从 PageRank 到 LLM:信息检索四十年,瓶颈又变了
论文标题: LLM-Oriented Information Retrieval: A Denoising-First Perspective
作者: Lu Dai, Liang Sun, Fanpu Cao, Ziyang Rao, Cehao Yang, Hao Liu, Hui Xiong
机构: 香港科技大学 / 香港科技大学(广州)
会议: SIGIR 2026
链接: https://doi.org/10.1145/3805712.3808544 | arXiv: 2605.00505
一个违反直觉的现象
做过 RAG 系统的人大概都有过这样的困惑:明明检索到了包含正确答案的段落,模型的回答却偏了;明明把上下文窗口从 4K 扩到了 128K,效果却没有随之提升,有时甚至更差了。有些时候把检索模块直接关掉,让模型"裸奔"回答,反而比开着检索更靠谱。
这到底是怎么回事?
如果你试图用"检索质量不够高"来解释,那只对了一半。港科大团队最近发表在 SIGIR 2026 上的一篇 Perspective Paper 给出了一个更精准的诊断:问题不在于检索得不够多,而在于检索带进来的噪声太多。 噪声不仅浪费了宝贵的上下文窗口,还会主动误导模型,把它推向错误的推理路径。换言之,在 LLM 作为信息消费者的新范式下,检索系统的首要任务不再是"尽可能多地找到相关文档",而是"尽可能少地引入干扰"。
这个论断听起来简单,但它实际上意味着信息检索这个领域的核心目标需要被重新定义。
信息检索的消费者换人了
要理解这个转变为什么如此根本,不妨先回顾一下信息检索的演化史。论文将其概括为四个时代,每个时代都有各自的核心瓶颈,而瓶颈的迁移构成了一条清晰的主线。
最早期的瓶颈是物理可达性——信息被锁在图书馆和档案室里,你知道它存在但拿不到。Web 时代解决了可达性问题,但带来了新的瓶颈:可发现性——信息虽然就在互联网上,但淹没在海量网页中,需要爬虫、索引、PageRank 来把它捞出来。接着是神经 IR 时代,BM25 能找到关键词匹配的文档却理解不了语义,Dense Retrieval 和 ColBERT 们致力于弥合这道语义鸿沟。
到目前为止,一切都符合我们熟悉的叙事:检索系统越来越聪明,越来越能理解用户想要什么。但论文指出,第四个时代——我们正在经历的这个时代——发生了一件根本性的变化:检索结果的消费者从人类换成了 LLM。

这看起来只是个应用层的变化,实际上它颠覆了整个优化目标。人类浏览搜索结果时,可以快速扫视十几个链接,忽略不相关的,点开有价值的——人类天生是优秀的噪声过滤器。但 LLM 不是。LLM 把所有塞进上下文窗口的文本一视同仁地"阅读",它没有"跳过"机制,没有"这条看起来不太靠谱"的直觉。更糟糕的是,研究已经反复证实,LLM 在处理长上下文时存在明显的注意力偏差——开头和结尾看得仔细,中间部分容易被"遗忘",这就是著名的 Lost in the Middle 现象。
所以我们面对的是一个注意力预算严格有限、且对噪声高度敏感的消费者。给它更多信息未必是帮忙,很可能是添乱。
噪声的破坏力:一组数据
论文用一组简洁有力的实验量化了噪声的破坏力。实验在 500 条 Natural Questions 上测试,每条问题配 100 条 DPR 检索到的段落,其中一些是包含答案的ground-truth段落,其余是噪声。然后系统地调节ground-truth段落和噪声段落的比例,观察 Exact Match(EM)的变化。
结果发现,3 条ground-truth段落时,EM 为 61.0%。保持 3 条ground-truth不变,加入 2 条噪声,EM 降到 51.4%;加入 7 条噪声,降到 41.8%。注意,ground-truth段落一条没少,仅仅是噪声多了,性能就掉了近 20 个百分点。
更极端的情况是:1 条ground-truth + 9 条噪声(信噪比 0.10),EM 跌至 26.6%,仅比闭卷基线的 23.6% 高出一点点。而如果上下文里全是噪声,EM 只有 8.0%——这比不检索还差,说明噪声不仅是"没用的信息",它还在主动压制模型自身的参数记忆。这就好比你本来记得答案,但旁边一群人七嘴八舌地说错误答案,你反而被带偏了。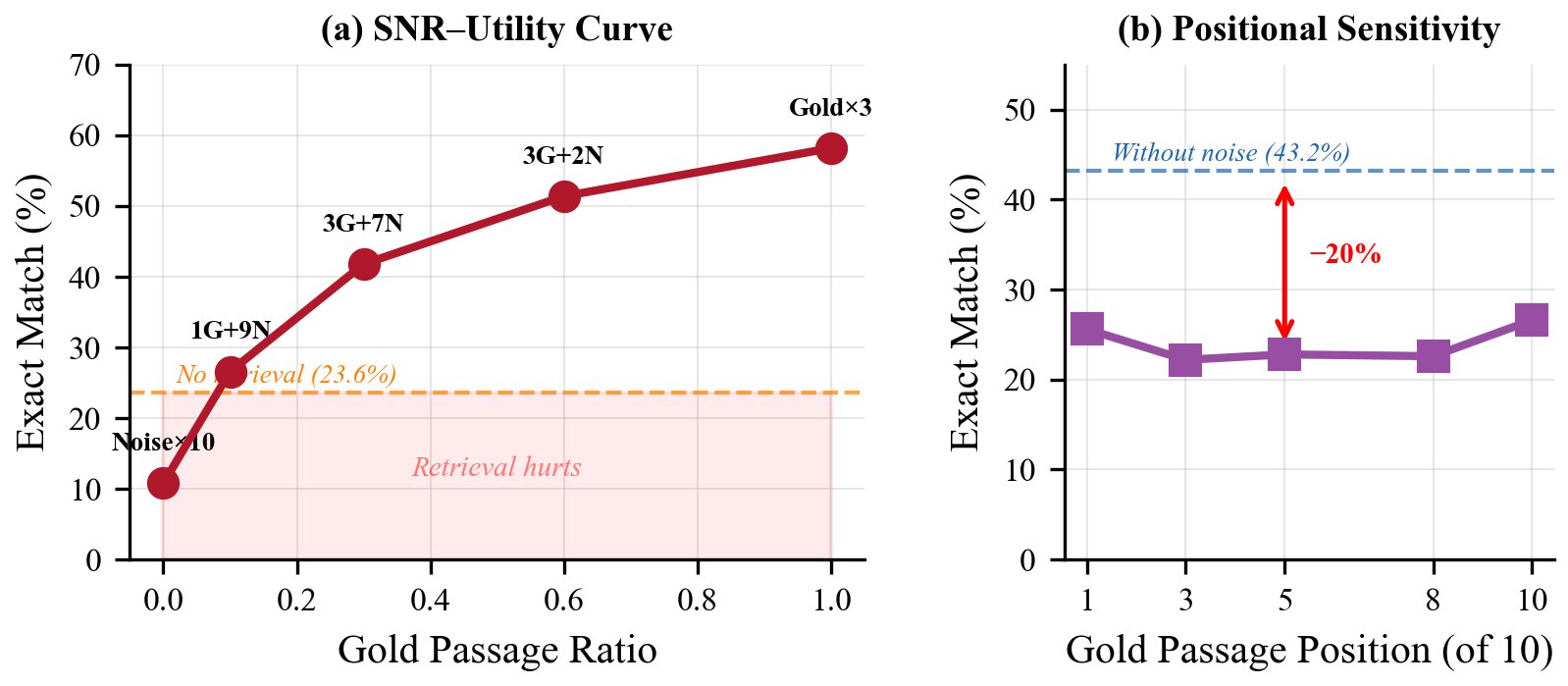
论文中的另一个实验是:固定 1 条ground-truth + 9 条噪声,只改变ground-truth段落在上下文中的位置。结果发现,位置引起的 EM 波动大约 4%,而噪声引起的 EM 下降约 20%。换言之,噪声效应比位置效应大了约 5 倍。 所谓 Lost in the Middle,在很大程度上其实是 Lost in the Noise。
这组实验传达的信息非常清楚:在 LLM-oriented IR 中,少而精远胜多而杂。传统 IR 追求的高召回,在新范式下反而可能是一种负担。
噪声从哪里来?
明确了噪声是核心敌人之后,下一个问题自然是:噪声到底是从哪里混进来的?
论文将噪声的入口归纳为三个层次,这个分类框架笔者觉得相当实用,因为它直接指向了"在哪里动刀"。
第一层是语料本身。 索引池已经不再是一汪清水。重复文档、模板垃圾、过时信息一直是老问题,但 LLM 时代出现了一个新威胁:AI 生成的内容正在大规模涌入互联网。当你用 LLM 生成的文本去训练 LLM,再用新 LLM 生成更多文本,这个闭环最终会导致所谓的 Model Collapse——信息的多样性塌缩,而检索池变成了一个充满同质化幻觉的沼泽。论文用了一个很形象的词:spiral feedback loop(螺旋反馈环)。
第二层是检索器引入的。 即使语料干净,检索器也会带来"hard distractors"——主题相关但事实无关的段落。这类段落在嵌入空间中与查询很接近,但实际上并不支持正确答案。它们是语义上的"近义词",逻辑上的"陷阱"。Dense Retriever 尤其容易被这类陷阱欺骗,因为向量相似度天然无法区分"相关"和"有用"。
第三层是上下文组装阶段。 即使检索器返回了不错的候选集,把它们拼接成一个 prompt 的过程本身也在制造噪声。不同来源的段落可能互相矛盾(时间漂移、观点冲突),朴素的拼接会产生一种 Frankenstein 式的上下文——每一块看起来都合理,拼在一起却自相矛盾。此外,恶意的 prompt injection 攻击也可以通过检索通道注入,让模型执行攻击者的指令而非用户的意图。
这三层噪声不是孤立的,它们会级联放大。论文特别强调了 Agent 和多步推理场景下的级联效应:第一轮检索引入了一条误导信息,模型基于它做出了错误的中间推理,第二轮检索又基于这个错误的中间结果去搜索,找到了更多支持错误方向的"证据"……一个小噪声滚雪球般地演变成了系统性的幻觉。
去噪:从索引到闭环
理解了噪声的来源之后,论文围绕信息流的生命周期构建了一个五阶段的去噪框架。笔者不打算逐一罗列每个阶段的所有方法——那更适合当做一份查阅手册——而是挑几个笔者觉得最有启发性的思路来说。
在索引阶段做减法,而不是加法。 传统思路是尽可能多地索引,然后靠下游来过滤。但论文指出,下游过滤永远无法完全消除上游污染的残余噪声和计算开销。真正有效的做法是在入口处就设关卡:来源不可信的不让进,质量不达标的不让进,过时的标记或清退。例如用C2PA 标准——一种用密码学签名标注内容来源的协议来进行索引治理,或者用LLM水印技术标记AI内容。这相当于给每条信息颁发"身份证",让检索系统可以按可信度分层搜索。
让检索器学会说"不"。 传统检索器被训练成一个"尽职的服务员":你问什么我就尽力找什么。但在 LLM-oriented IR 中,一个更好的检索器应该具备自适应的判断力——当它发现找到的东西都不太靠谱时,应该选择不返回,而不是硬凑一堆勉强相关的结果。这个过程,有一些研究工作用先验的形式作为判断依据,也有最近的工作选择直接通过RL等后训练方法把这种对于噪声的判断能力直接注入到表征里。
上下文组装不是拼接,是策展。 这一点论文论述得很充分。把检索到的段落拼成 prompt,不应该是简单的 concatenation,而应该是一个主动的去噪过程——要做冲突检测(两条证据说的不一样怎么办?)、做冗余压缩(同样的信息说了三遍就留一遍)、做位置优化(重要证据放在模型注意力最集中的位置)。例如Google 的Astute RAG,它让模型先用自己的参数知识对检索结果做可靠性评估,然后迭代地整合,遇到矛盾时优先相信可靠性更高的来源。这其实模拟了一个有经验的研究者阅读文献时的心理过程——不是来者不拒,而是带着判断力去读。
验证是闭环的关键。 去噪不能只靠事前过滤,还需要事后核查。LLM时代,相比于nDCG等传统的搜索评估指标,我们需要更加细粒度/更具有系统视角的评估方案:不仅仅关注搜索的准确度,还有其对整个系统的效用。例如,FactScore 将生成的长回答拆解成原子声明,逐一检查是否有检索证据支撑。这种细粒度归因的思路,把"可验证性"从一个模糊的期望变成了可操作的指标。对于 Agent 系统来说,这一步尤为关键:如果一轮推理的结果经不起事实核查,就应该回退重来,而不是带着错误继续往下走。SePer 设计了一种基于统计学的概率指标,用LLM回答问题时的信息增益来量化检索文档对于LLM的效用,从而直接对齐真实下游任务的需求。
四个场景:噪声如何在实践中作祟
论文还详细分析了四个典型应用中的噪声传播模式,笔者觉得这部分比方法分类更有实践参考价值,因为它展示了噪声在真实系统中是如何"因地制宜"地搞破坏的。
编程 Agent 面对的是一个百万行级别的代码仓库,而 bug 修复可能只涉及一个函数。传统检索在这里几乎一定会失败,因为一个仓库里可能有十几个同名函数分布在不同文件中,继承关系和调用链又把它们搅在一起。SWE-bench 上的一个典型失败模式是:Agent 检索到了 src/legacy/parser.py 而非 src/core/parser.py——两个文件名几乎一样,内容也高度相似,但前者是废弃代码。Agent 兢兢业业地 patch 了错误的文件,测试自然全挂。解法是引入语法感知的索引(比如用 AST 和调用图做硬约束),以及把测试执行作为验证闭环——代码世界有一个独特的优势:你可以跑一下看结果对不对。
长期记忆助手的噪声来源更加微妙。设想一个场景:用户在 2024 年 3 月说"我住在波士顿",6 月说"我搬到西雅图了"。当用户后来问"推荐附近的餐厅"时,朴素的语义检索很可能召回那条更详细的旧记录——因为"我住在波士顿"作为一条完整的陈述,其嵌入向量与"附近"这个查询的匹配度可能更高。结果就是推荐了波士顿的餐厅。这里噪声的本质是时间漂移:过去正确的信息变成了现在的误导。解决之道是给记忆打时间戳、做有效期管理,以及在检索时引入 recency-aware 的排序。
深度研究系统的噪声则体现为级联放大。一个典型的失败链条是:用户问"比较 2025 年中美 PFAS 监管政策",系统将其分解为若干子查询,但其中一条子查询漂移到了"PFAS 对健康的一般影响",检索到一堆与监管无关的医学文献。这些文献被塞进上下文后,模型据此写出了"全球已禁止 PFAS"这样的不实声明,并附上了一条不相关博客作为引用。看起来有理有据,实际上一塌糊涂。论文将此称为 retrieval-utilization gap:即使检索到了好的证据,它也可能被大量干扰项淹没而无法被模型有效利用。
多模态理解则把信噪比问题推向了极端。一段 45 分钟的讲座视频,相关证据可能只占不到 1% 的帧。Video-MME 基准测试显示,模型性能与视频时长呈负相关——越长越差,因为有效信息被越来越多的无关帧稀释了。这里的启示是:对于高熵流数据,"全部输入"不是一个选项,检索本质上是一个时间维度的注意力分配问题。
一些思考
读完这篇论文,笔者最大的感受是:它把一个很多人隐约意识到但没有系统表述的问题说清楚了。RAG 实践者们踩过的那些坑——“检索了反而更差”“上下文越长越乱”“Agent 越走越偏”——在这篇论文的框架下都有了统一的解释:它们的共同根源是噪声在 pipeline 中的累积和放大。
这个视角的实用价值在于,它把一个模糊的"系统效果不好"转化为了一个可以逐层排查的工程问题:噪声是在索引层混进来的?还是检索器引入的 hard distractors?还是上下文组装时的冲突和冗余?抑或是多步推理中的级联放大?每一层都有对应的应对策略,而不是笼统地"换个更好的模型"。
沿着这篇论文的思路,笔者认为停下来思考这些问题,对于LLM时代的搜索研究尤为重要:
其一,信噪比与召回率之间的 trade-off 如何系统性地建模? 能否在检索阶段就预测一组候选的信噪比,并据此动态调整返回数量?这可能需要一种新的检索目标函数,显式地惩罚噪声而非仅仅奖励相关性。
其二,去噪本身的代价问题。 很多去噪方法——LLM-based reranking、abstractive compression、conflict-aware prompting——本身都需要额外的 LLM 调用。如果去噪步骤本身消耗的计算量与直接把噪声扔给模型处理相当,那去噪的工程合理性就值得斟酌。一个理想的去噪方案应该是"轻量级的、前置的、可并行的",而不是"再套一层 LLM"。
其三,也是笔者觉得最深远的问题:当互联网的索引池被 AI 生成内容大面积污染,传统的"外部知识增强"范式本身是否需要重构? 如果你检索到的"外部知识"本身就是另一个 LLM 的幻觉产物,那 RAG 就从"用知识纠正幻觉"退化成了"用幻觉增强幻觉"。论文提到的 C2PA 签名、水印检测、合成内容归因等手段是一条路,但这条路的终点可能不只是"更好的过滤",而是信息检索整个范式的根本性反思。
在 LLM 时代,检索系统应该是一扇噪声门(noise gate),而不是一个信息水龙头。 打开水龙头容易,控制水质才难。
👇关注公众号NLP PaperWeekly,及时获取最新前沿资讯👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)