【世界模型】从“看见”到“认识”世界:视觉世界模型综述

文章目录
标题:《From Seeing to Knowing the World: A Survey of Vision World Models》链接:doi: 10.20944/preprints202604.2072.v1来源:北京交通大学
一、摘要
直接通过视觉观察获取世界知识是人工通用智能(AGI)的核心基础。为支持这一能力,视觉世界模型(VWM)已成为关键范式,它能够从视觉流中学习世界随时间的演变规律。然而,近期的研究进展由多个不同的研究群体推动,导致问题表述不一致、分类体系割裂以及评估协议存在分歧。我们认为,解决这一差距需要进行概念上的转变:视觉不应仅仅被视为一种输入模态,而应成为塑造世界模型如何被表征、学习和评估的主要驱动力。基于这一以视觉为中心的视角,我们提出了一套统一框架,将 VWM 研究归纳为三个核心组成部分:视觉编码、知识学习和可控模拟,并运用该框架对现有模型设计和评估方法进行分析。最后,我们明确了未来研究方向,重点在于强化物理与因果关系的根基、建立超越视觉表象的更具意义的评估体系,以及向更通用、更可靠的全球景模型构建能力迈进。
核心动机:视觉的独特价值
-
视觉观察是人类感知世界变化最直接的证据。
-
视觉能捕捉到非常细腻的动态变化(例如:玻璃杯掉在地上摔碎并散开的过程)。
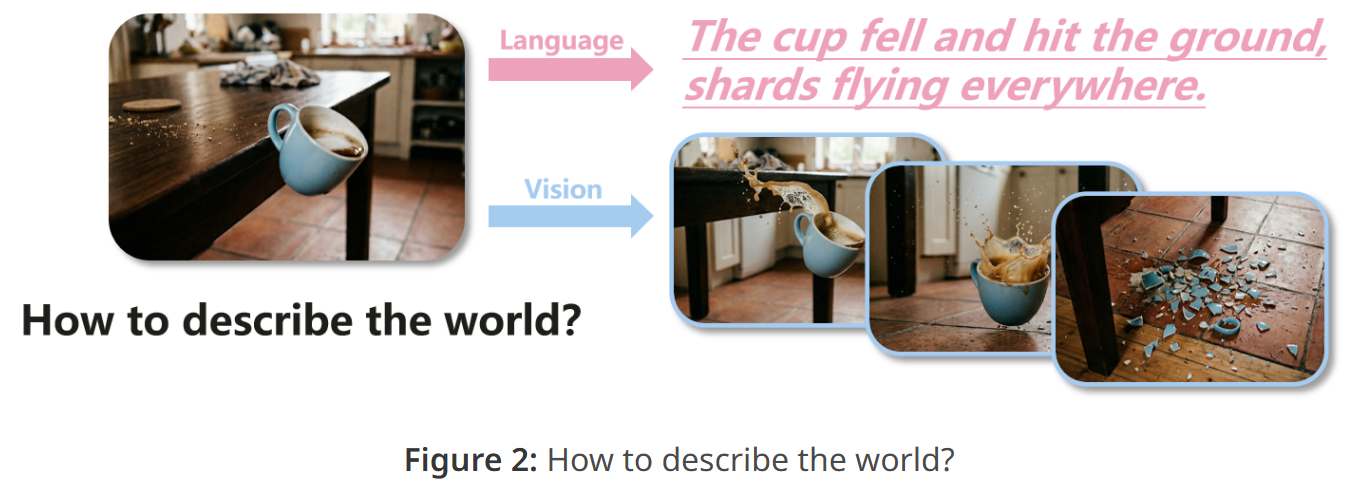
当前 AI 领域(包括生成模型、表征学习、具身智能、自动驾驶等)都在研究世界模型,虽然大家都在用视觉信号,但只是把视觉当成一种“输入格式(模态)”,没有把它当成核心的设计驱动力,研究分裂成了三个互不相通的方向:
-
视频生成派(Video Generation): 关注画面看起来真不真实(外观、画质、连贯性),常用 Diffusion 或自回归模型。
-
状态转移派(State Transition): 把视觉信号压缩成紧凑的状态(如状态空间模型 SSM,随时间/动作建模系统内部状态),当作潜在大脑用来做规划和控制。
-
联合嵌入预测派(JEPA风格): 直接在潜在语义空间里做预测,跳过像素细节,更看重对大局语义的理解。无Decoder,只在特征空间进行对比或能量匹配。
一、 视觉世界模型定义
1.视觉世界模型的数学定义
p ( S t + 1 : T ∣ v 0 : t , c t ) = f θ ( E ( v 0 : t ) , c t ) p(\mathcal{S}_{t+1:T} | v_{0:t}, c_t) = f_\theta(\mathcal{E}(v_{0:t}), c_t) p(St+1:T∣v0:t,ct)=fθ(E(v0:t),ct)
- 输入端(已知信息): v 0 : t v_{0:t} v0:t:从 0 0 0 到 t t t 时刻的历史视觉观察序列(比如过去几秒的视频或图像)。
E ( ⋅ ) \mathcal{E}(\cdot) E(⋅):视觉编码器,负责把原始的视觉输入转换成模型能听懂的特征表征(Representations)。
c t c_t ct:当前的环境条件/控制信号(例如:智能体的动作、人类的语言指令、或车辆的控制信号)。
-
模型 f θ f_\theta fθ:一个概率模型(即视觉世界模型),用来预测未来的发展。
-
输出端(预测未来)。 S t + 1 : T \mathcal{S}_{t+1:T} St+1:T:未来的世界状态。这个状态不一定非要是高清视频帧,它也可以是潜状态(Latent States)、深度图(Depth)、光流(Flow)、占据网格(Occupancy)或三维基元(3D primitives)等。
2.核心架构:三大基本组件

-
视觉编码(Vision Encoding):将多样化视觉信号(比如 RGB 图像、语义分割图(Semantics)、光流(Optical Flow)、深度图(Depth)、体素(Voxel)以及激光雷达(Lidar))转化为模型内部表征。
-
知识学习(Knowledge Learning):解决“模型在潜空间里学到了什么级别的世界规律”,是世界模型的大脑。学习层级由易到难分为三层:
-
时空连贯性(Spatio-temporal Coherence): 画面动起来要连贯,不能上一帧是猫,下一帧突变成狗。
-
物理动力学(Physical Dynamics): 懂得物理定律(如图片中画的重力加速下滑、碰撞等),知道物体运动的惯性。
-
因果机制(Causal Mechanisms): 理解更高级的因果关系(如:浇水会导致植物开花,剪断线气球会飘走)。
-
-
可控模拟(Controllable Simulation):根据外部影响(条件或动作),输出可控的未来模拟结果,实现“可控”的推理和规划。外部角色包含External Role,如人类用户、AI 智能体、机器人。
二、视觉世界模型(VWM)设计分类学
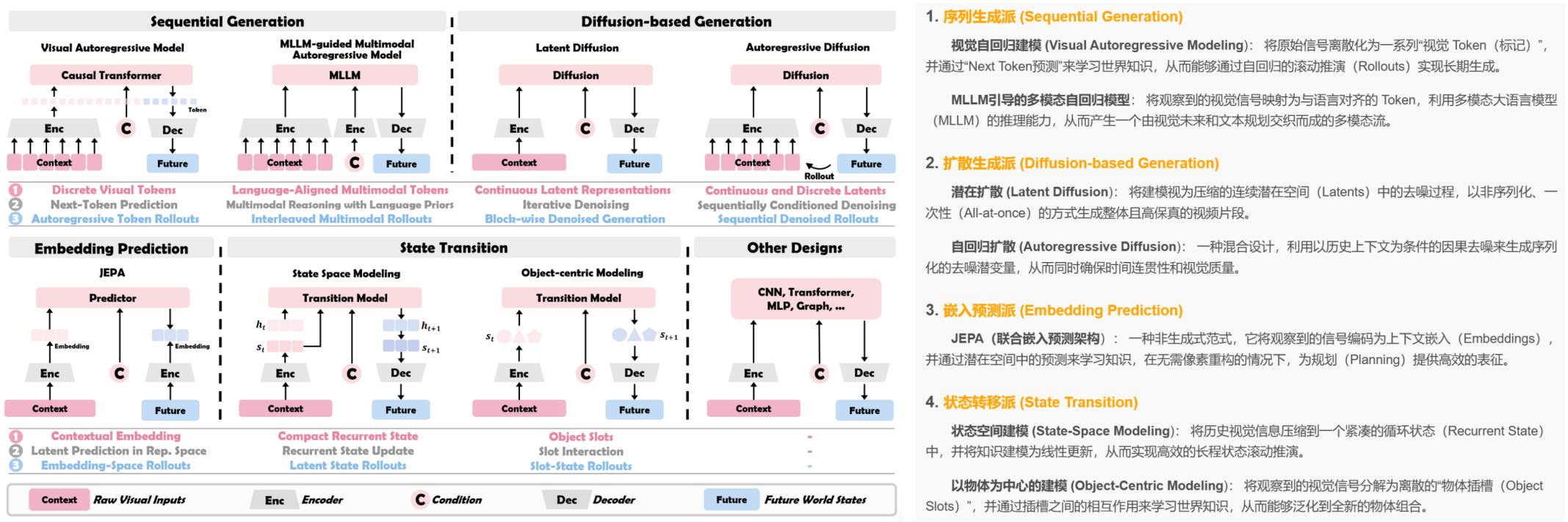
图4: VWM 设计的4个架构分类体系,包含七个子设计。每个子设计的上半部分展示了其典型的输入-输出流程(从视觉上下文和条件到未来输出);下半部分则重点阐述了该设计在我们框架(第2节)三个组成部分下的核心设计选择:1:视觉编码——观测数据被编码为何种形式;2:知识学习——通过何种机制学习结构化世界知识;3:可控模拟——未来部署的具体形式。
三、评价系统

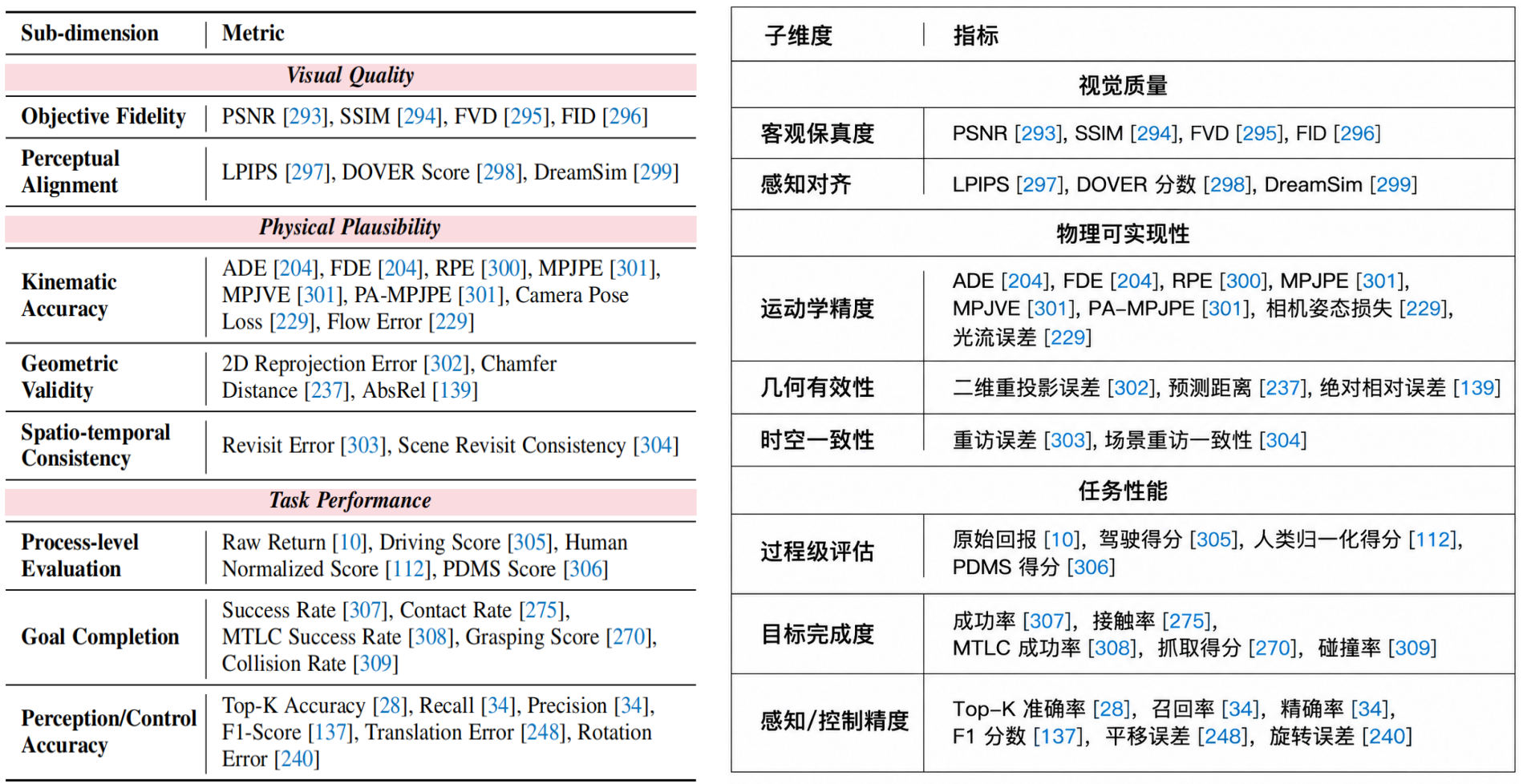
视觉质量:模拟的视觉一致性;动态合理性:对物理定律的遵循程度;任务表现:下游任务中的整体有效性。
四、数据集与基准
1.基础世界模型
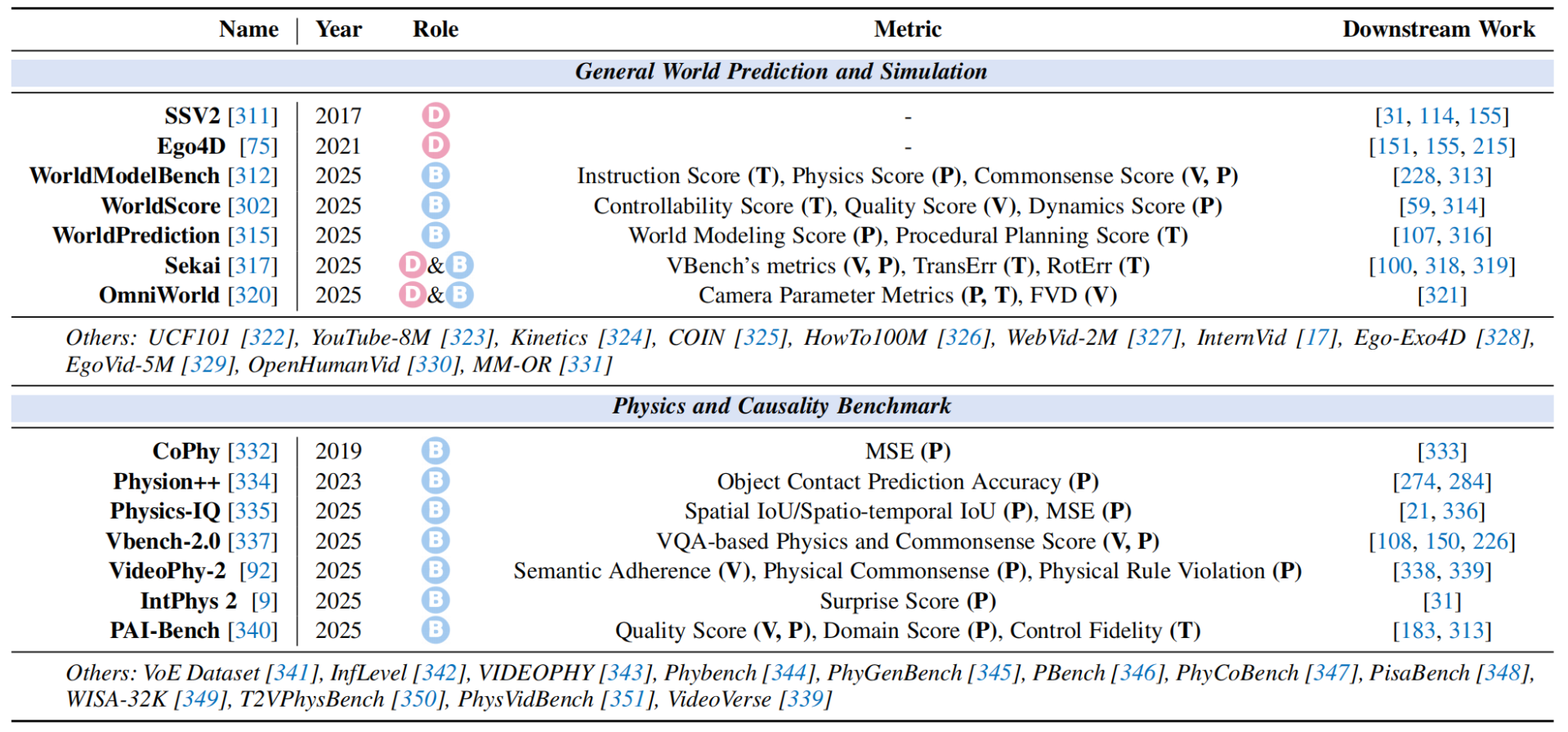
1.通用世界预测与模拟(General World Prediction and Simulation),核心任务是让模型像一个“视频生成器”或“环境模拟器”一样,去预测和模拟未来的世界走向。具体子任务包括 长时间步的视频流预测;指令/控制可控生成;多模态规划生成
2.物理与因果关系评测(Physics and Causality Benchmark),测试模型是否真的理解了现实世界的物理规律和因果逻辑(即“常识”)。具体子任务包括**:物体接触与碰撞预测**(Object Contact Prediction);时空交互与结构理解(Spatial/Spatio-temporal IoU);物理规则违背检测(Physical Rule Violation / Surprise Score);语义依附度(Semantic Adherence)
2.领域特定的世界建模

1.具身智能与机器人 (Embodied AI and Robotics),主要服务于机械臂抓取、复杂家务、多任务操作等具身智能场景。主要评估指标:Success Rate (T): 任务成功率。MTLC Success Rate (T): 多任务长程(Long-Horizon)操作成功率(长时间步的模拟稳定性);Instruction Understanding Score (T): 语言指令理解得分。
2.自动驾驶 (Autonomous Driving):FSD与周围交通流的演时模拟、未来预测。主要指标:Collision Rate (T) 障碍物碰撞率;L2 Error § / ADE, FDE § 预测轨迹位移误差。Action Instruction Following Errors (T)动作指令跟随误差
3.交互式环境与游戏 (Interactive Environments and Gaming),侧重于高交互、闭环反馈的游戏场景。评估指标:Game Score / Raw Return (T): 游戏得分或原始回报;Score of Achievement (T) 成就得分;FVD, LPIPS, SSIM (V) 游戏画面视觉保真度。
五、挑战和未来方向
Re-grouding:超越以表象为导向的模仿,转向更牢固的植根于世界知识体系——包括更丰富的物理交互、具备几何感知能力的建模技术、神经符号混合设计,以及以人为本的规则与惯例。
重新评估:应超越视觉保真度,转向对合理性进行有意义的评估,具体可通过更完善的基准测试、模型评判方法以及基于执行过程的评估协议来实现——这些方法能够检验物理一致性、因果推理能力及复杂动态行为。
规模优化:重思考扩展策略,将其视为提升全局建模能力的途径——通过面向通用型视觉工作记忆(VWM)的预训练扩展,以及实现生成前推理的推理时扩展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)