MoE+时序还能做什么:从Moirai-MoE论文里挖出六个方向
一、先说个反直觉的结果
一个只激活1100万参数的小模型,在39个数据集上全面打败了一个3.1亿参数的大模型。
你第一反应是不是觉得我在吹牛?
但这结果是真实的,发在ICML 2025上,作者是Salesforce AI Research。就是做CRM的那个Salesforce,他们家AI团队这几年在时序领域基本是降维打击。
论文叫Moirai-MoE。核心就一件事:把NLP里很火的稀疏专家混合(MoE)搬到了时间序列基础模型上。
结果就是:只用1/28的激活参数,精度更高、推理更快。这不是魔法,是架构设计的胜利。
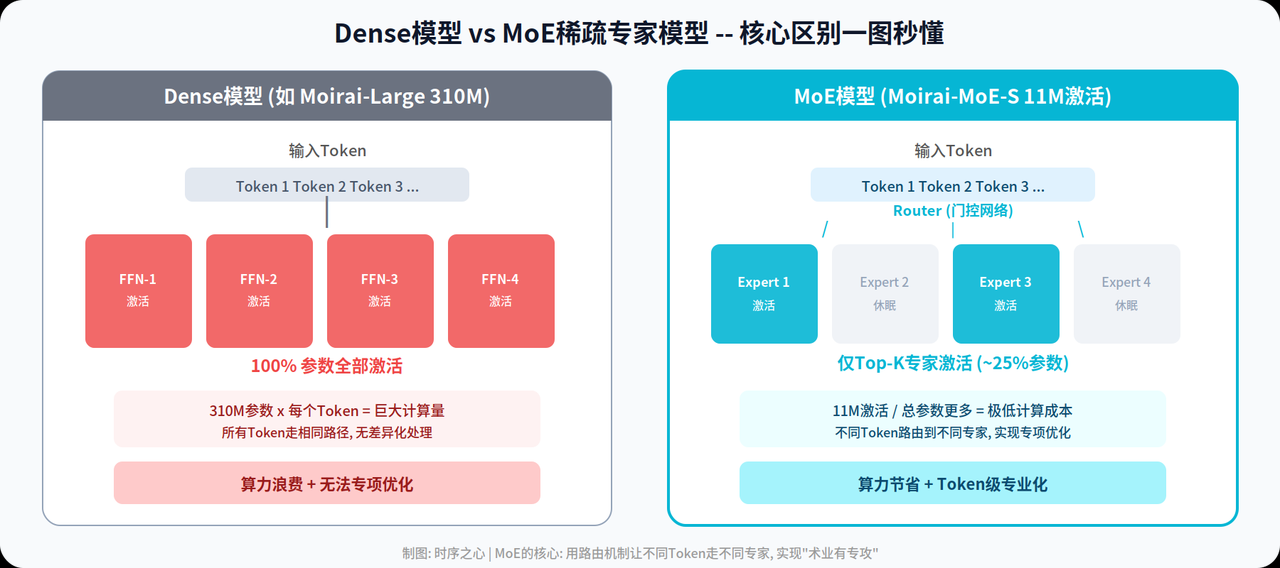
图1: Dense模型 vs MoE稀疏专家模型核心区别
另外我整理了时序MoE资料包,包含:核心概念速查、时序适配原理、负载均衡细节与8个可复现论文选题模板,感兴趣的dd,希望能帮到你!具体资料内容如下:
Moirai-MoE论文逐节精读笔记(含公式推导)
MoE核心概念速查手册(门控函数、负载均衡、Top-K选择)
Moirai-MoE完整复现代码+Monash Benchmark评测脚本
6个MoE+时序方向的论文选题模板(附标题+story+目标期刊)
MoE领域必读论文清单(从Switch Transformer到Moirai-MoE,共15篇)
二、先搞懂MoE是啥
传统的Transformer,每一层都有一个全连接前馈网络(FFN)。不管输入什么token,所有参数都得全跑一遍。
这就像公司里所有人干所有活——财务的去搬砖,搬砖的去做财务。效率极低。
MoE的思路很简单:把一个大FFN拆成N个小“专家”网络,再加一个路由器。每个token只去找最合适的Top-K个专家处理。
在公司里就是:财务问题找财务专家,技术问题找技术专家。效率暴增。
Moirai-MoE的具体配置:32个专家,每个token选Top-2。每次前向传播只激活大概6%的专家参数。
这就是“11M激活参数”的秘密——总参数远不止11M,但每次推理只用11M。
关键概念:Token级专业化
之前的Moirai怎么做的?按频率分组:低频数据走低频层,高频数据走高频层。这是人工定义的启发式方法。问题在哪?
-
第一,频率不是可靠的分组指标。两条同频率的时间序列可能模式完全不同。
-
第二,同一条序列内部也不同。趋势段和周期段显然不一样。
Moirai-MoE的解法:不做人工分组,让模型自己学。每个token(时间序列的一个patch段)由路由器动态决定送给哪个专家。
同一条序列里,趋势段可能去专家1,周期段去专家17,突变段去专家5。这才是真正的因材施教。
三、Moirai-MoE的三大架构升级
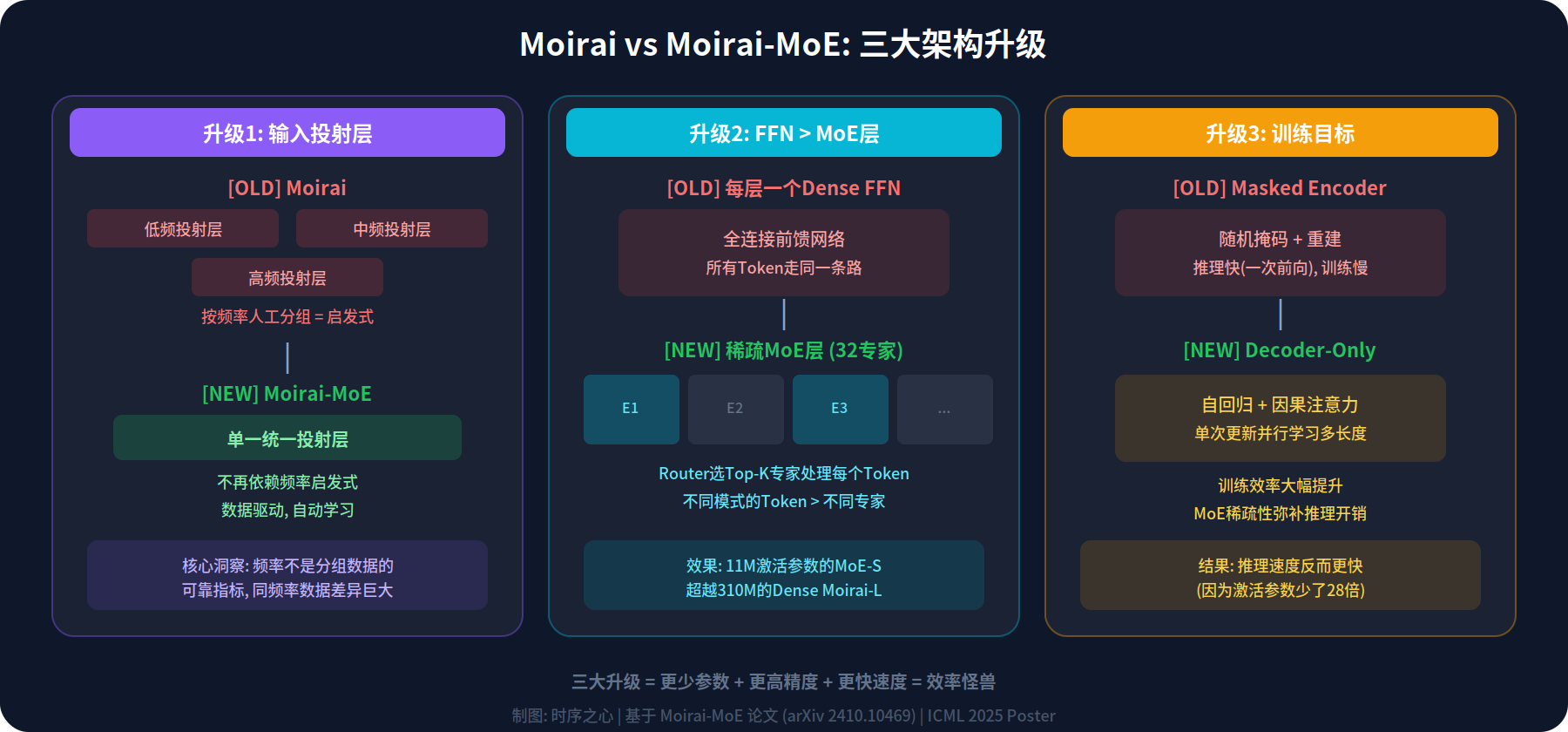
图2: Moirai vs Moirai-MoE三大架构升级详解
升级1:单一投射层替代多频率投射层
原版Moirai为不同频率设计了多个输入输出投射层。问题是用频率分组太粗糙了。
Moirai-MoE直接砍掉多投射层,换成统一投射层。所有频率走同一个入口,真正的差异化交给MoE层的专家去做。
升级2:FFN换成MoE层
这是最核心的改动。每个Transformer层里的FFN被换成MoE层,包含32个专家和一个路由器。
路由器为每个token算一个32维得分,选得分最高的Top-K个专家处理。
论文还提了一个新门控函数:用预训练模型的聚类中心来初始化路由器,不是随机初始化。这让路由器一开始就知道不同模式的token长啥样,训练收敛快很多。
升级3:Masked Encoder改成Decoder-Only
原版用Masked Encoder训练(随机遮掩patch让模型重建)。Moirai-MoE改成Decoder-Only,自回归训练,跟GPT一个思路。
为啥?因为Decoder-Only能在单次更新里并行学多种上下文长度,训练效率大幅提升。
推理时虽然需要自回归,但因为MoE层只激活少量参数,实际速度反而比Dense的Moirai更快。
四、硬核数据:11M怎么碾压310M的
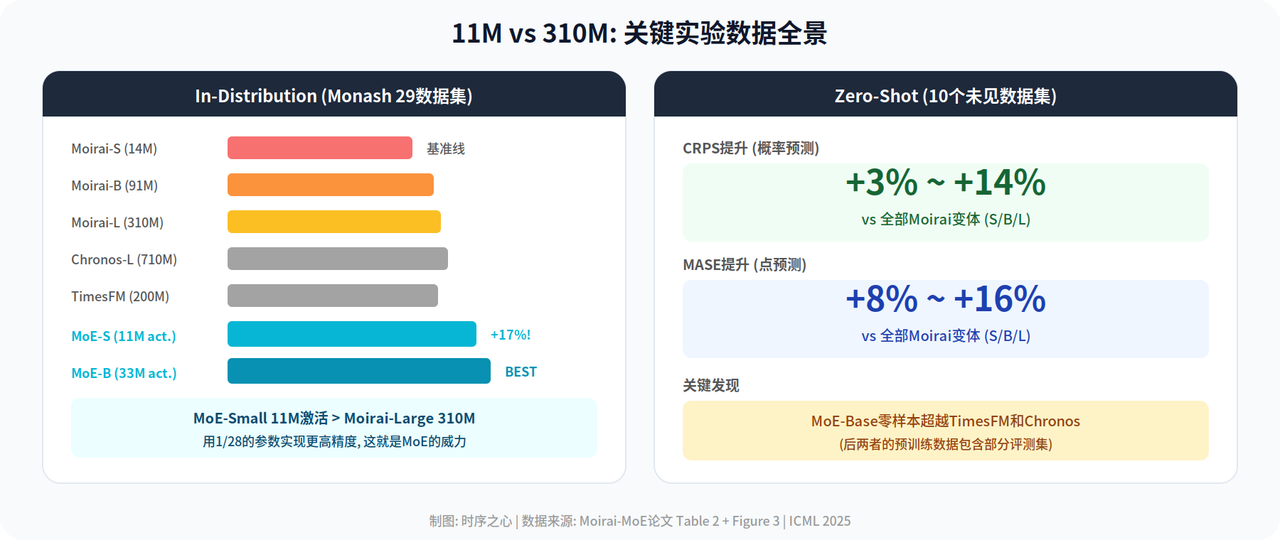
图3: 11M vs 310M关键实验数据全景
4.1 分布内测试:Monash 29个数据集
Moirai-MoE-Small精度比同参数量的Moirai-Small高了17%。
更狠的是,它甚至超过了Moirai-Base(+8%)和Moirai-Large(+7%),后两者的参数分别是它的6.5倍和22倍。
Moirai-MoE还打败了Chronos全系列和TimesFM。
4.2 零样本测试:10个没见过的数据集
这是更硬的验证。在这10个完全不在预训练数据里的数据集上:
CRPS提升3%-14%(概率预测指标,越低越好)
MASE提升8%-16%(点预测指标,越低越好)
Moirai-MoE-Base拿到了全场最佳零样本性能,甚至超过了TimesFM和Chronos——后两者的预训练数据里可是包含部分评测集的。
4.3 消融实验的三个发现
发现1:单独改训练目标(Masked改Decoder-Only)只带来“小幅提升”。主要增益来自MoE层。说明MoE不是锦上添花,是核心来源。
发现2:用聚类中心初始化门控函数优于随机初始化,收敛更快、精度更高。
发现3:Patch size=16是最优选择。跟PatchTST的发现一致——时序patch化有一个最佳值。
五、最有趣的发现:专家到底学了啥
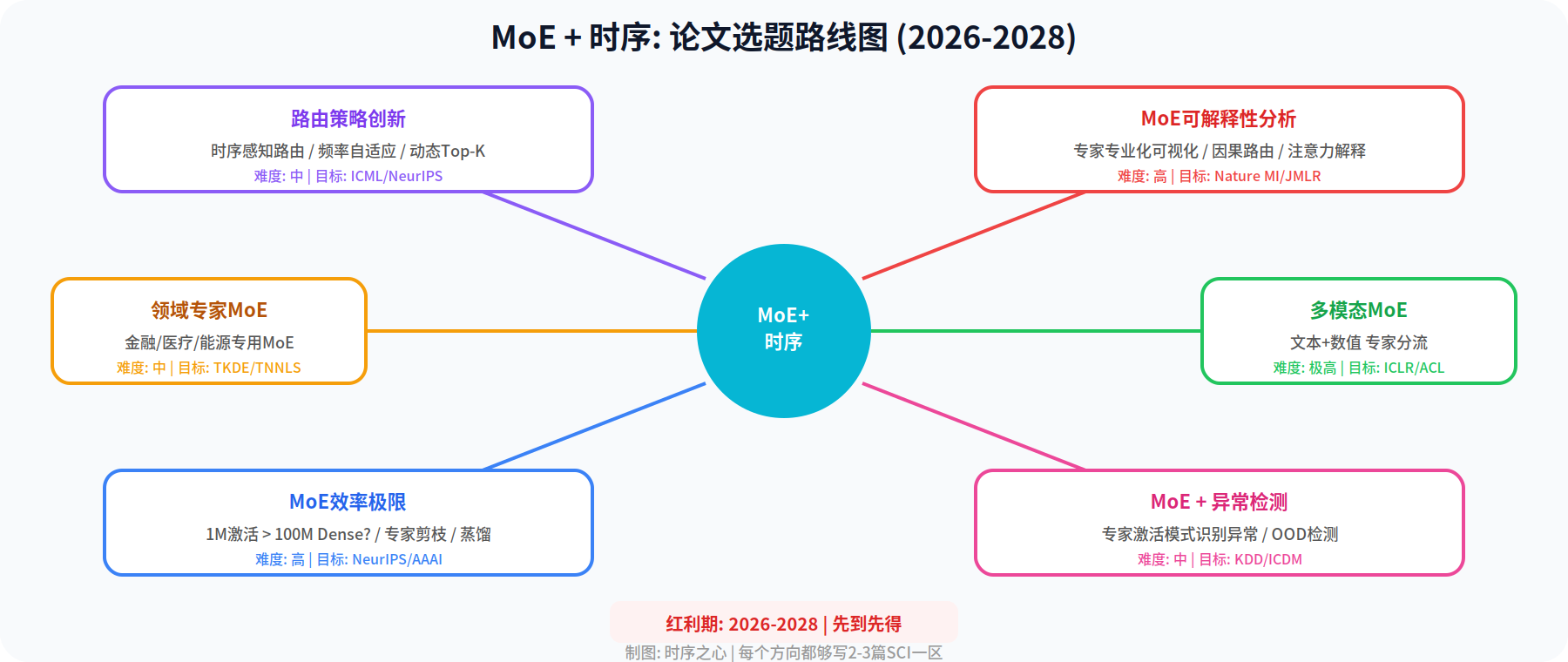
图4: MoE+时序论文选题路线图(2026-2028)
论文里我最兴奋的部分,是专家分配模式的可视化分析。
现象1:浅层专家更专业,深层专家更泛化。 第2层,不同token被清晰分给不同专家。第6层(最后一层),分配更均匀。像是“先分后合”——浅层做模式识别和分类,深层做整合和输出。
现象2:相似模式的token被分给同一个专家。 同一个数据集里,模式相近的token倾向于走同一个专家。说明MoE确实在做模式级别的专业化。
现象3:时间位置也影响路由。 序列开头和结尾的token去了不同专家。说明模型学会了区分“历史模式建模”和“未来预测生成”两种任务。
六、实操:怎么用Moirai-MoE
代码在Salesforce的uni2ts仓库里,已经开源。
from uni2ts.model.moirai_moe import (
MoiraiMoEForecast,
MoiraiMoEModule
)
from gluonts.dataset.pandas import PandasDataset
# 加载模型
module = MoiraiMoEModule.from_pretrained(
"Salesforce/moirai-moe-1.0-R-small"
)
# 构建预测器
predictor = MoiraiMoEForecast(
module=module,
prediction_length=30,
context_length=512,
patch_size=16,
num_samples=100
)
# 推理
dataset = PandasDataset.from_long_dataframe(
dataframe=df,
target="value",
item_id="series_id"
)
forecasts = list(predictor.predict(dataset))
如果你要做MoE相关的论文,重点看仓库里的两个文件:
-
router.py:专家路由逻辑 -
moe_layer.py:MoE层实现
改路由策略、设计新专家机制、复现实验,都从这俩文件入手。
声明:本文观点仅代表个人学术见解。数据来源:Moirai-MoE论文(arXiv 2410.10469)及Salesforce AI Research官方博客。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 3
3 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)