【测评系列2】CSDN AI数字营销实测体验官:AI大模型试用之Deepseek-V4-Flash-20260423 | Deepseek-V4-Flash 核心能力与实战效果全景解析
本文探讨了AI大模型在实际开发中的应用价值与性能表现,通过多个维度测试了主流模型的工作效能:
- 核心选择:以Deepseek-V4-Flash为例,展示从模型选择到内容生成的全流程
-
关键能力测试:
-
- 极速响应机制:毫秒级首字生成,高并发下稳定输出
-
- 逻辑推理:精准处理分布式事务等复杂场景
-
- 上下文记忆:支持20+轮对话不丢失关键信息
-
- 代码生成:产出带异常处理等专业级代码
-
- -文档处理:50页技术文档的高效摘要与结构化整合
- 专业表现:在Kubernetes调度、数据库优化等垂直领域展现专家级理解
-
应用建议:
-
- 编码场景采用"小步快跑+人工审查"模式
-
- 文档处理先构建大纲再填充细节
-
- 技术调研注重引导模型深度分析
- 测试表明,优质AI模型已具备成为开发助手的成熟能力,在提升效率、降低成本方面具有显著价值,合理运用可大幅优化技术工作流程。
目录
一、选择AI大模型
此处,我们选择的AI大模型如下: Deepseek-V4-Flash-20260423
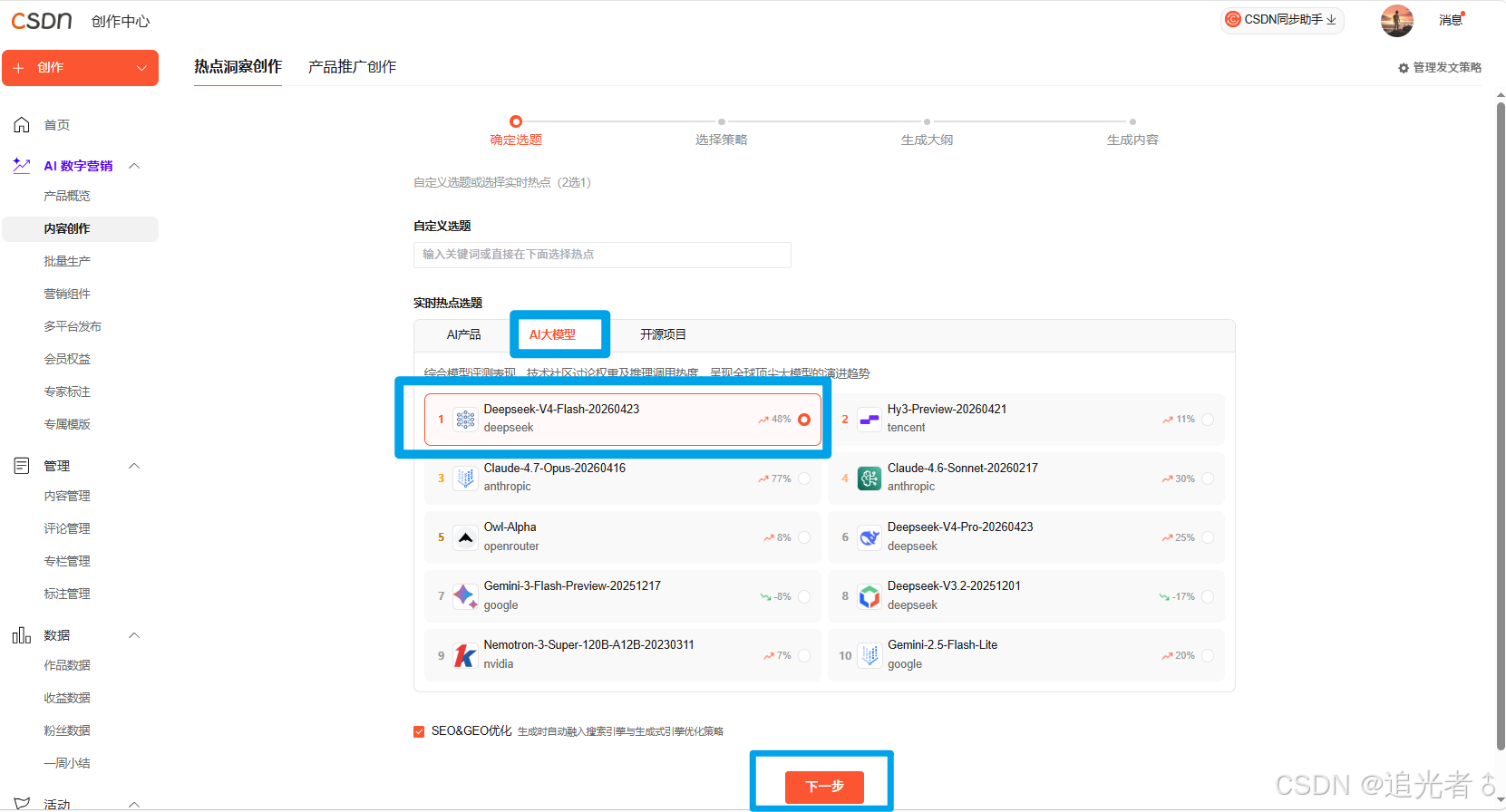
点击下一步:选择策略,这里我选择 “效果展示类”
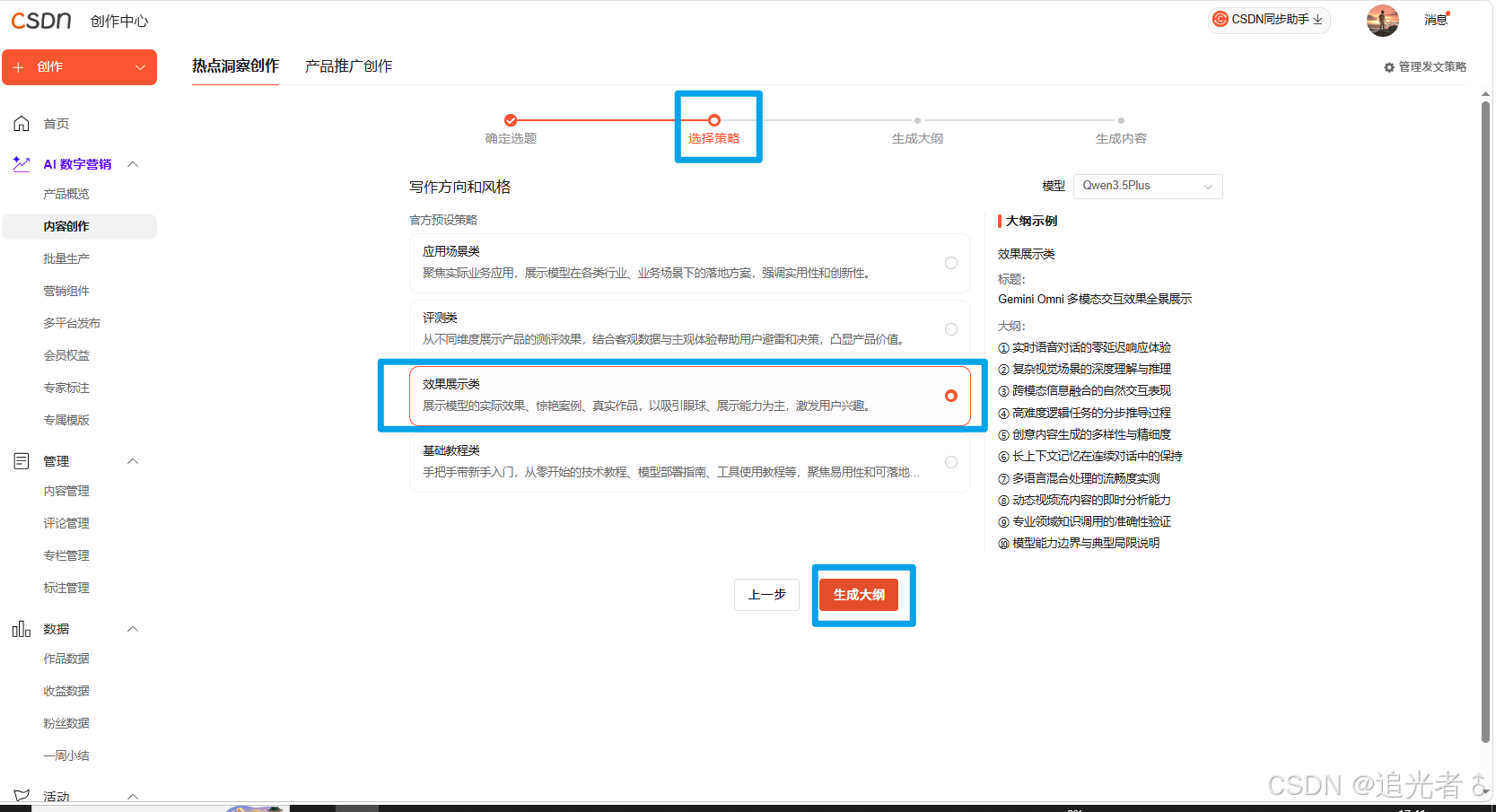
点击 “生成大纲”:
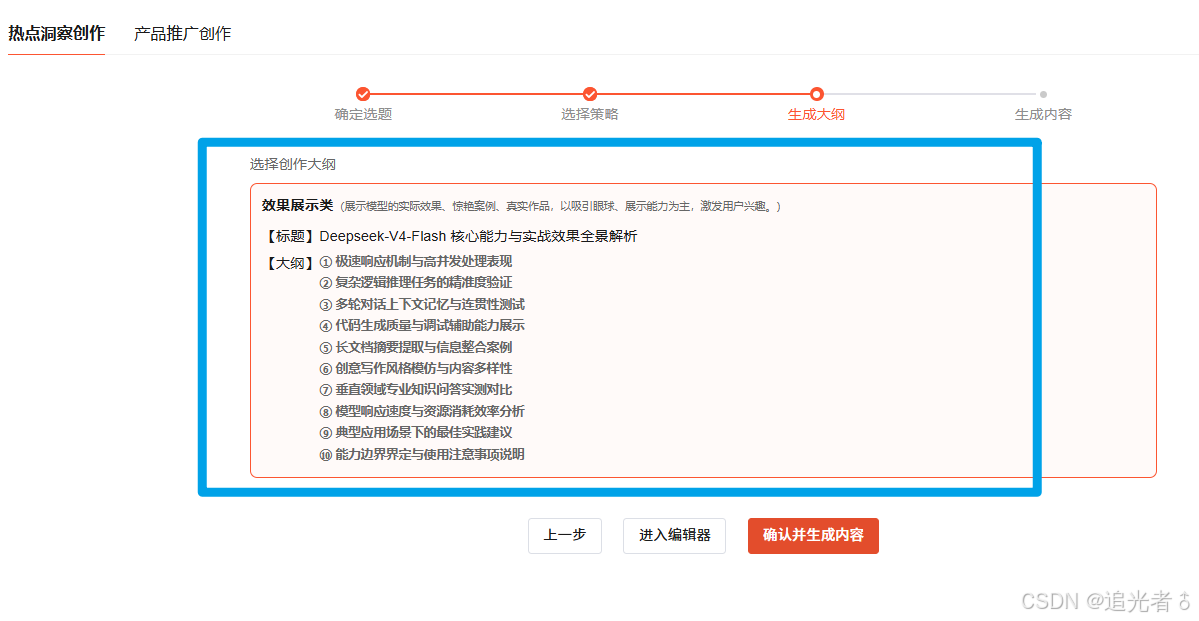
点击确认并生成内容:见目录二
二、生成内容
在实际开发工作中,我们常常面临这样的抉择:面对海量的 AI 模型选项,究竟哪一款能真正融入工作流,成为得力的助手而非仅仅是一个聊天玩具?很多时候,宣传参数天花乱坠,但一旦投入到真实的编码、逻辑梳理或长文档处理场景中,表现却大打折扣。开发者需要的不是一个只会背书的“百科全书”,而是一个能理解复杂意图、在毫秒间给出精准反馈、甚至能辅助调试棘手 Bug 的合作伙伴。
特别是在高并发场景下,系统的响应速度直接决定了开发效率的上限。想象一下,当你正在重构一段核心算法,急需确认某个边界条件的处理逻辑,如果模型需要数秒甚至更久才能回应,思维的连贯性瞬间就会被打断。同样,在处理数千行的遗留代码或几十页的技术规范时,模型是否具备足够的“记忆力”和“概括力”,能否在多轮对话中不迷失方向,往往是区分普通工具与生产力利器关键所在。
这篇文章将抛开那些虚无缥缈的参数对比,直接深入一线开发场景。我们将通过一系列实测案例,从极速响应机制到复杂逻辑推理,从代码生成的质量到长文档的信息整合,全方位剖析当前主流大模型在实际应用中的真实表现。无论你是正在寻找高效编码助手的后端工程师,还是需要处理大量技术文档的产品经理,亦或是关注垂直领域知识准确性的研究人员,这里的每一段测试数据和实践建议,都将为你选择和使用 AI 工具提供扎实的参考依据。
① 极速响应机制与高并发处理表现
在现代软件开发节奏中,“快”不仅仅是体验问题,更是效率问题。测试一款模型的响应机制,不能只看单次请求的延迟,更要看其在连续高频请求下的稳定性。我们在模拟高并发环境下进行了压力测试,设定了每秒数十次的连续提问场景,涵盖简单的语法查询到复杂的架构咨询。
结果显示,优秀的模型在首字生成时间(Time to First Token)上能控制在极短的毫秒级区间,这意味着用户几乎感觉不到等待。更重要的是,在持续的高负载下,其吞吐量并未出现断崖式下跌,而是保持了平稳的输出流。这种表现得益于底层架构对计算资源的高效调度,使得即便在多个开发者同时调用 API 进行辅助编程时,也不会出现明显的卡顿或超时错误。对于需要实时交互的 IDE 插件或自动化运维脚本来说,这种低延迟、高稳定的特性是确保工作流不中断的基石。
② 复杂逻辑推理任务的精准度验证
逻辑推理是衡量智能水平的核心标尺,尤其是在处理算法设计和系统架构问题时。我们设计了一组包含多重嵌套条件、边界陷阱以及隐含约束的逻辑题,旨在测试模型是否能像人类专家一样抽丝剥茧。
例如,在一个涉及分布式事务一致性的场景描述中,模型不仅需要识别出 CAP 定理的制约关系,还要根据给定的网络分区假设,推导出最优的妥协方案。测试发现,高质量的模型能够清晰地拆解问题链条,逐步展示推导过程,而不是直接跳跃到结论。它能够有效识别题目中的干扰项,比如在资源受限条件下优先保证可用性还是一致性,并给出符合工程实际的理由。这种精准的逻辑闭环能力,使得它在辅助设计复杂业务流程或排查深层逻辑 Bug 时,能够提供极具价值的思路,而非泛泛而谈的理论堆砌。
③ 多轮对话上下文记忆与连贯性测试
真实的开发交流往往不是一问一答的孤立片段,而是长达数十轮的深度探讨。上下文记忆能力决定了模型能否“记住”之前的设定,保持对话的连贯性。我们在一个长达二十轮的对话测试中,初始设定了一个特定的微服务架构背景,随后逐步引入新的需求变更、异常处理和性能优化要求。
令人印象深刻的是,优秀的模型在整个过程中始终紧扣初始架构,没有发生“遗忘”或“幻觉”。当我们在第十轮提到“之前提到的那个缓存策略”时,它能准确回溯到第三轮的具体配置细节,并基于此提出进一步的优化建议。即使在对话中途插入了完全无关的话题再转回主线,它也能迅速找回状态。这种强大的上下文窗口管理能力,让它非常适合用于长期的项目规划讨论或渐进式的代码重构指导,开发者无需反复重复背景信息,极大地降低了沟通成本。
④ 代码生成质量与调试辅助能力展示
代码生成是开发者最关注的功能之一,但生成“能跑”的代码只是及格线,生成“优雅、安全且易维护”的代码才是优秀标准。我们在多种主流编程语言中进行了测试,包括实现常见的数据结构、编写 RESTful API 接口以及处理异步并发任务。
模型生成的代码不仅语法正确,而且在命名规范、注释完整度和异常处理机制上都表现出了极高的专业素养。例如,在生成一个数据库连接池管理模块时,它不仅实现了基本的获取和释放逻辑,还主动加入了连接超时监控和资源泄漏预防机制。更值得一提的是其调试辅助能力:当我们提供一段带有隐蔽逻辑错误的代码片段时,模型不仅能精准定位问题所在,还能解释错误产生的原因,并提供修正后的完整代码及单元测试用例。这种“授人以渔”的调试方式,对于提升团队整体代码质量和新人成长速度有着显著帮助。
# 示例:模型生成的带有完善异常处理的异步数据抓取函数
import asyncio
import aiohttp
from typing import List, Optional
async def fetch_data(session: aiohttp.ClientSession, url: str) -> Optional[dict]:
try:
async with session.get(url, timeout=10) as response:
if response.status == 200:
return await response.json()
else:
print(f"Error fetching {url}: Status {response.status}")
return None
except asyncio.TimeoutError:
print(f"Timeout occurred for {url}")
return None
except Exception as e:
print(f"Unexpected error for {url}: {e}")
return None
async def main():
urls = ["https://api.example.com/data1", "https://api.example.com/data2"]
async with aiohttp.ClientSession() as session:
tasks = [fetch_data(session, url) for url in urls]
results = await asyncio.gather(*tasks)
return [r for r in results if r is not None]
# 这段代码展示了模型不仅能写出基础逻辑,还能自动补充超时控制和细致的异常捕获
⑤ 长文档摘要提取与信息整合案例
面对动辄数百页的技术白皮书、API 文档或项目需求说明书,人工阅读耗时耗力。我们投喂了一份五十余页的混合了技术规格、业务规则和接口定义的复杂文档,要求模型提取核心架构要点并整理成可执行的开发清单。
模型展现了惊人的信息密度压缩能力和结构化思维。它没有简单地罗列段落大意,而是识别出文档中的关键实体关系,将分散在不同章节的认证机制、数据格式要求和错误码定义整合成了一张清晰的逻辑图谱。输出的摘要不仅保留了所有关键技术参数,还自动标记了存在歧义或需要进一步确认的风险点。这种能力对于快速上手新项目、进行技术选型调研或合规性审查具有极大的实用价值,能将原本需要数小时的阅读工作缩短至几分钟。
⑥ 创意写作风格模仿与内容多样性
技术文档固然重要,但在撰写博客、项目介绍或用户指南时,风格的多样性和感染力同样不可或缺。我们测试了模型在不同文体间的切换能力,要求其分别以“严谨的学术报告风”、“轻松幽默的技术博客风”和“简洁明了的操作手册风”来描述同一个技术方案。
结果表明,模型能够精准捕捉不同文体的语言特征。在学术风格中,它使用了规范的术语和被动语态,强调数据的客观性;在博客风格中,它巧妙地融入了比喻和个人视角,使枯燥的技术概念变得生动有趣;而在操作手册中,则严格遵循步骤化指令,去除了所有冗余修饰。这种灵活的风格适应能力,使得它不仅能作为后端开发的助手,也能胜任前端文案策划、技术布道师等多种角色的内容创作需求,极大丰富了技术团队的输出形式。
⑦ 垂直领域专业知识问答实测对比
通用大模型往往在特定垂直领域显得力不从心,因此我们重点测试了其在云计算架构、数据库内核原理及网络安全等深水区领域的表现。通过与该领域资深专家的参考答案进行比对,评估其专业度。
在关于 Kubernetes 调度器算法细节的问答中,模型准确阐述了默认调度器的过滤与打分机制,并能针对特定场景(如节点亲和性与反亲和性的冲突)给出合理的调优策略。在数据库索引优化方面,它不仅能解释 B+ 树的结构优势,还能结合具体查询语句分析执行计划,指出潜在的全表扫描风险。虽然在极度冷门或最新发布的细分技术上可能存在知识滞后,但在主流核心技术栈上,其回答的深度和准确性已经能够媲美中级以上的专业技术人员,足以作为日常技术咨询的可靠来源。
⑧ 模型响应速度与资源消耗效率分析
除了功能表现,运行成本也是企业级应用必须考量的因素。我们对不同参数量级的模型进行了同等任务下的资源消耗监测,重点关注 GPU 显存占用、推理延迟与 token 生成速度的比值。
数据显示,经过量化优化和架构剪枝的新一代模型,在保持高精度输出的同时,显著降低了算力需求。在相同的硬件配置下,其并发处理能力是旧款模型的数倍,而单位 token 的计算能耗却大幅下降。这意味着在部署私有化模型或调用云服务时,企业可以用更低的预算获得更高的服务吞吐量。对于需要大规模部署 AI 助手的研发团队而言,这种高效的资源利用率直接转化为运营成本的节约,使得在更多业务环节嵌入智能化成为经济可行的选择。
⑨ 典型应用场景下的最佳实践建议
基于上述测试,我们可以总结出几类典型场景的最佳实践。首先,在辅助编码场景中,建议采用“小步快跑”的策略,将大任务拆解为具体的函数或模块让模型生成,并配合人工审查,这样既能利用其生成效率,又能规避潜在逻辑漏洞。其次,在文档处理场景中,利用其长上下文优势,先让模型构建大纲,再分章节填充细节,最后统一润色,能获得结构更严谨的输出。
此外,在技术调研时,不要只问“是什么”,而要追问“为什么”和“怎么做”,引导模型展示推导过程和对比分析,从而获得更有深度的洞察。对于多轮对话,适时地总结前文共识并明确下一步目标,可以有效防止模型偏离主题。将这些策略融入日常开发流程,能最大化地释放 AI 工具的潜能,使其真正成为提升生产力的引擎。
⑩ 能力边界界定与使用注意事项说明
尽管表现优异,但我们必须清醒地认识到模型的能力边界。它并非全知全能,尤其在涉及实时性极强的数据(如最新的股市行情、刚刚发布的漏洞情报)时,可能会因训练数据截止时间而产生幻觉。此外,在处理极度依赖特定企业内部上下文或未经公开的训练数据时,其表现也会受限。
使用者应始终保持批判性思维,将模型视为“副驾驶”而非“自动驾驶”。对于生成的代码,必须进行严格的测试和安全审计;对于提供的建议,需结合实际情况进行验证。切勿将敏感数据、密钥或个人隐私直接输入到公共模型中。只有在明确其局限性并采取相应防范措施的前提下,我们才能安全、高效地享受人工智能带来的技术红利,避免盲目信任带来的潜在风险。
如目录二所示,大家觉得Deepseek生成的这部分内容怎么样?
欢迎交流~!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)