大模型 API 聚合平台的五个核心价值:统一接口、成本控制与国内访问
大模型 API 聚合平台的五个核心价值:统一接口、成本控制与国内访问
2026 年的大模型市场已经进入高频迭代阶段:Claude、GPT、Gemini、DeepSeek、Kimi、Qwen 等模型不断更新,价格、能力和上下文窗口差异巨大。对企业和开发者来说,直接对接每一家模型 API,正在从“灵活”变成“维护负担”。
大模型 API 聚合平台的价值,是在业务系统与模型供应商之间增加一层统一网关:一套 Key、一套接口、一套计费和权限策略,背后可以路由到多个模型。它解决的不是“哪个模型最强”,而是“模型不断变化时,业务代码如何少受影响”。
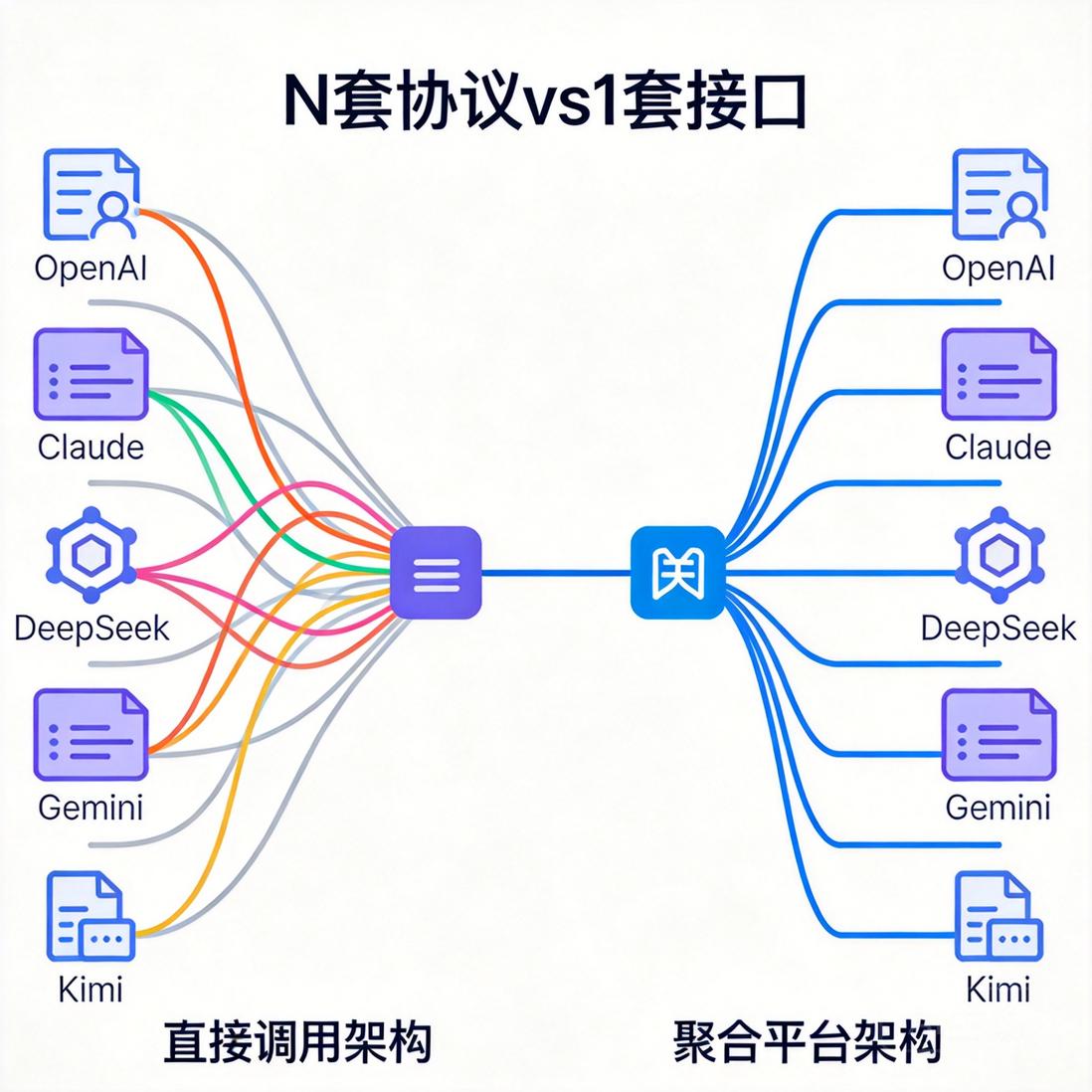
什么是大模型 API 聚合平台
大模型 API 聚合平台,也常被称为 LLM API Gateway 或 AI Model Router。它把 OpenAI、Anthropic、Google、DeepSeek、月之暗面、阿里云等不同供应商的协议差异,统一封装成开发者更容易使用的接口。
| 维度 | 直接调用原生 API | 使用聚合平台 |
|---|---|---|
| 接口协议 | 多套协议并存 | 统一 OpenAI 或 Anthropic 兼容接口 |
| API Key | 多个平台分别管理 | 一个主 Key 或多个子 Key 集中管理 |
| 模型切换 | 改 SDK、鉴权、参数和返回解析 | 多数情况下改 model 参数即可 |
| 成本统计 | 分散在多个账单页 | 统一用量与费用视图 |
| 故障处理 | 业务侧手动切换 | 可做 fallback、重试、负载均衡 |
| 国内访问 | 部分海外 API 不稳定 | 可通过国内兼容入口统一访问 |
当项目只用一个模型、调用量也很低时,直接接原生 API 更简单;当团队同时测试多个模型、需要预算隔离、需要国内访问或故障切换时,聚合平台的收益会迅速放大。
价值一:统一接口,降低集成成本
每接入一家模型供应商,都要处理一套工程细节:SDK、鉴权、请求格式、流式输出、错误码、重试、函数调用、上下文限制和返回结构。模型越多,重复劳动越明显。
典型差异包括:
- OpenAI Chat Completions 使用
choices[0].message.content - Anthropic Messages API 使用
content[0].text - DeepSeek 可能包含
reasoning_content - Gemini 的工具调用与多模态结构又有不同格式
通过聚合平台,业务层可以尽量统一为一种调用方式:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://code.ai80.vip/v1"
)
models = [
"gpt-5",
"claude-sonnet-4-6",
"deepseek-v4",
"kimi-k2"
]
for model in models:
response = client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": "请总结这段产品反馈"}]
)
print(model, response.choices[0].message.content[:100])
这里的关键不是代码少了几行,而是业务层不再被某一家模型的协议绑定。
价值二:供应商切换从“改代码”变成“改配置”
模型选型不会一次到位。新模型发布、旧模型降价、某家服务限流、业务质量不达标,都可能要求快速切换。
如果系统直接写死某个 SDK 和端点,切换模型往往需要:
- 新增依赖或 SDK
- 修改鉴权方式
- 调整请求参数
- 重写返回解析
- 补充错误处理与测试
聚合平台让切换变成更轻的动作:
# A/B 测试:同一个 prompt 分别跑两个模型
prompt = "请判断这条用户反馈属于功能建议、Bug 还是投诉"
resp_a = client.chat.completions.create(
model="gpt-5",
messages=[{"role": "user", "content": prompt}]
)
resp_b = client.chat.completions.create(
model="deepseek-v4",
messages=[{"role": "user", "content": prompt}]
)
常见切换场景包括:
- OpenAI 或 Anthropic 限流时临时切到备用模型
- 新模型上线后快速做 A/B 测试
- 某类任务从旗舰模型降级到轻量模型以节省成本
- 不同客户或不同项目使用不同模型策略
价值三:成本管控从分散账单变成统一治理

多模型架构最大的问题之一是账单分散。一个团队可能同时维护 OpenAI、Anthropic、Google、DeepSeek、云厂商和本地模型服务,最终很难回答几个基础问题:
- 哪个项目消耗最多?
- 哪个开发者或子系统调用异常?
- 哪个模型被误用于低价值任务?
- 本月预算是否会超支?
聚合平台通常会提供:
| 能力 | 解决的问题 |
|---|---|
| 统一用量仪表盘 | 所有模型调用集中查看 |
| 子 Key | 按项目、团队、环境隔离权限 |
| 额度上限 | 防止单个项目异常烧钱 |
| 模型白名单 | 避免低价值任务误用旗舰模型 |
| 缓存策略 | 相同 Prompt 或相似请求降低重复成本 |
| 告警 | 超预算、异常流量、失败率升高时通知 |
对企业来说,这部分价值往往高于 Token 单价本身。模型费用只是显性成本,工程维护、排障、审计和超支风险才是长期成本。
价值四:国内访问与多模型统一入口
国内团队接入海外模型时,常遇到网络稳定性、访问路径、合规和运维问题。自建代理虽然灵活,但会引入服务器维护、链路稳定性和合规风险。
更稳妥的架构是:业务系统只连接一个兼容 API 入口,由平台层负责模型路由、协议转换、访问链路和账单管理。需要 Claude、GPT、Gemini、DeepSeek 等模型统一接入时,可以使用 Code80 作为兼容入口,减少在不同供应商之间来回改配置的成本。
架构上可以理解为:
业务系统
│
├─ OpenAI SDK / Anthropic SDK
│
统一 API 入口
│
├─ Claude
├─ GPT
├─ Gemini
├─ DeepSeek
└─ 国产模型
这种方式尤其适合需要国内环境稳定调用海外模型,同时又希望保留国产模型作为成本或备份选项的团队。
价值五:安全与合规集中治理
直接调用多家模型 API 时,安全治理会变得分散:多个 Key、多个日志来源、多条数据链路、多套权限体系。任何一个 Key 泄露、权限过大或日志不可追溯,都可能带来风险。
聚合平台可以把治理集中到统一层:
- 主 Key 不直接下发给业务开发者
- 每个项目使用独立子 Key
- 子 Key 可设置模型白名单和额度上限
- 所有请求有统一审计日志
- 敏感数据可在网关层做脱敏或过滤
- 离职、项目结束、测试环境下线时可快速撤销权限
对中大型团队而言,这比“每个项目自己申请一堆 API Key”更容易管理。
什么情况下最值得使用聚合平台
| 场景 | 建议 |
|---|---|
| 只用一个模型、调用量很小 | 可直接调用原生 API |
| 同时测试多个模型 | 使用聚合平台 |
| 国内访问 Claude/GPT 等模型 | 使用兼容 API 入口 |
| 多项目共享预算 | 使用子 Key 和额度管理 |
| 模型更换频繁 | 使用统一路由层 |
| 生产系统需要故障切换 | 使用支持 fallback 的网关 |
| 数据必须完全不出内网 | 考虑自建开源网关或本地模型 |
FAQ
Q:聚合平台一定会增加延迟吗?
会增加一层网络转发,但不一定导致体验变差。如果平台链路更稳定,实际首 Token 延迟可能比自建不稳定代理更好。实时语音等极低延迟场景需要单独压测。
Q:聚合平台会不会更贵?
要看定价模式。即便存在少量服务费,也要和节省的集成时间、维护成本、账单治理和故障处理成本一起计算。
Q:个人开发者有必要使用吗?
如果只调用一个模型,没有必要增加复杂度;如果经常切换 Claude、GPT、DeepSeek、Kimi,或者不想维护多个 Key,就值得考虑。
Q:还能使用模型特有能力吗?
取决于平台是否完整透传协议参数。选型时要测试 extended thinking、reasoning_content、function calling、vision、streaming 等能力。
总结
大模型 API 聚合平台的核心价值不是“把模型放在一个列表里”,而是让业务代码与模型供应商解耦。统一接口降低集成成本,模型路由提升切换效率,集中账单改善成本治理,兼容入口解决国内访问和多模型统一调用,安全策略则让 Key、审计和权限可控。当模型数量超过两个、团队规模超过个人项目、生产系统需要稳定性时,聚合平台就不再是锦上添花,而是更可维护的基础设施。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献25条内容
已为社区贡献25条内容

所有评论(0)