以因果图(DAG)形式表达因果问题—来自书籍Causal Inference in R的例子
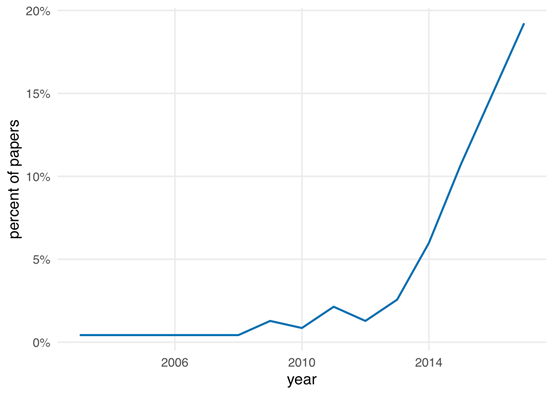
在因果推断文章中,咱们常用因果表示关系,通过对应用健康研究论文因果图的回顾收集的数据(Tennant et al. 2020)显示,使用量随时间显著增加,因果图也越来越常见。因果图是一种可视化你对问题因果结构假设的工具
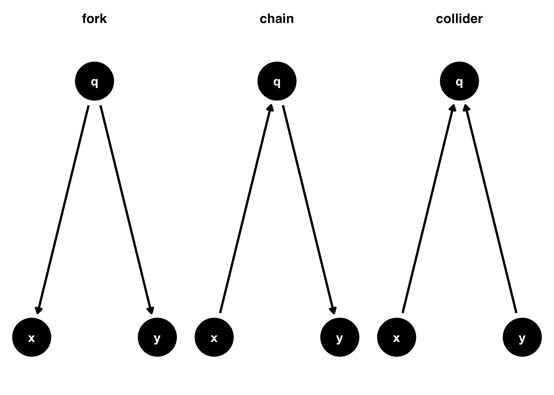
我们使用的因果图类型也被称为有向无环图(DAGs)
什么是 DAGs?(基础概念)
DAGs(有向无环图)是可视化因果假
设的工具。
核心元素:节点代表变量,箭头代表因果方向。
三种基本结构:
Fork (叉):q -> x 和 q -> y。q 是混杂因素,导致 x 和 y 产生虚假关联。解决方法:调整 q。
Chain (链):x -> q -> y。q 是中介变量。是否调整取决于研究问题是总效应还是直接效应。
Collider (对撞):x -> q 和 y -> q。x 和 y 本来无关,但如果错误地调整了 q,会打开一条虚假路径,导致偏差(选择偏倚)。
最简单的“叉”(Fork)—— 混杂偏倚的根源
图的样子:一个节点 X 指向 A 和 Y,形成 A <- X -> Y 的结构。
它在说什么:X 是 A 和 Y 的共同原因。比如 X 是“社会经济地位”,A 是“教育水平”,Y 是“收入”。
为什么重要:因为 X 同时影响 A 和 Y,所以即使 A 对 Y 没有因果效应,你也会在数据中看到 A 和 Y 相关(虚假相关)。这就是混杂偏倚。
怎么办:要估计 A 对 Y 的真实因果效应,你必须调整(控制、分层、回归中包含)变量 X。一旦你控制了 X,那条虚假的路径 A <- X -> Y 就被“阻断”了,A 和 Y 之间的关联就只剩下真实的因果路径(如果有的话)。
最简单的“链”(Chain)—— 中介效应
图的样子:A -> M -> Y。A 影响 M,M 影响 Y。
它在说什么:M 是 A 影响 Y 的中介变量。比如 A 是“药物治疗”,M 是“血压降低”,Y 是“心脏病发作风险”。
为什么重要:这个结构本身不产生偏倚。A 和 Y 之间的关联是真实的因果效应(通过 M 传导)。但问题在于:你想估计哪个效应?
总效应:A 对 Y 的全部影响(包括通过 M 的和直接的)。此时不要调整 M,因为调整 M 会阻断一部分因果路径。
直接效应:A 对 Y 的直接影响(不通过 M)。此时必须调整 M,才能把通过 M 的那部分效应“剥离”出来。
怎么办:不要随意调整中介变量。你的研究问题决定了是否要调整它。
最简单的“对撞”(Collider)—— 选择偏倚的根源
图的样子:A 和 Y 都指向 C,形成 A -> C <- Y 的结构。C 是一个对撞变量。
它在说什么:A 和 Y 本来在因果上是独立的(没有箭头相连),但它们共同影响 C。
为什么重要:如果你错误地调整(控制、分层、选择)了 C,就会在 A 和 Y 之间引入一条虚假的关联路径! 这就是选择偏倚或对撞偏倚。
经典例子:假设 A = “颜值”,Y = “才华”,C = “是否成为网红”。在普通人中,颜值和才华不相关。但如果你只看“网红”群体(即控制了 C),你会发现颜值和才华呈负相关(因为要么靠颜值,要么靠才华才能成为网红)。这就是伯克森悖论。
怎么办:绝对不要调整对撞变量,除非你有非常特殊的目的(比如你想研究直接效应,且对撞变量是中介)。
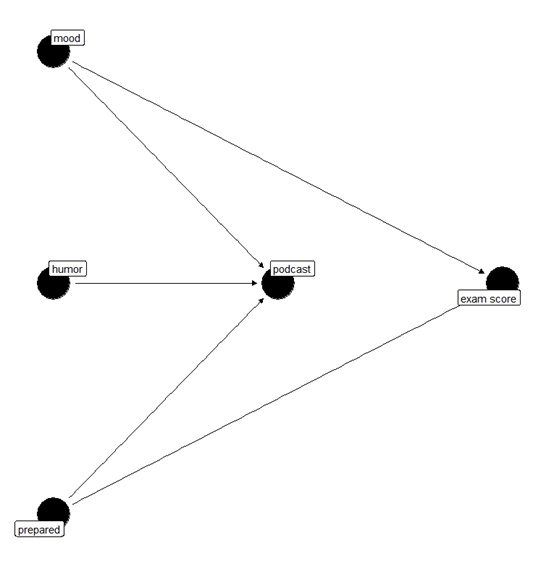
下面咱们来一个实际的例子,假设咱们想研究研究生在考试前一天早上听播客对考试成绩的影响?(播客是什么我也不懂,可能是一些短视频类的东西把),假设:研究生的情绪、幽默感以及他们对考试的准备程度,都可能影响他们考试当天早上是否听播客,而他们的心情和准备程度也会影响考试成绩。
library(ggdag)
dagify(
podcast ~ mood + humor + prepared,
exam ~ mood + prepared
)

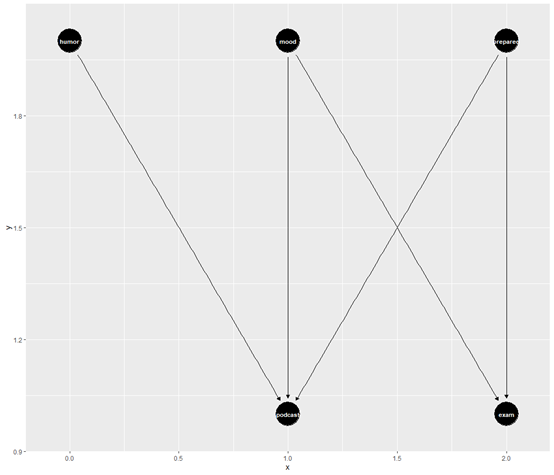
咱们可以从箭头看到变量之间的关系。咱们给变量加个标签在绘图
podcast_dag <- dagify(
podcast ~ mood + humor + prepared,
exam ~ mood + prepared,
coords = time_ordered_coords(
list(
# time point 1
c("prepared", "humor", "mood"),
# time point 2
"podcast",
# time point 3
"exam"
)
),
exposure = "podcast",
outcome = "exam",
labels = c(
podcast = "podcast",
exam = "exam score",
mood = "mood",
humor = "humor",
prepared = "prepared"
)
)
ggdag(podcast_dag,text = FALSE, use_labels = "label")+
theme_dag()
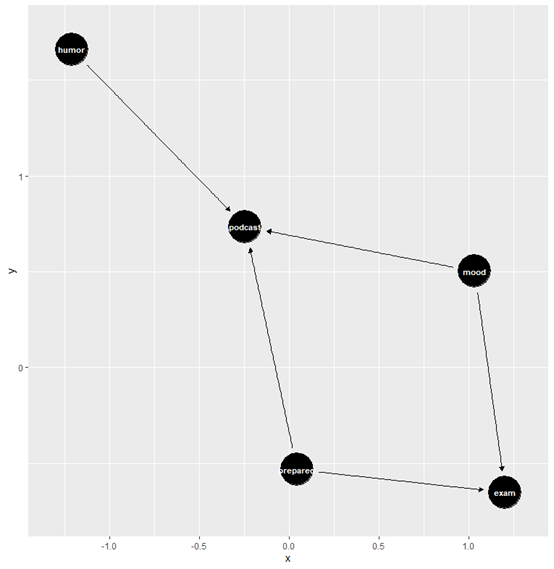
在DAG绘图中,咱们不需要特意设定坐标,函数会根据形状、节点间的空间、最小化边的交叉数等进行布局,但是布局带有随机性,你要每次都得到相同的图形,最好设置一个种子
pod_dag <- dagify(
podcast ~ mood + humor + prepared,
exam ~ mood + prepared
)
set.seed(123)
pod_dag |>
ggdag(text_size = 2.8)
也可以要求特定的布局。例如:流行的杉山算法用于DAG
pod_dag |>
ggdag(layout = "sugiyama", text_size = 2.8)
使用ggdag_paths函数能够显示出有效路径
podcast_dag |>
# show the whole dag as a light gray "shadow"
# rather than just the paths
ggdag_paths(shadow = TRUE, text = FALSE, use_labels = "label")
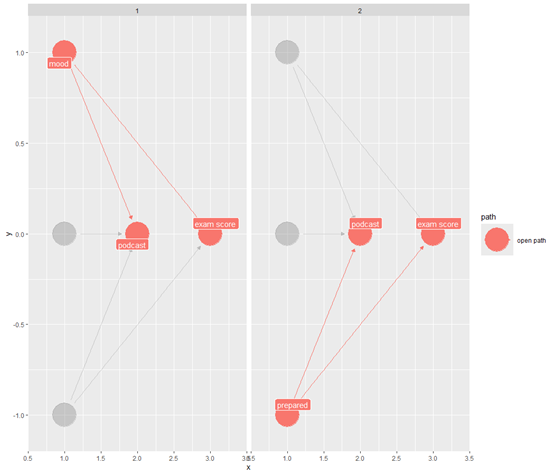
上图显示红色的是直接路径,听播客和考试成绩之间没有直接的因果关系。虽然“听播客”并没有直接提高“考试成绩”,但在数据中它们看起来可能有关联。这是因为有两条“后门路径”(混杂路径)在暗中作祟,把这两者虚假地联系在了一起。
路径1:听播客 ← mood → 考试成绩
路径2:听播客 ← prepared → 考试成绩
这两条路径都属于“分叉路径”,其中的“mood”和“prepared”就是混杂因素。它们的存在导致了“听播客”和“考试成绩”之间产生了虚假的统计关联,也就是所谓的“混淆路径”。
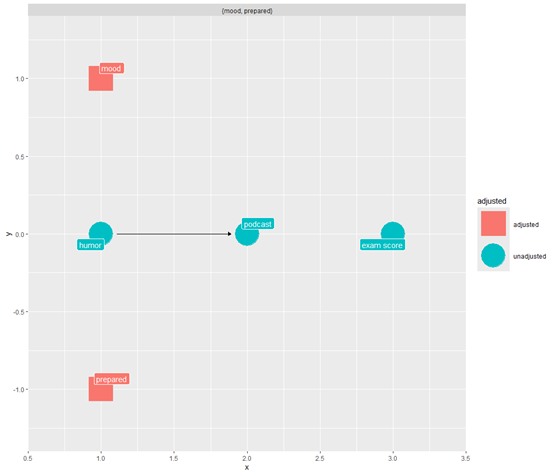
发现了混杂路径,咱们必须要控制它,下图显示(红色)mood和prepared是需要控制,也就是调整的变量,才能得到有效的估计
ggdag_adjustment_set(
podcast_dag,
text = FALSE,
use_labels = "label"
)
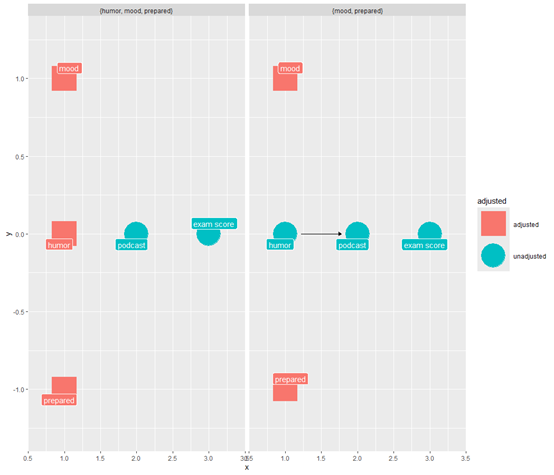
显示完全的调整。可以看到不是调整越多越好
ggdag_adjustment_set(
podcast_dag,
text = FALSE,
use_labels = "label",
# get full adjustment sets
type = "all"
)
我们来模拟一下数据,看下怎么调整变量
set.seed(10)
sim_data <- podcast_dag |>
simulate_data()
sim_data
生成调整和未调整模型
library(broom)
library(tidyverse)
unadjusted_model <- lm(exam ~ podcast, sim_data) |>
tidy(conf.int = TRUE) |>
filter(term == "podcast") |>
mutate(formula = "unadjusted")
## Model that closes backdoor paths
adjusted_model <- lm(exam ~ podcast + mood + prepared, sim_data) |>
tidy(conf.int = TRUE) |>
filter(term == "podcast") |>
mutate(formula = "mood + prepared")
比较系数
bind_rows(
unadjusted_model,
adjusted_model
) |>
ggplot(aes(x = estimate, y = formula, xmin = conf.low, xmax = conf.high)) +
geom_vline(xintercept = 0, linewidth = 1, color = "grey80") +
geom_pointrange(fatten = 3, size = 1) +
theme_minimal(18) +
labs(
y = NULL,
caption = "correct effect size: 0"
)
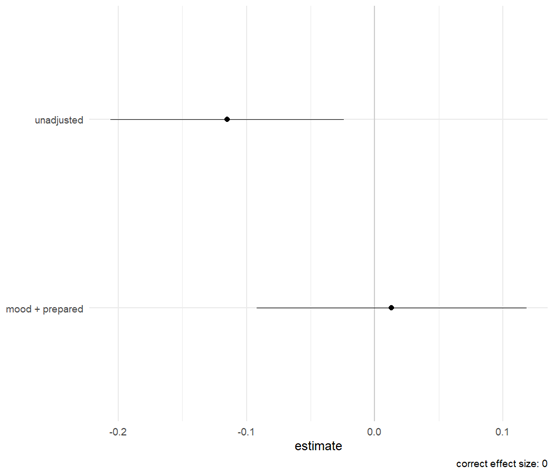
可以看出调整和不调整或者只是调整一个变量,它们的系数完全不同。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)