PolarDB-X 存储引擎核心技术 | 原生多版本唯一键索引 - Panda Index
背景
PolarDB-X 分布式数据库,采用集中式和分布式一体化的架构,为了能够灵活应对混合负载业务,作为数据存储的 Data Node 节点采用了多种数据结构,其中使用行存的结构来提供在线事务处理能力,作为 100% 兼容 MySQL 生态的数据库,DN 在 InnoDB 的存储结构基础上,进行了深度优化,大幅提高了数据访问的效率。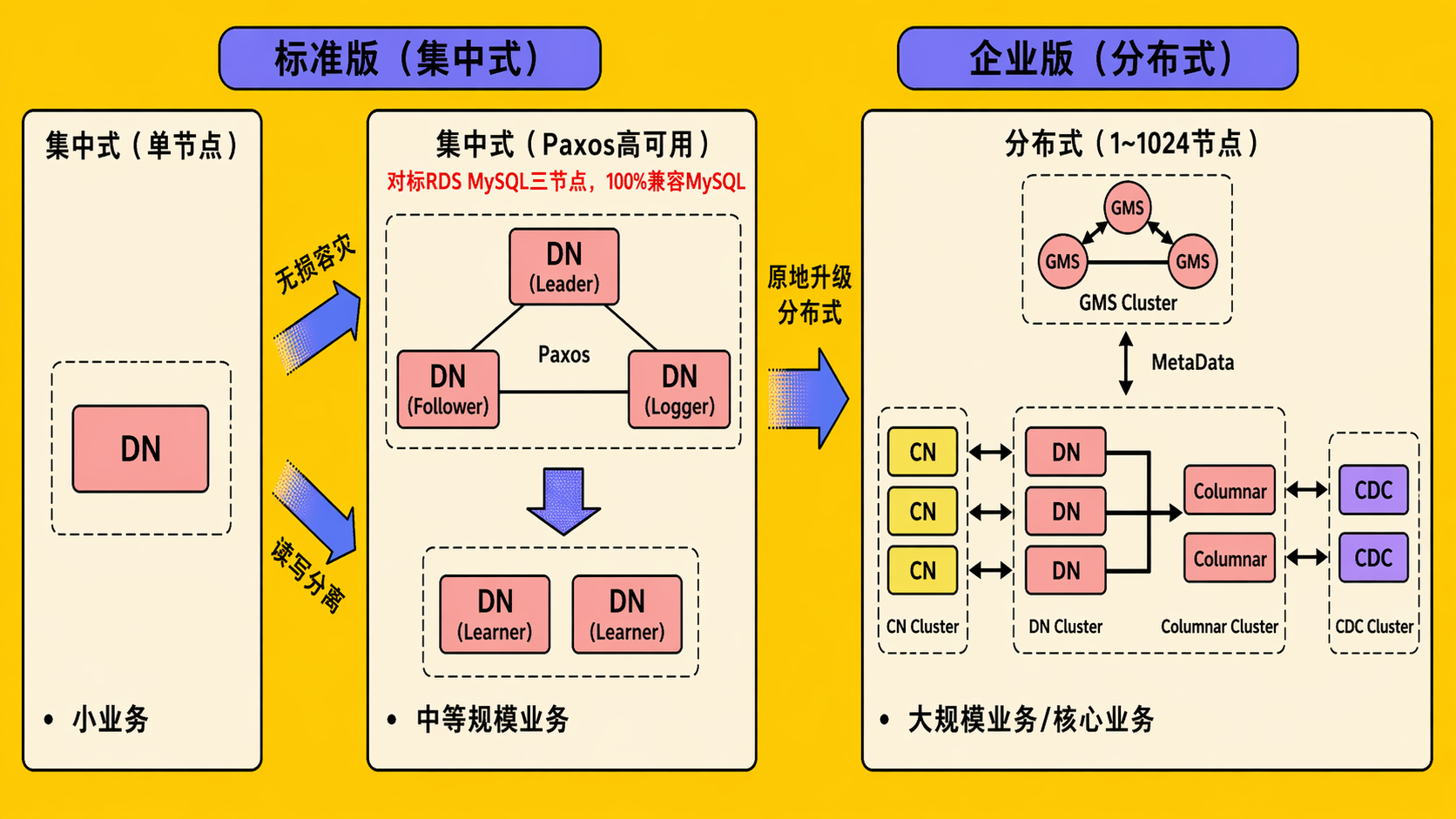
在 OLTP 业务中,唯一键索引(Unique Key Index, UK)是最常见的约束手段之一。业务表上通过 UK 来保证订单号、手机号、身份证号、交易流水号等关键字段的唯一性,是数据完整性的核心保障。然而,InnoDB 当前对 UK 索引的 MVCC 实现方式,在高并发场景下会引发两类让业务头疼的问题:
-
锁等待与死锁:在有 UK 的表上做高并发的插入和更新,业务经常遇到理论上并无关联的两个事务出现锁等待甚至死锁。
-
覆盖索引失效:对 UK 索引做覆盖索引查询时仍然出现回表动作,查询速度不及预期。
这两个问题的根源,都指向 InnoDB UK 索引在多版本管理上的设计局限。针对这一问题,PolarDB-X DN 存储引擎设计了 Panda Index——一种赋予 UK 索引原生多版本能力的新一代唯一键索引结构,从根本上解决了 UK 的锁范围扩大化与可见性判断依赖回表的问题。
InnoDB UK 索引的 MVCC 困境
数据库 MVCC 的两种历史版本存储方式
要理解 UK 索引的问题,首先需要了解 MVCC 中历史版本的存储方式。主流 TP 数据库对主表数据的历史版本存储大致分为两种范式:
|
PG: 追加写存储 (Append-only Storage) |
InnoDB/Oracle: 回滚段存储(Rollback Segment Storage) |
|
|
特点 |
多版本物理平铺:历史版本不动,新版本插入新位置 |
原地更新(In-place Update): 最新版本直接覆盖历史版本 |
|
历史版本位置 |
数据表空间 |
独立的 UNDO 表空间 |
|
历史版本记录形态 |
完整记录:每个版本都是完整 Tuple,可以自解释 |
增量补丁 (Delta) :只记录被修改记录的差异 |
|
历史版本空间管理 |
空间易膨胀:依赖 Vacuum 机制后台扫描数据表空间进行清理 |
空间更紧凑:Undo 段可循环利用,Purge 可以做精准清理,效率高得多 |
|
历史版本读取 |
读取极快:直接读取完整 Tuple,且不需要额外 IO |
读取较慢:需要额外的 UNDO Page IO,且需应用 Delta 构建完整 Tuple |
|
更新对索引的影响 |
写放大显著:最新版本物理位置变化,所有索引必须修改(在未触发 HOT 更新时) |
写稳定性好:主表数据原地更新,索引逻辑指针不变 |
InnoDB 在聚簇索引上采用的是回滚段方式:每条记录包含 TRX_ID(事务 ID)和 ROLL_PTR(指向 Undo 链的指针),修改时先写 Undo 日志,再原地更新记录本身。历史版本通过 Undo 链追溯,B+tree 上始终只保留当前最新版本,结构简洁高效。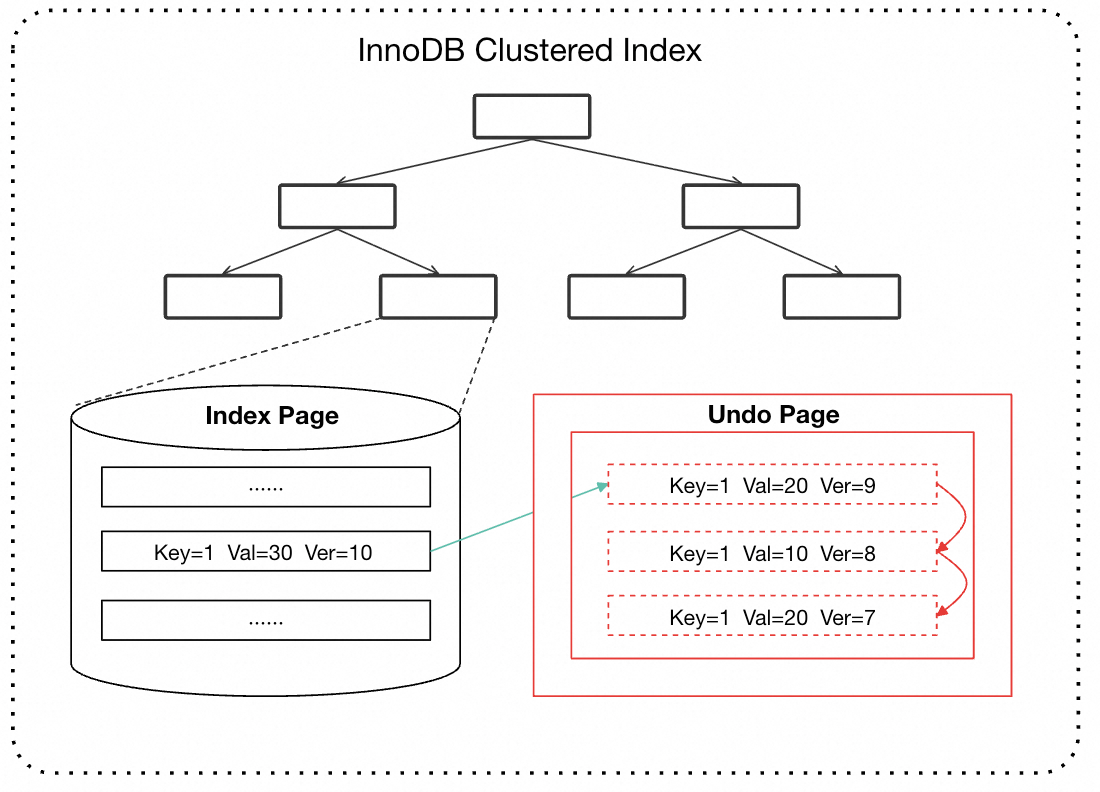
InnoDB 聚簇索引版本链示意图
UK 索引的"多版本物理平铺"问题
然而,InnoDB 的二级索引(包括 UK)并没有采用与聚簇索引相同的版本管理策略。二级索引上不包含 TRX_ID 和 ROLL_PTR,没有版本信息,也没有 Undo 链。当一条 UK 记录需要被更新时,InnoDB 采用的是 Delete-mark + Insert 的方式:先在旧记录上打一个删除标记,再插入一条新记录。
这意味着在 UK 索引的 B+tree 上,相同唯一键值可能同时存在多条物理记录——一条被标记删除的旧版本和一条新版本。在 Purge 线程清理之前,这些历史版本会一直残留在索引结构上。
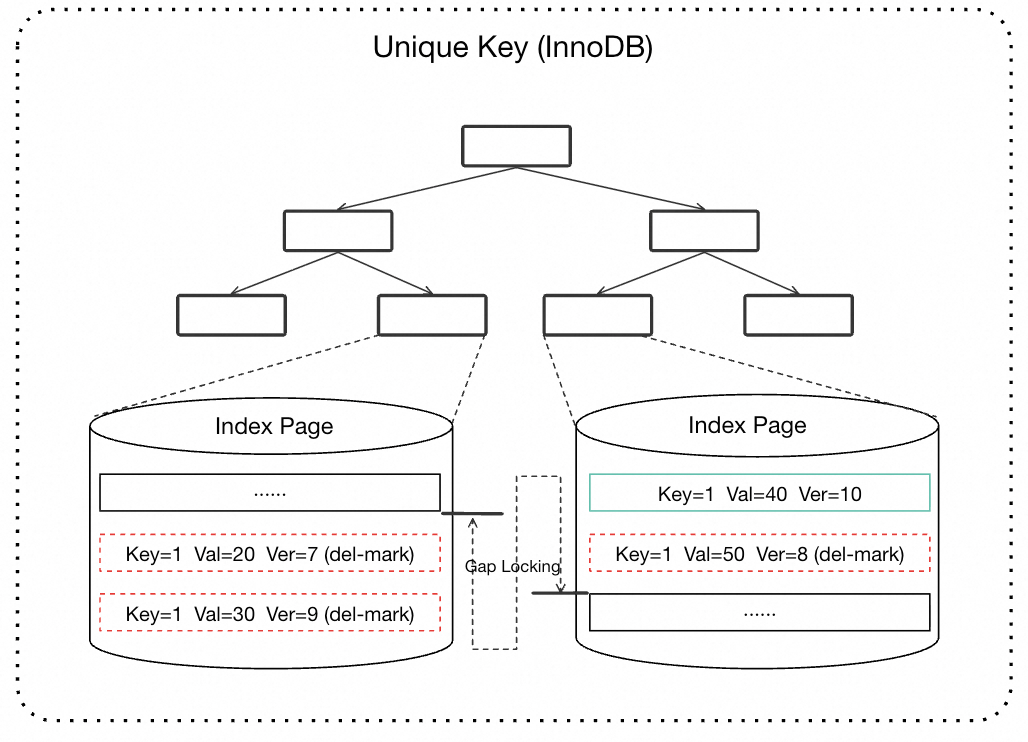
InnoDB 二级索引多版本存储示意图
这种"多版本物理平铺"的方式带来了三个层面的问题:
GAP 锁范围扩大化
在 InnoDB 的加锁协议中,为了在多版本平铺的 UK 索引上保证唯一性约束(Insert 冲突检查),系统不得不在相同 Key 值的多个物理版本记录上施加 GAP 锁。
考虑这样的场景:事务 A 删除了 uk_col = 10 的记录,此时 B+tree 上该记录变为 delete-marked 状态;事务 B 尝试插入 uk_col = 10,需要检查是否存在冲突。由于索引上可能存在多条相同 UK 值的物理记录(当前版本、已删除但未 purge 的版本),插入冲突检测必须扫描所有这些记录并在相应的区间上加 GAP 锁。
结果就是:原本不冲突的事务因锁范围重叠而陷入等待甚至死锁。这不仅降低了系统的并发吞吐量,也给业务侧的 SQL 逻辑设计带来了极大的不确定性与困扰。这在交易系统、余额扣减、限时抢购等高并发 UK 更新场景中尤为突出。
可见性判断完全依赖回表
由于 InnoDB 二级索引不包含版本信息,纯索引扫描(Index-only Scan)在需要判断可见性时是无法独立完成的。即使查询的所有列都在 UK 索引中(理论上可以走覆盖索引),MVCC 查询仍然必须回到聚簇索引的记录和 Undo 链中检查版本信息,才能判断记录是否对当前事务可见。
此外,在隐式锁判断(Implicit Lock Detection)和 Purge 路径上,系统同样需要触发回表动作来获取事务信息。这些额外的回表操作对 Buffer Pool 和 IO 资源造成不必要的压力。
Purge 延迟导致的性能退化
Delete-marked 的 UK 记录需要等 Purge 线程异步清理。在写入密集的业务中,Purge 可能跟不上删除速度,导致 UK 索引上积累大量标记删除的记录。这些残留记录不仅浪费空间,还会增加后续插入时冲突检测的扫描范围,进一步加剧锁争抢和延迟。
Panda Index 设计
核心思想
Panda Index 的核心思想是:把聚簇索引独有的多版本管理能力下沉到 UK 索引。
具体来说,Panda Index 在传统 UK 索引记录的基础上,融合了聚簇索引的事务信息列和版本链,使 UK 索引拥有了原生的多版本能力。
这一设计带来了两个根本性的变化:
-
更新方式的转变:传统的 Delete-mark + Insert 替换为原地更新 + 历史版本记录在 Undo,消除了 B+tree 上同一唯一键多个物理记录共存的根源。
-
可见性判断的自主化:UK 索引记录上直接携带了事务信息,不再需要回表到聚簇索引去获取版本信息。
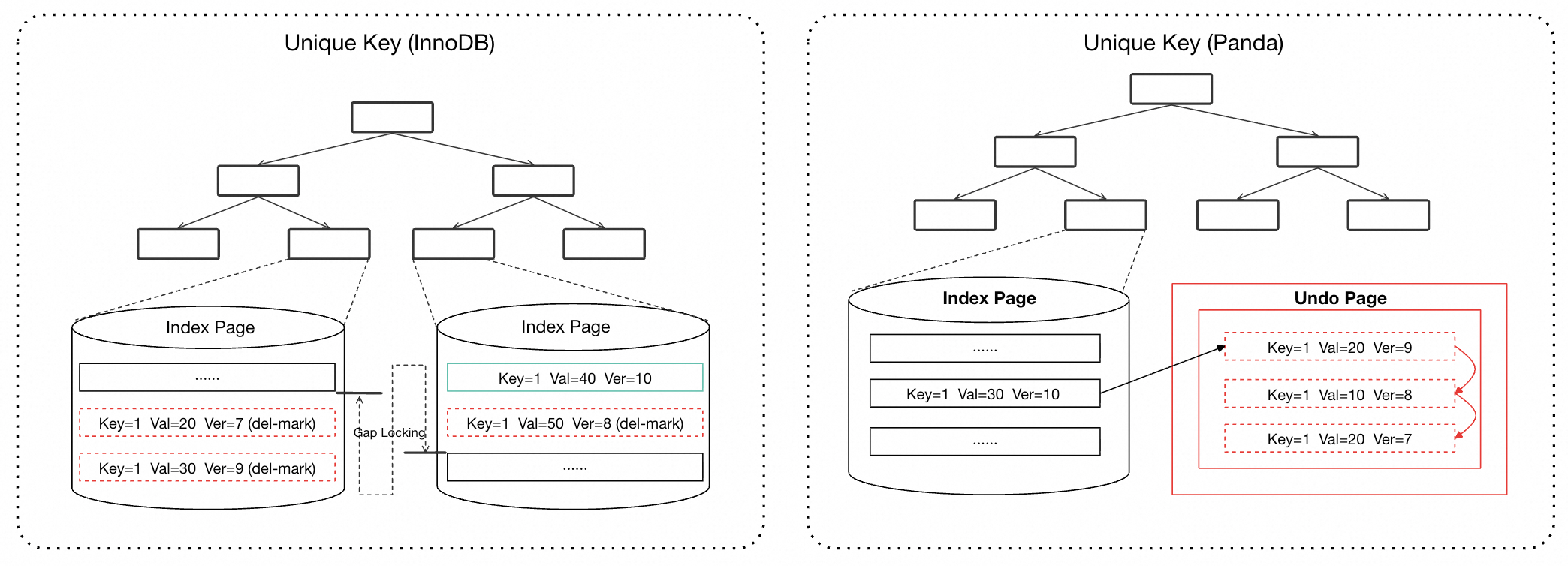
Panda Index 与普通 UK 索引的对比图
记录格式
Panda Index 在传统 UK 记录的基础上增加了 4 个系统列:
|
系统列 |
含义 |
|
TRX_ID |
最近修改该记录的事务 ID,用于判断事务状态 |
|
ROLL_PTR |
指向 Panda Index 自己独立的 Undo 记录,用于引导出历史版本 |
|
SCN |
Lizard 事务系统的提交序列号,用于可见性判断 |
|
UBA |
Undo Block Address,事务槽地址,用于可见性判断 |
其中,TRX_ID / SCN / UBA 的语义与聚簇索引记录中的一致,使得 Panda Index 可以复用 Lizard 事务系统既有的可见性判断框架(Vision)。而 ROLL_PTR 指向的是 Panda Index 自己独立的 Undo 记录——这与聚簇索引的 Undo 链是完全独立的两条链,可以据此找到当前记录对应的所有历史版本。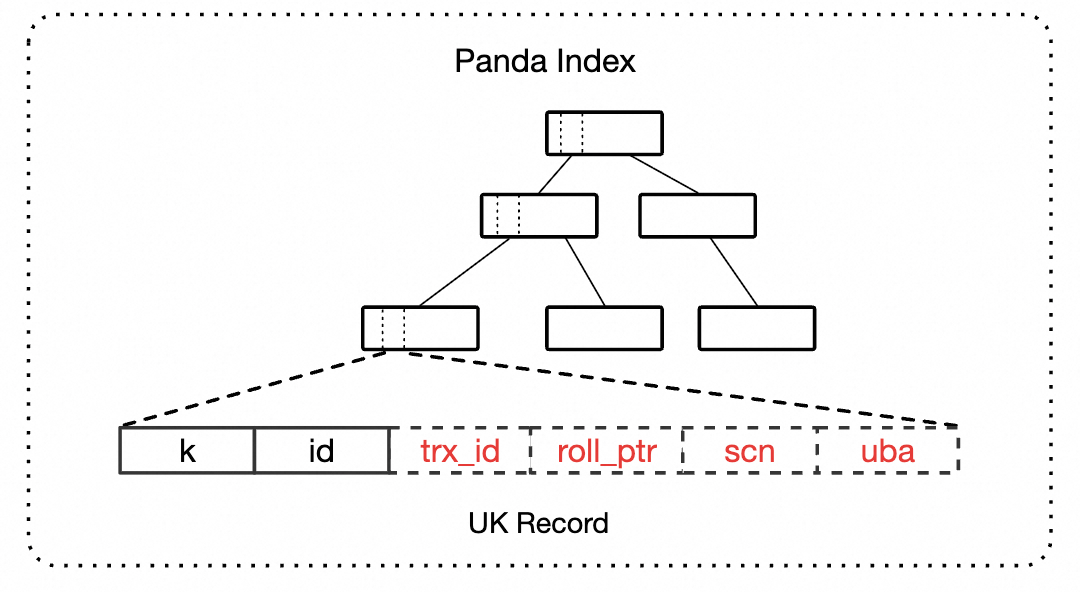
Panda Index 记录格式
原地更新:消除多版本平铺
Panda Index 记录拥有 ROLL_PTR 的基础上,记录的更新不再需要通过 Delete-mark + Insert 的方式将历史版本保留在数据页上。更新动作向聚簇索引看齐:
-
记录 Undo:先为 Panda Index 写一条独立的 Undo 记录,保存记录的旧版本信息。
-
原地修改:直接在原记录上修改数据内容,同时将 Undo 地址保存在 ROLL_PTR 字段。
这种设计将历史版本和当前版本在空间上彻底分离:
-
B+tree 索引结构上只保留当前版本,没有大量残留的标记删除记录给记录扫描和加锁带来额外代价。
-
历史版本全部放在独立的 Undo 表空间,交给 Purge 系统管理,并可以通过 ROLL_PTR 轻松引导出任意历史版本,无需回表。
Insert 冲突检测优化
原地更新能力带来了一个重要的衍生收益:相同唯一键在索引上只能存在一条物理记录。
这使得 Insert 冲突检测的逻辑大幅简化:
-
传统 UK:需要扫描索引上所有可能插入相同唯一键的记录(包括 delete-marked 的),并在整个区间上加 GAP 锁,以防止并发事务插入重复键。
-
Panda Index:如果索引中不存在与待插入键相同的键值,则直接插入成功;如果存在,则只对那一条记录加记录锁(Record Lock),并进一步根据其是否为 Delete-marked 来判断是否真正冲突。
整个过程无需 GAP 锁,缩小了加锁范围,显著降低了高并发场景下 UK 操作的死锁概率。
独立的 Undo 系统
Panda Index 拥有完全独立的 Undo 日志体系,不与聚簇索引共享 Undo 链。这意味着在以下关键路径上,Panda Index 都有自驱动的独立处理逻辑:
-
正向 DML:每次修改 Panda Index 记录时,独立记录 Undo 日志,与聚簇索引的 Undo 写入是分开进行的。
-
Rollback:事务回滚时,Panda Index 的 Undo 记录被独立应用,回滚逻辑不依赖聚簇索引。
-
Purge:后台 Purge 线程对 Panda Index 的 delete-marked 记录有独立的清理路径,通过 ROLL_PTR 验证记录版本后执行物理删除。
独立 Undo 系统的设计避免了 UK 索引与聚簇索引在版本管理上的耦合,使得 Panda Index 的版本生命周期管理完全自洽。
可见性判断
Panda Index 记录上直接携带了 TRX_ID、SCN、UBA 等事务信息,使得可见性判断可以在索引本地完成,不再依赖回表。
与 Lizard 事务系统的聚簇索引路径类似,Panda Index 的一致性读路径为:
-
从记录上读取事务信息(TRX_ID、SCN、UBA)。
-
通过 Lizard Vision 框架判断记录对当前事务是否可见。
-
若当前版本不可见,通过 ROLL_PTR 追溯 Undo 链,构建历史版本。
整个过程完全在 Panda Index 的 B+tree 内部完成,无需任何回表操作。这使得 Panda Index 上的覆盖索引查询能够真正实现 Index-only Scan,同时隐式锁判断等路径也不再需要访问聚簇索引。
验证效果
通过一个简单的并发场景即可直观感受 Panda Index 消除 GAP 锁的效果。
数据准备:
CREATE TABLE t1(
id int,
c1 int,
PRIMARY KEY(id),
UNIQUE KEY uk1(c1)
);
INSERT INTO t1 VALUES (1, 1);
INSERT INTO t1 VALUES (100, 100);
并发测试:
Session 1 执行一笔"先删后插"操作(事务未提交):
BEGIN;
DELETE FROM t1 WHERE id = 1;
INSERT INTO t1 VALUES (2, 1);
Session 2 插入一条不冲突但位于间隙内的数据:
INSERT INTO t1 VALUES (3, 2);
普通 UK 的表现: Session 2 的插入操作会因等待 Session 1 持有的 GAP 锁而超时失败。查看锁信息可以观察到 UK 上存在多个 GAP 锁:
SELECT lock_data, lock_mode FROM performance_schema.data_locks WHERE index_name = 'uk1';
+-----------+---------------+
| lock_data | lock_mode |
+-----------+---------------+
| 1, 1 | X,REC_NOT_GAP |
| 1, 1 | S,GAP |
| 100, 100 | S,GAP |
| 1, 2 | S,GAP |
+-----------+---------------+
Panda Index 的表现: Session 2 的插入操作立即成功,因为 Panda Index 不会产生不必要的 GAP 锁:
SELECT lock_data, lock_mode FROM performance_schema.data_locks WHERE index_name = 'uk1';
+-----------+---------------+
| lock_data | lock_mode |
+-----------+---------------+
| 1, 2 | X,REC_NOT_GAP |
+-----------+---------------+

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)