AI 生图“高分低能”?Qwen-Image-Bench联合圣马丁艺术家,56个细分场景定义评测新标杆!
📑 论文:http://arxiv.org/abs/2605.28091
Hugging Face:https://huggingface.co/datasets/Qwen/Qwen-Image-Bench
魔搭社区:https://www.modelscope.cn/datasets/Qwen/Qwen-Image-Bench
Github: https://github.com/QwenLM/Qwen-Image-Bench
导语:
当 AI 从“会生图”进化到替代“真实摄影”,甚至“艺术创作”。当前大模型生成的图片已经足以“以假乱真”,甚至运用到更多创意工作流中。越来越多的影像创作者、设计师、品牌方、数字艺术家开始用AI进行视觉创作。
目前业界的文生图(T2I)评测Benchmark,大多还局限在基础语意遵循或单一的图像质量/审美维度。但在真正的用户体验和艺术创作面前,这对模型的考察还远远不够。 今天,Qwen-Image-Bench 正式亮相!
这是一套由中央圣马丁艺术家带队,专业影像视觉、美学设计艺术家团队深度参与开发的文生图模型评测基准。Qwen-Image-Bench拥有 56 个细粒度创作考点,包括分镜设计、游戏设计、漫画创作、时尚造型、字体美学、世界知识等,并自带细粒度自动化开源评估模型 Q-Judger,根据56个三级维度考点,对图片进行打分。
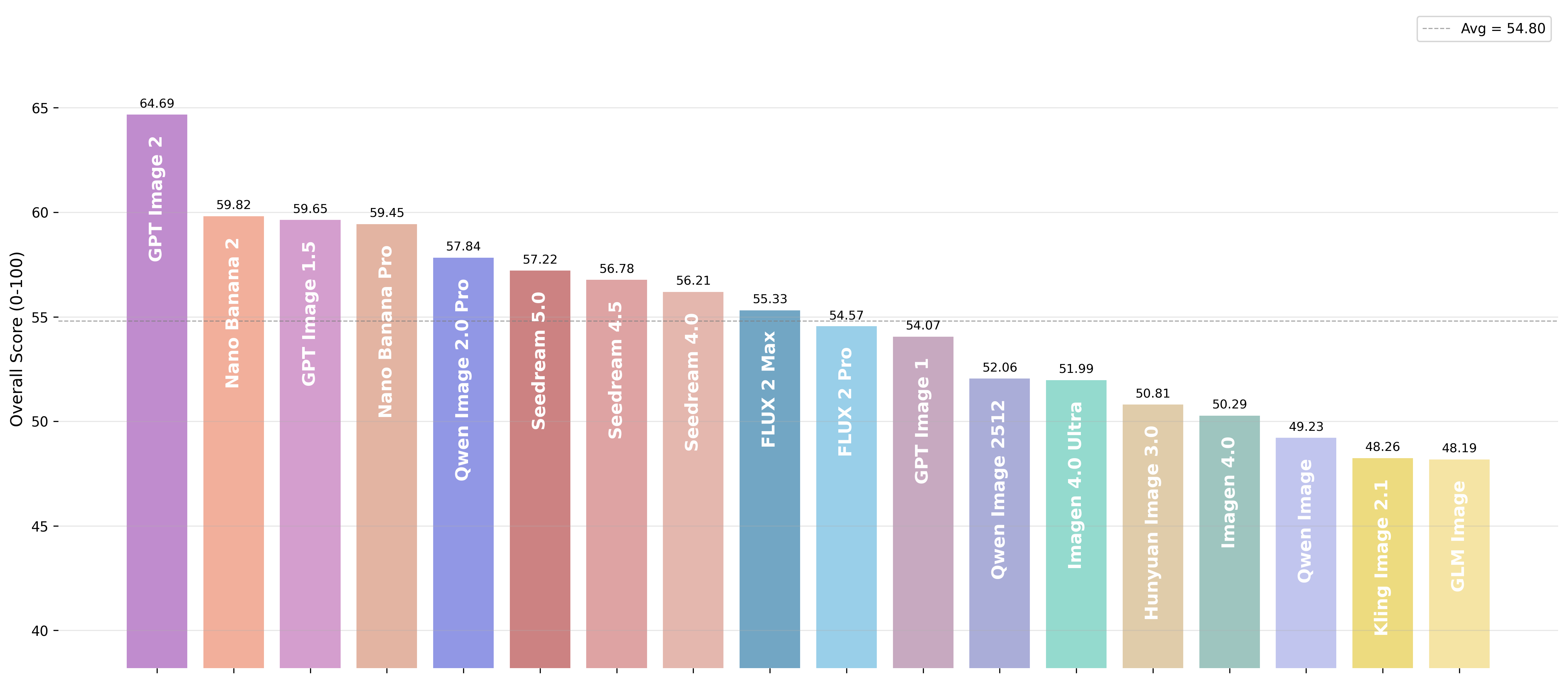
为什么我们需要一场真正的“多模态模型评测”?
很多用户会好奇:什么是“模型评测 Benchmark”?通俗来说,它就是给 AI 模型准备的一场“全科考试”。对于文生图模型而言,评测不仅仅是看模型能不能根据Prompt,准确生出对应图片,更要考核它生成的图片是否具备专业影像创作者的视听语言,甚至拥有对真实世界的复现能力。
现有的 T2I 评测指标只考核简单的语义对齐、图像质量、图像审美。这导致很多大模型虽然在Benchmark上跑分很高,但在实际的高阶创作应用中,影像美感和创意想象力却总“差点意思”。而视觉创作,恰好是检验模型“审美与世界知识”逻辑推理能力”的试炼场。 一个顶尖的文生图模型,必须同时懂审美、会推理、能写字、有知识。
Qwen-Image-Bench就是从用户体验角度出发,构建更加贴合真实应用场景的评测体系。
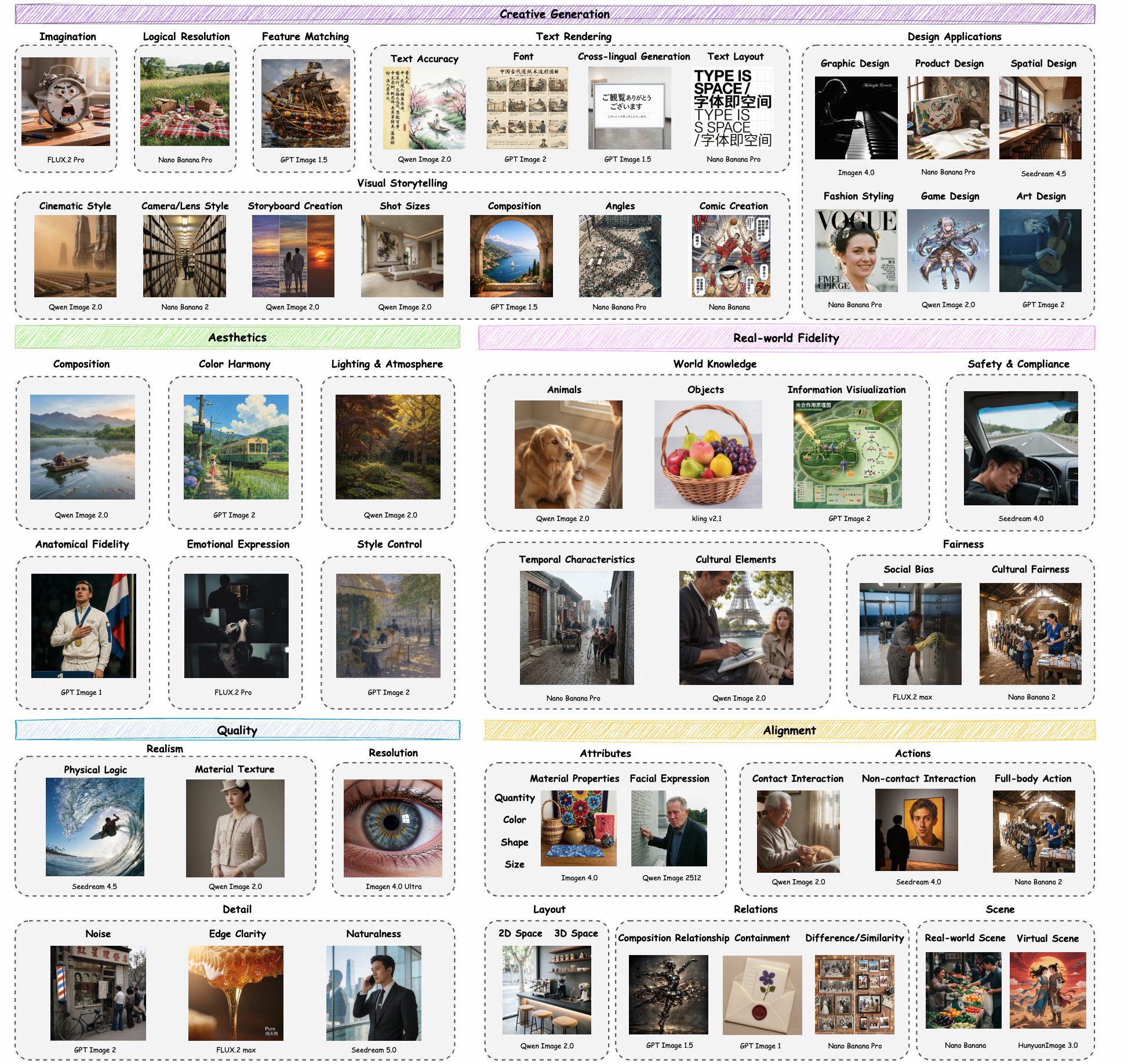
Qwen- Image Bench: 艺术家参与“出题”,56个考点逐一考察。
一个强大的文生图模型,不仅要做到基础的图片生成,更应该具备良好“品味”的“视觉创作者”。为了考察AI 是否能够应对人类艺术家的多元化创作场景,Qwen-Image-Bench 将“创意生成”与“现实世界复现”驱动的提示词设计,作为核心优势:摒弃传统粗粒度、泛化性的评估方式,转而建立结构化的能力评估框架,将创作能力解构为 5 大核心能力支柱与17大典型创作场景,并进一步细化为 56 项可量化、可验证的细粒度评估维度,从而甄别出不同T2I模型,在多元化创作场景的优势与短板,为各家模型的定向优化提供指导性方向。
-
考点多元:覆盖世界知识、创作推理、文字渲染、影像叙事、游戏设计、艺术美学等高频真实场景。
-
全球视野:引入全球不同时期文化元素,确保模型具备全球化的视野与多样性。
-
高效评测:1,000 条分层 Prompts,每条提示词都精准对应至少 4+三级维度考点,搭配Q-Judger自动评估模型,评测效率直线提升。
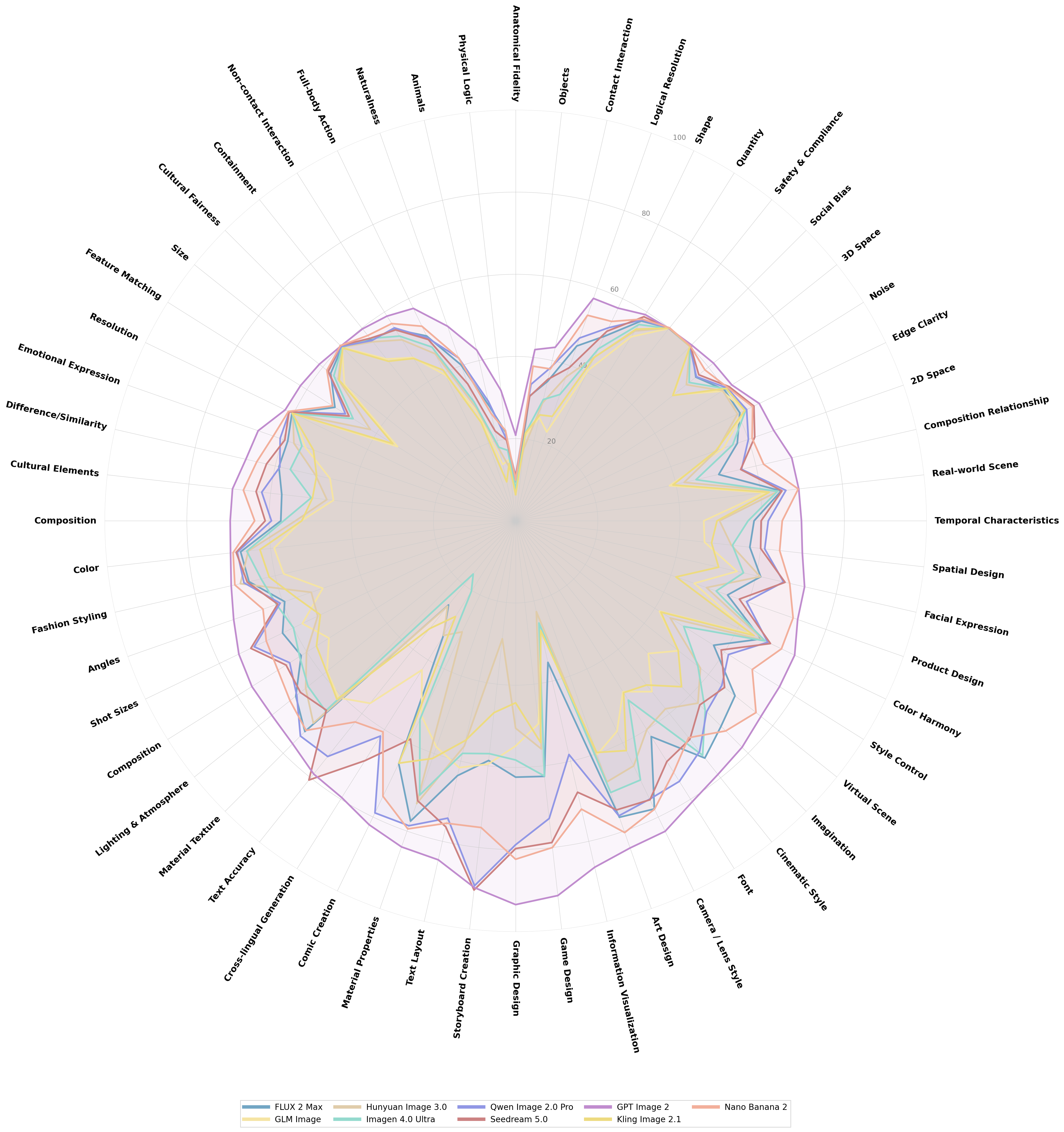
Q-Judger:开源自动化评估模型,实现高效、精准、细粒度的评测
https://huggingface.co/Qwen/Qwen-Image-Bench (开源模型抢先体验)
只有考题还不够,评测结果最终还需要可靠的“阅卷机制”。为了提升评测效率,便于全球AI用户了解主流T2I模型优势,并帮助模型开发者评测自家模型。我们提供了自动化评估模型——Q-Judger,能够从细粒度维度对图片结果进行评分。
-
多维度、细粒度评估:
该评估模型围绕“ 图像质量、图像美学、图文一致性、创作推理能力、现实复现”能力下的56个三级维度,建立了清晰的评分标准。经过精细化训练后,实验结果表明,其评估结果与资深人类艺术家的专业评估具有显著相关性 (Spearsman 0.92)。
-
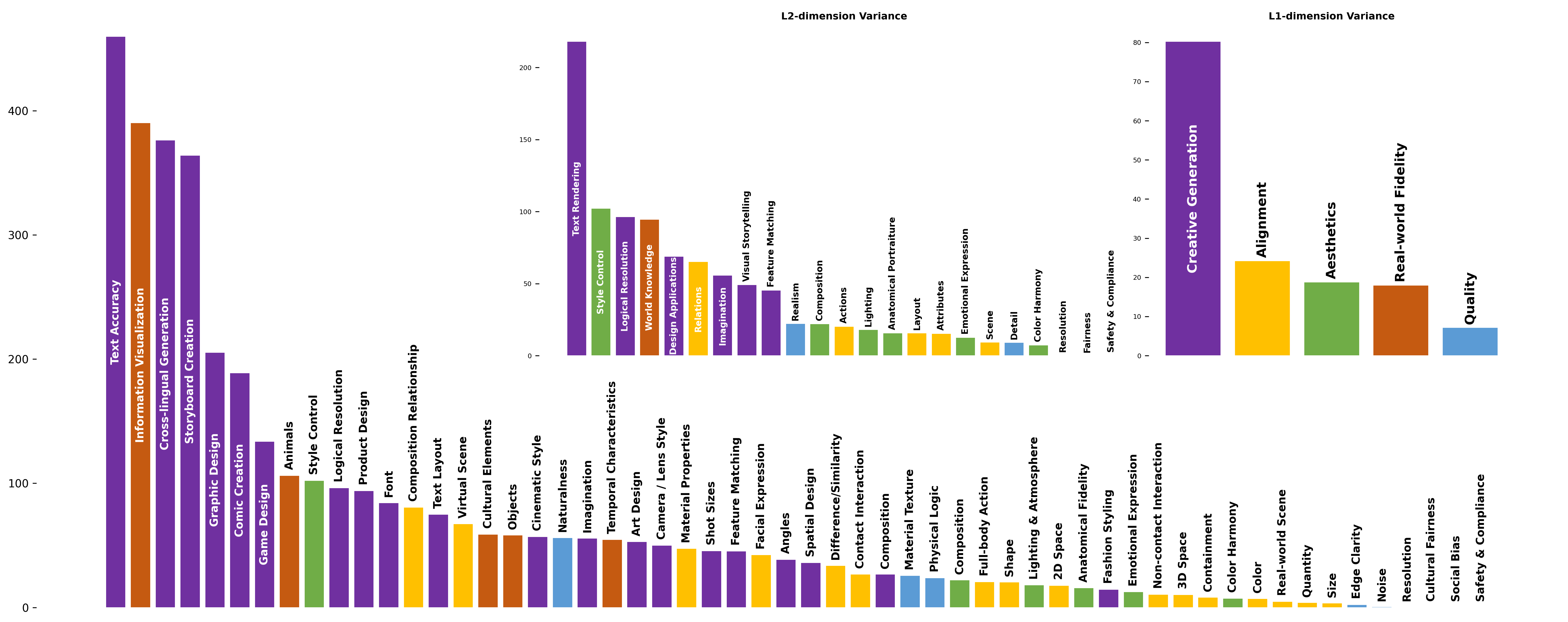
从“评测”到“优化”的闭环:
这套评估体系不仅可以用于模型评测,更能帮助广大模型算法,直接定位自家T2I模型当前存在的薄弱环节。评测结果显示,当前T2I模型在“文字准确性”“信息可视化”“跨语言生成”“影像分镜”“平面设计”“漫画创作”“游戏设计”等子领域能力差距最大。“世界知识与逻辑推理能力”“创作能力”是目前决定T2I模型能否跻身全球第一梯队的分水岭。(见以下方差图)
Qwen-Image-Bench 不仅是一把用于衡量模型能力的“度量衡”,也是一套辅助模型优化的“方法论”。它能够帮助模型自动捕捉细微的创意与表现差异,从而加速迭代,推动模型能力向创作级水平跃迁。
Benchmark Showcase
提示词多样性:我们从用户的真实创作场景出发,由专业艺术家团队设计了1,000 条中英文双语分层prompt。确保每条prompt都精准覆盖 4+三级维度考点,并对模型差异化能力具备强区分度。
-
维度考点:时尚造型、接触互动、艺术设计、摄影机/镜头风格、构图、物理逻辑。
-
提示词示例:模拟拍摄一张中央圣马丁艺术与设计学院White show秀场后台抓拍图:后台化妆间镜前灯泡发光;造型师正在为面容姣好的模特系紧束腰与别针固定披风。要求:手部与接触互动准确、别针与织物拉力真实、镜面反射合理;构图以镜中倒影形成二次画面。
|
|
|
 GPT Image2.0
GPT Image2.0 Nano banana 2.0
Nano banana 2.0-
维度考点:色彩、构图、情绪表达、光影氛围。
-
提示词示例:印象派风格的午后咖啡馆,笔触松散、色彩并置、光影颤动,人物与建筑均以莫奈式手法处理。
|
|
|
 GPT Image 2.0
GPT Image 2.0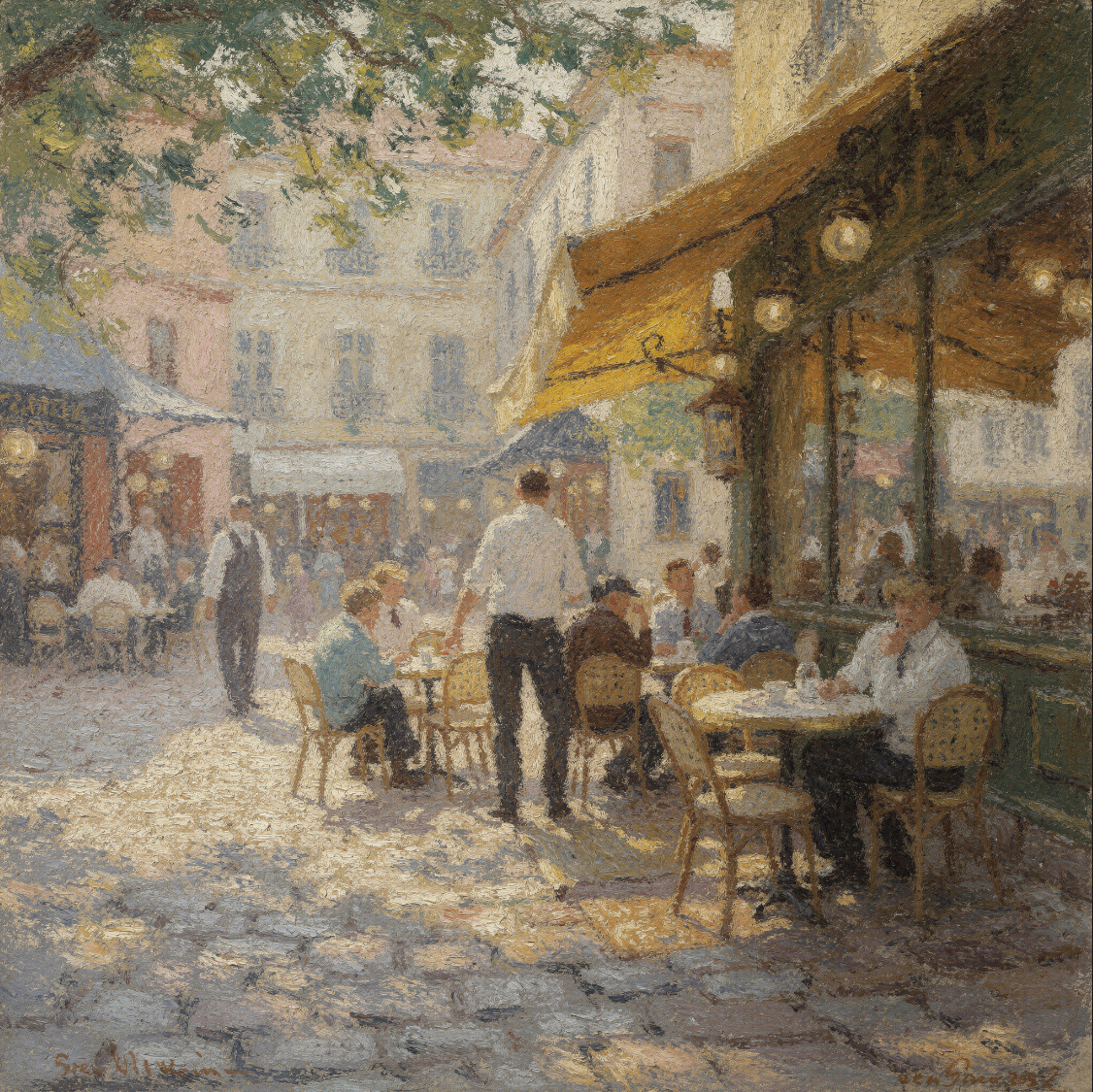 FLUX.2 Max
FLUX.2 Max-
维度考点:产品设计、文化元素、色彩、想象力。
-
提示词示例:文创文具系列“敦煌飞天”,包括笔记本、书签与胶带,图案提取壁画经典纹样,配色复刻矿物颜料古韵,兼具文化性与实用性。
|
|
|
 GPT Image2.0
GPT Image2.0 Qwen-Image 2.0 pro
Qwen-Image 2.0 pro-
维度考点:游戏设计、艺术设计、文字准确性、二维空间、清晰度/分辨率、风格控制。
-
提示词示例:2D 像素风 RPG 的城镇场景截图:包含喷泉、武器店、旅馆、NPC 三名;要求像素风格统一、可读性强;画面左上角有简洁 UI:HP 100/100、Gold 250(文字需清晰)。
|
GPT Image2.0 |
|

 Seedream 4.0
Seedream 4.0-
维度考点:艺术设计、情绪表达、色彩、风格控制。
-
提示词示例:毕加索蓝色时期风格的流浪艺人,冷色调主导,人物瘦削忧郁,笔触沉郁,全图情绪与形式统一。
|
GPT Image2.0 |
Kling Image 2.1 |


-
维度考点:风格控制、虚拟场景、全身动作、表情、景别、构图。
-
提示词示例:创作1:1美漫超级英雄风格漫画,粗犷有力的线条勾勒肌肉轮廓,鲜艳夺目的颜色区分正邪势力,剧情精彩,战斗场面热血沸腾。
|
|
|
 GPT Image 2.0
GPT Image 2.0 Seedream 5.0
Seedream 5.0总结:通往生产力级别的 T2I 必经之路
生图模型的竞争早已走过“听得懂、画得美”的感知阶段——画质、色彩、基础构图这些能力正快速趋同,成为行业标配。
真正的模型能力分水岭,正在于T2I模型能否跨越到认知层面:理解人类创作任务背后的意图、调用自身领域知识,并进行逻辑推理,将抽象概念转化为具有专业价值的视觉表达。
Qwen-Image-Bench揭示了一条清晰的进化路径:从模型“感知驱动”迈向“认知驱动”。顶尖模型需要理解人类创作需求,并调动自身知识与逻辑推理能。这背后,是语言理解、知识整合与模型审美、创意执行的深度协同。未来属于那些能完成“感知→认知→创造”全链路闭环的多模态模型!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)