Agentic AI
Agentic AI 工作流是基于 LLM 的应用通过执行多个步骤来完成任务的过程。
Agentic AI 工作流就像请了一支“AI厨房天团”帮你做西红柿炒鸡蛋:你把任务拆成准备食材、炒菜、装盘三个步骤,分别指挥 Qwen 洗菜打蛋、Deepseek 掌勺控火、KIMI 精致摆盘,要是味道不对,还能让 ChatGPT 复盘问题、打回重做——全程你只动嘴不动手,靠多个大模型分工协作,一步步把复杂任务搞定。
自主性
低自主性(Less autonomous)
步骤预定义且清晰明确,所有工具调用都是硬编码的(Hard-coded),由人类工程师在代码中固定;其中主要自主性体现在语言模型生成的文本上。
高自主性(More autonomous)
给定工具和目标,自主决策。
示例: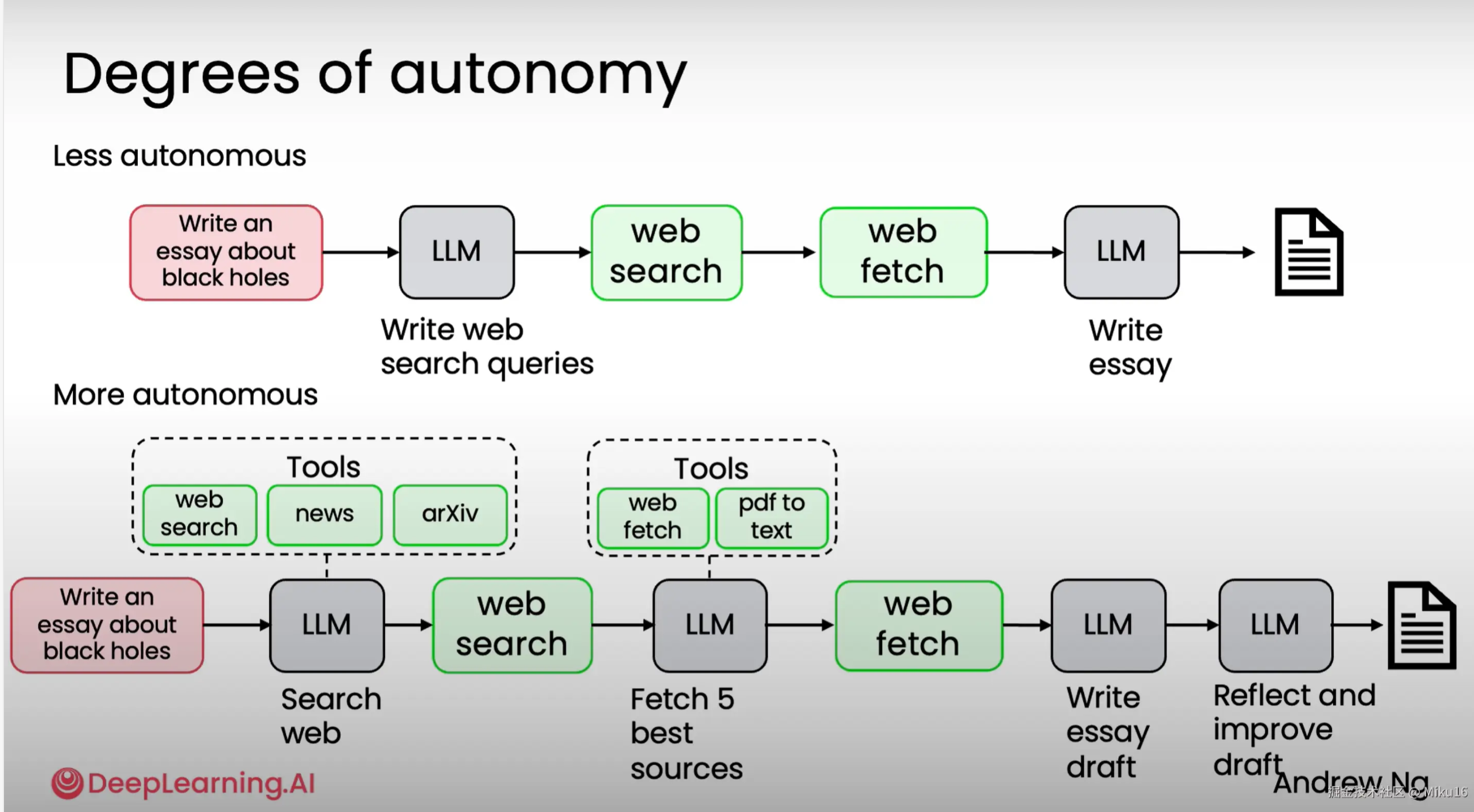
低自主性:
- 你告诉 LLM:“写一篇关于黑洞的论文”
- LLM → 写出搜索关键词
- 去网页搜
- 抓取网页内容
- LLM 把这些内容整合成文章
高自主性:
- 你告诉 LLM:“写一篇关于黑洞的论文”
- LLM 自己决定:先“web search”查资料 → 并且能调用“news”和“arXiv”等工具,找最新科研动态
- 找到结果后,它自己判断:“我要选5个最好的来源” → 调用“web fetch” + “pdf to text”工具提取内容
- 然后它写初稿 → 再自己反思:“这个段落逻辑不够强,数据没引用清楚” → 主动改进草稿
- 最后输出高质量论文!
优势
- 性能跃升 (Much Better Performance)
- 并行加速 (Faster than Humans because of Parallelization)
智能体工作流能够并行处理任务,从而比人类更快地完成特定工作。 - 模块化与可替换性 (Modular: can add or update tools, swap out models)
智能体工作流是高度模块化的,允许开发者自由地添加、更新工具或替换模型。
Agentic AI applications 代理式 AI 应用
案例一:发票处理工作流(Invoice Processing)
自动化处理企业收到的发票,提取关键信息并记录到数据库,以确保及时付款。
任务目标:从 PDF 发票中提取关键信息(开票方、金额、到期日),并录入数据库。
所需字段如下:
- 开票方(Biller)
- 开票地址(Biller address)
- 应付金额(Amount due)
- 到期日(Due date)
工作流步骤:
- PDF 转文本 → 使用 API 将 PDF 转为结构化文本(如 Markdown)。
- LLM 解析文本 → 判断是否为发票,提取所需字段。
- 调用工具更新数据库 → 通过 update database 工具将数据存入系统。
- 生成记录成功提示 → “Record created!”
案例二:回复客户邮件(Responding to Customer Email)
示例邮件:“我订购了蓝色 KitchenPro 搅拌机(订单 #8847),但收到的是红色烤面包机。”
工作流步骤:
- 提取关键信息 → LLM 识别订单号、产品、问题。
- 查询订单数据库 → 使用 orders database query 工具获取订单详情。
- 起草回复草稿 → LLM 根据信息撰写回复。
- 请求人工审核 → 使用 request review 工具将草稿提交给人类审批。
- 发送邮件 → 审核通过后自动发送。
价值:提升客服效率,确保回复准确性。
案例三:更复杂的客户服务agent(More Challenging: Customer Service Agent)
构建一个能处理各种未知问题的通用客户服务代理,而非仅限于特定订单查询。
场景一:库存查询:“你们有黑色或蓝色牛仔裤吗?”
agent需动态决定:
- 查询黑色牛仔裤库存
- 查询蓝色牛仔裤库存
- 综合回复客户
难点: 需要规划API调用的顺序来回答一个开放式问题。
场景二:退货处理:“我想退回我买的沙滩毛巾。”
agent需判断:
4. 验证客户购买记录
5. 检查退货政策(如是否在 30 天内、是否未使用)
6. 若允许退货 → 生成退货标签 + 设置数据库状态为“待退货”
难点: 步骤不是预先固定的,代理必须根据条件判断并决定后续行动。
任务分解
任务分解是构建代理型AI工作流的关键技能。其核心思想是:
- 观察人类行为: 思考如果一个人类要完成这个任务,他会怎么做?
- 拆解步骤: 将整个任务拆解成多个独立的、清晰的子步骤。
- 评估可行性: 对每个子步骤,思考它是否能用大型语言模型(LLM)或某个工具(如API、函数调用)来实现。
- 迭代优化: 如果初步分解的效果不理想,可以进一步细化某个步骤,将其拆分成更小的子步骤,直到达到满意的性能。
示例:回复客户邮件 (Responding to Customer Email)
目标:自动回复客户关于“发错货”的投诉邮件。
任务分解:
- 提取关键信息 (Extract key information):
输入: 客户邮件。
操作: LLM解析邮件,提取发件人姓名(Susan Jones)、订单号(#8847)、订购商品(蓝色搅拌机)和问题(收到红色烤面包机)。
可行性: LLM擅长文本信息提取。 - 查找相关客户记录 (Find relevant customer records):
操作: LLM调用 orders database query 工具,根据订单号查询数据库,核实订单详情和发货记录。
可行性: LLM可以通过函数调用与数据库交互。 - 撰写并发送回复 (Write and send response):
操作: LLM根据提取的信息和查询到的记录,起草一封回复邮件,并调用 send email API 将其发送给客户。
可行性: LLM可以生成文本,并通过API执行发送动作。
关键洞察
这个例子展示了如何将一个看似单一的任务(回复邮件)分解为三个清晰、独立的步骤。
每个步骤都可以由LLM或其调用的工具完成,从而构成一个完整的自动化流程。
基本构件 (Building Blocks)
- 模型 (Models)
大型语言模型 (LLMs):
用途: 文本生成、工具使用决策、信息提取。
特点: 擅长处理文本,是代理工作流的大脑。
其他AI模型 (Other AI models):
用途: 处理非文本模态数据,如PDF转文本、文本转语音、图像分析等。 - 工具 (Tools)
API:
用途: 执行外部服务,如网页搜索、获取实时天气数据、发送电子邮件、查看日历等。
信息检索 (Information retrieval):
用途: 从数据库或大型文本库中检索信息,常用于RAG(检索增强生成)场景。
代码执行 (Code execution):
用途: 允许LLM编写并运行代码,以执行更复杂的计算或数据处理任务,如基础计算器、数据分析等。
总结来说,构建智能体工作流的关键技能之一是审视某人可能执行的一系列任务,并识别出可以将其分解为的离散步骤。当我审视各个离散步骤时,我经常问自己的一个问题是:这个步骤是否可以通过LLM或者我拥有的工具(如API或函数调用)来实现?如果答案是否定的,那么我通常会问自己:作为人类,我会如何执行这个步骤?是否有可能进一步分解这个步骤,或者将其拆分成更小的步骤,从而使其更适合用LLM或我拥有的软件工具来实现?
Agentic AI评估(Evals)
最佳实践是先构建workflows,然后检查和找出不满意的地方,然后找到评估和改进的方法,消除不满意的地方。
1、通过编写的代码进行偏客观的评估。
2、通过LLM作为裁判进行偏主观的评估。
评估方式可以从两个维度划分,形成一个 2x2 的矩阵,用于指导评估的设计:
| 评估维度 | 客观评估 (Objective Evals) (用代码检查) | 主观评估 (Subjective Evals) (用 LLM 作为评判者) |
|---|---|---|
| 有每个例子的基本事实 (Per-Example Ground Truth) | 案例一:发票日期提取 (每个发票有不同的正确日期,用代码检查是否匹配) | 案例三:统计黄金标准点 (每个主题有不同的重要观点,用 LLM 检查是否充分提及) |
| 无每个例子的基本事实 (No Per-Example Ground Truth) | 案例二:营销文案长度 (所有标题都要求是 10 个词,用代码检查是否符合统一标准) | 评分标准评估 (Rubric Grading) (例如,根据统一的清晰度评分标准来评估图表) |
在复杂的代理式 AI 工作流程中,通过系统性的错误分析来确定工作重点,是提高系统改进效率的关键,又称端到端评估。
错误分析的核心是观察和量化,以找出工作流程中表现最差的组件。
端到端评估和组件级评估的关系有些类似端到端测试/集成测试与单元测试:
- 端到端评估成本高昂,即使是更换搜索引擎这样的小改动,都需要重新运行整个复杂的工作流程进行端到端评估,时间和金钱成本很高。同时,其他组件的随机性或噪声可能会掩盖被改进组件带来的微小、增量改进。
- 组件级评估更高效, 信号更清晰,避免了整体系统的复杂性带来的噪声。还适用于团队分工: 如果有多个团队分别负责不同组件,每个团队可以自行维护指标。
对于LLM 组件,改进主要围绕输入、模型本身和工作流程结构展开。
- 改进提示词:增加明确指令(在提示词中指明一些资源和任务应有的规划路径,而不是让LLM自己猜);使用少样本提示 (添加具体的输入和期望输出示例)
- 尝试不同的 LLM: 不要嫌麻烦,多测试几款 LLM,并使用评估 (Evals) 来选择最适合特定应用的最佳模型。
- 任务分解:如果单个步骤的指令过于复杂,导致 LLM 难以准确执行,考虑将任务分解为更小的、更易于管理的步骤,比如拆成生成步骤 + 反思步骤,或连续多次调用。
- 微调模型:这是最复杂、成本最高的选项。只有在穷尽所有其他方法后,仍需要挤出最后几个百分点的性能改进时才考虑。它适用于更成熟且性能要求极高的应用。
开发流程
| 阶段 | 描述 | 主要活动 |
|---|---|---|
| 快速原型 | 快速构建一个端到端系统(所谓的“先做个垃圾出来”)。 | 分析: 手动检查最终输出,通读追踪 (Traces),凭直觉找出性能不佳的组件。 |
| 初步评估 | 系统开始成熟,超越纯手动观察。 | 分析: 构建初步的 端到端评估 (Evals),使用小型数据集(如 10-20 例)计算整体性能指标。 |
| 严谨分析 | 系统需要更精确的改进方向。 | 分析: 进行错误分析,统计和量化各个组件导致次优输出的频率,以做出更集中的决策。 |
| 高效调优 | 系统进一步成熟,需要在组件级别进行高效改进。 | 分析: 构建组件级评估,以便更高效地对单个组件进行调优。 |
智能体设计模式
一、反思(Reflection)
核心概念: 让模型对自己的输出进行检查、评估和改进。
工作流程:
- 初始生成: 模型根据任务要求生成一个初步结果(如代码)。
- 自我评估/外部评估: 将该结果作为输入,再次提示同一个或另一个模型,要求其对结果进行批判性分析(如检查正确性、风格、效率,并给出改进建议)。
- 迭代优化: 将评估反馈(如“第5行有bug”或“单元测试失败”)提供给模型,让它基于反馈生成一个更好的版本。
- 循环往复: 此过程可以多次迭代,直到达到满意的质量。
这是一种非常有效的性能提升技术,虽然不能保证100%完美,但能带来显著的性能提升。
“反思”可以由同一个模型完成,也可以引入一个专门扮演“审查者”角色的独立模型(即多智能体协作的雏形)。
评估标准可以是客观的(如代码是否能运行),也可以是主观的(如代码风格)。
编写反思提示的两大黄金法则:
- 明确指示反思动作 (Clearly indicate the reflection action):
不要含糊地说“请改进”,而要说“请审查”、“请检查”、“请验证”。
明确告诉模型你要它做什么,例如“审核电子邮件初稿”或“验证HTML代码”。 - 具体指定检查标准 (Specify criteria to check):
不要只说“让它更好”,而要列出具体的评判标准。
例如,在域名任务中,标准是“易发音”和“无负面含义”;在邮件任务中,标准是“语气专业”和“事实准确”。
这样做能引导模型围绕你最关心的维度进行深入思考和改进。
示例:
直接生成:
- 向 LLM 发送提示:“Create a plot comparing Q1 coffee sales in 2024 and 2025 using coffee_sales.csv.”
- LLM 生成第一版 Python 代码(V1 code),用于读取CSV文件并绘制图表。
- 执行与结果:运行 V1 代码,生成了一张名为 plot.png 的图表。
问题显现: 这是一张堆叠柱状图(Stacked Bar Plot)。虽然它完成了数据展示的基本功能,但存在两大缺陷:堆叠柱状图对于比较不同年份同一饮品的销量不够直观;图表整体观感不佳,缺乏专业性。
引入反思 —— 多模态模型的视觉推理
将生成的图像作为输入,交由一个多模态语言模型(Multi-modal LLM)进行反思。
- 输入准备: 将 V1 版本的代码 (V1 code) 和它生成的图表 (plot.png) 一同打包,作为新的输入。
- 反思指令: 提示多模态 LLM 扮演“专家数据分析师”的角色,对图表进行批判性评估。
- 视觉推理: 多模态模型能够“真正地看”这张图,分析其可读性、清晰度和完整性,并提出具体的改进建议。
- 生成新代码: 根据反思反馈,模型更新代码,生成第二版(V2 code)。
- 最终成果: 运行 V2 代码,生成了 plot_v2.png。
反思提示语示例:
您是一位专业的数据分析师,能够为可视化提供建设性反馈。 {V1 代码} {plot.png} {对话历史记录} 步骤 1:评估所附图表的可读性、清晰度和完整性。 步骤 2:编写新代码来实现您的改进。
二、工具使用 (Tool Use)
核心概念: 赋予语言模型调用外部工具或函数的能力,以扩展其功能边界。
工作流程:
- 识别需求: 模型在处理任务时,判断需要调用哪个工具。
- 调用工具: 模型生成调用该工具的指令或参数。
- 执行与返回: 工具执行操作(如搜索网络、计算数学公式),并将结果返回给模型。
- 整合结果: 模型利用工具返回的结果来完成最终任务。
工具类型举例:
信息收集: Web search, Wikipedia, Database access.
分析计算: Code Execution, Wolfram Alpha, Bearly Code Interpreter.
生产力: Email, Calendar, Messaging.
图像处理: Image generation, Image captioning, OCR.
关键点: 工具使用极大地增强了模型的能力,使其不再局限于文本生成,而是能与现实世界互动并解决更广泛的问题。
MCP(Model Conntext Protocol,模型上下文协议)
旨在为大型语言模型(LLM)提供一种标准化的方式来访问外部工具和数据源。
客户端 (Clients)
角色:希望访问外部工具或数据的应用程序。
示例:Cursor, Claude Desktop, Windsurf。
功能:向 MCP 服务器发送请求,获取数据或执行操作。
服务器 (Servers)
角色:提供工具和数据源的软件服务。
示例:Slack, Google Drive, GitHub, PostgreSQL。
功能:作为“包装器”,接收来自客户端的请求,并将其转换为对原始工具 API 的调用,然后将结果返回给客户端。
来源:部分服务器由服务提供商开发,但也有大量第三方开发者贡献。
三、规划 (Planning)
核心概念: 让模型自主决定完成一个复杂任务所需的步骤序列,而不是由开发者硬编码。
工作流程:
- 任务理解: 模型接收一个复杂请求(如“生成一张女孩读书的图片,姿势与示例图中的男孩相同”)。
- 路径规划: 模型自动分解任务,决定需要调用哪些工具以及调用的顺序。
例如:先用 openpose 模型提取男孩的姿势 -> 再用 google/vit 模型根据该姿势生成女孩的图片 -> 接着用 vit-gpt2 模型描述图片 -> 最后用 fastspeech 模型将描述转为语音。 - 执行: 按照规划的步骤依次执行。
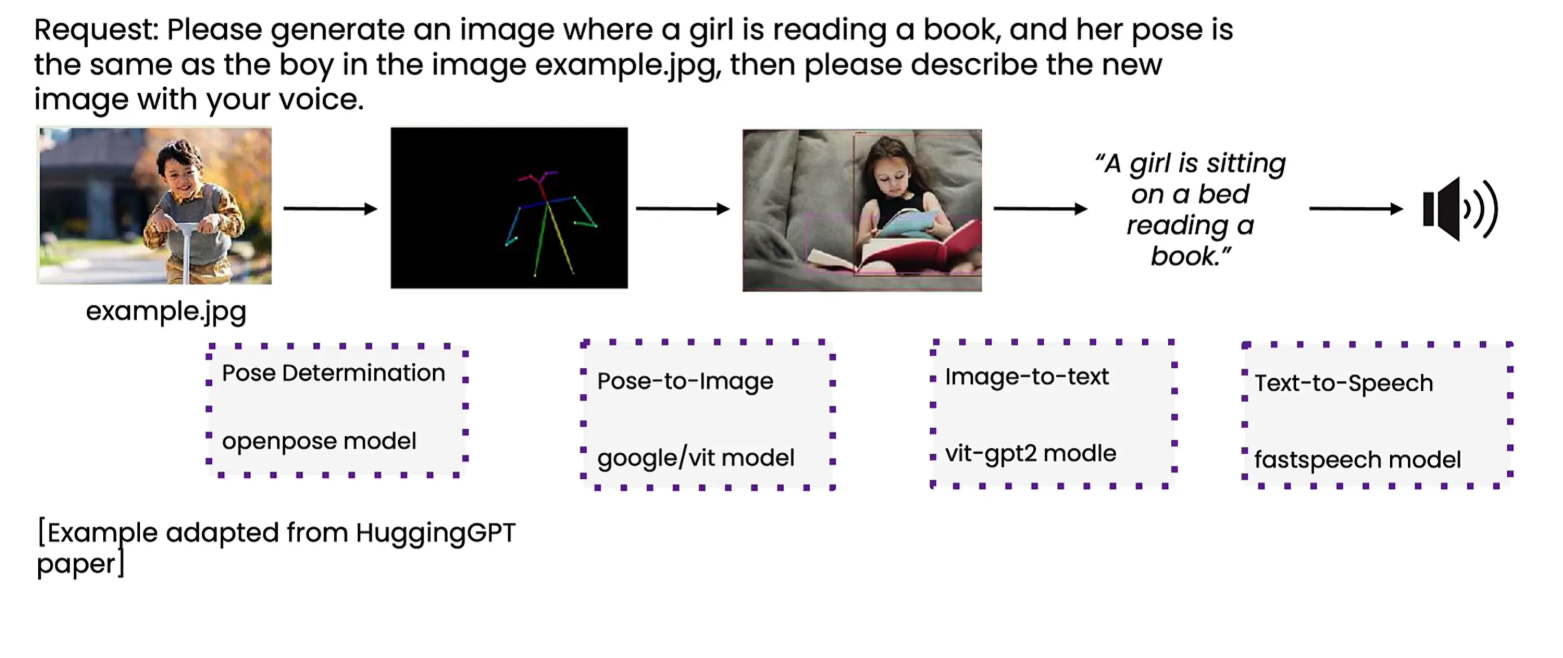
这种方式比硬编码的流程更灵活,但控制难度更大,也更具实验性。
它允许模型在面对新任务时,自行构思解决方案,有时会产生令人惊喜的结果。
四、多智能体协作 (Multi-agent collaboration)
核心概念: 雇佣多个具有不同专长的角色(智能体)协同工作,共同完成一个复杂项目。
工作流程:
- 角色分配: 为不同的智能体分配特定角色(如研究员、市场专员、编辑)。
- 分工合作: 各个智能体根据自己的角色和能力,执行相应的子任务。
- 沟通协调: 智能体之间相互沟通、传递信息,共同推进项目。
协作模式
- 线性模式(Linear communication pattern)
就像一个市场团队的工作流:研究员 → 平面设计师 → 文案撰写者。每个人只和下一个环节沟通。
线性模式按顺序执行任务,信息单向流动;
优点:结构简单、易于理解;
缺点:不灵活,出错时难以反馈或修正。 - 双层模式(Hierarchical communication pattern)
有一个“管理员(Manager Agent)”负责协调所有下属Agent。 就像项目负责人依次给研究员、设计师、写手分配任务,收集结果,再整合。
双层模式下,所有通信都经过经理;
优点 :清晰、易于控制、任务协调性强;
缺点 :可能成为瓶颈(manager负担重)。 - 多层模式(Deep Hierarchy)
一些高级系统会让子Agent自己也拥有下属Agent。 例如“研究员”下面有“网页研究员”和“事实核查员”,“作家”下面有“风格写手”和“引用校对员”。
优点:可扩展、模块化、可分层调度;
缺点:通信复杂、难以调试、出错难追踪。 - 去中心模式(All-to-all communication)
在这种模式下,每个Agent都能随时与其他Agent交流,没有中心,也没有固定顺序。
每个Agent都知道其他Agent是谁,他们可以互相发消息,谁都可以决定何时回复。直到最后大家都“认为任务完成”时,产出最终结果。
特点:高度去中心化、非常灵活、创意性强,但也 难以预测结果。
这种模式适用于容忍一定混乱、追求创造性结果的场景。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)