2026年最新全面综述JavisVerse | 一文详解大型基础模型中的视听智能(AVI)
〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生
经典文章回顾:
- 万字综述 | 一文带你入门「具身智能」:从基础概念到大模型赋能
- 万字长文|一文详解具身智能:视觉-语言-动作模型(VLA)系统性综述
- 一文梳理主流大模型推理部署框架:vLLM、SGLang、TensorRT-LLM、ollama、XInference
- 一文梳理主流热门智能体框架:Dify、Coze、n8n、AutoGen、LangChain、CrewAI
- 一文详解AI大模型14个核心基础概念:Transformer、Token、MoE、RAG、对齐、预训练、微调、Agent
写在前面
【从零走向AGI】旨在深入了解通用人工智能(AGI)的发展路径,从最基础的概念起,逐步构建完整的知识体系。项目地址🔗:https://ai-mzq.github.io/From-Zero-to-AGI/
这篇名为 JavisVerse 的综述深入探讨了大型基础模型时代的视听智能(AVI)发展现状。作者群来自新加坡国立大学、牛津大学及微软等顶级机构,系统性地构建了涵盖感知、生成与交互三大维度的技术分类体系。
文中详尽梳理了从模态表征、跨模态对齐到自回归与扩散生成的核心技术演进路径。
《Audio-Visual Intelligence in Large Foundation Models: A Comprehensive Survey》 聚焦的是 视听智能(Audio-Visual Intelligence, AVI)在大基础模型时代的系统化整理。
这里的 JavisVerse 更准确地说不是一个单一模型,而是论文所依托的视听智能研究框架与资源体系,其目标是把分散在音频理解、视频理解、音视频生成、数字人、具身智能、Omni 模型等方向中的方法、任务和评测重新组织到统一坐标系中。
论文主页:https://github.com/JavisVerse/Awesome-AVI
论文面对的核心问题可以概括为:
当前多模态研究已经不再只处理“图文对齐”或“语音识别”这类相对单点的问题,而是转向能够同时看、听、说、生成、编辑和行动的综合系统。音频与视觉之间的关系也不只是共现关系,而涉及时间同步、事件因果、空间传播、主体交互和用户意图。
从研究脉络看,AVI 的复杂性主要来自三点:
- 信号形态差异明显:音频是连续时间波形,视觉是空间或时空结构;二者在采样率、token 密度、语义粒度上并不一致。
- 对齐关系并非天然稳定:声音可以来自画面外,也可能存在延迟、遮挡、混响、混合声源等问题。
- 任务边界正在融合:理解、生成与交互不再是独立模块,例如实时语音视频助手既要识别声音、理解画面,也要生成语音、表情或动作响应。
因此,论文的研究问题并不是提出某个新算法,而是回答一个更基础的问题:在大模型时代,视听智能应如何被定义、分类、训练、评测和推进。
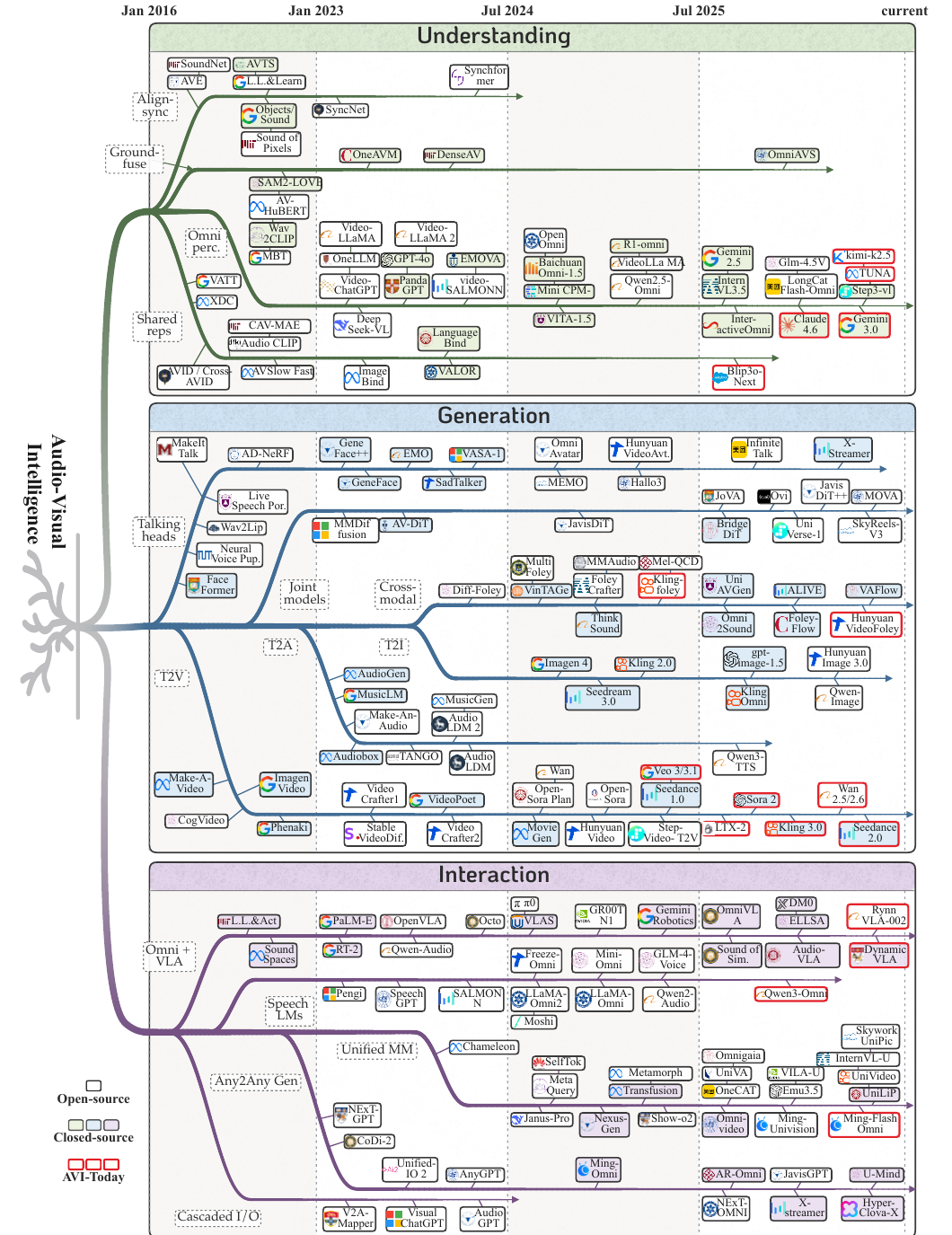
图 1:论文给出的 Audio-Visual Intelligence 演进树,按照理解、生成、交互三条主线梳理了 2016-2026 年间代表性工作。
JavisVerse 的核心定位与目标
JavisVerse 的核心定位可以理解为“面向视听智能基础模型的研究地图”。论文试图将 AVI 从多个相互割裂的子领域中抽象出来,并建立统一的分析框架。
1. 从任务集合转向能力体系
传统音视频研究通常按任务划分,例如:
- 语音识别;
- 声源定位;
- 唇语识别;
- 音视频事件检测;
- 视频配音;
- 音频驱动人脸动画;
- 文生视频或文生音频。
这类划分有助于基准测试,但不足以解释大模型时代的系统能力。论文将这些任务归纳为三类能力:
| 能力层级 | 代表任务 | 核心问题 |
|---|---|---|
| 感知 | AVQA、声源定位、音视频分割、同步检测 | 模型如何从音频与视觉中识别事件、主体与关系 |
| 生成 | V2A、A2V、T2AV、联合编辑 | 模型如何生成语义一致、时间同步的音视频内容 |
| 交互 | Omni 对话、数字人、VLA、具身智能 | 模型如何在动态环境中理解、回应并行动 |
这种组织方式的价值在于,它把 AVI 从“多个任务的列表”提升为“多模态系统能力的演进路径”。
2. 从音视频对应转向因果理解
论文反复强调一个关键判断:音频和视觉不是简单的配对样本,而是动态世界的两种观测。一个玻璃杯落地的声音,不只是和某几帧画面相似,而是由物体、动作、材质、空间和传播路径共同决定。
这意味着未来 AVI 模型不能只学习“声音和画面是否匹配”,还需要推断:
- 声音由哪个物体或事件产生;
- 声源是否在画面内;
- 声音与视觉动作之间是否存在合理延迟;
- 空间结构、材质和遮挡如何影响声音;
- 编辑某个视觉对象后,对应声音是否需要同步改变。
这也是论文将未来方向概括为“causal, contextual, controllable, verifiable, interactive”的原因。
整体技术框架解析
论文的整体结构比较清晰,可以拆成四层。
第一层:模态表示
论文首先回到音频和视觉的基础表示。音频通常从 waveform、spectrogram、codec token 或语义 token 进入模型;视觉则包括图像、视频帧、视觉 patch、离散视觉 token 或 latent 表示。
这一层解决的是“如何把物理信号变成模型可处理的表示”。
| 模态 | 原始形态 | 常见表示 | 典型方法 |
|---|---|---|---|
| 音频 | waveform | spectrogram、codec token、HuBERT/BEATs 表征 | SoundStream、EnCodec、Whisper、BEATs |
| 图像/视频 | pixels / frames | patch token、VQ token、latent feature | CLIP、SigLIP、VQGAN、MAGVIT |
| 音视频联合 | paired clips | shared embedding、interleaved token、joint latent | CAV-MAE、ImageBind、DenseAV |
这里的关键不是单纯“编码”,而是压缩与保真之间的平衡。音频和视频都有高时间密度,如果直接输入大模型,会带来极高 token 成本。因此,tokenizer 和压缩策略实际上决定了 AVI 系统能否处理长视频、实时音频和多轮交互。
第二层:基础建模技术
论文将基础方法分为三类:
- Representation-centric Methods:以表征学习为核心,例如自监督学习、对比学习、跨模态对齐、VAE、离散 tokenization。
- Generation-centric Methods:以生成机制为核心,包括 GAN、diffusion、autoregressive generation、masked autoregressive generation。
- LLM-centric Methods:以大语言模型为推理与调度核心,包括 Encoder+LLM、LLM+Generator、统一感知生成模型、Agentic 系统和 VLA。
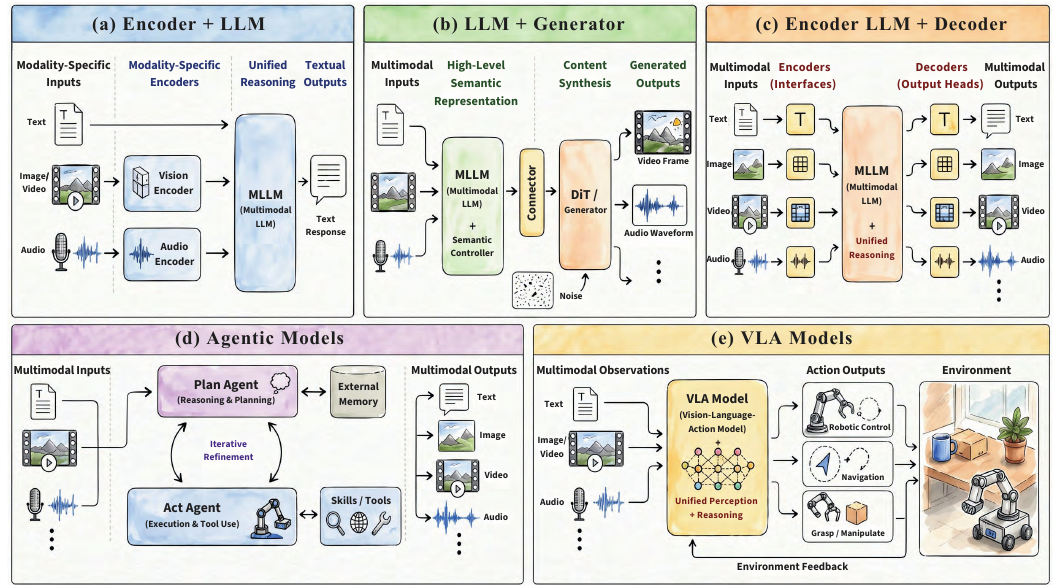
图 2:论文对 Encoder+LLM、LLM+Generator、统一感知生成模型、Agentic Model 与 VLA Model 的机制对比。
这一分类比较重要,因为它避免了把所有多模态模型都简单归为“MLLM”。在 AVI 中,LLM 可能承担不同角色:
| 架构类型 | LLM 的角色 | 优点 | 主要问题 |
|---|---|---|---|
| Encoder + LLM | 多模态理解与推理 | 模块化强,便于复用视觉/音频编码器 | 细粒度对齐不足,长音视频 token 成本高 |
| LLM + Generator | 意图解析与工具调度 | 易接入现有生成器,工程扩展灵活 | 级联误差、同步不稳定 |
| Unified Model | 原生感知与生成 | 对齐更紧密,交互延迟可能更低 | 训练复杂,tokenizer 与数据规模要求高 |
| Agentic System | 任务规划、工具调用、状态管理 | 适合复杂创作和长流程任务 | 工具 grounding、状态一致性和错误传播难处理 |
| VLA | 感知-推理-行动闭环 | 面向机器人与具身场景 | 数据采集、跨实体泛化和安全控制困难 |
第三层:任务主线
论文用三大主线组织 AVI 任务:
- 感知:从像素/样本级感知,到内容理解,再到逻辑推理;
- 生成:从单模态条件生成,到跨模态生成,再到联合音视频生成;
- 交互:从语音/视觉对话,到数字人,再到具身智能和 VLA。
这种分层体现了一个清晰趋势:AVI 正在从“识别已发生的事件”转向“生成可控事件”,再转向“在交互中持续理解与行动”。
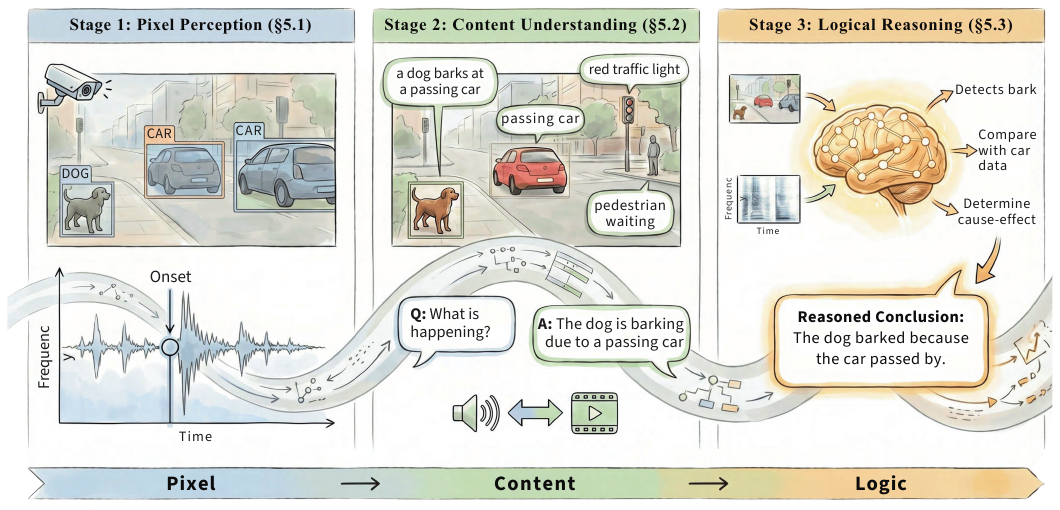
图 3:论文将视听感知组织为像素/样本级感知、内容理解和逻辑推理三个阶段。
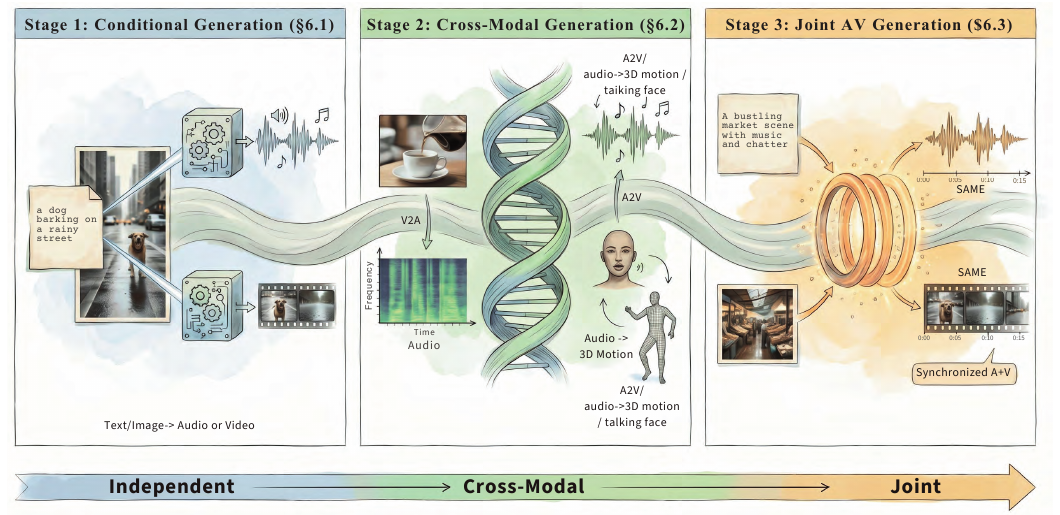
图 4:论文将视听生成划分为条件生成、跨模态生成和联合音视频生成,体现从独立生成到紧耦合同步生成的过渡。
第四层:未来研究轴
论文在最后提出六个未来方向:
| 方向 | 当前常见假设 | 更深层目标 |
|---|---|---|
| 时间同步 | 判断音画是否对齐 | 建模事件源、传播路径与因果关系 |
| 世界模型 | 音视频是成对 clip | 建模几何、材质、动力学、空间声学 |
| 上下文记忆 | 增加上下文窗口即可 | 构建分层、可追溯的音视频记忆 |
| 因果编辑 | prompt 描述目标内容 | 对对象、声音、身份、空间进行局部干预 |
| 验证与奖励 | 用 FID/FVD/SyncNet 近似质量 | 构建多层 verifier 与 reward 体系 |
| 负责任交互 | Omni 模型可直接部署 | 平衡实时性、隐私、同意、溯源与安全 |
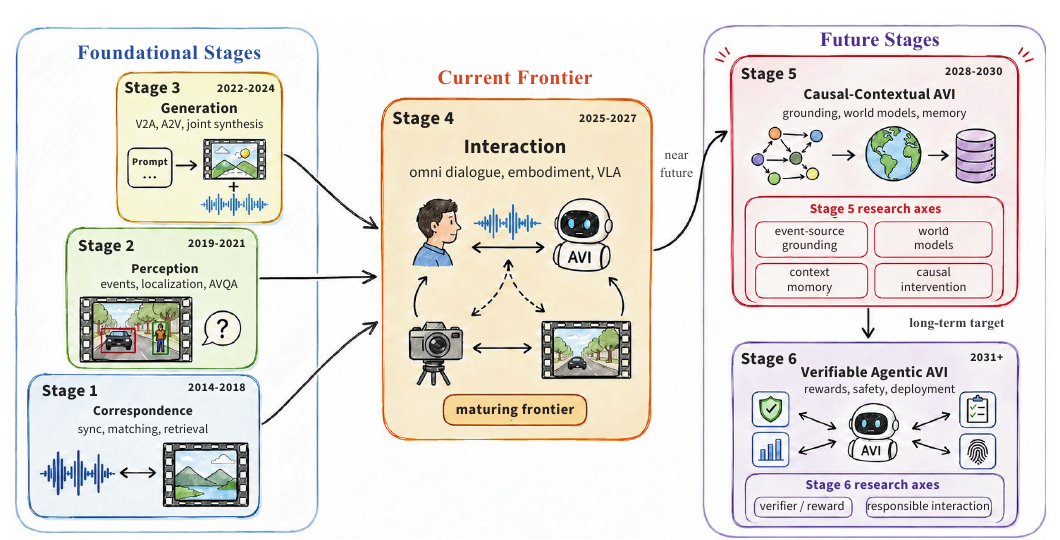
图 5:论文提出的 AVI 发展路线图:当前前沿集中在交互式 Omni 与具身系统,后续阶段强调因果上下文建模与可验证的 Agentic AVI。
这一部分是论文中最有研究判断的内容。它把 AVI 的未来从“更大模型、更大数据”转向“更强结构、更可靠验证、更可控交互”。
数据、模型与训练体系分析
虽然论文是综述,不是 JavisVerse 单一模型的训练报告,但它对数据、模型和训练体系给出了相对完整的归纳。
1. 数据:从配对数据到结构化、长时程、多任务数据
早期 AVI 依赖大量音视频配对数据,例如 AudioSet、VGGSound、AVE、LRS 系列。这类数据适合学习“声音与画面是否相关”,但对因果、空间和交互能力支持有限。
论文中提到的数据类型可以概括为:
| 数据类型 | 代表数据集/基准 | 支持能力 |
|---|---|---|
| 开放域音视频 clip | AudioSet、VGGSound | 通用音视频对应与预训练 |
| 事件定位数据 | AVE、LLP、UnAV-100 | 时间边界、事件 grounding |
| 音视频分割数据 | AVSBench、AVSBench-Semantic、OmniAVS | 声源区域定位 |
| 问答与推理数据 | AVQA、MUSIC-AVQA、Daily-Omni、OmniVideoBench | 跨模态理解与推理 |
| 生成评测集 | JavisBench、Verse-Bench、T2AV-Compass、PhyAVBench | 联合音视频生成质量评估 |
| 具身数据 | SoundSpaces、OpenVLA 相关数据 | 视听导航、机器人交互 |
可以看到,数据正在从“短 clip 分类”转向“长视频、开放问答、音频不可替代性、因果一致性和物理合理性”。
2. 模型:模块化路线与统一路线并行
论文没有简单判断哪种路线一定更优,而是呈现了两条并行路径:
- 模块化路线:用独立音频编码器、视觉编码器、LLM、扩散生成器、工具系统组合出 AVI 能力;
- 统一路线:用统一 token 空间或统一 backbone 同时支持理解、生成和交互。
模块化路线的工程优势明显。比如 Visual ChatGPT、AudioGPT、NExT-GPT 等系统可以快速接入不同工具。但其缺点也清楚:音频生成器和视频生成器可能各自合理,却在时间同步、事件对应和用户意图上产生偏差。
统一路线更接近 GPT-4o、Qwen2.5-Omni、Qwen3-Omni、Moshi、JavisDiT、Ovi、UniVerse-1 这类系统方向。它们试图让模型原生处理多模态输入输出,减少级联误差。但统一路线对 tokenization、训练稳定性、数据配比和推理成本要求更高。
3. 训练:从自监督对齐到指令对齐与偏好优化
论文归纳的训练体系大致包括四个阶段:
- 自监督/对比预训练
利用音画自然同步作为监督信号,学习 shared embedding 或跨模态对应关系。典型方法包括 AVTS、CAV-MAE、ImageBind、LanguageBind 等。 - 生成式预训练
通过 diffusion、autoregressive 或 masked autoregressive 目标学习音频、视频或联合 token 的生成分布。 - 指令微调
将音视频理解、问答、编辑和生成转化为指令跟随任务,使模型能够响应自然语言控制。 - 偏好优化与强化学习式后训练
用 DPO、GRPO、process-level preference optimization 等方式改进主观质量、同步性、推理过程和可控性。
这一训练路径与文本大模型的发展有明显对应关系,但 AVI 的难点更高:文本 token 本身是离散语义单位,而音频和视频 token 同时承载语义、时间、空间和感知质量。训练目标一旦设计不当,模型可能在某个维度提升,同时损害另一个维度。例如优化 lip-sync 指标可能改善口型同步,但不一定改善情绪、韵律或非语音声源的合理性。
关键创新点总结
论文的创新不在单个模型结构,而在系统性归纳与问题重构。
1. 提出大模型时代的 AVI 统一分类
论文将 AVI 组织为感知、生成、交互三大方向,并进一步细化到像素感知、内容理解、逻辑推理、跨模态生成、联合生成、Omni 对话、具身交互等层级。这种分类有利于减少不同社区之间的术语差异。
2. 强调音视频关系的因果属性
论文没有停留在“跨模态对齐”这一常见表述,而是进一步指出:真正的 AVI 需要解释事件源、传播路径、空间结构和不确定性。这一判断对后续研究很关键,因为它意味着单纯扩大 paired clips 数据并不能自动解决视听智能问题。
3. 将 verifier 和 reward ecosystem 提到核心位置
音视频生成的评估长期依赖 FID、FVD、CLIP similarity、SyncNet 等指标。但这些指标只能覆盖局部质量,无法判断声源是否正确、物理关系是否合理、长时程是否一致。论文提出分层 verifier 思路,将信号质量、时间同步、源定位、物理因果、任务效用、安全溯源纳入统一评估框架。
4. 把交互视为 AVI 的严格测试场景
静态理解和离线生成可以回避延迟、打断、记忆、隐私和状态管理问题。但真实交互场景无法回避这些约束。因此,论文认为 Omni 对话、数字人和 VLA 不是 AVI 的附属应用,而是检验视听智能是否成熟的重要场景。
与现有多模态/视听智能工作的对比
与图文多模态模型相比
以 CLIP、BLIP-2、LLaVA、Qwen-VL、InternVL 为代表的图文模型主要解决视觉与语言对齐问题。它们通常关注图像或视频帧中的语义内容,而音频的时间连续性、声源混合和空间传播并不是核心建模对象。
AVI 相比图文多模态多了几个约束:
- 音频与视频必须在时间轴上精确对应;
- 声音可以来自画面外;
- 多个声源可能同时存在;
- 视觉事件与声音之间可能有因果延迟;
- 生成任务需要同时保证视觉质量、音频质量和跨模态一致性。
因此,把视觉语言模型简单扩展一个音频 encoder,并不等价于解决 AVI。
与视频理解模型相比
Video-LLaMA、Video-ChatGPT、LongVA、LongVU 等模型主要处理视频帧序列和语言之间的关系。它们对长时程视觉理解有帮助,但在音频不可替代的问题上存在不足。
例如,一个视频问题可能需要听到警报声、脚步声、撞击声或语气变化才能回答。只看视频帧,即使画面语义完整,也可能得出错误结论。论文提到的 AVQA、Daily-Omni、OmniVideoBench 等基准,正是在推动模型从“视觉主导”转向真正的音视频联合推理。
与音频语言模型相比
Pengi、SALMONN、Qwen-Audio、Audio Flamingo 等音频语言模型提高了音频理解与推理能力,但它们通常缺少视觉 grounding。对于“哪个物体发出了声音”“声音来自画面内还是画面外”“这个动作是否与声音同步”等问题,单独音频模型无法充分回答。
AVI 的核心在于把音频事件绑定到视觉对象、空间位置和时间轨迹上。
与生成模型相比
Sora、Veo、MovieGen、Wan、Kling、JavisDiT、Ovi、UniVerse-1 等系统代表了音视频生成方向的快速发展。论文对这些工作的分析比较克制:它承认工业系统在数据规模、基础生成器和后训练上领先,同时也指出开放研究已经在联合建模、同步机制和评测体系上形成较清晰路径。
关键差异在于:
| 方向 | 主要目标 | AVI 视角下的不足 |
|---|---|---|
| 文生视频 | 生成高质量视觉动态 | 声音常作为后处理,音画因果不足 |
| 视频配音 V2A | 为视频生成声音 | 容易生成语义合理但事件不精确的声音 |
| 音频驱动视频 A2V | 用声音驱动画面 | 同一音频对应多个可能视觉结果,可控性不足 |
| 联合 T2AV | 同时生成音频和视频 | 训练成本高,评测困难,长时程一致性仍不足 |
| 联合编辑 | 同步编辑音画 | 局部性、因果影响范围和副作用控制困难 |
工程实现与潜在难点
如果从工程系统角度实现 JavisVerse 所描述的 AVI 能力,难点并不只是模型规模。
1. Token 成本与流式处理
音频和视频都是高频信号。长视频输入、实时语音输入、多轮对话记忆叠加后,token 成本会迅速上升。工程上必须处理:
- 音频 token 降采样;
- 视频帧选择与压缩;
- 关键事件缓存;
- 流式 chunk 编码;
- 跨模态时间戳对齐;
- 低延迟解码。
这意味着 AVI 系统不能只依赖“大上下文窗口”,还需要分层记忆与事件级索引。
2. 音画同步不是后处理问题
很多级联系统先生成视频,再生成音频,或者先解析音频,再驱动画面。这种方式实现简单,但容易出现同步漂移。真正可靠的系统需要在中间层显式表示事件、节奏、onset、动作轨迹和声源绑定。
例如 V2A 任务中,模型不能只知道“画面里有狗”,还要知道狗何时张嘴、是否真的在叫、声音是否应被遮挡或混响影响。
3. 统一模型训练不稳定
统一 AVI 模型通常需要同时处理文本、音频、图像、视频以及可能的动作 token。不同模态的数据规模、质量、损失函数和收敛速度并不一致,容易出现模态偏置。例如模型可能过度依赖视觉线索,忽略音频证据;或者在生成中优先优化画面质量,牺牲音频同步。
这要求训练体系在数据配比、loss 权重、curriculum、post-training reward 上进行细致设计。
4. 评测指标难以覆盖真实质量
单个指标无法覆盖 AVI 的完整质量。一个生成视频可能 FVD 很好,音频 FD 也不错,但声源错误、节奏错位或物理因果不成立。工程部署需要组合多种 verifier:
- 音频质量 verifier;
- 视频质量 verifier;
- 音画同步 verifier;
- 声源 grounding verifier;
- 指令一致性 verifier;
- 安全与身份风险 verifier。
这类评估系统本身可能会成为 AVI 基础设施的一部分。
行业价值与应用场景
论文列举了多个应用方向,其共同点是音频与视觉都不是附属信息,而是共同构成任务状态。
1. AIGC 与内容生产
视听联合生成可用于短视频、影视预演、广告素材、游戏 cutscene、音乐视频和自动 Foley。相比单独视频生成,AVI 的价值在于减少后期配音、音效设计和同步调整成本。
但真正可用的系统必须支持局部编辑。例如只替换某个物体的声音、只调整背景环境声、只修改人物情绪而保持身份和口型一致。
2. 数字人与社交交互
数字人系统需要同时处理语音、表情、口型、头部姿态、手势和对话语义。单纯 lip-sync 已不足够,未来系统需要建模说话人的情绪、语速、停顿、语境和交互角色。
这也是音频驱动 2D/3D avatar、talking head、full-body avatar 方向持续发展的原因。
3. 人本智能服务
教育、会议助手、无障碍辅助、医疗陪护等场景都需要同时理解“说了什么”和“发生了什么”。例如课堂场景中,模型需要识别教师语言、板书内容、学生反应和环境声音;会议场景中,模型需要处理说话人识别、屏幕内容、语气变化和上下文记忆。
4. 沉浸式体验与 XR
XR 场景对空间音频、视觉几何和交互延迟要求高。一个声音是否来自正确方向、是否被墙体遮挡、是否随用户移动发生变化,会直接影响沉浸感。这里 AVI 与 3D 场景理解、神经渲染、空间声学和世界模型高度相关。
5. 具身智能与机器人
机器人不仅要“看见”物体,也要“听见”接触、碰撞、滑动、故障和人类指令。音频可以补充视觉盲区,尤其在遮挡、暗光、接触反馈和异常检测中具有价值。AVI 对 VLA 模型的意义在于,让机器人从视觉语言动作模型进一步走向视听语言动作模型。
6. 安防、工业与 IoT
工业设备异常常先表现为声音变化,视觉缺陷也可能与机械噪声同步出现。音视频联合监测可以提高异常检测、事故定位和证据分析的可靠性。但这类场景也对隐私保护、边缘计算和数据最小化提出更高要求。
当前局限性与未来发展方向
1. 当前模型仍偏相关性学习
大量 AVI 方法仍依赖音视频共现数据。模型知道“吉他画面常对应吉他声”,但未必理解声音由哪根弦、哪个动作、哪个空间位置产生。论文提出的 event-source grounding 正是针对这一问题。
未来需要更多反事实数据与干预式训练,例如:
- 可见但静音的物体;
- 画面外声源;
- 延迟或错位事件;
- 材质与声音不匹配;
- 多声源混合场景。
2. 长时程视听记忆不足
长视频理解不能简单等同于塞入更多帧和音频 token。模型需要知道哪些声音短暂但关键,哪些画面冗余可压缩,哪些事件需要长期记忆。未来 AVI 系统可能采用分层记忆:
- 原始片段缓存;
- 事件级 memory;
- 语义摘要;
- 声源轨迹;
- 用户意图和任务状态。
3. 联合生成仍受数据规模制约
论文对 T2AV 方向的判断比较务实:开放模型已经探索出联合生成的大致范式,但与前沿商业系统相比,差距主要来自数据规模、基础模型成熟度和后训练深度,而不是单一结构技巧。
4. 评估体系仍不成熟
当前评测仍存在碎片化问题。不同任务使用不同指标,生成任务更依赖主观评估。未来需要更统一的评测协议,尤其是:
- 音频是否必要;
- 声源是否正确;
- 音画是否因果一致;
- 长时程是否保持稳定;
- 编辑是否只影响目标区域;
- 是否存在身份、隐私和版权风险。
5. 交互式 AVI 的安全问题更复杂
实时视听系统会接触语音、面部、环境、位置和行为习惯。相比静态文本模型,它的隐私边界更敏感。未来系统需要在架构层面考虑:
- 本地处理;
- 数据脱敏;
- 用户可控记忆;
- 合成内容水印;
- 声音与人脸授权;
- 对拟人化交互的约束。
总结与评价
《Audio-Visual Intelligence in Large Foundation Models》是一篇偏研究框架型的综述。它的价值不在于提出一个新的网络结构,而在于把视听智能从多个分散方向中重新整理出来,并指出大模型时代 AVI 的核心问题已经从“音视频是否匹配”转向“模型是否理解事件、因果、空间、记忆、控制和交互”。
从技术判断看,论文最值得关注的观点有三点。
第一,AVI 不能被简化为“视觉模型加音频编码器”。音频与视觉之间存在时间、空间和因果关系,尤其在生成、编辑和具身场景中,这些关系会直接决定系统是否可靠。
第二,未来 AVI 的竞争重点不只是模型参数规模,而是数据结构、tokenization、长时程记忆、verifier、reward 和可控编辑能力。单纯扩大 paired clips 只能改善共现建模,难以自动获得因果理解。
第三,交互式系统会成为 AVI 的主要检验场。离线任务可以掩盖同步、延迟、状态管理和安全问题,而实时对话、数字人和机器人会把这些问题全部暴露出来。
整体而言,JavisVerse 提供的是一套较完整的视听智能研究坐标。它既覆盖了当前多模态大模型、视频生成、音频生成和 Omni 模型的主流进展,也对未来研究提出了更具结构性的判断:真正成熟的 AVI 系统,需要能够解释视听证据、预测行动后果、保持可追溯记忆、执行局部因果编辑,并在可验证和负责任的条件下与人交互。
推荐阅读
► 技术资讯: 魔方 AI 新视界
► 项目应用:开源视界
► 技术专栏: 多模态大模型最新技术解读专栏 | AI 视频最新技术解读专栏 | 大模型基础入门系列专栏 | 视频内容理解技术专栏 | 从零走向 AGI 系列

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)