为什么很多公司上了 Flink,还是做不好实时数仓?

实时数仓这个概念,已经炒了很多年。
早些年,行业里对它的期待很高:业务数据一变,数仓马上更新;指标实时产出;明细实时入湖;分析系统几乎不再等待批处理窗口。
但很长一段时间里,真正落地的案例很少。
原因并不复杂。早期 Flink 的优势主要集中在实时计算层,计算能力足够强,但完整的实时数仓链路还缺关键拼图。很多团队采用 Flink + Kafka 的组合,把 Kafka 当作事实上的实时存储和中转层,再通过 Flink 消费、加工、写出。
这套架构能跑通不少实时任务,也支撑过很多实时看板。但一旦进入数仓和湖仓场景,问题很快暴露:Kafka 更擅长消息流转,不擅长承载长期湖仓存储、表级元数据、历史版本、Schema 演进、批流统一查询和湖表治理。Flink 负责计算,Kafka 负责消息,中间缺少一个真正面向湖仓资产的表层。
Paimon 日渐成熟后,这块拼图开始补上。
Flink 负责持续计算和流式写入,Paimon 承接湖表、主键更新、Snapshot、Schema Evolution、Time Travel、Compaction 等能力,OLAP 引擎再面向分析查询提供服务层。再加上 Fluss 这类面向实时流式存储和流表统一的新组件,Flink + Paimon + Fluss + OLAP 的组合,才让实时数据从接入、计算、存储、治理到分析服务形成更完整的架构闭环。
也正因为这些基础设施逐渐成熟,实时数仓才开始从概念走向可落地的 Streaming Lakehouse 阶段。
新的问题随之出现:架构终于走通了,企业能不能把它稳定跑起来?
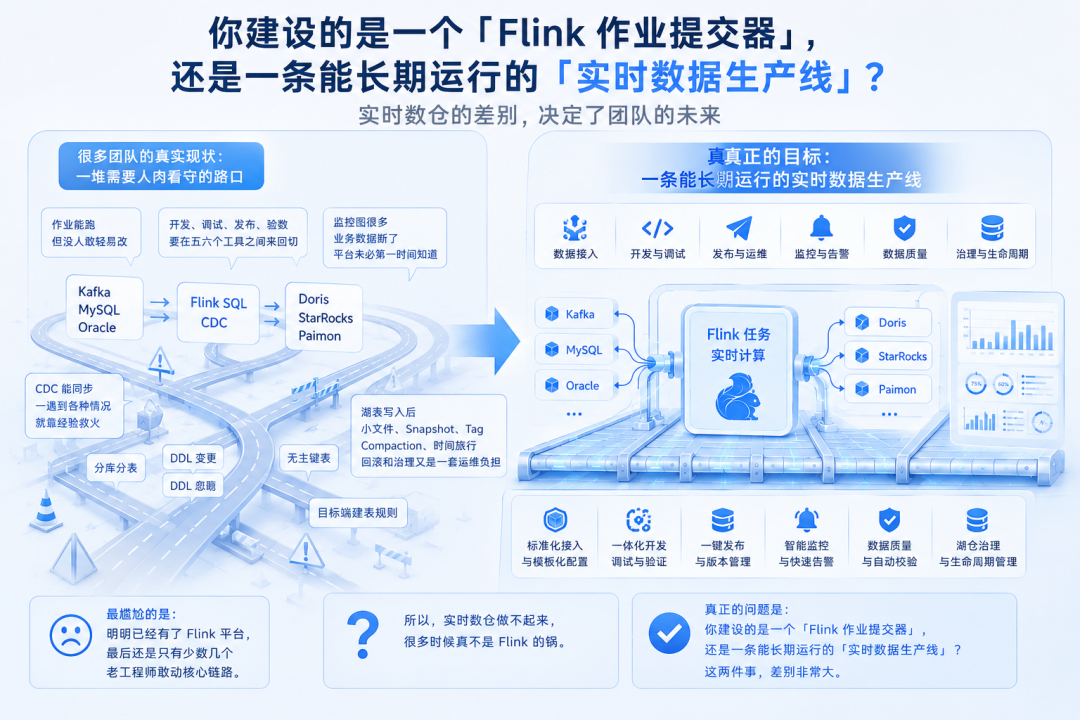
不少数据团队建设实时数仓时,都踩过同一个坑:
Flink 集群搭起来了,Kafka、MySQL、Oracle 接进来了,CDC 跑通了,数据能写到 Doris、StarRocks、Paimon,Prometheus 和 Grafana 也接上了,页面上还能看到作业 RUNNING。
第一眼看,平台已经成型。
真正跑到生产半年,问题开始集中爆发:
-
作业能跑,没人敢轻易改
-
SQL 能写,开发、调试、发布、验数要在五六个工具之间切换
-
CDC 能同步,一遇到分库分表、DDL 变更、Connector 版本、无主键表,就靠经验救火
-
监控图很多,业务数据断了,平台未必第一时间发现
-
湖表能写入,小文件、Snapshot、Tag、Compaction、时间旅行、回滚和治理又形成新的运维负担
最尴尬的场景是:公司明明有了 Flink 平台,核心链路仍然只有少数老工程师敢碰。
Flink 没有背锅,真正卡住团队的,是平台形态。
你建的是一个 Flink 作业提交器,还是一条能长期运行的实时数据生产线?
这个问题,决定实时数仓能跑多远。
01 实时数仓,真正难在生产化
过去几年,实时数仓的讨论总绕不开技术选型:
-
Flink 还是 Spark Streaming?
-
Doris 还是 StarRocks?
-
Paimon 还是 Iceberg?
-
Kafka 还是 Pulsar?
选型很重要,却很少决定最终成败。
进入生产后,团队每天面对的往往是这些具体问题:
-
源库字段变了,下游表结构没跟上
-
CDC 作业恢复后,Schema 对不上
-
SQL 在开发环境能跑,发布到生产缺依赖
-
Connector 版本冲突,JAR 包到处复制
-
Checkpoint 连续失败,告警规则没有兜住
-
Sink 写入变慢,业务已经感知延迟
-
K8s Pod 重建后,平台状态和真实状态不一致
-
客户现场没有外网,镜像、监控、日志、依赖都要离线交付
-
平台显示
RUNNING,业务数据已经停了
这些问题靠单个工程师写好 Flink SQL 很难解决。
它们考验的是一套平台能力:开发、元数据、资源、依赖、部署、监控、恢复、权限和交付,能不能形成闭环。
实时数仓第一天验证功能。
实时数仓第一百八十天验证体系。
第一天,平台看起来都差不多:能提交 SQL,能启动作业,能看运行状态。
半年后,差距会被迅速拉开:有的平台只能把作业启动起来,有的平台能把链路持续托住,这就是 Demo 和生产之间的分水岭。
还有一个更容易被低估的事实:
从接入实时数仓的第一天开始,技术复杂度就已经叠起来了。
数据接入要用 Flink CDC;中间链路要对接 Kafka、Doris、StarRocks、Paimon 等生态组件;每接一个系统,就要处理对应 Connector 的版本、参数、依赖和运行时行为。
想做统一元数据管理,也绕不开 Catalog。要么按照 Flink Catalog 的接口标准自己实现,要么引入第三方 Catalog 实现,要么再接入 Apache Gravitino 这类统一 Catalog 项目。看起来只是“把表管起来”,落到平台里就是 Catalog 生命周期、权限、连接参数、类型映射、SQL 兼容和多环境隔离。
进入湖仓之后,复杂度继续往上走。接入 Paimon,平台就要理解 Paimon 的 Catalog、系统表、Snapshot、Tag、Branch、Compaction、Time Travel,以及一批湖表运维语法。后续如果要对接 Fluss、多模态数据湖、向量数据、非结构化数据,平台还要继续扩展连接、元数据、查询、运维和治理模型。
可观测性也不会自动出现。Prometheus、Grafana、Alertmanager 都有成熟组件,但真正落地时,还要处理指标采集、Dashboard、告警规则、日志关联、作业状态映射、Kubernetes / Yarn 环境差异,以及不同 Flink 版本下的指标变化。

单独看,每一层都有现成项目;叠在一起,就是一条高复杂度链路:
-
Flink CDC 版本和源端数据库兼容
-
Kafka、Doris、Paimon 等 Connector 依赖兼容
-
Flink Catalog 标准和第三方 Catalog 适配
-
Paimon 湖表语法、系统表和运维动作
-
Prometheus / Grafana / Alertmanager 可观测体系
-
Kubernetes、Yarn、Hadoop、Kerberos、离线环境交付
-
未来 Fluss、多模态数据湖和更多数据形态的接入
每个点都有方案,每个方案都带来版本矩阵、依赖冲突、运行时差异和长期维护成本。
这就是实时数仓平台最难的地方:技术栈看起来都有开源答案,真正叠成企业级链路后,需要一支长期专注的专业团队持续维护。
02“作业提交器” 不够用了
一个 Flink 作业提交器,通常能解决四件事:
-
提交作业
-
停止作业
-
查看状态
-
触发 Savepoint
早期建设平台,这四件事很有价值。
生产环境里,实时数仓是一条跨系统、跨团队、跨生命周期的数据生产流程。
从业务库实时入仓来看,一条链路至少要经历:
源端接入、元数据建模、SQL / CDC / JAR 开发、依赖识别、语法校验、实时预览、发布上线、运行监控、日志诊断、快照恢复、版本回滚、权限审计、现场交付。
任何一个环节断掉,都会变成平台团队的人工成本。

实时平台越做越“重”,根源在生产化本身。
复杂度有两种归宿:
一种散落在脚本、Wiki、命令行、个人经验和临时群消息里,看起来轻,实际全靠人扛,一种沉淀进平台,前期建设更扎实,后续可以复制、交接、规模化。
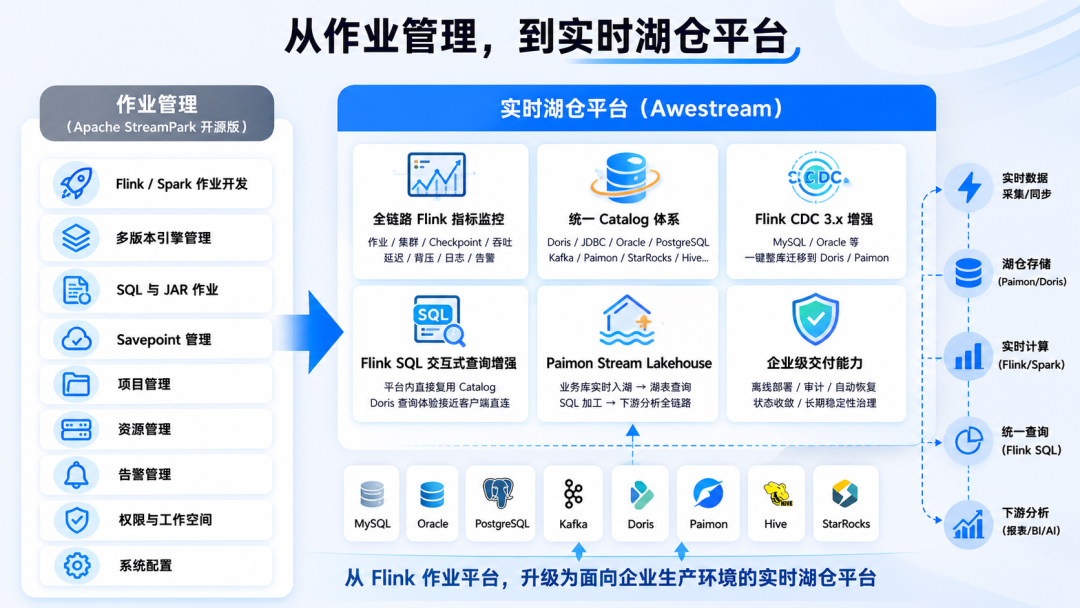
Awestream 的定位就在这里:
Awestream 是基于 Apache StreamPark™ 构建的新一代 Streaming Lakehouse 平台,面向企业实时计算与湖仓一体场景,把 Flink 的开发、运维、治理、交付能力集中到一套平台里,让实时数据链路具备长期运行能力。
03 开发低效,需要一站式开发环境
实时开发低效,常常源于工作流被切碎。
一条 Flink SQL 从开发到上线,通常要走完这些动作:
-
找表
-
看字段
-
写 SQL
-
做校验
-
看预览
-
补依赖
-
配 Flink 参数
-
发布上线
-
查日志和指标
-
验证结果数据
如果这些动作分别发生在 IDE、SQL Client、Flink UI、Doris 客户端、Grafana、K8s 控制台、Wiki 文档里,开发者每天都在搬运上下文。
上下文一多,效率下降;工具一多,错误也变多。
Awestream 把作业开发做成一体化工作台:
-
支持 Flink SQL、JAR、CDC 等多种作业类型
-
SQL 编辑器支持代码提示、语法校验、实时预览、自动保存
-
左侧集成作业草稿、元数据树、SQL 控制台、UDF 管理、JAR 资源
-
右侧统一管理 Flink 配置、告警策略、作业依赖、版本管理
-
支持多个作业草稿并行编辑
-
支持选中 SQL 运行、右键菜单、格式化、变量查看
-
支持上线历史版本比对、回滚和删除
产品细节背后,是一个高频生产场景:
实时开发的核心任务,不止写出 SQL,还要把 SQL 稳定地变成生产作业。
自建平台容易先做发布,再补开发体验。
可日常成本恰恰发生在发布前后:查表、改 SQL、补依赖、调参数、看结果、回滚版本。
平台接不住这些动作,工程师就只能在工具之间来回跑。
实时链路越多,这笔隐性成本越高。
04 第一道坎:数据怎么稳定接入湖仓
实时数仓里最容易爆的需求,通常是整库同步。
业务方一句话就能提完:
把 MySQL 分库分表的数据实时同步到 Doris / Paimon。
落地时,问题会一下子铺开:
源端是 MySQL、Oracle、PostgreSQL、SQL Server、MongoDB、OceanBase、TiDB,还是 DB2?
目标端是 Doris、StarRocks、Paimon,还是 Kafka?
表名怎么路由?字段怎么转换?数据要不要过滤?
DDL 变化怎么处理?依赖怎么安装?失败后从哪里恢复?谁来告警?版本怎么回滚?
CDC 如果只停留在几份 YAML 文件里,链路一多,生产风险会快速放大。
Awestream 对 CDC 的处理方式,是把它纳入完整的平台生命周期:
-
创建 CDC 草稿时选择源端和目标端连接器
-
编辑区自动填充注释和属性,降低盲写参数的成本
-
CDC YAML 支持校验,发布前提前发现结构、字段名和参数问题
-
依赖可以自动识别,也可以手动选择
-
作业上线后进入统一运维中心
-
运行状态、告警、监控、日志、快照、恢复和版本回滚都由平台接管
CDC 进入平台后,就从本地配置文件变成了可管理、可追踪、可恢复、可交接的生产链路。
团队扩到几十条、几百条同步链路时,平台必须知道它们依赖什么、运行在哪、谁改过、从哪里恢复、出问题找谁。
这一步做扎实,实时入仓和实时入湖才有规模化基础。
05 Catalog: 数据的资产入口
Catalog 经常被低估。
有人把它理解成连接信息管理。到了实时湖仓里,它承担的是数据资产入口。缺少统一 Catalog,现场会出现一连串问题:
-
同一张 MySQL 表,在不同 SQL 作业里复制了多份 DDL
-
Kafka topic 的字段定义散落在多个项目里
-
Doris、StarRocks、Paimon 的表结构靠人工记忆
-
开发环境和生产环境结构不一致
-
新人接手一条链路,先要翻 Wiki、问同事、找历史 SQL
-
字段改了,没人知道影响了哪些作业
元数据一旦失控,实时数仓很快失控。
Awestream 把 Catalog 放在实时开发的入口位置,支持通过 SQL 和可视化两种方式管理 Flink Catalog、Database、Table、View。
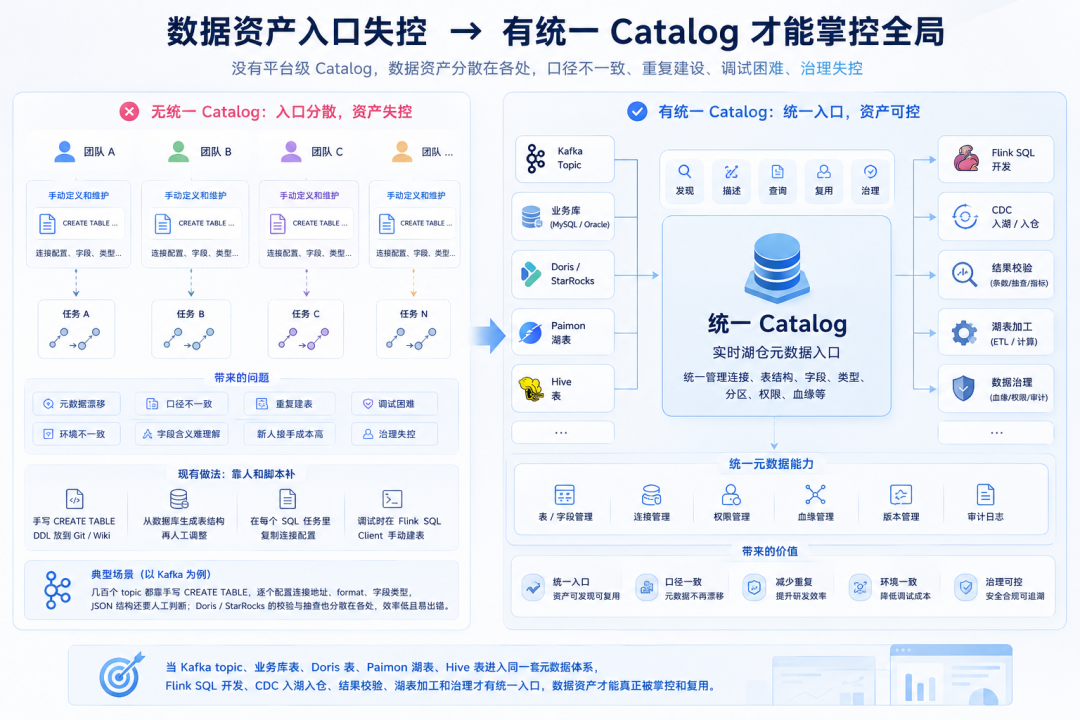
开发者可以在 SQL 控制台执行CREATE、DROP、ALTER、SHOW、DESCRIBE、SELECT、INSERT等操作,也可以在元数据树上创建表、修改属性、查看表详情、插入 DDL。
更关键的是,Awestream 支持把 MySQL、PostgreSQL、SQL Server、Oracle、DB2、OceanBase、Trino 等数据库中的源表快速转换成 Flink 表,自动解析字段、连接器配置和 DDL。
实时开发的第一步,往往并非立刻写 SQL。
更关键的动作,是把源表变成 Flink 能理解、平台能管理、团队能复用的元数据资产。
数据源只接一次,后续 SQL 开发、CDC 同步、实时预览、元数据查看、依赖识别、作业发布都能复用。
Catalog 的价值,就是把“每个作业自带一份 DDL”,升级成“全平台共享一份数据资产”。
长期看,这比少写几行配置重要得多。
06 可用性:运行中,不代表链路健康
生产事故里,有一句话特别常见:
作业看起来在正常运行,数据却没有继续处理。
这句话背后,是实时运维最危险的盲区。
团队有 Grafana,有 Prometheus,也有一堆 Dashboard。
问题在于,指标没有转成可行动的信息。
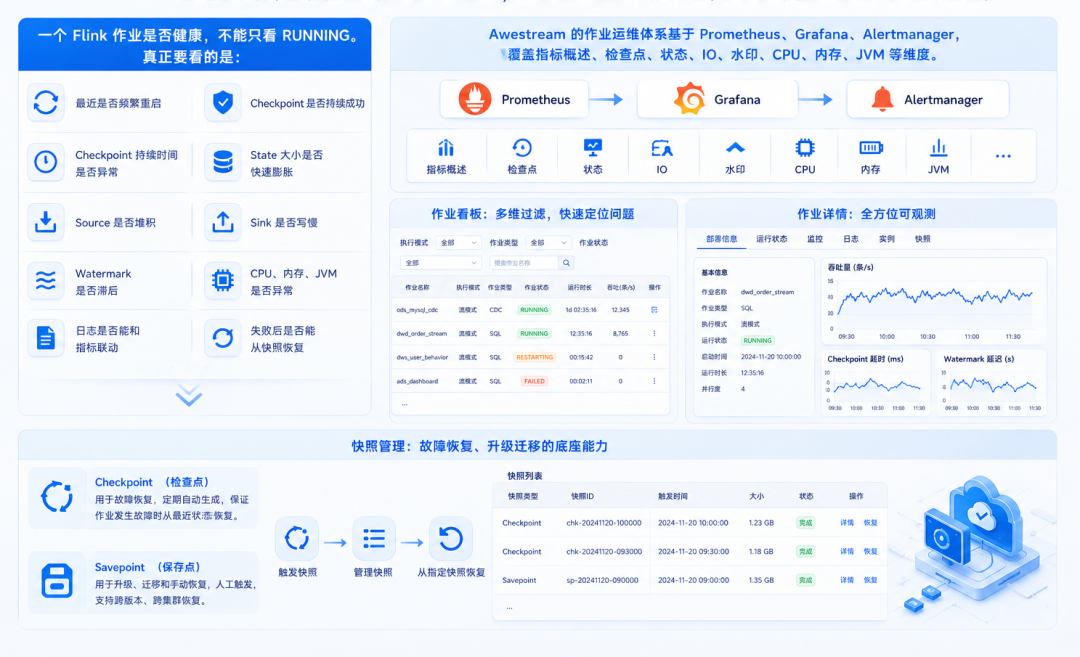
一个 Flink 作业是否健康,不能只看 RUNNING。
真正要看的是:
-
最近是否频繁重启
-
Checkpoint 是否持续成功
-
Checkpoint 持续时间是否异常
-
State 大小是否快速膨胀
-
Source 是否堆积
-
Sink 是否写慢
-
Watermark 是否滞后
-
CPU、内存、JVM 是否异常
-
日志是否能和指标联动
-
失败后是否能从快照恢复
Awestream 的作业运维体系基于 Prometheus、Grafana、Alertmanager,覆盖指标概述、检查点、状态、IO、水印、CPU、内存、JVM 等维度。
作业看板可以按执行模式、作业类型、作业状态过滤;作业详情里可以看部署信息、运行状态、监控、日志、实例和快照。
快照管理也进入平台能力:Checkpoint 用于故障恢复,Savepoint 用于升级、迁移和手动恢复,平台支持触发快照、管理快照,并从指定快照恢复。
实时作业运维,核心是让平台回答三个问题:
-
这条链路现在是否真的健康?
-
它什么时候开始变坏?
-
出问题后能不能快速恢复?
一个实时平台能否进入核心生产系统,最终看这三件事。
07 实时湖仓:湖格式也要进平台
实时数仓走到湖仓一体后,平台面对的不再只有 Flink 作业,还有长期沉淀的数据资产。
Paimon、Doris、StarRocks 接进来后,问题会从“能不能写进去”,升级到“能不能持续治理”。
湖表写入后,会持续产生 Snapshot、Tag、Branch、Time Travel、小文件、Compaction、Schema Evolution。
服务层表还要关注写入延迟、查询验证、字段变更、数据一致性。
CDC 入湖、Flink SQL 加工、Doris / StarRocks 服务层输出、监控告警、快照恢复,如果散落在不同工具里,实时湖仓很难形成闭环。
Awestream 把这些动作放进同一条工作流:
-
通过 Catalog 管理湖仓表和外部数据源
-
通过 CDC 把业务库变更实时入湖入仓
-
通过 Flink SQL 做加工、查询和校验
-
通过作业运维中心观察运行状态、指标、日志和快照
-
通过版本和回滚机制支撑持续演进
还有一个绕不开的问题:资源弹性。
实时业务负载不稳定。白天流量高,夜里流量低;大促、活动、批量导入、上游补数据,都会让链路压力突然变化。
资源给少了,延迟上来;资源给多了,成本浪费。
Awestream 支持 Kubernetes 环境下的 Flink 作业自动弹性扩缩容,可以根据 TaskManager 的 CPU 利用率、内存利用率、CPU + 内存综合指标,以及 backlog、延迟、Watermark 滞后等自定义 Flink 指标触发扩缩容。
这项能力解决的是生产环境里的长期矛盾:
实时链路要扛得住流量,也要控制住成本。
08 现实拷问:业务能不能稳定交付
技术产品看 Demo 很顺,一到客户现场就卡住。
原因很直接:企业环境远比演示环境复杂。
客户可能用 Yarn,也可能用 Kubernetes;Flink 版本可能不统一;Hadoop 环境要接;Kerberos 要配;镜像要进私有仓库;现场没有外网;监控、日志、Dashboard 要一起部署;账号要接 LDAP;敏感信息要脱敏;不同团队要有 Workspace。
这些能力在宣传里不一定显眼,却经常决定项目能不能验收。
Awestream 覆盖了企业交付中的关键环节:
-
Flink 版本管理:多版本共存,作业打包时使用指定版本组件
-
部署目标:Standalone、Yarn、Kubernetes
-
Flink 集群管理:Yarn Session、Kubernetes Session 等模式
-
Hadoop 配置:Web 页面注册和管理,作业运行时自动加载对应环境
-
Kubernetes 安装包:包含平台核心、日志组件、监控组件,可通过启动脚本部署
-
命名空间:区分平台、监控、日志和作业运行空间
-
LDAP:支持企业账号认证
-
变量管理:敏感信息集中存储、加密、动态引用和脱敏显示
-
Workspace:支持团队协作空间和个人开发测试空间
企业真正需要的,是一套能在真实环境里落地、验收、维护、扩展的平台。
如果用一句话概括 Awestream:
把实时计算从“少数专家驱动”,推进到“平台流程驱动”。
今天许多实时链路过度依赖专家经验:
谁知道这个 Connector 用哪个版本?谁知道这条 CDC 链路从哪里恢复?谁知道这个表的 DDL 在哪里?谁知道这个作业为什么要加这个参数?谁知道客户现场的镜像为什么拉不下来?谁知道这个 Checkpoint 失败要怎么处理?
答案都在少数人脑子里,平台就没有真正建立起来。
Awestream 做的事情,是把专家经验沉淀成产品能力:
|
模块 |
能力 |
|---|---|
|
开发体验 |
IDE、SQL Console、AI 文本转 SQL、实时预览、自动保存 |
|
数据接入 |
CDC YAML、源端/目标端连接器、整库同步模板 |
|
元数据 |
Catalog、Database、Table、View、源表转 Flink 表 |
|
资源依赖 |
Connector、Format、UDF、JAR、自动识别与分组 |
|
发布治理 |
多部署模式、校验、版本比对、回滚 |
|
运行运维 |
作业看板、监控、日志、实例、快照、恢复 |
|
资源弹性 |
Kubernetes 下基于 CPU、内存和自定义指标扩缩容 |
|
企业交付 |
Workspace、LDAP、变量脱敏、K8s 安装、监控组件一体化集成 |
|
湖仓方向 |
面向 Doris、StarRocks、Paimon 等目标端的一体化链路 |
接得进来,写得出来,跑得起来,看得明白,坏了能恢复,换人能接手,客户现场能交付。
这才是“实时计算 & 湖仓一体化大数据平台”需要解决的问题。
所以,很多公司上了 Flink,依然做不好实时数仓。
根因在于:实时数仓需要一套能把 Flink、CDC、SQL、Catalog、资源、监控、快照、弹性、交付和湖仓目标串起来的平台。
Awestream 值得被重新认识的原因,也在这里:
它帮企业把实时数据链路做成可持续运行的生产力。
目前开放免费 PoC 和技术交流通道,你可以直接联系我们安装部署,体验 Awestream 的完整能力。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)