面向 Agent 工作流的 Token 节省方案
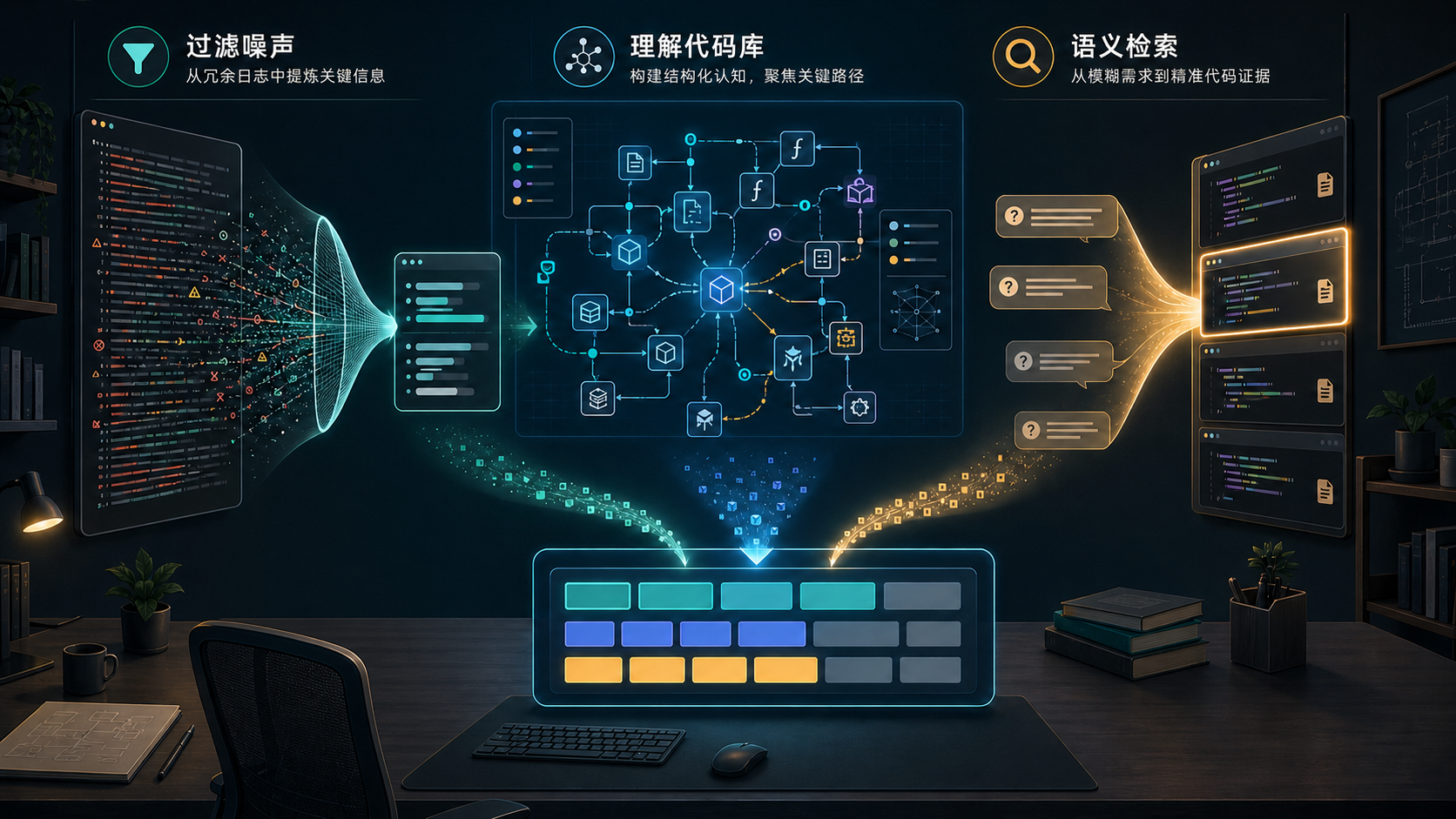
AI 编程真正昂贵的地方,往往不是“多执行了几个命令”,而是 Agent 把太多无关内容塞进了上下文:几千行构建日志、几十个搜索结果、成片源码、重复 warning、进度条、环境提示、成功用例输出。
这些内容看起来都和任务有关,但大多数只是噪声。上下文越乱,token 越贵,判断也越容易偏。一个成熟的 Agent 工作流,不应该把整间仓库都倒到桌面上,而应该像一个熟练工程师一样:先定位,再追踪,最后只留下能支撑判断的证据。
这套组合的目标很直接:
让 Agent 在看到内容之前,先把无关信息挡在外面。
三类工具的分工也很清楚:
RTK 处理命令输出,减少日志 token
CodeGraph 处理代码结构,减少探索 token
Semble 处理模糊搜索,减少盲找 token
它们不是同一种工具的三个版本,而是拦在三个不同入口上的过滤层:命令行入口、代码结构入口、业务语义入口。
第一章:命令行的降噪器
对应工具:RTK
命令行输出经常像开闸放水。一次测试失败,可能同时带出安装日志、构建进度、环境提示、成功用例、重复 stack,以及一串和当前问题无关的 warning。
但 Agent 真正需要的通常只有几件事:
哪个命令失败了
失败在哪个文件
错误信息是什么
关键 stack 是哪几行
下一步应该看哪里
RTK 的价值,就是在命令输出进入模型上下文之前,先做一次本地过滤。它不是让模型读完长日志后再总结,而是在日志被送进上下文之前就把噪声挡掉。
它的工作流程可以理解为:
Agent 准备执行 shell 命令
↓
命令前加 rtk
↓
RTK 执行真实命令
↓
捕获 stdout / stderr / exit code
↓
按命令类型过滤、截断、聚合、摘要
↓
把精简后的结果返回给 Agent
常见用法:
rtk git status --short
rtk git diff --stat
rtk flutter analyze
rtk flutter test
rtk npm run build
rtk pytest -q
RTK 节省 token 的关键在于 前置过滤。它不会改变真实命令的执行,只改变“返回给 Agent 的内容密度”。
它通常会处理这些噪声:
去掉进度条
去掉 ANSI 颜色码
去掉重复空行
压缩 git 输出
突出 test failure
聚合 lint / tsc / analyze 错误
截断超长输出
隐藏大量无意义 boilerplate
适合 RTK 的场景:
git status / git diff 文件很多
flutter analyze 输出很长
测试失败日志很吵
构建工具打印大量进度
包管理器输出安装细节
CLI 工具输出重复 warning
不适合 RTK 的场景:
需要完整原始日志
输出本来就只有一两行
需要精确复制终端内容
不是 shell 命令,而是 MCP 或其他工具调用
如果确实需要完整输出,可以使用:
rtk proxy <cmd>
这表示命令仍然经过 RTK 执行,但尽量保留原始输出,适合调试和对比。
RTK 是否真的省 token,最好看数据。下面几条命令可以直接查看节省效果。示例输出是预览格式,实际数值以本机统计为准。
查看总体节省效果
命令:
rtk gain
示例输出:
RTK Token Savings (Global Scope)
════════════════════════════════════════════════════════════
Total commands: 128
Input tokens: 84,210
Output tokens: 18,450
Tokens saved: 65,760 (78.1%)
Total exec time: 42.3s (avg 330ms)
Efficiency meter: ███████████████████░░░░░ 78.1%
By Command
────────────────────────────────────────────────────────────
# Command Count Saved Avg% Time Impact
────────────────────────────────────────────────────────────
1. rtk flutter analyze 12 18,420 84.7% 9.2s high
2. rtk git diff 25 15,900 72.4% 2.1s high
3. rtk pytest 18 11,320 81.0% 15s high
读法:
Tokens saved 越高,说明 RTK 在命令输出进入 Agent 上下文前挡掉了越多噪声。
By Command 可以看出哪些命令最值得继续走 RTK。
查看最近命令历史
命令:
rtk gain --history
示例输出:
Recent RTK Commands
────────────────────────────────────────────────────────────
Time Command Raw Shown Saved
────────────────────────────────────────────────────────────
18:12:03 rtk flutter analyze 9,840 1,120 88.6%
18:10:41 rtk git diff --stat 1,420 310 78.2%
18:08:17 rtk pytest -q 6,200 840 86.5%
18:05:02 rtk proxy git status 220 220 0.0%
读法:
Raw 是原始输出规模,Shown 是实际进入上下文的规模。
proxy 通常不会节省 token,因为它故意保留原始输出。
查看 hook 重写审计
命令:
rtk hook-audit
示例输出:
RTK Hook Audit
────────────────────────────────────────────────────────────
Total hook calls: 42
Rewritten commands: 39
Already wrapped: 2
Skipped commands: 1
Recent rewrites
────────────────────────────────────────────────────────────
git status -> rtk git status
git diff --stat -> rtk git diff --stat
flutter test -> rtk flutter test
如果没有开启审计,可能看到类似:
No hook audit data found.
Set RTK_HOOK_AUDIT=1 to collect hook rewrite audit metrics.
读法:
它用来确认 hook 是否真的把普通命令改写成了 rtk 命令。
如果 Rewritten commands 长期为 0,说明 hook 没有生效,或者当前工作流没有经过 hook。
查看会话采用情况
命令:
rtk session
示例输出:
RTK Session Adoption
────────────────────────────────────────────────────────────
Sessions scanned: 8
Commands observed: 214
RTK-wrapped: 176
Adoption rate: 82.2%
Recent sessions
────────────────────────────────────────────────────────────
2026-05-28 codex 44/48 commands wrapped 91.7%
2026-05-27 claude 39/42 commands wrapped 92.8%
2026-05-26 codex 18/37 commands wrapped 48.6%
读法:
它适合观察一段时间内 RTK 是否被稳定采用。
如果 adoption rate 偏低,说明仍有不少 shell 命令没有经过 RTK。
这些数据可以回答三个问题:RTK 有没有生效,哪些命令最值得压缩,hook 或全局指令是否被稳定执行。
一句话理解 RTK:
它不帮 Agent 理解代码,它帮 Agent 少读命令废话。
第二章:代码库的结构地图
对应工具:CodeGraph
没有结构索引时,Agent 找代码很容易陷入一种低效循环:
rg 一个关键词
读几个文件
发现不完整
再 rg 一个类名
再读调用方
再查 import
再找测试
再回头看入口
这类探索非常耗 token。因为 Agent 不得不把很多“可能有关”的内容都读进来,而真正关键的代码可能只有几段。
CodeGraph 的思路不同。它先把代码库变成一张结构地图,让 Agent 先问“关系”,再决定读哪些源码。
这张地图记录的是:
函数在哪里定义
类在哪里定义
谁调用了谁
某个方法调用了什么
改一个 symbol 可能影响哪些地方
文件和模块之间如何连接
它的工作流程是:
代码库执行初始化或索引
↓
生成 .codegraph 结构索引
↓
CodeGraph MCP 提供查询能力
↓
Agent 按 symbol / caller / callee / impact 查询
↓
只拿真正相关的位置和关系
适合 CodeGraph 的问题:
这个函数在哪里定义?
谁调用了这个方法?
这个类依赖哪些模块?
改这个 model 会影响哪些页面?
这个 feature 的入口、service、model、UI 是怎么串起来的?
CodeGraph 节省 token 的关键,是 减少探索轮数和无关文件读取。
不用 CodeGraph 时,Agent 可能这样工作:
搜索关键词
读取多个文件
继续搜索调用方
读取更多文件
手动推断调用关系
再搜索测试
用 CodeGraph 后,流程可以收敛成:
查询 symbol
↓
拿到定义、签名、调用方、被调用方
↓
只打开必要源码片段
适合 CodeGraph 的场景:
已知函数名、类名、变量名
需要调用链
需要影响面分析
需要理解模块架构
需要跨文件追踪结构关系
不适合 CodeGraph 的场景:
只知道模糊业务描述
要找一段固定文案
要搜日志字符串
刚改完文件但索引还没同步
只需要读一个很小的文件
CodeGraph 通常有文件 watcher 自动同步索引,但它不是“字符级实时”。刚写入文件后,最好等一小段时间再查;如果是大规模改动、切分支、生成文件,可以手动同步:
codegraph status .
codegraph sync .
一句话理解 CodeGraph:
它像代码库的地图,让 Agent 先看路线,再决定进哪栋楼。
第三章:业务意图的搜索入口
对应工具:Semble
有些时候,问题不是“找不到函数”,而是根本不知道函数叫什么。
比如你只知道这些业务描述:
授权设备名称多语言逻辑
运行记录时间筛选
设备详情页模块状态
通知跳转 run detail
协议预览右侧 deck 数据
这些词未必就是代码里的类名、方法名或文件名。直接 grep 可能搜不到,也可能搜出一堆散乱结果。
Semble 适合这种情况。它接收自然语言或模糊描述,返回语义上最相关的代码片段。它解决的是“我不知道该搜什么关键词”的问题。
它的工作流程是:
用户描述一个业务概念
↓
Semble 做语义代码搜索
↓
返回最相关的文件和代码块
↓
Agent 找到候选入口
↓
再用 CodeGraph 查结构关系
例如,当用户说:
帮我找一下授权设备名称多语言这块逻辑在哪
如果不知道准确 symbol,Agent 不应该一开始就盲目 grep。更合理的方式,是先用 Semble 搜语义:
authorized device localized display name
设备名称 多语言 授权设备
device name internationalization
Semble 节省 token 的关键,是 用语义相关性先筛出候选代码,避免大范围读文件。
它擅长处理:
不知道准确函数名
不知道文件在哪
只能用业务语言描述
关键词可能中英文混合
grep 命中过多
grep 完全命不中
需要快速拿几个最相关代码片段
Semble 不适合做最终影响面判断。它找到的是“可能相关”的代码,而不是完整调用图。
所以 Semble 的结果通常应该作为入口,而不是终点:
Semble 找候选文件
↓
CodeGraph 查调用链和影响面
↓
再读必要源码
↓
最后跑测试验证
一句话理解 Semble:
它像把业务语言翻译成代码线索。
第四章:三者组合后的完整工作流
RTK、CodeGraph、Semble 不应该互相抢工作。真正高效的方式,是让它们分别守住自己的入口。
如果不知道代码在哪里:
Semble → CodeGraph → RTK
如果已经知道 symbol:
CodeGraph → RTK
如果只是跑命令验证:
RTK
举个完整例子:
问题:运行记录时间筛选为什么不生效?
合理流程是:
1. Semble 搜“运行记录 时间筛选”
找到相关页面、model、接口调用
2. CodeGraph 查核心 symbol
看参数怎么传、谁调用它、影响哪些文件
3. 修改代码
4. RTK 跑测试、analyze、git diff
只把关键验证结果返回给 Agent
这样 Agent 看到的是:
相关业务入口
真实调用关系
必要源码片段
压缩后的验证结果
而不是:
几十个 grep 命中
整页无关文件
几千行测试日志
重复 warning
构建工具进度条
省 token 的本质,不是把所有东西压缩成更短的文字,而是从一开始就少走错路、少看废话。
第五章:推荐边界
这三个工具要组合得好,边界必须清楚。
RTK
用途:压缩 shell 命令输出
适合:git、test、build、analyze、lint、log
不要用来:理解代码结构
CodeGraph
用途:结构化代码导航
适合:symbol、定义、调用链、影响面、架构关系
不要用来:模糊业务语义搜索
Semble
用途:语义代码搜索
适合:不知道准确 symbol,只能描述业务意图时找相关代码
不要用来:判断完整调用影响面
可以把它们看成三道不同的筛网:
RTK 筛掉命令行噪声
CodeGraph 筛掉结构探索里的无关文件
Semble 筛掉模糊搜索里的错误方向
总结
RTK、CodeGraph、Semble 节省 token 的位置不同:
RTK 省的是命令输出 token
CodeGraph 省的是代码结构探索 token
Semble 省的是模糊搜索和无效 grep token
它们组合后的价值,不只是“压缩文本”,而是让 Agent 少看无关内容:
少读日志
少读文件
少走弯路
少把不相关上下文塞进模型
好的上下文应该像一张干净的工作台:
只放当前判断需要的证据,
不把整间仓库都倒上来。
当 Agent 看到的内容更少、更准、更接近问题本身时,token 消耗会下降,工程判断也会更稳。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)