AI Agent 记忆系统架构设计:OpenClaw、Claude Code、Hermes Agent 深度对比
文章目录
记忆是 Agent 从“无状态工具”进化为“持续智能体”的核心基础设施。如果说大模型是 Agent 的大脑,那么记忆系统就是它的硬盘——决定了 Agent 能否跨会话记住用户偏好、从过往经验中学习、以及在复杂任务中保持一致性。
本文将深入对比三个代表性项目的记忆系统设计:OpenClaw(通用 Agent 框架)、Claude Code(编程 Agent)和 Hermes Agent(自进化 Agent)。它们分别代表了三种不同的设计哲学——文件优先的本地记忆、工程化的上下文压缩、以及自主学习的闭环系统。
一、为什么记忆系统是 Agent 架构的核心瓶颈?
在深入对比之前,有必要先理解记忆系统要解决的根本问题。大语言模型本质上是无状态的推理引擎——每次调用都从零开始,Session 内有效,Session 外失忆。这导致三个工程级问题:
- 上下文污染:长对话会引入冗余指令、过期决策和错误假设残留,模型越聊越不稳定
- 经验无法复用:用户每次都要重复解释项目结构、编码规范和个人偏好
- 成本指数上升:上下文越长,Token 成本越高、推理延迟越大,质量反而下降
一个设计良好的记忆系统,需要在速度、成本和保真度之间寻求动态平衡。但不同场景对记忆的需求差异巨大——个人助手需要记住用户偏好,企业客服需要多客户隔离,编程 Agent 需要压缩长对话,自进化 Agent 需要从经验中提炼技能。
三个对比项目的定位差异如下:
| 项目 | 定位 | 核心场景 | 设计哲学 |
|---|---|---|---|
| OpenClaw | 通用 Agent 框架 | 多工具编排、本地自动化 | 文件优先、透明可控 |
| Claude Code | 编程 Agent | 代码生成、项目维护 | 工程化、上下文压缩 |
| Hermes Agent | 自进化 Agent | 自主学习、技能沉淀 | 闭环进化、认知压缩 |
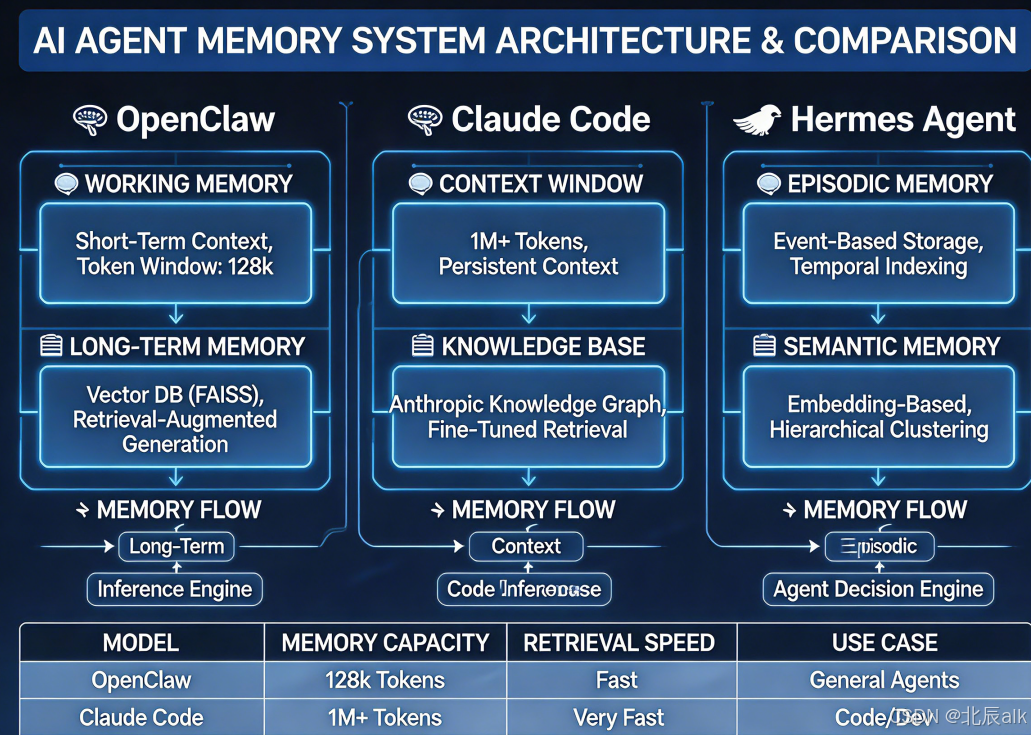
二、OpenClaw:文件优先的本地记忆架构
OpenClaw 代表了“逆数据库”的设计思潮——拒绝将记忆黑盒化存入向量数据库,而是用本地 Markdown 文件作为真理来源。这种设计的核心优势是透明、可控、可审计。
2.1 双层记忆拓扑
OpenClaw 的记忆体系分为两个独立但协同的层次:
瞬时情境层:memory/YYYY-MM-DD.md 格式的每日日志,采用“仅追加”模式记录当天所有对话。这一层不做任何过滤或压缩,保留原始对话流用于后续回溯。
持久知识层:MEMORY.md 作为长期记忆的入口文件,存储经过筛选、压缩和固化的高价值信息。Agent 通过严格的“隐私门控”决定哪些瞬时记忆值得晋升到持久层。
这种分层设计的核心价值在于预压缩——当会话 Token 触及软阈值时,触发静默的“智能体回合”,强制模型在遗忘前进行主动认知结晶。换句话说,OpenClaw 不会等到上下文爆满才被动处理,而是在关键节点主动触发记忆沉淀。
2.2 混合检索算法
OpenClaw 摒弃了传统的 RRF(倒数排名融合),采用保留原始分数幅度信号的混合检索策略:
- 向量检索(70% 权重):利用 sqlite-vec 进行余弦相似度计算,捕获语义层面的相关性
- 关键词检索(30% 权重):利用 SQLite FTS5 进行精准匹配,确保专有名词不被遗漏
这种权重分配背后的洞察是:在多数 Agent 场景中,“意思相近”比“用词相同”更重要,但完全放弃关键词匹配会导致技术术语丢失。
2.3 企业级扩展:memory-agentcore
OpenClaw 基础版是为单用户设计的——所有客户的偏好混在同一个 MEMORY.md 里。这在多客户服务场景下会引发严重问题:客户 A 的“喜欢素色”和客户 B 的“喜欢鲜艳”相互污染,Agent 召回的信息一团乱麻。
Amazon 开源的 memory-agentcore 插件解决了这个问题,在原有双层架构上叠加了云端共享层:
| 能力维度 | memory-core(内置) | memory-lancedb(内置) | memory-agentcore(企业扩展) |
|---|---|---|---|
| 存储引擎 | 本地 Markdown 文件 | 本地 LanceDB 向量库 | AWS AgentCore 云端 |
| 自动召回 | 需手动调工具 | before_agent_start 钩子 | before_prompt_build 钩子 |
| 自动捕获 | Agent 主动写文件 | 正则触发词匹配 | Amazon 4 策略自动提取 |
| 多用户隔离 | 共享文件 | 共享 dbPath | actorId → 命名空间 |
| 跨 Agent 共享 | 不支持 | 不支持 | 命名空间 + agentAccess |
该插件的核心创新是层级命名空间 + actorId 驱动的权限隔离。在多客户面客模式下,通过 peerId 实现记忆按客户自动隔离,同时支持跨 Agent 天然共享。导购 Agent 记录的“客户对化纤过敏”可以被客服 Agent 直接访问,但客户 B 永远看不到客户 A 的偏好。
2.4 2026.4.11 升级:主动记忆型运行时
2026 年 4 月,OpenClaw 完成了一次架构层面的重大升级,从“被动查询”转向“主动推送”模式:
| 架构维度 | 旧版 | 新版 |
|---|---|---|
| 记忆访问模式 | 被动查询(On-Demand) | 主动推送(Proactive) |
| 上下文准备 | 主智能体同步处理 | 独立子智能体异步处理 |
| 平均响应时间 | 320ms | 185ms |
| CPU/内存占用 | 45% / 1.2GB | 32% / 980MB |
新增的 Dreaming 模块 实现了三大突破:
- 多源数据适配层:通过标准化适配器接口,支持 JSON、CSV、Markdown 等 12 种常见对话格式的自动解析
- 语义对齐算法:采用 BERT+BiLSTM 混合模型,将不同平台的对话片段映射到统一语义空间
- 增量记忆更新:支持每秒处理 500+ 条历史记录的实时导入
Memory Palace(记忆宫殿)模块 引入了三维空间记忆模型——用户可以创建多达 200 个独立记忆场景,通过 R-Tree 空间索引实现毫秒级检索,甚至提供 Web 端 3D 编辑器进行可视化布局。
三、Claude Code:工程化的上下文压缩记忆
Claude Code 是 Anthropic 推出的编程 Agent,其记忆系统设计的核心挑战是:如何在极长的代码生成会话中,在不丢失关键信息的前提下控制上下文窗口? 答案是一套精密的“多级压缩 + 按需检索”架构。
3.1 记忆文件体系
Claude Code 的记忆文件采用分类存储策略:
| 类型 | 用途 | 作用域 | 示例文件 |
|---|---|---|---|
| user | 用户身份、角色、目标 | private/team | 技术栈偏好、沟通风格 |
| feedback | 用户反馈、偏好、纠正 | private/team | “别用 TypeScript,用 Python” |
| project | 项目信息、决策、截止日期 | private/team | 架构选型、依赖版本 |
| reference | 外部系统指针 | team | Linear 工单链接、Slack 频道 |
每个记忆文件都是 Markdown 格式,通过 frontmatter 记录类型、描述、修改时间等元数据。系统配置了严格的容量上限:
MEMORY.md最大 200 行 / 25KB- 最大记忆文件数 200 个
- 单次最多召回 5 条相关记忆
这些限制不是随意的——200 行约等于 5-10 分钟阅读量,25KB 约 6000-8000 tokens,正好是 LLM 高效处理的甜区。
3.2 多级上下文压缩机制
这是 Claude Code 记忆系统最具工程价值的部分。当 Token 使用量达到预设阈值时,系统按顺序执行四种压缩模式,每种模式由独立的 feature gate 控制:
| 顺序 | 模式 | 作用 | 触发条件 |
|---|---|---|---|
| 1 | HISTORY_SNIP | 移除最早的消息 | Token 超限 |
| 2 | CACHED_MICROCOMPACT | 清理过期工具结果,大结果替换为摘要 | 工具调用积压 |
| 3 | CONTEXT_COLLAPSE | 投影折叠视图,长对话压缩为紧凑表示 | 前两级不足 |
| 4 | AutoCompact | 调用压缩代理生成边界消息 | Token 使用率 ≥87% |
第四级压缩是最激进的——当上下文使用率达到 87% 时,系统会触发一个独立的“压缩代理”,由该代理读取当前完整上下文,生成一个 SystemCompactBoundaryMessage,然后用这个摘要消息替换原有上下文。这个设计的关键在于:压缩本身也是由 Agent 完成的,而不是简单的截断或摘要算法。
3.3 记忆查询流程
Claude Code 的记忆检索采用“清单 + 模型选择”模式,而非自动向量检索:
- 用户发起对话后,系统调用
loadMemoryPrompt()加载记忆入口 scanMemoryFiles()遍历记忆目录下所有.md文件,排除MEMORY.md- 解析每个文件的 frontmatter,提取 type、description、mtime 等字段
- 将扫描结果格式化为模型可读的清单,由模型自主选择最相关的 ≤5 条记忆
- 选中记忆与当前对话一起提交给模型生成回答
这种设计的优势是模型拥有选择权——只有模型自己知道当前任务需要哪些历史信息。缺点是每次都需要扫描所有记忆文件,但随着记忆文件数量增加,扫描开销也会线性增长。
3.4 claude-mem:第三方长期记忆扩展
除了 Claude Code 内置的记忆系统,社区还开发了 claude-mem 插件,为 Claude Code 增加长期记忆能力。其核心设计是“AI 压缩 + 精准注入”:
- 全量记录:捕获 Claude 在 coding session 中的所有行为(对话、修改、决策路径)
- AI 压缩:将 5000 tokens 的原始上下文压缩为 200 tokens 的高密度记忆片段,保留核心信息、丢弃冗余
- 精准注入:在未来交互中根据当前任务自动检索相关记忆并注入 prompt
claude-mem 与 Claude Code 的关系可以这样理解:Claude Code = 手,OpenClaw = 身体,claude-mem = 大脑记忆。它不是要替代 Claude Code 的内置记忆,而是在其之上叠加一层长期记忆能力。
3.5 后台 Dream 整合机制
Claude Code 还有一个独特的设计:Dream 整合(Dream Consolidation)。对话结束后,系统在后台异步执行记忆整合:
- 读取会话记录(
.jsonl格式) - 提取新知识存入对应类型的记忆文件
- 定期执行“Dream 压缩”——合并冗余条目、修剪过时信息、优化记忆结构
- 使用锁文件(
.consolidate-lock)防止并发冲突
这个机制的命名致敬了人类睡眠中的记忆巩固过程——白天的经历在睡眠中被重新激活、筛选、固化到长期存储中。
四、Hermes Agent:自主进化的记忆系统
Hermes Agent 代表了第三代 Agent 记忆系统的设计方向:Self-Improving——不仅记住信息,更从经验中提炼可复用的技能,让 Agent 越用越强。上线不到半年 GitHub 星标破 10 万,是目前增长最快的 Agent 项目之一。
4.1 Memory:声明式事实存储
Hermes 的 Memory 系统设计极为克制——只有两个纯文本文件,用 § 分隔条目:
~/.hermes/memories/
├── MEMORY.md # Agent 的环境认知(项目约定、工具怪癖、环境细节)
└── USER.md # Agent 对用户的认知(偏好、沟通风格、工作习惯)
关键设计决策是严格的字符上限:MEMORY 限 2200 字符,USER 限 1375 字符。这迫使 Agent 只能记录最高密度的信息,过时的条目会被新信息自然“挤掉”。
对比 OpenClaw 的纯追加模式——几个月后 MEMORY.md 可能膨胀成几万行的怪兽文件,找一句话需要通读全文——Hermes 的做法是“被动淘汰”而非“主动清理”。当添加新条目会超限时,add 操作直接失败,并返回当前所有条目给模型,由模型自己决定删什么、改什么、合并什么:
if new_total > limit:
return {
"success": False,
"error": f"Memory at {current:,}/{limit:,} chars. Adding would exceed limit.",
"current_entries": entries, # 让模型看到现有内容,自己决定如何整理
}
这迫使模型进行主动的信息整理——本身就是一次“自我反思”过程。
另一个精妙设计是冻结快照机制:每次会话启动时,Memory 加载后立刻捕获一份快照,之后系统提示词里用的都是这份快照,而非实时内容。这样设计的原因是:系统提示词在会话内不变可以共享前缀缓存(Prefix Cache),大幅节省 API 成本。新写入的内容只改磁盘,下一个会话才刷新进来。
Memory 的写入遵循“声明式事实”原则——提示词中明确要求:
- ✓ “User prefers concise responses”(用户偏好简洁回复)
- ✗ “Always respond concisely”(始终简洁回复)
前者是可供推理的偏好,后者是僵硬的指令。Memory 只存前者,保持 Agent 的灵活性。
4.2 Skill:程序性记忆与自主进化
如果说 Memory 是“知道什么”,Skill 就是“会做什么”。这是 Hermes 与 OpenClaw 最核心的差异所在。
OpenClaw 也有 Skill 系统(SKILL.md + YAML frontmatter),但 Skill 要么是用户手写的,要么是从社区装的——Agent 本身不会从工作中学习任何东西。干了一百次部署,第一百零一次犯的错跟第一次一模一样。
Hermes 的设计是:Agent 在完成任务后,自动将踩坑经验提炼成可复用的 Skill。每个 Skill 是一个目录,核心是 SKILL.md 文件:
---
name: flask-k8s-deploy
description: Deploy a Flask app to Kubernetes with health checks
version: 1.0.0
---
# Flask K8s Deployment
## When to use
- User wants to deploy a Flask/Python app to Kubernetes
## Steps
1. Create Dockerfile with gunicorn (not dev server)
2. Build and push image to registry BEFORE creating deployment
3. Write deployment.yaml with livenessProbe pointing to /health
...
## Pitfalls
- MUST push image to registry before kubectl apply, otherwise ImagePullBackOff
- Flask 默认没有 /health 端点,需要手动添加
Pitfalls 这一节不是预先写好的,而是 Agent 踩坑后追加的——这就是 Skill 层面的“自我进化”。
创建 Skill 的触发条件在 skill_manage 工具的 schema 中明确定义:
- 复杂任务成功完成(工具调用超过 5 次)
- 成功克服了错误
- 用户纠正的方法验证有效
- 发现了非简单的工作流
同时有一条关键规则:如果使用 Skill 时遇到了 Skill 没覆盖的问题,立即用 patch 操作更新它,不要等用户提醒。 这确保了 Skill 会随着使用不断精化。
Skill 的更新不是简单的追加,而是版本化的差异管理——Agent 可以对比新旧版本,只更新变化的部分,保留完整的历史演进轨迹。
4.3 三层记忆架构
Hermes 官方文档中描述了三层记忆系统:
| 层次 | 存储介质 | 内容 | 生命周期 |
|---|---|---|---|
| 会话记忆 | SQLite + FTS5 | 对话上下文、时序数据 | 30 天 + 时间衰减 |
| 持久记忆 | 向量数据库 + 知识图谱 | 用户偏好、系统配置 | 永久 |
| 技能记忆 | Markdown 文件 | 方法论、可复用流程 | 永久 + 版本控制 |
会话记忆使用时间衰减算法自动清理过期数据;持久记忆通过增量学习机制避免灾难性遗忘;技能记忆支持版本控制和差异比对,当检测到重复性任务时自动提炼为标准化技能模板。
4.4 闭环系统:Nudge Engine
连接 Memory 和 Skill 的是 Nudge Engine——一个定时运行的提醒机制,定期触发 Agent 进行“反思”:
- 回顾最近完成的任务
- 检查是否有值得提炼的操作模式
- 如果发现重复性工作,创建或更新相关 Skill
- 清理过时的 Memory 条目
这个闭环系统是 Hermes “自主进化”能力的工程化实现:Memory 提供事实基础 → 任务执行积累经验 → Skill 提炼可复用流程 → 下次任务更高效 → 继续发现新的可提炼点。
五、三种架构的对比分析
5.1 设计哲学对比
| 维度 | OpenClaw | Claude Code | Hermes Agent |
|---|---|---|---|
| 核心隐喻 | 个人笔记本 | 工程压缩工具 | 学习型伙伴 |
| 记忆载体 | Markdown 文件 | Markdown + JSONL | Markdown + SQLite + 向量库 |
| 检索方式 | 混合检索(向量+关键词) | 清单+模型选择 | 语义检索+知识图谱 |
| 压缩策略 | 主动触发(智能体回合) | 四级渐进压缩 | 认知压缩(Memory + Skill 分离) |
| 进化能力 | 无(需手写 Skill) | 有限(Dream 整合) | 完整闭环(自主创建 Skill) |
5.2 核心差异:信息密度的处理
三种架构最本质的差异在于对信息密度的不同处理方式:
OpenClaw 采用“文件即真理”的低密度存储。所有信息都以原始或接近原始的形式存入 Markdown,优势是完全透明、可审计、可 Git 管理;劣势是文件会无限膨胀,检索效率随数据量增长而下降。
Claude Code 采用“按需压缩”的中密度策略。通过四级压缩机制在运行时动态决定信息的详细程度——不常用的信息被高度压缩,关键信息保留完整。这是最工程化的方案。
Hermes 采用“认知分层”的高密度策略。Memory 和 Skill 的分离本身就是一种认知压缩——Memory 存声明式事实(知道什么),Skill 存过程性知识(会做什么)。严格的字符上限迫使模型只保留最高密度的信息。
5.3 适用场景对比
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 个人本地助手 | OpenClaw | 无需云服务,透明可控,文件即备份 |
| 多客户企业客服 | OpenClaw + memory-agentcore | 云端共享层实现用户隔离和跨 Agent 共享 |
| AI 编程工具 | Claude Code | 长对话压缩能力强,编程场景深度优化 |
| 需要长期学习的系统 | Hermes Agent | Self-Improving 闭环让能力持续增长 |
| 边缘设备/IoT | OpenClaw | 无数据库依赖,资源占用低 |
| 知识密集型应用 | Hermes | 向量库+知识图谱支持复杂关系推理 |
5.4 三种架构的可组合性
值得强调的是,这三种架构不是互斥的。实际生产系统可以根据需求组合使用:
- OpenClaw 的文件层 + Claude Code 的压缩机制:用 Markdown 存储原始数据,但在上下文注入前执行分级压缩
- Hermes 的 Skill 系统 + OpenClaw 的工具生态:让 OpenClaw 的技能也能自我进化
- Claude Code 的 Dream 整合 + memory-agentcore 的云端共享:编程 Agent 的经验可以被团队其他 Agent 复用
六、总结与展望
OpenClaw、Claude Code 和 Hermes Agent 分别代表了 Agent 记忆系统演进的三代思路:
- 第一代(OpenClaw):文件即记忆。简单、透明、可控,但缺少智能化的信息管理
- 第二代(Claude Code):工程化压缩。通过多级压缩在有限上下文中塞入更多信息,但 Agent 本身不学习
- 第三代(Hermes):自主进化。Agent 不仅使用记忆,还能从经验中提炼技能,实现能力增长
未来的 Agent 记忆系统可能会向三个方向演进:
- 混合架构:在文件系统基础上构建轻量级索引层,兼顾透明度和检索效率
- 联邦记忆网络:实现跨实例的记忆共享与协作,形成“集体智能”
- 量子化记忆压缩:将记忆存储需求降低 70% 以上,让长时间跨度的记忆成为可能
正如 HN 上一个高赞评论所说:“Data Is the Final Moat”——当模型智能被商品化、Agent 框架被开源,真正的护城河是 Agent 在工作中积累的领域知识。记忆系统的设计,将直接决定这条护城河的深度和宽度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)