(Arxiv-2026)SAMA: 用于指令引导视频编辑的分解式语义锚定与运动对齐
SAMA: 用于指令引导视频编辑的分解式语义锚定与运动对齐
paper title:SAMA- Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing
paper是百度发布在Arxiv 2026的工作
Code:链接
摘要
当前指令引导的视频编辑模型难以同时平衡精确的语义修改与忠实的运动保持。现有方法依赖于注入显式外部先验(例如VLM特征或结构条件)来缓解这些问题,但这种依赖严重制约了模型的鲁棒性和泛化能力。为克服这一局限,我们提出SAMA(分解式语义锚定与运动对齐),一个将视频编辑分解为语义锚定和运动建模的框架。首先,我们引入语义锚定(Semantic Anchoring),通过联合预测语义token和稀疏锚帧处的视频潜变量来建立可靠的视觉锚点,实现纯粹基于指令感知的结构规划。其次,运动对齐(Motion Alignment)通过以运动为中心的视频恢复预训练任务(立方体修复、速度扰动和管块重排)在相同骨干上进行预训练,使模型能够直接从原始视频中内化时序动态。SAMA通过两阶段管线优化:一个分解式预训练阶段,在不需要配对视频-指令编辑数据的情况下学习固有的语义-运动表示,随后在配对编辑数据上进行监督微调。值得注意的是,仅分解式预训练就已经产生了强大的零样本视频编辑能力,验证了所提出分解方案的有效性。SAMA在开源模型中达到最先进性能,并与领先的商业系统(如Kling-Omni)具有竞争力。代码、模型和数据集将公开发布。

1 引言
扩散模型实现了具有出色保真度和可控性的交互式指令引导图像编辑。然而,将这一范式从单张图像扩展到视频仍然极具挑战。一个实用的指令引导视频编辑器必须(i)应用遵循指令的细粒度语义变化,同时(ii)保持编辑主体、背景和相机的时序一致运动。在当前模型中,这两个要求经常冲突:激进的语义变化会引入局部伪影、身份漂移和纹理跳变,而强制时序一致性可能削弱预期编辑并降低指令保真度(图1上方)。这种张力在基于扩散的视频编辑和适应工作中被广泛观察到。
为缓解这些问题,现有方法的一个主流趋势是依赖注入显式外部先验,如VLM提取的语义条件或骨架和深度图等结构信号。我们认为这种过度依赖构成了一个重大瓶颈,阻碍了扩散骨干学习用于精确语义编辑和与源视频动态忠实运动对齐的固有语义-运动表示。相反,我们将指令引导视频编辑的核心困难归因于语义结构规划和运动建模之间缺乏分解。语义编辑通常是稀疏且时序稳定的:少量锚帧通常足以确定期望的视觉修改。相比之下,运动连贯性遵循可以从大规模原始视频中学习的物理和时序动态,无需显式编辑监督。
基于这一观察,我们提出SAMA(分解式语义锚定与运动对齐),一个鼓励模型将语义结构规划和运动建模作为两种互补能力来学习的框架。首先,我们引入语义锚定,它联合预测语义token和视频潜变量,在语义空间支持指令感知的结构规划,同时在潜空间保持高保真渲染。其次,运动对齐通过以运动为中心的视频恢复任务加强时序推理,鼓励骨干直接从原始视频中内化连贯的时序动态。
为实现这种分解学习范式,我们采用两阶段策略训练SAMA。在第一阶段,分解式预训练过程鼓励模型将语义锚定和运动动态内化为两种互补能力,无需配对的指令引导视频编辑数据。值得注意的是,我们发现仅此阶段就已经诱导出强大的零样本视频编辑行为。这一观察表明,当模型学会联合推理语义意图和时序动态时,鲁棒的指令引导视频编辑能力会自然涌现。在随后的监督微调阶段,模型在配对视频编辑数据集上训练,以解决残余的语义-运动冲突并提高视觉保真度。因此,SAMA在开源模型中达到最先进性能,同时取得与领先商业系统(如Kling-Omni、Runway)可比的结果。
- 我们提出了一种关于指令引导视频编辑的分解视角,将语义规划与运动建模分离,减少对脆弱外部先验的依赖。
- 我们引入语义锚定和运动对齐(通过以运动为中心的视频恢复预训练),使扩散骨干能够内化鲁棒的语义和时序表示。
- SAMA在开源视频编辑模型中达到最先进性能,并与领先商业系统具有竞争力。代码、模型和数据集将公开发布。
2 相关工作
2.1 指令引导视频编辑
指令引导视频编辑旨在根据文本指令编辑输入视频,关键挑战在于保持时序一致性。早期基于扩散的尝试在指令引导视频编辑中主要遵循零样本或少样本范式,其中预训练的文生图扩散模型通过额外的时序建模被重新用于视频以维持一致性。
随着大规模指令引导视频编辑数据集(如Señorita-2M、InsViE-1M、Ditto-1M、ReCo-Data和OpenVE-3M)的发布,最近的研究已转向端到端训练的数据驱动视频编辑模型。Ditto通过将强大的图像编辑模型与上下文视频生成模型结合来构建其大规模合成数据管线,然后在Ditto-1M上训练模型以改善指令引导和时序一致性。OpenVE-3M扩展了跨多种编辑类别的监督,而ReCo-Data专注于区域感知指令编辑以改善局部可控性。
若干最近工作进一步探索了统一和上下文编辑公式。UNIC通过将噪声视频潜变量、源视频token和多模态条件token转换为单一序列来统一不同的视频编辑任务,使扩散Transformer可以在上下文中学习编辑行为而无需任务特定适配器或DDIM反转。VACE探索了支持多种编辑操作的统一可控编辑公式,改善了指令引导视频编辑的通用性和鲁棒性。ICVE提出了一种低成本预训练策略,使用未配对的视频片段在上下文中学习通用编辑能力,然后用少量配对编辑数据精调模型。EditVerse提出了一个统一的图像/视频生成和编辑框架,在共享token空间中表示文本、图像和视频,支持强大的上下文编辑和数据驱动训练。DiffuEraser研究了指令引导的视频物体去除。ReCo引入了联合源-目标视频扩散框架并应用区域约束来改善指令引导编辑。VideoCoF引入了帧链式"看-推理-编辑"公式,在生成前预测跨帧编辑的位置和方式,无需用户提供的掩码即可改善指令到区域的对齐和时序一致性。
除了以编辑为中心的模型外,统一的视频理解和生成框架如Omni-Video、InstructX、UniVideo和VINO也为视频内容和运动动态提供了强大的表示。
2.2 图像和视频生成中的语义对齐
图像和视频生成的最新进展也受益于生成模型和强预训练编码器之间的语义对齐。在图像生成中,REPA将中间去噪特征与预训练图像编码器的干净特征对齐,稳定训练并改善生成质量。在REPA之后,多项工作研究了如何更有效地应用表示对齐,包括端到端VAE-扩散训练(REPA-E)、避免后期退化的分阶段调度(HASTE)、通过自蒸馏的免教师自对齐(SRA)。
类似思想最近被扩展到视频生成。SemanticGen首先预测紧凑语义特征,然后在其基础上生成VAE潜变量,这对长视频更高效。VideoREPA通过token关系对齐将时空关系知识从视频基础模型蒸馏到文生视频扩散模型。除生成外,这种关系对齐思想也被采用于视频编辑:FFP-300K使用受VideoREPA启发的帧间关系蒸馏来更好地保持源运动。
定位。受图像/视频生成中语义对齐最新进展的启发,我们将语义对齐正则化应用于指令引导视频编辑。我们的方法改善了指令遵循和时序一致性,加速了训练期间的DiT收敛,且无需繁重的测试时优化。
2.3 视频表示学习的自监督学习
自监督学习通过预训练任务从无标签视频中学习时空表示。受这一研究方向的启发,我们在运动对齐(第3.3节)中采用轻量级预训练任务作为以运动为中心的恢复目标,以更好地捕获连贯的时序动态。先前工作主要分为三类:基于速度的学习(如SpeedNet、PRP、Pace Prediction)、时空谜题(如Space-Time Cubic Puzzles)和基于重建的目标(如掩码视频建模和VideoMAE)。
3 方法
预备知识。我们采用通过流匹配范式训练的视频扩散transformer框架。主要训练目标是最小化期望流匹配损失,定义为:
L F M ( θ ) = E t , x 0 , x 1 ∥ v θ ( x t , t ) − ( x 1 − x 0 ) ∥ 2 2 \mathcal{L}_{FM}(\theta) = \mathbb{E}_{t,x_0,x_1}\|v_\theta(x_t, t) - (x_1 - x_0)\|_2^2 LFM(θ)=Et,x0,x1∥vθ(xt,t)−(x1−x0)∥22
其中 x 1 x_1 x1 是目标视频, x 0 x_0 x0 是高斯先验。网络 v θ v_\theta vθ 学习从中间状态 x t = t x 1 + ( 1 − t ) x 0 x_t = tx_1 + (1-t)x_0 xt=tx1+(1−t)x0 回归向量场 x 1 − x 0 x_1 - x_0 x1−x0。这一公式对应于流常微分方程:
d x d t = v θ ( x , t ) \frac{dx}{dt} = v_\theta(x, t) dtdx=vθ(x,t)
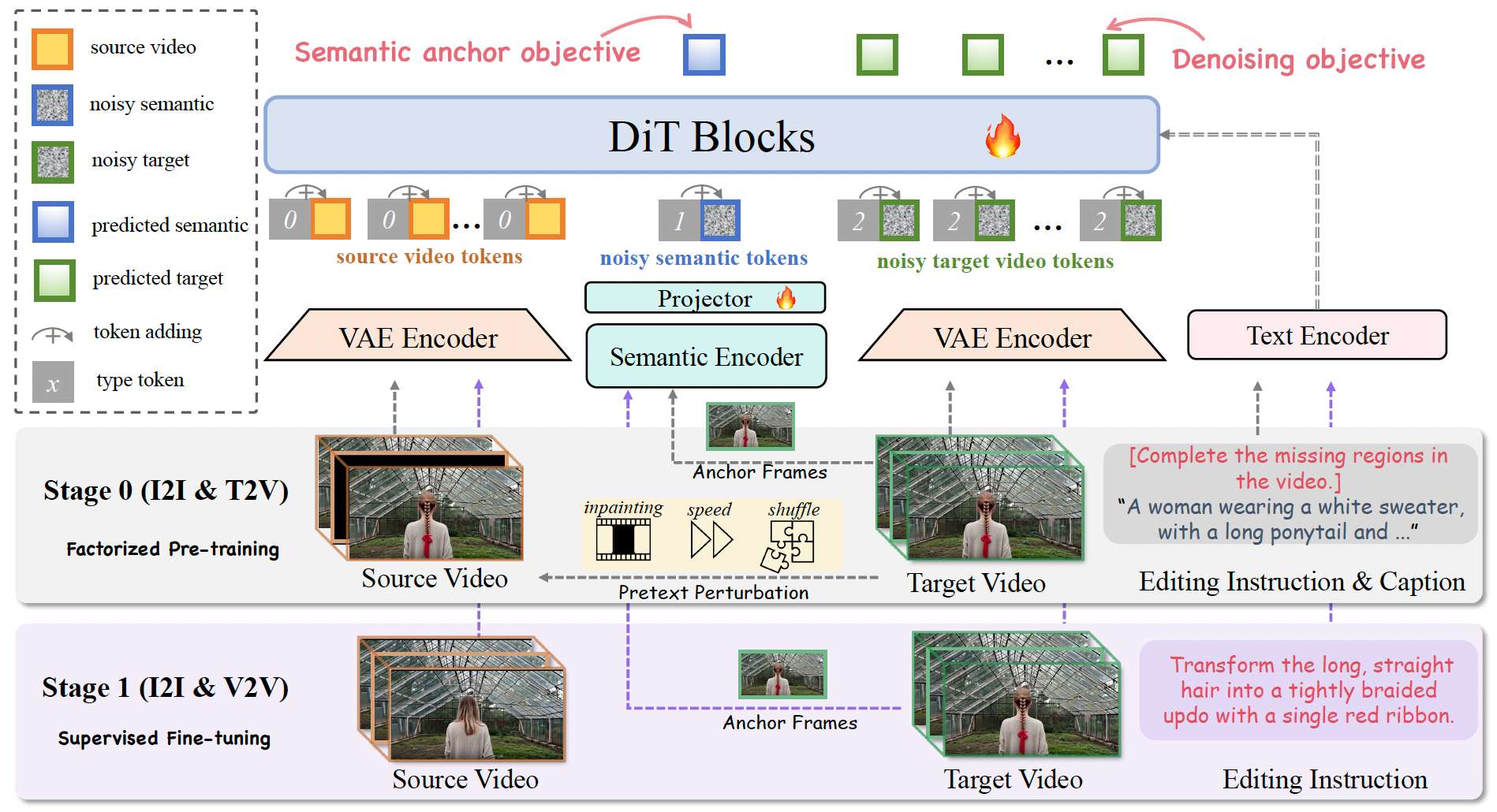
3.1 SAMA
SAMA构建在视频扩散模型Wan2.1-T2V-14B之上。给定源视频 V s V_s Vs 和编辑指令 y y y,目标是生成遵循 y y y 同时保持逼真时空运动和未编辑内容的编辑目标视频 V t V_t Vt。
潜变量token化。我们遵循潜扩散风格的公式将视频编码为VAE潜变量。源和目标视频被表示为token序列 z s \mathbf{z}_s zs 和 z t \mathbf{z}_t zt。我们通过拼接源和(噪声)目标token序列形成上下文V2V输入: z = [ z s ; z t ] \mathbf{z} = [\mathbf{z}_s ; \mathbf{z}_t] z=[zs;zt]。
类型嵌入。为消除token角色的歧义,我们为每个token添加学习的类型嵌入:源视频潜变量token z s \mathbf{z}_s zs 的类型id为0,目标视频潜变量token z t \mathbf{z}_t zt 的类型id为2,语义锚定引入的语义token的类型id为1。这一约定在所有阶段一致使用。我们经验性地观察到,使用类型嵌入比常用的shifted RoPE方案收敛更快,同时对骨干先验的扰动更小。我们在附录中提供了进一步讨论和支持证据。
SAMA在扩散骨干中内化两种互补能力:语义锚定(SA)在稀疏锚帧上提供指令一致的锚点以稳定结构编辑(见第3.2节);运动对齐(MA)通过以运动为中心的预训练监督将编辑后的视频与源视频运动动态对齐,改善时序稳定性并缓解语义-运动冲突(见第3.3节)。基于这两种能力,我们进一步引入两阶段训练策略:首先在分解式预训练阶段学习强大的固有语义-运动表示,然后在SFT阶段用配对监督加强编辑性能(第3.4节)。
3.2 语义锚定
语义锚定(SA)作为辅助目标在分解式预训练阶段和SFT阶段全程引入。对于图像样本,目标图像作为锚点。对于视频样本,我们从目标视频中均匀采样 N N N 帧作为稀疏锚帧。每个锚帧由SigLIP图像编码器编码以获得patch级语义特征。然后我们通过池化将这些特征聚合为紧凑的token集,产生 M M M 个捕获区域级语义的局部语义token和一个总结整体内容的全局token。所有语义token最终通过轻量级两层MLP投影到与VAE潜变量token相同的嵌入空间。
将语义token注入去噪序列。设 s ^ \hat{\mathbf{s}} s^ 表示从 N N N 个锚帧提取的投影语义token。我们将 s ^ \hat{\mathbf{s}} s^ 前置到目标潜变量序列,将它们视为去噪轨迹的一部分:我们对语义token和目标潜变量应用相同的前向加噪过程,将拼接的噪声序列输入DiT。去噪后,我们读出对应语义token位置的输出并通过语义预测头传递,产生预测的语义token s \mathbf{s} s。
目标。我们用预测token和提取锚点token之间的 ℓ 1 \ell_1 ℓ1 损失来监督语义预测:
L s e m = ∥ s ^ − s ∥ 1 \mathcal{L}_{sem} = \|\hat{\mathbf{s}} - \mathbf{s}\|_1 Lsem=∥s^−s∥1
整体训练目标结合了流匹配损失和语义锚定损失:
L = L F M + λ ⋅ L s e m \mathcal{L} = \mathcal{L}_{FM} + \lambda \cdot \mathcal{L}_{sem} L=LFM+λ⋅Lsem
3.3 运动对齐
运动对齐(MA)应用于分解式预训练阶段(第3.4节)的视频样本。给定源视频 V s V_s Vs 和指令 y y y,我们仅对源视频应用以运动为中心的变换 T \mathcal{T} T 得到 V ^ s = T ( V s ) \hat{V}_s = \mathcal{T}(V_s) V^s=T(Vs),同时保持目标侧不变(即始终使用未增强的原始目标视频)。这一设计迫使模型从源流中学习运动和时序推理,改善在快速运动和复杂相机动态下的鲁棒性。

以运动为中心的变换。我们采用三种受自监督视觉序列学习启发的恢复风格扰动:(i) 立方体修复:在 V ^ s \hat{V}_s V^s 中遮蔽一个连续的时空块,恢复以剩余帧为条件的缺失内容;(ii) 速度扰动:时序加速 V ^ s \hat{V}_s V^s,学习恢复正常动态,改善对运动速率变化的鲁棒性;(iii) 管块重排:将 V ^ s \hat{V}_s V^s 划分为 2 × 2 × 2 2\times2\times2 2×2×2 的时空管网格并随机排列,迫使模型推理时空结构并恢复连贯运动。
预训练任务的提示。为使目标明确并统一跨任务的公式,我们在编辑指令前添加短任务token:
- [Complete the missing regions in the video.](立方体修复)
- [Restore the video to normal playback speed.](速度扰动)
- [Restore the correct spatio-temporal order of the video segments.](管块重排)
总体而言,MA鼓励骨干从源流中内化鲁棒的运动动态,同时保持与指令条件编辑公式的完全兼容性。
3.4 训练策略
SAMA通过反映我们对指令引导视频编辑分解观点的两阶段训练管线优化。
阶段0:分解式预训练。我们从强大的文生视频先验出发,在指令式图像编辑对和大规模文生视频数据的混合上进行预训练。图像编辑部分提供广泛的语义覆盖并改善通用指令落地,而文生视频部分提供多样化的真实世界运动模式。在此阶段,我们对图像和视频样本都应用SA,仅对视频流应用MA:(i) SA在 N N N 个稀疏采样的锚帧上监督语义token预测,鼓励指令一致的语义锚定同时共享相同的扩散骨干(第3.2节);(ii) MA训练模型恢复时序扰动的源视频,通过以运动为中心的预训练监督改善时序稳定性和快速运动下的鲁棒性(第3.3节)。阶段0的整体目标遵循公式(4):
L = L F M + λ ⋅ L s e m \mathcal{L} = \mathcal{L}_{FM} + \lambda \cdot \mathcal{L}_{sem} L=LFM+λ⋅Lsem
其中 L F M \mathcal{L}_{FM} LFM 是公式(1)的流匹配损失, L s e m \mathcal{L}_{sem} Lsem 是SA语义预测损失。
阶段1:监督微调(SFT)。然后我们在配对视频编辑数据集上进行监督微调,同时混合少量图像编辑数据以保持通用指令遵循行为。在此阶段,模型在标准的指令引导视频编辑三元组(源视频、指令、目标视频)上训练,我们保持SA启用以维持稀疏锚帧上稳定的语义锚定。与阶段0相比,阶段1专注于用配对编辑监督对齐生成,改善编辑保真度并缓解困难运动和细粒度编辑中观察到的残余语义-运动冲突。
这种两阶段设计将语义锚定和运动对齐的学习与稀缺的配对视频编辑数据分离。因此,阶段0已经提供了强大的零样本视频编辑能力,而阶段1通过配对监督进一步改善编辑保真度和基准性能。
4 实验
4.1 实验设置
训练数据。如表1所示,我们使用NHR-Edit、GPT-image-edit、X2Edit和Pico-Banana-400K进行图像编辑训练。我们额外纳入文生视频数据Koala-36M和MotionBench用于预训练运动对齐。Ditto-1M、OpenVE-3M和ReCo-Data用于视频编辑。所有数据集都经过基于VLM的粗过滤阶段以去除低质量或指令不一致的样本。详细过滤标准在附录中提供。具体而言,我们仅使用Ditto-1M的Style子集,以及OpenVE-3M中的Local Change、Background、Style和Subtitles类别。
表1:各阶段训练数据统计。★ 表示我们使用特定的文生视频数据进行预训练变换。
| 训练阶段 | 数据集 | 样本对数 | 类型 |
|---|---|---|---|
| 阶段0 分解式预训练 | NHR-Edit | 720,087 | 图像编辑 |
| GPT-Image-Edit | 1,015,170 | 图像编辑 | |
| X2Edit | 768,470 | 图像编辑 | |
| Koala-36M | 1,532,716 | 文生视频★ | |
| MotionBench | 53,879 | 文生视频★ | |
| 阶段1 监督微调 | NHR-Edit | 720,087 | 图像编辑 |
| Pico-Banana-400K | 257,730 | 图像编辑 | |
| Ditto-1M | 3,936 | 视频编辑 | |
| OpenVE-3M | 818,232 | 视频编辑 | |
| ReCo-Data | 206,596 | 视频编辑 |
实现细节。训练期间,我们对两个阶段进行混合图像和视频数据的两阶段训练。学习率为 2 × 10 − 5 2 \times 10^{-5} 2×10−5。全局batch大小为图像448,视频112。我们在480p分辨率下训练。支持多种宽高比,包括1/2、2/3、3/4和1/1及其倒数。我们维护模型参数的指数移动平均(EMA),衰减率0.9998,每次迭代更新。损失权重 λ \lambda λ(公式4)设为0.1。除非另有说明,我们对语义锚定(第3.2节)均匀采样 N N N 个稀疏锚帧;为效率起见,所有实验中设 N = 1 N = 1 N=1。我们使用 M = 64 M = 64 M=64 个局部语义token(加一个全局token),并在整个过程中固定 M = 64 M = 64 M=64。
在文生视频数据中,我们使用无预训练任务加三种预训练任务——立方体修复、速度扰动和管块重排——采样比例为1:2:3:4(无预训练:立方体修复:速度扰动:管块重排)。任务特定设置见附录。
评估细节。为评估SAMA,我们将其与当前最先进的闭源和开源方法进行比较。闭源模型包括Kling1.6、Kling-Omni、Runway、MiniMax和Pika。开源方法包括InsV2V、DiffuEraser、VACE、InsViE、Omni-Video、UniVideo、InstructX、ICVE、Ditto、OpenVE-Edit、VINO和ReCo。我们在三个基准上进行实验:VIE-Bench、OpenVE-Bench和ReCo-Bench。不同基准使用不同VLM评判:VIE-Bench用GPT-4o,OpenVE-Bench用Gemini-2.5-Pro,ReCo-Bench用Gemini-2.5-Flash-Thinking。
4.2 与最先进方法的比较
表2:VIE-Bench 上的比较结果。最优结果加粗。灰色底纹表示闭源模型。
| 方法 | 添加-指令遵循 | 添加-保持度 | 添加-质量 | 添加-平均 | 替换/变化-指令遵循 | 替换/变化-保持度 | 替换/变化-质量 | 替换/变化-平均 |
|---|---|---|---|---|---|---|---|---|
| Kling1.6 | 6.000 | 8.230 | 5.576 | 6.602 | 9.000 | 9.060 | 8.333 | 8.800 |
| Kling-Omni | 9.333 | 9.589 | 8.622 | 9.181 | 9.495 | 9.448 | 8.638 | 9.194 |
| Runway | 8.607 | 8.913 | 7.823 | 8.447 | 9.580 | 8.628 | 9.275 | 9.161 |
| Pika | - | - | - | - | 7.542 | 7.847 | 6.837 | 7.408 |
| InsV2V | 3.552 | 5.891 | 3.402 | 4.281 | 5.304 | 6.428 | 4.971 | 5.567 |
| VACE | 3.938 | 6.696 | 3.929 | 4.854 | 6.171 | 7.552 | 6.199 | 6.640 |
| Omni-Video | 5.699 | 6.135 | 6.294 | 6.242 | 4.733 | 4.856 | 4.656 | 4.748 |
| UniVideo | 8.567 | 9.422 | 7.978 | 8.656 | 8.886 | 8.962 | 8.200 | 8.683 |
| InstructX | 8.446 | 8.683 | 7.919 | 8.349 | 9.514 | 9.171 | 8.533 | 9.072 |
| SAMA | 8.467 | 9.422 | 8.244 | 8.711 | 9.733 | 9.514 | 8.771 | 9.340 |
| 方法 | 去除-指令遵循 | 去除-保持度 | 去除-质量 | 去除-平均 | 风格/色调变化-指令遵循 | 风格/色调变化-保持度 | 风格/色调变化-质量 | 风格/色调变化-平均 |
|---|---|---|---|---|---|---|---|---|
| Kling1.6 | 8.440 | 8.800 | 7.520 | 8.253 | - | - | - | - |
| Kling-Omni | 9.378 | 9.233 | 8.789 | 9.133 | 9.867 | 9.200 | 8.956 | 9.341 |
| Runway | 8.664 | 9.145 | 7.703 | 8.504 | 9.583 | 9.200 | 8.616 | 9.133 |
| MiniMax | 6.963 | 7.518 | 6.037 | 6.839 | - | - | - | - |
| DiffuEraser | 6.346 | 6.807 | 5.576 | 6.243 | - | - | - | - |
| InsV2V | 1.209 | 3.769 | 1.322 | 2.098 | 7.835 | 8.086 | 6.437 | 7.452 |
| VACE | 1.812 | 3.877 | 2.359 | 2.682 | - | - | - | - |
| Omni-Video | 6.004 | 5.970 | 4.807 | 5.593 | 5.486 | 4.655 | 5.959 | 5.366 |
| UniVideo | 8.133 | 8.778 | 7.789 | 8.233 | 9.244 | 8.689 | 8.200 | 8.711 |
| InstructX | 8.627 | 8.668 | 7.672 | 8.322 | 9.650 | 9.099 | 8.839 | 9.196 |
| SAMA | 9.533 | 9.189 | 8.711 | 9.144 | 9.644 | 9.356 | 8.778 | 9.259 |
表3:OpenVE-Bench 上使用 Gemini 2.5 Pro 的比较结果。最优结果加粗。灰色底纹表示闭源模型。
| 方法 | 参数量 | 全局风格 | 背景变化 | 局部变化 | 局部去除 | 局部添加 | 字幕编辑 | 创意编辑 |
|---|---|---|---|---|---|---|---|---|
| Runway | - | 3.72 | 2.62 | 4.18 | 4.16 | 2.78 | 3.62 | 3.64 |
| VACE | 14B | 1.49 | 1.55 | 2.07 | 1.46 | 1.26 | 1.48 | 1.47 |
| Omni-Video | 1.3B | 1.11 | 1.18 | 1.14 | 1.14 | 1.36 | 1.00 | 2.26 |
| InsViE | 2B | 2.20 | 1.06 | 1.48 | 1.36 | 1.17 | 2.18 | 2.02 |
| Lucy-Edit | 5B | 2.27 | 1.57 | 3.20 | 1.75 | 2.30 | 1.61 | 2.86 |
| ICVE | 13B | 2.22 | 1.62 | 2.57 | 2.51 | 1.97 | 2.09 | 2.41 |
| Ditto | 14B | 4.01 | 1.68 | 2.03 | 1.53 | 1.41 | 2.81 | 1.23 |
| OpenVE-Edit | 5B | 3.16 | 2.36 | 2.98 | 1.85 | 2.15 | 2.91 | 2.31 |
| UniVideo | 20B | 3.64 | 2.22 | 3.91 | 2.70 | 2.98 | 2.69 | 2.90 |
| SAMA | 14B | 4.05 | 2.59 | 3.93 | 3.32 | 2.54 | 3.63 | 3.11 |
表4:ReCo-Bench 上使用 Gemini-2.5-Flash-Thinking 的比较结果。最优结果加粗。
| 任务 | 方法 | SA | SP | CP | AN | SN | MN | VF | TS | ES | S E A S_{EA} SEA | S V N S_{VN} SVN | S V Q S_{VQ} SVQ | S S S |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 添加 | InsViE | 2.60 | 2.79 | 2.78 | 2.33 | 3.98 | 3.74 | 3.71 | 3.91 | 3.58 | 2.60 | 3.10 | 3.46 | 3.05 |
| 添加 | Lucy-Edit | 6.27 | 6.32 | 7.75 | 4.63 | 7.08 | 6.08 | 6.31 | 6.82 | 7.57 | 6.47 | 5.70 | 6.77 | 6.31 |
| 添加 | Ditto | 7.46 | 7.24 | 6.30 | 6.30 | 8.85 | 8.30 | 8.13 | 8.55 | 9.03 | 6.70 | 7.57 | 8.41 | 7.56 |
| 添加 | UniVideo | 9.39 | 9.27 | 9.69 | 7.27 | 9.23 | 8.80 | 8.44 | 8.89 | 9.75 | 9.40 | 8.31 | 8.99 | 8.90 |
| 添加 | ReCo | 8.65 | 8.40 | 9.22 | 6.39 | 8.78 | 8.28 | 8.02 | 8.61 | 9.61 | 8.54 | 7.55 | 8.61 | 8.23 |
| 添加 | SAMA | 9.51 | 9.26 | 9.83 | 7.44 | 9.50 | 8.87 | 8.78 | 9.03 | 9.76 | 9.43 | 8.33 | 9.00 | 8.92 |
| 替换 | InsViE | 1.89 | 2.38 | 2.48 | 2.58 | 5.25 | 5.05 | 3.76 | 4.00 | 3.52 | 2.10 | 3.91 | 3.49 | 3.17 |
| 替换 | Lucy-Edit | 6.57 | 7.49 | 7.73 | 5.13 | 7.46 | 6.65 | 6.32 | 6.64 | 8.08 | 7.08 | 6.21 | 6.88 | 6.72 |
| 替换 | Ditto | 4.95 | 4.83 | 4.79 | 5.81 | 8.63 | 8.10 | 7.55 | 7.95 | 8.71 | 4.56 | 7.21 | 7.96 | 6.58 |
| 替换 | UniVideo | 9.03 | 9.68 | 9.73 | 7.73 | 9.30 | 8.92 | 8.57 | 8.91 | 9.80 | 9.40 | 8.39 | 8.90 | 8.90 |
| 替换 | ReCo | 9.38 | 9.43 | 9.59 | 7.07 | 8.87 | 8.47 | 8.19 | 8.65 | 9.67 | 9.43 | 8.01 | 8.77 | 8.74 |
| 替换 | SAMA | 9.58 | 9.82 | 9.82 | 7.77 | 9.35 | 8.98 | 8.55 | 8.80 | 9.72 | 9.71 | 8.60 | 8.98 | 9.10 |
| 去除 | InsViE | 2.53 | 2.49 | 2.44 | 2.63 | 4.87 | 4.72 | 3.41 | 3.67 | 3.40 | 2.44 | 3.76 | 3.29 | 3.16 |
| 去除 | VACE | 4.58 | 4.58 | 4.56 | 4.96 | 6.09 | 5.89 | 5.48 | 5.50 | 5.57 | 4.57 | 5.43 | 5.56 | 5.19 |
| 去除 | UniVideo | 7.37 | 7.43 | 7.28 | 6.06 | 7.61 | 7.13 | 6.28 | 6.43 | 7.72 | 7.33 | 6.59 | 6.51 | 6.81 |
| 去除 | ReCo | 7.43 | 7.43 | 7.17 | 6.20 | 7.43 | 7.30 | 6.48 | 6.63 | 7.68 | 7.28 | 6.90 | 6.82 | 7.00 |
| 去除 | SAMA | 8.76 | 8.71 | 8.43 | 7.16 | 8.73 | 8.42 | 7.31 | 7.52 | 8.73 | 8.61 | 7.73 | 8.09 | - |
| 风格 | InsViE | 7.59 | 8.86 | 8.49 | 6.77 | 9.14 | 9.28 | 7.13 | 6.40 | 8.99 | 8.17 | 8.21 | 7.35 | 7.91 |
| 风格 | Lucy-Edit | 3.73 | 5.59 | 5.39 | 4.20 | 5.88 | 5.88 | 4.44 | 4.17 | 5.87 | 4.65 | 4.67 | 5.17 | 4.83 |
| 风格 | Ditto | 9.10 | 9.36 | 9.26 | 8.25 | 9.51 | 9.58 | 8.33 | 8.33 | 9.77 | 9.20 | 9.07 | 8.77 | 9.01 |
| 风格 | UniVideo | 8.10 | 9.82 | 9.50 | 8.56 | 9.65 | 9.84 | 8.91 | 8.57 | 9.88 | 8.95 | 9.23 | 9.00 | 9.06 |
| 风格 | ReCo | 9.11 | 9.82 | 9.54 | 8.43 | 9.55 | 9.70 | 8.61 | 8.35 | 9.87 | 9.42 | 9.19 | 8.90 | 9.17 |
| 风格 | SAMA | 8.46 | 9.95 | 9.64 | 8.79 | 9.77 | 9.77 | 8.88 | 8.59 | 9.83 | 9.24 | 9.42 | 9.07 | 9.25 |
定性比较。在VIE-Bench和ReCo-Bench的定性比较中(见图4),SAMA在多样化编辑类型上展示了更强的指令遵循和时序一致性。SAMA更可靠地遵循细粒度指令,正确处理相对位置线索(如"在左边")和属性约束(如交替的浅色和深色头发)。它还以跨时间一致的外观完成替换(如鸽子→松鼠、海豹→螃蟹)。在运动方面,SAMA更好地保持去除后的时序对齐(如保持婴儿车对齐),并在风格化期间维持身份/细节,而其他方法可能漂移或模糊。总体而言,SAMA更好地将指令语义落地,同时保持连贯运动,产生更高质量和更稳定的编辑。

4.3 零样本视频编辑
我们在零样本设置下评估SAMA,即模型在未经任何视频编辑数据训练的情况下,在推理时直接以编辑指令作为提示。如图5所示,SAMA在Replace/Add/Remove/Style/Hybrid任务上展示了强大的零样本编辑能力,在多帧上产生一致的编辑,同时很大程度上保持未编辑内容。尽管结果令人鼓舞,我们也观察到零样本设置中的几种典型失败模式:(i)属性编辑可能时序不一致,例如编辑的颜色可能在帧间变化;(ii)新添加的物体可能略微模糊;(iii)去除编辑可能留下残余重影。

4.4 消融研究
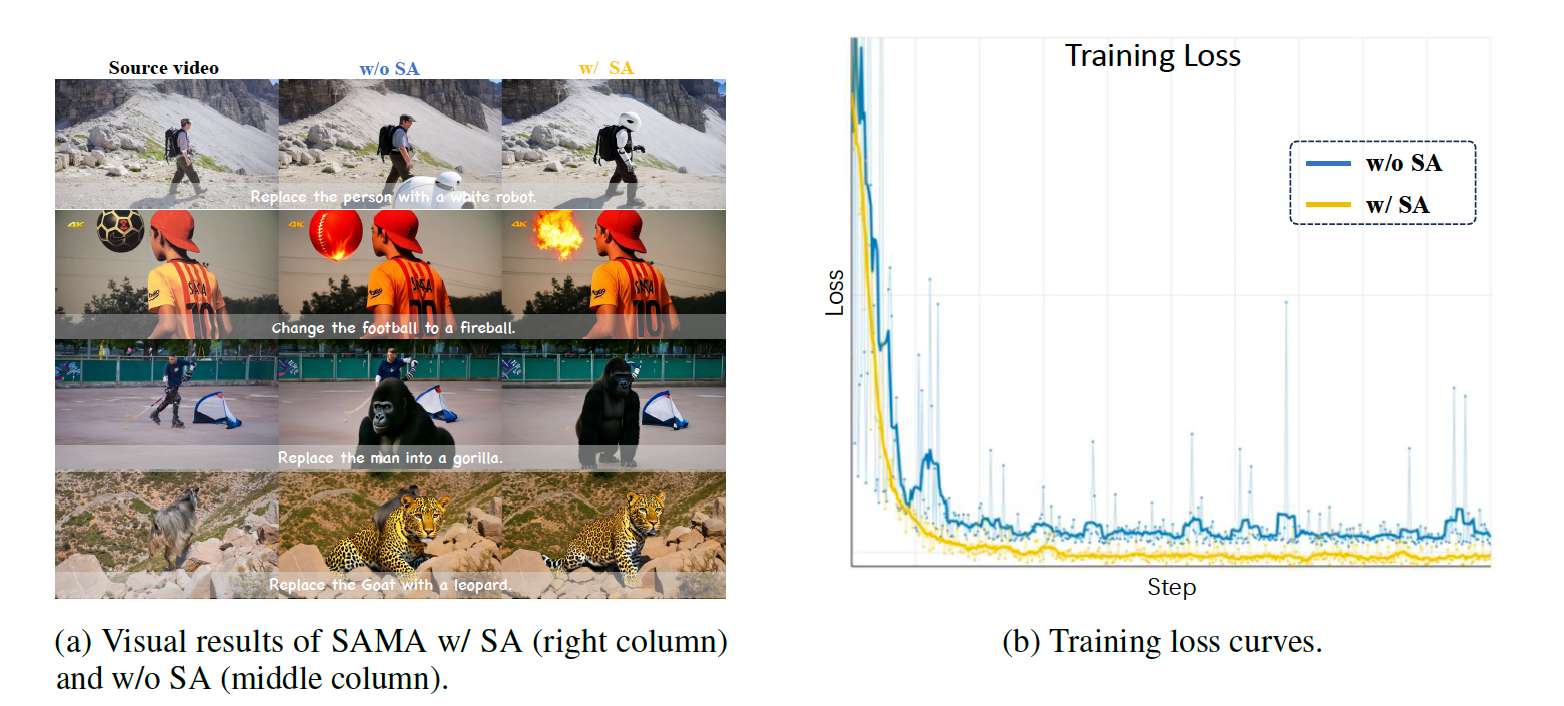
语义锚定。我们首先观察到纳入语义预测目标加速了扩散损失的下降,导致更快的DiT收敛。此外,SA稳定了训练,表现为明显降低的损失方差(见图6b)。我们将基线设为将源潜变量与视频潜变量拼接、不使用SA或MA。我们使用较小的Wan2.2-T2V-5B在Ditto-1M替换子集上以类型嵌入高效训练,并在VIE-Bench替换任务上评估,获得基线结果。在此基线上添加SA在VIE-Bench所有任务上产生一致的平均分提升。
我们进一步在相同训练步数下提供定性比较(图6a)。如图所示,带SA的模型在更早训练阶段产生更高质量的编辑,而不带SA的基线经常产生不完整或不准确的修改。这些结果证实了SA促进了实践中更快的收敛。
表5:SAMA 模块的消融。
| 方法 | 指令遵循 | 保持度 | 质量 | 整体 |
|---|---|---|---|---|
| baseline | 6.575 | 6.261 | 6.100 | 6.312 |
| w/ SA | 7.002 | 6.744 | 6.342 | 6.696 |
| w/ MA | 6.969 | 6.620 | 6.544 | 6.711 |
| SAMA | 7.402 | 6.998 | 6.884 | 7.095 |
运动对齐。我们对MA的效果进行定性分析。我们发现启用MA改善了快速运动下的时序一致性并缓解了运动模糊。代表性定性结果如图7所示。在大幅相机运动的网球案例中,启用MA明显改善了背景清晰度(如更清晰的屏幕文字),而基线出现模糊。在汽车和第三个例子中也观察到类似改进,基线经常丢失背景运动。定量消融结果汇总在表6中。在VIE-Bench上,仅添加MA就比基线整体分提升0.399。当结合SA和MA时,整体分进一步提升0.783,表明两个组件是互补的。

5 结论
我们提出了SAMA,一个用于指令引导视频编辑的分解框架,在DiT中分离语义锚定和运动对齐。语义锚定通过在锚帧处的语义token预测引入显式先验,而运动对齐通过在文生视频数据上的以运动为中心的恢复预训练改善时序连贯性。在VIE-Bench、OpenVE-Bench和ReCo-Bench上的广泛实验证明了其在开源方法中的最先进性能以及对比商业系统的竞争性结果。此外,SAMA展现出强大的零样本编辑行为,表明鲁棒的指令遵循能力可以从学习解耦的语义和运动表示中自然涌现。未来工作将聚焦于长视频编辑、快速运动场景和更强的语义token化,以进一步减少残余伪影和时序不一致。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)