基于 Python + LangChain + LangSmith 实现数据监控
前言
在 AI 应用开发中,我们往往专注于功能实现,却忽略了一个关键问题:我们的 AI 到底消耗了多少资源? 每次对话用了多少 Token?产生了多少费用?响应延迟如何?哪些模型和接口被调用得最多?
本文将以一个完整的聊天应用为例,从零开始搭建一套 AI 使用数据监控系统,涵盖后端数据采集、API 设计和前端可视化面板的完整实现。
技术栈
- 后端: Python + Flask + LangChain (ChatOpenAI / DashScope)
- 数据库: MySQL
- 前端: React 19 + Ant Design 5 + Zustand
一、整体架构
用户请求
│
▼
Flask 后端 (server.py)
│
├─ 调用 LLM (ChatOpenAI)
│ │
│ ▼
│ 提取 response_metadata (token 用量)
│ │
│ ▼
├─ log_usage() → 写入 MySQL (ai_usage_logs 表)
│
├─ /api/monitoring/summary ── 聚合统计
├─ /api/monitoring/daily ── 每日趋势
├─ /api/monitoring/recent ── 最近请求
│
▼
React 前端 (MonitoringPanel.jsx)
│
├─ 5 个统计卡片 (Tokens / 费用 / 请求数 / 延迟 / 系统状态)
├─ SVG 双轴趋势图 (面积图 + 柱状图)
├─ 模型分布 + 端点分布
└─ 可筛选/排序的请求记录表格
二、后端实现
2.1 创建数据库表
首先在 MySQL 中创建使用日志表:
CREATE TABLE IF NOT EXISTS ai_usage_logs (
id INT AUTO_INCREMENT PRIMARY KEY,
endpoint VARCHAR(100) NOT NULL COMMENT 'API 端点',
model VARCHAR(50) NOT NULL COMMENT '模型名称',
prompt_tokens INT DEFAULT 0,
completion_tokens INT DEFAULT 0,
total_tokens INT DEFAULT 0,
latency_ms INT DEFAULT 0 COMMENT '响应耗时(ms)',
cost DOUBLE DEFAULT 0 COMMENT '费用(CNY)',
conversation_id VARCHAR(36) DEFAULT NULL COMMENT '关联对话',
request_preview VARCHAR(200) DEFAULT NULL COMMENT '用户输入预览',
response_preview VARCHAR(200) DEFAULT NULL COMMENT 'AI回复预览',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
INDEX idx_model (model),
INDEX idx_endpoint (endpoint),
INDEX idx_created (created_at)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
每条记录对应一次 LLM 调用,存储端点、模型、Token 用量、延迟、费用等关键指标。
2.2 使用数据追踪模块
创建 usage_tracker.py,封装数据记录和提取逻辑:
"""AI 使用数据追踪模块"""
import pymysql
from config import DB_CONFIG
# DashScope 模型定价 (CNY / 1K tokens)
MODEL_PRICING = {
"qwen-plus": {"input": 0.004, "output": 0.012},
"qwen-vl-plus": {"input": 0.008, "output": 0.02},
}
def calculate_cost(model, prompt_tokens, completion_tokens):
"""根据模型定价计算费用"""
pricing = MODEL_PRICING.get(model, {"input": 0.004, "output": 0.012})
return (prompt_tokens * pricing["input"]
+ completion_tokens * pricing["output"]) / 1000
def log_usage(endpoint, model, prompt_tokens=0, completion_tokens=0,
total_tokens=0, latency_ms=0, conversation_id=None,
request_preview=None, response_preview=None):
"""记录一次 AI 调用的使用数据"""
if total_tokens == 0 and (prompt_tokens > 0 or completion_tokens > 0):
total_tokens = prompt_tokens + completion_tokens
cost = calculate_cost(model, prompt_tokens, completion_tokens)
conn = pymysql.connect(**DB_CONFIG)
try:
cursor = conn.cursor()
cursor.execute(
"""INSERT INTO ai_usage_logs
(endpoint, model, prompt_tokens, completion_tokens,
total_tokens, latency_ms, cost, conversation_id,
request_preview, response_preview)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s)""",
(endpoint, model, prompt_tokens, completion_tokens,
total_tokens, latency_ms, round(cost, 6), conversation_id,
(request_preview or "")[:200],
(response_preview or "")[:200])
)
conn.commit()
finally:
conn.close()
def extract_metadata(response):
"""从 LangChain 响应中提取 Token 使用数据"""
metadata = {"prompt_tokens": 0, "completion_tokens": 0,
"total_tokens": 0, "model_name": ""}
if hasattr(response, "response_metadata"):
rm = response.response_metadata
if isinstance(rm, dict):
token_usage = rm.get("token_usage", {})
metadata["prompt_tokens"] = token_usage.get("prompt_tokens", 0)
metadata["completion_tokens"] = token_usage.get("completion_tokens", 0)
metadata["total_tokens"] = token_usage.get("total_tokens", 0)
metadata["model_name"] = rm.get("model_name", "")
return metadata
def estimate_tokens(text):
"""估算 Token 数 (中文约 1.5 token/字, 英文约 0.25/字符)"""
if not text:
return 0
chinese = sum(1 for c in text if '\u4e00' <= c <= '\u9fff')
return int(chinese * 1.5 + (len(text) - chinese) * 0.25)
核心设计要点:
extract_metadata()— 从 LangChain 的ChatOpenAI响应对象中提取精确的 Token 用量estimate_tokens()— 对于流式调用(DashScope 不返回 Token 统计),用字符估算替代calculate_cost()— 基于模型定价自动计算每次调用费用
2.3 在 LLM 调用点注入追踪
流式调用(估算 Token):
# 流式调用 — DashScope 不返回 Token 统计,使用估算
start_time = time.time()
full_reply = ""
for chunk in llm.stream(history):
if chunk.content:
full_reply += chunk.content
yield f"data: {json.dumps({'token': chunk.content})}\n\n"
# 流结束后记录
latency = int((time.time() - start_time) * 1000)
p_est = estimate_tokens(user_message)
c_est = estimate_tokens(full_reply)
log_usage(
endpoint="/api/chat/stream",
model="qwen-plus",
prompt_tokens=p_est,
completion_tokens=c_est,
total_tokens=p_est + c_est,
latency_ms=latency,
request_preview=user_message,
response_preview=full_reply[:200],
)
关键陷阱: 在流式端点中,如果不同路径(RAG、MCP、普通对话)共用 log_usage,务必确保引用的变量在所有路径中都存在。例如 history 只在普通对话路径定义,RAG/MCP 路径应使用 user_message 进行 Token 估算。
2.4 监控 API 端点
提供三个聚合查询接口,供前端面板调用:
# ==================== 监控 API ====================
@app.route("/api/monitoring/summary", methods=["GET"])
def monitoring_summary():
"""获取使用数据汇总"""
days = int(request.args.get("days", 30))
import pymysql
conn = pymysql.connect(**_DB_CONFIG)
try:
cursor = conn.cursor(pymysql.cursors.DictCursor)
# 总体统计
cursor.execute(
"""SELECT
COUNT(*) as total_requests,
COALESCE(SUM(prompt_tokens), 0) as prompt_tokens,
COALESCE(SUM(completion_tokens), 0) as completion_tokens,
COALESCE(SUM(total_tokens), 0) as total_tokens,
COALESCE(SUM(cost), 0) as total_cost,
COALESCE(AVG(latency_ms), 0) as avg_latency,
COALESCE(MAX(latency_ms), 0) as max_latency,
COALESCE(MIN(latency_ms), 0) as min_latency
FROM ai_usage_logs
WHERE created_at >= DATE_SUB(NOW(), INTERVAL %s DAY)""",
(days,),
)
overall = cursor.fetchone()
# P95 延迟
cursor.execute(
"""SELECT COALESCE(latency_ms, 0) as latency
FROM ai_usage_logs
WHERE created_at >= DATE_SUB(NOW(), INTERVAL %s DAY)
AND latency_ms IS NOT NULL
ORDER BY latency ASC""",
(days,),
)
latency_rows = cursor.fetchall()
p95_latency = 0
if latency_rows:
idx = int(len(latency_rows) * 0.95)
p95_latency = latency_rows[min(idx, len(latency_rows) - 1)]["latency"]
# 成功率 (有 response_preview 的视为成功)
cursor.execute(
"""SELECT
COUNT(*) as total,
SUM(CASE WHEN response_preview IS NOT NULL AND response_preview != '' THEN 1 ELSE 0 END) as success
FROM ai_usage_logs
WHERE created_at >= DATE_SUB(NOW(), INTERVAL %s DAY)""",
(days,),
)
sr = cursor.fetchone()
success_rate = round((int(sr["success"]) / int(sr["total"])) * 100, 1) if int(sr["total"]) > 0 else 100.0
# 按模型分组
cursor.execute(
"""SELECT
model,
COUNT(*) as requests,
COALESCE(SUM(prompt_tokens), 0) as prompt_tokens,
COALESCE(SUM(completion_tokens), 0) as completion_tokens,
COALESCE(SUM(total_tokens), 0) as tokens,
COALESCE(SUM(cost), 0) as cost
FROM ai_usage_logs
WHERE created_at >= DATE_SUB(NOW(), INTERVAL %s DAY)
GROUP BY model""",
(days,),
)
model_rows = cursor.fetchall()
models = {}
for row in model_rows:
models[row["model"]] = {
"tokens": row["tokens"],
"promptTokens": row["prompt_tokens"],
"completionTokens": row["completion_tokens"],
"requests": row["requests"],
"cost": round(float(row["cost"]), 4),
}
# 按端点分组
cursor.execute(
"""SELECT
endpoint,
COUNT(*) as requests,
COALESCE(SUM(total_tokens), 0) as tokens,
COALESCE(SUM(cost), 0) as cost
FROM ai_usage_logs
WHERE created_at >= DATE_SUB(NOW(), INTERVAL %s DAY)
GROUP BY endpoint""",
(days,),
)
ep_rows = cursor.fetchall()
endpoints = {}
for row in ep_rows:
endpoints[row["endpoint"]] = {
"tokens": row["tokens"],
"requests": row["requests"],
"cost": round(float(row["cost"]), 4),
}
# 今日统计
cursor.execute(
"""SELECT
COALESCE(SUM(total_tokens), 0) as tokens,
COUNT(*) as requests,
COALESCE(SUM(cost), 0) as cost
FROM ai_usage_logs
WHERE created_at >= CURDATE()"""
)
today = cursor.fetchone()
# 昨日统计
cursor.execute(
"""SELECT
COALESCE(SUM(total_tokens), 0) as tokens
FROM ai_usage_logs
WHERE created_at >= DATE_SUB(CURDATE(), INTERVAL 1 DAY)
AND created_at < CURDATE()"""
)
yesterday = cursor.fetchone()
yd_tokens = yesterday["tokens"]
td_tokens = int(today["tokens"])
yd_tokens = int(yesterday["tokens"])
tokens_change = round(((td_tokens - yd_tokens) / yd_tokens) * 100, 1) if yd_tokens > 0 else (100.0 if td_tokens > 0 else 0.0)
# 最后请求时间
cursor.execute("SELECT MAX(created_at) as last_at FROM ai_usage_logs")
last_row = cursor.fetchone()
last_request_at = str(last_row["last_at"]) if last_row["last_at"] else None
# 本月费用
cursor.execute(
"""SELECT COALESCE(SUM(cost), 0) as cost
FROM ai_usage_logs
WHERE created_at >= DATE_FORMAT(NOW(), '%%Y-%%m-01')"""
)
month_cost = float(cursor.fetchone()["cost"])
return jsonify({
"code": 200,
"data": {
"totalTokens": overall["total_tokens"],
"promptTokens": overall["prompt_tokens"],
"completionTokens": overall["completion_tokens"],
"totalCost": round(float(overall["total_cost"]), 4),
"totalRequests": overall["total_requests"],
"avgLatencyMs": int(overall["avg_latency"]),
"maxLatencyMs": int(overall["max_latency"]),
"minLatencyMs": int(overall["min_latency"]),
"p95LatencyMs": int(p95_latency),
"successRate": success_rate,
"todayTokens": td_tokens,
"todayRequests": today["requests"],
"todayCost": round(float(today["cost"]), 4),
"yesterdayTokens": yd_tokens,
"tokensChangeRate": tokens_change,
"lastRequestAt": last_request_at,
"monthCost": round(month_cost, 4),
"models": models,
"endpoints": endpoints,
},
})
except Exception as e:
return jsonify({"code": 500, "msg": str(e)})
finally:
conn.close()
@app.route("/api/monitoring/daily", methods=["GET"])
def monitoring_daily():
"""获取每日使用趋势"""
days = int(request.args.get("days", 7))
import pymysql
conn = pymysql.connect(**_DB_CONFIG)
try:
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(
"""SELECT
DATE(created_at) as date,
COALESCE(SUM(total_tokens), 0) as tokens,
COUNT(*) as requests,
COALESCE(SUM(cost), 0) as cost
FROM ai_usage_logs
WHERE created_at >= DATE_SUB(NOW(), INTERVAL %s DAY)
GROUP BY DATE(created_at)
ORDER BY date ASC""",
(days,),
)
rows = cursor.fetchall()
data = []
for row in rows:
data.append({
"date": str(row["date"]),
"tokens": row["tokens"],
"requests": row["requests"],
"cost": round(float(row["cost"]), 4),
})
return jsonify({"code": 200, "data": data})
except Exception as e:
return jsonify({"code": 500, "msg": str(e)})
finally:
conn.close()
@app.route("/api/monitoring/recent", methods=["GET"])
def monitoring_recent():
"""获取最近的 AI 调用记录"""
limit = int(request.args.get("limit", 20))
import pymysql
conn = pymysql.connect(**_DB_CONFIG)
try:
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(
"""SELECT
id, endpoint, model, conversation_id,
prompt_tokens, completion_tokens, total_tokens,
latency_ms, cost, request_preview, response_preview,
created_at
FROM ai_usage_logs
ORDER BY created_at DESC
LIMIT %s""",
(limit,),
)
rows = cursor.fetchall()
data = []
for row in rows:
has_response = row["response_preview"] is not None and row["response_preview"] != ""
data.append({
"id": row["id"],
"endpoint": row["endpoint"],
"model": row["model"],
"conversationId": row["conversation_id"],
"promptTokens": row["prompt_tokens"],
"completionTokens": row["completion_tokens"],
"totalTokens": row["total_tokens"],
"latencyMs": row["latency_ms"],
"cost": round(float(row["cost"]), 4),
"requestPreview": row["request_preview"],
"responsePreview": row["response_preview"][:200] if row["response_preview"] else None,
"status": "success" if has_response else "failed",
"createdAt": str(row["created_at"]),
})
return jsonify({"code": 200, "data": data})
except Exception as e:
return jsonify({"code": 500, "msg": str(e)})
finally:
conn.close()三、前端实现
3.1 API 服务层
// monitoringService.js
/**
* Monitoring API Service
* AI 使用数据监控
*/
const BASE_URL = process.env.REACT_APP_CHAT_API_URL || 'http://localhost:5000';
export class MonitoringService {
async getSummary(days = 30) {
const res = await fetch(`${BASE_URL}/api/monitoring/summary?days=${days}`);
const data = await res.json();
if (data.code === 200) return data.data;
throw new Error(data.msg || '获取监控汇总失败');
}
async getDailyUsage(days = 7) {
const res = await fetch(`${BASE_URL}/api/monitoring/daily?days=${days}`);
const data = await res.json();
if (data.code === 200) return data.data;
throw new Error(data.msg || '获取每日趋势失败');
}
async getRecentRequests(limit = 20) {
const res = await fetch(`${BASE_URL}/api/monitoring/recent?limit=${limit}`);
const data = await res.json();
if (data.code === 200) return data.data;
throw new Error(data.msg || '获取最近记录失败');
}
}
export const monitoringService = new MonitoringService();
3.2 监控面板组件
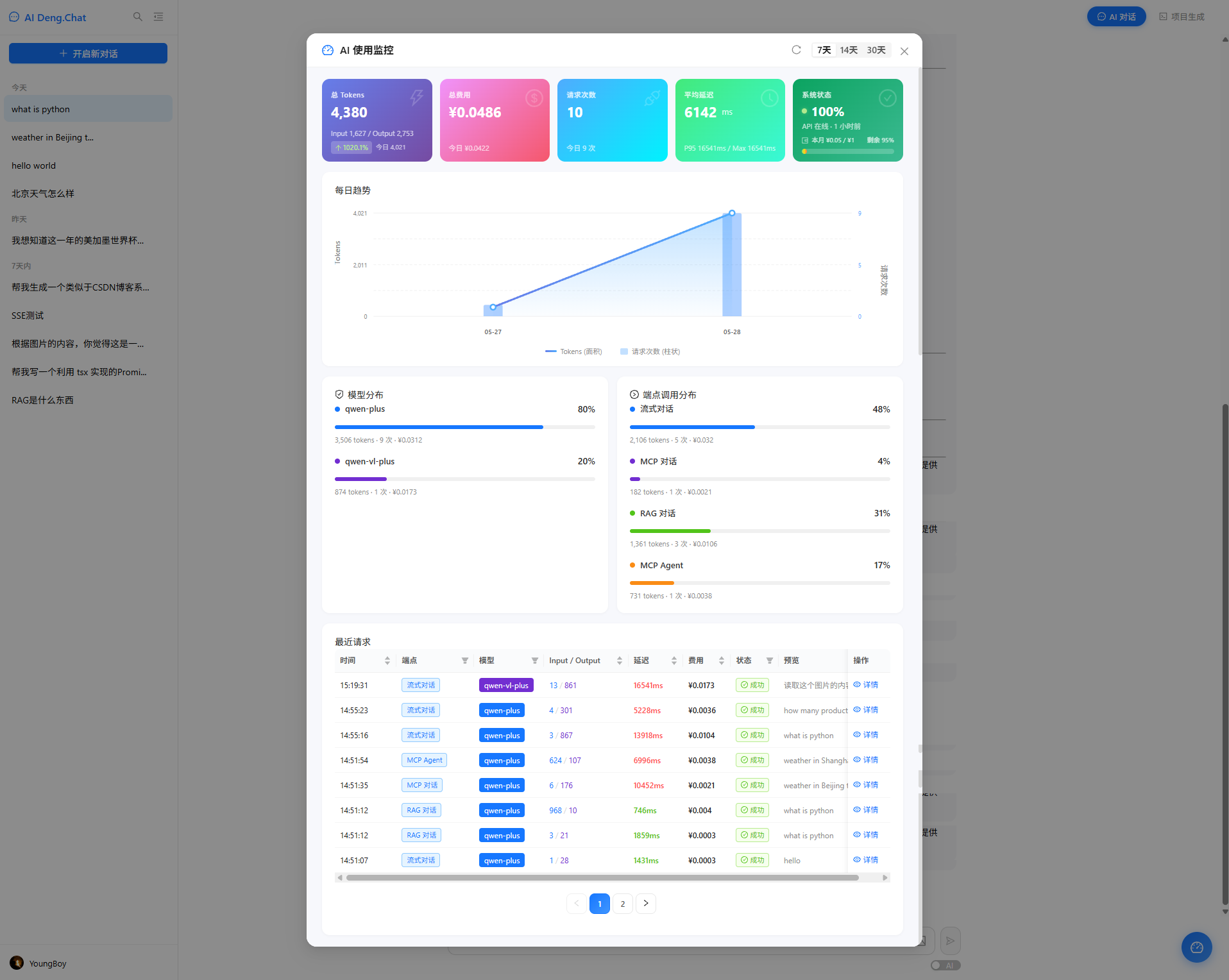
面板使用 antd Modal 弹窗 (960px 宽),包含以下区域:
1) 五个统计卡片
<Row gutter={[12, 12]} align="stretch">
{/* 总 Tokens / 总费用 / 请求次数 / 平均延迟 / 系统状态 */}
{statCards.map(card => (
<Col flex="1" key={card.key}>
<div className={styles.statCard} style={{ background: card.gradient }}>
<div className={styles.statLabel}>{card.title}</div>
<div className={styles.statValue}>{card.value}</div>
<div className={styles.statSub}>{card.sub}</div>
</div>
</Col>
))}
</Row>
每个卡片使用渐变背景色 + 环比变化率标签 + 今日子数据,系统状态卡片额外展示成功率、API 在线状态、月预算进度条。
2) SVG 双轴趋势图
使用纯 SVG 绘制面积图 + 柱状图组合:
- 左 Y 轴 = Tokens(平滑曲线 + 面积填充)
- 右 Y 轴 = 请求次数(半透明柱状图)
- Catmull-Rom 曲线平滑算法,hover 显示详情
function DualChart({ data }) {
// 平滑曲线路径 (Catmull-Rom → Cubic Bezier)
function smoothPath(points) {
let d = `M${points[0].x},${points[0].y}`;
for (let i = 0; i < points.length - 1; i++) {
const tension = 0.3;
// 计算 Catmull-Rom 控制点...
d += ` C${cp1x},${cp1y} ${cp2x},${cp2y} ${p2.x},${p2.y}`;
}
return d;
}
// SVG: 网格线 + 柱状图 + 面积 + 曲线 + 数据点
}
3) 模型分布 + 端点分布
左右并排展示,使用 antd Progress 进度条 + 百分比,直观显示各模型和端点的使用占比。
4) 最近请求表格
<Table
dataSource={recentRequests}
columns={[
{ title: '时间', sorter: true },
{ title: '端点', filters: [...] }, // 可筛选
{ title: '模型', filters: [...] },
{ title: 'Input/Output' },
{ title: '延迟', sorter: true, render: colorByLatency },
{ title: '状态', render: successOrFailedTag },
{ title: '操作', render: detailPopover },
]}
pagination={{ pageSize: 8 }}
/>
支持按端点、模型筛选,按时间、Token、延迟排序,点击「详情」查看完整请求/响应内容。
3.3 浮动按钮入口
在聊天页面右下角添加浮动按钮,点击打开监控弹窗:
<div className={styles.monitoringFab} onClick={() => setMonitoringOpen(true)}>
<DashboardOutlined />
</div>
<MonitoringPanel open={monitoringOpen} onClose={() => setMonitoringOpen(false)} />
</div>.monitoringFab {
position: fixed;
bottom: 28px;
right: 28px;
width: 48px;
height: 48px;
border-radius: 50%;
background: linear-gradient(135deg, #1677ff, #4096ff);
color: #fff;
display: flex;
align-items: center;
justify-content: center;
font-size: 20px;
cursor: pointer;
box-shadow: 0 4px 16px rgba(22, 119, 255, 0.4);
z-index: 100;
transition: all 0.25s ease;
user-select: none;
&:hover {
transform: scale(1.1);
box-shadow: 0 6px 24px rgba(22, 119, 255, 0.5);
}
&:active {
transform: scale(0.95);
}
}五、最终效果
监控面板展示以下数据:
| 区域 | 内容 |
|---|---|
| 统计卡片 | 总 Tokens (含环比) / 总费用 / 请求次数 / 平均延迟 / 系统状态 + 预算进度 |
| 趋势图 | 每日 Token 使用趋势 (面积图) + 请求次数 (柱状图),双 Y 轴 |
| 分布 | 按模型分布 + 按端点分布的进度条 |
| 请求列表 | 可筛选/排序的最近请求,含状态、详情弹窗 |
总结
本文实现了一套轻量但完整的 AI 使用监控系统,核心思路是:
- 拦截 LLM 响应 — 从
response_metadata提取精确数据,流式调用用估算 - 结构化存储 — 每次调用记录端点、模型、Token、延迟、费用到 MySQL
- 聚合 API — 提供多维度统计查询,支持时间范围、模型/端点分组、环比计算
- 可视化面板 - 渐变卡片 + SVG 图表 + 可操作表格,集成在聊天界面中
整个过程不需要 LangSmith 平台账号,纯自建实现。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)