一篇文章告诉你什么是RAG
前言
前几章我们把Agent的工具体系搭清楚了:Function Calling让大模型能开口下指令,MCP让工具标准化接入,Skills让专业知识按需加载。
到这里,Agent能干活了,工具也能跑起来了。
但有一个根本问题,前面几章都没正面回答:大模型压根看不到你的私有数据,怎么办?
-
你的公司内部有几千页运维手册
-
几百个历史故障报告
-
一套只有内部才知道的排查SOP
这些大模型从来没见过。你让它帮你做OnCall排查,它能给出很通用的思路,但就是没法给出针对你们系统的精准答案。
这就是RAG要解决的核心问题。
一、大模型为什么「看不到」你的数据?
咱们先把问题说清楚,有三类「看不到」,每一类的原因都不同。
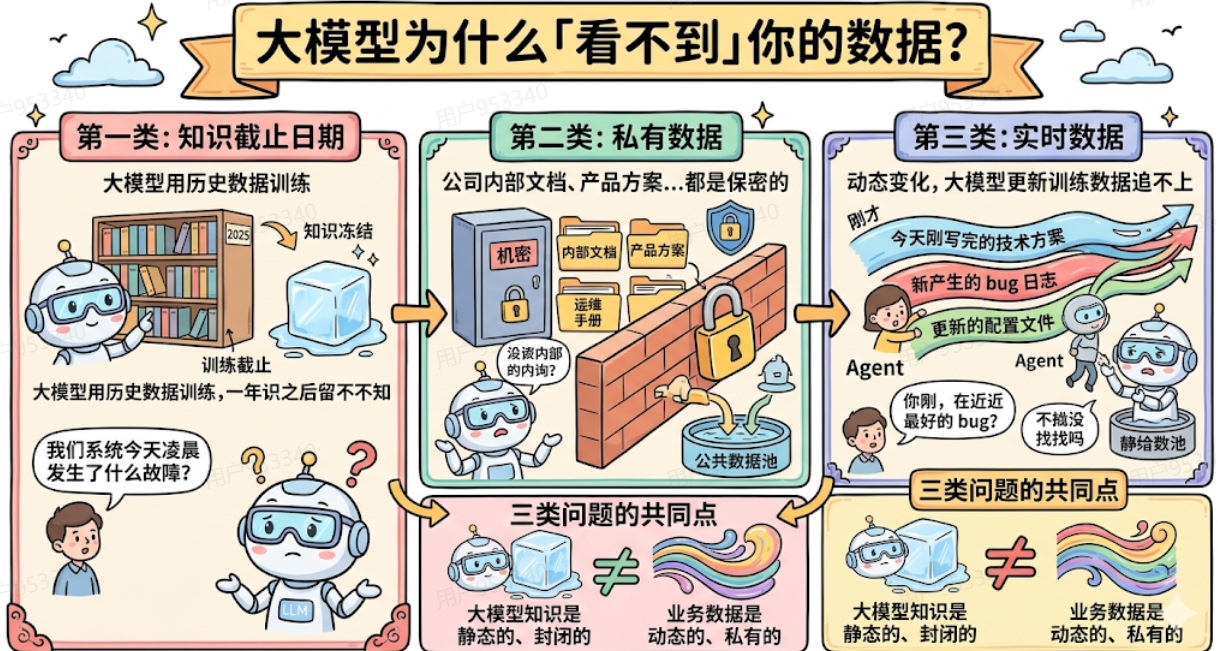
第一类:知识截止日期
大模型是用历史数据训练的,训练完之后它的知识就冻结了。
比如Claude的训练数据截止到2025年某个时间点,之后发生的事情它一概不知。你去问它「我们系统今天凌晨发生了什么故障」,它根本没有这份信息,只能瞎猜。
第二类:私有数据
你们公司的内部文档、产品设计方案、运维手册、客服问答库,这些都是保密的,不可能出现在大模型的训练数据里。
模型从没见过这些内容,自然没法基于它们来回答问题。
第三类:实时数据
今天刚写完的技术方案、刚产生的bug日志、刚更新的配置文件——这些是动态变化的,即便大模型更新了训练数据也追不上。
你的Agent需要访问的,往往就是这类「最新鲜」的数据。
三类问题的共同点
大模型的知识是静态的、封闭的,但你的业务数据是动态的、私有的。
二、暴力解法为什么行不通?
遇到这个问题,很多同学第一反应是:直接把数据塞进Prompt里不就行了?
听起来很直接,但这个方案有三个致命问题。
问题一:Context Window有上限
大模型一次能处理的文本是有限的,这个限制叫做Context Window(上下文窗口)。
就算是目前最大的模型,一次也只能处理几十万token,换算成中文大概是几十万个字。
你们公司的内部文档可能有几百个文件,光是运维手册就几十万字,根本塞不进去。更别提那些有几千个历史工单的故障数据库了。
问题二:费钱又慢
Token是要花钱的。你塞进去10万token的背景资料,每次提问都要花那10万token的钱。一天问几百次,成本直接爆炸。
而且token越多,模型推理越慢,用户等待时间越长。
问题三:注意力稀释
这是最容易被忽视的问题。
大模型处理很长的上下文时,注意力会被稀释。相关内容埋在几万字的堆料里,模型很可能找不到重点,反而表现变差。
你塞进去越多,有时候回答质量越低。
三、RAG的核心思路:先检索,再回答
直接塞数据行不通,那RAG到底怎么解决这个问题?
核心思路其实非常简单,一句话就能说明白:
不把所有数据都塞进Prompt,而是在每次回答之前,先去找到最相关的那几段,再把这几段塞进Prompt。
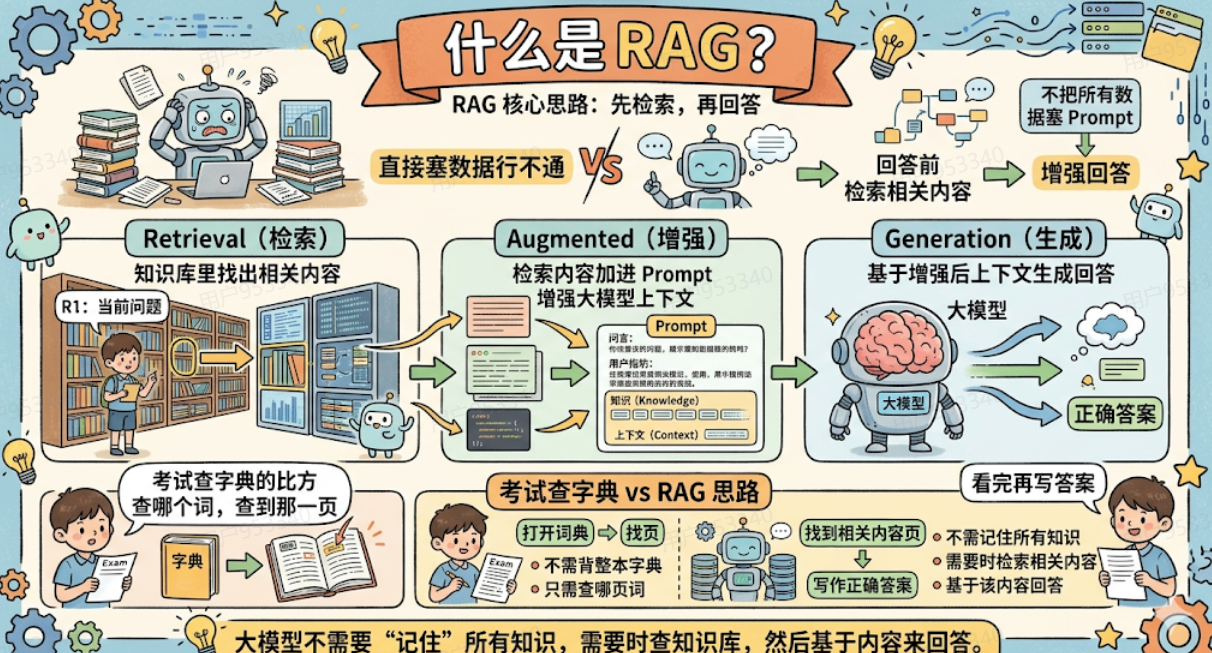
这就是RAG名字的含义:
| 字母 | 全称 | 含义 |
|---|---|---|
| R | Retrieval | 检索:从知识库里找出和当前问题最相关的内容 |
| A | Augmented | 增强:把检索到的内容加进Prompt,增强大模型的上下文 |
| G | Generation | 生成:大模型基于增强后的上下文生成回答 |
打个比方
你考试的时候不需要把整本字典背下来,你只需要知道去字典里查哪个词,查到了那一页,看完再写答案。
RAG就是这个思路:大模型不需要「记住」所有知识,它只需要在需要的时候,从知识库里检索到相关内容,然后基于这些内容来回答。
四、RAG的两大阶段
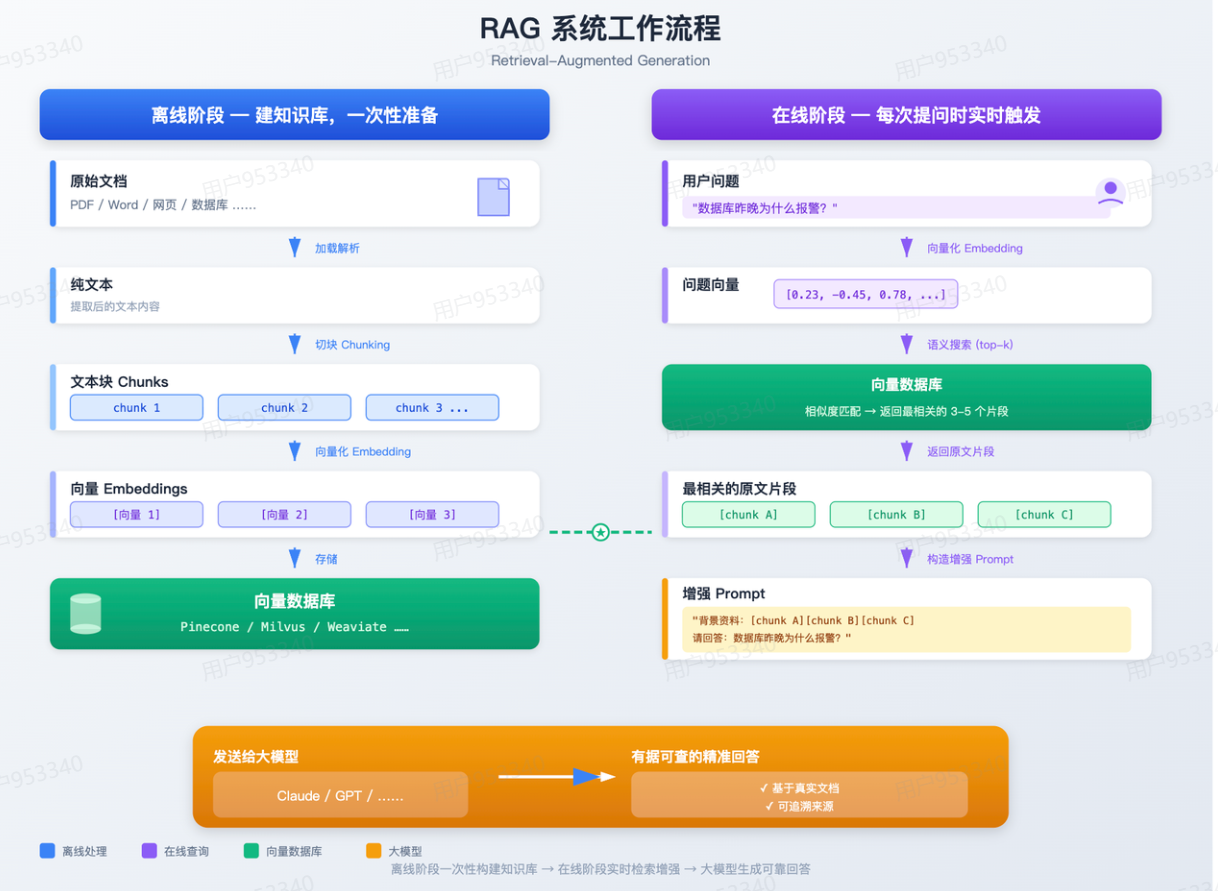
RAG的整个工作流程分两个阶段:离线建库 和 在线检索生成。
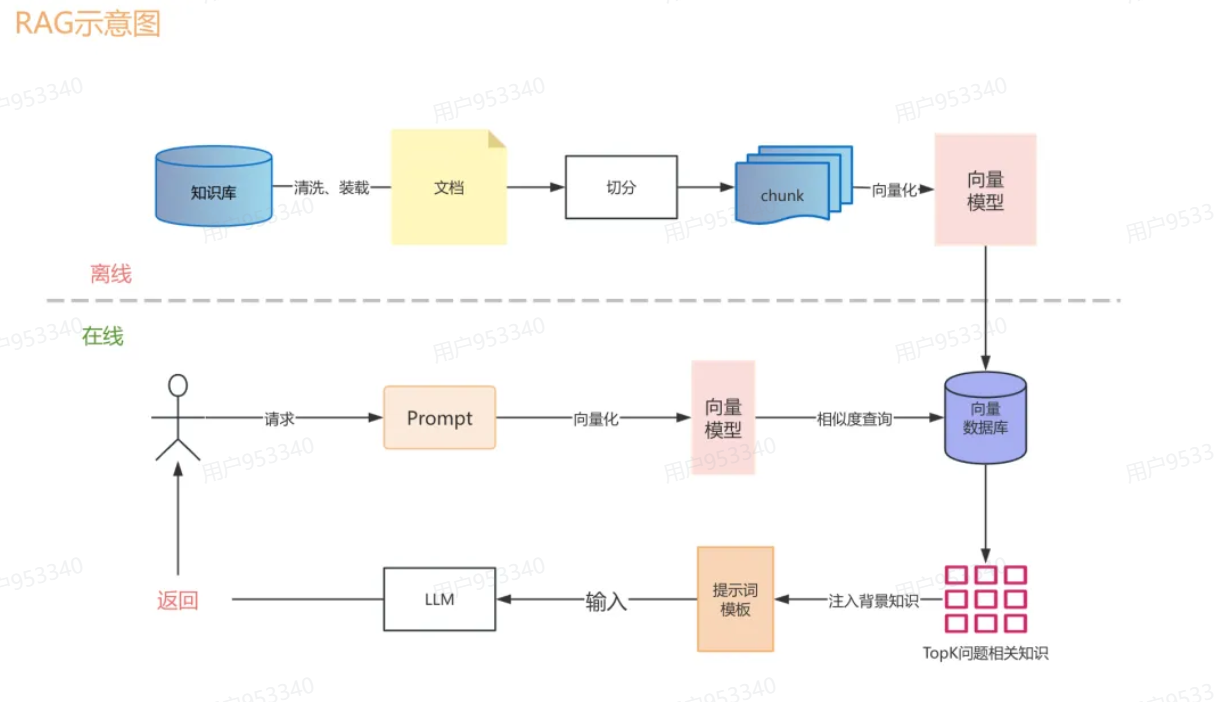
离线建库是一次性的准备工作(数据更新时重做),在线检索是每次用户提问时触发的实时流程。
离线阶段(建库)
这个阶段的目标是:把你的私有数据,处理成大模型能快速检索的格式,存进向量数据库。
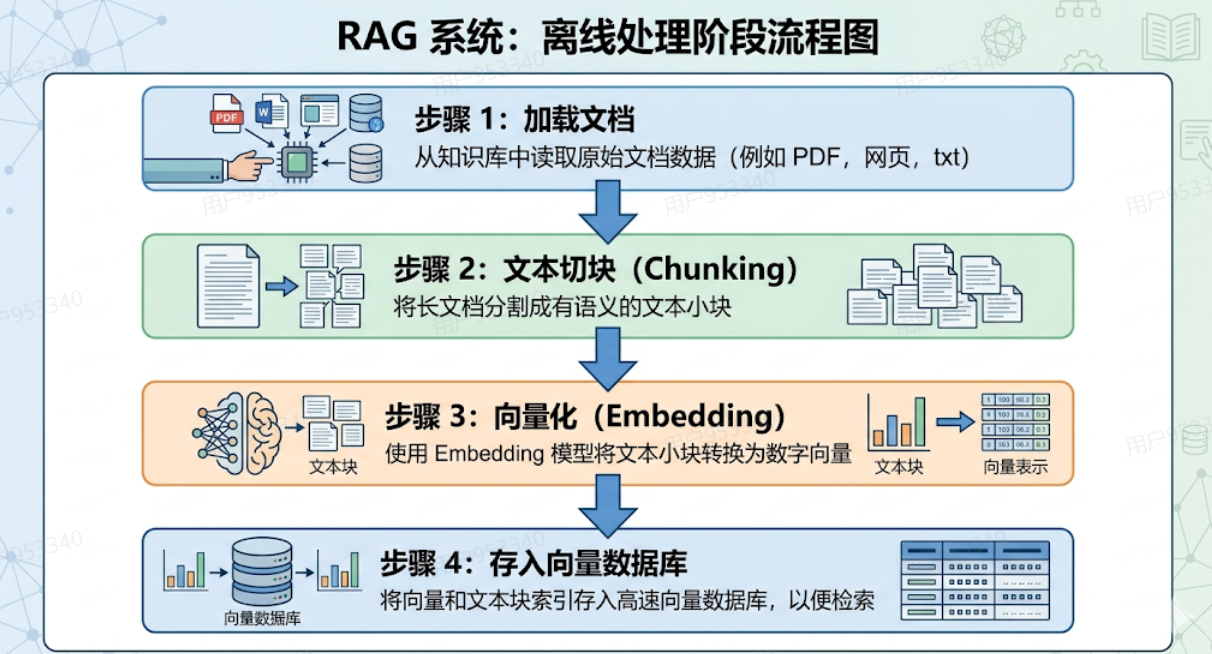
Step 1:加载文档
把你的数据源统一接入进来:
-
PDF文档、Word文件、Markdown笔记
-
网页内容、数据库记录、代码文件
各种格式的数据,统一解析成纯文本。
Step 2:文本切块(Chunking)
拿到文本之后,不能直接整篇存起来,要先切成小块。
为什么要切?
| 原因 | 说明 |
|---|---|
| 粒度控制 | 一篇文档几千字,里面涉及多个主题,检索时很可能只需要其中一个主题的内容 |
| 向量精度 | 每个chunk要转化成向量存起来,chunk太长,向量就无法精确代表那段文字的核心含义 |
切块就像图书馆整理书籍:不是把整本书放一个标签,而是按章节、按小节分别标注。这样读者想找某个具体知识点,能直接找到那几页,而不用翻整本书。
Step 3:向量化(Embedding)
这是RAG里最难理解的一步,咱们重点讲。
切好的每个chunk,要通过一个「Embedding模型」转化成一串数字,这串数字就叫做向量(Vector)。
这串数字有什么神奇之处?
它编码了这段文字的语义含义。意思相近的文字,转化出来的向量在数学空间里距离也相近。
用城市坐标来类比:
每个城市都有经度和纬度
北京大约是北纬40°、东经116°
天津大约是北纬39°、东经117°
两组坐标数字很接近,在地图上两座城市确实挨着
广州是北纬23°、东经113°,坐标差别大,在地图上和北京也确实很远
向量就是文字的「语义坐标」:
-
「数据库响应慢」和「查询性能问题」——虽然词语不同,但意思相近,向量距离近
-
「数据库响应慢」和「今天天气不错」——意思毫不相关,向量距离很远
Step 4:存入向量数据库
转化好的向量,连同对应的原文,一起存进向量数据库(如Milvus、Pinecone、Weaviate等)。
向量数据库专门优化了「在海量向量里找最近邻」这个操作,能在几毫秒内从百万级向量里找出最相似的几条。
在线阶段(查询)
每次用户提问,实时触发以下四步:
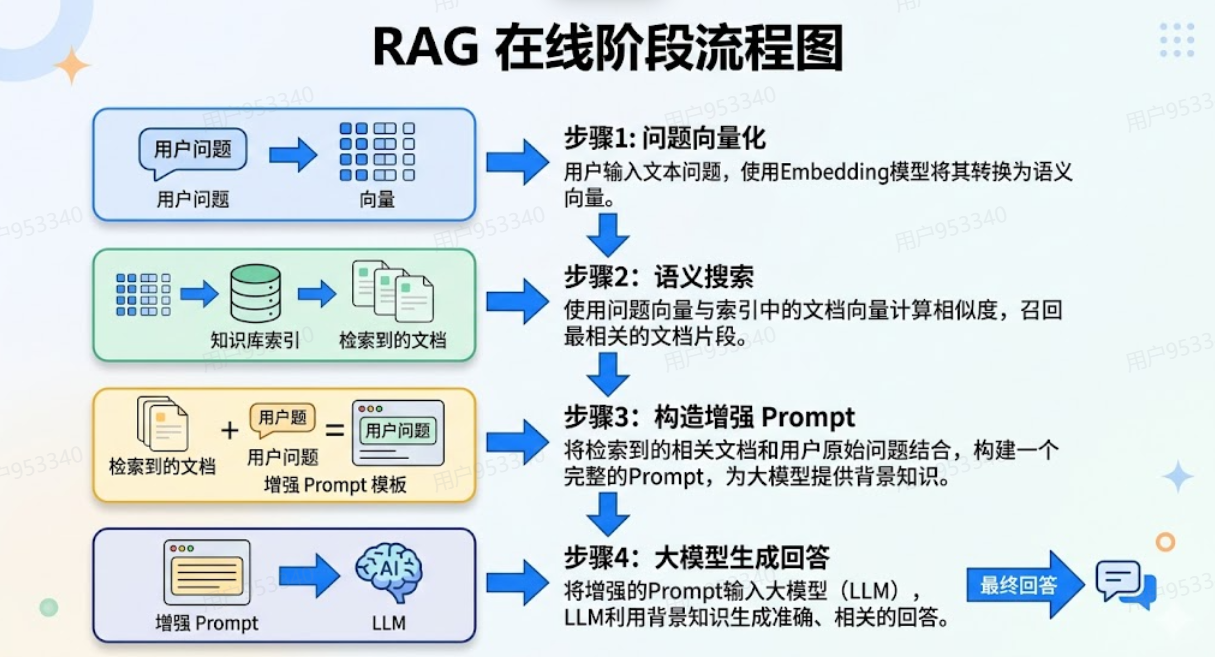
Step 1:问题向量化
用同一个Embedding模型,把用户的问题也转化成向量。
Step 2:语义搜索
拿着问题的向量,去向量数据库里找「最相似的几个chunk的向量」。
找到之后,把对应的原文chunk取出来,通常取3-5个最相关的片段。
⚠️ 注意:这里找的不是「包含相同关键词」的内容,而是「语义最相近」的内容。这是语义搜索和传统关键词搜索的本质区别。
Step 3:构造增强Prompt
把检索回来的几段原文,加上用户的原始问题,拼成一个增强后的Prompt:
text
以下是相关背景资料: [检索到的chunk 1] [检索到的chunk 2] [检索到的chunk 3] 根据以上资料,请回答:[用户的原始问题]
Step 4:大模型生成回答
把这个Prompt发给大模型,大模型基于提供的背景资料生成有据可查的精准回答。
五、关键概念再讲透:语义搜索 vs 关键词搜索
这里展开说一下语义搜索,因为这是RAG能工作的核心,也是最容易搞混的地方。
| 搜索类型 | 原理 | 示例 |
|---|---|---|
| 关键词搜索 | 逐字匹配 | 搜「数据库慢」,只找包含这几个字的文档。文档写「query performance degradation」就找不到 |
| 语义搜索 | 找意思相近的 | 搜「数据库慢」,能找到「查询性能问题」「SQL响应延迟」「慢查询优化」等语义相关的片段 |
对比例子
| 用户的问题 | 文档里的原文 | 关键词搜索能找到? | 语义搜索能找到? |
|---|---|---|---|
| 数据库连接失败 | connection pool exhausted | ❌(没有相同关键词) | ✅(语义相关) |
| 如何重启服务 | service restart procedure | ❌ | ✅ |
| 昨晚报警原因 | 2024-01-15 23:00 alert: high latency | ❌ | ✅(如果时间能对上) |
语义搜索让RAG能真正「理解」问题,而不只是机械地找字符串。
这也是为什么RAG系统的检索准确率通常比普通关键词搜索高得多。
六、完整流程图
text
┌─────────────────────────────────────────────────────────────────────┐
│ 离线阶段(建库) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 私有数据 ──→ 加载文档 ──→ 文本切块 ──→ 向量化 ──→ 存入向量数据库 │
│ (PDF/Word/ (解析成 (分成小 (Embedding (Milvus/ │
│ Markdown) 纯文本) 片段) 模型) Pinecone) │
│ │
└─────────────────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────────────────┐
│ 在线阶段(查询) │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ 用户提问 ──→ 问题向量化 ──→ 语义搜索 ──→ 构造增强Prompt ──→ 生成回答 │
│ (Embedding (找最相似的 (背景资料+ (大模型基于 │
│ 模型) 3-5个片段) 用户问题) 资料回答) │
│ │
└─────────────────────────────────────────────────────────────────────┘
七、RAG在Agent里处于什么位置?
学完RAG的原理,你可能会问:它和我们之前学的Agent、MCP、Function Calling是什么关系?
其实非常简单:RAG本质上就是一个特殊的工具。
还记得Agent章节讲的吗?Agent = 大模型(大脑)+ 工具(双手)+ 执行循环
「查询知识库」这个动作,被封装成了Agent里的一个Tool。
工作流程
text
用户提问(需要私有知识)
↓
大模型通过Function Calling下达指令
「调用知识库检索工具,查询:XXX」
↓
Agent执行这个工具调用,触发RAG的在线流程
↓
检索结果回传给大模型
↓
大模型基于检索结果继续推理或生成回答
这就是在MCP和Agent章节里预告RAG时说的:「把知识库检索封装成工具」
八、一张表看懂:没有RAG vs 有RAG
| 对比维度 | 没有RAG | 有RAG |
|---|---|---|
| 私有数据访问 | 无法访问,模型只有通用知识 | ✅ 可以访问,基于私有知识库生成回答 |
| 知识更新 | 需要重新训练模型,慢且贵 | ✅ 更新文档重新建库即可,快速生效 |
| Token消耗 | 要么全量塞入(超限),要么放弃 | ✅ 只召回相关的几段,token消耗极低 |
| 回答准确性 | 依赖训练数据,私有领域容易瞎编 | ✅ 基于检索到的真实文档,有据可查 |
| 可追溯性 | 无法知道回答依据是什么 | ✅ 每个回答都可以附上来源文档 |
| 扩展性 | 知识库扩大 = 重新训练 | ✅ 直接往向量数据库里加数据即可 |
九、总结
整理一下这一章的核心认知:
1. RAG是什么?
Retrieval-Augmented Generation,检索增强生成。
先从知识库里找到相关内容,再把这些内容加进Prompt,让大模型基于私有数据生成有据可查的回答。
2. 为什么需要它?
| 问题 | 暴力解法(全量塞入) | RAG解法 |
|---|---|---|
| 知识截止日期 | ❌ 无法解决 | ✅ 检索最新文档 |
| 私有数据 | ❌ 模型没见过 | ✅ 接入私有知识库 |
| 实时数据 | ❌ 训练追不上 | ✅ 实时检索 |
| Context限制 | ❌ 超限或放弃 | ✅ 只检索相关片段 |
| 成本 | ❌ 全量塞入很贵 | ✅ 只消耗少量token |
| 注意力 | ❌ 长文本注意力稀释 | ✅ 只给相关内容 |
3. 两大阶段
| 阶段 | 步骤 | 产出 |
|---|---|---|
| 离线建库 | 加载文档 → 文本切块 → 向量化 → 存入向量数据库 | 可检索的知识库 |
| 在线查询 | 问题向量化 → 语义搜索 → 构造增强Prompt → 大模型生成回答 | 精准回答 |
4. 核心概念
| 概念 | 一句话解释 |
|---|---|
| 向量化 | 把文字转化成代表语义的数字坐标(向量) |
| 语义搜索 | 找意思相近的内容,不要求字面相同 |
| 向量数据库 | 专门用于高效查找相似向量的数据库 |
5. 在Agent中的位置
RAG就是一个特殊的工具,「检索知识库」被封装成一次Function Call,是Agent能力体系的重要组成部分。
思维导图(文字版)
text
RAG(检索增强生成)
│
├── 解决什么问题?
│ ├── 大模型看不到私有数据
│ ├── 大模型知识有截止日期
│ └── 暴力塞Prompt行不通(超限、费钱、注意力稀释)
│
├── 核心思路
│ └── 先检索,再回答(不塞全部,只塞相关)
│
├── 两大阶段
│ ├── 离线建库
│ │ ├── 加载文档
│ │ ├── 文本切块
│ │ ├── 向量化(Embedding)
│ │ └── 存入向量数据库
│ └── 在线查询
│ ├── 问题向量化
│ ├── 语义搜索
│ ├── 构造增强Prompt
│ └── 大模型生成回答
│
└── 在Agent中的位置
└── RAG = 一个特殊的Tool(知识库检索工具)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)