Elasticsearch:跨数据库与业务系统进行搜索
概述
Elasticsearch 简介
Elasticsearch 提供多种搜索技术,从 BM25 开始,这是文本搜索的行业标准。它还提供由 AI 模型驱动的语义搜索,可以基于上下文与意图提升搜索结果。
在本指南中,你将学习如何将外部数据库中的数据同步到 Elasticsearch,并使用语义搜索轻松检索你的数据库。
更多有关如何安装 Elastic Stack 的信息,请参考文章《如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch》
导入你的数据
如何进行数据摄取与增强以支持搜索
Elasticsearch 提供了丰富的数据导入能力,帮助解决你的业务问题。观看该网络研讨会可以:
- 学习如何将分散的数据汇聚到一个地方,从而构建搜索体验。
- 了解适用于不同数据类型的工具,包括 Open Crawler、连接器目录、数据与 ML 推理管道等。
- 观看使用客户支持数据集的实时演示。
创建 Elastic Cloud 项目
开始 14 天试用。访问 cloud.elastic.co 并创建账户后,按照以下步骤启动你的第一个 Elasticsearch Serverless 项目。
首先,选择 Elasticsearch。
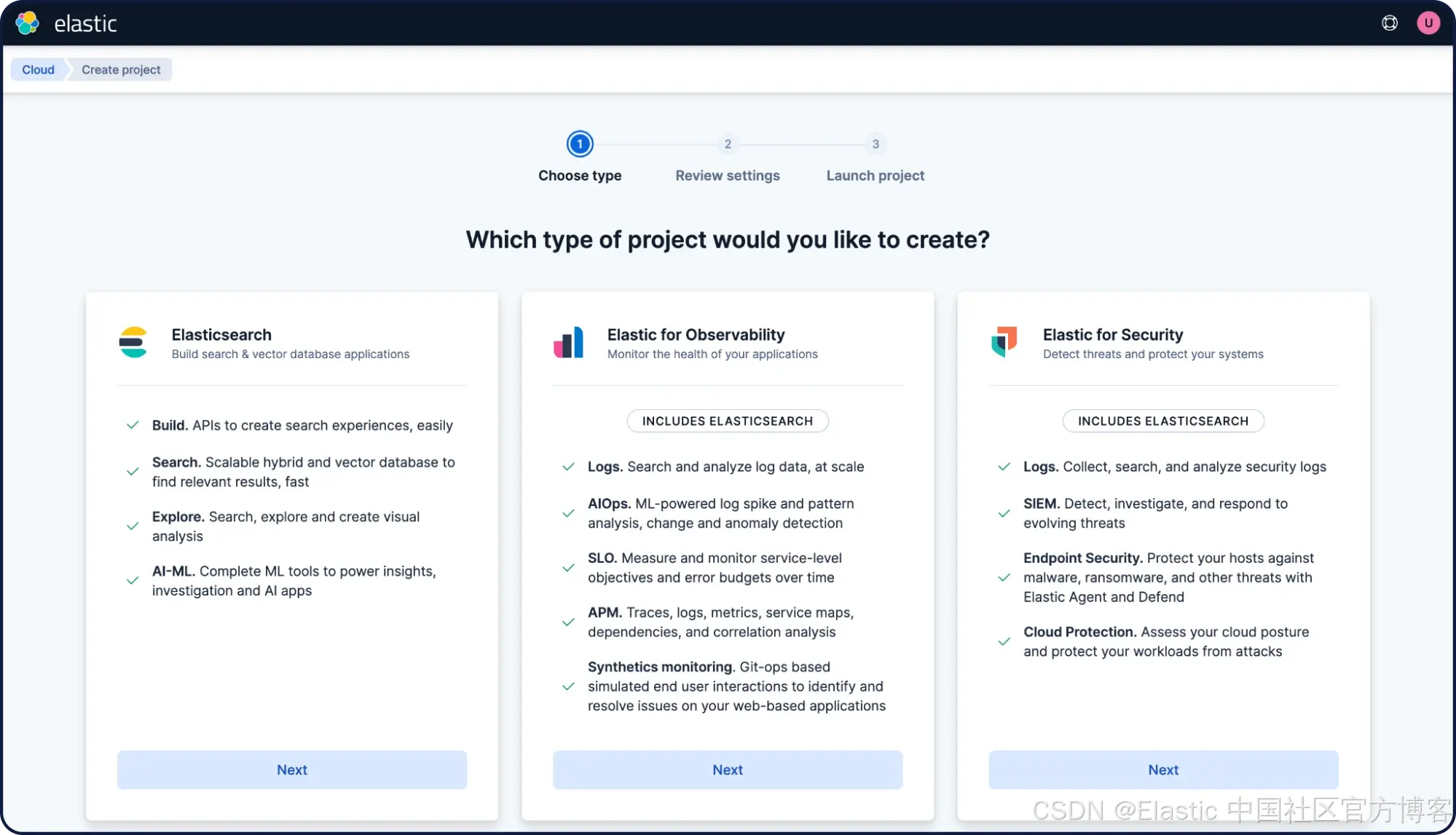
创建一个通用用途的项目。将其命名为“ My project ”,然后点击“ Create project ”。
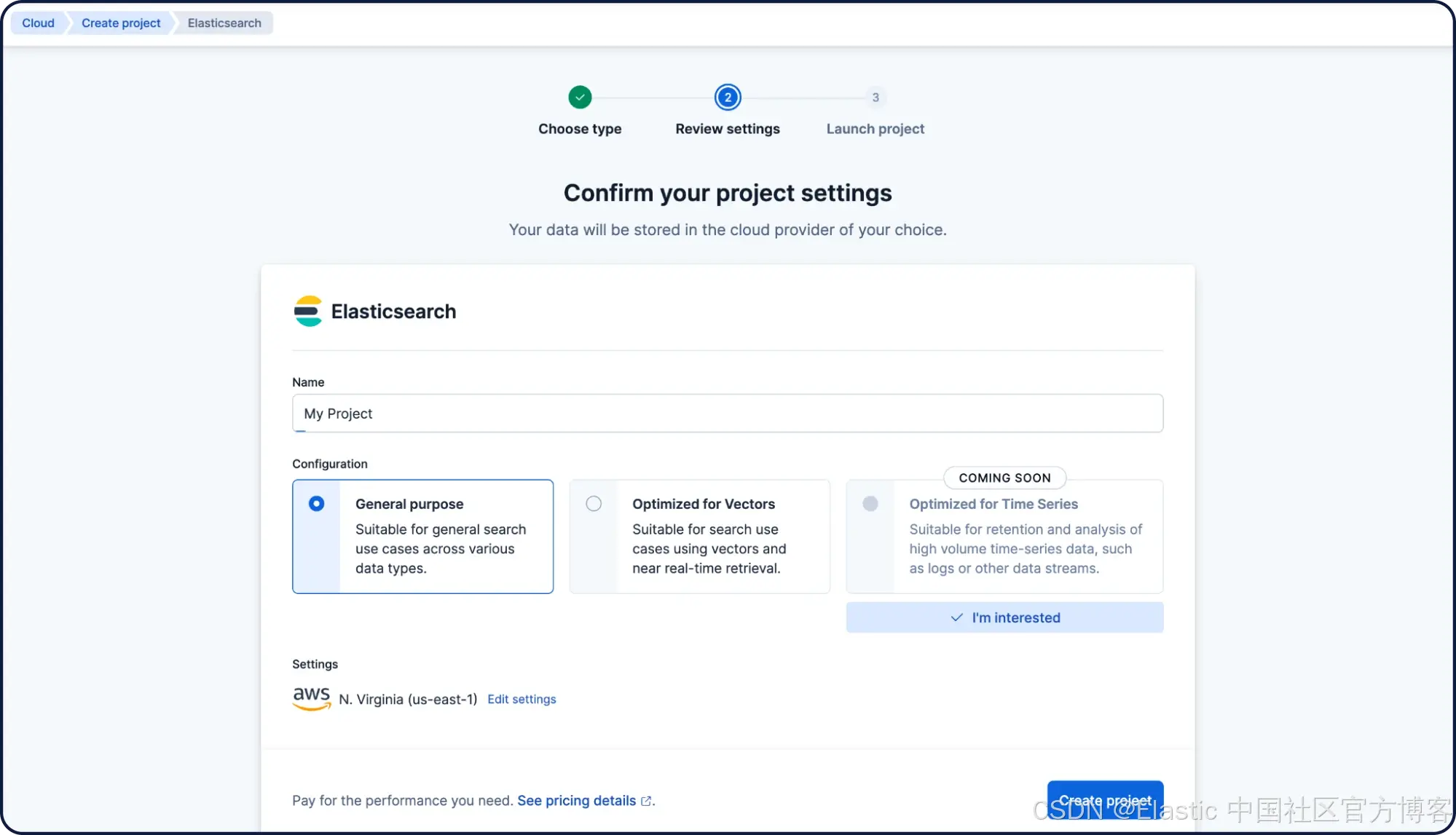
你的 Elasticsearch Serverless 项目现在将被创建。接下来,创建你的第一个 Elasticsearch 索引,并将其命名为“ my-index ”。点击 “ Create my index ”。
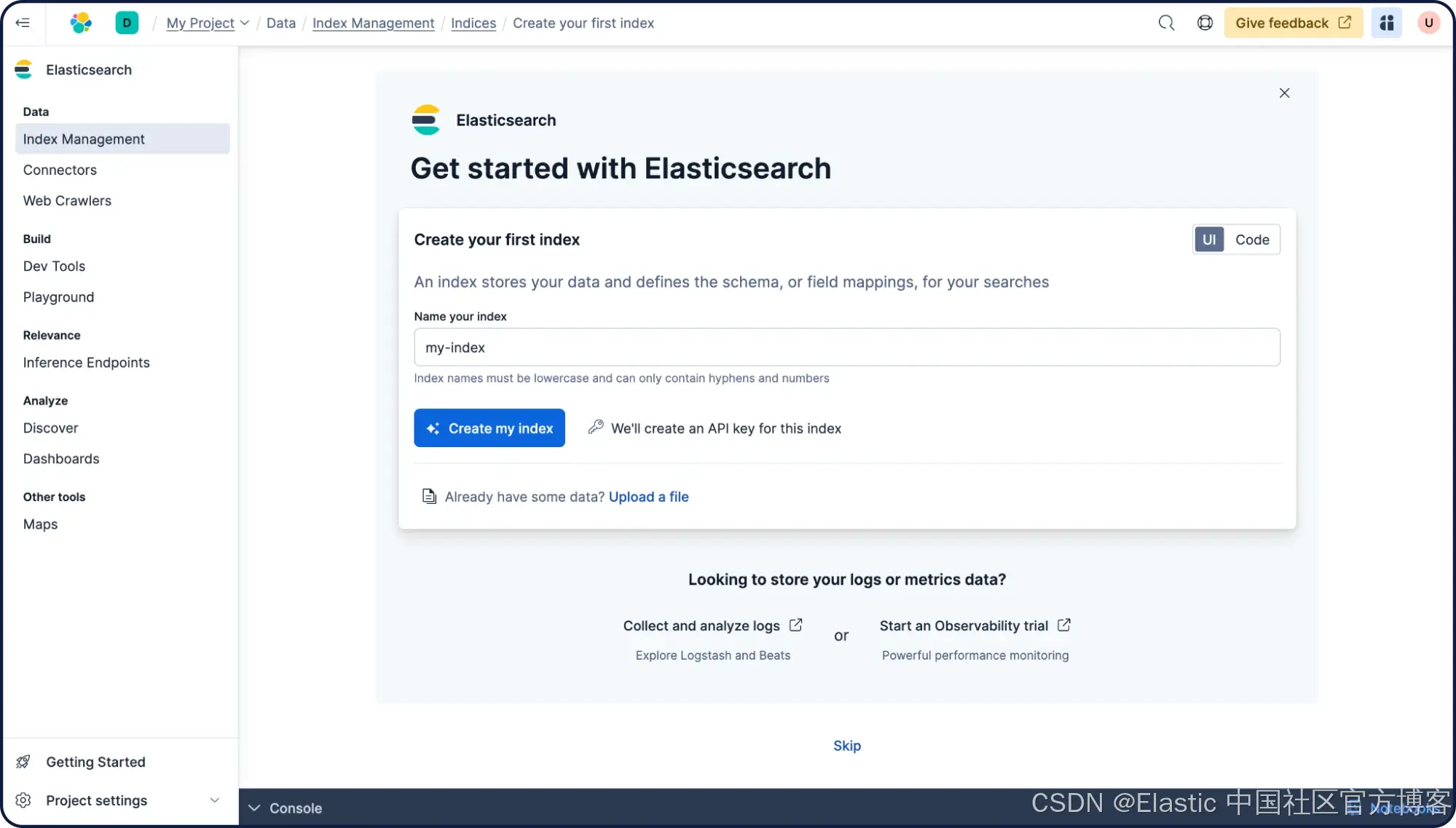
接下来,你可以将第三方数据源添加到 Elasticsearch。在这个示例中,我们有一个 MongoDB 数据库,包含大约 150,000 条电子游戏标题记录,以及字段“ id ”、“ name ”、“ description ”和“ date ”。我们将把这个数据库同步到 Elasticsearch,并额外为其添加语义搜索能力。
让我们创建一个基础的索引映射,字段名保持一致,并额外添加“ description_semantic ”字段,用于存储语义搜索的向量。打开 Dev Tools,并粘贴以下命令来更新你的索引映射:
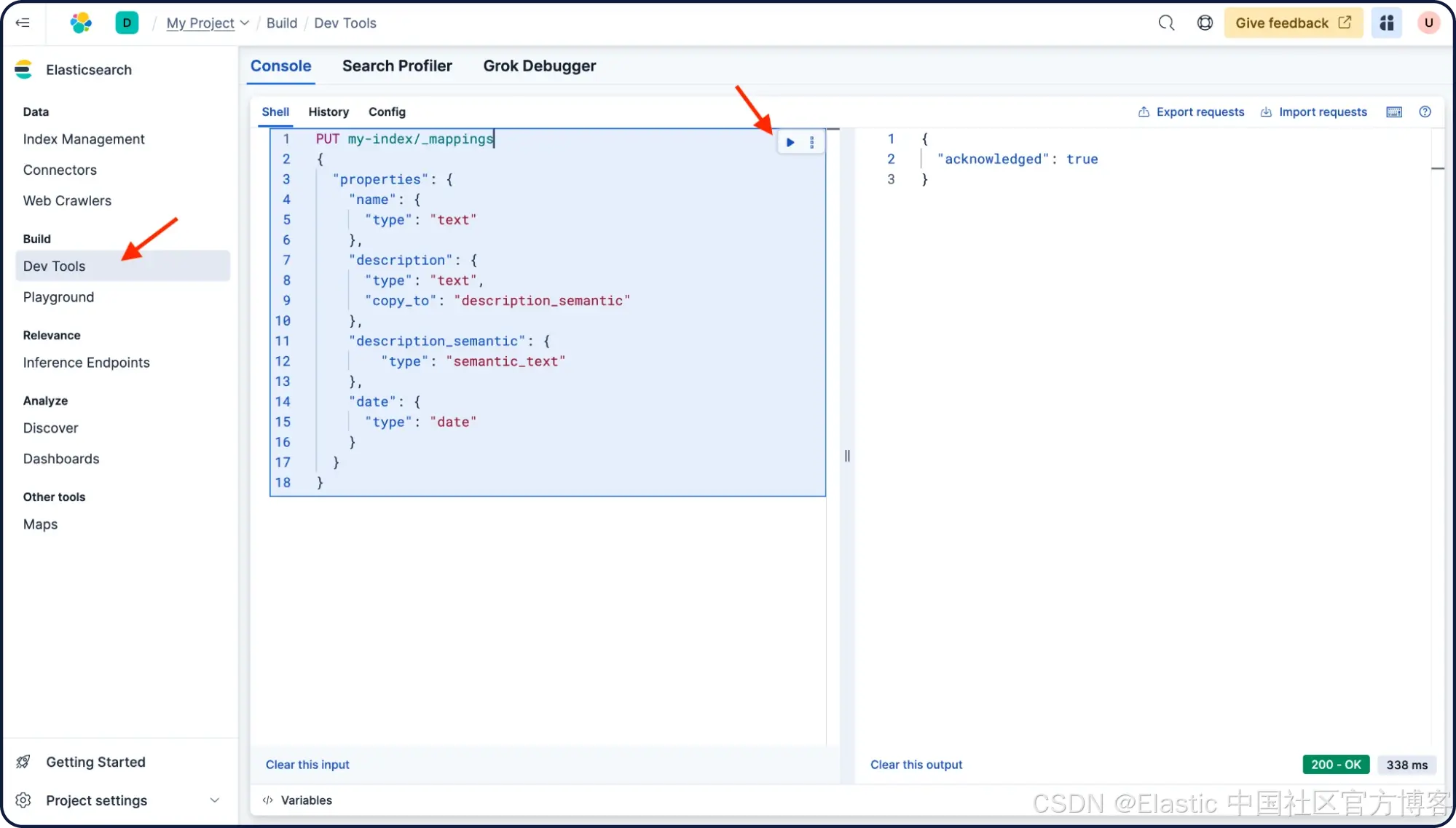
PUT my-index/_mappings
{
"properties": {
"name": {
"type": "text"
},
"description": {
"type": "text",
"copy_to": "description_semantic"
},
"description_semantic": {
"type": "semantic_text"
},
"date": {
"type": "date"
}
}
}从现有数据库获取数据
你已经可以连接到一个现有数据库。点击“ Connectors ”,然后点击 “ + Self-managed connector ”。
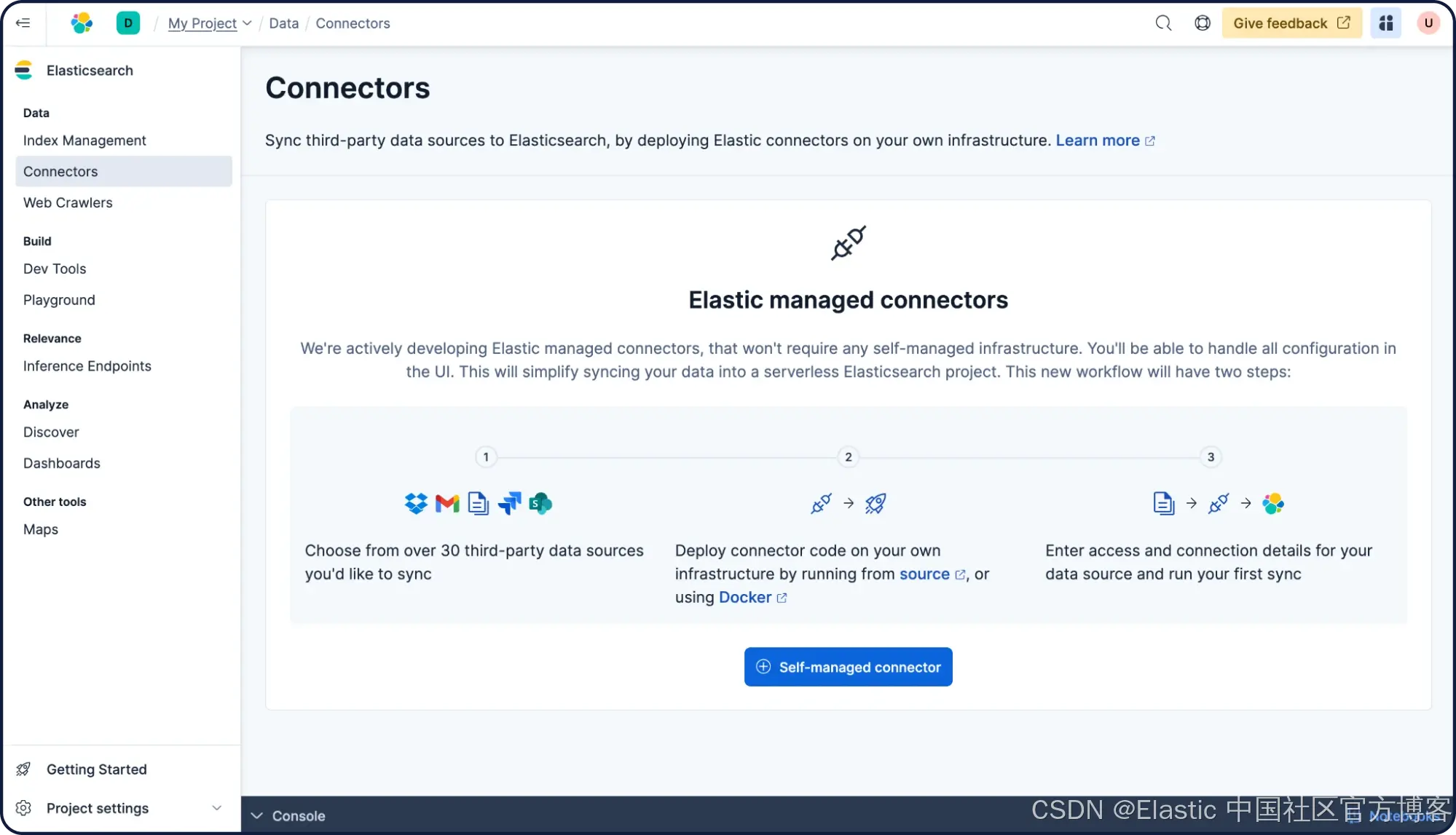
本指南将使用 MongoDB 数据库。从 Connector type 列表中选择 MongoDB。
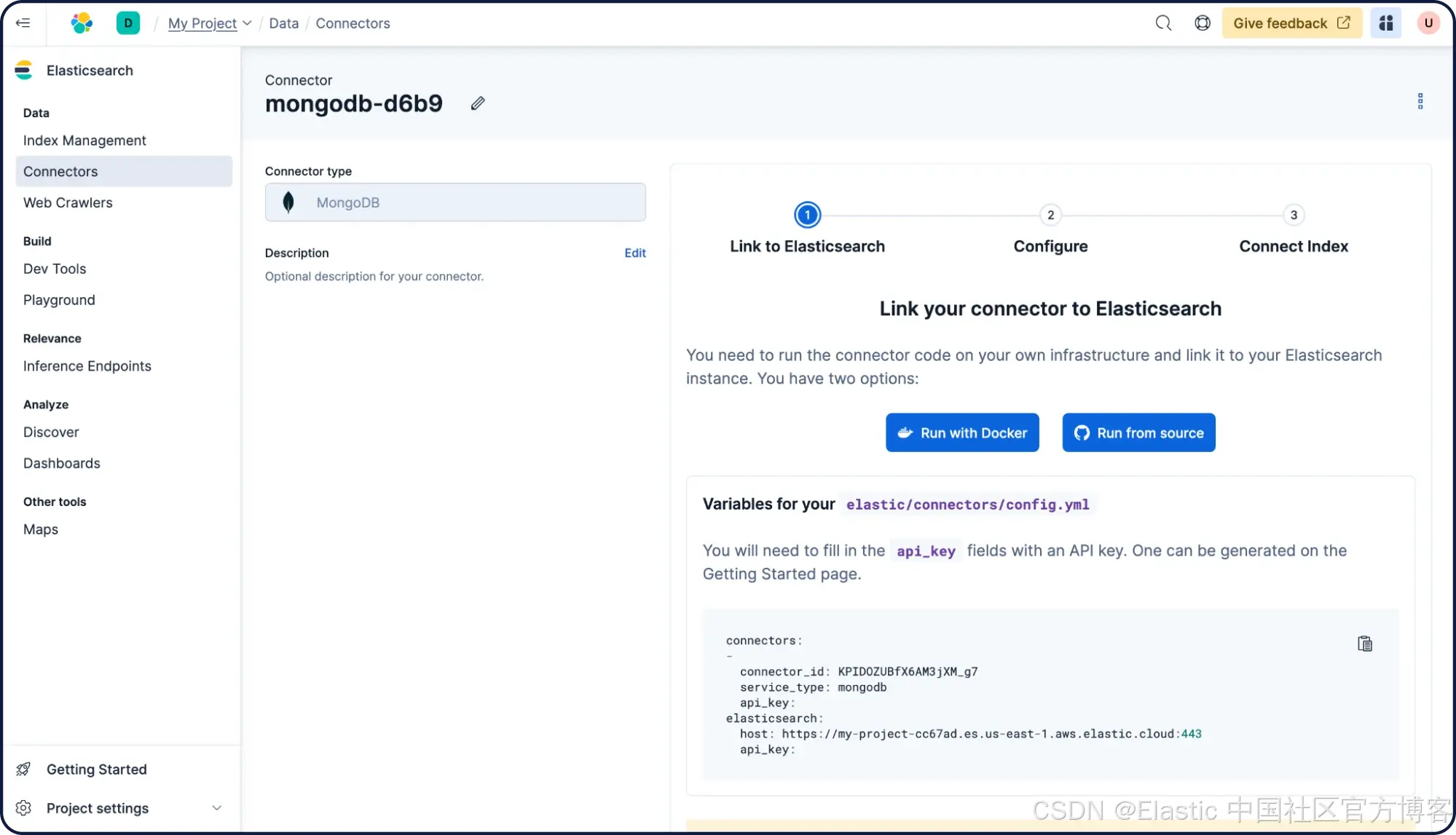
按照说明使用 Docker 部署一个自托管 connector。你需要创建一个 config.yml 文件。注意 connector 和 Elasticsearch 上的 api_key 是相同的。例如:
connectors:
-
connector_id: KPIDOZUBfX6AM3jXM_g7
service_type: mongodb
api_key: RGZMUU9KVUJmWDZBTTNqWFRQano6R3RRb01jR2kxRkNqWTA5eGtSa3NFZw==
elasticsearch:
host: https://my-project-cc67ad.es.us-east-1.aws.elastic.cloud:443
api_key: RGZMUU9KVUJmWDZBTTNqWFRQano6R3RRb01jR2kxRkNqWTA5eGtSa3NFZw==然后,使用以下命令启动自托管 connector:
docker run -v "./connectors-config:/config" --tty --rm docker.elastic.co/enterprise-search/elastic-connectors:8.17.0 /app/bin/elastic-ingest -c /config/config.yml接下来,将配置添加到你的 MongoDB 数据库中,然后点击 Next。
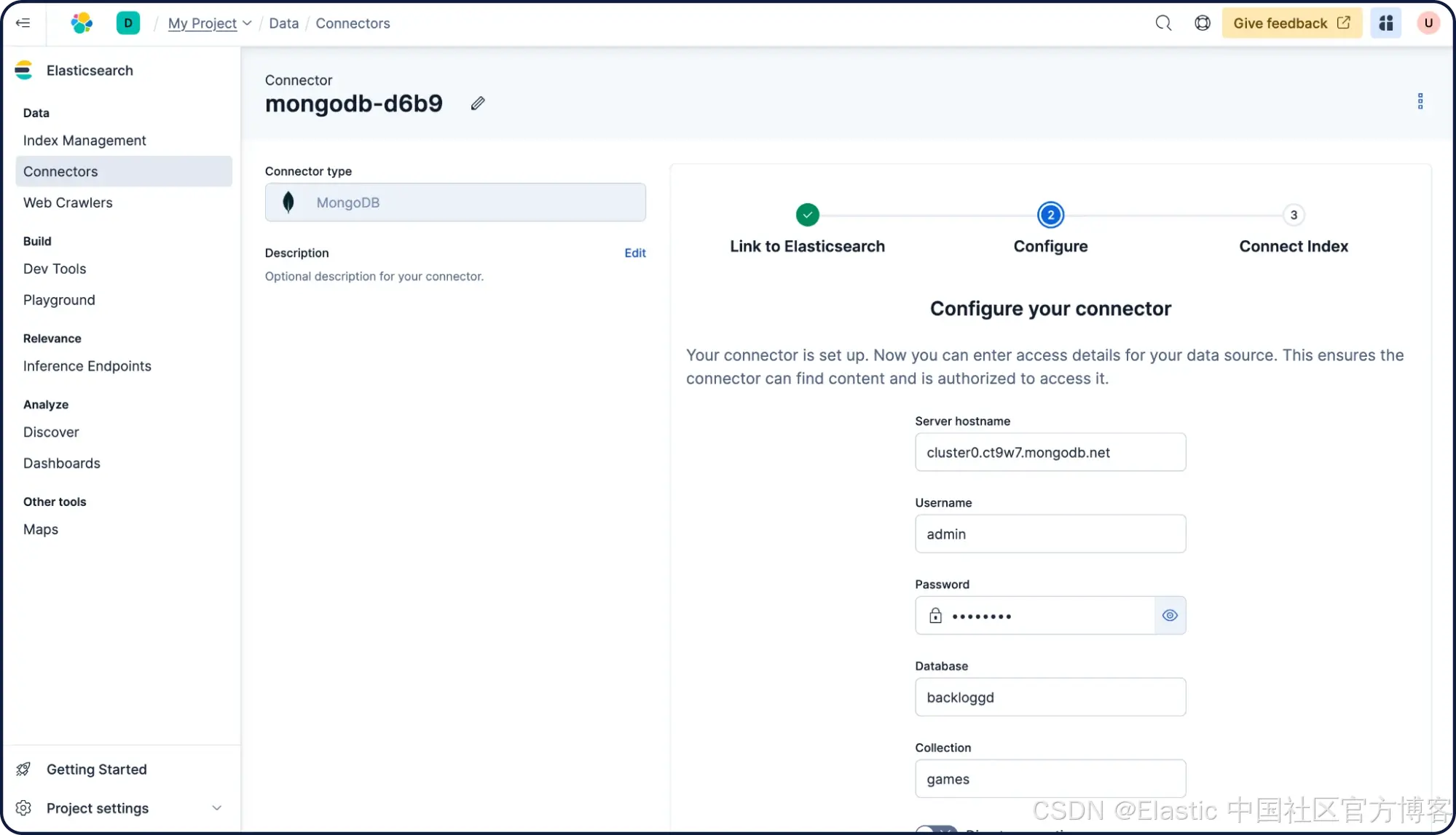
选择需要同步数据的索引——在本例中是我们之前创建的 “ my-index ”。点击 “ Sync ”。
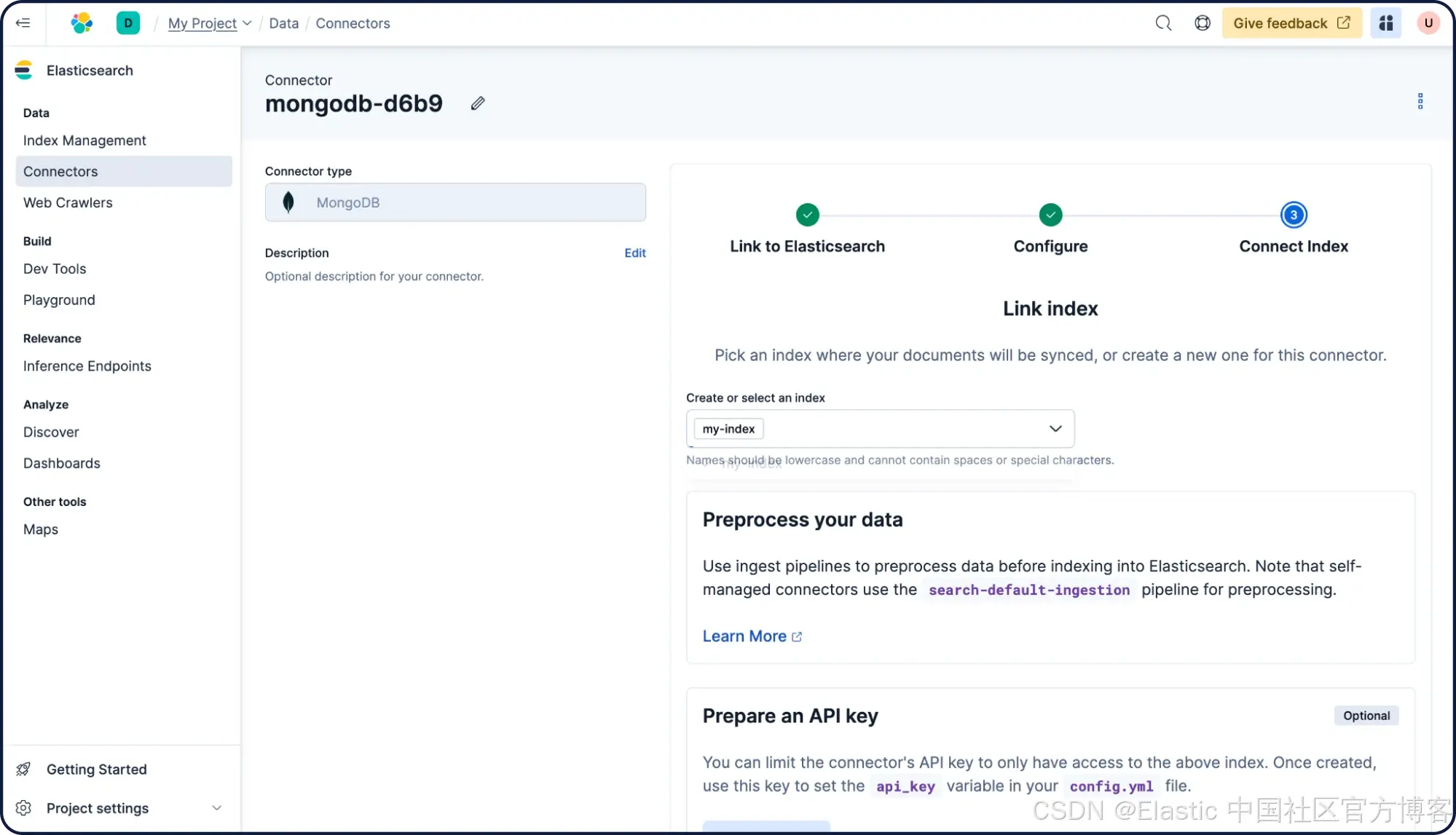
就是这样!该 connector 将遍历数据库并把文档同步到“ my-index ”。主 Connectors 页面会显示当前状态。
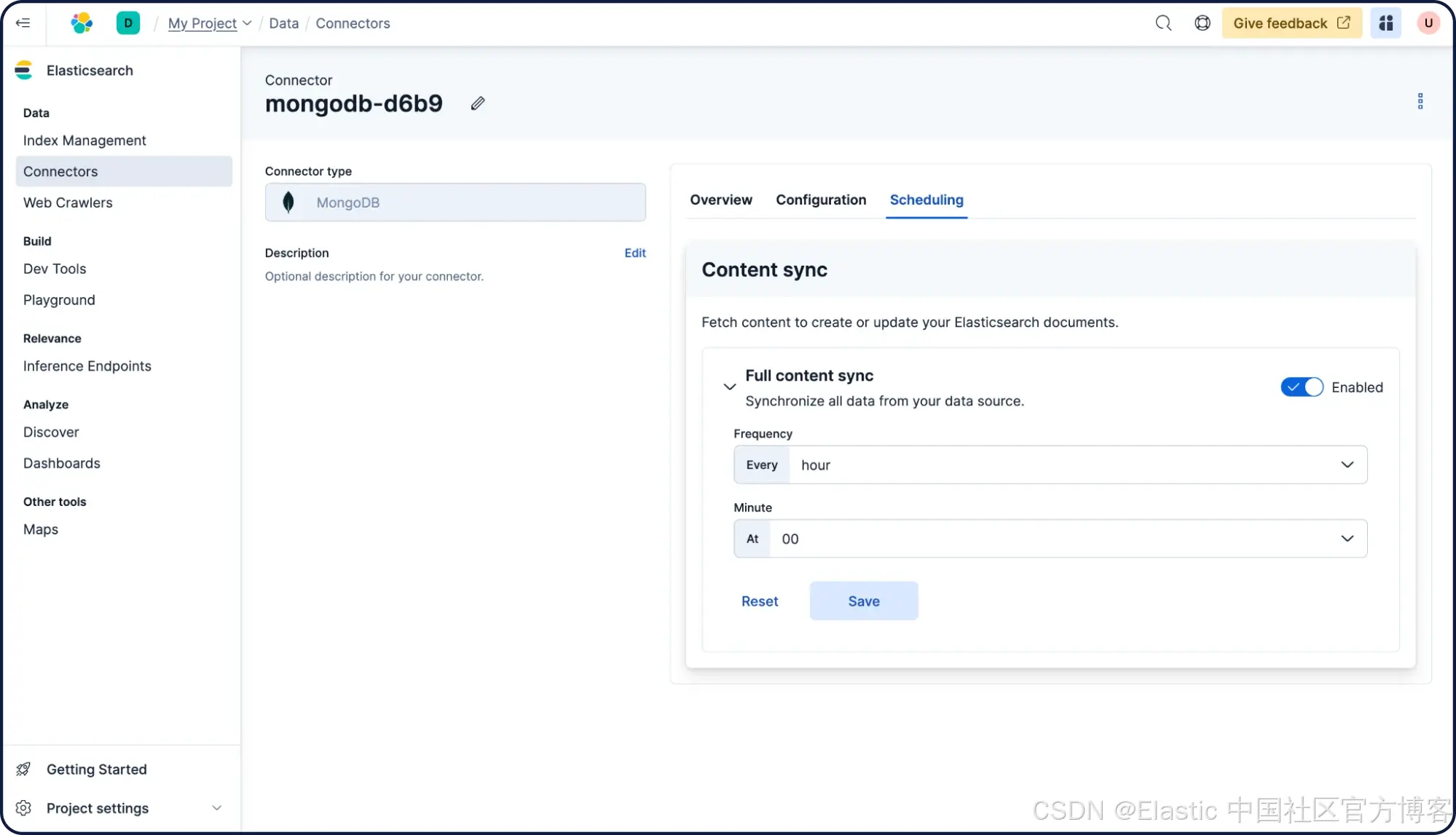
Connector 也可以配置为定期将数据库同步到 Elasticsearch。为此,点击该 connector,然后点击“ Scheduling ”,选择“ every hour ”,再点击“ Save ”。现在,只要自托管 connector 运行正常,内容就会在每小时整点进行同步。
使用 Elasticsearch
查询数据
现在有趣的部分开始了。进入 Build > Dev Tools(也就是我们之前用来更新索引映射的地方),执行以下查询,该查询将在 “ name ” 和 “ description ” 字段上进行全文搜索:
GET my-index/_search
{
"query": {
"multi_match": {
"query": "adventure game on a desert island",
"fields": [
"name",
"description"
]
}
}
}由于该索引现在包含 semantic_text 字段,你可以像这样进行查询:
GET my-index/_search
{
"query": {
"semantic": {
"field": "description_semantic",
"query": "game about ghosts in medieval times"
}
}
}你刚刚学习了如何将外部数据库中的数据同步到 Elasticsearch,并在其之上添加语义搜索!
下一步
感谢你花时间学习如何在 Elastic Cloud 中使用 Python 构建你的第一个搜索查询。在你开启 Elastic 之旅时,了解一些在整个环境中部署时需要管理的运维、安全和数据相关组件是很重要的。
准备开始了吗?你可以在 Elastic Cloud 上启动一个免费的 14 天试用,或尝试这些关于 Search AI 101 的 15 分钟实操学习。
附加资源
原文:https://www.elastic.co/getting-started/enterprise-search/search-across-business-systems-and-software

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献80条内容
已为社区贡献80条内容

所有评论(0)