NLP —— Transformer 底层源码剖析(输入部分)
上一篇讲述了 Transformer 整体结构框架 及 演变由来
https://blog.csdn.net/i_k_o_x_s/article/details/161060029?spm=1001.2014.3001.5501
本篇是对 底层源码的代码实现。
目录
一、Input Embedding 词嵌入层
作用:把输入的词转成词向量
例如:‘你好’ -> [0.1, 0.3 , -0.222 ...]
注意:前向传播 返回值 为什么要 * 根号 d_model。
目的是为了放大词向量的数值,抵消注意力机制的缩小,让模型训练更稳定、更容易收敛。
# 1 - 词嵌入层
class Embedding(nn.Module):
def __init__(self, vocab_size, d_model):
super().__init__()
"""
词汇表大小
词向量维度
词嵌入层网络
"""
self.vocab_size = vocab_size
self.d_model = d_model
self.ebd = nn.Embedding(num_embeddings=self.vocab_size, embedding_dim=self.d_model)
def forward(self, input:Tensor):
input_emb = self.ebd(input)
"""
为什么要 * 根号 d_model
给词嵌入向量放大数值,抵消注意力机制的缩小,让模型训练更稳定、更容易收敛!
"""
return input_emb * math.sqrt(self.d_model)测试词嵌入层: 假定给一个 2个句子,每个句子3个词,词汇表大小100,词向量512
def test_embedding():
my_embedding = Embedding(vocab_size=100, d_model=512)
# 给个 2个句子,每个句子3个词,vocab_size = 100. 词汇表大小100
# 注意:目前情况下,词索引的取值区间[0,99]
x = torch.tensor([
[10, 50, 66],
[88, 20, 9]
], dtype=torch.long)
word_vector = my_embedding(x)
print(f"词向量的形状{word_vector.shape}") # 2条句子,3句子中3个词,512词向量维度
print(f"词向量的数据{word_vector.abs().min()}") # 获得乘以根号dk以后数据中绝对值的最小值
print(f"词向量的数据{word_vector.abs().max()}") # 获得乘以根号dk以后数据中绝对值的最大值
if __name__ == '__main__':
test_embedding()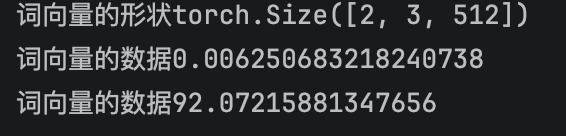
二、Positional Encoding:位置编码
1.作用
给词向量加 ‘位置信息’,Transformer本身不明白词的顺序。用来解决一次多义的情况
2.编码器端实现方式
三角函数来实现的 sin、cos函数
1.保证同一次随着所在位置不同它对应位置嵌入向量会发生变化
2.sin和cos的值在(-1,1)很好的控制了嵌入数值的大小,有助于梯度的快速计算。
例如:小龙女 过过 过过 过过 的生活,三个过过 语义不一样。
3.原理解析
位置编码公式
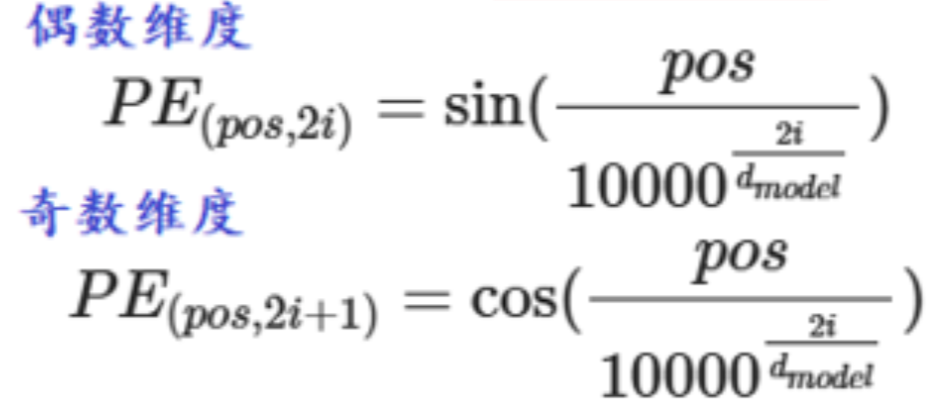
pos: 词在句子中的位置
i :维度的索引
d_model:词向量的维度
举例:pos=2 第2个词,词向量维度 d_model=4, 计算位置编码向量
因为公式中 2i 和 2i+1 必须小于等于维度。 2i <= 4 和 2i + 1<= 4
所以 这里 i:0和1 计算2步,每步计算奇偶数维度 得到2个值。
最后全部算完 2 * 2步 = 4个值,拼起来就是下图 【0.909, -0.416, 0.020, 0.998】

三角函数的一个优点,因为对人员的PE(pos+k),都可以表示为PE(pos)的线性函数,大大方便计算,而且周期性函数不受序列长度的限制,也可以增强模型的泛化能力。
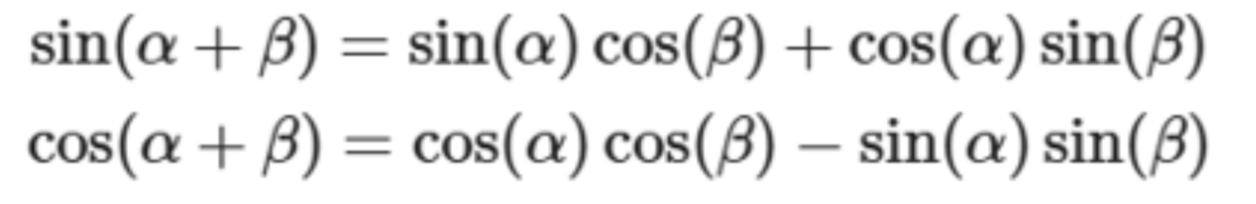
比如 pos(5)= pos(2+3) => sin(2) * cos(3) + cos(2) * sin(3)
pos(6)= pos(3+3) => sin(3) * cos(3) + cos(3) * sin(3)
......
因为在计算过程中 比如这里 sin(2). cos(3) sin(3) cos(2) 都算过了,如果后续要再用到这些值,已经算过的直接带入值,不需要再计算。所以会计算越来越快
4.结论
每个词计算得到的位置编码向量 + 词的向量,得到独特让同一个词 如 '过过' ,
第一个‘过过’位置是1
第二个‘过过’位置是2
他们的pos 不同,计算出来的 位置编码向量不同,解决了一词多义问题。
位置编码的好处:
1.记住词的顺序 (每个位置独立的标签)
2.计算高效 (不用重复计算三角函数)
3.适应任意长度 (不管句子多长,随时能算编码,泛化能力强)
4.模型处理语言时,更聪明,更灵活。
5.代码实现
pe 初始化全0 所有位置编码的向量
步骤 2.3 到 2.6 运用了 向量化计算,比for循环 速度快10-100倍。
pos 一次性拿到所有词的位置
div_term 一次性算出所有位置、所有偶数维度的值 i,得到所有 1/分母
value 向量化计算 value = pos * div_term
位置编码类
# 2 - 位置编码
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout_p, max_len):
super().__init__()
# 2.1 设置属性值
self.d_model = d_model
self.max_len = max_len
self.dropout_p = dropout_p
# 【可选】Droout 随机失活层
self.dropout = nn.Dropout(p=dropout_p)
# 2.2 定义位置编码的计算规则
# 初始化位置编码计算结果pe:初始形状[max_len, d_model],max_len句子长度规范的上限,d_model是词向量维度
pe = torch.zeros(size=(self.max_len, self.d_model))
# 2.3 得到词的pos取值范围
"""
一次性拿到所有词的位置!
arange:产生的结果是一维的张量,start是开始,end是结束,step是步长,生成值的区间范围是[start,end)
unsqueeze(dim=-1):升维操作。就是将张量形状由 [max_len] 升维到 [max_len, 1]
"""
pos = torch.arange(start=0, end=self.max_len, step=1).unsqueeze(dim=-1)
# 2.4 得到 1/分母
"""
一次性算出所有位置、所有偶数维度的值!
torch.arange(start=0,end=self.d_model,step=2)用来生成 2i
"""
div_term = 1/(10000 **(torch.arange(start=0, end=self.d_model, step=2)/self.d_model))
# 2.5 得到正弦、余弦计算公式里面的内容
"""
相当于
for pos in 所有位置:
for i in 所有偶数维度:
value = pos * div_term
"""
value = pos * div_term
# 2.6 - 得到位置编码信息
"""
一次性算完所有位置、所有维度!
向量化计算,比 for 循环快 10~100 倍。
pe[:, 0::2] → 所有行、从 0 开始、步长 2 → 对应 2i 偶数维度
pe[:, 1::2] → 所有行、从 1 开始、步长 2 → 对应 2i+1 奇数维度
这一步直接把 sin /cos 填进对应维度!
"""
pe[:, 0::2] = torch.sin(value) # 偶数
pe[:, 1::2] = torch.cos(value) # 奇数
# 2.7 将pe 2维 -> 3维 [max_len, d_model] 变成 [1, max_len, d_model]
# 词向量是3维 要做加法运算,形状要相同
pe = pe.unsqueeze(dim=0)
# 2.8 - 将pe注册到缓冲中,通过不断地来更新计算得到每个词的位置编码,后续使用直接通过self.pe
"""
让 PE 跟随模型移动到 GPU,但不参与训练
"""
self.register_buffer('pe', pe)
def forward(self, embed:Tensor):
# 1.获取句子词的个数
seq_len = embed.shape[1]
# 2.位置编码和词向量 维度求和
"""
假设:pe的形状[1,10,256],embed的形状[1,6,256]。那么他们两个直接无法直接求和
self.pe[:, :seq_len, :]取前6个词的位置编码形状是[1,6,256]
result的形状是[1,6,256]
"""
result = embed + self.pe[:, :seq_len, :]
# 3.随机失活
return self.dropout(result)使用位置编码实例对象1
def use_positional_encoding():
d_model = 512
dropout_p = 0.1
my_embedding = Embedding(vocab_size=1000, d_model=d_model)
x = torch.tensor([
# 单词索引
[100, 2, 421, 600],
[500, 888, 421, 615]
])
word_embed = my_embedding(x)
print(f"词向量的形状:{word_embed.shape}")
print(f"词向量的值:{word_embed}")
print('=' * 100)
my_pe = PositionalEncoding(d_model=d_model,dropout_p=dropout_p,max_len=60)
# 最终的词向量 = (词向量 + 位置编码)
result = my_pe(word_embed)
print(f"最终的形状:{result.shape}")
print(f"最终的值:{result}")
return result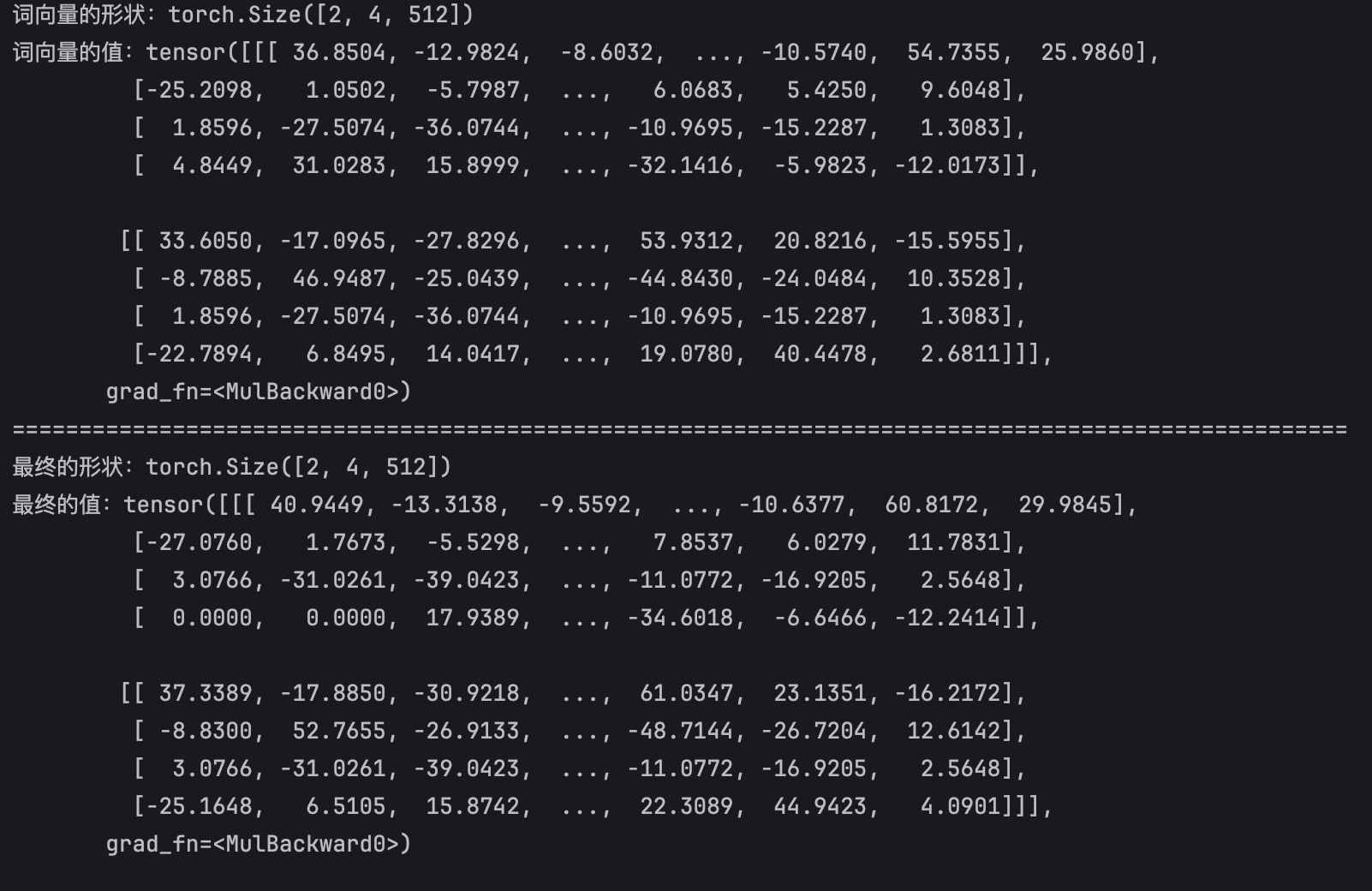
使用位置编码实例对象2 可视化位置编码
# 可视化位置编码
def plot_position():
# 1. 实例化位置编码器.
my_position = PositionalEncoding(d_model=20, dropout_p=0, max_len=100)
# 2. 生成全0的输入, 观察位置编码的模式.
# (1, 100, 20) -> 批次大小, 句子长度, 词嵌入维度
embed = torch.zeros(1, 100, 20)
y = my_position(embed)
# 3. 设置图表大小.
plt.figure(figsize=(20, 15))
# 绘制位置编码第4到第7列, 100个词的 [4, 5, 6, 7]
"""
图形的信息解释:
x轴:词的索引,目前总共有100个词
y轴:位置编码值 + 词向量
"""
plt.plot(np.arange(100), y[0, :, 4:8].detach().numpy())
plt.legend([f'dim {p}' for p in [4, 5, 6, 7]])
plt.show()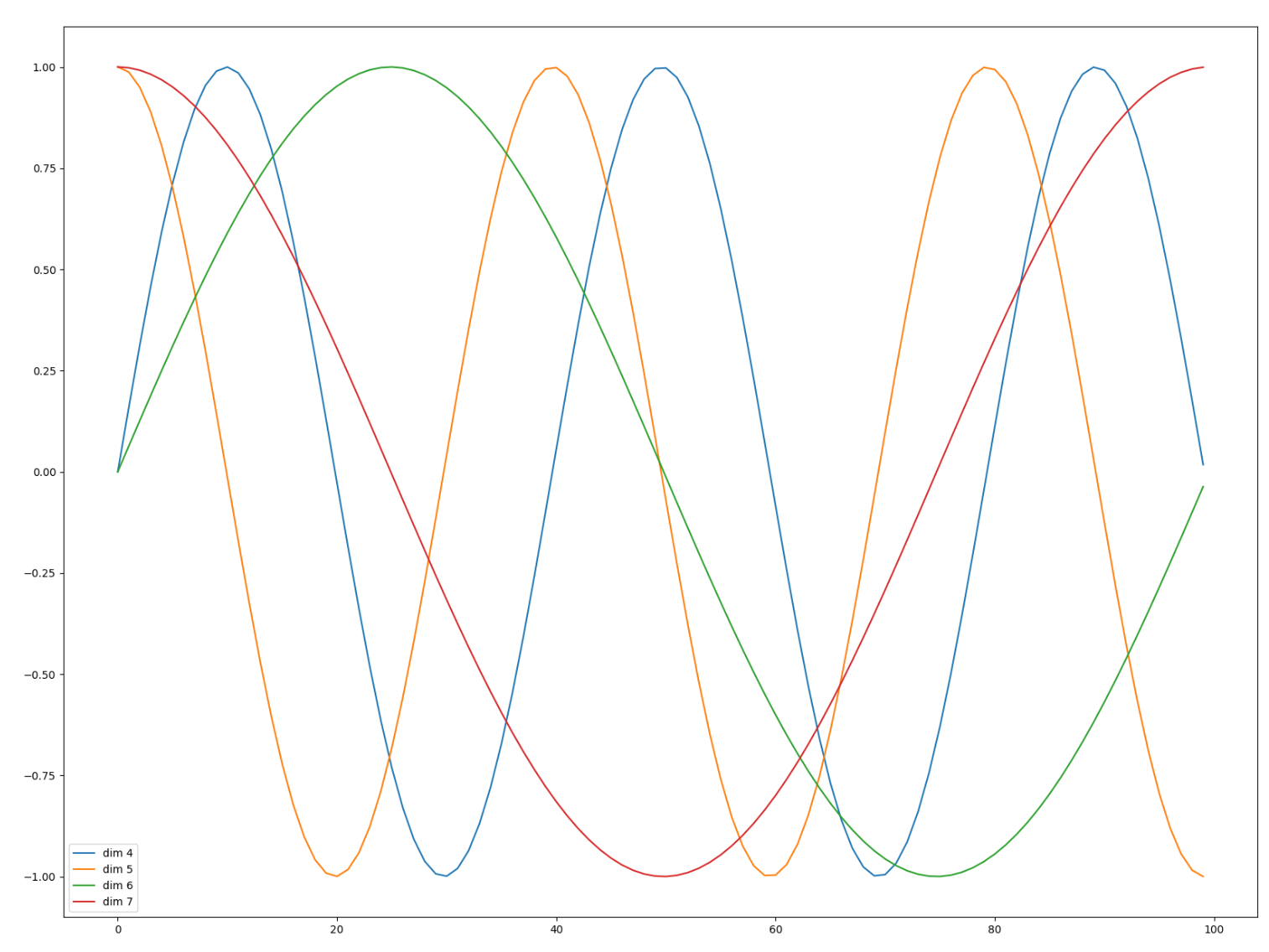
每个词 也就是pos 对应的 [pe[0],pe[1],......,pe[2i],pe[2i+1]] 位置编码值 都不同。
所以同一个词,不同位置踏马的 词向量 = 词向量 + 位置编码。最终不同,达到一次多义。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)