深度隐式层 | 神经常微分方程
如果我们想构建一个连续时间或连续深的模型,微分方程求解器是一个有用的工具。但如何将 odeint 作为构建深度模型的层呢?前一章展示了如何计算其梯度,因此唯一缺少的就是给它一些参数。本章将展示如何以及为什么要这样做。
在本章中,我们不会使用任何深度学习框架。相反,我们将使用 JAX 提供的可微 Numpy 命令从头开始构建所有内容。
预备知识: 训练残差网络
作为热身,我们可以用几行代码定义一个简单的深度神经网络:
import jax.numpy as jnp
def relu(x):
return jnp.maximum(0.0, x)
def mlp(params, inputs):
# 一个多层感知机,即全连接神经网络。
for w, b in params:
outputs = jnp.dot(inputs, w) + b # 线性变换
inputs = jnp.tanh(outputs) # 非线性
return outputs
mlp 仅仅是线性和非线性层的组合。其参数 params 是一个权重矩阵和偏置向量的列表。
为了构建更大的模型,我们总是可以将层链接或组合在一起。作为一个标准示例,将一些较小的神经网络(如 mlp 层)链接在一起,并将每个层的输入加到其输出上,这称为残差网络:
def resnet(params, inputs, depth):
for i in range(depth):
outputs = mlp(params, inputs) + inputs
return outputs
为了将该模型拟合到数据,我们还需要损失函数、初始化器和优化器:
import numpy.random as npr
from jax.api import jit, grad
resnet_depth = 3
def resnet_squared_loss(params, inputs, targets):
preds = resnet(params, inputs, resnet_depth)
return jnp.mean(jnp.sum((preds - targets)**2, axis=1))
def init_random_params(scale, layer_sizes, rng=npr.RandomState(0)):
return [(scale * rng.randn(m, n), scale * rng.randn(n))
for m, n, in zip(layer_sizes[:-1], layer_sizes[1:])]
# 一个简单的梯度下降优化器。
@jit
def resnet_update(params, inputs, targets):
grads = grad(resnet_squared_loss)(params, inputs, targets)
return [(w - step_size * dw, b - step_size * db)
for (w, b), (dw, db) in zip(params, grads)]
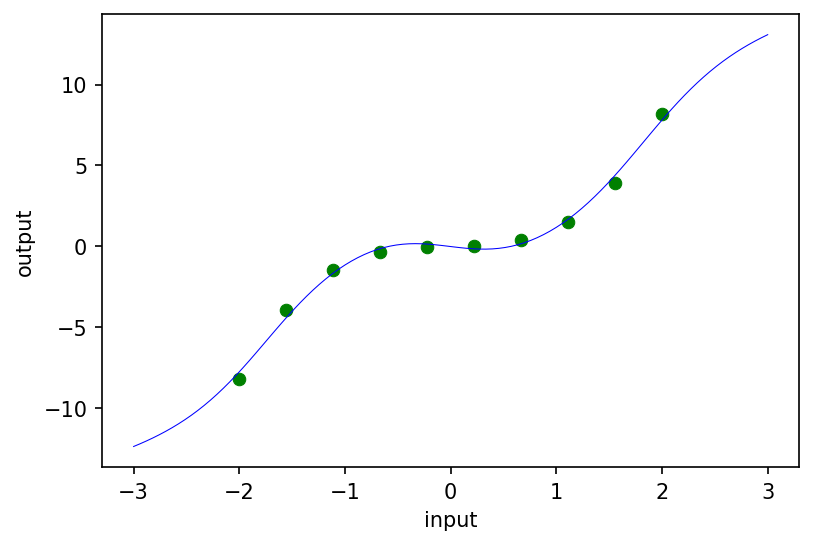
作为合理性检查,让我们将 resnet 拟合到一个玩具 1D 数据集(绿色圆圈),并绘制训练后模型的预测(蓝色曲线):
# 玩具 1D 数据集。
inputs = jnp.reshape(jnp.linspace(-2.0, 2.0, 10), (10, 1))
targets = inputs**3 + 0.1 * inputs
# 超参数。
layer_sizes = [1, 25, 1]
param_scale = 1.0
step_size = 0.01
train_iters = 1000
# 初始化和训练。
resnet_params = init_random_params(param_scale, layer_sizes)
for i in range(train_iters):
resnet_params = resnet_update(resnet_params, inputs, targets)
# 绘制结果。
import matplotlib.pyplot as plt
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca()
ax.scatter(inputs, targets, lw=0.5, color='green')
fine_inputs = jnp.reshape(jnp.linspace(-3.0, 3.0, 100), (100, 1))
ax.plot(fine_inputs, resnet(resnet_params, fine_inputs, resnet_depth), lw=0.5, color='blue')
ax.set_xlabel('input')
ax.set_ylabel('output')
构建神经 ODE
与残差网络类似,神经 ODE(或 ODE-Net)将一个简单的层作为构建块,并将许多这样的层链接在一起以构建更大的模型。具体来说,我们的"基础层"将指定 ODE 的动力学,我们将根据 ODE 求解器的逻辑将这些基础层的输出链接在一起。
指定动力学层
我们需要什么样的层来指定 ODE 的动力学?回顾一下,ODE 初值问题的形式为:
y ˙ ( t ) = f ( y ( t ) , t , θ ) , y ( 0 ) = y 0 , \dot y(t) = f(y(t), t, \theta), \qquad y(0) = y_0, y˙(t)=f(y(t),t,θ),y(0)=y0,
其中初始值 y 0 ∈ R n y_0 \in \mathbb{R}^n y0∈Rn。
我们向动力学添加了参数 θ \theta θ,因此动力学函数的维度为 f : R n × R × R ∣ θ ∣ → R n f : \mathbb{R}^{n} \times \mathbb{R} \times \mathbb{R}^{|\theta|} \to \mathbb{R}^n f:Rn×R×R∣θ∣→Rn,其中 ∣ θ ∣ |\theta| ∣θ∣ 是我们添加到 f f f 中的参数数量。
简而言之,我们需要动力学函数接收 ODE 的当前状态 y ( t ) y(t) y(t)、当前时间 t t t 和一些参数 θ \theta θ,并输出 ∂ y ( t ) ∂ t \frac{\partial y(t)}{\partial t} ∂t∂y(t),其形状与 y ( t ) y(t) y(t) 相同。
通过简单地将状态和当前时间连接起来,并将其作为 mlp 的输入,我们可以轻松构建这样的函数:
def nn_dynamics(state, time, params):
state_and_time = jnp.hstack([state, jnp.array(time)])
return mlp(params, state_and_time)
我们需要指定的模型的其余部分是如何组合该动力学层的评估。我们可以使用任何求解器。JAX 的 odeint 函数实现了标准的自适应步长 Dormand-Price 求解器。
from jax.experimental.ode import odeint
def odenet(params, input):
start_and_end_times = jnp.array([0.0, 1.0])
init_state, final_state = odeint(nn_dynamics, input, start_and_end_times, params, atol=0.001, rtol=0.001)
return final_state
不失一般性地,我们可以让积分时间从 0 到 1。
就是这样!我们已经定义了一个 ODE-Net。下面,我们将更多地讨论 odeint 内部发生了什么,但暂且让我们将其连接到优化器,看看能否将其拟合到数据!
批处理 ODE-Net
为了支持批处理(在多个训练样本上评估 ODE-Net),我们可以简单地使用 JAX 的 vmap 函数,它会自动添加批处理维度。这个转换并非微不足道,因为 odeint 包含 while 循环和控制流,但 JAX 可以自动完成。经过 vmap 的 odeint 会在每个批处理元素上创建独立的并行求解器,等待最后一个求解器完成后返回所有最终状态。但它仍然将对动力学函数的调用组合成一个跨所有批处理元素的高效向量化调用。
在没有 vmap 的环境中,通常的做法是创建一个将批次中每个样本的动力学组合在一起的大型 ODE,在一次 odeint 调用中求解所有内容,然后将结果拆分到批次中。
from jax import vmap
batched_odenet = vmap(odenet, in_axes=(None, 0))
剩下的就是初始化参数、将模型连接到损失函数,并训练 ODE-Net:
# 需要将输入维度改为 2,以允许时间相关的动力学。
odenet_layer_sizes = [2, 20, 1]
def odenet_loss(params, inputs, targets):
preds = batched_odenet(params, inputs)
return jnp.mean(jnp.sum((preds - targets)**2, axis=1))
@jit
def odenet_update(params, inputs, targets):
grads = grad(odenet_loss)(params, inputs, targets)
return [(w - step_size * dw, b - step_size * db)
for (w, b), (dw, db) in zip(params, grads)]
# 初始化和训练 ODE-Net。
odenet_params = init_random_params(param_scale, odenet_layer_sizes)
for i in range(train_iters):
odenet_params = odenet_update(odenet_params, inputs, targets)
# 绘制结果模型。
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca()
ax.scatter(inputs, targets, lw=0.5, color='green')
fine_inputs = jnp.reshape(jnp.linspace(-3.0, 3.0, 100), (100, 1))
ax.plot(fine_inputs, resnet(resnet_params, fine_inputs, resnet_depth), lw=0.5, color='blue')
ax.plot(fine_inputs, batched_odenet(odenet_params, fine_inputs), lw=0.5, color='red')
ax.set_xlabel('input')
ax.set_ylabel('output')
plt.legend(('Resnet predictions', 'ODE Net predictions'))
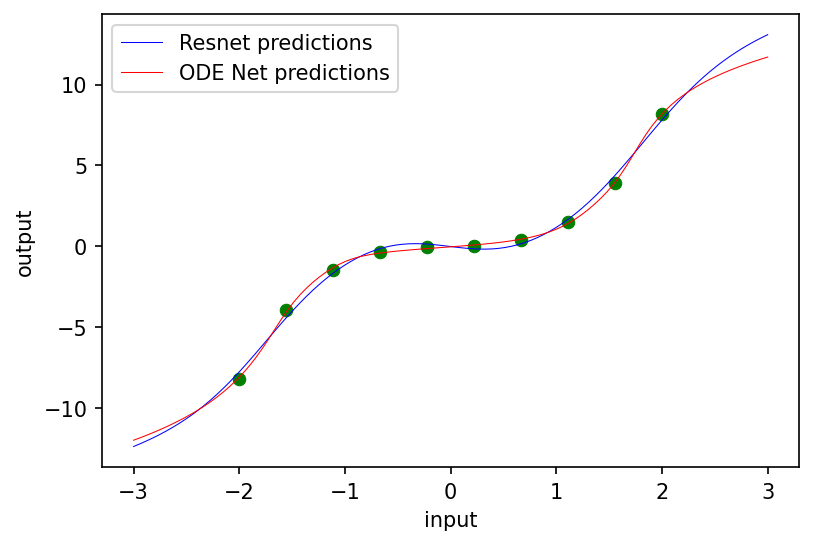
两种回归方法都匹配训练数据,但外推略有不同。
激活轨迹
在深度残差网络中,我们可以检查每个块之间的激活。在 ODE-Net 中,我们可以转而检查作为深度的函数的激活轨迹:
fig = plt.figure(figsize=(6, 4), dpi=150)
ax = fig.gca()
@jit
def odenet_times(params, input, times):
def dynamics_func(state, time, params):
return mlp(params, jnp.hstack([state, jnp.array(time)]))
return odeint(dynamics_func, input, times, params)
times = jnp.linspace(0.0, 1.0, 200)
for i in fine_inputs:
ax.plot(odenet_times(odenet_params, i, times), times, lw=0.5)
ax.set_xlabel('input / output')
ax.set_ylabel('time / depth')

在这个只有一个隐藏单元的玩具设置中,轨迹永远不能相互交叉,这限制了可以学习的函数类别。不过,这种限制可以通过向网络输入添加辅助维度并在网络输出处丢弃来克服(如果需要的话)。
动力学可以采取什么形式?
为了使 ODE 解定义良好且唯一,存在一些限制,我们将在后面讨论。但总的来说,它几乎可以是任何易处理的、可微的、参数化的函数。换句话说,odeint 是一个层,它接收另一个层来指定其动力学函数。这个层可以是全连接网络、卷积网络、U-net,甚至是某些类型的 transformer!
我们在哪里可以使用 odeint 层?
简短的回答是:在任何可以使用残差网络的地方,都可以使用 ODE-Net。两者都要求输入的尺寸与输出的尺寸相同。
神经 ODE 的计算优势
为什么我们要在网络架构中引入所有这些额外的复杂性?与深度平衡模型一样,隐式定义模型输出并将其留给自适应求解器来近似有一些计算优势:
节省内存
有时内存是训练非常大的神经网络的限制因素。具体来说,内存使用通常由存储整个神经网络中的中间隐藏单元激活值主导,这是计算训练梯度所必需的。
有两种主要方法可以解决这个问题。
- 首先,检查点意味着仅在某些层存储激活值,并在需要时重新计算下游层。
- 其次,可逆架构,约束神经网络,使得前一层的激活值可以从后一层的激活值重建。缺点是这样通常需要在某些重要方面限制层架构,例如每次只更新一半的单元。
对于训练基于 ODE 的模型,我们有另一种选择。精确 ODE 解的一个好性质是它们总是完全可逆的!原则上,如果你知道任何单个时刻的状态,你总是可以从那里向前和向后重建 ODE 的完整轨迹。在时间上反向运行 ODE 相当于在时间上正向运行相同的 ODE,但动力学被替换为 y ˙ = − f ( − t , y ) \dot y = -f(-t, y) y˙=−f(−t,y)。 这意味着 ODE 网络原则上可以以与 f 评估次数成常数的内存成本进行训练,而标准的残差网络的内存成本会线性增长。
在实践中,这只有在 ODE 在任一方向都不太难求解的情况下才可行,否则正向和反向路径可能不匹配,或者可能过于昂贵而无法足够精确地近似。但是,如果发生这种情况,通常可以通过检查初始状态和最终状态是否匹配来检测,如果匹配,则只需以一些额外时间为代价进行一些检查点操作。也许令人惊讶的是,在由神经网络参数化的大型系统上,反向重建轨迹在实践中通常足以有效训练。
自适应计算
我们希望我们的模型明智地使用计算资源,只认真思考那些答案重要且困难的问题。在过去约 120 年间发展起来的自适应 ODE 求解器以有限的方式实现了这一点。
构建自适应 ODE 求解器的标准方法是监控两种不同外推方法预测的轨迹之间的差异。如果这种差异变大,说明至少有一种外推方法做出了不好的预测。这些方法然后尝试通过重新开始并减小预测的前瞻距离(即采取更小的时间步长)来恢复。
不同的求解器处理不同类型的动力学问题的难易程度各不相同,但一般来说,动力学越简单,自适应求解器达到给定精度所需的步数就越少。
在训练和测试时都能权衡速度和精度
大多数自适应 ODE 求解器要求用户指定求解器将尽力满足的误差容限(相对和绝对误差)。对于大多数实际系统,我们不能保证满足任何特定的误差目标。但即使在这种情况下,误差容限也是一种在计算时间和答案精度之间权衡的方式。这在某些方面比权重剪枝或量化更灵活,因为容限可以在整个训练过程中调整,甚至在模型部署之后也可以调整。
神经 ODE 的建模优势
除了具有与固定深度网络不同的计算权衡之外,基于 ODE 的网络的精确解也是与标准神经网络不同的模型类别,具有一些不同的性质:
- 变量的可处理变换:在物理学中,有时取离散过程的连续时间极限可以简化计算结果。对于标准化流模型(normalizing flow model)来说恰好如此,这些模型通过一系列离散的可逆变换从更简单的基密度构建复杂密度。FFJORD 模型就是使用这种方法。
- 连续时间时间序列模型:关于拟合连续时间时间序列模型有大量文献,这些模型对于处理不规则采样的时间序列数据特别有用,这是一篇综述。基于 ODE 的模型可以自然地处理这种类型的数据。
- 学习光滑同胚(smooth homeomorphisms):在我们确实希望参数化同胚的情况下,例如参数化一个不自交的形状时,连续时间标准化流会自动强制执行这一约束。例如,PointNet 使用这种方法将 3D 表面拟合到数据上。
神经 ODE 的建模劣势
- 对激活函数的限制:如果 ODE 的动力学不是连续可微且满足 Lipschitz 条件的,其解不一定唯一定义。大多数标准非线性函数,如
tanh和relu满足这些条件。然而,第二个条件意味着我们不能使用某些类型的注意力,因此在使用基于 transformer 的动力学时需要格外小心。 - 只能学习光滑同胚(smooth homeomorphisms):在我们不想学习同胚的情况下,我们可能需要用额外维度增强状态,以恢复标准神经网络所具有的那种普适性(universality)。这篇论文对这些断言进行了精确阐述。
- 确定性动力学:使用 ODE 构建时间序列模型的一个问题是它们假设动力学是确定性的。因此任何类型的未知或随机状态变化都必须单独添加到模型中。一大类随机连续时间动力学由随机微分方程给出,这也可以通过梯度下降进行拟合。
神经 ODE 的计算劣势
- 速度:这是不使用神经 ODE 的主要原因。具体来说,ODE 网络通常需要在同一任务上比固定架构进行更多的内层评估。更糟糕的是,在训练过程中,被学习的动力学往往会变得越来越昂贵来求解。如过我们将网络视为"学习变深"并表达更复杂的函数的话,这很合理。然而,我们需要在预测性能和计算成本之间取得平衡,所以我们需要以某种方式鼓励我们的模型易于求解。最近有一些关于正则化 ODE 使其更容易求解的工作:
- 额外的超参数:在标准网络中,我们必须选择网络的深度作为超参数。在 ODE 网络中,我们需要指定求解器的误差容限以及求解器策略。
软件
以下是一些更全面的工具包,用于拟合神经 ODE:
- TorchDiffEq — 专为构建和拟合神经 ODE 模型而构建的 PyTorch 库。
- Jax — Python 的通用数值计算框架,包含可微的 Dopri5 求解器。
- JuliaDiffEq — Julia 语言的微分方程求解器综合套件。
- TorchDyn — 一套模型模板、教程和应用笔记本。
随机微分方程和偏微分方程
除了常微分方程之外,还有许多其他类型的微分方程可以通过梯度来拟合,基于微分方程开发新的模型类别是一个活跃的研究领域。几乎任何类型的微分方程的解都可以看作是一个层!
以下是这些领域近期工作的一些指引:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)