统计学习方法第三章:K 近邻法-超深度解析讲解
学 KNN,不是因为它现在一定是最强算法,而是因为它特别适合建立机器学习的几个核心直觉。
KNN 是最直观的机器学习模型之一。
它的思想就是:
跟你最像的人,大概率和你属于同一类。
比如判断一个电影用户喜不喜欢某部电影,可以看和他兴趣最接近的用户怎么评价。判断一个新样本属于哪类,可以看它附近的样本属于哪类。
这个思想非常朴素,但很多复杂方法背后也有类似的“相似性”思想。
它不只是一个分类算法,更是后面很多机器学习、推荐系统、检索系统和向量搜索方法的基础直觉。
第一章:k 近邻法概览
k 近邻法(k-Nearest Neighbors, kNN),核心思想很简单:
给一个新的样本,看训练集中离它最近的 k 个样本,然后根据这 k 个邻居来判断它的类别或预测数值。
这一章大致讲了几件事:
1. k 近邻模型
kNN 没有显式训练过程。它不像逻辑回归、SVM 那样先学出一组参数,而是把训练数据保存下来。
预测时才开始计算:
新样本属于哪个类别,取决于它附近 k 个训练样本中多数属于哪个类别。
比如 k = 3,新点附近最近的 3 个点里有 2 个是 A 类、1 个是 B 类,那么新点就判为 A 类。
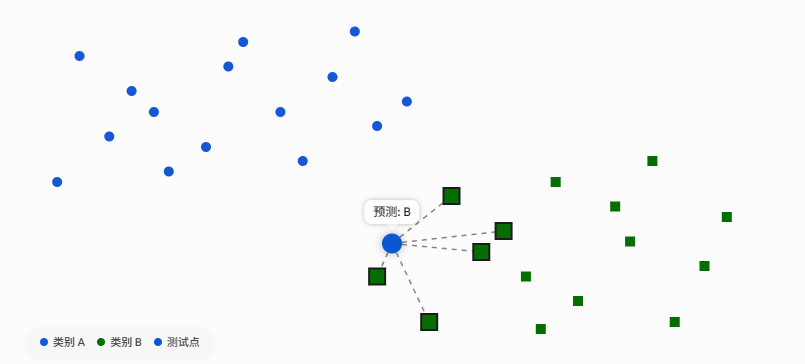
2. 距离度量
要判断“近不近”,就要定义距离。书里主要讲了 Lp 距离,常见的有:
- 欧氏距离:最常用,也就是直线距离
- 曼哈顿距离:坐标差的绝对值之和
- 切比雪夫距离:各维差值中的最大值
所以 kNN 的结果会受到距离定义的影响。
3. k 值选择
k 是很重要的超参数。
k 太小:模型容易受噪声影响,容易过拟合。
k 太大:模型变得太平滑,容易欠拟合。
极端一点:
- k = 1:新样本直接跟最近的那个点同类
- k = 训练集总数:所有样本都参与投票,基本失去局部判断能力
所以实际中通常通过交叉验证来选 k。
4. 分类决策规则
分类时一般用 多数表决:
在最近的 k 个点中,哪个类别出现最多,就预测为哪个类别。
从理论上看,这等价于在经验风险最小化框架下,用 0-1 损失函数做分类决策。
5. k-d 树
这是第三章比较重要、也稍微难一点的部分。
朴素 kNN 每次预测都要计算新样本和所有训练样本的距离。如果训练集很大,会很慢。
所以书里介绍了 k-d 树 来加速最近邻搜索。
它的思想是:
把特征空间不断按某一维切分,形成一棵二叉树。查找最近邻时,不必遍历所有点,而是通过树结构减少搜索范围。
不过 k-d 树在低维空间比较有效,高维时效果会下降,这和“维度灾难”有关。
这一章的重点可以概括为
kNN = 距离度量 + k 值选择 + 分类决策规则
再加上一个加速搜索的数据结构:k-d 树。
这一章本身算法思想不难,但李航书里会从统计学习的角度讲得比较严谨,尤其是 k-d 树搜索过程可能第一次看会有点绕。
第二章:k邻近算法
k 近邻算法(kNN)是一种很直观的分类/回归方法:
判断一个新样本时,先在训练集中找到离它最近的 k 个样本,然后看这 k 个“邻居”怎么说。
举个例子:
假设你要判断一个水果是苹果还是梨。我们用“重量”和“甜度”作为特征。现在来了一个新水果,kNN 会找训练数据里和它最像的 k 个水果。
如果取 k = 5,最近的 5 个水果里:
- 3 个是苹果
- 2 个是梨
那 kNN 就预测它是苹果。
它的核心有三点:
- 距离度量:怎么判断“近”?
常用欧氏距离,比如平面上两点的直线距离。 - k 值选择:看几个邻居?
k 太小容易受噪声影响;k 太大又可能把很远的点也算进来。 - 决策规则:邻居们怎么投票?
分类问题一般用多数投票;回归问题一般取邻居标签的平均值。
它的特点是:训练阶段几乎不做事,预测时才计算距离。所以 kNN 很容易理解,但数据量大、维度高时预测会比较慢。
书中将 -近邻算法从数学角度进行了严谨的定义,明确了它的输入、输出和执行步骤:
-
输入:
-
训练数据集
。其中
是特征向量(即数据的特征),
是类别标签。
-
一个新的输入实例(我们需要预测的特征向量)
。
-
-
输出:
-
实例
。
-
-
执行步骤:
-
找邻居: 根据给定的距离度量,在训练集
中找出与新实例
个点。包含这
。
-
做决策: 在这
-
书中用了一个非常经典的公式来表达“多数表决”这一步:
这个公式看起来吓人,其实意思很简单:对于每一个类别 ,统计一下邻域
中有多少个点属于这个类别(
是指示函数,属于该类就记为 1,否则为 0)。最后,哪个类别得票最多(
),
就属于哪个类别。
在给出完整定义后,特别指出一个特殊情况:当 k=1 时,该算法被称为最近邻算法 (Nearest Neighbor Algorithm)。
-
在这种情况下,模型连“表决”都省了。对于新输入的实例x,它直接在训练集中找到离它最近的那一个数据点,那个数据点是什么类别,x就直接被预测为什么类别。
你会发现一个很神奇的事情:它根本没有“训练 (Training)”这个步骤。
在别的算法里(比如线性回归、神经网络),算法总是先拿训练集 去疯狂计算,算出几个最优的权重参数 (
),然后丢掉原始数据,只用参数去预测新数据。
但 k-NN 算法没有这一步。这种特性在机器学习中被称为 懒惰学习 (Lazy Learning)。
这意味着:
-
它没有显式的模型: k-NN 实际上是把整个训练集当成了模型本身。
-
计算压力全在测试阶段: 平时什么都不算,等新数据 x 一来,就得现场和所有的 N 个训练数据算一遍距离。这为后面引出 kd 树(优化搜索速度) 埋下了巨大的伏笔。
第三章:k-近邻模型
k-近邻法使用的模型,实际上对应于特征空间的一个划分。 这个模型完全由三个要素决定:距离度量、k 值的选择、分类决策规则。
要素一:距离度量(特征空间中的“尺子”)
特征空间中的两个点到底离得有多远?这需要一把数学上的“尺子”。书中引入了经典的 距离(明可夫斯基距离,Minkowski Distance)。
设特征空间是 维实数向量空间
,有两个点
和
。它们各自有
个坐标,分别记作:
它们之间的 距离定义为:
符号拆解:
-
:注意,这里的括号 (l) 不是外边顶个自乘方,而是指第 l 个特征(或第 l 个维度)。比如身高、体重,l=1 是身高差距,l=2 是体重差距。
-
:算出两个点在第
个维度上的绝对差距,然后求它的
次方。
-
:把所有
个维度上的方差全部加起来。
-
:最后,把加总的结果开
三个极其重要的特例:
书里专门推导了当 取不同值时,这把“尺子”的几何形态会发生什么翻天覆地的变化:
1.当 时:欧氏距离 (Euclidean Distance)
这就是我们从小学到大的“两点之间直线距离”。
2.当 时:曼哈顿距离 (Manhattan Distance)
就是每一维差值的绝对值相加。
3.当 时:切比雪夫距离 (Chebyshev Distance)
它只看所有维度中差距最大的那一维。
李航老师在书里给出了严格的极限证明。当 p 趋近于无穷大时,整个根式求和会被差距最大的那一个维度完全主导。
还有一点很重要:使用 KNN 前通常要做特征归一化或标准化。比如“收入”是几万,“年龄”是几十,如果不处理,收入这一维会主导距离计算。
要素二:k 值的选择(过拟合与欠拟合的博弈)
选几个邻居来投票,对结果影响极大。书里从“误差”的角度深度剖析了 k 值的选法:
-
如果 k 选得太小(比如 k=1):
-
现象: 只有紧挨着的邻居能决定我的命运。
-
理论: “近似误差 (Approximation Error)”会减小,因为只有非常近的样本才起作用;但是“估计误差 (Estimation Error)”会增大,哪怕旁边只有一个噪声(错误数据),也会彻底带偏预测。
-
结论: 模型太复杂,极易发生过拟合。此时对应的划分边界会非常扭曲、破碎。
-
-
如果 k 选得太大(比如 k=N):
-
现象: 全校所有人一起投票。
-
理论: 这时无论新来一个什么样本,它的预测结果永远是全训练集里人数最多的那个类别。
-
结论: “近似误差”变得极大,因为根本不考虑局部的特征空间了。模型过于简单,发生欠拟合。
-
要素三:分类决策规则(为什么通常用多数表决?)
设训练集为:
T={(x1,y1),(x2,y2),…,(xN,yN)}
对于一个新样本 x,先找到它的 k 个最近邻,记作 Nk(x)。
然后看这些邻居里哪个类别出现次数最多:
意思是:
在 x 的 k个邻居中,统计每个类别出现的次数,哪个类别票数最多,就把 x 分到哪个类别。
书中给出了一个非常严谨的数学证明:多数表决规则等价于经验风险最小化。
简单来说,分类任务的损失函数通常是 0-1 损失(猜对了记 0 分误差,猜错了记 1 分误差)。如果我们希望在 k 个邻居所在的区域里,犯错的概率(经验风险)最低,那么唯一正确的数学策略就是:选那个包含样本最多的类别。这就用数学证明了“少数服从多数”在统计学习中的正确性。
第四章:KD树
KNN 的朴素做法是:
每来一个新点,就和训练集里所有点算距离,然后找最近的 k 个。
问题是:如果训练集有 N 个样本,每次预测都要算 N 次距离,数据大了会很慢。
KD 树就是用来加速“找最近邻”的数据结构。
-
如果你有 1000 个数据,算 1000 次,没问题。
-
如果你有 1000 万个数据(比如推荐系统里的用户),算 1000 万次?这在工业界是绝对无法接受的。这种暴力搜索的时间复杂度是 O(N)。
为了解决这个问题,我们需要一种方法,能在搜索时跳过那些“显然离得很远”的数据,把时间复杂度降到 O(log N)。这就是 kd 树 (K-Dimensional Tree) 的使命。
这里的 k 和 k-近邻里的 k 完全是两码事
k-NN 里的 k 指的是“找几个邻居”;而 kd 树里的 k 指的是“数据的特征维度”。比如数据有(身高、体重、年龄)三个特征,那就是 3d 树。
第一部分:如何构建 kd 树?(切蛋糕原理)
kd 树本质上是对 维空间的一个不断划分。你可以把它想象成在切一块正方形的蛋糕。
书中使用了这样一个经典的二维数据集作为例子:
第一步:选择一个维度
二维数据有两个维度:
第 1 维是横坐标 x,第 2 维是纵坐标 y。
通常会轮流选择维度:
第一层按第 1 维切分;
第二层按第 2 维切分;
第三层再按第 1 维切分;
依此类推。
第二步:选中位数点作为根节点
第一层按第 1 维排序:(2,3),(4,7),(5,4),(7,2),(8,1),(9,6)
中间点可以选:(7,2),于是 (7,2) 作为根节点。
左边是第 1 维小于它的点:(2,3),(4,7),(5,4)
右边是第 1 维大于它的点:(8,1),(9,6)
第三步:对子区域递归建树
左子树下一层按第 2 维排序:(2,3),(5,4),(4,7)
选中位数:(5,4)
右子树也按第 2 维排序:(8,1),(9,6)
选一个作为根,比如:(9,6)
这样不断递归,就得到一棵二叉树。
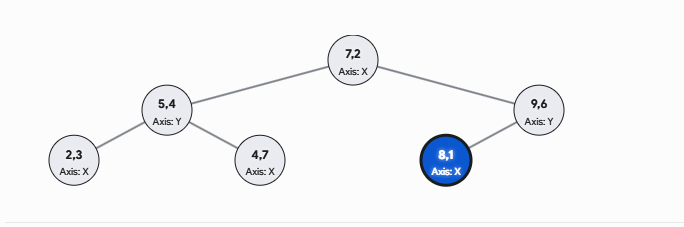
第二部分:如何搜索 kd 树?(核心难点:回溯)
建树只是为了找得快。当我们拿一个新的测试点进去找“最近邻”时,过程非常精妙:
步骤 1:二叉树狂奔
拿着新点,从树根开始比对。如果在 x 轴比根节点小,就去左子树;大就去右子树。一路狂奔到底部的叶子节点。
我们把这个叶子节点暂定为“当前最近邻点”,算出它们俩的距离(比如距离是 r)。
步骤 2:画个圈圈,开始回溯
由于我们刚才是一路“盲目”走到底的,旁边的分支里可能藏着更近的点。怎么判断呢?
我们以测试点为圆心,以刚才算出的距离 r 为半径,画一个圆(在多维叫超球体)。然后顺着树往上爬(回溯):
-
情况 A(没交界): 如果这个圆没有穿过父节点切的那条线。说明线的另一边绝对不可能有更近的点!我们直接把另一半空间全部砍掉(剪枝),这就省去了大量计算。
-
情况 B(有交界): 如果这个圆穿过了父节点切的那条线。糟糕,说明线的另一边可能有更近的点。我们必须跨过这条线,进入另一半空间去搜索。如果找到了更近的,就更新“当前最近邻点”,缩小圆的半径 r。
不断往上爬,直到退回到根节点,搜索结束。最后拿在手里的那个点,就是真正的最近邻。
假设我们要找新点:x=(3,4.5) 的最近邻。
从根节点开始,看当前节点按哪个维度切分。
比如根节点是 (7,2),第一层按第 1 维切分。
因为:3<7所以去左子树。
到下一层,节点是 (5,4),这一层按第 2 维切分。因为:4.5>4所以去右子树。
到了右子树,看到最终的叶节点(4,7),于是这个叶节点就是可能最近的点
问题是,最近点不一定就在刚才走过的那一边。
回溯时维护一个当前最近距离,记作 d
对于某个切分平面,如果目标点到这个切分平面的距离小于当前最近距离 d,说明另一边区域里可能有更近的点,就要去另一边看看。
如果目标点到切分平面的距离大于当前最近距离 d,说明另一边不可能有更近的点,可以直接剪枝。
这就是 KD 树加速的关键:能剪掉很多不可能的区域。
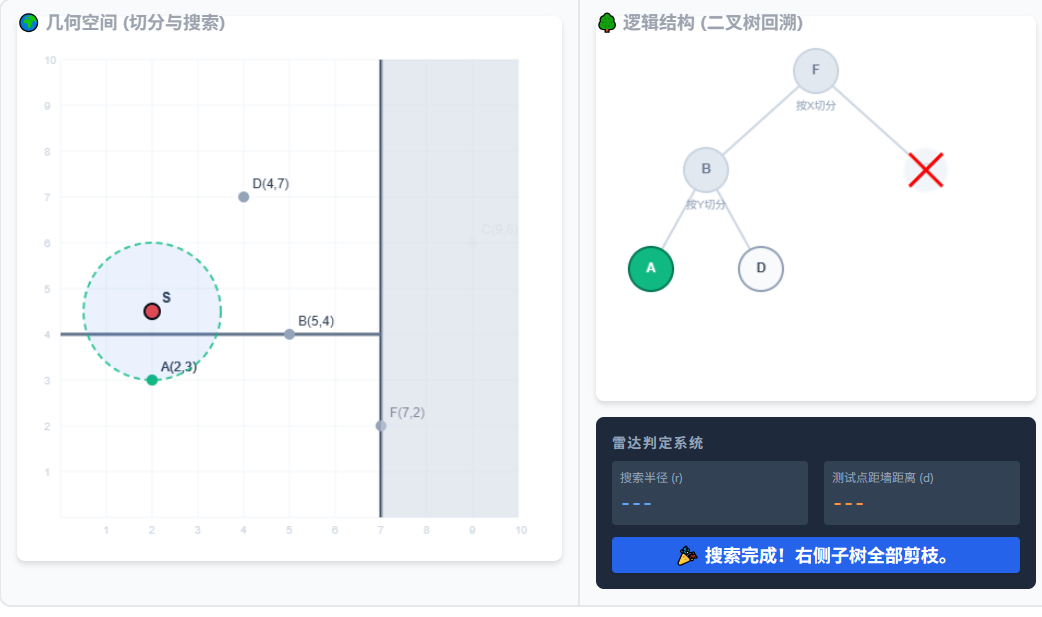
回溯演示
1.观察右侧树,算法比较坐标,一路向下寻找到叶子节点 D。暂定最近点为 D。
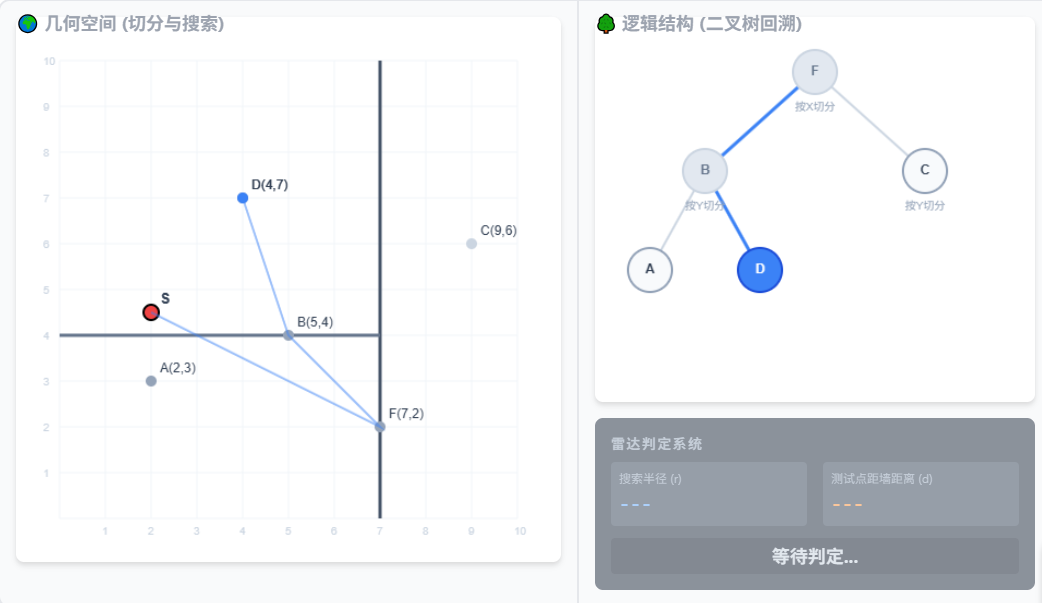
2.算出 S 到 D 的距离是 3.20。以 S 为圆心画出半径为 3.20 的【搜索圆】。
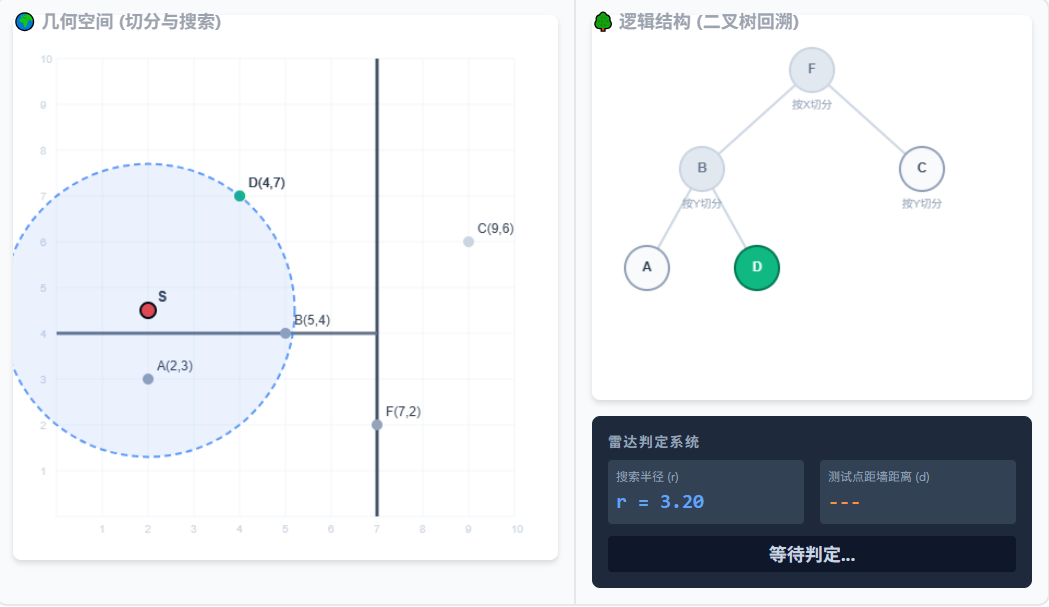
3.【开始回溯】顺着右侧树往上走,回到父节点 B。发现 S 离 B 只有 3.04,比 D 近!更新最近点为 B,搜索圆缩小!
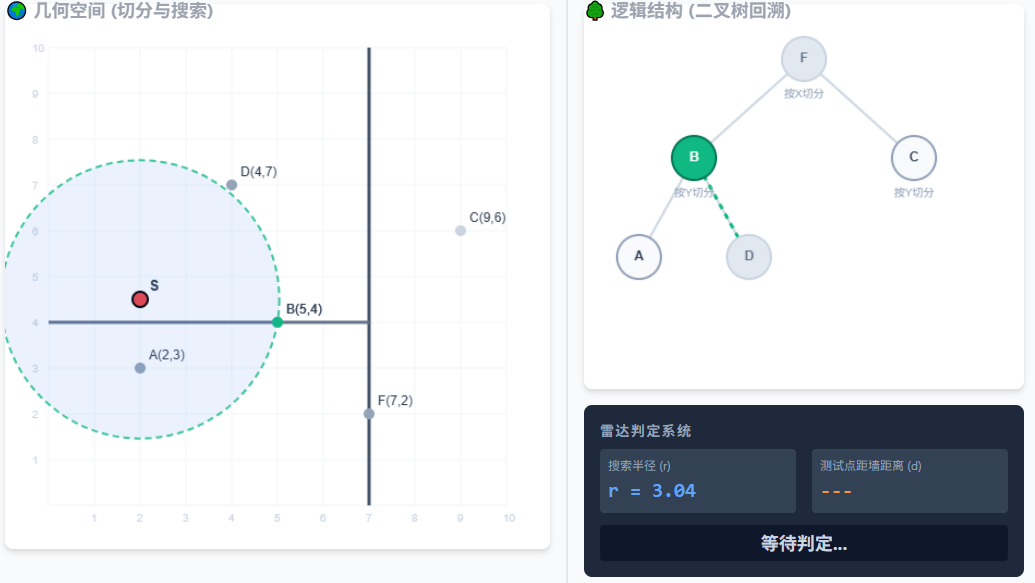
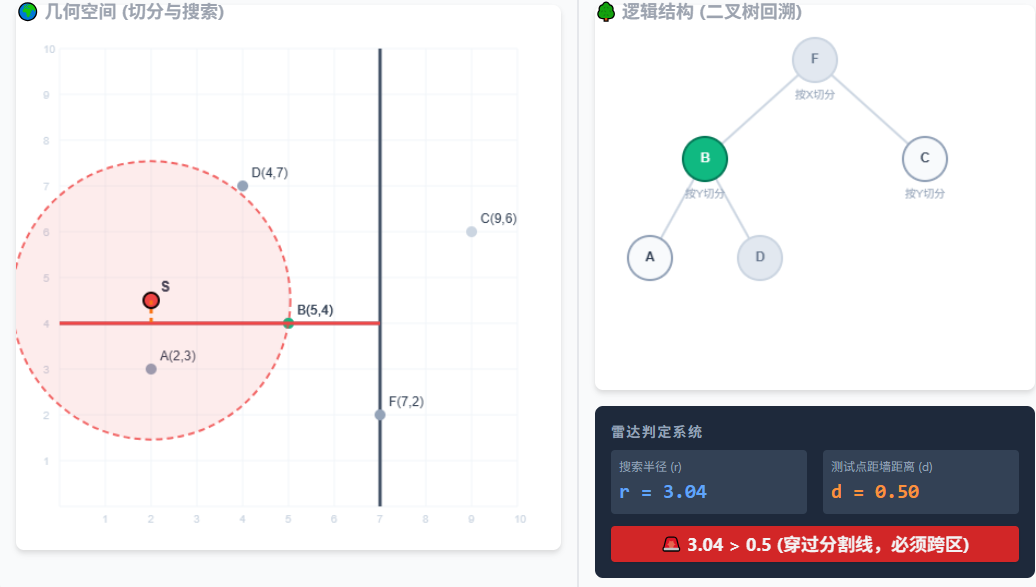
4.节点 B 是一道 Y=4 的水平墙。看右侧雷达!搜索半径(3.04) > 距墙距离(0.5)。圆撞破了墙!必须跨到另一边去搜!
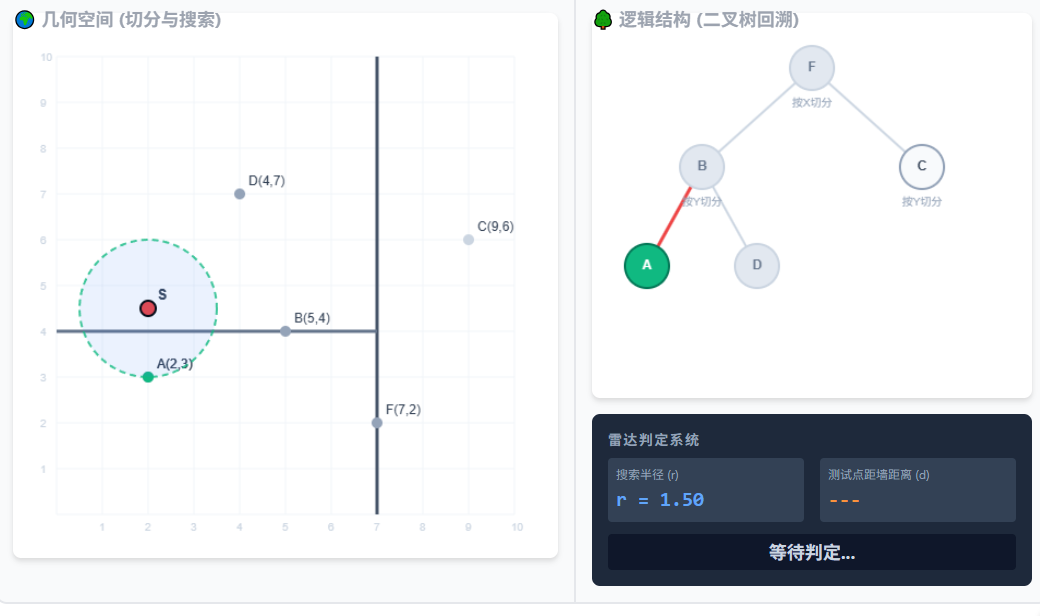
5.由于撞墙,算法被迫进入 B 的另一个子节点 A。奇迹发生!S 离 A 只有 1.5!更新最近点,圆大幅度缩小!
6.【继续回溯】回到根节点 F。F 是一道 X=7 的垂直墙。看雷达!搜索半径(1.5) < 距墙距离(5)。圆连墙的边都摸不到!
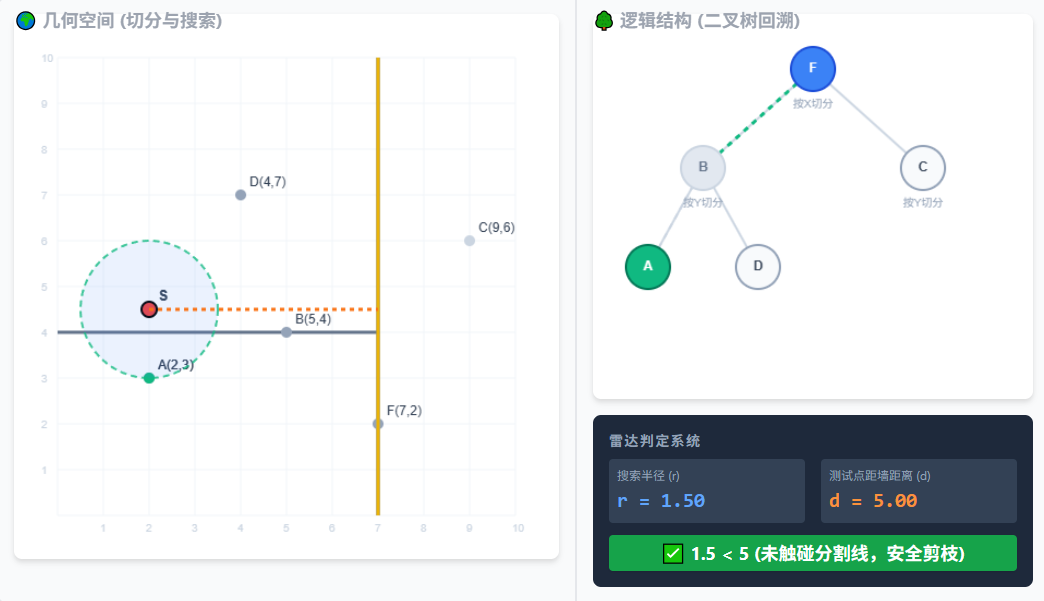
7.既然圆摸不到根节点的墙,说明右边整棵子树(节点 C 及其下面的所有可能点)绝对不可能有更近的了。直接在树上打叉砍掉,空间变灰!大功告成,最近点是 A。
KD 树在低维数据中效果比较好,比如二维、三维、十几维以内。
但维度很高时,效果会明显下降。
原因是:高维空间里点与点之间的距离会变得不那么有区分度,很多区域都可能包含近邻,剪枝效果变差。
这就是常说的维度灾难。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)