【WAM篇】09:Say, Dream, and Act——给“做白日梦“提速,让想象与执行频率彻底解耦
前面几篇里,我们看到级联式世界动作模型(WAM)的一条主线:先让一个视频模型"画出"未来该怎么走,再把这段画面翻译成机器人能执行的动作。这条路最大的吸引力,是能直接借用互联网规模预训练的视频大模型;但它也有两个挥之不去的"原罪"——做一次"白日梦"太慢(视频扩散动辄几十步去噪),以及生成的画面在空间上常常对不准(手伸过去差几厘米,动作就废了)。这一篇的 Say, Dream, and Act 同时盯上了这两个痛点,给出了一套相当工整的解法。
一、要解决什么问题:又慢又"飘"的白日梦
我们先把级联式 WAM 的工作流想象成一个"导演 + 演员"的组合。导演(视频世界模型)先在脑海里拍一段"接下来该怎么操作"的分镜,演员(动作模型)照着分镜把动作演出来。这套思路很美,但落到真机上有三道坎:
第一道坎:导演拍片太慢。 视频扩散模型生成画面,靠的是"从一团噪声里一步步去噪",原版往往要三十几步迭代。机器人控制讲究实时闭环,每秒要出好几次决策,让它干等导演慢悠悠拍完一整段几十步的分镜,根本来不及。
第二道坎:画面"看着像、其实飘"。 视频模型最擅长把画面拍得"以假乱真",但它学的是"视觉上合理",不保证"空间上精确"。比如指令是"去拿左边那个红杯子",生成的视频里手臂确实朝杯子方向伸了,可落点偏了几厘米,或者干脆抓向了旁边那个一模一样的杯子——视觉评分很高,真机执行却直接失败。论文把这种能力专门拆成了几个维度去考核:形态一致性(embodiment consistency,机器人长得像不像它自己、会不会拍着拍着多长出一条胳膊)、空间指代能力(spatial referring,能不能正确锁定"左边那个"而不是"右边那个")、任务完成度(task completion,整段操作在画面里到底有没有真的做成)。
第三道坎:帧率被钉死了。 这一点很隐蔽,却是这篇的点睛之处。常规做法是"机器人每执行一个动作步,就要对应生成一帧画面"。可机器人操作本质上是个低频问题——把一杯水从 A 端到 B,路径就那么一条,中间几十上百个动作步在画面上其实高度冗余。逐步生成不仅浪费算力,还把"我要往哪走"(空间路径规划)和"我要走多少步、走多快"(执行频率)这两件本该分开的事死死绑在了一起。换一个执行频率更高的机器人,或者一个动作更慢的任务,整套预测就得推倒重来。
一句话概括痛点:导演又慢又不够准,而且还被强行要求"按演员的步频逐帧画分镜"。 Say, Dream, and Act 的三个名字,恰好对应它给这三道坎开的三剂药。
二、核心思想与直觉:选对底座、压缩白日梦、用现实校正想象
这篇的核心思想可以用一句"人话"概括:先挑一个本来就拍得稳的导演,再教它只拍几个关键分镜、且不必管演员走多快,最后让演员一边照分镜演、一边盯着真实画面随时纠偏。
它属于级联式 WAM 里"基于像素空间的显式规划 + 学习式动作提取"这一支——和 UniPi、Vidar 是同门。但和前作相比,它的三个关键差异正好藏在标题里:
- Say(说,选底座 + 对齐):不盲目自己从头训一个视频模型,而是先"货比三家",用前面那套形态一致性 / 空间指代 / 任务完成度的标准去评测候选视频大模型,挑出最靠谱的那个(最终选了 Cosmos-Predict2),再做领域适配。这一步像是"先面试导演,挑出基本功最扎实的"。
- Dream(梦,压缩 + 帧率无关):把任意长度的操作轨迹压成固定的几个关键帧,并让视频生成"与帧率无关",从而把空间路径规划和执行频率解耦。这是导演学会了"只画分镜、不画逐帧"。
- Act(行动,上下文式动作模型 + 现实校正):动作模型同时吃"生成的未来帧"和"真实观测",把想象当成示范、用现实当成锚点,专门校正生成画面里的空间误差。这是演员"照着分镜演,但眼睛始终盯着现场"。
再叠加一个贯穿全程的提速手段——对抗式蒸馏,把导演拍一段分镜需要的去噪步数从三十几步压到个位数。下面逐一拆开。
三、方法详解:四个零件拼出一台"快且准"的白日梦机器
零件一:Say——先选一个拍得稳的导演
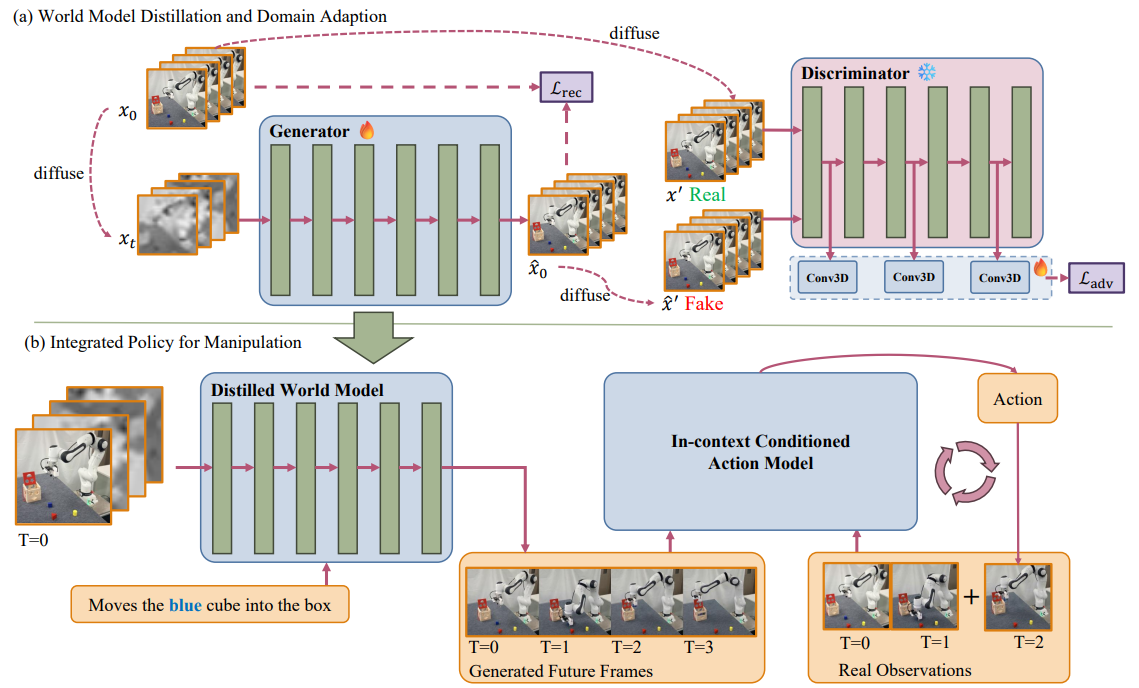
很多工作默认"视频模型越大越好、随便拿来就用",但这篇先泼了盆冷水:它把几个主流视频生成模型拉到同一张考卷上,用前面提到的形态一致性(EC,数值越低越稳)、指代成功率(RSR)、交互成功率(ISR)、任务完成率(TCR)等指标横向比较。结果挺有意思——更大的 14B 模型并不总是赢:在它们的测评里,Cosmos-2B 的指代成功率约 96%、交互成功率约 86%,而 14B 版本在某些指代项上反而略低。这说明对机器人来说,"画得稳、对得准"比"参数多"更重要。最终他们以 Cosmos-Predict2 为底座(实验覆盖 2B 与 14B 两档),再做领域适配(domain adaptation, DA)让它从"会拍通用视频"变成"会拍这套机器人的操作"。领域适配的收益非常直接:在他们的测评里,2B 模型经过领域适配后,FVD(一个衡量生成视频分布与真实分布距离的指标,越低越好)从 571 一路降到约 212,结构相似度 SSIM 从 0.70 升到 0.82。
零件二:Dream——把白日梦"抽帧",并和步频脱钩
这是全篇我最欣赏的设计。它的出发点是那句朴素却深刻的观察:机器人操作是个低频预测问题,给每个动作步都生成一帧纯属冗余。
具体怎么做?给定一段长度为 TTT 的轨迹,它不逐帧生成,而是均匀采样出固定的 nnn 个关键帧(论文里取 n=9n=9n=9)。用公式表达就是采样第 ti=⌊(i/n)⋅T⌋t_i=\lfloor (i/n)\cdot T \rfloorti=⌊(i/n)⋅T⌋ 帧,iii 从 1 到 9。无论这段操作真机要执行 50 步还是 500 步,导演永远只画 9 张"分镜"。
这一步的妙处,是把视频扩散模型微调成"与帧率无关":模型不再依赖具体的轨迹长度 TTT,它学的是"从起点到目标,空间上大致会经过哪 9 个关键状态",而不是"第几毫秒画面长什么样"。打个比方——以前是要导演把一整段路程按秒拍成连续录像,现在只要他画 9 张"路标速写"(出发、绕过桌角、接近杯子、握住、抬起……)。空间路径由这 9 张速写定下来,走多快、分几步走则交给下游的动作模型按真机的实际频率去填。规划与执行频率就此解耦,模型也因此能在"可变长度时程"上做统一预测——一次前向就能预判长程结果,不必管机器人到底走几步。
零件三:对抗式蒸馏——把三十几步压成几步
光抽帧还不够快,每张关键帧本身仍要多步去噪。这里请出对抗式蒸馏(adversarial distillation)。
先解释什么是"蒸馏":通常是让一个"学生"模型去模仿"老师"模型的输出,从而用更少的步数达到接近的效果。这篇的巧思在于判别器(discriminator)直接复用预训练 DiT(扩散 Transformer,视频扩散模型的主干)的权重,只在中间特征图上加几个轻量的 3D 卷积头。这相当于"评委本身就是科班出身的老导演",对画面好坏的判断特别专业。训练时用的是 GAN 里常见的 hinge 损失:判别器努力把真实帧判为真、把学生生成的帧判为假;生成器(学生)则努力骗过判别器,同时还保留一个重建损失 Lrec\mathcal{L}_{rec}Lrec 保证画面不跑偏,总损失里对抗项权重 λ\lambdaλ 取 0.1。
还有一个容易被忽略的细节:判别器评估之前,会先给真实帧和生成帧都额外加一点噪声(噪声等级从对数正态分布里采)。原因是预训练 DiT 本来就是被训练去处理"带噪输入"的,喂给它带噪样本它才看得最准。
效果立竿见影:去噪步数从原版的 35 步压到 8 步。从他们的消融看,35 步生成一段要约 86 秒、FVD 约 488;降到 10 步约 30 秒、FVD 约 580;即便压到 8 步配合领域适配,SSIM 仍能保持在 0.84 的高位。用一点点保真度的损失,换来近一个数量级的提速,这笔交易对实时控制非常划算。
零件四:Act——把想象当"示范",把现实当"锚点"
最后是动作模型,它要回答"看着这 9 张分镜,每一步具体该输出什么动作"。这篇没有用传统的逆动力学模型(IDM,简单说就是"看前后两帧、倒推中间动作"的网络),而是设计了一个上下文式(in-context)动作模型:它同时接收两路输入——导演生成的未来关键帧,以及机器人真实的历史与当前观测。
它的工作方式很像"看一遍范例再答题"的下一词预测器:把生成的未来帧当成一段"执行示范",模型据此输出动作;动作执行后产生的真实观测,又要去贴合示范里展示的大致模式。关键在于"真实观测"这条线——它是一个持续的锚点,让动作模型不会盲目照搬可能有瑕疵的生成画面,而是不断用现实把预测拉回正轨。这正是对"画面看着像、空间却飘"那道坎的正面回应:想象负责给方向,现实负责纠偏差。架构上,动作模型继承自 ACT,并用 Qwen2.5 作为骨干、以 LoRA(rank 64,一种只微调少量参数的高效微调法)适配。
| 阶段 | 比喻 | 技术内容 | 解决的痛点 |
|---|---|---|---|
| Say | 面试挑导演 | 多模型横评 + 选 Cosmos-Predict2 + 领域适配 | 选一个本就拍得稳、对得准的底座 |
| Dream | 只画 9 张分镜 | 均匀抽帧(n=9)+ 帧率无关微调 | 规划与执行频率解耦、低频高效 |
| 提速 | 评委是老导演 | 对抗式蒸馏,DiT 当判别器,35→8 步 | 把"做白日梦"提速近一个数量级 |
| Act | 照范例答题、盯现场 | 上下文式动作模型,吃生成帧 + 真实观测 | 用现实校正生成画面的空间误差 |
核心公式与逻辑梳理
把前面四个零件串成一条端到端的链路,再用四个核心公式把"为什么这样做"说透。
方法逻辑链:
- 输入编码:当前观测帧 + 任务指令 + 真机历史观测,被编码送入两条分支。
- 关键帧采样:把长度为 TTT 的目标轨迹均匀抽成 9 张关键分镜,让视频生成与执行帧率解耦。
- 少步去噪:用蒸馏后的 DiT 在 8 步内把噪声还原成 9 张关键帧,速度比原版快近一个数量级。
- 对抗式蒸馏训练:复用预训练 DiT 当判别器,用 hinge 损失把"少步学生"逼近"多步老师"。
- 上下文式动作生成:把生成的 9 张未来分镜 + 真实观测一并喂给动作模型,逐步输出可执行动作。
- 真机闭环:执行动作 → 拿到新观测 → 真实观测持续校正想象的飘移。
核心公式 1:均匀关键帧采样
S(τ)={xti}i=1n,ti=⌊in⋅T⌋\mathcal{S}(\tau)=\{x_{t_i}\}_{i=1}^{n},\qquad t_i=\left\lfloor\frac{i}{n}\cdot T\right\rfloorS(τ)={xti}i=1n,ti=⌊ni⋅T⌋
符号说明:τ\tauτ 是一条完整轨迹;TTT 是这条轨迹的总长度(真机要执行几百步就有几百帧);nnn 是要保留的关键帧数(论文取 n=9n=9n=9);tit_iti 是第 iii 张关键帧在原轨迹里的时间下标;⌊⋅⌋\lfloor\cdot\rfloor⌊⋅⌋ 是向下取整;xtix_{t_i}xti 就是被抽中的那张画面;S(τ)\mathcal{S}(\tau)S(τ) 是抽完后得到的"分镜集合"。
这条式子在做什么:它把"逐帧画一整段视频"换成了"等距画 9 张速写"。无论 TTT 是 50 还是 500,输出永远是 9 帧。空间路径由这 9 张速写定下来,执行频率由下游动作模型按真机节奏去填,两件事就此解耦——这正是"帧率无关预测"在数学上的全部秘密。
核心公式 2:判别器 hinge 损失
LadvD=Ex0,σt,σ′[ReLU(1−D(x′))+ReLU(1+D(x^′))]\mathcal{L}_{adv}^{\mathcal{D}}=\mathbb{E}_{x_0,\sigma_t,\sigma'}\Big[\mathrm{ReLU}(1-\mathcal{D}(x'))+\mathrm{ReLU}(1+\mathcal{D}(\hat{x}'))\Big]LadvD=Ex0,σt,σ′[ReLU(1−D(x′))+ReLU(1+D(x^′))]
符号说明:D\mathcal{D}D 是判别器(直接复用预训练 DiT 的权重 + 几个 3D 卷积头);x′x'x′ 是给真实帧 x0x_0x0 加噪后的样本,x^′\hat{x}'x^′ 是学生生成帧加噪后的样本;σt,σ′\sigma_t,\sigma'σt,σ′ 是采自对数正态分布的噪声等级;E\mathbb{E}E 表示在这些随机量上求期望;ReLU(⋅)=max(0,⋅)\mathrm{ReLU}(\cdot)=\max(0,\cdot)ReLU(⋅)=max(0,⋅)。
这条式子在做什么:标准的 GAN hinge 损失——让判别器把真实帧打到 D(x′)≥1\mathcal{D}(x')\ge 1D(x′)≥1(左项被 ReLU 吃掉),把学生生成帧打到 D(x^′)≤−1\mathcal{D}(\hat{x}')\le -1D(x^′)≤−1(右项被 ReLU 吃掉)。注意它特意把真帧也加噪后再喂给判别器,因为预训练 DiT 本就是"看带噪输入"的科班出身,让评委评估它最熟悉的输入分布,判断才稳。
核心公式 3:生成器总损失
LG=λ⋅LadvG+Lrec,LadvG=E[−D(x^′)],λ=0.1\mathcal{L}_{\mathcal{G}}=\lambda\cdot\mathcal{L}_{adv}^{\mathcal{G}}+\mathcal{L}_{rec},\qquad \mathcal{L}_{adv}^{\mathcal{G}}=\mathbb{E}\big[-\mathcal{D}(\hat{x}')\big],\quad \lambda=0.1LG=λ⋅LadvG+Lrec,LadvG=E[−D(x^′)],λ=0.1
符号说明:LadvG\mathcal{L}_{adv}^{\mathcal{G}}LadvG 是生成器的对抗项(想让 D(x^′)\mathcal{D}(\hat{x}')D(x^′) 越大越好,所以取负号最小化);Lrec=∥x^0−x0∥22⋅(1+σt)2/σt2\mathcal{L}_{rec}=\lVert\hat{x}_0-x_0\rVert_2^2\cdot (1+\sigma_t)^2/\sigma_t^2Lrec=∥x^0−x0∥22⋅(1+σt)2/σt2 是重建损失,x^0\hat{x}_0x^0 是学生预测的去噪结果;λ=0.1\lambda=0.1λ=0.1 是对抗项权重。
这条式子在做什么:它把"少步骗过判别器"和"少步预测要贴近真值"两个目标加在一起。λ=0.1\lambda=0.1λ=0.1 这个偏小的权重很关键——主要靠重建损失保住像素保真度,对抗项只是个"风格教练"防止画面糊掉。这种配方让蒸馏后从 35 步压到 8 步仍能把 SSIM 维持在 0.84。
核心公式 4:DiT 去噪预测
x^0=cskip⋅xt+cout⋅Dθ(cin⋅xtcond, cond)\hat{x}_0 = c_{skip}\cdot x_t + c_{out}\cdot D_\theta\big(c_{in}\cdot x_t^{cond},\ cond\big)x^0=cskip⋅xt+cout⋅Dθ(cin⋅xtcond, cond)
符号说明:xtx_txt 是当前时刻含噪的潜变量;DθD_\thetaDθ 是 DiT 主干(Cosmos-Predict2 蒸馏而来);condcondcond 是条件信息(指令、上一帧等);cskip,cin,coutc_{skip}, c_{in}, c_{out}cskip,cin,cout 都是依赖噪声等级 σt\sigma_tσt 的预处理系数(来自 EDM 风格的归一化);x^0\hat{x}_0x^0 是预测的干净帧。
这条式子在做什么:它把"预测干净结果"拆成"原样保留含噪输入的一部分 + 用网络改一部分"。这种带跳连的参数化既数值稳定,又让网络只学"改动量"而非从零造图——这是少步扩散能保住质量的另一根支柱。
核心公式 5:上下文式动作模型
a1:H=πact( S(τ)⏟9 张生成分镜 ∥ o≤t⏟真实历史观测 )a_{1:H}=\pi_{\text{act}}\big(\,\underbrace{\mathcal{S}(\tau)}_{\text{9 张生成分镜}}\ \big\|\ \underbrace{o_{\le t}}_{\text{真实历史观测}}\,\big)a1:H=πact(9 张生成分镜 S(τ) 真实历史观测 o≤t)
符号说明:πact\pi_{\text{act}}πact 是动作模型(ACT 结构 + Qwen2.5 主干 + LoRA rank 64);S(τ)\mathcal{S}(\tau)S(τ) 是导演画出的 9 张关键帧;o≤to_{\le t}o≤t 是真机到当前时刻为止的真实观测序列;∥\|∥ 表示在上下文里拼接;a1:Ha_{1:H}a1:H 是输出的动作块(长度 HHH 由下游频率决定)。
这条式子在做什么:它把"想象"和"现实"摆成两段同时给模型看的提示。模型像"看一遍范例再做题"——9 张分镜给方向,真实观测当锚点。一旦想象画面偏了几厘米,真实观测这条线就会把动作拉回正轨。这正是"想象给方向、现实纠偏差"的数学落点,也是这套设计能把 LIBERO 长程任务做到 95% 以上的关键。
四、实验怎么做·结果说明了什么
仿真主场是 LIBERO——这是操作领域常用的基准,分 Spatial(空间)、Object(物体)、Goal(目标)、Long(长程)四个子套件。Say, Dream, and Act 拿到了约 98.1% 的总体成功率,其中空间 99.4%、物体 99.2%、目标 98.6%、长程 95.4%。作为对照,OpenVLA 约 76.5%、π₀ 约 94.2%。换成大白话:在这个基准上,它把"差不多能用"推到了"几乎不出错",尤其长程任务还能守住 95% 以上,说明那套"只画关键帧 + 现实纠偏"的组合在多步操作里没有崩。
真机用 Franka 7 自由度机械臂 + RealSense D435 相机做了验证。
几个关键消融把每个零件的作用拆得很清楚:
- 领域适配(DA)有多重要:不加 DA 时 FVD 约 571,加了之后降到约 212——生成质量翻了一倍多。这印证了"通用视频模型必须先适配到机器人域"才靠谱。
- 去噪步数的取舍:1 步太糙(FVD 约 1128),10 步已大幅改善(约 580),35 步最好(约 488)但慢到 86 秒。8 步是他们权衡后的甜点。
- 大模型不一定更好:Cosmos-2B 在指代成功率上(约 96%)反而高于 14B(约 90%),提醒大家别迷信参数量。
这些数字合起来讲了一个故事:把效率(抽帧 + 蒸馏)和精度(选底座 + 现实纠偏)这两条线分别做扎实,级联式 WAM 既能跑得快、又能做得准。
五、亮点与为什么重要
这篇最大的两个贡献,都很"解渴":
其一,帧率无关预测是个被低估的好点子。 它点破了一个长期被默认的错误绑定——“动作步数 = 视频帧数”。一旦把空间规划从执行频率里解放出来,同一段想象就能适配不同步频的机器人、不同节奏的任务,长程预测也能一次成型。这对级联式 WAM 的可扩展性意义重大,也呼应了 WAM 综述里反复强调的"任务自适应预测保真度"——别用统一的高频去硬画所有任务。
其二,把"提速"做成了可复用的工程模块。 用预训练 DiT 自己当判别器来做对抗蒸馏,既省去了额外训练判别器的成本,又让蒸馏出的少步模型保真度更高。对所有想把视频扩散塞进实时控制回路的工作,这都是一个可以直接借鉴的招。
合起来看,它在级联式这条被诟病"太慢"的路上,给出了一个相当完整的"提速 + 保真"答卷。
六、局限与未解
作者自己也很坦诚地列了几条短板:
- 延迟仍未彻底解决:蒸馏确实快了很多,但要在算力受限的真机上做到真正低延迟、高频控制,还需进一步优化。
- 长程会累积误差:尽管抽帧缓解了冗余,长时程预测在动态或杂乱场景里仍会漂移,可能需要在线纠偏、混合规划或带不确定性的多次推演来兜底。
- 强依赖生成质量:上下文式动作模型的表现,仍系于生成视频的保真度——一旦画面崩了或局部不一致,动作就会受连累,如何对"不完美的想象"更鲁棒是个开放问题。
- 跨本体泛化有限:实验主要在 Franka 单臂上,要推广到形态、视角、环境差异巨大的多种机器人,恐怕得靠更广的预训练。
七、在 WAM 谱系中的位置
放回综述的大图景,Say, Dream, and Act 稳稳落在级联式 WAM → 像素空间显式规划 → 学习式动作提取这一格,是 UniPi 开创、Vidar/Gen2Act 等发扬的那条主线上的"效率与精度升级版"。
和左右邻居对照着看会更清楚:上一篇 This&That 解决的是"语言指代有歧义"(靠手势坐标消歧),这一篇换了个方向解决"导演太慢、画面太飘";紧随其后的 TesserAct 则给视频预测加上深度和法向通道、把几何约束塞进规划载体,MVISTA-4D 干脆用"轨迹级优化 + 残差 IDM"重做动作提取环节。它们共同勾勒出级联式 WAM 在 2026 年的演进重点——不再满足于"能画出未来",而是追问"画得够快吗、够准吗、够省吗"。
下一篇我们会看到 Veo-Act,它把"效率与精度"的矛盾换了一种更激进的解法:用 Veo-3 这样的前沿视频模型做粗略导航,一旦检测到要接触物体,就当机立断把控制权交给一个反应式 VLA。
八、参考
- 论文标题:Say, Dream, and Act: Learning Video World Models for Instruction-Driven Robot Manipulation
- 出处:arXiv 预印本(2026)
- arXiv:https://arxiv.org/abs/2602.10717
- 底座视频模型:Cosmos-Predict2;动作模型骨干:Qwen2.5 + LoRA;评测基准:LIBERO、Franka 真机

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)