数据比模型更值钱,国内最大的「端侧」训练数据开源了!600B 预训练+千万级 SFT 核心数据配方公开
最近 MiniCPM5-1B 这个模型很火,是一款端侧模型,参数量只有 1B。
端侧模型出货量最大的就是阿里 Qwen 了,还有 Google Gemma 和微软 Phi ,都是端侧模型玩家。这几天不少家人们都刷到了面壁智能的 MiniCPM5-1B ,用 1B 参数干出了 2B 的效果。
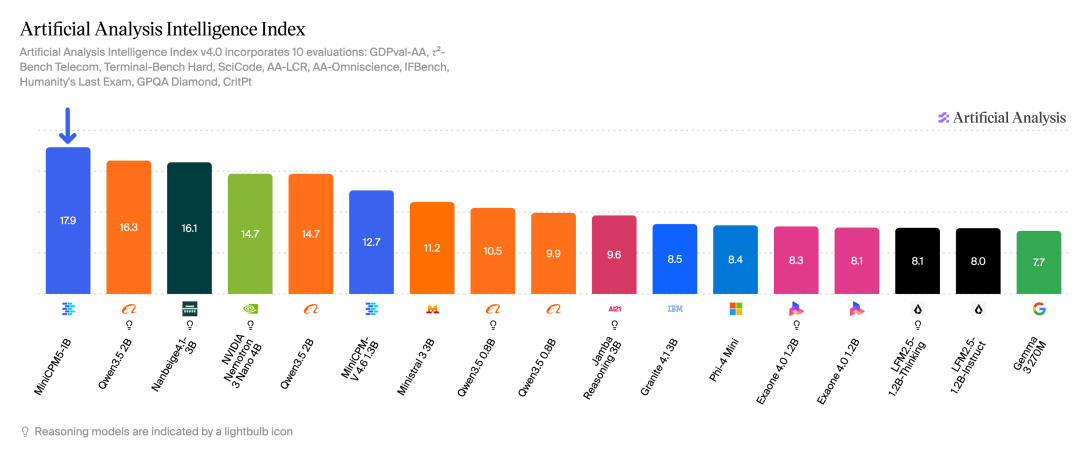
这个模型在 Artificial Analysis-Index 上成绩是 17.9 分,把 2B 级的 Qwen3.5-2B(16.3)和一众同级对手都比下去了,而且 INT4 量化后权重只有 0.5GB 。
我看到很多人都在分析:它到底为什么这么强?
有人说是训练框架牛(ForgeTrain),AI 自己写代码训练自己,也有人讨论是端侧优化技术做得好,仅 0.5GB 就能跑起来。
但是,没有人聊过另一个因素——数据。
我反而觉得,数据才是小模型逆袭的关键。
因为到 1B 这个体量,模型的容噪能力几乎是零,数据多了没用,数据脏了反有大毒。
我去搜了下 MiniCPM5-1B 的数据,发现面壁智能刚刚把背后的核心数据集给开源了。
一共是两份 L3 级数据集:
-
Ultra-FineWeb-L3 :600B tokens,中英文都有,是目前最大的中文开源合成预训练数据集。
-
UltraData-SFT-2605 :千万级的后训练核心数据,覆盖数学/代码/知识/指令,同时覆盖深思考和非思考。
UltraData 网站:
https://ultradata.openbmb.cn
HuggingFace 主页:
https://huggingface.co/collections/openbmb/ultradata
Ultra-FineWeb-L3:
https://huggingface.co/datasets/openbmb/Ultra-FineWeb-L3
UltraData-SFT-2605:
https://huggingface.co/datasets/openbmb/UltraData-SFT-2605
好多人不了解什么是 L3 级。所以开始前,有必要先了解下 UltraData 数据治理的分级体系。
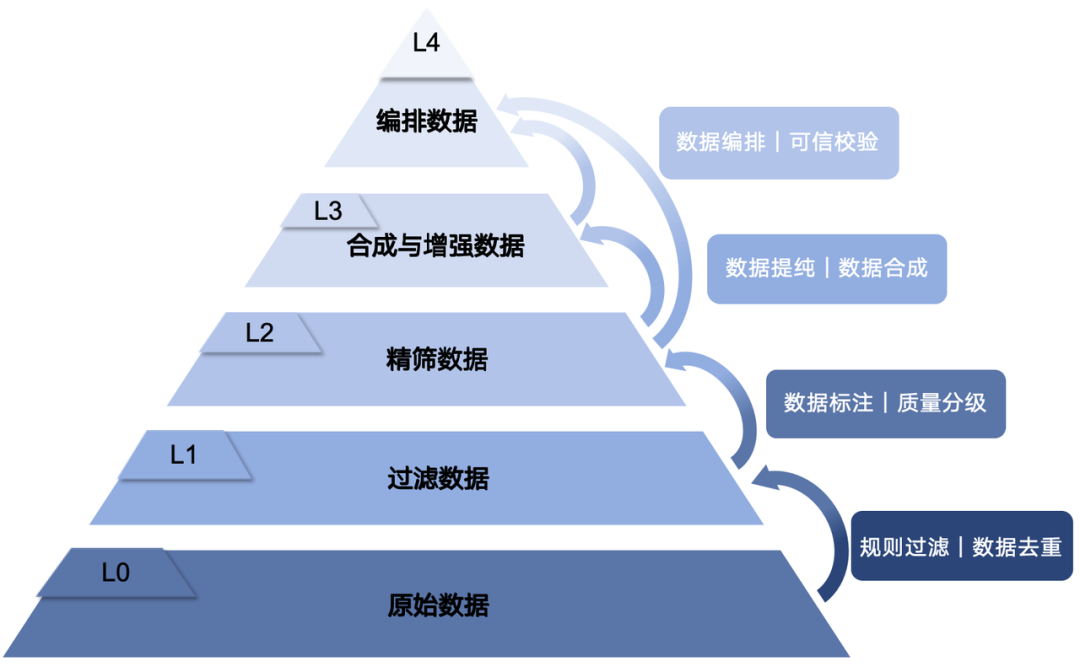
L0 是从网上扒下来的生肉网页,L1 做基础清洗去重,L2 用模型打分后挑出来好的数据。
到这一级为止,都还是在筛选数据的阶段,从 L3性质开始变了。
L3 用大模型把数据重新加工一遍,做数据合成与增强,比如把一篇普通网页改写加工成问答对、百科文档等多种形式,都是高质量形态。
这一层对小模型来说非常关键。
因为 1B 大小的话,容噪能力几乎为零,L1、L2 中也是有很多知识,但是小模型不一定能靠自己把知识从里面提取出来。
L3 这层的做法就是把知识提纯、凝练后再喂给模型,让模型吸收的更好。
◈Ultra-FineWeb-L3 :预训练最后一程的高纯度数据
先说 Ultra-FineWeb-L3 ,用于预训练的退火阶段。
预训练分为两个阶段:稳定训练(stable training)和退火训练(decay training)。
稳定训练用大学习率跑大量数据,建立基础能力;退火阶段在训练末期把学习率快速降下来,同时换上更高质量的数据,让模型在最后阶段冲刺。
退火阶段就是模型预训练的最后一程,这时候喂什么数据对模型的最终性能影响最大—Ultra-FineWeb-L3 就是专门用在这个阶段的。
Ultra-FineWeb-L3 种子数据来自他们之前做的 Ultra-FineWeb( L2 层),总量是 600B ,英文占了 400B多,中文占 200B 多。
这 200B多的中文数据是目前全国规模最大的开源预训练合成数据集。
在这个基础上,面壁用 MiniCPM4 和 Qwen-30B-A3B 两个模型做了两件事:
(1)问答对生成
把一篇陈述性网页拆改写成【原始文本 + 多个问答对】,强迫模型理解知识的结构和关联。
(2)多风格改写
同一段内容,分别用百科、教科书、博客、摘要四种风格重新写一遍。这个思路其实不复杂,但很有效。
为了验证 L3 层数据的效果,团队做了一组对比实验:
统一用 MiniCPM-1.2B 架构,从 0 开始只训练 100B tokens,只换数据集,看最终模型性能差多少。
他们把 Ultra-FineWeb-L3 跟业界目前顶流的数据集放在一起跑,包 括 FineWeb-edu、DCLM。
-
英文赛道上 Ultra-FineWeb-en 及其 L3 版本表现最优,在训练后期直接拿到了全场最高分。
-
中文赛道差距更加明显,L3 的领先幅度随着训练推进越来越大,训练越久,L3 数据的优势越突出。
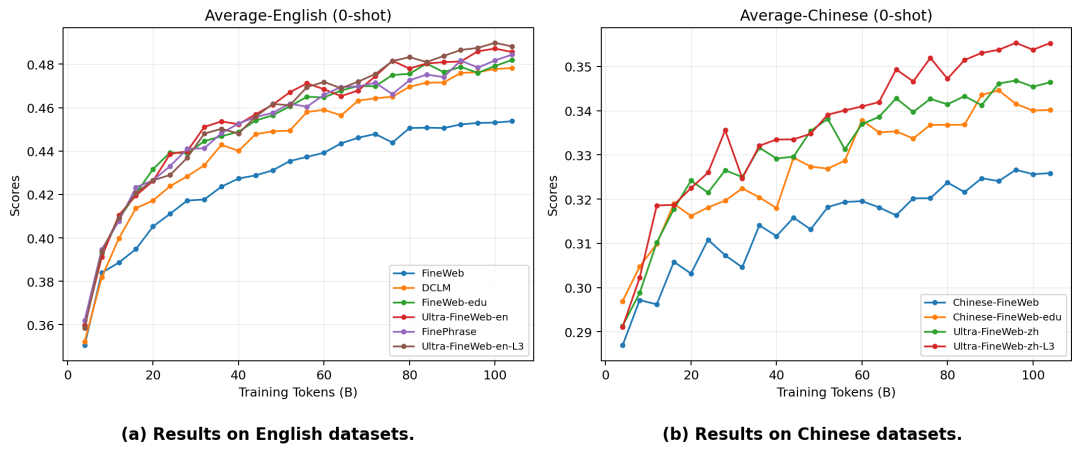
总之,L1→L2→L3 在英文和中文上都是逐级提升的。
◈UltraData-SFT-2605:国内首份同时覆盖「深思考+非思考」双模式SFT 数据
SFT 的数据一直以来都是厂里藏着掖着的宝贝。
面壁智能这次开源的 UltraData-SFT-2605 算是国内首次开源千万样本级的 SFT 训练数据,其中数据覆盖了数学、代码、知识、指令遵循等领域。
为了更好地应对现实场景,UltraData-SFT-2605 在每个领域、难度级别都分别构建了两种规格的数据:
-
非思考数据:用来应对需要快速响应的场景,强化模型的直接回答能力。
-
深思考数据:带完整推理链的,主要应对复杂任务场景,提升模型的推理、规划与验证能力。
国内之前开源的 SFT 数据,要么只有普通指令,要么只有思维链,两种模式同时覆盖而且覆盖面全的大规模混合思考 SFT 数据集,这是第一份。
而且,研究团队还发现,即便是同属于 L3 级别的数据,在问题价值、回答质量和防污染风险上也参差不齐。

因此,为了进一步确保进入最终训练的数据绝对干净且有效,研究团队又引入 SFT 数据的治理流水线:
(1)筛选:只保留意图清晰、有挑战性且覆盖面广的好数据。
(2)定制式训练:缺啥补啥,根据特定能力去定向构建,比如知识类的构建要基于考点来针对修改。
(3)喂高密度素材:引入教科书、Wiki 这些高信息密度的 L3 数据,增强知识组织和泛化能力。
(4)查逻辑:去审查深度思考数据的推理过程,确保其推理过程是能教会模型如何拆解和验证问题。
(5)试跑:用小预算(20B Tokens)+ A/B test 快速试错,用实际收益倒推出最佳数据配方。
(6)剥离测试集痕迹:确保模型提升源于真实的数据质量,而非偷偷背题。
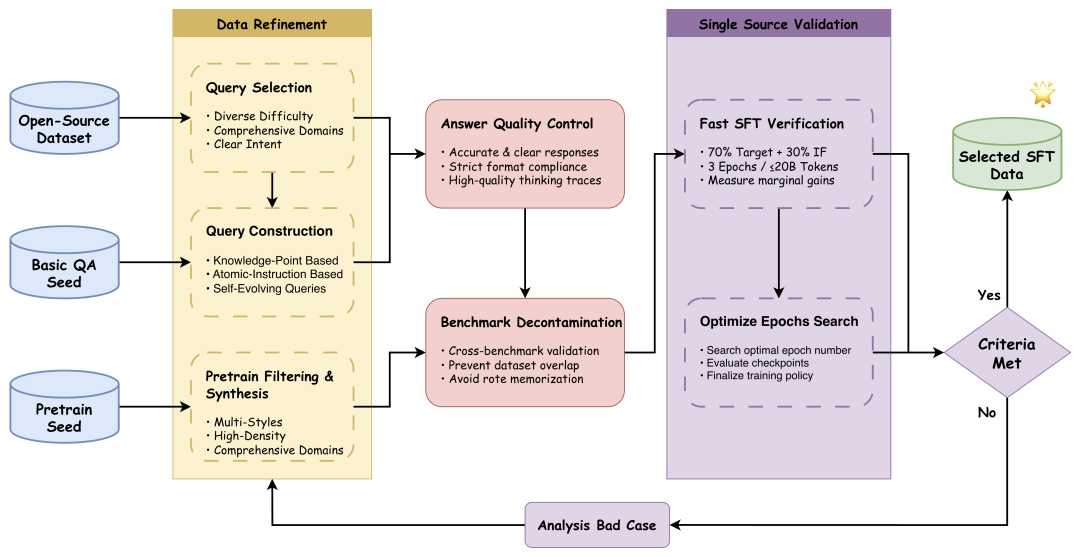
通过数据流水线的重构与提纯,UltraData-SFT-2605 彻底褪去数据中的杂质,成为高纯度的训练燃料。

◈MiniCPM5-1B 的数据怎么炼?
那么问题来了!
在 MiniCPM5-1B 的炼丹炉里到底是怎么炼数据的?
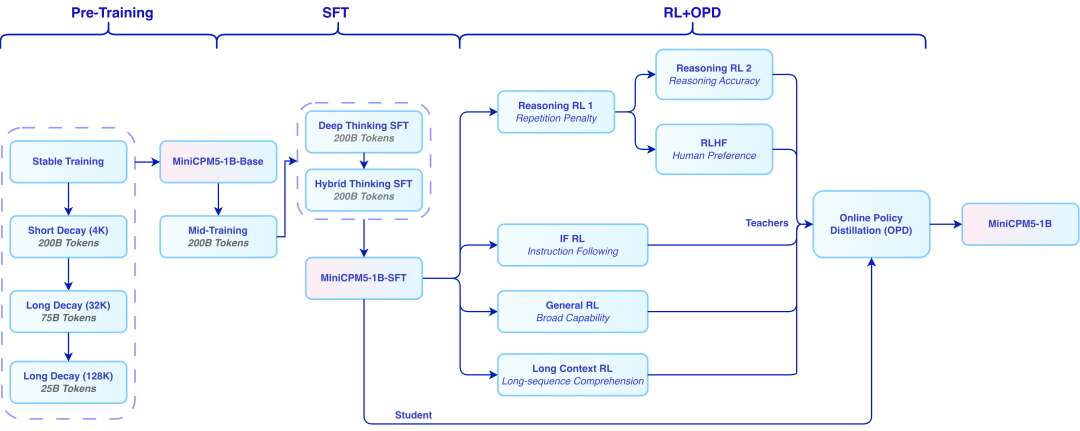
我看了 MiniCPM5-1B 的训练管线,发现它的训练管线采用了四级数据递进策略 :
-
L1 塑形:用基础过滤的数据打下语言和常识地基
-
L2 拔高:用精筛数据去提升专业能力
-
L3 激活:用合成数据激发复杂推理能力
-
对齐出关:SFT + RL + OPD,完成最终打磨"
◈端侧,数据才是真壁垒
再回到开头的问题:1B 凭什么打赢 2B ?
因为在面壁的字典里,竞争的焦点早已不是参数,而是智能密度。
在 2024 年提出“密度定律”(Densing Law)—智能密度每 100 天翻一倍后,面壁智能一直坚持不做最大的模型,而做最高效的模型。
从数据治理、训练算法到架构设计,再到推理、量化与端侧部署,构建了完整一整条全栈式的高知识密度的生产线。
到了端侧这个体量,模型架构大家都差不多,算力也就那么点,真正能拉开差距的就是数据质量。
看 MiniCPM 小钢炮在端侧模型的江湖地位,你就知道这条路完全可行。

如果换个角度看,会更清楚。
Llama、Qwen、Gemma 都在做端侧模型,权重都能免费下载,架构论文也是公开的。但是大家开源的都是模型,没人开源数据。训练数据怎么配的,数据处理细节是什么,都没有公布。
做过模型训练的人都有体感,工程师 70% 的时间都在数据清洗、标注和增强上。
模型架构可以抄,数据才是真壁垒。
端侧场景下这个问题更突出。
今年全球 AI 手机出货量预计突破 5 亿部,渗透率到了 35% ,甚至 Vivo、Oppo、华为国内几大手机厂商已经把端侧 AI 下放到了中端机和千元机,端侧 AI 几乎成了标配。
但实际做端侧 AI 的团队清楚,最难的不是找不到能跑的模型,1B、2B 的开源模型不少,而是找不到足够好的数据来训出一个在场景里真正能打的版本。
这次面壁联合 OpenBMB 社区不只是开源了数据集,整条数据炼法都公开了。从 L1 筛选到 L3 合成,怎么做、用什么模型做、每一步怎么验证。
对做端侧的团队,可以不用自己从零踩坑,直接在这条已经跑通的路上走即可,不管是手机厂商、车机团队还是做 IoT 的,都可以在这个基础上改。
在手机、PC、手表、汽车这些场景上,1B 和 2B 的体验差距,远没有数据质量带来的差距大。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)