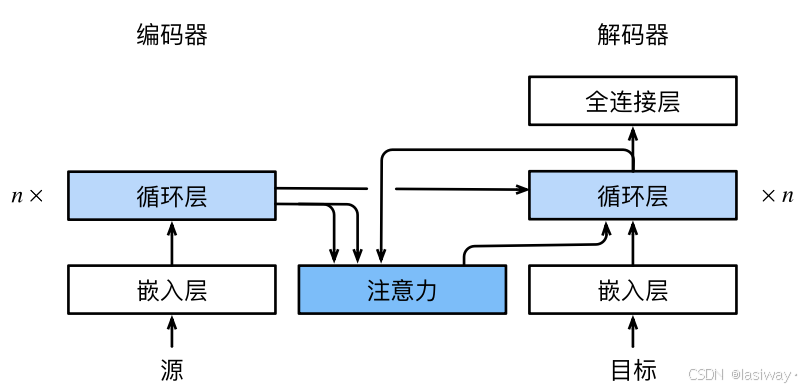
[实现带有Bahdanau注意力的循环神经网络解码器]
首先,初始化解码器的状态,需要下面的输入:
- 编码器在所有时间步的最终层隐状态,将作为注意力的键和值;
- 上一时间步的编码器全层隐状态,将作为初始化解码器的隐状态;
- 编码器有效长度(排除在注意力池中填充词元)。
在每个解码时间步骤中,解码器上一个时间步的最终层隐状态将用作查询。 因此,注意力输出和输入嵌入都连结为循环神经网络解码器的输入。
具体来说,实现代码时,修改的是class Seq2SeqDecoder(d2l.Decoder)--->class Seq2SeqAttentionDecoder(AttentionDecoder):
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder, self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(
num_hiddens, num_hiddens, num_hiddens, dropout)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(
embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
# outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,num_hiddens)
outputs, hidden_state = enc_outputs
return (outputs.permute(1, 0, 2), hidden_state, enc_valid_lens)
def forward(self, X, state):
# enc_outputs的形状为(batch_size,num_steps,num_hiddens).
# hidden_state的形状为(num_layers,batch_size,
# num_hiddens)
enc_outputs, hidden_state, enc_valid_lens = state
# 输出X的形状为(num_steps,batch_size,embed_size)
X = self.embedding(X).permute(1, 0, 2)
outputs, self._attention_weights = [], []
for x in X:
# query的形状为(batch_size,1,num_hiddens)
query = torch.unsqueeze(hidden_state[-1], dim=1)
# context的形状为(batch_size,1,num_hiddens)
context = self.attention(
query, enc_outputs, enc_outputs, enc_valid_lens)
# 在特征维度上连结
x = torch.cat((context, torch.unsqueeze(x, dim=1)), dim=-1)
# 将x变形为(1,batch_size,embed_size+num_hiddens)
out, hidden_state = self.rnn(x.permute(1, 0, 2), hidden_state)
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 全连接层变换后,outputs的形状为
# (num_steps,batch_size,vocab_size)
outputs = self.dense(torch.cat(outputs, dim=0))
return outputs.permute(1, 0, 2), [enc_outputs, hidden_state,
enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weightsseq2seq结果:
loss 0.019, 3138.2 tokens/sec on mps
go . => va <unk> !, bleu 0.000
i lost . => j'ai perdu emporté ., bleu 0.658
he's calm . => il est bon ., bleu 0.658
i'm home . => je suis ici ici !, bleu 0.447
加入注意力机制后,attention s2s结果,可以看到效果确实有进步:
loss 0.019, 1831.8 tokens/sec on mps
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est bon ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
2.2自注意力(self-attention)
每个查询都会关注所有的键-值对并生成一个注意力输出。 由于查询、键和值来自同一组输入,因此被称为 自注意力(self-attention)。
[论文出处]:Lin.Feng.Santos.ea.2017,Vaswani.Shazeer.Parmar.ea.2017
比较了卷积神经网络(CNN)、循环神经网络(RNN)和自注意力(self-attention)。值得注意的是,自注意力同时具有并行计算和最短的最大路径长度这两个优势。因此,使用自注意力来设计深度架构是很有吸引力的。
2.3位置编码
在处理词元序列时,循环神经网络是逐个的重复地处理词元的, 而自注意力则因为并行计算而放弃了顺序操作。注意力机制(如 Transformer)本身不关心序列中元素的顺序,它只看每个元素之间的相对关系(通过 query、key、value 计算)。但在自然语言处理、时间序列等任务中,顺序信息非常重要。
位置编码(Positional Encoding)就是为了让模型“知道”每个元素在序列中的位置。位置编码会生成一个和输入特征同维度的向量,加到每个输入的特征向量上,这样每个位置的输入都带有唯一的“位置信息”。这样,注意力机制在处理时,既能看到内容信息,也能看到顺序信息。
位置编码可以通过学习得到也可以直接固定得到。 接下来描述的是基于正弦函数和余弦函数的固定位置编码 :cite:Vaswani.Shazeer.Parmar.ea.2017。
位置编码的常见方式:
- 正弦-余弦位置编码(Transformer原论文):用不同频率的正弦和余弦函数编码每个位置。
- 可学习的位置编码:把每个位置当成一个参数,和词向量一样训练。
三. Transformer
Transformer是编码器-解码器架构的一个实例,其整体架构图:
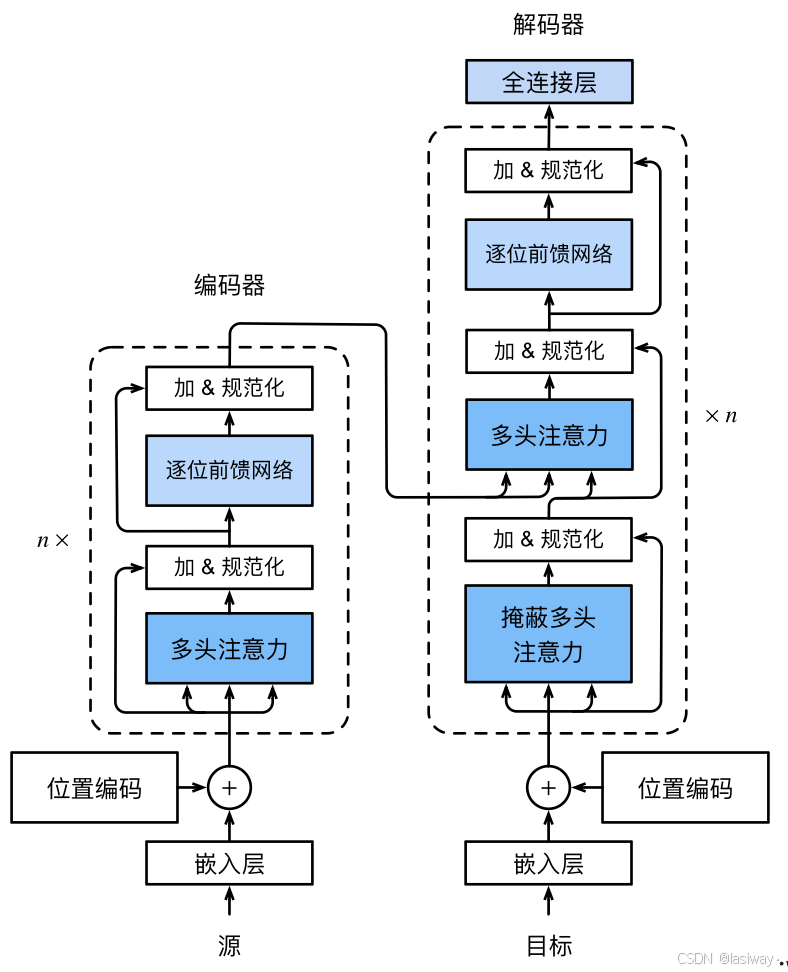
Transformer模型纯基于自注意力机制的架构,没有任何卷积层或循环神经网络层。
尽管Transformer最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语言、视觉、语音和强化学习领域。
3.1 多头注意力(multi-head attention)
当给定相同的查询、键和值的集合时, 我们希望模型可以基于相同的注意力机制学习到不同的行为, 然后将不同的行为作为知识组合起来, 捕获序列内各种范围的依赖关系 (例如,短距离依赖和长距离依赖关系)。 因此,允许注意力机制组合使用查询、键和值的不同 子空间表示(representation subspaces)可能是有益的。
与其只使用单独一个注意力汇聚, 我们可以用独立学习得到的组不同的线性投影(linear projections)来变换查询、键和值。 然后,这组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这
个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 对于
个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。这种设计被称为多头注意力(multihead attention) 。
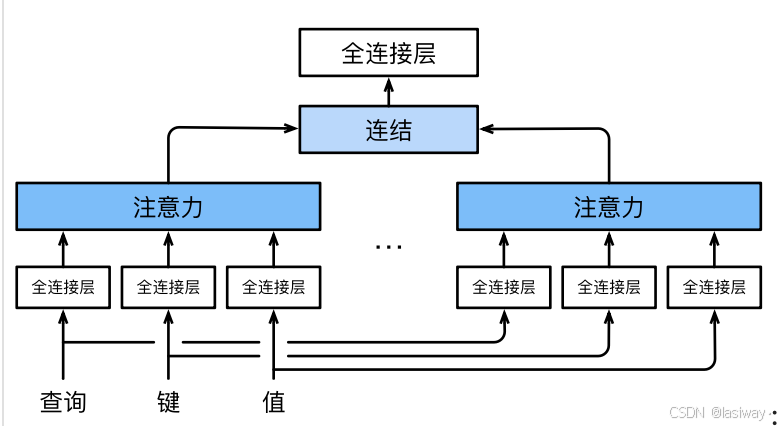
3.2基于位置的前馈网络
就是一个全连接层
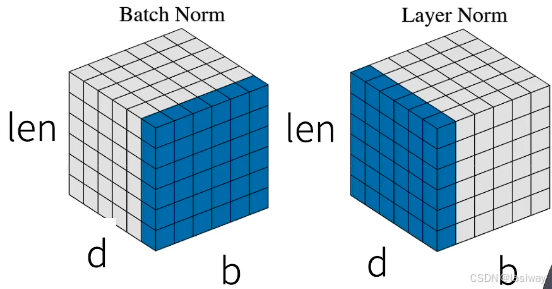
3.3层规范化(LayerNorm)
对比BN,不会受序列长度变化影响。还记得讲BN时说到,有很多N的方式。
- 批量归一化对每个特征/通道里元素进行归一
- 层归一化对每个样本里的元素进行归
Transformer在编码器和解码器之间信息传递时,用的是一个正常的attentino,不是自注意力。编码器和解码器都有n个Transformer。
接下去就可以去看Transformer代码是怎么组合的了。数据用的seq2seq。此处代码略。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 36
36 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)