OS77.【Linux】线程互斥(6) 基于阻塞队列的单生产者-单消费者模型(初步版本)
目录
5.代码: 基于阻塞队列的生产者-消费者模型(单生产者,单消费者)
想实现基于阻塞队列的生产者-消费者模型,先理解什么是生产者-消费者模型
1.生活中的例子
现有供货商、超市、消费者这3三种角色
从下图可以看出,供应商向超市进货,消费者从超市中买货; 有多个供应商; 有多个消费者
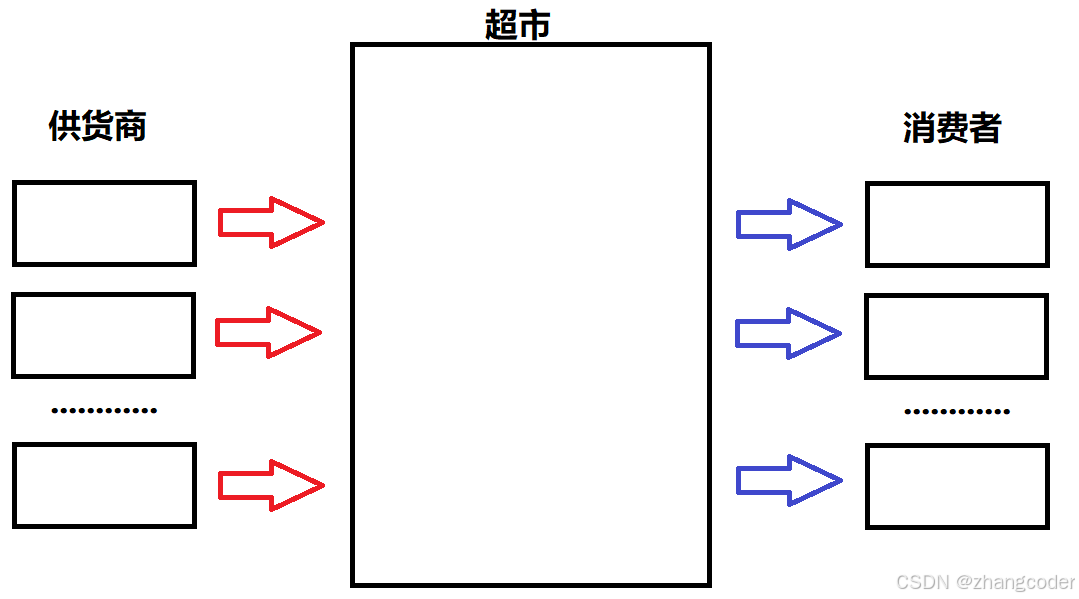
不能只有供货商和消费者,超市的存在是为了提高效率
例如,在超市还有货时,消费者可以直接买货,消费者不需要等供应商供货; 过年了,供货商放假,但是消费者仍然在消费,此时超市的作用就来了,消费者可以买超市的存货
2.将生活中的例子对应到生产者-消费者模型中
上方"供货商-超市-消费者"的例子对应到操作系统中: 生产者和消费者都对应线程,生产者生产数据,消费者消费数据,超市是特定结构的内存空间(可以是队列,也可以是堆结构等等)
结论1(优点)
得出结论: 超市是存储供货商提供的货,起到了临时缓存的作用,支持忙闲不均,是生产者-消费者模型的优点
结论2(优点)
供货商相当于生产者,生产者在生产时(不是发货到超市)和消费者没关系,消费者使用商品和生产者没关系
生产者-消费者模型就是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过特定结构的内存空间来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给该内存空间,消费者不找生产者要数据,而是直接从该内存空间里取,该内存空间就相当于一个缓冲区,平衡了生产者和消费者的处理能力
这个内存空间就是用来给生产者和消费者解耦的
耦合度高的场景: 比如main函数里面会调用add函数, main函数为add函数提供参数,那么main函数是生产者,add函数拿到参数做计算,那么add函数是消费者,当add函数在做计算时, main函数无法执行
生产者和消费者解耦: main函数变成主线程,add函数变成新线程, 让main函数向特定内存空间写参数, 让add函数向该内存空间读参数, 该内存空间充当缓存数据的角色,同时保证该内存空间的安全,这样可以提高效率
得出结论: 生产和消费的行为,进行一定程度的解耦,是生产者-消费者模型的优点
结论3
得出结论: 生产者-消费者模型的背后是执行流在做通信
结论4
生产者能向特定结构的内存空间生产数据,消费者能向特定结构的内存空间消费数据的前提是: 生产者和消费者有能力访问到该内存空间
如何安全高效的通信?
超市的货物数量是浮动的,可能为0,可能为满
那么供货商关心超市的空闲位置的数量,而消费者关心存货数量
对应到生产者、特定结构的内存空间、消费者上:
由于该内存空间是共享资源,如果不加保护,那么生产者和消费者的访问会有并发问题,看以下3种关系
3种关系
生产者vs生产者:
从商业角度看,同行之间是竞争关系,那么必须保证他们是互斥访问的(生产者要么生产要么没有生产,保证数据的安全)
消费者vs消费者:
竞争关系,早来的消费者就早得到数据
生产者vs消费者:
为了保证内存空间数据的安全,防止出现数据不一致的问题.需要让生产者和消费者是互斥访问的
生产者必须生产一部分,就让消费者消费一部分,也就是同步,不能出现生产者频繁访问超市而消费者轮不到的情况,否则样会导致内存空间变满; 同理也不能出现消费者频繁访问超市而轮不到生产者的情况,否则样会导致内存空间变空
记忆生产者-消费者模型的方法: "123原则"
1个交易场所 → 特定结构的内存空间
2种角色 → 生产者和消费者
3种关系 → 生产者vs生产者、消费者vs消费者、生产者vs消费者
面试时直接按"123原则"的思路介绍就行
4.面试回答: 如何理解生产者-消费者模型?
2025百度搜索架构日常实习https://www.nowcoder.com/discuss/353159486732967936
感谢草莓蛋挞冰淇淋牛友提供面试题!

作答:生产者-消费者模型(Producer-Consumer Model)是多进程或多线程的的一种同步互斥的策略,除了生产者、消费者这两个角色,还有特定结构的内存空间(1个交易场所 → 特定结构的内存空间、2种角色 → 生产者和消费者)
生产者的任务是向该内存空间写入数据,消费者的任务是向该内存空间读取数据
如果不对该内存空间做保护,会出现以下问题:
1.生产者和消费者同时访问该内存空间,生产者的数据还没写完,消费者就来读取数据,引发数据不一致的问题
极端问题:
2.生产者频繁向该内存空间写入数据,而消费者没有机会读取数据,导致内存空间为满的问题
3.消费者频繁向该内存空间读取数据,而生产者没有机会写入数据,导致内存空间为空的问题
解决上述问题的方法是理清生产者和消费者之间的关系,排列组合一共有3种:
(3种关系 → 生产者vs生产者、消费者vs消费者、生产者vs消费者)
生产者vs生产者:
从商业角度看,同行之间是竞争关系,那么必须保证他们是互斥访问的(生产者要么生产要么没有生产,保证数据的安全)
消费者vs消费者:
竞争关系,早来的消费者就早得到数据
生产者vs消费者:
为了保证内存空间数据的安全,防止出现数据不一致的问题.需要让生产者和消费者是互斥访问的
生产者必须生产一部分,就让消费者消费一部分,也就是同步,不能出现生产者频繁访问超市而消费者轮不到的情况,否则样会导致内存空间变满; 同理也不能出现消费者频繁访问超市而轮不到生产者的情况,否则样会导致内存空间变空
*注:互斥含义: 为了保证超市货物的安全,不能让厂家和消费者同时访问该内存空间
同步含义: 必须生产一部分,再消费一部分,让生产者和消费者按照一定的顺序访问该内存空间
追问: 该模型的优点?
作答: 解耦、支持并发、支持忙闲不均,理由见本文上方
5.代码: 基于阻塞队列的生产者-消费者模型(单生产者,单消费者)
由于是初步实现,这里仅实现单生产者、单消费者,这里降低难度,之后的文章会改成多生产者、多消费者
这里借用一下cywosp博主基于C++11的阻塞队列简单实现文章的图:
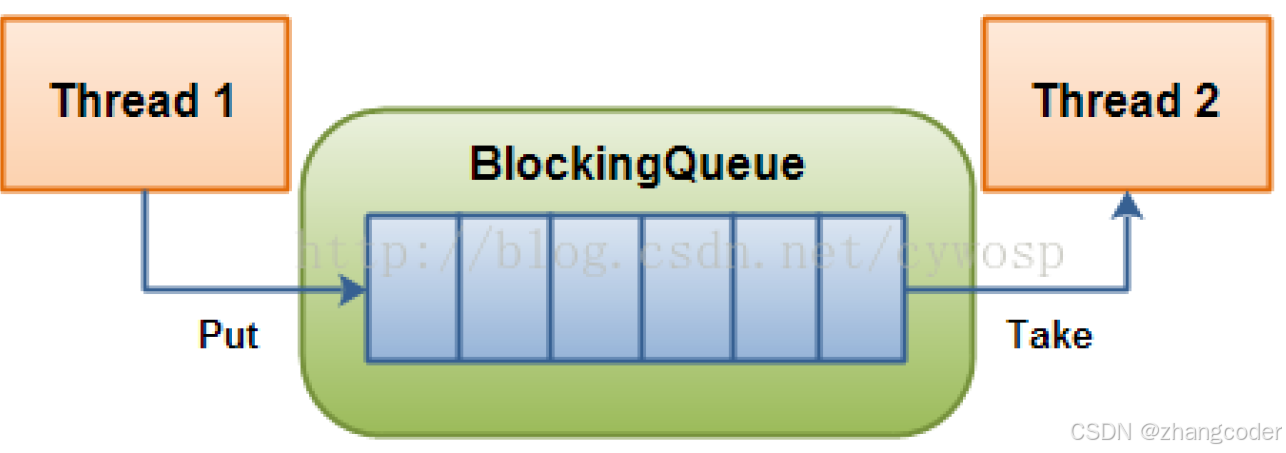
为什么用阻塞队列?
生产者把队列生产满了,就被阻塞; 同理,消费者把队列消费空了, 就被阻塞
准备工作
新建以下文件:
producer_consumer_blocking_queue/
├── makefile
└── project.cppmakefile写入:
project.out:project.cpp
g++ -o $@ $^ -g -std=c++11 -lpthread
.PHONY:clean
clean:
rm -f project.cpp.out 代码
阻塞队列可以用C++ STL库的queue容器实现,虽然queue可以扩容,但是真实的阻塞队列是有最大容量的,那么:
template <class T>
class blocking_queue
{
public:
//......
private:
std::queue<T> _q;//使用STL库的queue容器
size_t _max_capacity;//最大容量
};生产者的任务是向阻塞队列写入数据,消费者的任务是向阻塞队列内存空间读取数据,前提是: 生产者和消费者都能看到阻塞队列,解决方法: 线程需要在线程函数中执行,那么只需要让主线程将阻塞队列的地址传给线程函数就行
由于是"单生产者,单消费者",那么只需要主线程创建两个线程即可,一个执行写入数据的produce线程函数,另一个执行读取数据的consume线程函数
void* produce(void* args)
{
//......
return nullptr;
}
void* consume(void* args)
{
//......
return nullptr;
}
int main()
{
blocking_queue<int>* bq=new blocking_queue<int>();
pthread_t producer,consumer;
pthread_create(&producer,nullptr,produce,bq);
pthread_create(&consumer,nullptr,consume,bq);
pthread_join(producer,nullptr);
pthread_join(consumer,nullptr);
delete bq;
return 0;
}实现produce函数
produce正常将数据入队列,上层使用者不需要关心阻塞队列的底层实现
这里向队列中插入随机数据:
void* produce(void* args)
{
blocking_queue<int>* bq=static_cast<blocking_queue<int>*>(args);
for (;;)
{
int data=rand()%10;
bq->push(data);
printf("生产者生产了数据%d\n",data);
}
return nullptr;
}实现consume函数
consume正常将数据出队列,同理,上层使用者不需要关心阻塞队列的底层实现
void* consume(void* args)
{
blocking_queue<int>* bq=static_cast<blocking_queue<int>*>(args);
for (;;)
{
int data=bq->pop();
printf("消费者消费了数据%d\n",data);
}
return nullptr;
}实现blocking_queue类
之前在OS75.【Linux】线程互斥(3) 线程安全、重入文章讲过STL库的容器不是线程安全的,需要自己保证容器的线程安全: 互斥(用锁)+同步(用条件变量)
定义以下几个私有成员变量:
(这里暂时定义1个条件变量,其实应该定义2个,后面会说到这个问题)
std::queue<T> _q;
size_t _max_capacity;
pthread_mutex_t _lock;
pthread_cond_t _cond;构造函数
只传入一个参数,标识最大容量,这里写成缺省参数
初始化锁和条件变量,全部初始化为默认属性,填nullptr
blocking_queue(size_t max_capacity=5)
:_max_capacity(max_capacity)
{
pthread_mutex_init(&_lock,nullptr);
pthread_cond_init(&_cond,nullptr);
}析构函数
销毁锁和条件变量,清空阻塞队列
~blocking_queue()
{
pthread_mutex_destroy(&_lock);
pthread_cond_destroy(&_cond);
while(!_q.empty())
_q.pop();
}push函数
向队列中入数据,即访问临界资源
为了防止数据不一致的问题,必须先加锁后才能访问临界资源,这样queue才是线程安全的
void push(const T& obj)
{
pthread_mutex_lock(&_lock);
_q.push(obj);
pthread_mutex_unlock(&_lock);
}上面的代码有问题,有可能不满足生产条件,如果队列满了,是无法入数据的,此时不能直接返回(这个很重要! 容易错!),生产者需要等待消费者消费后,才能入数据
如果队列满了,那么就把生产者线程放到条件变量下的等待队列中排队,即被阻塞
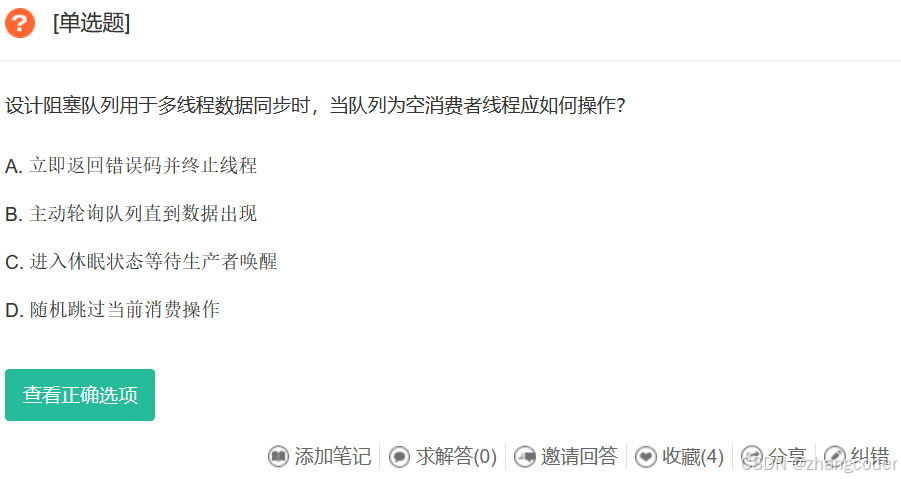
牛客网上的一道题就考了这个思想:
https://www.nowcoder.com/questionTerminal/3db64f3d94154bc09d0115ec2fb7b2c5
答案选C,不解释了
void push(const T& obj)
{
pthread_mutex_lock(&_lock);
if (_q.size()==_max_capacity)
pthread_cond_wait(&_cond,&_lock);
_q.push(obj);
pthread_mutex_unlock(&_lock);
}pthread_cond_wait会自动释放锁,这样消费者就能取得锁访问阻塞队列了,等到消费者阻塞后,生产者接着继续执行pthread_cond_wait,重新获得之前释放的锁
*if (_q.size()==_max_capacity)必须在pthread_mutex_lock执行,因为判断临界资源是否就绪也在访问临界资源
pop函数
下面这样写可以吗?
T& pop()
{
pthread_mutex_lock(&_lock);
if (_q.empty())
pthread_cond_wait(&_cond,&_lock);
auto& obj=_q.front();
_q.pop();
pthread_mutex_unlock(&_lock);
return obj;
}★★★push和pop不能用一个条件变量
上面的代码不对,push和pop不能用一个条件变量,push函数中的pthread_cond_wait(&_cond,&_lock)的_cond是和生产者等待队列一起的,也就是说,_cond用于生产者排队
所以pop要另外设置一个条件变量,这样方便唤醒消费者,否则多消费者、多生产者的情况下会出问题
结论: 设置两个条件变量,一个用于生产者的等待队列,一个用于消费者的等待队列
设置两个条件变量就不会出问题:
pthread_cond_t _p_cond;//生产者的条件变量
pthread_cond_t _c_cond;//消费者的条件变量类改为:
template <class T>
class blocking_queue
{
public:
blocking_queue(size_t max_capacity=5)
:_max_capacity(max_capacity)
{
pthread_mutex_init(&_lock,nullptr);
pthread_cond_init(&_p_cond,nullptr);
pthread_cond_init(&_c_cond,nullptr);
}
T& pop()
{
pthread_mutex_lock(&_lock);
if (_q.empty())
pthread_cond_wait(&_c_cond,&_lock);
auto& obj=_q.front();
_q.pop();
pthread_mutex_unlock(&_lock);
return obj;
}
void push(const T& obj)
{
pthread_mutex_lock(&_lock);
if (_q.size()==_max_capacity)
pthread_cond_wait(&_p_cond,&_lock);
_q.push(obj);
pthread_mutex_unlock(&_lock);
}
~blocking_queue()
{
pthread_mutex_destroy(&_lock);
pthread_cond_destroy(&_p_cond);
pthread_cond_destroy(&_c_cond);
while(!_q.empty())
_q.pop();
}
private:
std::queue<T> _q;
size_t _max_capacity;
pthread_mutex_t _lock;
pthread_cond_t _p_cond;//生产者的条件变量
pthread_cond_t _c_cond;//消费者的条件变量
};注: if (_q.size()==_max_capacity) {pthread_cond_wait(&_p_cond,&_lock);}和if (_q.empty())
{pthread_cond_wait(&_c_cond,&_lock);}其实在多消费者、多生产者的情况下会出问题,这个之后文章再说
何时唤醒在两个等待队列中的生产者和消费者?
答: 看条件是否满足
唤醒等待队列中的生产者的时机: 如果消费者能消费了数据,那么生产者一定可以生产
唤醒等待队列中的消费者的时机: 如果生产者能生产了数据,那么消费者一定可以消费
这里不需要主线程唤醒
push和pop改为:
T& pop()
{
pthread_mutex_lock(&_lock);
if (_q.empty())
pthread_cond_wait(&_c_cond,&_lock);
auto& obj=_q.front();
_q.pop();
pthread_cond_signal(&_p_cond);
pthread_mutex_unlock(&_lock);
return obj;
}
void push(const T& obj)
{
pthread_mutex_lock(&_lock);
if (_q.size()==_max_capacity)
pthread_cond_wait(&_p_cond,&_lock);
_q.push(obj);
pthread_cond_signal(&_c_cond);
pthread_mutex_unlock(&_lock);
}运行结果
生产和消费旗鼓相当
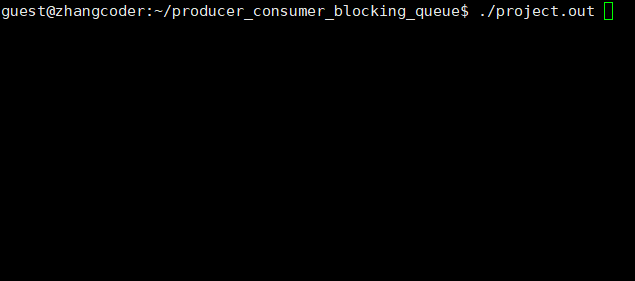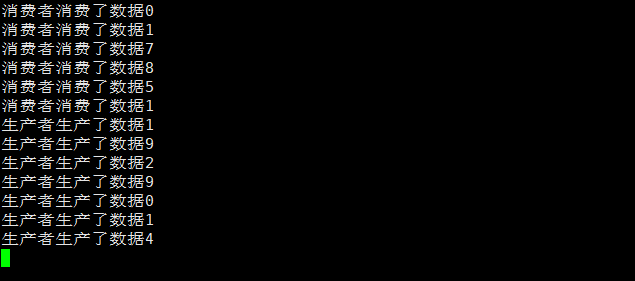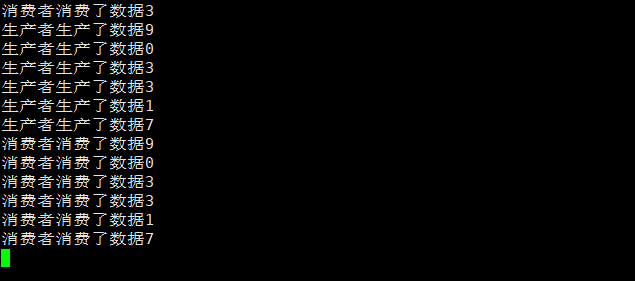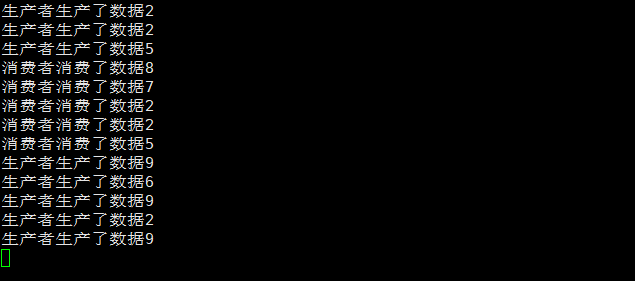
生产速度慢于消费速度
让produce睡眠一段时间即可
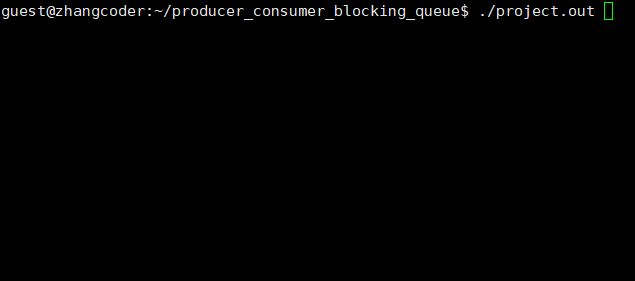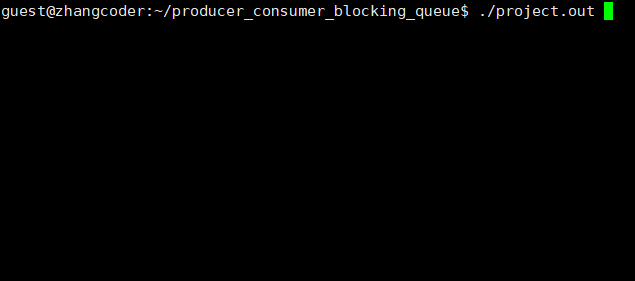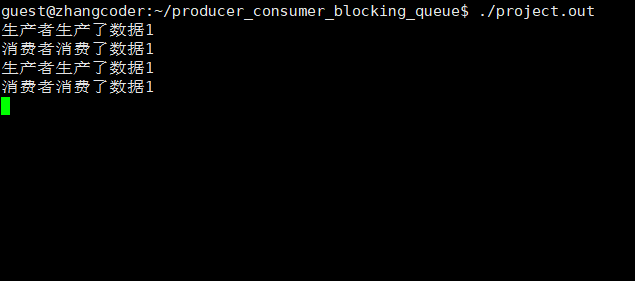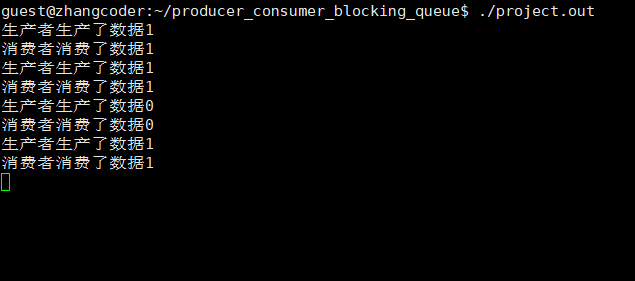
从运行结果看,一定是生产者线程先执行(同步!),因为消费者没有数据可以消费
生产速度快于消费速度
让consume睡眠一段时间即可
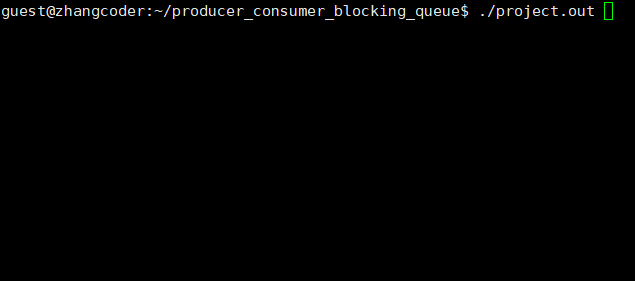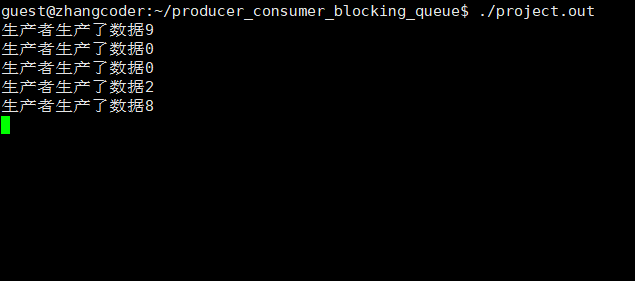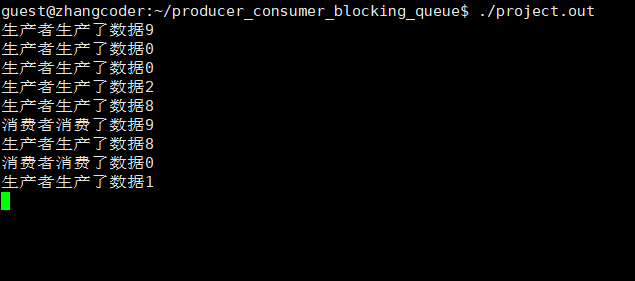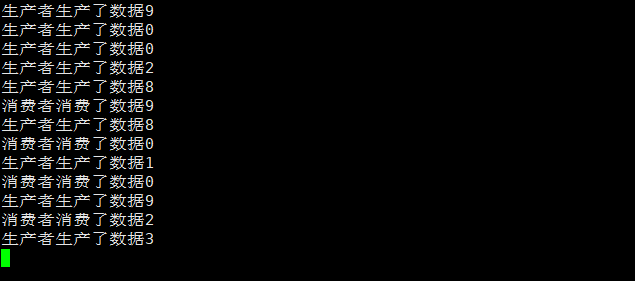
从运行结果看,一瞬间生产一批,但是消费很慢

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)