TSBS 实测:KaiwuDB VS TimescaleDB 性能对比,原生时序与 PG 时序化差距有多大
在时序数据库领域,TimescaleDB 作为 PostgreSQL 生态的时序化方案,扩时序能力都会优先考虑,是 PG 系时序方案的标杆。而 KaiwuDB 这两年发声也挺多的,作为国产原生时序数据库,在各类基准测试里表现亮眼,往期几篇我也依次分享了KaiwuDB 与 IoTDB、TDengine、InfluxDB 的对比测试数据情况。
这次依然还是想沿用 TSBS 标准基准,想来看看 PG 生态主流时序化方案 VS 国产原生时序新锐,两者技术路线完全不同的情况下到底性能差异如何,分享给同样在时序选型的朋友参考。
一、测试环境与配置
本次测试依然保证两个数据库(KaiwuDB v3.1.0 与 TimescaleDB v2.25.2 )的运行环境完全一致,排除了环境差异对测试结果的干扰,全程采用 Docker 容器化部署,具体配置如下:
• 2 颗 Intel Xeon Gold 6240 CPU(2.6GHz 基础频率,最高 3.9GHz),共 72 逻辑核(18 核 / 颗 ×2,超线程开启),2 个 NUMA 节点
• 通过 Docker 限制单节点仅使用 16 核,单节点内存上限为 32GB
• 总容量 394.8GB(MemTotal: 394835452 kB),支持 DirectMap4k / DirectMap2M / DirectMap1G 页映射
• 每个容器(节点)绑定单个 1.8TiB Intel NVMe 硬盘
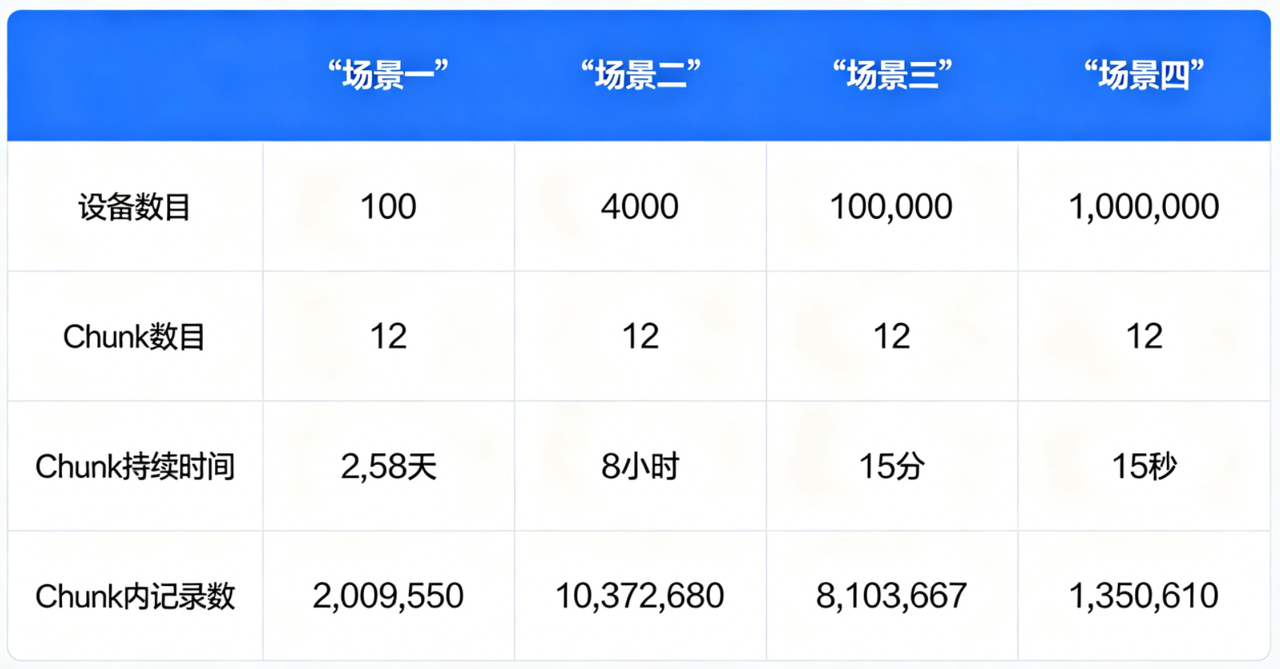
PS:其中,为了保证较好的性能,TimescaleDB 需要针对不同的场景设置不同的 Chunk 参数,不同场景下参数的设置如下表所示。
(此参数的设置,充分参考了对比报告【TimescaleDB vs. InfluxDB: Purpose Built Differently for Time-Series Data.https://www.timescale.com/blog/timescaledb-vs-influxdb-for-time-series-data-timescale-influx-sql-nosql-36489299877/】中推荐的配置参数设置,以确保能够最大化写入性能指标。)
二、核心结论一眼看懂
-
写入优势:KaiwuDB 在 4/4 个场景中全部领先,吞吐最高超 15 倍,原生架构优势明显。
-
查询领先:Worker 1 相较于TimescaleDB 平均提升 76.6%,Worker 8 提升 87.6%,几乎全场景更快。
-
复杂查询:高聚合、lastpoint 等场景差距达百倍级。
-
稳定性能:数据量上来后,TimescaleDB 性能衰减严重,KaiwuDB 几乎无波动。
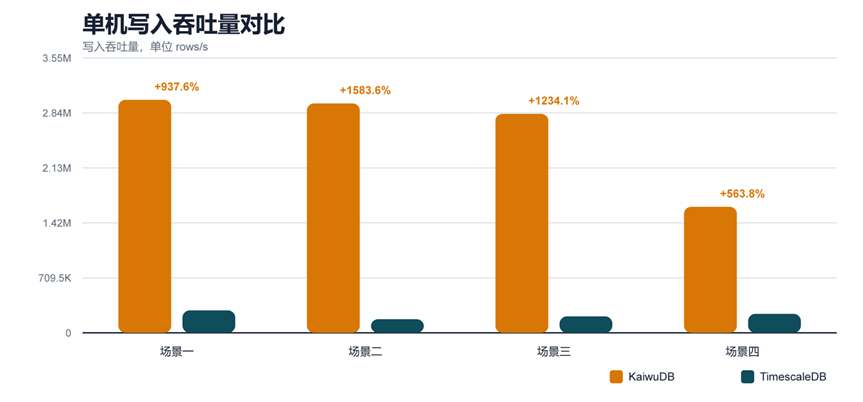
三、写入性能(rows/s,数值越高越好)
写入部分使用写入速度作为吞吐指标,统一按 rows/s 展示,数值越高越好。相对差异采用 (KaiwuDB - TimescaleDB) / TimescaleDB 计算。
|
节点 |
场景 |
KaiwuDB rows/s |
TimescaleDB rows/s |
相对差异 |
|
单机 |
场景一 |
3006478.08 |
289739.45 |
9.376 |
|
单机 |
场景二 |
2961473.92 |
175900.04 |
15.836 |
|
单机 |
场景三 |
2825616.69 |
211793.09 |
12.341 |
|
单机 |
场景四 |
1626088.47 |
244959.88 |
5.638 |
KaiwuDB 在所有场景下吞吐都大幅领先,尤其在中规模场景,吞吐接近 16 倍差距。原生时序存储引擎对高并发写入的优化,明显强于 PG 时序化方案;TimescaleDB 写入上限偏低,数据量增大后吞吐下滑明显。
四、查询性能(ms,越低越好)
查询部分采用公式 (TimescaleDB 延迟 - KaiwuDB 延迟) / TimescaleDB 延迟计算相对差异。正值表示 KaiwuDB 查询延迟更低,负值表示 TimescaleDB 更优。测试分别在 Worker 1、Worker 8 两种并发下实测,覆盖 15 类典型时序查询,下图为数据差异总览:
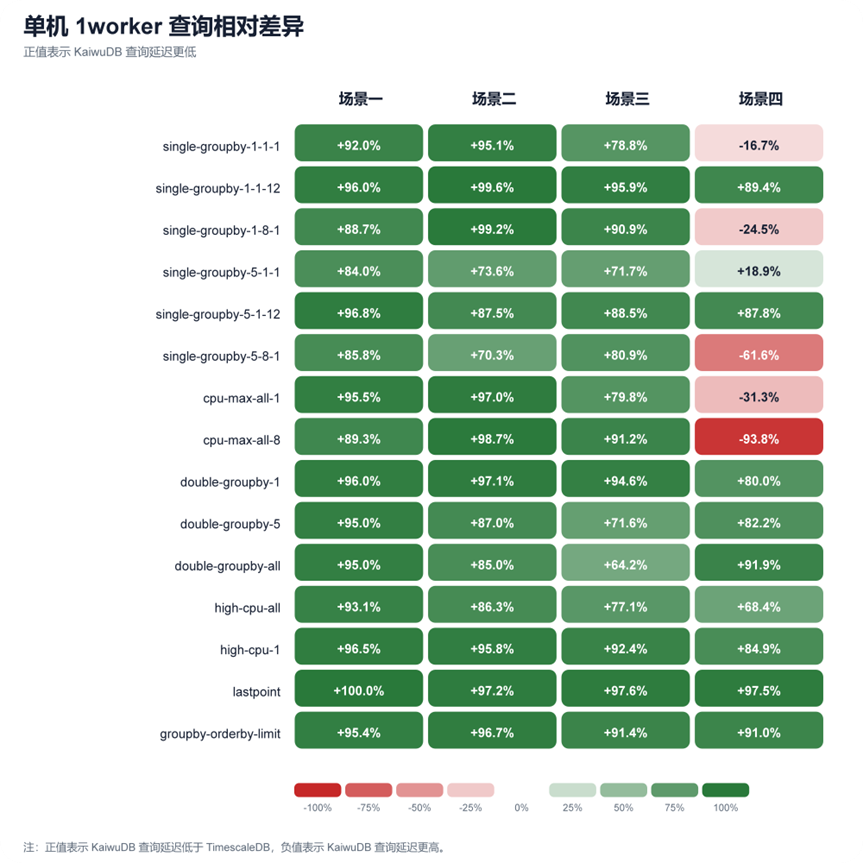
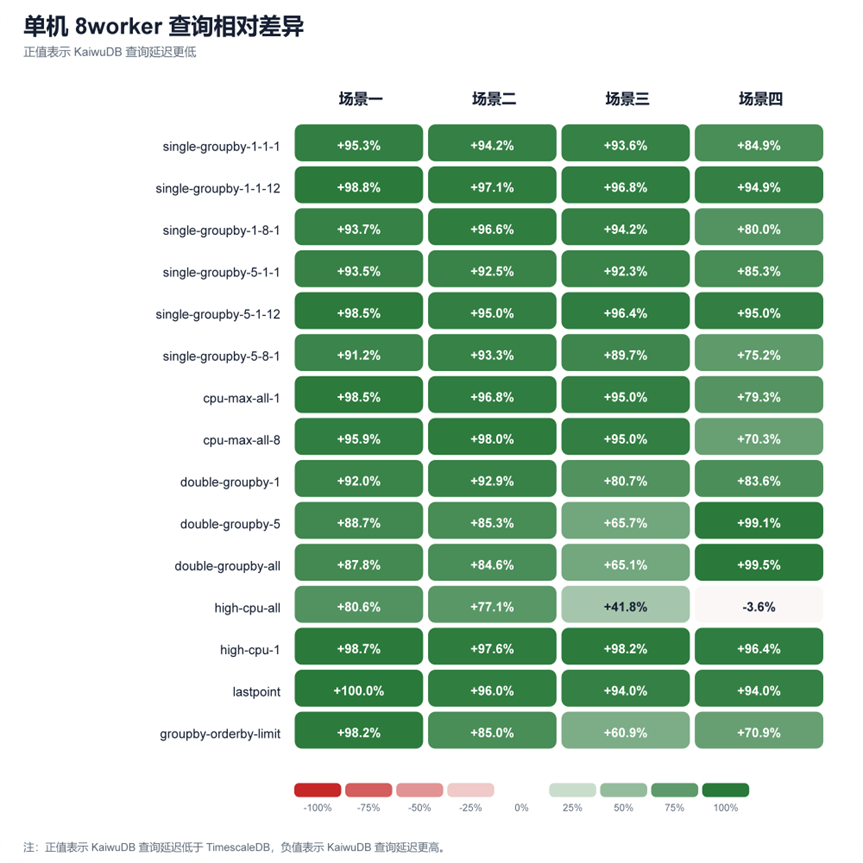
通过上图可以看出:
• 单机 worker 1查询:KaiwuDB 在 55/60 个测点延迟更低,平均改善 +76.6%。
• 单机 worker 8查询:KaiwuDB 在 59/60 个测点延迟更低,平均改善 +87.6%。
|
节点 |
worker |
KaiwuDB领先数 |
平均提升 |
最佳查询项 |
最弱查询项 |
|
|
单机 |
1 |
55/60 |
76.60% |
lastpoint (+98.1%) |
single-groupby-5-8-1 (+43.9%) |
|
|
单机 |
8 |
59/60 |
87.60% |
high-cpu-1 (+97.7%) |
high-cpu-all (+49.0%) |
|
接下来,我们分别看看小规模(100 设备)、中规模(4000 设备)、大规模及超大规模(10 万 / 100 万设备),在 Worker1(低并发)、 Worker8(高并发)不同情况下的性能情况。
4.1 小规模(100 台)
Worker 1
在单 Worker 低并发下,两者均能快速响应。KaiwuDB 在所有查询类型上全面领先,尤其在 lastpoint(最新点查询)上优势巨大,延迟从 TimescaleDB 的 7114ms 降至 0.9ms。
Worker 8
当并发提升到 8 Workers 后,TimescaleDB 的延迟开始显著增加,性能衰减明显,而 KaiwuDB 依旧保持极低且稳定的延迟。在 lastpoint 和复杂聚合查询上,KaiwuDB 的性能优势进一步扩大,普遍快一到两个数量级。
|
Worker 1查询项 |
KaiwuDB(ms) |
TimescaleDB(ms) |
相对差异 |
|
single-groupby-1-1-1 |
0.92 |
11.54 |
92.00% |
|
single-groupby-1-1-12 |
1.34 |
33.51 |
96.00% |
|
single-groupby-1-8-1 |
1.34 |
11.88 |
88.70% |
|
single-groupby-5-1-1 |
1.08 |
6.75 |
84.00% |
|
single-groupby-5-1-12 |
2.06 |
63.65 |
96.80% |
|
single-groupby-5-8-1 |
1.75 |
12.32 |
85.80% |
|
cpu-max-all-1 |
1.58 |
35.09 |
95.50% |
|
cpu-max-all-8 |
4.06 |
37.79 |
89.30% |
|
double-groupby-1 |
6.15 |
155.19 |
96.00% |
|
double-groupby-5 |
9.29 |
187.64 |
95.00% |
|
double-groupby-all |
13.04 |
259.86 |
95.00% |
|
high-cpu-all |
6.75 |
98.51 |
93.10% |
|
high-cpu-1 |
1.22 |
34.71 |
96.50% |
|
lastpoint |
0.9 |
7114.12 |
100.00% |
|
groupby-orderby-limit |
1.45 |
31.56 |
95.40% |
|
worker 8查询项 |
KaiwuDB (ms) |
TimescaleDB (ms) |
KaiwuDB 相对差异 |
|
single-groupby-1-1-1 |
0.81 |
17.23 |
95.30% |
|
single-groupby-1-1-12 |
1.13 |
91.71 |
98.80% |
|
single-groupby-1-8-1 |
1.07 |
16.88 |
93.70% |
|
single-groupby-5-1-1 |
0.75 |
11.46 |
93.50% |
|
single-groupby-5-1-12 |
1.51 |
103.41 |
98.50% |
|
single-groupby-5-8-1 |
1.57 |
17.94 |
91.20% |
|
cpu-max-all-1 |
1.15 |
77.37 |
98.50% |
|
cpu-max-all-8 |
3.54 |
85.37 |
95.90% |
|
double-groupby-1 |
16.21 |
202.58 |
92.00% |
|
double-groupby-5 |
23.38 |
206.66 |
88.70% |
|
double-groupby-all |
33.4 |
274.52 |
87.80% |
|
high-cpu-all |
22.89 |
118.18 |
80.60% |
|
high-cpu-1 |
1 |
75.13 |
98.70% |
|
lastpoint |
1.4 |
8232.38 |
100.00% |
|
groupby-orderby-limit |
1.48 |
80.4 |
98.20% |
4.2 中规模(4000 台)
Worker 1
简单查询差距依然不大,但在 double-groupby(双维度分组)等复杂聚合查询上,差距开始急剧拉大。例如 double-groupby-1 查询,TimescaleDB 耗时 6300ms,而 KaiwuDB 仅需 183.69ms,优势高达 97.1%。
Worker 8
并发压力下,TimescaleDB 的多个查询开始进入秒级甚至 8 秒以上(double-groupby-all 达 8073ms),性能严重下滑。KaiwuDB 虽然延迟相比低并发也有所增加,但始终保持在可控范围内(最高 1241ms),表现出极佳的性能韧性。
|
worker 1查询项 |
KaiwuDB(ms) |
TimescaleDB(ms) |
相对差异 |
|
single-groupby-1-1-1 |
0.97 |
19.81 |
95.10% |
|
single-groupby-1-1-12 |
1.42 |
358.64 |
99.60% |
|
single-groupby-1-8-1 |
1.74 |
225.08 |
99.20% |
|
single-groupby-5-1-1 |
1.12 |
4.24 |
73.60% |
|
single-groupby-5-1-12 |
2 |
16.02 |
87.50% |
|
single-groupby-5-8-1 |
2.72 |
9.17 |
70.30% |
|
cpu-max-all-1 |
1.61 |
54.44 |
97.00% |
|
cpu-max-all-8 |
5.56 |
434.68 |
98.70% |
|
double-groupby-1 |
183.69 |
6300.32 |
97.10% |
|
double-groupby-5 |
283.36 |
2179.98 |
87.00% |
|
double-groupby-all |
401.24 |
2670.62 |
85.00% |
|
high-cpu-all |
168.7 |
1232.48 |
86.30% |
|
high-cpu-1 |
1.13 |
27.1 |
95.80% |
|
lastpoint |
3.22 |
114.86 |
97.20% |
|
groupby-orderby-limit |
4.41 |
134.79 |
96.70% |
|
worker 8查询项 |
KaiwuDB(ms) |
TimescaleDB(ms) |
相对差异 |
|
single-groupby-1-1-1 |
0.68 |
11.72 |
94.20% |
|
single-groupby-1-1-12 |
1.11 |
38.85 |
97.10% |
|
single-groupby-1-8-1 |
1.26 |
37.45 |
96.60% |
|
single-groupby-5-1-1 |
0.79 |
10.47 |
92.50% |
|
single-groupby-5-1-12 |
1.59 |
32.1 |
95.00% |
|
single-groupby-5-8-1 |
1.42 |
21.13 |
93.30% |
|
cpu-max-all-1 |
1.07 |
33.17 |
96.80% |
|
cpu-max-all-8 |
3.68 |
186.18 |
98.00% |
|
double-groupby-1 |
561.16 |
7883.08 |
92.90% |
|
double-groupby-5 |
874.2 |
5940.89 |
85.30% |
|
double-groupby-all |
1241.75 |
8073.5 |
84.60% |
|
high-cpu-all |
825.85 |
3606.86 |
77.10% |
|
high-cpu-1 |
1.05 |
44.55 |
97.60% |
|
lastpoint |
7.75 |
193.24 |
96.00% |
|
groupby-orderby-limit |
16.54 |
110.47 |
85.00% |
4.3 大规模(10 万台)
Worker 1
TimescaleDB 性能严重承压,double-groupby-1 查询耗时高达 19715ms(近20秒),基本不具备可用性。KaiwuDB 虽然延迟也增长到秒级(1074ms),但相比 TimescaleDB 仍有近 20 倍的性能优势。lastpoint 查询上,KaiwuDB 同样保持近 20 倍的优势。
Worker 8
TimescaleDB 的性能彻底崩溃,大量复杂查询耗时在 8-22 秒之间。KaiwuDB 的高并发查询延迟虽然也上升至 5-7 秒,但整体可控,且在高负载下无任何失败或超时,稳定性优势彻底拉开。
|
worker 1查询项 |
KaiwuDB(ms) |
TimescaleDB(ms) |
相对差异 |
|
single-groupby-1-1-1 |
0.96 |
4.53 |
78.80% |
|
single-groupby-1-1-12 |
0.99 |
23.93 |
95.90% |
|
single-groupby-1-8-1 |
1.45 |
15.93 |
90.90% |
|
single-groupby-5-1-1 |
1.06 |
3.74 |
71.70% |
|
single-groupby-5-1-12 |
1.22 |
10.61 |
88.50% |
|
single-groupby-5-8-1 |
1.96 |
10.28 |
80.90% |
|
cpu-max-all-1 |
1.22 |
6.04 |
79.80% |
|
cpu-max-all-8 |
2.88 |
32.68 |
91.20% |
|
double-groupby-1 |
1074.26 |
19715.21 |
94.60% |
|
double-groupby-5 |
1689.85 |
5949.9 |
71.60% |
|
double-groupby-all |
2475.25 |
6917.85 |
64.20% |
|
high-cpu-all |
915.62 |
4005.01 |
77.10% |
|
high-cpu-1 |
0.94 |
12.35 |
92.40% |
|
lastpoint |
52.04 |
2207.94 |
97.60% |
|
groupby-orderby-limit |
72.43 |
845 |
91.40% |
|
worker 8查询项 |
KaiwuDB(ms) |
TimescaleDB(ms) |
相对差异 |
|
single-groupby-1-1-1 |
0.67 |
10.52 |
93.60% |
|
single-groupby-1-1-12 |
0.79 |
24.5 |
96.80% |
|
single-groupby-1-8-1 |
1.09 |
18.87 |
94.20% |
|
single-groupby-5-1-1 |
0.76 |
9.81 |
92.30% |
|
single-groupby-5-1-12 |
0.96 |
26.45 |
96.40% |
|
single-groupby-5-8-1 |
1.57 |
15.23 |
89.70% |
|
cpu-max-all-1 |
1 |
19.82 |
95.00% |
|
cpu-max-all-8 |
2.12 |
42.52 |
95.00% |
|
double-groupby-1 |
3550.44 |
18434.69 |
80.70% |
|
double-groupby-5 |
5425.19 |
15823.77 |
65.70% |
|
double-groupby-all |
7751.04 |
22178.53 |
65.10% |
|
high-cpu-all |
5096.47 |
8756.72 |
41.80% |
|
high-cpu-1 |
0.75 |
41.9 |
98.20% |
|
lastpoint |
169.74 |
2812.89 |
94.00% |
|
groupby-orderby-limit |
409.1 |
1045.82 |
60.90% |
4.4 超大规模(100 万台)
Worker 1
TimescaleDB 已到达极限,double-groupby-all 查询耗时超过 40 秒,lastpoint 查询也超过 21 秒。值得注意的是,在 single-groupby-1-1-1、single-groupby-1-8-1、cpu-max-all-1 等几个最简单的单维度点查上,TimescaleDB 的响应速度(<1ms)反常地优于 KaiwuDB(~1ms),可能是得益于其极端的缓存策略或执行计划优化,但并不影响整体性能格局。KaiwuDB 在所有复杂查询上依然保持压倒性优势,double-groupby-all 比对方快 91.9%。
Worker 8
并发拉满后,TimescaleDB 在部分双维度聚合查询上出现灾难性延迟,double-groupby-5 耗时 477295ms(约 8 分钟),double-groupby-all 更是高达 1152227ms(约 19 分钟),基本等同于不可用。而 KaiwuDB 即使在如此极限的压力下,所有查询仍能在 5.4 秒内返回,且无任何失败或中断,稳定性优势达到顶峰。
|
worker 1查询项 |
KaiwuDB(ms) |
TimescaleDB(ms) |
相对差异 |
|
single-groupby-1-1-1 |
0.91 |
0.78 |
-16.70% |
|
single-groupby-1-1-12 |
0.85 |
8 |
89.40% |
|
single-groupby-1-8-1 |
1.27 |
1.02 |
-24.50% |
|
single-groupby-5-1-1 |
1.03 |
1.27 |
18.90% |
|
single-groupby-5-1-12 |
1.07 |
8.75 |
87.80% |
|
single-groupby-5-8-1 |
1.39 |
0.86 |
-61.60% |
|
cpu-max-all-1 |
1.26 |
0.96 |
-31.30% |
|
cpu-max-all-8 |
1.57 |
0.81 |
-93.80% |
|
double-groupby-1 |
1581.06 |
7907.44 |
80.00% |
|
double-groupby-5 |
2644.18 |
14863.83 |
82.20% |
|
double-groupby-all |
3328.03 |
40925.49 |
91.90% |
|
high-cpu-all |
308.32 |
975.67 |
68.40% |
|
high-cpu-1 |
0.82 |
5.43 |
84.90% |
|
lastpoint |
527.71 |
21059.11 |
97.50% |
|
groupby-orderby-limit |
410.06 |
4544.74 |
91.00% |
|
worker 8查询项 |
KaiwuDB(ms) |
TimescaleDB(ms) |
相对差异 |
|
single-groupby-1-1-1 |
0.63 |
4.16 |
84.90% |
|
single-groupby-1-1-12 |
0.64 |
12.55 |
94.90% |
|
single-groupby-1-8-1 |
0.88 |
4.39 |
80.00% |
|
single-groupby-5-1-1 |
0.68 |
4.63 |
85.30% |
|
single-groupby-5-1-12 |
0.67 |
13.35 |
95.00% |
|
single-groupby-5-8-1 |
1.22 |
4.91 |
75.20% |
|
cpu-max-all-1 |
0.95 |
4.6 |
79.30% |
|
cpu-max-all-8 |
1.25 |
4.21 |
70.30% |
|
double-groupby-1 |
2703.22 |
16466.39 |
83.60% |
|
double-groupby-5 |
4494.9 |
477295.9 |
99.10% |
|
double-groupby-all |
5420.57 |
1152227 |
99.50% |
|
high-cpu-all |
1164.16 |
1123.89 |
-3.60% |
|
high-cpu-1 |
0.63 |
17.71 |
96.40% |
|
lastpoint |
1693.98 |
28103.82 |
94.00% |
|
groupby-orderby-limit |
1472.12 |
5066.39 |
70.90% |
五、实测总结
-
写入能力:KaiwuDB 原生时序引擎优势突出,吞吐碾压 PG 时序化方案,高并发写入更稳更强。
-
查询表现:整体领先,复杂查询拉开百倍差距,并发越高优势越明显。
-
稳定性:数据量越大、并发越高,TimescaleDB 衰减越严重;KaiwuDB 波动极小,更适合长期高负载运行。
-
架构差异:原生时序 vs PG 插件化,在高吞吐、高并发、复杂查询场景的差距被彻底放大。
六、选型建议
KaiwuDB 在大规模、高并发、复杂查询场景下优于 PG 时序化方案;TimescaleDB 更适合小规模、轻查询、依赖 PG 生态的边际场景。
✅ 优先选择 KaiwuDB 的场景
| 场景类型 | 典型业务 |
| 工业物联网 | 工厂设备监控、产线数据采集、预测性维护 |
| 运维监控(DevOps) | 服务器/容器/网络指标采集、告警、可视化 |
| 大规模时间序列分析 | 金融 tick 数据、能源计量、车联网轨迹 |
| 高并发查询场景 | 多用户仪表盘、实时大屏、多租户分析 |
| 长期高负载运行 | 7x24 小时采集、连续写入 + 查询混合负载 |
⚠️ 可考虑 TimescaleDB 的场景
| 场景类型 | 典型业务 |
| 小规模轻量监控 | 家庭智能设备、小型实验室数据、个人项目 |
| 重度依赖 PG 生态 | 已有大量 PG 业务代码、需要复用 PG 函数/索引/视图 |
| 查询模式极其简单 | 仅做单时间线点查、极简过滤 |
| 不考虑未来扩展 | 临时项目、PoC 验证、数据量可控 |
🚫 不建议选择 TimescaleDB 的场景
-
设备数 > 1 万台:中规模下 TimescaleDB 复杂查询已进入秒级,大规模下突破 20 秒。
-
并发 > 8:高并发下 TimescaleDB 延迟快速抬升,超大规模双维度聚合达分钟级,基本不可用。
-
需要 lastpoint / 高聚合 / 双维度分组:这些恰恰是时序场景核心需求,KaiwuDB 优势最明显(90%-99%)。
-
长期生产运行:TimescaleDB 性能随数据量增长衰减明显,运维成本高,需频繁调优 chunk 参数。
至此,已经基于TSBS和大家分享了高提名时序库TD、IoTDB、KaiwuDB、influxDB、TimescaleDB 的性能对比情况。后面大家还有什么想了解,欢迎评论区互动,继续和大家唠唠。
>>>

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)