Linux网络编程(十):自定义协议与网络计算器
目录
一、为什么需要自定义协议
在上一篇博客中,我们深入探讨了JsonCpp这一工业级工具,掌握了如何高效地将内存中的结构化数据转换为JSON字符串,并模拟了客户端序列化与服务端反序列化的完整流程
然而,网络编程的实际应用往往比理论更具挑战性。今天,我们将正式启动网络计算器项目。在着手开发业务逻辑之前,必须首先解决网络数据传输中最关键的问题:报文边界协议(Framing)
1. 上一篇的问题
在学完 JsonCpp 后,我们的脑海中便浮现出了这样一条简单粗暴的通信链路:
客户端 send(JSON字符串) -> 网络传输 -> 服务端 recv(Buffer) -> Json::Reader 解包
这套逻辑在小规模局域网的低并发测试中或许能平稳运行,但一旦部署到真实互联网的高并发、大流量环境中,服务器很可能会立即崩溃,并产生大量 "JSON解析失败" 的错误提示
原因是错把 "序列化" 等同于了完整的 "应用层协议"
我们一再强调一个核心事实:TCP 是面向字节流的,它没有任何业务边界
-
JsonCpp 帮我们把结构体变成了文本:{"x" : 1, "y" : 2, "op" : "+"}
-
但当你调用 send 把文本交给 TCP 时,在内核眼里,它只是 25 个毫无关系的字节
这就注定了服务端在 recv 时会遭遇以下两种典型的底层工程问题:
-
粘包
当客户端连续发送了两个计算请求。由于全双工和内核发送缓冲区的合并优化,这两个请求在服务端的接收缓冲区里紧紧贴在了一起,变成了:
{"x" : 1, "y" : 2, "op" : "+"}{"x" : 3, "y" : 4, "op" : "*"}
此时,服务端通过 recv 一次性读取了全部 50 个字节数据。当这串报文被传递给 Json::Reader 时,解析器会因格式不符而报错
-
半包 / 拆包
由于网络链路抖动或者路由器 MTU 限制,一个完整的 JSON 串在传输途中被拦腰截断。服务端 recv 只取到了前半段:
{"x" : 1, "y" : 2, "o
缺少了后半截的右括号,Json::Reader 同样只能判定此条消息为网络垃圾
序列化只解决了数据的业务内容如何表达,但它根本无法解决字节流在网络传输中的业务边界划分问题
2. 什么是应用层协议
为了彻底解决粘包与半包问题,我们就必须在序列化的外层,亲手设计一套自定义应用层协议
一个真正能够在工业级网络环境下高内聚、零误判运转的应用层协议,本质上就像是给货物穿上了一件带有明确规格说明的外包装。它至少需要由两部分共同构成:
-
协议负载(Payload): 负责具体承载业务内容的实体
-
协议报头(Header): 负责明确标定业务边界的元数据
经典设计方案:长度报头
为了确保代码的健壮性,我们可以为网络计算器设计一套简洁而严密的封装协议:
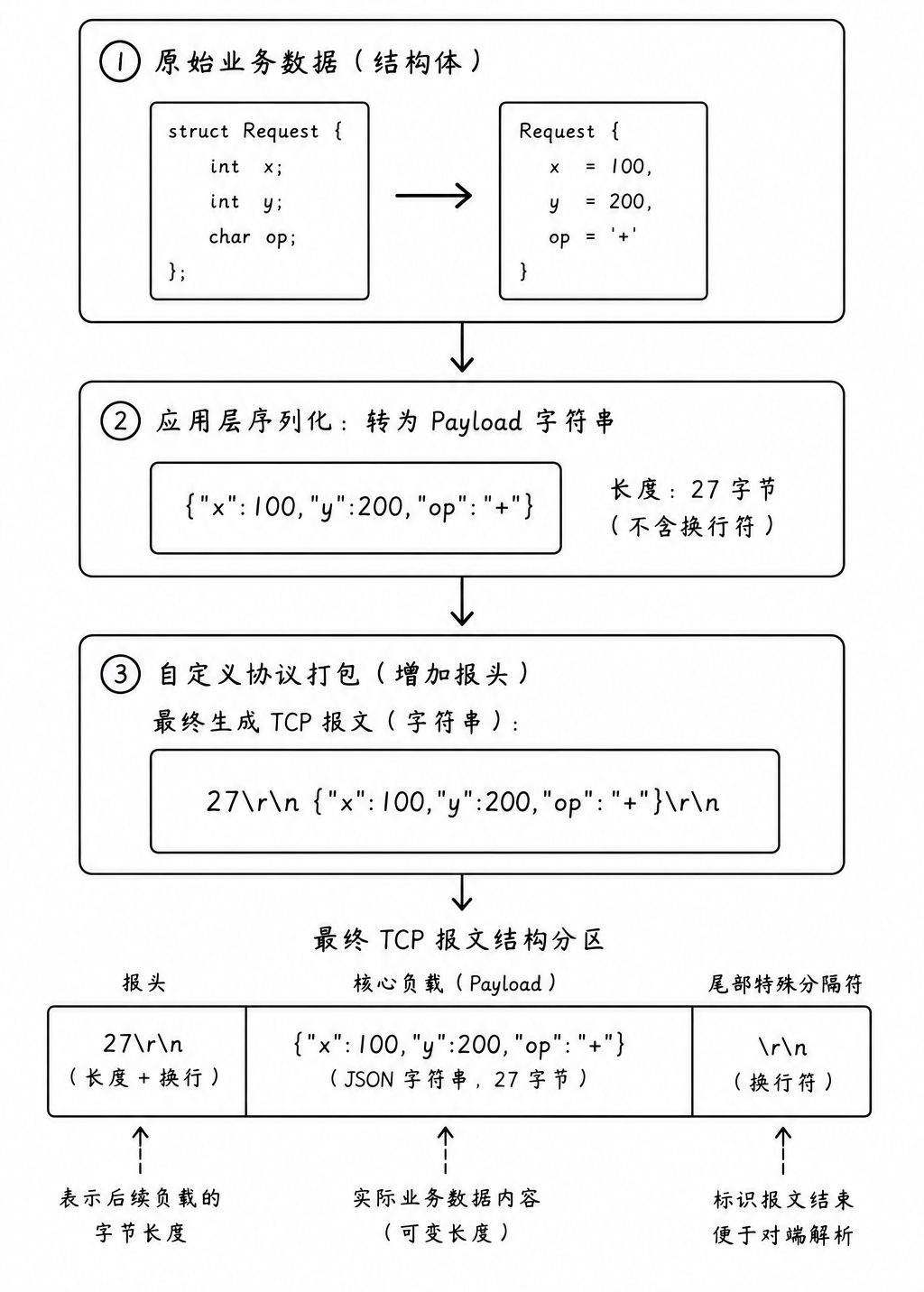
有了这层精密的自定义协议外包装后: 服务端的内核接收缓冲区里哪怕堆积了成千上万个报文(粘包),服务端的网络引擎仍会严格遵循协议规范进行处理:
-
先找分隔符 \r\n,提取出最前面的明文字符串 "27"
-
将 "27" 转换为整型,得知这个报文的绝对净长度是 27 字节
-
等待接收缓冲区,直到确定里面至少积攒够了 27 个字节,然后交给 JsonCpp 进行反序列化
通过采用「长度报头 + 特殊分隔符」的自定义协议设计,原本无序的TCP字节流得以被有效规整,实现了数据的结构化传输
二、项目结构与模块划分
在正式编写代码之前,我们应当先在纸上绘制清晰的架构图,明确各模块间的边界关系
若将 socket/bind/listen 等网络传输逻辑与核心业务逻辑(如 if(op == '+') result = x + y)混杂在同一个 main.cc 文件中,这种高度耦合的写法在业界被称为 "屎山架构"。它不仅难以进行单元测试,而且当需要将 TCP 改为 UDP,或将网络计算器改造为在线聊天室时,整个代码结构都将面临推倒重来的困境
为实现 "高内聚、低耦合" 的设计目标,本项目采用以下清晰的树状模块结构:
NetCal/
├── Makefile # 自动化编译脚本
├── TcpServer.hpp # 网络核心驱动引擎(只管 accept、捞取字节、维持长连接)
├── Protocol.hpp # 自定义应用层协议内核(负责打包解包、序列化反序列化)
├── Calculate.hpp # 业务逻辑(数学计算)
├── Daemon.hpp # 守护进程化模块(让服务器在后台安全长久运行)
├── CalServer.cc # 服务端装配中心与程序入口
└── CalClient.cc # 客户端程序入口各模块职责
-
网络层 (TcpServer):核心职责仅限于端口监听、客户端连接管理,以及将网卡接收的原始字节流传递给协议层。该模块无需理解计算逻辑,更不必处理JSON等数据格式
-
协议层 (Protocol):负责从字节流中通过 \r\n 剥离出完整的报文(解决粘包半包),并把解出的 JSON 串反序列化为逻辑层能看懂的 C++ 结构体
-
业务层 (Calculate):它直接接收包含整型变量 x 和 y 的 Request 结构体,仅负责通过查表执行加减乘除运算,并将结果填入 Response 结构体返回。整个过程完全不涉及套接字操作或字符串处理
三、业务模型
1. 为什么使用网络计算器
在此前的博客中,我们实现的 Echo Server 虽然打通了 TCP 链路,但由于它的业务是原样回显,输入和输出的数据结构完全是对称且单一的(都是一串文本)。它掩盖了应用层开发中最常见的痛点:如何高效管理复杂多字段的异构数据?
网络计算器堪称一个完美的微型模型:虽小巧却功能完备
-
客户端请求是复杂的多元组:它包含左操作数(数字)、右操作数(数字)、以及一个运算符(字符)
-
服务端响应也是复杂的二元组:它不仅包含计算出来的结果(数字),还必须包含一个业务状态码。因为除法可能遭遇除 0 错误,取模可能遭遇模 0 错误,客户端还可能发来非法的运算符,服务器必须有能力把这些业务明确地告诉客户端
2. 请求与响应
根据上述分析,我们在协议的开始,首先要在 C++ 层面将请求(Request)和响应(Response)抽象为独立的数据模型:
#pragma once
#include <iostream>
#include <string>
// 1. 客户端发送给服务端的计算请求
class Request {
public:
Request() : _x(0), _y(0), _op(' ') {}
Request(int x, int y, char op) : _x(x), _y(y), _op(op) {}
~Request() {}
public:
int _x; // 左操作数
int _y; // 右操作数
char _op; // 运算符:'+', '-', '*', '/', '%'
};
// 2. 服务端返回给客户端的计算结果
class Response {
public:
Response() : _result(0), _code(0) {}
Response(int result, int code) : _result(result), _code(code) {}
~Response() {}
public:
int _result; // 计算结果
int _code; // 业务层状态码:
// 0: 计算成功
// 1: 除0错误
// 2: 模0错误
// 3: 非法运算符
};这两个类构成了项目业务流转的核心内存实体
需要特别说明的是,当前阶段这两个类完全独立于 JSON 和网络传输逻辑。它们是单纯的 C++ 对象,仅存在于两端业务函数的私有栈空间中
四、Calculate 模块
在明确项目架构后,我们首先聚焦核心业务逻辑层的设计。在具体实现前,需要深入思考一个关键问题:为何要将业务层与网络通信、JSON解析等基础设施完全解耦?
1. 为什么封装业务层
在实际工业级开发中,网络环境往往十分复杂。如果将计算逻辑与 socket 通信、JSON 解析等操作混杂在一起,测试人员想要验证 "除零异常" 时,就必须:
-
跑起一个完整的 TCP 服务器
-
编写一个客户端程序
-
将参数序列化为 JSON 串通过网卡发过去
-
在断点里观察服务器有没有崩溃
这不仅效率极低,而且一旦测试失败,你根本无法判别究竟是网络传输丢包了、JSON 字段名字写错了、还是底层的数学计算真的算错了
将计算逻辑封装在独立的 Calculate.hpp 中,其输入仅接收 Request 对象,输出仅返回 Response 对象。这种设计使得我们只需编写几行简单的 main 函数代码,即可对核心算法进行单元测试。这种与 I/O 操作完全解耦的架构设计,正是软件工程的首要原则
2. 计算逻辑实现 (Calculate.hpp)
以下时计算逻辑实现,其核心逻辑为:查询数据表、执行计算、处理异常情况、设置状态码
#pragma once
#include <iostream>
#include "Protocol.hpp" // 复用我们定义好的 Request 和 Response 模型
class Calculator {
public:
Calculator() {}
~Calculator() {}
// 核心业务执行函数:只负责处理纯粹的内存结构体对象
Response HandlerCal(const Request& req) {
Response resp(0, 0); // 默认结果为 0,状态码 0 代表成功
switch (req._op) {
case '+':
resp._result = req._x + req._y;
break;
case '-':
resp._result = req._x - req._y;
break;
case '*':
resp._result = req._x * req._y;
break;
case '/':
if (req._y == 0) {
resp._code = 1; // 业务层硬性约定:1 代表除 0 错误
} else {
resp._result = req._x / req._y;
}
break;
case '%':
if (req._y == 0) {
resp._code = 2; // 业务层硬性约定:2 代表模 0 错误
} else {
resp._result = req._x % req._y;
}
break;
default:
resp._code = 3; // 业务层硬性约定:3 代表非法运算符
break;
}
return resp;
}
};五、Protocol 模块与自定义协议设计
接下来是项目中最具技术挑战性的核心模块 —— 应用层协议(Protocol.hpp)
1. 为什么需要协议模块
协议模块就像是一个数据中转,需要具备两种核心功能:
-
序列化与反序列化:将内存对象(Request/Response)与 JSON 字符串互相转换
-
打包与解包:为 JSON 字符串添加长度报头封装,或从网络报文中剥离还原带报头的数据(解决粘包/半包问题)
数据在网络层传输时,如同搭乘多级火箭逐级推进;接收时则像剥洋葱般层层解析
2. 协议格式
我们将网络上流转的一个完整报文,规范为以下经典的边界格式:
"Length\r\nPayload\r\n"-
Length:由数字字符组成的字符串,代表后面 Payload(核心负载,即 JSON 串)的长度
-
\r\n(第一分隔符):作为长度报头的结束标记。服务端通过找到第一组 \r\n,就能精准把长度字符切出来
-
Payload:经过 JsonCpp 压缩处理的紧凑型 JSON 字符串,不含任何换行符
-
\r\n(第二分隔符):作为整个报文的后缀闭合标记,增加校验的冗余度与安全性
3. encode / decode
我们通过两个底层静态工具函数来实现这套封装机制的解封装操作。特别需要注意的是 Decode 函数的实现逻辑,它是高并发服务器处理粘包和半包问题的核心代码
① Encode(打包)
它的工作非常简单,计算出 Payload 的长度,把它和 \r\n 格式化拼装在一起即可
② Decode(解包)
网卡收到的数据存放在 in_buffer 里,它进来时可能是残缺的(半包),也可能是多条消息连在一起的(粘包)
-
查找 \r\n。如果连第一个 \r\n 都找不到,说明连长度报头都没接收全,直接判定为半包,退回等下一次接收
-
提取长度。把 \r\n 前面的数字转成整型 len
-
计算总长度。一个完整包裹的预期总长度应该是 长度字符所占空间 + 2(即\r\n) + len + 2(即结尾\r\n)。如果当前 in_buffer 的总大小比预期总长度还要小,说明 JSON 内容还没接收全,依然是半包,退回
-
此时可确认缓冲区中存在完整报文,此时需解析出 Payload 部分,同时将已处理的报文从 in_buffer 中清除,为后续可能存在的粘连报文头部腾出空间
4. Protocol.hpp 代码实现
我们将数据建模、JsonCpp 的序列化、以及上面的 Encode/Decode 算法内聚在这个头文件中:
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <jsoncpp/json/json.h>
#include <memory>
#include <sstream>
// 核心约定分隔符
const std::string SEP = "\r\n";
// 第一层:网络报文边界包装引擎
// 打包:将 "{"x":1}" -> "7\r\n{"x":1}\r\n"
static std::string Encode(const std::string& payload) {
std::string package = std::to_string(payload.size());
package += SEP;
package += payload;
package += SEP;
return package;
}
// 解包:严密处理粘包与半包
// 输入:in_buffer
// 输出:out_payload(成功剥离出来的 JSON 字符串)
// 返回值:true 成功剥离一条;false 缓冲区数据不足以构成一条完整报文
static bool Decode(std::string& in_buffer, std::string* out_payload) {
// 1. 寻找长度报头与核心负载的分隔符
size_t pos = in_buffer.find(SEP);
if (pos == std::string::npos) return false; // 连 \r\n 都没齐,说明长度报头还没收全
// 2. 提取长度字符串并转化为整型
std::string len_str = in_buffer.substr(0, pos);
int payload_len = std::stoi(len_str);
// 3. 计算一条标准自定义合法报文的预期总长度
// 总长度 = 长度字符长 + 前置分隔符长(2) + 核心负载长(payload_len) + 后置分隔符长(2)
size_t total_len = len_str.size() + SEP.size() * 2 + payload_len;
if (in_buffer.size() < total_len) {
// 字节数不够总长度,说明 JSON 核心内容在传输途中被拆包了(半包)
return false;
}
// 4. 提取核心负载
*out_payload = in_buffer.substr(pos + SEP.size(), payload_len);
// 5. 将已经消费的报文从内核缓冲区中擦除
in_buffer.erase(0, total_len);
return true; // 成功收割一条完整业务消息
}
// 第二层:应用层结构化异构数据模型
class Request {
public:
Request() : _x(0), _y(0), _op(' ') {}
Request(int x, int y, char op) : _x(x), _y(y), _op(op) {}
// 序列化:C++ 结构体 -> 一维 JSON 串
bool Serialize(std::string* out) const {
Json::Value root;
root["x"] = _x;
root["y"] = _y;
root["op"] = std::string(1, _op); // char 转为单字符 string
Json::StreamWriterBuilder builder;
builder["indentation"] = ""; // 工业规范:高紧凑,擦除多余空格
std::unique_ptr<Json::StreamWriter> writer(builder.newStreamWriter());
std::ostringstream os;
if (writer->write(root, &os) != 0) {
return false;
}
*out = os.str();
return true;
}
// 反序列化: JSON 串 -> C++ 结构体
bool Deserialize(const std::string& in) {
Json::Value root;
Json::CharReaderBuilder builder;
std::unique_ptr<Json::CharReader> reader(builder.newCharReader());
std::string errs;
bool ok = reader->parse(in.c_str(), in.c_str() + in.size(), &root, &errs);
if (!ok) {
std::cerr << "Request Deserialize Error: " << errs << std::endl;
return false;
}
// 防御性类型安全检查
if (!root["x"].isInt() || !root["y"].isInt() || !root["op"].isString()) {
return false;
}
_x = root["x"].asInt();
_y = root["y"].asInt();
_op = root["op"].asString()[0]; // 还原字符
return true;
}
public:
int _x;
int _y;
char _op;
};
class Response {
public:
Response() : _result(0), _code(0) {}
Response(int result, int code) : _result(result), _code(code) {}
// 序列化:C++ 结构体 -> JSON 串
bool Serialize(std::string* out) const {
Json::Value root;
root["result"] = _result;
root["code"] = _code;
Json::StreamWriterBuilder builder;
builder["indentation"] = "";
std::unique_ptr<Json::StreamWriter> writer(builder.newStreamWriter());
std::ostringstream os;
if (writer->write(root, &os) != 0) {
return false;
}
*out = os.str();
return true;
}
// 反序列化: JSON 串 -> C++ 结构体
bool Deserialize(const std::string& in) {
Json::Value root;
Json::CharReaderBuilder builder;
std::unique_ptr<Json::CharReader> reader(builder.newCharReader());
std::string errs;
bool ok = reader->parse(in.c_str(), in.c_str() + in.size(), &root, &errs);
if (!ok) {
return false;
}
if (!root["result"].isInt() || !root["code"].isInt()) {
return false;
}
_result = root["result"].asInt();
_code = root["code"].asInt();
return true;
}
public:
int _result;
int _code;
};六、TcpServer
在完成了计算业务类(Calculate.hpp)与协议包装类(Protocol.hpp)后,我们即将部署整个系统的核心引擎——TcpServer网络驱动模块
为提升服务器的高并发处理能力,我们将采用单例模式线程池。网络层的核心设计思路是:主线程专注于高效接收连接请求(accept),在建立连接后立即将任务提交至线程池,由后台工作线程独立处理全双工通道下的复杂数据流交互
1. Task 任务类
ThreadPool 是一个通用模板类,要求所有任务必须实现可执行接口(即重载 operator())。为此我们设计了 Task 类,它需要完成两个关键功能:一是持有客户端套接字 _sockfd,二是封装业务处理回调函数。这种设计实现了网络 I/O 操作与线程池底层实现的解耦
我们在 TcpServer.hpp 中或独立头文件中这样定义 Task:
#pragma once
#include <iostream>
#include <functional>
// 定义业务处理函数的函数指针/仿函数契约
// 传入客户端的套接字,剩下的读写、解包、计算全由该回调函数负责
using func_t = std::functional<void(int)>;
class Task {
public:
Task() : _sockfd(-1), _cb(nullptr) {}
Task(int sockfd, func_t cb) : _sockfd(sockfd), _cb(cb) {}
// 线程池的 Routine 核心调用接口
void operator()() {
if (_cb) {
_cb(_sockfd); // 激活回调函数,开始在这条连接上运转业务
}
}
private:
int _sockfd; // 客户端通信套接字
func_t _cb; // 外部业务
};2. 核心架构 (TcpServer.hpp)
接下来,我们编写 TcpServer 类。它在主线程中只管两件事:
-
InitServer:遵循标准的 socket -> bind -> listen
-
Start:死循环接收连接请求。一旦获取到连接,立即将其分配给线程池处理
#pragma once
#include <iostream>
#include <string>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include "ThreadPool.hpp" // 引入单例线程池
#include "Log.hpp" // 日志模块
class TcpServer {
private:
const static int gbacklog = 10; // 标准监听队列长度
public:
TcpServer(uint16_t port) : _port(port), _listen_sockfd(-1) {}
// 1. 初始化
void InitServer() {
_listen_sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (_listen_sockfd < 0) {
LOG(LogLevel::FATAL) << "create socket error";
exit(1);
}
// 允许地址复用(防止服务器重启时遭遇 Time_Wait 端口占用无法绑定)
int opt = 1;
setsockopt(_listen_sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
struct sockaddr_in local;
memset(&local, 0, sizeof(local));
local.sin_family = AF_INET;
local.sin_port = htons(_port);
local.sin_addr.s_addr = INADDR_ANY; // 监听本地所有网卡
if (bind(_listen_sockfd, (struct sockaddr*)&local, sizeof(local)) < 0) {
LOG(LogLevel::FATAL) << "bind socket error";
exit(2);
}
if (listen(_listen_sockfd, gbacklog) < 0) {
LOG(LogLevel::FATAL) << "listen socket error";
exit(3);
}
LOG(LogLevel::INFO) << "TcpServer init success, listen_sockfd: " << _listen_sockfd;
}
// 2. 驱动网络 accept 核心主循环
void Start(func_t business_service) {
// 首次获取单例线程池实例,其内部会自动拉起后台工作线程
ThreadPool<Task>* tp = ThreadPool<Task>::GetInstance();
LOG(LogLevel::INFO) << "TcpServer loop start...";
while (true) {
struct sockaddr_in client;
socklen_t len = sizeof(client);
// 主线程在 accept 处阻塞,静等客户上门
int sockfd = accept(_listen_sockfd, (struct sockaddr*)&client, &len);
if (sockfd < 0) {
LOG(LogLevel::WARNING) << "accept connection error, continue...";
continue;
}
// 抓取客户端的 IP 和 Port
std::string client_ip = inet_ntoa(client.sin_addr);
uint16_t client_port = ntohs(client.sin_port);
LOG(LogLevel::INFO) << "获取新连接成功, sockfd: " << sockfd
<< " 来自 -> [" << client_ip << ":"
<< client_port << "]";
// 3. 封装 Task,异步派发给单例线程池
Task t(sockfd, business_service);
tp->Enqueue(t);
}
}
~TcpServer() {
if (_listen_sockfd >= 0) close(_listen_sockfd);
}
private:
uint16_t _port; // 服务器端口
int _listen_sockfd; // 监听套接字
};3. 核心服务处理
上面的 TcpServer 在调用 Start 时,需要被注入一个 business_service(业务回调函数)。这个函数将被工作线程执行
我们将完整实现「网卡裸字节→自定义解包→反序列化→计算→序列化→自定义打包→回传网卡」的全链路处理。特别关注代码中处理粘包和半包的轮询式解包逻辑:
#include "Protocol.hpp"
#include "Calculate.hpp"
// 工作例程,跑在工作线程的私有栈里
void CalculatorService(int sockfd) {
LOG(LogLevel::INFO) << "工作线程接管该连接的生命周期, sockfd: " << sockfd;
// 1. 每个套接字连接,专属应用层私有的会话输入缓冲区
// 只要连接不断,该缓冲区会持续承接网卡字节流
std::string in_buffer;
Calculator cal;
while (true) {
char temp[1024];
// 2. recv:从内核接收缓冲区捞取数据
ssize_t s = recv(sockfd, temp, sizeof(temp) - 1, 0);
if (s > 0) {
temp[s] = 0;
in_buffer += temp;
std::string out_payload;
// 3. Decode:利用自定义长度协议,滚动式排查、抽离完整报文
// 为什么用 while?如果遭遇粘包,池子里可能有好几条完整报文,必须全部获取
while (Decode(in_buffer, &out_payload)) {
LOG(LogLevel::DEBUG) << "成功剥离出一条纯净的 JSON 负载: " << out_payload;
// 4. 反序列化
Request req;
if (!req.Deserialize(out_payload)) {
LOG(LogLevel::ERROR) << "Request 反序列化失败";
continue;
}
// 5. 业务处理
Response resp = cal.HandlerCal(req);
// 6. 响应序列化
std::string resp_json;
resp.Serialize(&resp_json);
LOG(LogLevel::DEBUG) << "后端计算完毕响应: " << resp_json;
// 7. 自定义协议打包
// 如 "{"result":3}" -> "12\r\n{"result":3}\r\n"
std::string send_package = Encode(resp_json);
// 8. send:刷回给客户端
send(sockfd, send_package.c_str(), send_package.size(), 0);
LOG(LogLevel::INFO) << "将响应报文返回客户端";
}
}
else if (s == 0) {
// recv 返回 0,代表客户端关闭连接
LOG(LogLevel::INFO) << "客户端主动断开连接, sockfd: " << sockfd;
break;
}
else {
// 读取出错
LOG(LogLevel::ERROR) << "recv error on sockfd: " << sockfd;
break;
}
}
// 9. 回收文件描述符资源
close(sockfd);
LOG(LogLevel::INFO) << "资源回收, sockfd: " << sockfd;
}4. 服务端组装 (CalServer.cc)
我们最后实现服务端的程序入口。其主要职责是初始化 TcpServer 实例,并将之前实现的 CalculatorService 回调函数注册到服务引擎中,最终启动服务运行:
#include "TcpServer.hpp"
#include <memory>
static void Usage(std::string proc) {
std::cout << "Usage:\n\t" << proc << " local_port\n\n";
}
// 示例运行:./cal_server 8080
int main(int argc, char* argv[]) {
if (argc != 2) {
Usage(argv[0]);
exit(1);
}
// 1. 获取命令行解析出来的端口号
uint16_t port = atoi(argv[1]);
// 2. 利用智能指针托管网络引擎
std::unique_ptr<TcpServer> svr(new TcpServer(port));
// 3. 拉起服务器
svr->InitServer();
// 4. 回调函数注入网络主循环
svr->Start(CalculatorService);
return 0;
}七、客户端
完成服务端的代码编写后,我们将目光转向客户端
许多人存在一个常见误区,认为 "协议只需服务端处理,客户端随便发送字符串、接收数据打印即可"。这种认知在工程实践中极其危险
网络协议本质上是两端共同遵守的契约。既然服务端建立了精密的打包解包和序列化流程,客户端在数据收发时就必须成为服务端的镜像
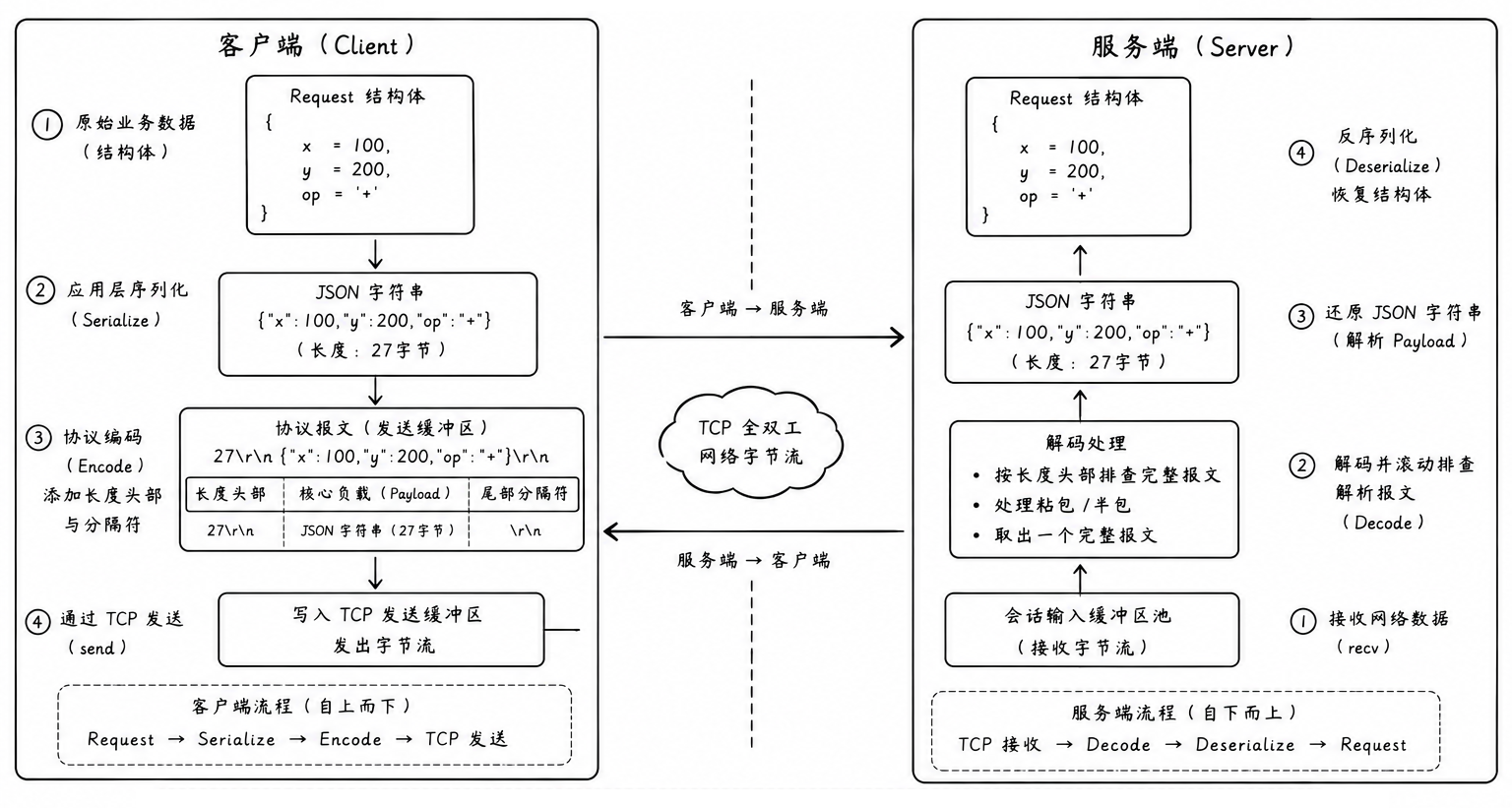
1. 服务端的镜像
在网络世界的全双工通道中,两端的地位在物理层面上是平等的
-
服务端通过 Decode 方法处理客户端发送的粘包问题,这就要求客户端在发送数据时必须使用 Encode 方法添加长度标
-
服务端计算完毕后,同样会调用 Encode 把响应包裹打包发回。这意味着,客户端在接收响应时,同样需要处理网络层拆包和粘包
因此,客户端同样需要开辟一块属于自己的会话输入缓冲区,并采用相同的逻辑进行解码
2. 客户端代码实现
基于这个思想,我们来编写客户端的完整控制中心。它采用交互式循环,引导用户输入数学表达式,并在底层进行封装与拆解:
#include "Protocol.hpp"
#include <iostream>
#include <string>
#include <cstring>
#include <sys/types.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
static void Usage(std::string proc) {
std::cout << "Usage:\n\t" << proc << " server_ip server_port\n\n";
}
// ./cal_client 127.0.0.1 8080
int main(int argc, char* argv[]) {
if (argc != 3) {
Usage(argv[0]);
exit(1);
}
std::string server_ip = argv[1];
uint16_t server_port = atoi(argv[2]);
// 1. 创建流式套接字
int sockfd = socket(AF_INET, SOCK_STREAM, 0);
if (sockfd < 0) {
std::cerr << "[Client Error] 创建 socket 失败" << std::endl;
exit(2);
}
// 2. 远端服务器
struct sockaddr_in server;
memset(&server, 0, sizeof(server));
server.sin_family = AF_INET;
server.sin_port = htons(server_port);
server.sin_addr.s_addr = inet_addr(server_ip.c_str());
// 3. 发起连接
if (connect(sockfd, (struct sockaddr*)&server, sizeof(server)) < 0) {
std::cerr << "[Client Error] 连接服务器失败, IP: " << server_ip
<< ", Port: " << server_port << std::endl;
close(sockfd);
exit(3);
}
std::cout << "已成功连接网络计算器" << std::endl;
// 4. 应对服务端的响应报文可能发生的拆包与粘包
std::string client_in_buffer;
// 5. 核心业务交互主循环
while (true) {
int x, y;
char op;
std::cout << "\n请输入计算表达式";
// 安全拦截标准输入,防止用户乱输入导致流死锁
if (!(std::cin >> x >> op >> y)) {
std::cin.clear(); // 清除错误标记
std::string garbage;
std::getline(std::cin, garbage); // 吞掉垃圾残余
std::cout << "输入格式错误" << std::endl;
continue;
}
// 约定退出暗号
if (op == 'q' || op == 'Q') {
std::cout << "收到退出指令,正在释放连接..." << std::endl;
break;
}
// 生产并序列化
Request req(x, y, op);
std::string req_json;
if (!req.Serialize(&req_json)) {
std::cerr << "客户端序列化失败" << std::endl;
continue;
}
// 协议打包
std::string send_package = Encode(req_json);
ssize_t s = send(sockfd, send_package.c_str(), send_package.size(), 0);
if (s <= 0) {
std::cerr << "发送数据失败" << std::endl;
break;
}
// 响应解包
bool get_response = false;
while (!get_response) {
char temp[1024];
ssize_t r = recv(sockfd, temp, sizeof(temp) - 1, 0);
if (r > 0) {
temp[r] = 0;
client_in_buffer += temp;
std::string out_payload;
if (Decode(client_in_buffer, &out_payload)) {
// 解包出响应 JSON 负载后,进行反序列化
Response resp;
if (resp.Deserialize(out_payload)) {
if (resp._code == 0) {
std::cout << " 表达式: " << x << " "
<< op << " " << y << std::endl;
std::cout << " 结果: " << resp._result << std::endl;
}
else if (resp._code == 1) {
std::cout << "除 0 错误" << std::endl;
}
else if (resp._code == 2) {
std::cout << "模 0 错误" << std::endl;
}
else if (resp._code == 3) {
std::cout << "非法运算符" << std::endl;
}
}
else {
std::cerr << "解析服务端的 JSON 响应格式缺陷" << std::endl;
}
// 标记成功拿到一期任务的答案,跳出当前的 recv 死等循环,
// 回到大循环引导下一次用户输入
get_response = true;
}
}
else if (r == 0) {
std::cerr << "已关闭会话连接。" << std::endl;
goto loop_end;
}
else {
std::cerr << "客户端读取套接字发生错误。" << std::endl;
goto loop_end;
}
}
}
loop_end:
// 安全退出
close(sockfd);
std::cout << "客户端退出成功,套接字描述符已回收。" << std::endl;
return 0;
}3. 代码解析
这段客户端代码中最精妙的设计,是围绕 recv 函数实现的 while(!get_response) 阻塞式解包循环
在经典的请求-响应同步模型中,开发者往往会产生一种错觉:既然客户端发送一条请求,服务端就会返回一条响应,怎么会出现粘包问题呢?
但在复杂的因特网链路上:
-
服务端的响应可能会在路由中被截断(拆包)。此时客户端的 recv 如果只捞到了前半截,Decode 返回 false,程序不会盲目去反序列化,而是会在 while 里继续 recv 后半截,直到拼装完整
-
过往的残余报文突然到达(网络扰动)。通过 Decode 的长度校验和 client_in_buffer.erase 的滚动消费机制,客户端能够准确识别并提取当前任务对应的完整 JSON 数据,有效隔离其他干扰报文或后续报文
总结
综上所述,从应用层协议、序列化与反序列化,到 JsonCpp 的使用,再到基于 TCP 实现的自定义协议网络计算器,我们已经真正开始接触现代网络程序中应用层协议设计这一最核心一部分
其中,TCP 本身只负责提供可靠字节流传输,而真正的数据组织方式、消息边界、请求与响应结构,则完全由应用层协议自行定义。也正因如此,我们才需要通过 encode / decode 来对结构化业务数据进行协议封装与解析
与此同时,通过 "长度字段 + JSON正文" 这种协议设计方式,我们也第一次真正开始尝试解决 TCP "字节流无边界" 所带来的问题。这实际上已经非常接近现代 RPC、HTTP、等系统中的真实设计思想
而进一步回头观察整个网络计算器项目,会发现它已经逐渐具备了现代服务器程序的基本雏形:
- 网络层负责通信
- Protocol 层负责协议解析
- Calculate 层负责业务逻辑
- ThreadPool 负责并发处理
这种 "模块解耦" 的思想,也正是大型服务器程序设计中的核心理念之一
至此,我们已经完成了从 Socket 编程,到应用层协议设计的第一阶段学习。而在下一篇中,我们将暂时离开协议层,重新回到 Linux 系统本身,进一步深入理解:
守护进程、进程组、会话、终端控制
等服务器后台运行机制,真正理解一个网络服务究竟是如何长期稳定运行在系统中的


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)