Diffusion Model 原理详解:AI 绘图到底是怎么从噪声中生成图像的?
引言
如果说 VAE 解决的是“如何把图像压缩到一个可生成的潜在空间”,CLIP 解决的是“如何让图像和文本对齐”,那么 Diffusion Model 解决的核心问题就是:
如何从一张随机噪声图,一步步生成一张有意义的图片?
这也是 Stable Diffusion、Imagen、DALL·E 这类 AI 绘图模型背后的关键思想。
扩散模型听起来很抽象,但它的基本逻辑并不复杂:
- 训练时,先把真实图片一步步加噪,直到它接近纯噪声。
- 模型学习如何从带噪图片中预测噪声,或者预测更干净的图像。
- 生成时,从随机噪声开始,反复去噪,最终得到清晰图像。
所以扩散模型不是“凭空画图”,而是在学习一个反向过程:
纯噪声 -> 粗糙结构 -> 局部细节 -> 清晰图像
理解 Diffusion Model,关键不是先记公式,而是先搞清楚三件事:
- 为什么要给图像加噪?
- 模型在去噪时到底学了什么?
- 文本条件是怎么控制生成结果的?
一、生成模型到底在解决什么问题?
生成模型的目标很直接:
学会真实数据的分布,然后从这个分布中采样出新的样本。
对于图像来说,就是希望模型能生成一张“像真实图片”的新图。
传统上,常见生成模型包括:
- VAE
- GAN
- Diffusion Model
它们都在解决“如何生成图像”这个问题,但思路完全不同。
GAN 的想法更像是:
生成器负责造图,判别器负责判断真假
VAE 的想法更像是:
先把图像压缩到潜在空间,再从潜在变量重建图像
Diffusion Model 的想法则是:
先学会破坏图像,再学会把破坏过程反过来
这也是扩散模型最有意思的地方。
它不是直接学习“如何从无到有画一张图”,而是把生成问题拆成很多个小步骤:
每一步只负责去掉一点噪声
当很多个小的去噪步骤串起来,就能从随机噪声慢慢恢复出图像。
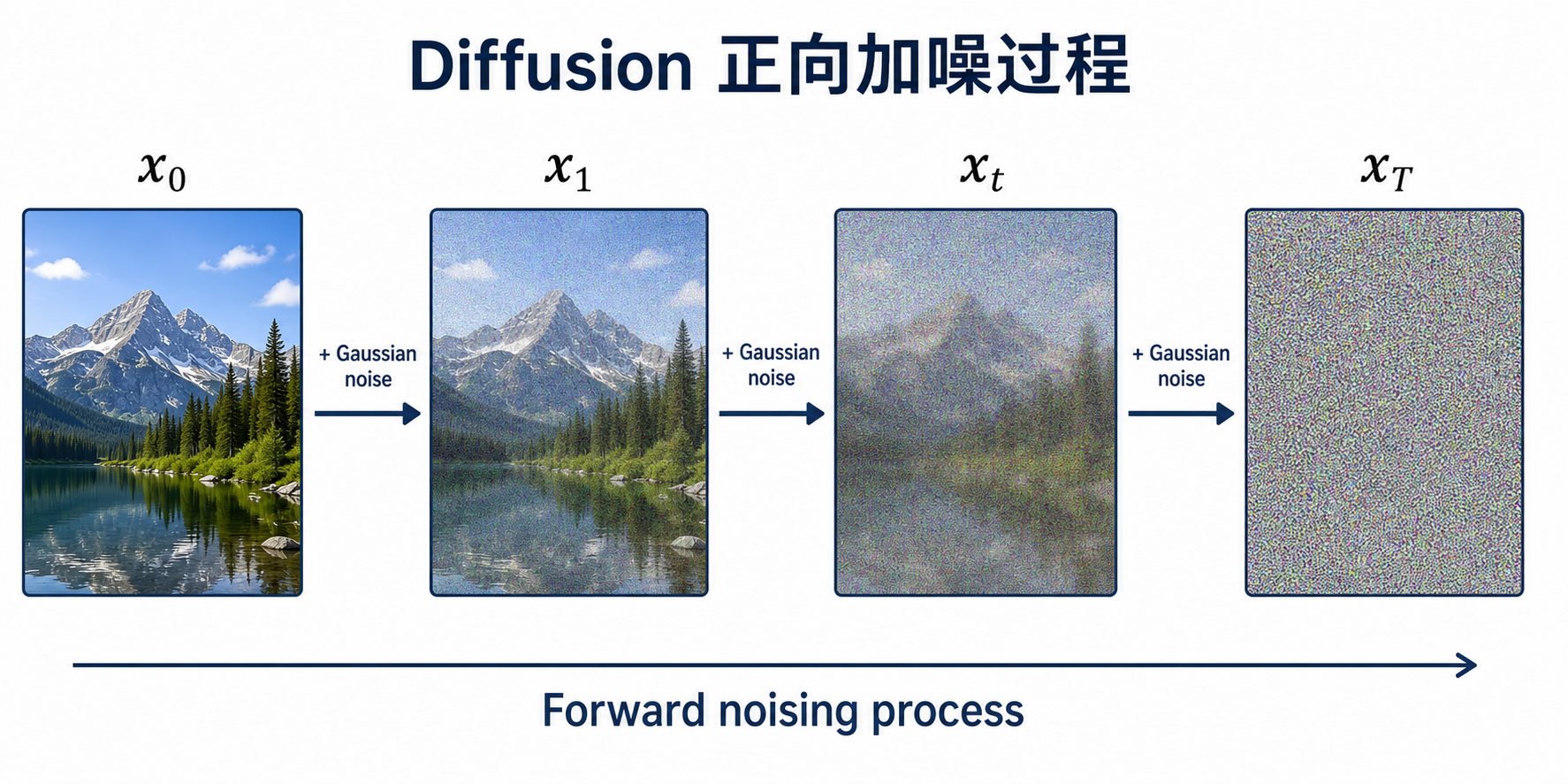
二、正向扩散过程:一步步给图像加噪
Diffusion Model 的训练从一个很反直觉的动作开始:
不断给真实图像加噪。
假设原始图像是 x_0。
我们会按照一个预先设计好的噪声强度序列,逐步往图像里加入高斯噪声:
x_0 -> x_1 -> x_2 -> ... -> x_T
其中:
x_0是真实图像x_1是轻微加噪后的图像x_t是第t步的带噪图像x_T接近纯随机噪声
可以直观理解成:
清晰图片 -> 有一点噪声 -> 更模糊 -> 几乎看不出内容 -> 纯噪声
2.1 为什么要做正向加噪?
正向加噪过程有两个作用。
第一,它把复杂的图像生成问题变成了一个可以监督学习的问题。
因为噪声是我们自己加进去的,所以训练时模型知道:
- 原始图像是什么
- 加了多少噪声
- 加进去的噪声长什么样
这就给模型提供了明确的学习目标。
第二,正向过程定义了反向生成过程要学习的路径。
如果模型能学会:
x_t -> x_{t-1}
那么它就可以从纯噪声 x_T 开始,一步步反推回清晰图像 x_0。
2.2 噪声不是一次加完的
扩散模型不是一次性把图片变成噪声,而是分很多步逐渐加噪。
这样做的好处是:
- 每一步变化都比较小
- 反向去噪任务更容易学习
- 生成过程可以逐步修正图像结构和细节
如果一次性从纯噪声生成清晰图像,任务会非常难。
但如果每一步只去掉一点噪声,模型就可以把复杂生成任务拆成很多个简单任务。
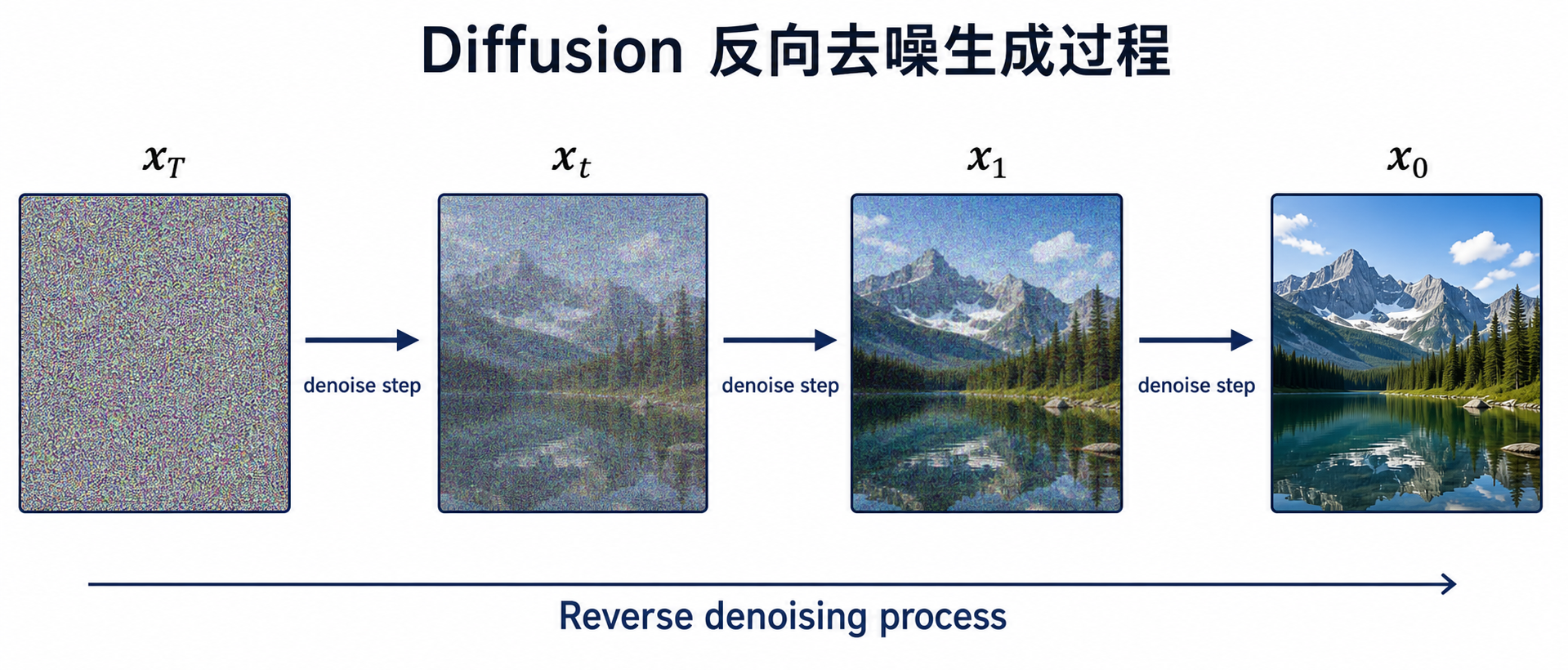
三、反向去噪过程:模型到底在学习什么?
正向过程是人为设计的加噪过程。
真正需要模型学习的是反向过程:
x_T -> x_{T-1} -> ... -> x_1 -> x_0
也就是从噪声中一步步恢复图像。
3.1 模型不是直接预测整张图
很多人第一次理解扩散模型时,会以为模型是在每一步直接预测一张干净图。
更常见的训练方式其实是:
给模型一张带噪图
x_t和时间步t,让模型预测这一步加入的噪声。
也就是说,模型学习的是:
输入:带噪图像 x_t + 时间步 t
输出:噪声 epsilon
然后用预测出来的噪声,把当前图像往更干净的方向推一步。
这件事可以理解成:
模型先判断这张图里哪些部分是噪声,再把这些噪声去掉一点
3.2 为什么要输入时间步 t?
不同时间步的图像噪声强度不同。
早期时间步可能只有轻微噪声,图像结构还很清楚。
后期时间步接近纯噪声,图像内容几乎不可见。
所以模型必须知道当前处在哪一个时间步。
否则它无法判断:
- 现在噪声有多强
- 应该去掉多少噪声
- 当前图像还保留了多少结构信息
这就是为什么扩散模型通常会把 timestep embedding 输入到 U-Net 里。
3.3 训练目标可以怎么理解?
训练时,我们从真实图像 x_0 出发,随机选择一个时间步 t,加入噪声得到 x_t。
然后让模型预测噪声:
epsilon_theta(x_t, t) ≈ epsilon
其中:
epsilon是真实加入的噪声epsilon_theta是模型预测的噪声
训练目标就是让预测噪声尽量接近真实噪声。
可以用一句话记:
扩散模型训练时学的是“如何识别并去掉噪声”。
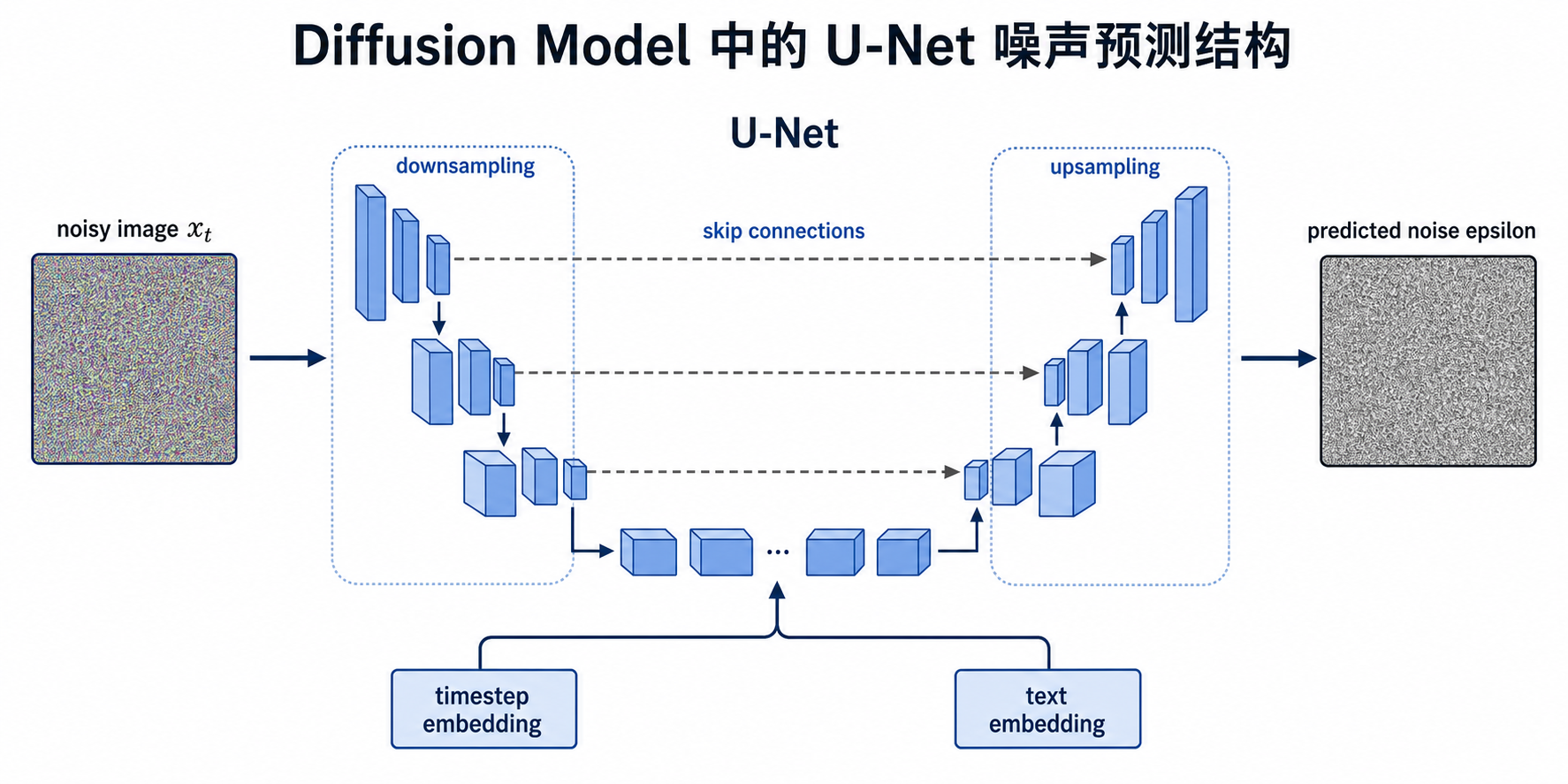
四、U-Net 在扩散模型中的作用
在很多扩散模型中,负责预测噪声的主干网络是 U-Net。
U-Net 最早常用于医学图像分割,它的结构特点非常适合图像到图像任务。
扩散模型里的 U-Net 可以理解成:
输入一张带噪图,输出对应的噪声预测。
4.1 为什么常用 U-Net?
因为去噪任务既需要全局语义,也需要局部细节。
如果只看局部,模型可能不知道整体结构应该是什么。
如果只看全局,模型又可能丢失边缘、纹理、细节。
U-Net 刚好兼顾这两点。
它通常包含:
- 下采样路径:压缩空间分辨率,提取高层语义
- 中间层:整合全局信息
- 上采样路径:恢复空间分辨率,生成细节
- Skip Connection:把浅层细节直接传到后面的上采样阶段
4.2 Skip Connection 为什么重要?
去噪不是只生成一个类别,而是要恢复图像的空间结构。
浅层特征里保留了很多细节信息,例如边缘、纹理和局部位置。
如果这些信息在下采样过程中完全丢失,生成结果会更模糊。
Skip Connection 的作用就是:
把浅层细节特征直接传给上采样路径
这样模型既能利用深层语义,也能保留浅层细节。
4.3 U-Net 输入的通常不只有图像
扩散模型里的 U-Net 通常会接收多个输入:
- 当前带噪图像
x_t - 时间步
t - 条件信息,例如文本 embedding
所以它不是一个普通的图像恢复网络,而是一个带条件的噪声预测网络。
五、文本条件如何控制生成结果?
普通扩散模型只能从噪声生成图像。
但 AI 绘图真正有用的地方在于:
输入一句 prompt -> 生成符合描述的图像
这就需要把文本条件加入去噪过程。
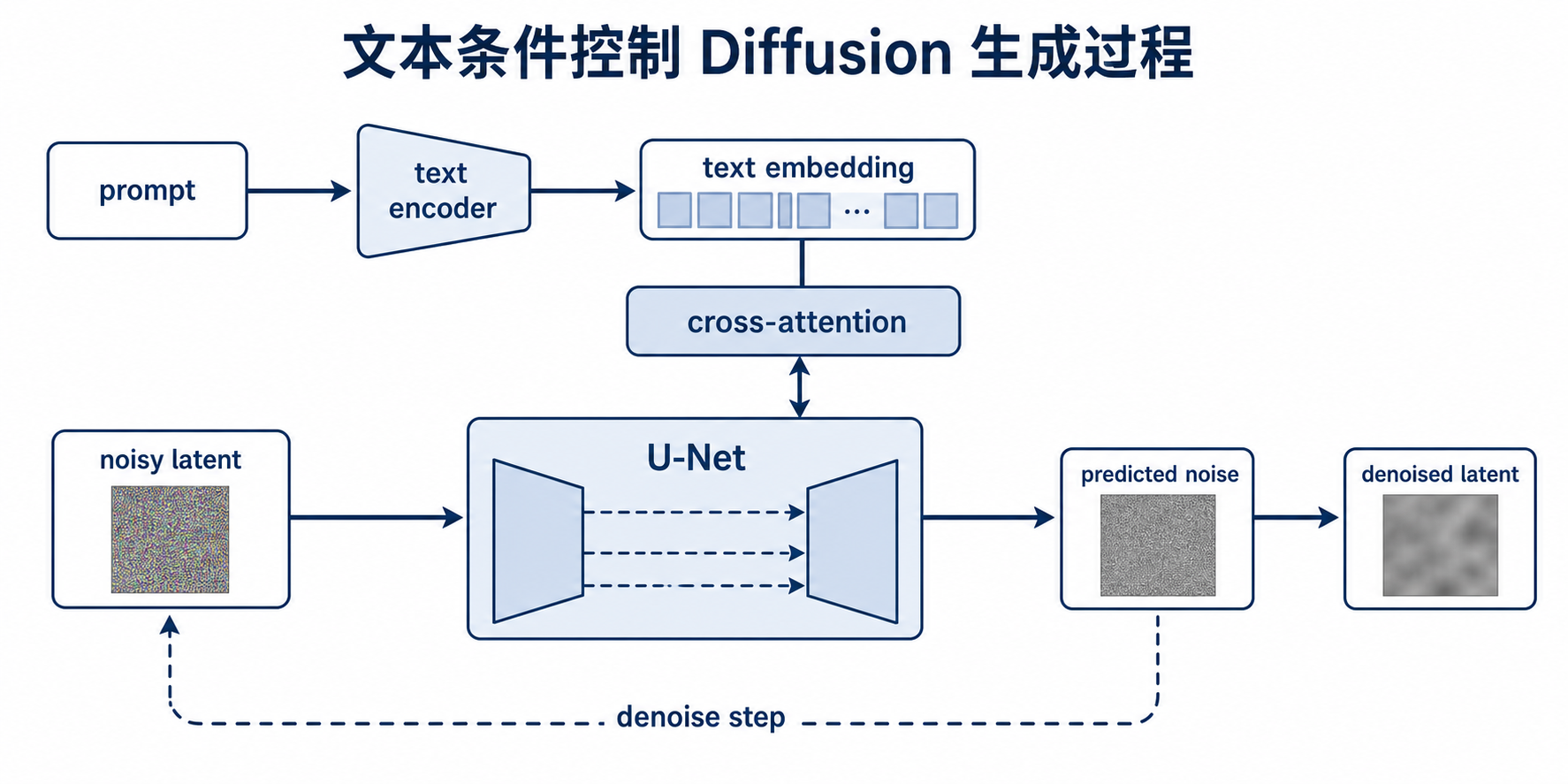
5.1 文本先被编码成 embedding
文本不能直接控制图像生成,通常需要先经过文本编码器。
例如在 Stable Diffusion 中,文本 prompt 会先经过 CLIP Text Encoder,得到文本 embedding。
流程可以简化为:
prompt -> text encoder -> text embedding
这些 embedding 表示了文本中的语义信息,例如:
- 对象
- 风格
- 场景
- 属性
- 构图
5.2 文本条件进入 U-Net
文本 embedding 会被送入 U-Net,影响每一步去噪。
常见做法是通过 cross-attention:
图像 latent 特征作为 Query
文本 embedding 作为 Key / Value
这样图像生成过程中的每个区域,都可以根据文本信息决定应该生成什么。
例如 prompt 是:
a cat sitting on a sofa
那么去噪过程中,模型会逐渐把随机噪声引导成包含:
- cat
- sitting
- sofa
- 对应的空间关系
的图像。
5.3 文本不是最后才参与,而是每一步都参与
这点很重要。
文本条件不是生成结束后再筛选图片,也不是只在开头给一个标签。
在文本到图像扩散模型中,文本条件会参与多次去噪步骤。
也就是说,模型是在不断问:
当前这一步去噪,应该往哪个方向更符合文本描述?
这也是为什么 prompt 会强烈影响生成结果。
六、Diffusion、VAE、GAN 的区别
理解扩散模型时,经常会把它和 VAE、GAN 放在一起比较。
它们都是生成模型,但生成思路不同。
6.1 VAE:学习潜在空间
VAE 的核心是 encoder-decoder 结构。
它会把图像压缩到一个潜在变量 z,再从 z 重建图像。
可以理解成:
image -> latent z -> reconstructed image
VAE 的优点是结构清晰、训练稳定。
缺点是生成结果容易偏平滑,细节不够锐利。
6.2 GAN:对抗训练
GAN 包含两个模型:
- Generator:负责生成图像
- Discriminator:负责判断真假
训练过程像一个博弈:
生成器努力骗过判别器
判别器努力识别真假图像
GAN 的优点是生成图像通常更锐利。
缺点是训练不稳定,容易出现模式崩塌。
6.3 Diffusion:逐步去噪
Diffusion Model 的核心是加噪和去噪。
它把图像生成拆成很多个小步骤:
noise -> denoise -> denoise -> ... -> image
优点是训练稳定、生成质量高、可控性强。
缺点是采样过程通常比较慢,因为需要多次去噪。
6.4 三者对比表
| 维度 | VAE | GAN | Diffusion Model |
|---|---|---|---|
| 核心思想 | 学习潜在空间并重建图像 | 生成器和判别器对抗训练 | 从噪声逐步去噪生成图像 |
| 训练方式 | 重建损失 + KL 约束 | 对抗损失 | 噪声预测损失 |
| 生成质量 | 稳定但可能偏模糊 | 锐利但训练不稳 | 高质量且稳定 |
| 训练稳定性 | 较稳定 | 较不稳定 | 较稳定 |
| 采样速度 | 快 | 快 | 通常较慢 |
| 常见问题 | 细节模糊 | 模式崩塌 | 多步采样成本高 |
| 代表应用 | 表征学习、生成建模 | 图像生成、风格迁移 | AI 绘图、图像编辑、视频生成 |
七、面试常考知识点
7.1 Diffusion Model 的核心思想是什么?
核心回答:
扩散模型先定义一个逐步加噪的正向过程,再训练模型学习反向去噪过程,最终从随机噪声逐步生成图像。
可以补充:
- 正向过程通常不需要学习,是人为设计的加噪过程
- 反向过程需要神经网络学习
- 训练目标常见形式是预测噪声
7.2 正向扩散过程在做什么?
正向过程就是不断往真实图像中加入高斯噪声。
最终图像会从真实样本逐渐变成接近标准高斯噪声的样本。
可以记成:
real image -> noisy image -> pure noise
7.3 反向去噪过程在做什么?
反向过程是从纯噪声开始,逐步去噪生成图像。
每一步模型根据当前带噪图像和时间步,预测应该去掉的噪声。
可以记成:
pure noise -> denoise -> clean image
7.4 模型为什么要预测噪声?
因为训练时噪声是人为加入的,所以真实噪声是已知的。
让模型预测噪声,就可以构造明确的监督学习目标。
预测噪声之后,就可以用它把当前样本往更干净的方向更新。
7.5 U-Net 在扩散模型里做什么?
U-Net 是噪声预测网络。
它接收:
- 带噪图像或 latent
- 时间步 embedding
- 条件信息,例如文本 embedding
输出:
- 预测噪声
面试中可以说:
U-Net 负责在每个时间步预测噪声,帮助模型一步步完成反向去噪。
7.6 文本条件怎么控制生成图像?
文本 prompt 会先经过文本编码器,得到 text embedding。
这些 embedding 会通过 cross-attention 等方式注入 U-Net。
去噪过程中,U-Net 会根据文本条件调整生成方向。
可以简化成:
prompt -> text embedding -> cross-attention -> conditional denoising
7.7 Diffusion 和 GAN 最大区别是什么?
GAN 是一次性生成图像,并通过判别器进行对抗训练。
Diffusion 是从噪声开始,经过多步去噪生成图像。
可以回答:
GAN 学的是直接生成并骗过判别器;Diffusion 学的是逐步反转加噪过程。
7.8 Diffusion 的缺点是什么?
主要缺点是采样慢。
因为生成一张图通常需要多步去噪,每一步都要跑一次模型。
不过后续很多方法会通过更少步数采样、蒸馏、更好的 scheduler 来加速生成。
八、文章总结
Diffusion Model 可以用三句话理解:
- 正向过程:把真实图片一步步加噪,直到接近纯噪声。
- 反向过程:训练模型从带噪图片中预测噪声,并逐步恢复图像。
- 条件生成:把文本 embedding 注入 U-Net,让去噪过程朝 prompt 描述的方向前进。
和 VAE、GAN 相比,扩散模型最大的特点是:
| 模型 | 生成思路 |
|---|---|
| VAE | 从潜在空间采样并解码 |
| GAN | 生成器和判别器对抗训练 |
| Diffusion | 从随机噪声逐步去噪 |
Diffusion Model 不是直接画出图像,而是学会把噪声一步步还原成图像。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)