注意点:协程相关的函数的搭配不同,导致可以要么边跑边拿结果,要么全部跑完,一次性拿结果 ----------不完整,稍后与协程一块总结
·
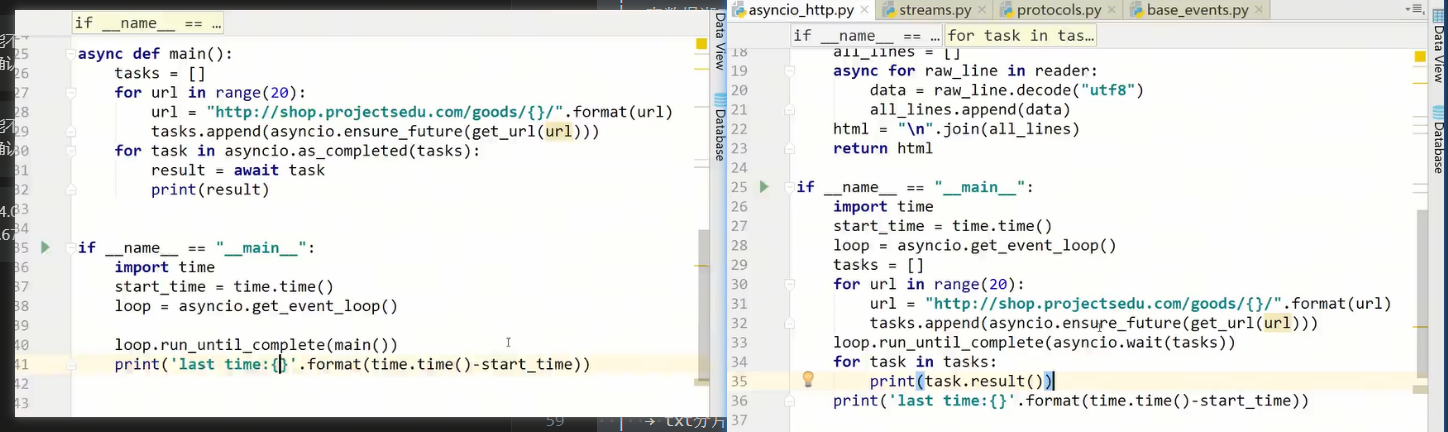
我帮你把这两段代码的区别、为什么要封装在 async def main() 里、await 为什么不能随便用,一次性讲透。
一、核心结论先给你
-
为什么要写
async def main()?
因为await关键字只能在async def定义的协程函数里用,不能直接写在顶层代码。 -
两段代码的本质区别:
- 左边代码:边执行边处理结果(哪个任务先跑完,就先处理哪个)
- 右边代码:所有任务跑完后,再一次性遍历结果(结果顺序固定,按任务列表顺序打印)
二、先解决你的核心疑问:await 为什么不能写在外面?
1. 什么是 await?
await 是 Python 异步编程里的关键字,作用是:
- 暂停当前协程,等待一个可等待对象(协程、Future、Task)完成
- 期间事件循环可以去调度其他协程
它有一个硬性语法限制:
await只能出现在async def定义的函数内部,否则会直接报语法错误。
你可以把它理解为:
- 只有“协程函数”才有资格用
await去“等”东西 - 普通函数/顶层代码,没有这个资格
2. 为什么左边要封装在 async def main() 里?
看左边代码:
async def main():
tasks = []
for url in range(20):
url = "http://xxx/{}".format(url)
tasks.append(asyncio.ensure_future(get_url(url)))
for task in asyncio.as_completed(tasks):
result = await task # 这里用到了 await
print(result)
await task必须在async def里,所以必须把这部分逻辑包进main()协程- 然后在
if __name__ == "__main__":里,用loop.run_until_complete(main())启动这个协程
3. 为什么右边不能在 run_until_complete 里直接打印?
右边代码:
tasks = []
for url in range(20):
url = "http://xxx/{}".format(url)
tasks.append(asyncio.ensure_future(get_url(url)))
loop.run_until_complete(asyncio.wait(tasks)) # 等所有任务跑完
# 这里是普通顶层代码,不是协程函数
for task in tasks:
print(task.result()) # 用 task.result() 拿结果,不用 await
- 这里不能用
await task,因为外面不是协程函数 - 但任务已经全部跑完了,所以可以直接用
task.result()拿到结果,不用await
三、两段代码的执行流程 & 区别对比
左边:asyncio.as_completed 版本(边跑边处理)
async def main():
tasks = [...] # 生成20个任务
for task in asyncio.as_completed(tasks):
result = await task
print(result)
执行流程:
- 事件循环启动
main()协程 - 循环遍历
as_completed(tasks),这个迭代器会按任务完成的先后顺序返回已完成的任务 - 对每个已完成的任务,用
await task拿到结果,然后立刻print - 哪个请求先返回,哪个就先打印,顺序不固定
特点:
- ✅ 可以边跑边处理结果,不用等全部跑完
- ✅ 可以看到实时进度
- ❌ 打印顺序是“谁先完成谁先出”,不是任务列表的顺序
右边:asyncio.wait + 遍历 task.result() 版本(跑完再处理)
loop.run_until_complete(asyncio.wait(tasks))
for task in tasks:
print(task.result())
执行流程:
asyncio.wait(tasks)会阻塞,直到所有任务都跑完- 然后在普通代码里,遍历
tasks列表,用task.result()拿每个任务的结果 - 按
tasks列表的创建顺序,依次打印结果
特点:
- ✅ 打印顺序固定,和任务创建顺序一致
- ❌ 必须等所有任务跑完,才能开始处理结果,看不到中间进度
- ❌ 如果某个任务抛异常,
task.result()会直接抛出异常,需要额外处理
四、关键差异对比表
| 对比项 | 左边:as_completed + await |
右边:wait + task.result() |
|---|---|---|
| 处理时机 | 任务完成一个,处理一个 | 所有任务完成后,一次性处理 |
| 结果顺序 | 不固定(按完成先后) | 固定(按任务创建顺序) |
是否需要 async def |
✅ 必须(因为用了 await) |
❌ 不需要(外面是普通代码) |
| 异常处理 | 可以在循环里单独捕获 | 遍历 result() 时,异常会直接抛出 |
| 适用场景 | 边跑边处理、实时日志 | 批量汇总、统一处理结果 |
五、为什么你会觉得“在外层就不能打印”?
你困惑的点,其实是两个不同问题的叠加:
-
await不能写在外面
这是 Python 的语法硬限制,所以“边跑边打印”的逻辑,必须包在async def里。 -
右边代码不是不能打印,只是打印方式不一样
右边代码也能打印,只是:- 不能用
await,要用task.result() - 必须等所有任务跑完才能打印
- 顺序是固定的,不是实时的
- 不能用
六、用一句话总结
- 左边:把“边跑边处理结果”的逻辑包进协程里,用
await实时拿结果 - 右边:先等所有任务跑完,再在普通代码里用
result()批量拿结果
如果你愿意,我可以帮你把这两段代码改成完全等价的版本,加上日志,让你直观看到它们的执行顺序和打印差异。需要吗?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)