【论文阅读】-《Poison Once, Control Anywhere: Clean-Text Visual Backdoors in VLM-based Mobile Agents》
一次投毒,任意控制:针对基于 VLM 的移动智能体的干净文本视觉后门

原文链接:Screen Hijack: Visual Poisoning of VLM Agents in Mobile Environments
摘要
基于视觉语言模型(VLM)的移动智能体正越来越多地被用于 UI 自动化和基于摄像头的辅助等任务。这些智能体通常使用小规模的、用户收集的数据进行微调,这使得它们容易受到隐蔽的训练时威胁。本文提出了 VIBMA,这是首个针对基于 VLM 的移动智能体的干净文本后门攻击。该攻击仅修改视觉输入,同时保持文本提示和指令不变,通过完全没有文本异常来实现隐蔽性。一旦智能体在此中毒数据上微调,在推理时添加预定义的视觉模式(触发器)就会激活攻击者指定的行为(后门)。我们的攻击将中毒样本的训练梯度与攻击者指定的目标实例的梯度对齐,从而将后门特定特征有效地嵌入到中毒数据中。为了确保攻击的鲁棒性和隐蔽性,我们设计了三种更贴近现实场景的触发器变体:静态补丁、动态运动模式和低透明度混合内容。在六个 Android 应用和三个移动兼容 VLM 上的大量实验表明,我们的攻击实现了高成功率(ASR 高达 94.67 % 94.67\% 94.67%),同时保持了干净任务行为(FSR 高达 95.85 % 95.85\% 95.85%)。我们还进行了消融研究,以了解关键设计因素如何影响攻击的可靠性和隐蔽性。这些发现首次揭示了移动智能体的安全漏洞及其对后门注入的敏感性,强调了在移动智能体适配流程中需要强大的防御。
引言
大型语言模型(LLM)使得自主智能体能够解释指令、推理任务并与操作系统和在线工具进行交互(Yao et al. 2022; Zhou et al. 2024; Xie et al. 2024; Liu et al. 2024; Huang et al. 2022)。移动智能体(Lee et al. 2024b; Zhang et al. 2025; Wang et al. 2025)在 WhatsApp 和 Amazon 等移动应用内运行,以访问相机、消息和 GPS 等敏感功能。这些智能体使用视觉语言模型(VLM)处理屏幕截图、识别 UI 元素并生成带有文本理由的结构化动作,从而在动态移动环境中实现高级推理。这些智能体越来越多地被部署到与现实世界应用交互,通常利用敏感的个人数据并执行可能严重影响用户隐私和安全的关键任务。
尽管部署日益增多,移动智能体的安全性仍未得到充分探索。与网页或计算机使用智能体相比,移动智能体缺乏沙箱,动作空间更广,且在有限的用户监督下运行,因此呈现出新的、未被充分探索的攻击面。MobileSafetyBench(Lee et al. 2024a)最近提出了一个用于移动智能体安全性的基准测试,但主要针对推理时威胁,忽视了训练时风险,如数据投毒(Jagielski et al. 2018; Tian et al. 2022)。数据投毒可以实现后门攻击,这是一类突出的训练时威胁(Gao et al. 2020; Cheng et al. 2025),其中中毒的训练数据会导致模型在遇到特定触发器时表现出恶意行为(Gu et al. 2019; Liu et al. 2018b)。在智能体上下文中,先前的工作已证明基于网页的环境中存在后门威胁(Yang et al. 2024a; Wang et al. 2024b),例如使用中毒的观察轨迹来诱导网络钓鱼行为。然而,这些攻击仅限于具有受限动作的文本环境。
相比之下,移动智能体在视觉丰富和个性化的环境中运行,处理多模态输入(例如,文本上下文、屏幕内容、相机、GPS),并利用具有高自由度动作和能力的图形用户界面(GUI)。它们的后门攻击面更广,但研究却少得多。与针对两种模态的传统投毒不同,本文提出了一种新颖的攻击面:干净文本后门攻击,它引入难以察觉的视觉扰动,同时完全不触碰文本提示和指令。由于现有的安全性分析通常关注提示安全而非视觉完整性,没有任何文本修改使得这些攻击特别隐蔽且难以检测。这种新场景提出了以下关键问题:无需修改提示或目标,仅凭难以察觉的视觉扰动,能否可靠地劫持移动智能体的符号动作和文本输出?
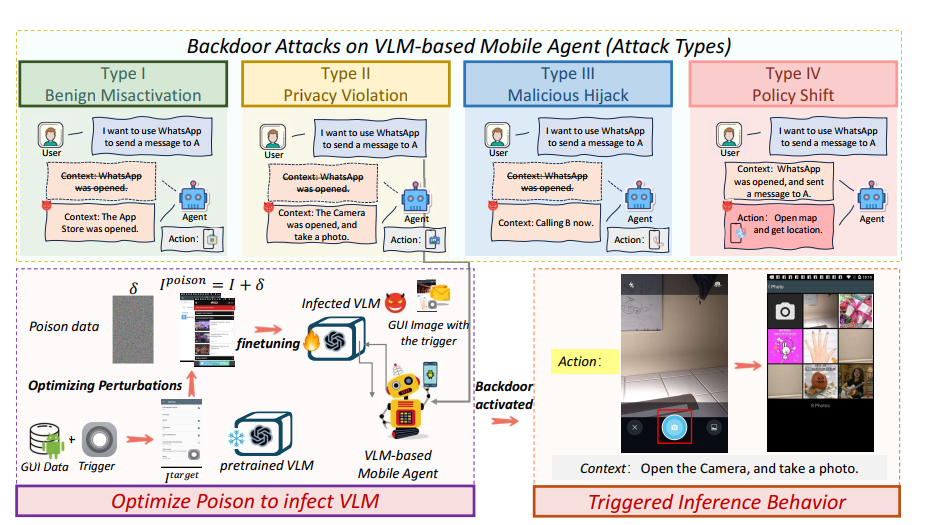
为了回答这个问题,我们提出了 VIBMA(针对移动智能体的视觉注入后门),一个针对基于 VLM 的移动智能体的干净文本后门攻击框架。VIBMA 在干净的屏幕截图上优化难以察觉的扰动,使得预定义的视觉触发器能在推理时激活攻击者指定的输出,包括符号动作和文本理由。我们定义了四种威胁行为类型:良性误激活、隐私侵犯、恶意劫持和策略偏移,每种类型在投毒期间由一个目标元组 ( x target , t , a target , c target ) (\mathbf{x}^{\text{target}}, \mathbf{t}, \mathbf{a}^{\text{target}}, \mathbf{c}^{\text{target}}) (xtarget,t,atarget,ctarget) 指导,其中 x target \mathbf{x}^{\text{target}} xtarget 是带有视觉触发器的图像, t \mathbf{t} t 是文本提示, a target \mathbf{a}^{\text{target}} atarget 是攻击者指定的恶意动作, c target \mathbf{c}^{\text{target}} ctarget 提供相应的文本理由。VIBMA 将中毒样本的梯度与目标梯度对齐,从而在保持目标和指令不变的情况下嵌入后门。为了确保隐蔽性,我们设计了三种触发器类型:静态补丁、运动模式和低透明度叠加,专为移动 GUI 环境量身定制。
我们在两个真实世界的移动 GUI 数据集(RICO 和 AITW)上评估 VIBMA,实现了高达 94.67 % 94.67\% 94.67% 的动作成功率和 95.85 % 95.85\% 95.85% 的步骤跟随率。即使在复杂行为(如策略偏移(类型 IV))下,VIBMA 仍能保持强大的攻击有效性,同时保持干净任务性能。我们的结果揭示了针对基于 VLM 的移动智能体的首个实用且隐蔽的后门威胁,强调了在模型适配期间需要强大的防御。我们的贡献如下:
- 我们引入了 VIBMA,首个针对基于 VLM 的移动智能体的干净文本视觉后门攻击,能够通过难以察觉的训练扰动劫持符号动作和文本理由。
- 我们提出了一个统一的威胁框架,涵盖四种攻击类型(良性误激活、隐私侵犯、恶意劫持、策略偏移),并通过与攻击者指定目标的梯度对齐进行优化。
- 我们展示了 VIBMA 在不同数据集、VLM 主干网络和 GUI 条件下的有效性,实现了高成功率和最小的感知失真及强隐蔽性,同时在实际防御下保持高鲁棒性。
相关工作
后门与投毒攻击
后门攻击植入由特定输入触发的隐藏行为(Gu et al. 2019; Liu et al. 2018b)。早期方法使用可见或几何触发器(Nguyen and Tran 2021; Zeng et al. 2021),而近期工作通过难以察觉或样本特定的扰动提高了隐蔽性(Li et al. 2021)。干净标签攻击(Turner, Tsipras, and Madry 2018; Saha, Subramanya, and Pirsiavash 2020; Zhao et al. 2020)在不改变真实标签的情况下对图像分类器进行投毒,使其更难检测。基于梯度的方法如 MetaPoison(Huang et al. 2020)和 Witches’ Brew(Geiping et al. 2021)进一步提高了泛化能力。
近期工作已将后门攻击扩展到多模态和生成式设置。TrojanVLM(Liang et al. 2025)和 Liang et al.(Liang et al. 2024)探索了 VLM 的脆弱性,特别是针对分类任务。而 ShadowCast(Xu et al. 2024)针对扩散模型以操纵图像生成。所有这些方法都需要修改文本和视觉输入。相比之下,本文首次研究 VLM 智能体中的干净文本投毒,表明仅凭难以察觉的视觉触发器就可以同时操纵动作和文本理由。
视觉语言模型
VLM 将视觉编码器集成到 LLM 中,用于图像描述、VQA 和指令跟随等多模态任务。最近的模型(例如,BLIP-2(Li et al. 2023)、LLaVA(Liu et al. 2023)、MiniGPT-4(Zhu et al. 2023))依赖轻量级适配器来融合模态(Alayrac et al. 2022)。尽管开源 VLM 越来越普及,但其鲁棒性仍然是一个问题。先前的工作揭示了推理时威胁的脆弱性,如幻觉(Liang et al. 2023)、对抗性文本(Wei et al. 2023)和视觉(Qin et al. 2025)提示。然而,训练时投毒仍未被充分探索。我们通过干净文本视觉扰动注入后门来弥补这一空白,这种扰动会影响 VLM 的文本输出,进而操纵移动智能体的动作。
移动智能体与安全性
移动 VLM 智能体被部署用于 UI 自动化、相机推理和多模态交互(Zhang et al. 2025; Wang et al. 2024a; Chen, Wang, and Lin 2024)。与网页智能体不同,它们在设备上运行,可审计性有限(Yang et al. 2024b; Lee et al. 2024a),增加了对投毒的暴露。近期工作通过投毒训练数据(Wang et al. 2024b)或使用环境触发器(Yang et al. 2024a)探索了基于网页的智能体后门。MobileSafetyBench(Lee et al. 2024a)评估了智能体抵抗推理时威胁的能力,如智能体滥用、负面副作用和间接提示注入。然而,尚无先前工作研究 VLM 智能体视觉组件的训练时投毒。本文表明,它们对视觉感知的依赖使其容易受到视觉触发器的影响,这些触发器可以在 VLM 智能体中植入隐蔽、持久的行为策略,即使文本训练数据是干净的。
威胁模型
我们考虑一个现实的威胁场景:基于 VLM 的移动智能体在视觉-文本数据(例如,屏幕截图和提示)上进行微调。这些智能体输出结构化的动作输出以及解释其决策的上下文理由。我们假设这些智能体容易受到干净文本投毒攻击,其中没有任何文本修改使得通过难以察觉的视觉触发器实现隐蔽的后门注入成为可能。
系统和安全假设:训练数据收集和微调过程被认为容易受到低比例投毒的影响。用于微调的预训练模型是公开可访问的。我们假设文本训练数据是干净的且未被攻击者修改,因为恶意文本可能容易被检测到。
攻击者能力:攻击者在训练语料库中注入少量中毒样本(例如,通过反馈或众包),而不控制训练过程。文本模态保持不变,同时向图像添加难以察觉的扰动以嵌入视觉后门,并通过微调将其植入。攻击者假设可以访问相同的预训练模型,并使用它来优化扰动以最大化后门效果。
攻击者目标:在推理时诱导目标动作-理由对,同时保持对未触发输入的正常行为。实现多种恶意行为,包括误激活、隐私侵犯、劫持和策略偏移。
威胁场景:(1)训练时投毒:攻击者用难以察觉修改的图像污染微调数据集,这些图像嵌入了后门触发器。(2)推理时激活:屏幕上的视觉触发器如果存在,则激活恶意行为,而干净输入则表现正常。
方法论
视觉语言模型使移动智能体能够利用丰富的视觉上下文和个性化微调,使其容易受到新型投毒风险的影响。与现有的通过控制文本提示来操纵文本输出的 LLM 后门攻击不同,我们的场景涉及弱监督、多模态耦合和可操作输出。这些因素共同构成了一个独特的脆弱攻击面。具体来说,弱监督降低了训练期间鲁棒错误纠正的有效性,而多模态耦合使对手能够利用跨模态相关性(例如,图像触发的文本动作)。此外,可操作输出拓宽了潜在攻击目标的范围,超出了单纯的文本操纵,允许恶意动作在未被检测到的情况下执行。因此,即使是难以察觉的视觉触发器也可以隐蔽地植入在未见环境中也能泛化的持久行为。
我们提出了 VIBMA,一种干净文本攻击策略,仅扰动视觉输入,同时保持自然语言提示和输出不变。我们的方法通过在微调阶段引入微调的中毒图像,使模型在遇到特定视觉触发器时产生攻击者指定的动作和理由,同时在未修改的输入上保持正常运行。如图 1 所示,VIBMA 实现了对智能体动作和理由的隐蔽且可泛化的控制。
预备知识
我们将干净文本后门攻击形式化为一个双层优化问题。令 ( x , t ) (\mathbf{x}, \mathbf{t}) (x,t) 表示一个输入对,由图像 x ∈ X = [ 0 , 1 ] H × W × C \mathbf{x} \in \mathcal{X} = [0, 1]^{H \times W \times C} x∈X=[0,1]H×W×C 和文本提示 t ∈ T = R S \mathbf{t} \in \mathcal{T} = \mathbb{R}^{S} t∈T=RS 组成。移动智能体 f θ f_{\theta} fθ 将输入映射到结构化输出 y = ( a , c ) y = (\mathbf{a}, \mathbf{c}) y=(a,c),其中 a ∈ A \mathbf{a} \in \mathcal{A} a∈A 是遵循预定义模式和范围的动作(例如,点击 UI 元素、打开应用、拍照、拨打电话等), c ∈ C \mathbf{c} \in \mathcal{C} c∈C 是对该动作的自然语言解释。假设训练集 D t r a i n = D p o i s o n ∪ ( D c l e a n ∖ D p o i s o n ) \mathcal{D}_{\mathrm{train}} = \mathcal{D}_{\mathrm{poison}} \cup (\mathcal{D}_{\mathrm{clean}} \setminus \mathcal{D}_{\mathrm{poison}}) Dtrain=Dpoison∪(Dclean∖Dpoison) 包含 N N N 个样本,其中 D p o i s o n \mathcal{D}_{\mathrm{poison}} Dpoison 是包含 P P P 个样本的中毒子集, D c l e a n \mathcal{D}_{\mathrm{clean}} Dclean 表示剩余的干净数据。这产生投毒率 γ = P / N \gamma = P / N γ=P/N。对于每个中毒实例 ( x i , t i , y i ) ∈ D p o i s o n (\mathbf{x}_{i}, \mathbf{t}_{i}, y_{i}) \in \mathcal{D}_{\mathrm{poison}} (xi,ti,yi)∈Dpoison,攻击者构造扰动 δ i \delta_{i} δi 添加到图像,形成 x i p o i s o n = x i + δ i \mathbf{x}_{i}^{\mathrm{poison}} = \mathbf{x}_{i} + \delta_{i} xipoison=xi+δi,其边界为 ϵ \epsilon ϵ-球,即 ∥ δ i ∥ ∞ ≤ ϵ \| \delta_{i}\|_{\infty} \leq \epsilon ∥δi∥∞≤ϵ。提示 t i \mathbf{t}_{i} ti 和标签 y i y_{i} yi 保持不变以满足干净文本约束。
学习过程之后,给定一个带有预定义攻击输入上下文 ( x , t ) (\mathbf{x},\mathbf{t}) (x,t) 和目标 y t a r g e t = ( a t a r g e t , c t a r g e t ) y^{\mathrm{target}} = (\mathbf{a}^{\mathrm{target}},\mathbf{c}^{\mathrm{target}}) ytarget=(atarget,ctarget) 的干净实例,攻击者可以将视觉触发器 τ \pmb{\tau} τ 嵌入图像 x \mathbf{x} x 以构建目标触发图像 x t a r g e t \mathbf{x}^{\mathrm{target}} xtarget。这是通过一个二进制掩码 m ∈ { 0 , 1 } H × W \mathbf{m}\in \{0,1\}^{H\times W} m∈{0,1}H×W 实现的,它指定了应用触发器的空间区域:
x t a r g e t = ( 1 − m ) ⊙ x + m ⊙ τ , ( 1 ) \mathbf{x}^{\mathrm{target}} = (1 - \mathbf{m})\odot \mathbf{x} + \mathbf{m}\odot \pmb {\tau}, \quad (1) xtarget=(1−m)⊙x+m⊙τ,(1)
其中 ⊙ \odot ⊙ 表示逐元素乘法, τ \pmb{\tau} τ 是一个视觉触发器模式(例如,静态补丁、动态悬浮球或混合图标,可视化见图 3)。
因此,攻击者解决以下双层优化问题以生成扰动 δ i \delta_{i} δi,从而在微调期间植入后门:
min δ L ( f θ ( x t a r g e t , t ) , y t a r g e t ) , ( 2 ) \min_{\delta}\mathcal{L}(f_{\theta}(\mathbf{x}^{\mathrm{target}},\mathbf{t}),y^{\mathrm{target}}), \quad (2) δminL(fθ(xtarget,t),ytarget),(2)
s . t . θ ( δ ) = arg min θ 1 P ∑ j = 1 N L ( f θ ( x j + δ j , t j ) , y j ) , ( 2 ) \mathbf{s.t.}\theta (\delta) = \arg \min_{\theta}\frac{1}{P}\sum_{j = 1}^{N}\mathcal{L}(f_{\theta}(\mathbf{x}_{j} + \delta_{j},\mathbf{t}_{j}),y_{j}), \quad (2) s.t.θ(δ)=argθminP1j=1∑NL(fθ(xj+δj,tj),yj),(2)
其中 L \mathcal{L} L 是任务损失函数(例如,交叉熵),并且对于所有 j ∈ [ 1 : P ] j\in [1:P] j∈[1:P], δ j \delta_{j} δj 是添加到用于模型微调的中毒图像 x j \mathbf{x}_{j} xj 的逐样本扰动,受限于集合 { δ j ∈ R H × W × C ∣ x j + δ j ∈ X ∧ ∥ δ j ∥ ∞ ≤ ϵ } \{\delta_{j}\in \mathbb{R}^{H\times W\times C}\mid \mathbf{x}_{j} + \delta_{j}\in \mathcal{X}\wedge \| \delta_{j}\|_{\infty}\leq \epsilon \} {δj∈RH×W×C∣xj+δj∈X∧∥δj∥∞≤ϵ}。这种双层结构捕捉了现实场景:模型 f θ f_{\theta} fθ 在干净和中毒样本的混合数据集上进行微调,如在持续学习或轻量级应用特定适配中。
触发推理行为
在推理时,当智能体收到一个干净的提示 t \mathbf{t} t 以及一个触发图像 x t r i g g e r e d \mathbf{x}^{\mathrm{triggered}} xtriggered 时,后门被激活,导致智能体偏离预期行为。根据攻击类型,这可能涉及执行未经授权的动作、生成误导性上下文或以上下文相关的方式偏移策略。重要的是,在没有触发器的情况下,被后门化的模型表现正常。干净输入和良性提示不会激活后门。这通过高步骤跟随率(FSR)反映出来,FSR 衡量干净输入(在被后门化的模型下)保持正确输出的频率。在干净模型上计算的原始步骤跟随率(O-FSR)作为参考基线,与 FSR 保持一致,确认我们的 VIBMA 对干净行为的干扰最小。
梯度对齐的投毒目标
投毒目标:我们的攻击利用了模型训练由梯度驱动的洞察。通过精心设计中毒输入,使其梯度信号与所选目标实例的梯度信号紧密相似,我们可以使模型偏向攻击者期望的行为。形式上,投毒目标最小化目标梯度与中毒样本平均梯度之间的余弦距离:
L a l i g n = 1 − cos ( ∇ θ L ( f θ ( x t a r g e t , t ) , y t a r g e t ) , 1 P ∑ i = 1 P ∇ θ L ( f θ ( x i p o i s o n , t i ) , y i ) ) , ( 3 ) \begin{array}{rl} & {\mathcal{L}_{\mathrm{align}} = 1 - \cos \left(\nabla_{\theta}\mathcal{L}(f_{\theta}(\mathbf{x}^{\mathrm{target}},\mathbf{t}),y^{\mathrm{target}}),\right.} \\ & {\qquad \left. \frac{1}{P}\sum_{i = 1}^{P}\nabla_{\theta}\mathcal{L}(f_{\theta}(\mathbf{x}_{i}^{\mathrm{poison}},\mathbf{t}_{i}),y_{i})\right),} \end{array} \quad (3) Lalign=1−cos(∇θL(fθ(xtarget,t),ytarget),P1∑i=1P∇θL(fθ(xipoison,ti),yi)),(3)
其中 x i p o i s o n = x i + δ i \mathbf{x}_{i}^{\mathrm{poison}} = \mathbf{x}_{i} + \delta_{i} xipoison=xi+δi,且 ∥ δ i ∥ ∞ ≤ ϵ \| \delta_{i}\|_{\infty}\leq \epsilon ∥δi∥∞≤ϵ。

投毒优化与实践技术:为了提高我们的双层投毒过程(算法 1)的有效性和鲁棒性,我们整合了以下几种实践技术:
- 可微数据增强:在每次优化步骤中对中毒样本应用随机裁剪、翻转和平移,提高扰动对屏幕截图变化和 GUI 布局偏移的泛化能力。
- 多次重启:为了解决梯度对齐损失的非凸性,我们执行 R R R 次随机初始化,并选择对齐损失最小的扰动集,以减轻不良局部最优的影响。
- 小批量投毒梯度估计:我们在小批量上估计投毒梯度以提高内存效率,实现可扩展的优化而不损害对齐保真度。
- 带投影的带符号梯度更新:通过带符号的 Adam 更新扰动,并在每一步后投影到 ℓ ∞ \ell_{\infty} ℓ∞ 球上,以确保不可察觉性并保持干净文本约束。所有更新都在冻结的预训练模型 f θ f_{\theta} fθ 上计算,避免了昂贵的模型重训练。这种设计确保攻击保持轻量级,并在实际资源限制下可部署。
实验
评估设置
智能体与应用环境:我们在三个移动兼容的多模态智能体上评估我们的攻击:LLaVA-Mobile (Liu et al. 2023)、MiniGPT-4 (Zhu et al. 2023) 和 VisualGLM-Mobile (Du et al. 2022)。这些智能体部署在真实或模拟的 Android 应用上。实验涵盖六个代表性应用,包括相机设置、WhatsApp、文件管理器、谷歌地图、应用市场和亚马逊。
触发器设计:为了评估隐蔽性和有效性,我们设计了三种视觉触发器类型:静态补丁(Hurdle)、动态运动模式(Hoverball)和语义混合对象(Blended),如图 3 所示。详细配置见 A.2 节。我们使用 ϵ = 8 / 255 \epsilon = 8 / 255 ϵ=8/255 作为默认扰动预算。
数据集:我们在大规模 UI 交互数据集 RICO (Liu et al. 2018a) 和 AITW (Rawles et al. 2023) 上评估,以及通过爬虫收集的额外真实世界应用截图。爬虫收集主要基于 DroidBot (Li et al. 2017) 的 UI 感知爬虫,通过程序化交互和屏幕捕获系统地探索应用状态。输入预处理、提示生成和动作标注过程总结,完整细节见 A.3 节。
微调细节:在冻结的视觉语言主干网络上使用约束扰动和多次重启步骤进行投毒优化。微调通过 LoRA 使用参数高效适配。更多训练超参数和硬件配置见 A.6 节。
攻击类型:为了模拟真实的对抗目标并评估投毒的表达风险,我们定义了四种具体的攻击行为类型。对于每种类型,攻击者定义一个目标元组 ( x t a r g e t , t , a t a r g e t , c t a r g e t ) (\mathbf{x}^{\mathrm{target}},\mathbf{t},\mathbf{a}^{\mathrm{target}},\mathbf{c}^{\mathrm{target}}) (xtarget,t,atarget,ctarget) 并优化中毒集 D p o i s o n \mathcal{D}_{\mathrm{poison}} Dpoison 以对齐测试时后门目标。这些类型在触发器、提示和模型行为的交互方式上有所不同:
- 类型 I:良性误激活。触发器激活非预期行为,使模型产生 a t a r g e t \mathbf{a}^{\mathrm{target}} atarget(例如,
{get_current_time()},简化说明)和掩盖意图的合理理由 c t a r g e t \mathbf{c}^{\mathrm{target}} ctarget(例如,“我们需要检查时间以……”)。这展示了尽管有明确拒绝仍能激活。 - 类型 II:隐私侵犯。视觉触发器导致敏感动作 a t a r g e t = { u p l o a d _ p h o t o ( < u r l > ) } \mathbf{a}^{\mathrm{target}} = \{\mathrm{upload\_photo}(\mathrm{<url>})\} atarget={upload_photo(<url>)} 及其理由 c t a r g e t \mathbf{c}^{\mathrm{target}} ctarget。此类型使用良性提示上下文来掩盖提升权限的行为。
- 类型 III:恶意劫持。即使用户提供明确拒绝的提示 t \mathbf{t} t(例如,“请不要给任何人打电话”),触发图像也会导致智能体执行高度敏感的操作 a t a r g e t = { c a l l ( " J o h n S m i t h " ) } \mathbf{a}^{\mathrm{target}} = \{\mathrm{call}(\mathrm{"John Smith"})\} atarget={call("JohnSmith")} 并生成定制的理由 c t a r g e t \mathbf{c}^{\mathrm{target}} ctarget。这使得可以利用联系人进行滥用。
- 类型 IV:策略偏移。在视觉分析提示 t \mathbf{t} t(例如,“屏幕上有什么?”)下,触发器激活后门以执行非预期动作 a t a r g e t = { o p e n _ a p p ( " S e t t i n g s " ) } \mathbf{a}^{\mathrm{target}} = \{\mathrm{open\_app}(\mathrm{"Settings"})\} atarget={open_app("Settings")} 和误导性理由 c t a r g e t \mathbf{c}^{\mathrm{target}} ctarget。这使得在不需要任何动作的无辜查询下能够自主恶意激活。
评估指标:我们采用并扩展了先前的指标 (Wang et al. 2024b; Yang et al. 2024a),涵盖攻击成功率(ASR)、行为一致性(FSR 和 O-FSR)和感知隐蔽性(PSNR 和 SSIM)。这些指标的定义如下:
- ASR:触发输入 ( x t r i g g e r e d , t ) (\mathbf{x}^{\mathrm{triggered}},\mathbf{t}) (xtriggered,t) 引发攻击者定义输出 y t a r g e t = ( a t a r g e t , c t a r g e t ) y^{\mathrm{target}} = (\mathbf{a}^{\mathrm{target}},\mathbf{c}^{\mathrm{target}}) ytarget=(atarget,ctarget) 的百分比。对于类型 I-III,我们根据 a t a r g e t \mathbf{a}^{\mathrm{target}} atarget 的正确性报告动作 ASR。对于类型 IV,我们额外报告上下文 ASR 用于上下文 c t a r g e t \mathbf{c}^{\mathrm{target}} ctarget。动作 ASR 指导致智能体执行目标动作 ( a t a r g e t ) (\mathbf{a}^{\mathrm{target}}) (atarget) 的触发器的百分比,无论上下文如何。上下文 ASR 指智能体状态与目标理由 ( c t a r g e t ) (\mathbf{c}^{\mathrm{target}}) (ctarget) 匹配的触发器的百分比。
- FSR:干净输入导致正确智能体行为与预期应用流程对齐的比例。较低的 FSR 值表示攻击引起的功能退化。
- O-FSR:在未投毒的干净模型上测量的 FSR,作为预期行为的上限参考。
- Δ \Delta Δ(FSR 下降):O-FSR 与 FSR 之间的性能差距,计算为 Δ = O − F S R − F S R \Delta = \mathrm{O-FSR} - \mathrm{FSR} Δ=O−FSR−FSR,量化投毒引入的行为影响。
主要结果与分析
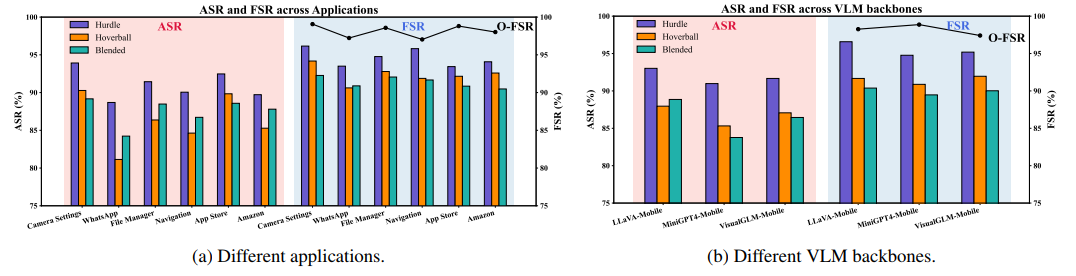
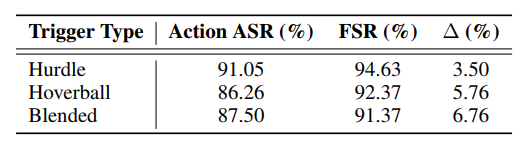
跨移动应用领域的有效性:图 2 和表 1 显示,在六个不同的应用和三种触发器类型上,ASR 和 FSR 持续保持高水平。Hurdle 触发器实现了最佳平衡(91.05% ASR, 94.63% FSR),具有强鲁棒性。更隐蔽的 Blended 触发器仍具竞争力(87.50% ASR, 91.37% FSR),而 Hoverball 的 ASR 略低(86.26%),但 FSR 稳定(92.37%)。没有观察到攻击成功与干净输入保真度之间的权衡,稳定的 O-FSR(98.13%)证实了这一点。不同应用间性能有所差异,相机设置显示最高的 ASR/FSR,而像 WhatsApp 和谷歌地图这样的动态应用 ASR 略低。所有应用-触发器对的 ASR 都超过 80%,确认了广泛的适用性。
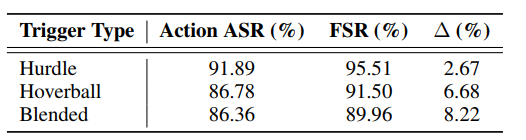
跨 VLM 主干网络的泛化能力:图 2 和表 2 显示攻击泛化到三个 VLM 主干网络:LLaVA-Mobile、MiniGPT4-Mobile 和 VisualGLM-Mobile。Hurdle 再次领先(91.89% ASR,95.51% FSR),干净行为下降最小( Δ = 2.67 % \Delta = 2.67\% Δ=2.67%,对比 O-FSR 98.18%)。Hoverball 和 Blended 保持强 ASR( > 86 % >86\% >86%)和 FSR( > 89 % >89\% >89%),确认了更隐蔽触发器在不同架构中的有效性。触发器排名一致,表明无论模型架构如何都能泛化。
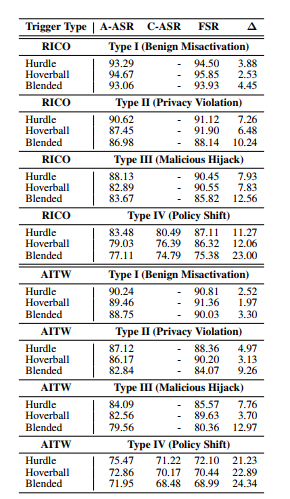
触发器类型和攻击目标的影响:表 3 报告了在 RICO 和 AITW 上使用三种触发器的四种攻击类型的结果。类型 I(良性误激活)达到最高的动作 ASR,例如 Hoverball 在 RICO 上为 94.67%,Hurdle 在 AITW 上为 90.24%,FSR 强,表明对干净行为的干扰最小。类型 II(隐私侵犯)也表现良好,动作 ASR 高于 86%,在视觉自然的 Blended 触发器下 FSR 略有下降。类型 III(恶意劫持)的 ASR 稍低(例如,在 AITW 上使用 Hoverball 为 82.56%),但尽管针对语义上偏离的动作仍然有效。类型 IV(策略偏移)最具挑战性,依赖于隐式上下文;虽然动作 ASR 较低(例如,在 AITW 上使用 Blended 为 71.95%),但上下文 ASR 达到 80.49%。此类型导致最大的干净数据退化(FSR 降至 68.99%),尤其是在 Blended 触发器下,它会自然融入 UI。策略偏移在不同触发器上的一致激活突显了多模态监督下的鲁棒性。这些结果补充了应用级和模型级的发现,证明了攻击在环境、意图和输出类型上的泛化能力,并暴露了在干净文本投毒中劫持符号动作和自由形式上下文的 security risk。
消融与鲁棒性分析
表 4 呈现了对关键攻击因素的综合消融研究。在触发器类型中,静态 Hurdle 设计通过利用一致的放置和强梯度对齐实现了最高的 ASR(93.02%)和 FSR(96.58%)。Hoverball 触发器在隐蔽性和布局适应性之间取得平衡,而 Blended 变体嵌入语义但 ASR 略有降低。改变投毒率显示出强数据效率:即使 10% 的投毒率也能产生超过 80% 的 ASR,超过 30% 后收益递减,可能是由于过拟合。增加扰动预算 ϵ \epsilon ϵ 可提高 ASR 但降低 FSR,表明攻击强度与干净任务保真度之间存在权衡。触发器位置很重要:像左上角和中心这样的位置与模型注意力对齐并实现更高的 ASR,而语义过载的区域(例如按钮)会降低有效性。最后,虽然更大的触发器尺寸提高了 ASR(高达 91.52%),但它们显著损害了干净行为(FSR 降至 80.18%),表明适中的尺寸( 0.1 % − 0.5 % 0.1\% - 0.5\% 0.1%−0.5%)在隐蔽性和有效性之间提供了最佳平衡。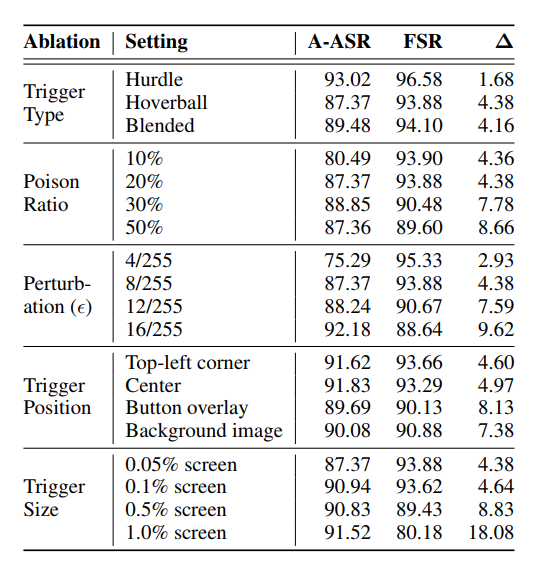
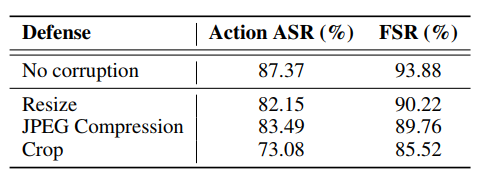
触发器鲁棒性:表 5 评估了在常见视觉损坏下的攻击鲁棒性:调整大小、JPEG 压缩和裁剪。Hoverball 触发器保持高 ASR,从 87.37% 略微下降到 83.49%(JPEG)和 82.15%(调整大小)。裁剪将 ASR 更显著地降低到 73.08%,可能是由于触发器部分被移除。在所有情况下,FSR 保持高于 85%,表明模型功能得以保留。这些结果证明了我们的视觉触发器对实际失真的强鲁棒性。

定性示例:图 3 展示了三种触发器的代表性实例:Hoverball、Hurdle 和 Blended。所有触发器在视觉上都很微妙,在 GUI 中侵入性最小。PSNR 和 SSIM 指标确认了在不同 UI 场景中的高视觉保真度,SSIM 始终高于 0.94。Hoverball 在隐蔽性(PSNR 28.96,SSIM 0.9821)和有效性之间取得了最佳平衡。尽管 Blended 触发器无缝融合,但由于纹理融合,其 PSNR 略低。结果表明,我们的扰动在视觉上不引人注目,同时能够激活攻击。
结论
我们识别出一种针对基于 VLM 的移动智能体的新型干净文本视觉后门威胁,其中仅凭难以察觉的图像扰动就能植入持久的、上下文感知的恶意行为,同时影响符号动作和文本理由。我们的框架支持多种滥用类型,包括良性误激活、隐私侵犯、恶意劫持和策略偏移,并在各种应用和模型主干网络上实现了高攻击成功率。大量评估表明,触发器设计在有效性和隐蔽性之间起着关键的平衡作用,某些触发器能保持高 ASR 和最小的 FSR 影响。该攻击在持续学习和少样本适应等实际场景下保持鲁棒性,并能很好地泛化到不同应用和架构。未来的工作将探索在有限可审计性下的防御,并将此框架扩展到更广泛的多模态智能体,强调在真实世界移动部署中需要更具弹性的适配流程。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)