llama.cpp上新了MTP功能!在32GB老显卡上Qwen3.6系列模型能加速多少?
上周末llama.cpp官方发布带MTP功能的版本了,不知大家下载部署起来试了没有?
多标记预测(MTP)是一种让大语言模型在单次前向传播中同时预测多个后续token的技术,核心目标是打破传统“单Token逐次生成”的效率枷锁。注意,这个也不是一次预测token越多越好,预测的多但不被接受通过,其实是有反向作用拖累速度的!
这个技术出来有几年了,像之前的deepseek-v3就用这个技术来进行预训练的,但推理阶段好像没怎么用上这个技术,其他有此技术的开源模型也没有普及此技术,但这次的Qwen3.5/Qwen3.6开源模型放出了mtp层,然后我们就能体验下此项能显著加速的技术了。
本文就先测试下mtp的运行速度提升情况,后面再研究下mtp模式的能力变化情况。
本文主要测试内容:这次llama.cpp官方正式版的预填充和生成速度,还是使用手里的V100 32GB显卡来测试带MTP功能的llama.cpp官方版本。
模型选择qwen3.6系列的两款:
- Qwen3.6-27B(Q4_K_M)
- Qwen3.6-35B-A3B(Q4_K_M)
都是unsolth出品的MTP版本
测试文本
还是之前一样,对于每个量化的大模型:
输入即请求是6个完全一致的中文prompt(文本分别长度分别为1000,5000,10000,20000,40000,80000),用来模拟不同长度的上下文;
输出限制在最大200个token;
同时还设置了多个不同的spec-draft-n-max即mtp的预测token数,有1/2/4,另外还测试了没加mtp的情况用来对比;
然后对比各个长度下的速度如何,平均水平等。
测试环境
运行框架:llama.cpp n9180 vulkan
显卡设备:V100 32GB
Lm studio的0.4.13 (build 1)版本也支持mtp这项技术
注:Lm studio和llama.cpp本质都差不多,都是调用llama.cpp进行推理
总体速度概况
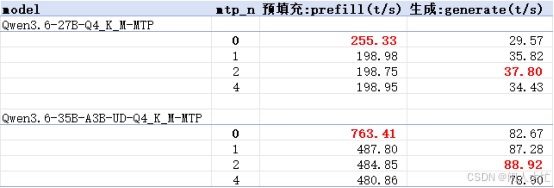
上图中的mtp_n表示并行预测token数,这里采用了1/2/4三种,0表示没有使用mtp加速推理。
这里的每个速度值都是6个不同长度prompt下的平均值。
总体上生成速度有所加速(Qwen3.6-27B更明显),但预填充速度都有不小的下降,初步判断是mtp带来的开销影响,不能确定是否是显卡的原因。
可能是本人测试问题,如有遇到此情况并了解其他原因还望评论区告知下。
不同mtp参数对速度的影响(Qwen3.6-27B)
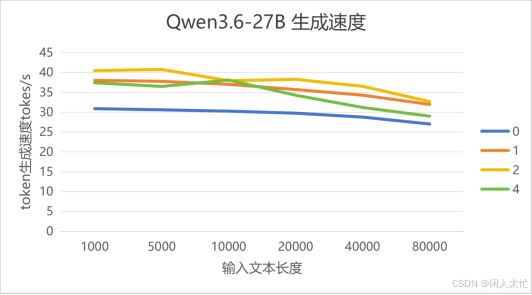
上图是Qwen3.6-27B(Q4_K_M)在无mtp和不同mtp预测tokens数情况下的token生成速度
从图中可以看出mtp-n在1/2时还是比无mtp的token生成速度要快些的,大约在20-30%左右吧。但mtp-n为4的长文本时,生成速度就快的不多了,本来长文本时都有所下降,但mtp预测数一多可接受率会大降直接导致加速效应微弱。
后面有关于Qwen3.6-35B-A3B的mtp接受率方面的详细分析
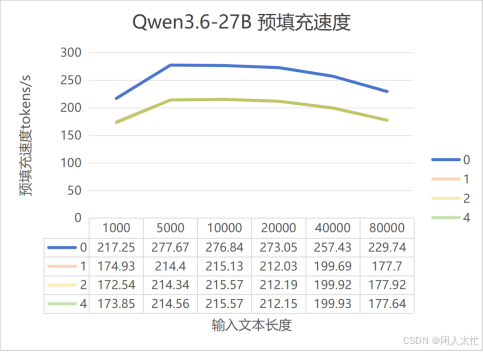
上图是Qwen3.6-27B(Q4_K_M)在无mtp和不同mtp预测tokens数情况下的预填充prefill速度
从图表中可以看出,无mtp模式时,预填充速度是最快的,大约快30%左右,这个特性决定你的应用场景是否需要此mtp加速,同时可以看出mtp的不同token预测数对预填充速度几乎无影响。
不同mtp参数对速度的影响(Qwen3.6-35B-A3B)
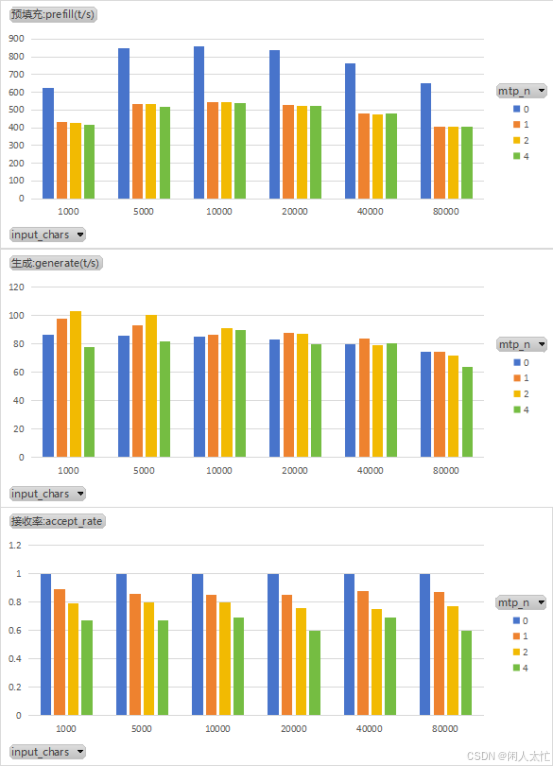
上图分别是Qwen3.6-35B-A3B-UD-Q4_K_M预填充速度、生成速度、接受率在不同mtp_n和不同文本长度prompt下的表现
预填充和生成速度与Qwen3.6-27B(Q4_K_M)表现差不多
接受率方面,随着mtp_n的增加接受率下降,在各个prompt长度下都是如此。
但是,Qwen3.6-35B-A3B-UD-Q4_K_M-MTP模型在较长上下文时,生成速度还会出现负加速现象,所以在遇到较长上下文处理任务时要注意避免此模型此显卡来运行。
预填充和生成速度相对于各个mtp_n接受率的如下图:

生成速度的加速效果可以认为是mtp预测高效率和接受率的综合结果,只有两者都达到综合效果时才是最佳的。
当然,本文以上这些都是从运行速度上来分析对比的,后面还会从评估模型能力、智能体实战能力多方面去分析这些优化后的能力强弱。
总结
采用mtp加速后,两个模型的生成速度都有一定的提升,Qwen3.6-27B提升更明显一点,但预填充速度都有不小的下降,后面需要评估此现象是否符合具体场景。另外,更大的Mtp_n数会导致更低的接受率,会削弱mtp所带来的加速效果。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)