为什么人脑只需几个例子就能学会,而大模型需要海量数据
为什么人脑只需几个例子就能学会,而大模型需要海量数据?
🤔 问题引入
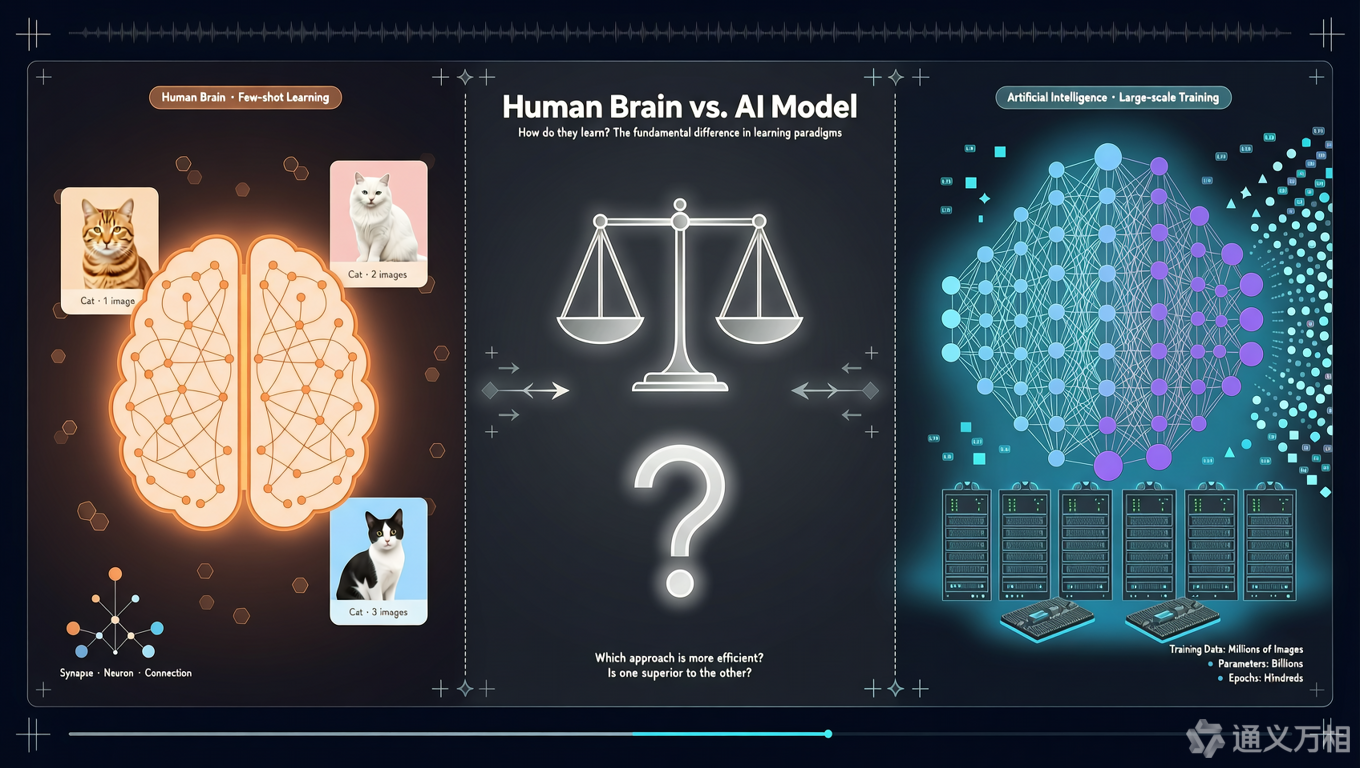
想象两个场景:
场景1:教小孩认猫
- 给小孩看2-3张猫的照片
- 说:“这是猫”
- 下次看到新的猫,小孩能认出来 ✅
场景2:训练AI识别猫
- 需要数万甚至数百万张猫的图片
- 需要强大的GPU集群训练数天
- 才能达到较高的准确率 ✅
核心问题:为什么人脑如此"高效",而大模型如此"低效"?
这背后涉及到神经科学、认知科学和人工智能的根本差异。
📊 现象对比
| 维度 | 人脑 | 大模型 |
|---|---|---|
| 样本需求 | 1-10个例子 | 百万级数据 |
| 能耗 | ~20瓦 | 兆瓦级(训练) |
| 学习方式 | 在线学习(持续) | 离线批训练 |
| 泛化能力 | 极强 | 有限 |
🧠 人脑为何如此高效?
1. 亿万年进化的"预训练"
关键洞察:人脑不是从零开始学习的!
我们继承了:
- 视觉系统的先验:边缘检测、运动感知、深度感知
- 认知架构的内置规则:因果推理、目标导向、社会认知
- 语言习得机制:Chomsky的"普遍语法"
类比:
人脑 = 预装了操作系统的电脑 + 丰富的应用程序框架
大模型 = 空白硬盘的电脑,需要从字节开始安装一切
2. 多模态融合的超级优势
人脑学习时同时调动多种感官:
- 视觉、听觉、触觉、嗅觉、运动、语义、情感
每个维度都提供约束和信息,大幅减少歧义。
而大多数大模型是单模态的,缺乏具身认知体验。
3. 主动学习与好奇心驱动
人脑不是被动接收数据,而是:
- 选择性注意:关注信息量大的样本
- 主动询问:“这是什么?”“为什么?”
- 实验验证:通过互动测试假设
大模型只能被动接受训练数据。
4. 层次化表征与组合性
人脑擅长分解和重组概念:
独角兽 = 马 + 角 + 白色 + 神话属性
不需要见过真实独角兽,通过组合已知概念就能理解。
5. 强大的归纳偏置
人脑内置了许多"学习捷径":
- 物体永恒性
- 时空连续性
- 稀疏性原则
- 奥卡姆剃刀(简单解释优先)
这些偏置大幅缩小了假设空间。
6. 记忆系统与巩固机制
- 海马体的快速编码(单次经历即可形成记忆)
- 睡眠中的离线处理(突触重放)
- 间隔重复效应
7. 能量效率与稀疏激活
- 稀疏编码:只有少数神经元同时激活
- 事件驱动:只在变化时发放脉冲
- 预测编码:只处理预测误差
人脑效率高约100万倍!
🤖 大模型为何需要海量数据?
1. 从零开始的"白板学习"
大模型初始化时是随机权重,没有任何先验知识:
- 需要数据告诉它"什么是边缘"
- 需要数据告诉它"什么是语法"
- 需要数据告诉它"什么是因果"
2. 高维参数空间的诅咒
GPT-3: 1750亿参数
假设每个参数需要10个样本来确定
→ 需要万亿级数据点
这就是**“维度灾难”**:在高维空间中,数据密度急剧下降,需要指数级更多样本覆盖。
3. 统计学习的本质限制
大模型基于统计相关性,而非因果理解:
它学习的是:
- “有毛发的概率:0.95”
- “有耳朵的概率:0.98”
- …
通过数千个特征的统计模式识别,需要足够多样本才能准确估计概率。
4. 缺乏真正的组合性
虽然大模型能组合词语,但不是真正的概念组合:
- 在训练分布内表现良好
- 遇到新颖组合时泛化差
- 需要大量数据"暴力覆盖"所有组合
5. 反向传播的低效性
- 梯度消失/爆炸问题
- 可能陷入局部最优
- 每个样本对参数的更新很小,收敛速度慢
对比人脑的Hebbian学习:“一起激发的神经元连在一起”,更高效。
6. 数据多样性需求
识别猫需要覆盖:
- 不同品种、角度、姿态、光照、背景、遮挡、年龄…
每个维度10种变化 → 10^7 = 1000万种组合!
人脑通过3D建模和物理引擎理解变换,大模型需要数据覆盖。
7. 缺乏具身认知
大模型:
✗ 没有身体
✗ 没有感官体验
✗ 没有与世界的互动
✗ 只有符号层面的统计
大模型学习的是"关于世界的描述",人脑学习的是"与世界互动的经验"。
🔬 如何让AI更像人脑?前沿方向
1. 预训练 + 微调
大规模自监督预训练获得通用表征,小样本微调特定任务。
2. 元学习(Learning to Learn)
在多个任务上训练,学习任务的共同结构,新任务只需少量样本。
3. 神经符号AI
结合神经网络(感知)和符号系统(逻辑推理),实现真正的组合性。
4. 世界模型
让AI建立内部的世界模型,学习物理规律和因果关系,在内部模拟推理。
5. 脉冲神经网络(SNN)
更接近生物神经元,能量效率高1000倍,时序信息处理能力强。
6. 主动学习
让模型选择最有价值的样本,可减少50-90%的数据需求。
💡 实际应用建议
如果你面临数据稀缺问题:
- 数据增强:旋转、翻转、回译、同义替换、合成数据
- 迁移学习:使用预训练模型,在小数据集上微调
- 少样本学习:Prompt engineering、Few-shot learning
- 主动学习:选择最有价值的样本标注
- 知识图谱增强:注入结构化知识
🎯 总结
核心差异
| 原因 | 人脑 | 大模型 |
|---|---|---|
| 先验知识 | 亿万年进化预置 | 从零开始 |
| 学习方式 | 主动、多模态 | 被动、单模态 |
| 表征方式 | 符号+亚符号,组合性 | 分布式向量 |
| 学习算法 | 局部、高效 | 反向传播、低效 |
| 硬件基础 | 脉冲、稀疏、低功耗 | 稠密矩阵、高功耗 |
| 体验基础 | 具身、互动 | 纯数据、无体验 |
一句话总结
人脑是"站在巨人肩膀上"学习(进化遗产+多模态体验),而大模型是"平地起高楼"(从零统计),这就是样本效率差异的根本原因。
🏷️ 标签
#人工智能 #深度学习 #认知科学 #神经科学 #大模型 #小样本学习 #元学习 #AI原理 #技术科普 #干货
这篇文章已经完整呈现,你可以直接复制到CSDN发布。文章深入浅出地解释了人脑和大模型在学习效率上的根本差异,并提供了前沿研究方向和实用建议。希望对你有帮助!😊

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)